TL;DR
- 场景:分布式服务拆分后,服务间通信从同步调用演进到异步解耦,伴随重试、幂等、可靠性问题
- 结论:同步链路必须"有界重试+可观测+降级",跨服务副作用用"任务化/MQ+幂等+补偿"兜底
- 产出:一套选型对照(RPC vs HTTP)、同步/异步落地骨架、以及常见故障速查与修复动作

分布式架构通信
SOA
在面向服务的架构(SOA)中,系统设计会根据实际的业务需求进行模块化拆分,将整体系统分解为多个独立部署的服务模块。每个服务模块都具有明确的业务边界,专注于特定的业务功能,例如订单服务、支付服务、库存服务等。这些模块之间通过定义良好的接口进行交互,保持相互独立。
这种架构具有以下显著优势:
- 分布式特性:服务可以部署在不同的服务器或容器中,充分利用分布式计算资源
- 松耦合:服务之间通过接口契约进行交互,内部实现可以独立演进
- 扩展灵活:可以根据业务需求单独扩展某个服务,而不影响其他服务
- 可重用性:服务可以被多个业务系统复用,减少重复开发
在SOA实现中,通常会采用Dubbo和ZooKeeper来构建服务间的远程通信机制:
- Dubbo作为高性能的RPC框架,负责处理服务间的调用通信,提供负载均衡、服务容错等功能
- ZooKeeper作为分布式协调服务,用于服务的注册与发现,维护服务的可用性状态
典型的工作流程包括:
- 服务提供者启动时向ZooKeeper注册服务
- 服务消费者从ZooKeeper获取可用的服务列表
- 通过Dubbo的RPC机制进行远程调用
- ZooKeeper持续监控服务健康状态,更新服务注册信息
例如在电商系统中:
- 订单服务需要调用支付服务完成支付
- 支付服务又会调用银行接口服务
- 每个服务都可以独立部署和扩展
- 通过Dubbo+ZooKeeper实现这些服务间的可靠通信
微服务
Feign 简介
Spring Cloud 中使用 Feign 来解决服务之间远程通信的问题。Feign 是一个轻量级的 RESTful HTTP 客户端,它广泛用于 Spring Cloud 微服务架构中,特别符合面向接口化编程的习惯。
Feign 的主要特点:
- 声明式 REST 客户端,通过简单的接口定义即可完成服务调用
- 集成了 Ribbon 实现客户端负载均衡
- 支持 Hystrix 熔断机制
