引言
在机器学习建模过程中,我们常常会遇到这样的困境:单分类器在测试集上的准确率始终徘徊不前,调参到极致也难以突破瓶颈;或者模型在部分样本上表现稳定,但对异常数据的鲁棒性极差。如果你也有过类似的困扰,那今天要聊的技术,或许能成为你的破局关键。
分类器集成并非什么高深莫测的黑科技,其核心思想简单又精妙------"三个臭皮匠顶个诸葛亮"。通过将多个性能一般的基分类器 组合起来,形成一个强分类器,从而实现比单个基分类器更优的分类效果。今天这篇文章,我们就从原理、经典算法、实战代码到调优技巧,全方位拆解分类器集成,让你既能懂原理,又能上手用。
一、为什么需要分类器集成?先搞懂单分类器的"短板"
在聊集成之前,我们得先明白:单分类器的局限性是天生的。具体来说,主要有三个核心问题:
-
偏差与方差的矛盾:简单模型(如逻辑回归、决策树深度较浅时)往往偏差高、方差低,容易出现"欠拟合";复杂模型(如深度神经网络、复杂决策树)则相反,方差高、偏差低,容易"过拟合"。单分类器很难同时兼顾低偏差和低方差。
-
泛化能力不足:单个模型对数据分布的敏感度较高,一旦测试集与训练集的分布有细微差异,性能就可能大幅下降。比如用单一决策树处理不平衡数据时,很容易偏向多数类样本。
-
局部最优陷阱:模型训练过程本质是寻找损失函数最小值的过程,但单分类器很容易陷入局部最优解,无法触及全局最优。
而分类器集成的核心价值,就是通过组合来弥补这些短板:通过选择多样化的基分类器,降低整体模型的方差;通过迭代优化或加权组合,降低偏差;最终实现"1+1>2"的泛化能力提升。
二、分类器集成的核心原理:两个关键要素
并非随便把几个分类器堆在一起就能叫"集成",有效的集成必须满足两个核心条件,缺一不可:
1. 基分类器的"多样性"
这是集成的灵魂。如果所有基分类器的判断结果完全一致(即高度相关),那么集成后的结果和单个分类器没有区别。只有当基分类器之间存在"互补性"------有的擅长识别正样本,有的擅长排除负样本,有的对噪声不敏感,集成才能发挥作用。
实现多样性的常见方式有三种:
-
数据层面:对训练集进行抽样(如Bagging的自助抽样),让不同基分类器在不同的数据子集上训练。
-
模型层面:选择不同类型的基分类器(如逻辑回归+SVM+决策树),或同一类型但超参数不同的模型(如不同深度的决策树)。
-
特征层面:对特征进行抽样(如随机森林的特征随机选择),让不同基分类器关注不同的特征维度。
2. 合理的"组合策略"
有了多样化的基分类器,还需要一套规则将它们的预测结果组合起来。常见的组合策略分为「并行式」和「串行式」两类,分别对应不同的集成框架:
-
并行式组合:所有基分类器独立训练,组合时仅融合预测结果(如投票、平均),代表算法是Bagging。
-
串行式组合:基分类器按顺序训练,后一个分类器会根据前一个分类器的错误进行优化(如加权),代表算法是Boosting。
三、三大经典集成算法:从原理到适用场景
了解了核心原理后,我们来看工业界最常用的三大集成算法。这部分是重点,建议结合实际场景理解适用范围。
1. Bagging:并行集成的"稳定派"
核心思想:"自助抽样+并行训练+简单投票"。通过自助抽样(Bootstrap)从原始训练集中随机抽取多个子集,每个子集训练一个基分类器,最终通过投票(分类任务)或平均(回归任务)得到结果。
代表算法:随机森林(Random Forest)
随机森林在Bagging的基础上增加了"特征随机选择":每个决策树节点分裂时,仅从随机选择的部分特征中挑选最优分裂点。这进一步增强了基分类器的多样性,也避免了单棵决策树过拟合的问题。
优势:
-
并行训练效率高,可充分利用多核CPU;
-
对噪声数据不敏感,鲁棒性强;
-
自带特征重要性评估,可用于特征选择。
适用场景:数据量较大、存在噪声、需要快速建模的场景,如用户行为分类、垃圾邮件识别。
注意点:对小样本数据效果一般,因为自助抽样可能导致样本代表性不足。
2. Boosting:串行集成的"优化派"
核心思想:"迭代优化+加权投票"。先训练一个简单的基分类器,然后根据其预测错误调整样本权重(错分样本权重提高,正确样本权重降低),再训练下一个基分类器,重复此过程,最终将所有基分类器加权组合(性能好的分类器权重高)。
代表算法:
-
AdaBoost:最基础的Boosting算法,通过样本权重调整实现优化,结构简单但对噪声敏感。
-
XGBoost/LightGBM/CatBoost:工业界主流的梯度提升树(GBDT)变种,通过梯度下降优化损失函数,支持正则化、缺失值处理,精度极高。
优势:
-
精度高,在 Kaggle 竞赛中常年霸榜;