- 内置多种编码器和解码器
- 可扩展的注解支持
Feign 的实现原理
Feign 本质上封装了 HTTP 调用流程,其工作方式类似于 Dubbo 的服务调用模式,但底层是基于 HTTP 而非 RPC。开发者只需定义一个接口并用注解修饰它,Feign 就会自动处理请求的生成和响应的解析。
典型使用示例:
java
@FeignClient(name = "user-service")
public interface UserServiceClient {
@GetMapping("/users/{id}")
User getUserById(@PathVariable("id") Long id);
}RPC 与 HTTP 协议比较
RPC 协议特点
- 主要基于 TCP/UDP 底层协议
- 通常是长连接,减少了每次通信的握手开销
- 通信效率更高,适合高频服务调用
- 序列化协议更紧凑(如 Protobuf、Thrift)
- 典型实现:Dubbo、gRPC、Thrift
HTTP 协议特点
- 作为应用层协议构建在 TCP 之上
- 通常是短连接,每次请求需要三次握手
- 开发迭代更快,适合快速原型开发
- 文本协议更易调试(REST/JSON)
- 典型实现:Spring Cloud Feign、RestTemplate
协议选择建议
适用 HTTP 的场景
- 系统间接口数量较少(<20个)
- 交互频率较低(<100次/分钟)
- 需要快速开发和调试
- 跨语言调用需求明显
- 对网络穿透性要求高(如需要经过代理)
适用 RPC 的场景
- 系统间接口数量较多(>50个)
- 高频交互需求(>1000次/分钟)
- 对性能要求苛刻(延迟<10ms)
- 内部服务间通信
- 需要复杂服务治理功能(如链路追踪、熔断降级)
在 Spring Cloud 生态中,Feign 提供了良好的平衡点,既保持了 HTTP 的简单性,又通过优化手段提升了性能,是微服务间通信的理想选择。
分布式同步通信
电商项目中,如果后台添加商品信息,该信息需要放到数据库。与此同时,需要同步更新搜索引擎的倒排索引。此外,如果有静态的页面的,也需要同步更新。
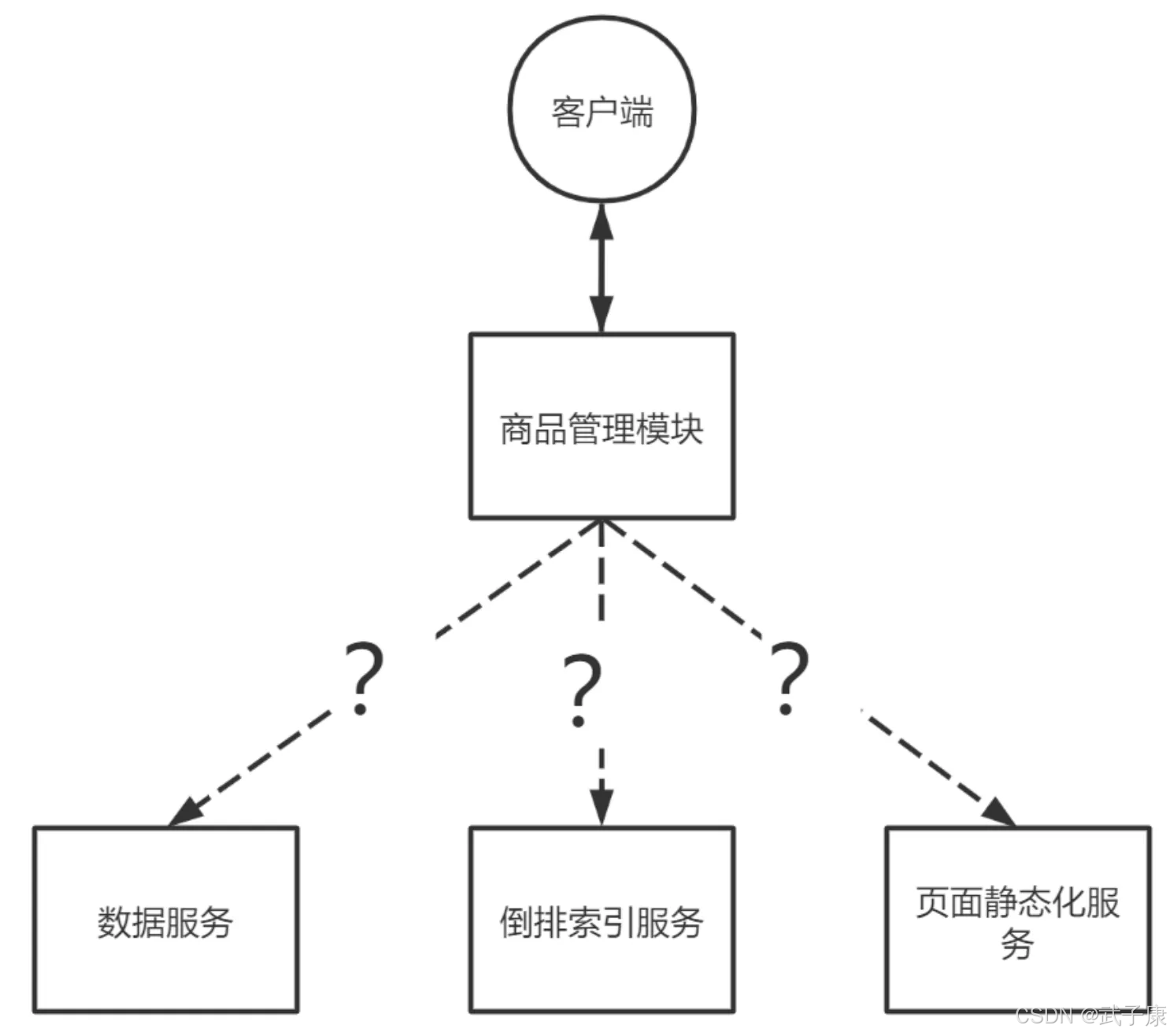
可是,这个复杂的过程应该如何实现?
方法一
可以在后台添加商品的方法中,如果数据插入数据库成功,就调用更新倒排索引的方法,接着调用更新静态化页面的方法。
java
// 方案1:最简同步 Demo(写入成功后立刻刷新)
Long goodsId = addGoods(goods);
if (goodsId == null) {
return;
}
refreshInvertedIndex(goods);
refreshStaticPage(goods);问题:
- 倒排索引更新失败怎么办?
- 页面静态化失败怎么办?
我们可以通过重试的方式来解决:
java
// 方案2:带重试的同步 Demo(避免递归死循环;可控重试次数 + 可选退避)
private static final int MAX_RETRY = 3;
private static final long BASE_BACKOFF_MS = 100;
public Long saveGoods(Goods goods) {
Long goodsId = addGoods(goods);
if (goodsId == null) {
return null;
}
boolean indexOk = retry(() -> indexService.refreshIndex(goods), MAX_RETRY, BASE_BACKOFF_MS);
boolean pageOk = retry(() -> staticPageService.refreshStaticPage(goods), MAX_RETRY, BASE_BACKOFF_MS);
// Demo 场景下可按需要记录结果
// log.info("goodsId={}, indexOk={}, pageOk={}", goodsId, indexOk, pageOk);
return goodsId;
}
@FunctionalInterface
private interface CheckedBooleanSupplier {
boolean getAsBoolean() throws Exception;
}
private boolean retry(CheckedBooleanSupplier action, int maxRetry, long baseBackoffMs) {
for (int attempt = 1; attempt <= maxRetry; attempt++) {
try {
if (action.getAsBoolean()) {
return true;
}
} catch (Exception ignored) {
// Demo:忽略异常;生产建议日志 + 指标 + 告警
}
// 最后一轮不再 sleep
if (attempt < maxRetry && baseBackoffMs > 0) {
sleepQuietly(baseBackoffMs * attempt); // 线性退避;也可改指数退避
}
}
return false;
}
private void sleepQuietly(long ms) {
try {
Thread.sleep(ms);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}但是在以上的代码中有问题:
- 如果相应的更新一直是失败的,岂不是一直死循环直到调用栈崩溃?
- 如果相应的更新一直是重试的,添加商品调用是不是一直是阻塞的?
- 如果添加商品的时候并发量很大,效率岂不是很低?
或许可以加上迭代等待时间、重试的次数等等,还可以加上多线程等等。
但是问题是:如果是一直失败该怎么办呢?
方法二
可以先执行添加商品的方法,将更新索引和静态页面更新缓存到一个公共的位置,然后由相应的服务从该位置获取任务来执行。
java
// 方案3:异步任务 Demo(主链路只落库;刷新交给任务系统)
Long goodsId = addGoods(goods);
if (goodsId == null) {
return;
}
goodsTaskService.cache(goods); // 入队/缓存,后续由 worker 刷新索引与静态页此时,由于添加商品仅仅是将数据插入数据库,然后将任务信息缓存,调用立刻返回。对于添加商品方法的调用,不会存在线程阻塞,不会存在调用栈崩溃。
由于更新倒排索引的服务和更新静态页面的服务要从公共的缓存或者任务池中取出任务执行,他们也会有执行失败的问题,也需要重试。如果一直更新失败,也需要一个方式来处理。比如更新失败,每隔3秒重试,重试3次就放弃执行等等。
最后将错误放到一个公共服务中,等待后续的补偿,无论是手工补偿还是自动补偿。
但是也有了新的问题:
- 公共服务,会不会宕机?是否存在不可用的情况?
- 确定消息发送到公共服务了吗?
- 如何向公共服务重试呢?
- 如果重试的时候发送成功了,但是发送了很多次,倒排索引和静态页面是否重复执行呢?
- 如果这几个服务重复执行了,最终结果会一样吗?