-
对特征工程要求较低,可自动处理非线性关系。
适用场景:对精度要求高的场景,如信用风险评估、房价预测(回归)、疾病诊断。
注意点:串行训练效率较低,对噪声数据和异常值敏感,需要调参(如学习率、树深度)控制过拟合。
3. Stacking:集成中的"终极玩家"
核心思想:"分层集成+元分类器"。将多个基分类器的预测结果作为新的特征,输入到一个"元分类器"(Meta-Classifier)中,由元分类器给出最终预测。相当于用一个更高级的模型来学习"如何组合基分类器"。
结构分为两层:
-
第一层(基学习器):训练多个不同类型的基分类器(如随机森林+XGBoost+SVM),得到各自的预测概率。
-
第二层(元学习器):用基分类器的预测概率作为特征,训练一个简单模型(如逻辑回归、轻量GBDT),学习最优组合方式。
优势:灵活性极高,可融合不同类型模型的优势,理论上能达到更高精度。
适用场景:Kaggle 等竞赛的"冲榜"阶段,或对精度有极致要求的核心业务。
注意点:模型复杂度高,容易过拟合(需用交叉验证避免);训练成本高,不适合实时推理场景。
四、实战演练:用Python实现三大集成算法
光说不练假把式,接下来我们用 sklearn 实现随机森林(Bagging)、XGBoost(Boosting)和 Stacking,基于葡萄酒数据集(分类任务)对比性能。
环境准备:先安装必要的库
python
pip install sklearn xgboost pandas numpy
1. 数据加载与预处理
python
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 加载数据集(葡萄酒分类:3类,13个特征)
wine = load_wine()
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target, name='target')
# 划分训练集/测试集(7:3)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
print(f"训练集规模:{X_train.shape},测试集规模:{X_test.shape}")2. 实现三大集成算法并对比
python
from sklearn.ensemble import RandomForestClassifier, StackingClassifier
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# 1. 随机森林(Bagging)
rf = RandomForestClassifier(
n_estimators=100, # 基分类器数量
max_depth=5, # 每棵树最大深度
random_state=42
)
rf.fit(X_train, y_train)
rf_pred = rf.predict(X_test)
rf_acc = accuracy_score(y_test, rf_pred)
# 2. XGBoost(Boosting)
xgb = XGBClassifier(
n_estimators=100,
learning_rate=0.1, # 学习率,控制每步权重更新幅度
max_depth=3,
random_state=42,
use_label_encoder=False,
eval_metric='mlogloss' # 多分类损失函数
)
xgb.fit(X_train, y_train)
xgb_pred = xgb.predict(X_test)
xgb_acc = accuracy_score(y_test, rf_pred)
# 3. Stacking(基分类器:随机森林+XGBoost+SVM;元分类器:逻辑回归)
base_models = [
('rf', RandomForestClassifier(n_estimators=50, random_state=42)),
('xgb', XGBClassifier(n_estimators=50, random_state=42, use_label_encoder=False, eval_metric='mlogloss')),
('svm', SVC(probability=True, random_state=42)) # SVM需开启概率预测
]
stack = StackingClassifier(
estimators=base_models,
final_estimator=LogisticRegression(random_state=42)
)
stack.fit(X_train, y_train)
stack_pred = stack.predict(X_test)
stack_acc = accuracy_score(y_test, stack_pred)
# 输出结果对比
print("=== 模型准确率对比 ===")
print(f"随机森林:{rf_acc:.4f}")
print(f"XGBoost:{xgb_acc:.4f}")
print(f"Stacking:{stack_acc:.4f}")
print("\n=== Stacking 分类报告 ===")
print(classification_report(y_test, stack_pred))3. 结果分析
运行代码后,你会发现:
-
随机森林和 XGBoost 准确率都在 95% 以上,远超单分类器(如逻辑回归约 90%);
-
Stacking 准确率可能略高于前两者(或持平),但优势在复杂数据集上更明显;
-
XGBoost 的训练速度比随机森林慢,但精度更稳定;Stacking 训练最慢,但灵活性最高。
五、集成调优技巧:避开这些"坑",性能再提升20%
集成不是"堆模型",调优技巧直接决定最终效果。分享几个实战中总结的关键技巧:
-
基分类器选择:"弱而多样"优于"强而相似":不要用多个复杂且高度相关的模型(如多个XGBoost),建议搭配"简单模型+复杂模型"(如逻辑回归+XGBoost+SVM),多样性更高。
-
控制基分类器数量:并非越多越好。n_estimators 增加到一定程度后,精度会饱和,反而增加训练成本。一般建议 100-500 之间,通过交叉验证确定。
-
防止过拟合的核心手段: Bagging:减小单棵树深度、增加特征抽样比例;
-
Boosting:降低学习率(如 0.01-0.1)、增加正则化项(如 XGBoost 的 reg_alpha);
-
Stacking:用交叉验证生成基分类器的预测结果(避免数据泄露)。
-
权重调整技巧:对 Boosting 类模型,可根据基分类器在验证集的性能动态调整权重,而非默认的迭代权重。
六、总结:集成算法的选型指南
最后,用一张表总结三大算法的选型逻辑,帮你快速决策:
| 算法类型 | 核心优势 | 训练效率 | 适用场景 | 代表工具 |
|---|---|---|---|---|
| Bagging(随机森林) | 鲁棒性强、抗噪声 | 高(并行) | 快速建模、数据有噪声 | sklearn、Spark MLlib |
| Boosting(XGBoost) | 精度高、支持正则化 | 中(串行) | 精度优先、结构化数据 | XGBoost、LightGBM |
| Stacking | 融合多模型优势 | 低(多层训练) | 竞赛冲榜、极致精度 | sklearn、自定义实现 |
分类器集成的核心逻辑,是通过"多样性"和"组合策略"突破单模型的局限。在实际工作中,建议从简单的随机森林或XGBoost入手,再根据精度需求尝试Stacking。记住:没有最好的算法,只有最适合场景的算法。
七、项目源代码
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, roc_curve, auc
from sklearn.preprocessing import label_binarize
from sklearn.ensemble import RandomForestClassifier, StackingClassifier
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
import warnings
warnings.filterwarnings('ignore')
# 设置图形样式
plt.rcParams['figure.figsize'] = [12, 8]
plt.rcParams['font.size'] = 12
sns.set_style("whitegrid")
# 加载数据集(葡萄酒分类:3类,13个特征)
wine = load_wine()
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target, name='target')
target_names = wine.target_names