分布式服务中,用于业务拆分,应用也需要拆分,甚至数据库分库分表。
但是完成一个业务处理,往往要设计到多个模块之间的协调处理。此时模块之间,服务与服务之间以及客户端与服务端之间的通信会变得非常复杂。
分布式异步通信
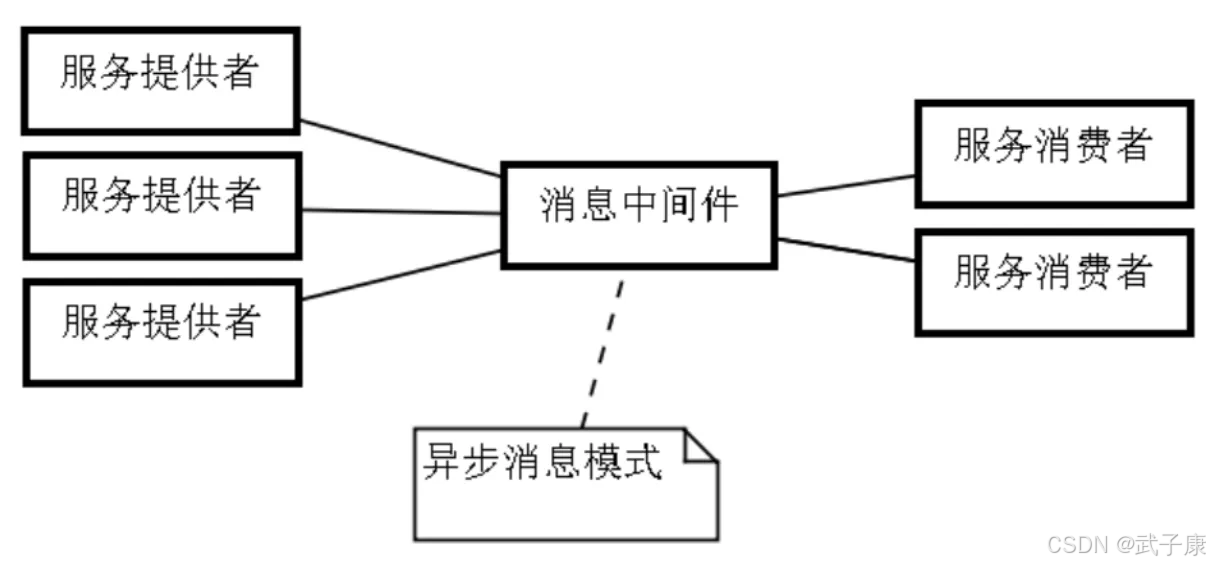
比较典型的:生产者消费者模式,可以跨平台、支持异构系统,通常借助消息中间件来完成。这种模式通过消息队列作为中间媒介,将消息的生产者(Producer)和消费者(Consumer)解耦。常见实现包括RabbitMQ、Kafka等消息中间件,支持不同编程语言(如Java、Python、Go等)和不同操作系统(Linux、Windows等)的系统间通信。例如,电商系统中的订单服务(生产者)可以将订单消息发送到消息队列,由库存服务(消费者)异步处理,两个服务可以独立部署和扩展。
优点:
- 系统间解耦:生产者和消费者不需要知道对方的存在,只需关注消息格式即可。例如,支付系统完成支付后只需将支付成功消息发送到队列,后续的订单状态更新、物流通知等都由不同消费者处理。
- 可恢复性:当消费者暂时不可用时,消息会持久化在队列中,待恢复后继续处理。比如在系统升级期间积累的消息可以在升级完成后继续消费。
- 支持异构系统:不同技术栈的系统可以通过统一的消息协议交互,如使用JSON或Protobuf格式的消息。
- 并发处理能力:可以启动多个消费者实例并行处理消息,提高吞吐量。例如双11期间可以动态增加消费者实例应对流量高峰。
- 流量削峰:突发流量可以被消息队列缓冲,避免直接冲击下游系统。比如秒杀活动产生的大量请求可以先进入队列,再由系统按处理能力消费。
缺点:
- 中间件瓶颈:消息队列本身可能成为性能瓶颈,需要集群部署和优化配置。例如Kafka需要合理设置分区数量和副本因子。
- 一致性问题:在分布式环境下难以保证严格的事务一致性,通常采用最终一致性方案。如订单支付和库存扣减可能短暂不一致。
- 开发复杂性:相比直接调用,需要处理消息序列化、重试机制、死信队列等问题,调试时需要借助额外工具查看消息内容。
- 运维成本:需要维护消息中间件集群,监控队列积压、消费者延迟等指标,增加了基础设施的复杂度。
- 额外开销:消息的序列化/反序列化、网络传输等都会带来性能损耗,不适合对延迟要求极高的场景。
异步问题
使用异步消息模式需要注意以下关键问题:
-
业务处理的同步/异步划分:
- 必须同步处理的业务:
- 需要即时响应的用户操作(如支付验证、登录认证)
- 强一致性的核心业务(如账户余额变更)
- 关键业务流程控制(如订单创建)
- 适合异步处理的业务:
- 通知类业务(如邮件/短信发送)
- 数据分析与报表生成
- 非关键业务流程(如日志记录、库存更新)
- 必须同步处理的业务:
-
消息安全与可靠性保障:
- 安全措施:
- 使用TLS/SSL加密传输
- 实施消息签名验证
- 敏感数据脱敏处理
- 防丢失机制:
- 消息持久化存储
- 确认(ACK)机制
- 死信队列(DLQ)处理
- 防重复方案:
- 唯一消息ID
- 消费者端幂等处理
- 去重表设计
- 安全措施:
-
延迟优化方案:
- 技术层面:
- 优化消息队列集群部署(同区域/可用区)
- 使用高性能序列化协议(如Protobuf)
- 批量消息处理
- 架构层面:
- 合理设置消息TTL
- 实现优先级队列
- 采用流处理替代批处理
- 技术层面:
-
消息顺序保障:
- 需要顺序处理的场景:
- 状态变更操作(如订单状态流转)
- 增量数据同步
- 解决方案:
- 分区有序队列
- 单消费者线程模型
- 版本号/时间戳校验
- 需要顺序处理的场景:
-
失败处理与幂等性:
- 重发策略:
- 指数退避重试
- 最大重试次数限制
- 人工干预通道
- 幂等实现:
- 业务唯一键校验
- 操作状态机检查
- 事务日志记录
- 典型案例:
- 支付结果通知:基于交易ID去重
- 库存扣减:使用CAS(Compare-And-Swap)机制
- 重发策略:
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 同步重试导致 CPU 飙升/线程打满 | 无界重试、递归调用、缺少超时与退避 | 线程栈/火焰图出现重复方法;接口 RT 线性上升 | 改为 for 有界重试;加入超时、退避、熔断;最后失败走降级/补偿 |
| 递归重试触发 StackOverflowError | 递归无退出条件 | JVM 异常栈显示同一方法层层嵌套 | 禁用递归重试;用迭代+最大次数;记录失败任务进入补偿队列 |
| 添加商品接口 RT 大、并发下吞吐下降 | 主链路同步做索引/静态页副作用,阻塞放大 | APM 显示外部调用耗时占比高;线程池排队 | 主链路只落库;副作用任务化(MQ/任务表/缓存队列);worker 异步处理 |
| 异步任务"看似入队"但实际丢任务 | 入队与落库非原子、无投递确认、宕机丢内存队列 | 对账:DB 有数据但无任务;队列/缓存无对应消息 | Outbox/事务消息:落库与任务记录同事务;异步投递并可重放;至少一次投递+幂等消费 |
| 任务重复执行导致索引/页面重复刷新 | 至少一次投递、重试、消费者超时重平衡 | 消费日志同一业务键多次处理 | 消费端幂等:业务唯一键/去重表/状态机;刷新接口设计为幂等写入 |
| worker 一直重试造成雪崩、队列积压 | 下游长期不可用仍高频重试 | 队列 lag 增长;重试次数激增;下游错误率高 | 指数退避+最大重试;失败进 DLQ;熔断+限流;告警触发人工/自动补偿 |
| MQ 顺序错乱导致状态回退 | 分区策略不一致、并行消费未按 key 粘滞 | 同一订单状态出现"已完成→处理中" | 以业务键分区;同 key 串行处理;写入带版本号/时间戳校验 |
| Feign 调用偶发超时/502/503 | 下游超时、连接池不足、负载均衡实例脏数据 | APM/日志看超时点;连接池指标;注册中心实例列表 | 设置连接/读超时;连接池调优;实例摘除与健康检查;熔断降级 |
| "可靠发送"后仍出现数据不一致 | 期望强一致但实际跨服务副作用 | 对账显示短暂不一致或长期缺口 | 明确一致性等级:最终一致;补齐补偿任务、对账校验、重放机制 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接