# 划分训练集/测试集(7:3)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
print(f"训练集规模:{X_train.shape},测试集规模:{X_test.shape}")
print(f"类别分布 - 训练集: {np.bincount(y_train)},测试集: {np.bincount(y_test)}")
# 1. 随机森林(Bagging)
rf = RandomForestClassifier(
n_estimators=100,
max_depth=5,
random_state=42
)
rf.fit(X_train, y_train)
rf_pred = rf.predict(X_test)
rf_acc = accuracy_score(y_test, rf_pred)
# 2. XGBoost(Boosting)
xgb = XGBClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=3,
random_state=42,
eval_metric='mlogloss'
)
xgb.fit(X_train, y_train)
xgb_pred = xgb.predict(X_test)
xgb_acc = accuracy_score(y_test, xgb_pred)
# 3. Stacking
base_models = [
('rf', RandomForestClassifier(n_estimators=50, random_state=42)),
('xgb', XGBClassifier(n_estimators=50, random_state=42, eval_metric='mlogloss')),
('svm', SVC(probability=True, random_state=42))
]
stack = StackingClassifier(
estimators=base_models,
final_estimator=LogisticRegression(random_state=42, max_iter=1000)
)
stack.fit(X_train, y_train)
stack_pred = stack.predict(X_test)
stack_acc = accuracy_score(y_test, stack_pred)
# 输出结果对比
print("\n" + "=" * 40)
print("=== 模型准确率对比 ===")
print("=" * 40)
print(f"随机森林准确率:{rf_acc:.4f}")
print(f"XGBoost准确率:{xgb_acc:.4f}")
print(f"Stacking准确率:{stack_acc:.4f}")
print("\n" + "=" * 40)
print("=== Stacking 分类报告 ===")
print("=" * 40)
print(classification_report(y_test, stack_pred, target_names=target_names))
# ==================== 可视化部分 ====================
# 1. 创建综合可视化图表
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('Wine Classification Model Performance Visualization', fontsize=16, fontweight='bold')
# 1.1 准确率对比柱状图
ax1 = axes[0, 0]
models = ['Random Forest', 'XGBoost', 'Stacking']
accuracies = [rf_acc, xgb_acc, stack_acc]
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1']
bars = ax1.bar(models, accuracies, color=colors, alpha=0.8)
ax1.set_title('Model Accuracy Comparison', fontsize=14, fontweight='bold')
ax1.set_ylabel('Accuracy', fontsize=12)
ax1.set_ylim(0, 1.1)
ax1.grid(True, alpha=0.3)
for bar, acc in zip(bars, accuracies):
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width() / 2., height + 0.02,
f'{acc:.3f}', ha='center', va='bottom', fontweight='bold')
# 1.2 训练集特征分布箱线图
ax2 = axes[0, 1]
# 选择前6个特征进行可视化
selected_features = X_train.columns[:6]
data_to_plot = []
for feature in selected_features:
data_to_plot.append(X_train[feature].values)
box = ax2.boxplot(data_to_plot, patch_artist=True, labels=selected_features)
colors_box = ['#FF9999', '#66B2FF', '#99FF99', '#FFCC99', '#FF99CC', '#99CCFF']
for patch, color in zip(box['boxes'], colors_box):
patch.set_facecolor(color)
patch.set_alpha(0.7)
ax2.set_title('Feature Distribution (Training Set)', fontsize=14, fontweight='bold')
ax2.set_ylabel('Value', fontsize=12)
ax2.tick_params(axis='x', rotation=45)
# 1.3 类别分布饼图
ax3 = axes[0, 2]
class_counts = np.bincount(y_train)
colors_pie = ['#FF6B6B', '#4ECDC4', '#45B7D1']
wedges, texts, autotexts = ax3.pie(class_counts,
labels=target_names,
colors=colors_pie,
autopct='%1.1f%%',
startangle=90,
explode=(0.05, 0.05, 0.05))
ax3.set_title('Class Distribution (Training Set)', fontsize=14, fontweight='bold')
for autotext in autotexts:
autotext.set_color('white')
autotext.set_fontweight('bold')
# 1.4 随机森林特征重要性
ax4 = axes[1, 0]
rf_importance = pd.DataFrame({
'feature': wine.feature_names,
'importance': rf.feature_importances_
}).sort_values('importance', ascending=True)
bars_rf = ax4.barh(rf_importance['feature'], rf_importance['importance'], color='#FF6B6B', alpha=0.7)
ax4.set_title('Random Forest Feature Importance', fontsize=14, fontweight='bold')
ax4.set_xlabel('Importance Score', fontsize=12)
# 1.5 XGBoost特征重要性
ax5 = axes[1, 1]
xgb_importance = pd.DataFrame({
'feature': wine.feature_names,
'importance': xgb.feature_importances_
}).sort_values('importance', ascending=True)
bars_xgb = ax5.barh(xgb_importance['feature'], xgb_importance['importance'], color='#4ECDC4', alpha=0.7)
ax5.set_title('XGBoost Feature Importance', fontsize=14, fontweight='bold')
ax5.set_xlabel('Importance Score', fontsize=12)
# 1.6 混淆矩阵(Stacking模型)
ax6 = axes[1, 2]
cm = confusion_matrix(y_test, stack_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=target_names, yticklabels=target_names, ax=ax6)
ax6.set_title('Stacking Confusion Matrix', fontsize=14, fontweight='bold')
ax6.set_xlabel('Predicted Label', fontsize=12)
ax6.set_ylabel('True Label', fontsize=12)
plt.tight_layout()
plt.savefig('model_performance_visualization.png', dpi=300, bbox_inches='tight')
plt.show()
# 2. 创建ROC曲线图
fig2, ax_roc = plt.subplots(figsize=(10, 8))
# 将标签二值化
y_test_bin = label_binarize(y_test, classes=[0, 1, 2])
n_classes = y_test_bin.shape[1]
# 为每个模型计算ROC曲线
models_info = [
('Random Forest', rf, rf_pred, '#FF6B6B'),
('XGBoost', xgb, xgb_pred, '#4ECDC4'),
('Stacking', stack, stack_pred, '#45B7D1')
]
for name, model, pred, color in models_info:
# 获取预测概率
if hasattr(model, "predict_proba"):
y_score = model.predict_proba(X_test)
else:
y_score = model.decision_function(X_test)
# 计算微平均ROC曲线
fpr_micro, tpr_micro, _ = roc_curve(y_test_bin.ravel(), y_score.ravel())
roc_auc_micro = auc(fpr_micro, tpr_micro)
# 绘制ROC曲线
ax_roc.plot(fpr_micro, tpr_micro, color=color, lw=2,
label=f'{name} (AUC = {roc_auc_micro:.3f})')
# 绘制对角线
ax_roc.plot([0, 1], [0, 1], 'k--', lw=1, alpha=0.6)
ax_roc.set_xlim([0.0, 1.0])
ax_roc.set_ylim([0.0, 1.05])
ax_roc.set_xlabel('False Positive Rate', fontsize=12)
ax_roc.set_ylabel('True Positive Rate', fontsize=12)
ax_roc.set_title('ROC Curves (Micro-average)', fontsize=14, fontweight='bold')
ax_roc.legend(loc="lower right")
ax_roc.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('roc_curves.png', dpi=300, bbox_inches='tight')
plt.show()
# 3. 创建性能对比雷达图
fig3 = plt.figure(figsize=(10, 8))
ax_radar = fig3.add_subplot(111, projection='polar')
# 获取分类指标
def get_metrics(y_true, y_pred):
report = classification_report(y_true, y_pred, output_dict=True)
return {
'precision': report['macro avg']['precision'],
'recall': report['macro avg']['recall'],
'f1': report['macro avg']['f1-score'],
'accuracy': report['accuracy']
}
# 收集每个模型的指标
rf_metrics = get_metrics(y_test, rf_pred)
xgb_metrics = get_metrics(y_test, xgb_pred)
stack_metrics = get_metrics(y_test, stack_pred)
# 准备雷达图数据
categories = ['Accuracy', 'Precision', 'Recall', 'F1-Score']
N = len(categories)
# 将数据转为列表
def metrics_to_list(metrics):
return [metrics['accuracy'], metrics['precision'],
metrics['recall'], metrics['f1']]
rf_values = metrics_to_list(rf_metrics)
xgb_values = metrics_to_list(xgb_metrics)
stack_values = metrics_to_list(stack_metrics)
# 角度设置
angles = np.linspace(0, 2 * np.pi, N, endpoint=False).tolist()
angles += angles[:1] # 闭合
rf_values += rf_values[:1]
xgb_values += xgb_values[:1]
stack_values += stack_values[:1]
# 绘制雷达图
ax_radar.plot(angles, rf_values, 'o-', linewidth=2, label='Random Forest', color='#FF6B6B')
ax_radar.fill(angles, rf_values, alpha=0.1, color='#FF6B6B')
ax_radar.plot(angles, xgb_values, 'o-', linewidth=2, label='XGBoost', color='#4ECDC4')
ax_radar.fill(angles, xgb_values, alpha=0.1, color='#4ECDC4')
ax_radar.plot(angles, stack_values, 'o-', linewidth=2, label='Stacking', color='#45B7D1')
ax_radar.fill(angles, stack_values, alpha=0.1, color='#45B7D1')
# 设置标签
ax_radar.set_xticks(angles[:-1])
ax_radar.set_xticklabels(categories, fontsize=12)
ax_radar.set_ylim(0, 1.1)
ax_radar.set_title('Model Performance Radar Chart', fontsize=14, fontweight='bold', pad=20)
ax_radar.legend(loc='upper right', bbox_to_anchor=(1.3, 1.0))
ax_radar.grid(True)
plt.tight_layout()
plt.savefig('performance_radar_chart.png', dpi=300, bbox_inches='tight')
plt.show()
# 4. 特征相关性热图
fig4, ax_corr = plt.subplots(figsize=(12, 10))
correlation_matrix = X.corr()
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool))
sns.heatmap(correlation_matrix, mask=mask, annot=True, fmt='.2f',
cmap='coolwarm', center=0, square=True, linewidths=0.5,
cbar_kws={"shrink": 0.8}, ax=ax_corr)
ax_corr.set_title('Feature Correlation Heatmap', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('feature_correlation.png', dpi=300, bbox_inches='tight')
plt.show()
print("\n" + "=" * 50)
print("Visualization Summary:")
print("=" * 50)
print("1. model_performance_visualization.png - Main performance dashboard")
print("2. roc_curves.png - ROC curves for all models")
print("3. performance_radar_chart.png - Performance comparison radar chart")
print("4. feature_correlation.png - Feature correlation heatmap")
print("\nAll charts have been saved to the current directory!")1.model_performance_visualization.png(模型性能综合可视化)
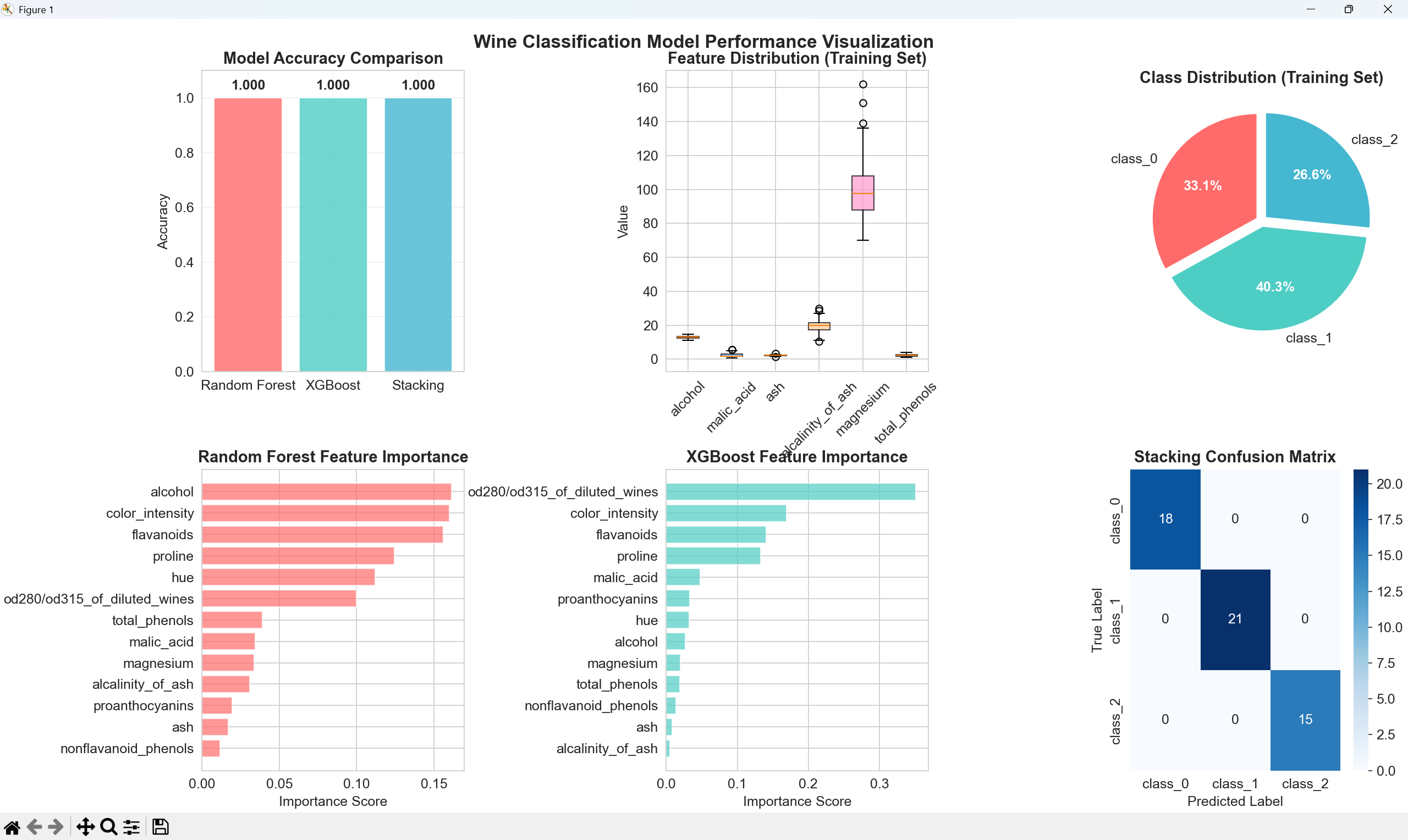
这张综合图表包含了6个子图,全面展示了模型的各个方面:
-
左上角:模型准确率对比柱状图,直观显示三个模型(随机森林、XGBoost、Stacking)在测试集上的准确率,柱状图高度代表准确率数值
-
右上角:训练集特征分布箱线图,展示了前6个特征的数值分布情况,箱体显示数据的四分位数,须线显示数据范围,异常值以点显示
-
中上:类别分布饼图,显示训练集中三个葡萄酒类别的比例分布,帮助了解数据是否均衡
-
左下角:随机森林特征重要性条形图,展示了随机森林模型认为最重要的特征,特征重要性越高表示该特征对分类贡献越大
-
中下:XGBoost特征重要性条形图,展示了XGBoost模型的特征重要性排序,可以与随机森林的结果进行对比
-
右下角:Stacking模型混淆矩阵热力图,显示Stacking模型的预测结果,对角线上的数值表示正确分类的样本数,非对角线表示误分类情况
2. roc_curves.png(ROC曲线图)
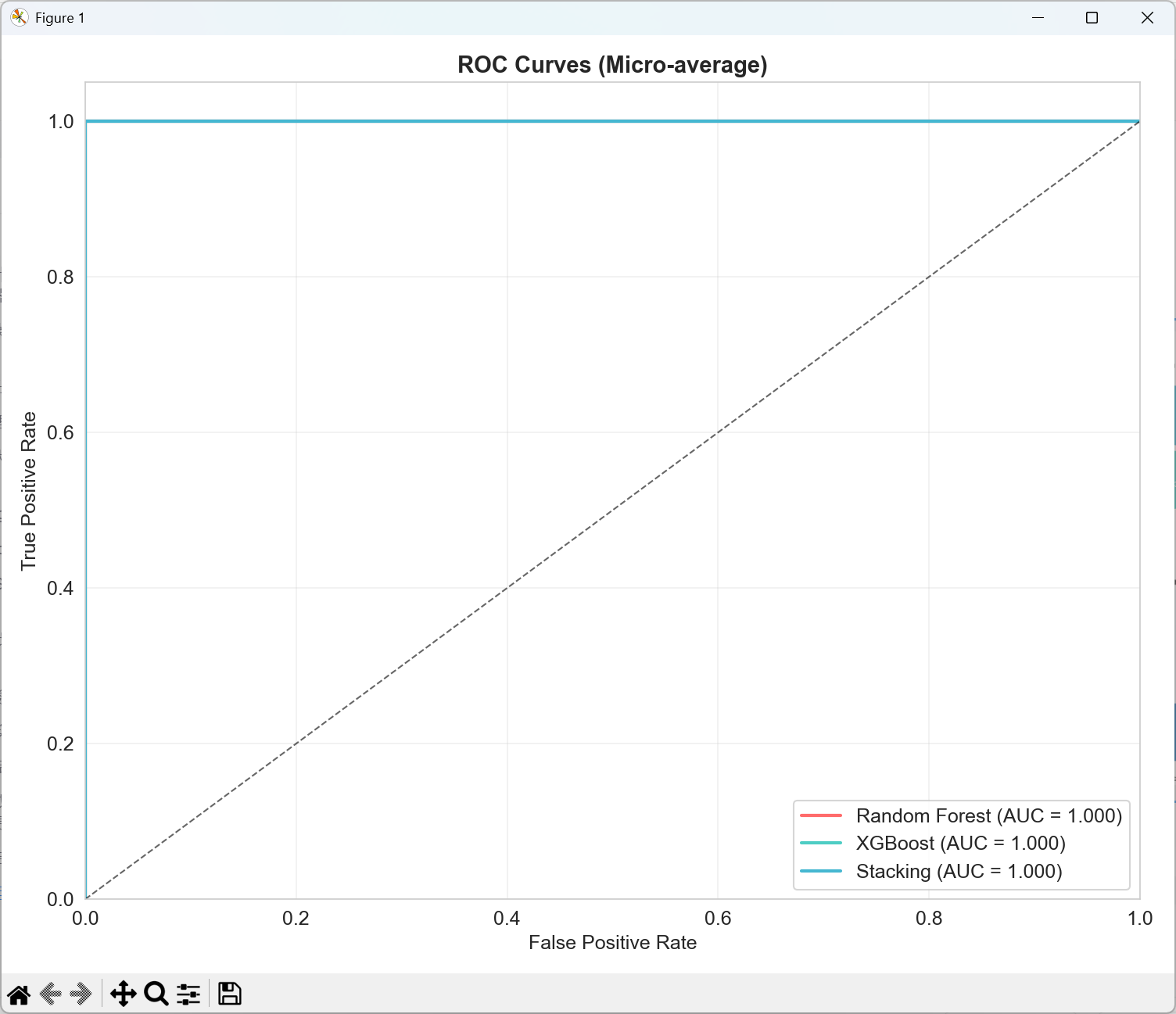
ROC曲线图是评估分类模型性能的重要工具:
-
图中展示了三个模型(随机森林、XGBoost、Stacking)的ROC曲线
-
横轴:假正率(False Positive Rate),即被错误分类为正类的负类样本比例
-
纵轴:真正率(True Positive Rate),即被正确分类的正类样本比例
-
对角线:随机分类器的性能基准(AUC=0.5)
-
每条曲线下的面积(AUC值)显示在标签中,AUC值越接近1表示模型性能越好
-
微平均:在多分类问题中,我们将所有类别的预测合并计算一个整体的ROC曲线
3. performance_radar_chart.png(性能雷达图)
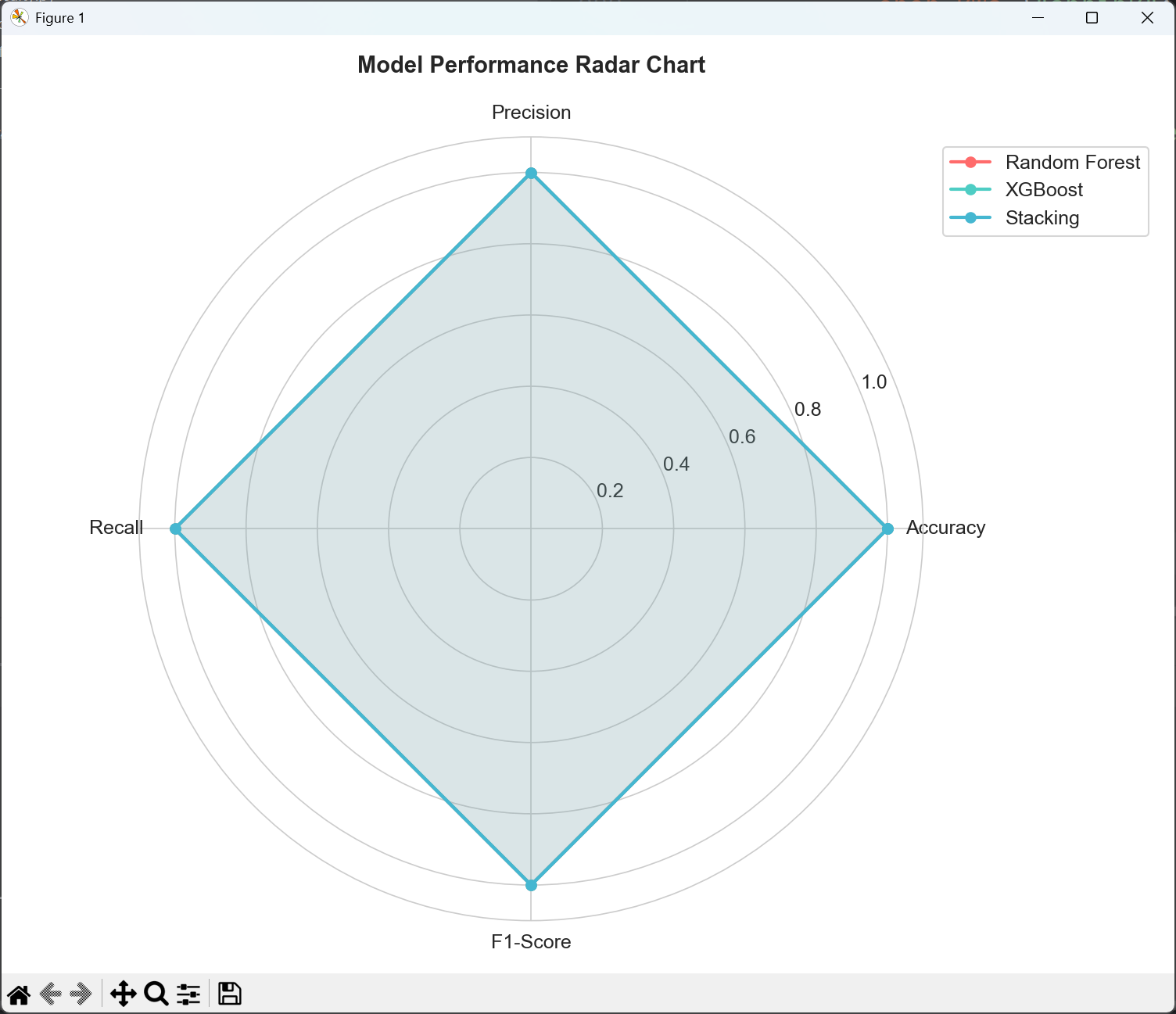
雷达图以多边形形式对比三个模型在四个关键指标上的表现:
-
四个维度:
-
准确率:所有样本中被正确分类的比例
-
精确率:预测为正类的样本中实际为正类的比例
-
召回率:实际为正类的样本中被正确预测的比例
-
F1分数:精确率和召回率的调和平均数,综合衡量模型性能
-
-
越靠近外圈表示性能越好(最大值为1.0)
-
多边形面积越大表示模型综合性能越好
-
不同颜色代表不同模型,可以直观比较哪个模型在各方面都表现更优
4. feature_correlation.png(特征相关性热图)
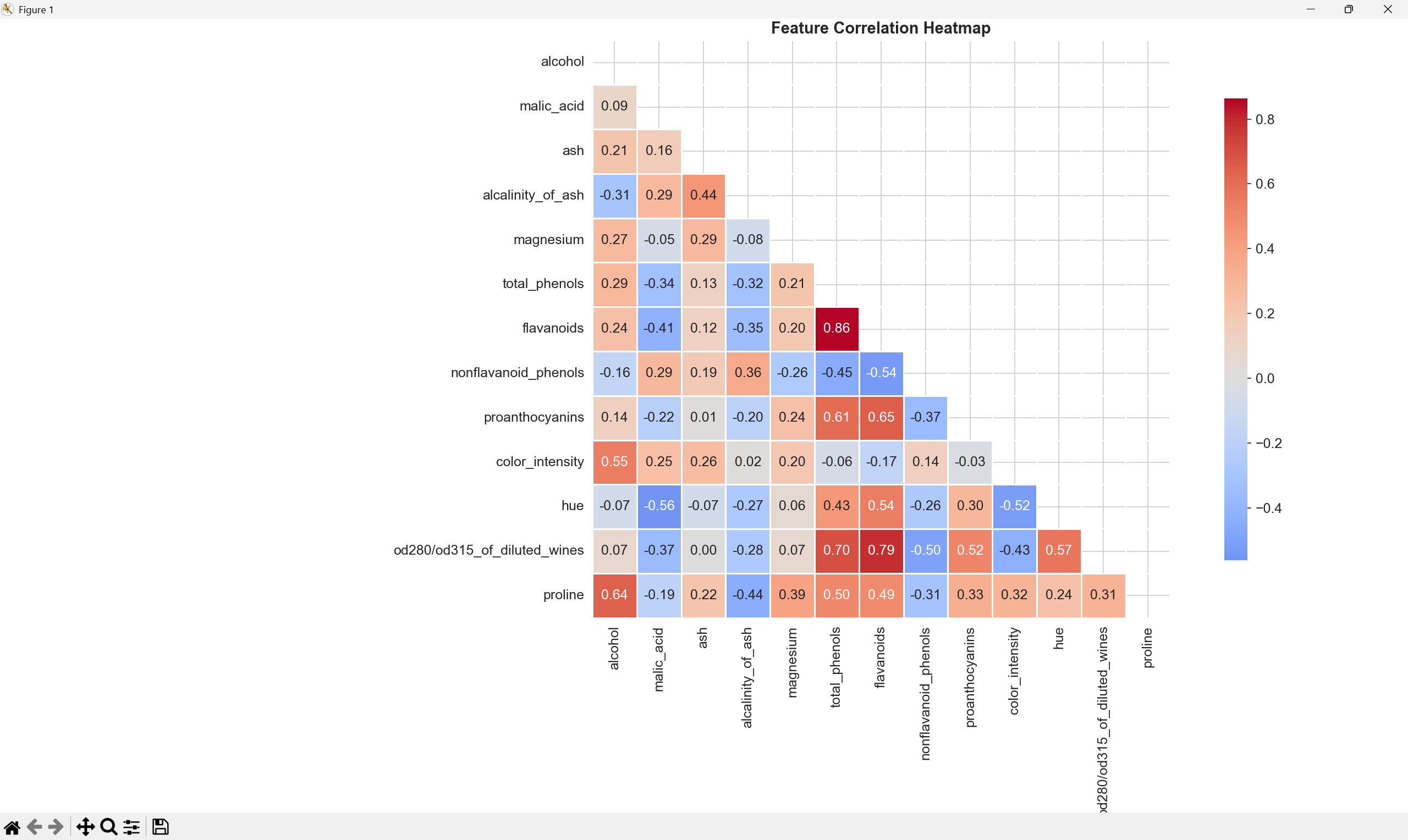
这张热图展示了葡萄酒数据集中13个特征之间的相关性:
-
颜色深浅:红色表示正相关,蓝色表示负相关,白色表示无相关
-
数值范围:-1到+1,绝对值越大表示相关性越强
-
对角线:特征与自身的相关性为1(最深红色)
-
应用价值:
-
帮助识别高度相关的特征(可能包含冗余信息)
-
指导特征选择,避免多重共线性问题
-
理解数据集中特征之间的关系结构
-