目录
[(1)编码器(Contracting Path)](#(1)编码器(Contracting Path))
[(2)解码器(Expansive Path)](#(2)解码器(Expansive Path))
[(3)最后一层输出层(给每个像素打 "分割标签")](#(3)最后一层输出层(给每个像素打 “分割标签”))
[3.conv 3×3卷积 计算方式](#3.conv 3×3卷积 计算方式)
[步骤 0:输入层](#步骤 0:输入层)
[步骤 1:第 1 次卷积 + 池化](#步骤 1:第 1 次卷积 + 池化)
[步骤 2:第 2 次卷积 + 池化](#步骤 2:第 2 次卷积 + 池化)
[步骤 3:第 3 次卷积 + 池化](#步骤 3:第 3 次卷积 + 池化)
[步骤 4:第 4 次卷积 + 池化](#步骤 4:第 4 次卷积 + 池化)
[3.解码器(右侧:上采样 + 拼接流程;看蓝色序号)](#3.解码器(右侧:上采样 + 拼接流程;看蓝色序号))
[步骤 1:第 1 次上采样 + 拼接 + 卷积](#步骤 1:第 1 次上采样 + 拼接 + 卷积)
[步骤 2:第 2 次上采样 + 拼接 + 卷积](#步骤 2:第 2 次上采样 + 拼接 + 卷积)
[步骤 3:第 3 次上采样 + 拼接 + 卷积](#步骤 3:第 3 次上采样 + 拼接 + 卷积)
[步骤 4:第 4 次上采样 + 拼接 + 卷积](#步骤 4:第 4 次上采样 + 拼接 + 卷积)
[四.重叠分块策略(Overlap-tile strategy)](#四.重叠分块策略(Overlap-tile strategy))
[(2) 图中元素的含义](#(2) 图中元素的含义)
[(1)为什么需要 "重叠"?](#(1)为什么需要 “重叠”?)
[(2)"重叠" 的具体操作](#(2)“重叠” 的具体操作)
[1.ISBI 2012 EM数据集](#1.ISBI 2012 EM数据集)
[2.load_tif 中处理图像文件对象](#2.load_tif 中处理图像文件对象)
[(1)img是代表整个 TIFF 文件的对象,但不是物理文件本身。](#(1)img是代表整个 TIFF 文件的对象,但不是物理文件本身。)
[③列表转 numpy 数组](#③列表转 numpy 数组)
[(3) return np.array(images)..., np.newaxis](#(3) return np.array(images)[..., np.newaxis])
[4.torch.save(model.state_dict()............)](#4.torch.save(model.state_dict()…………))
一.U-Net架构细节解释
1.介绍
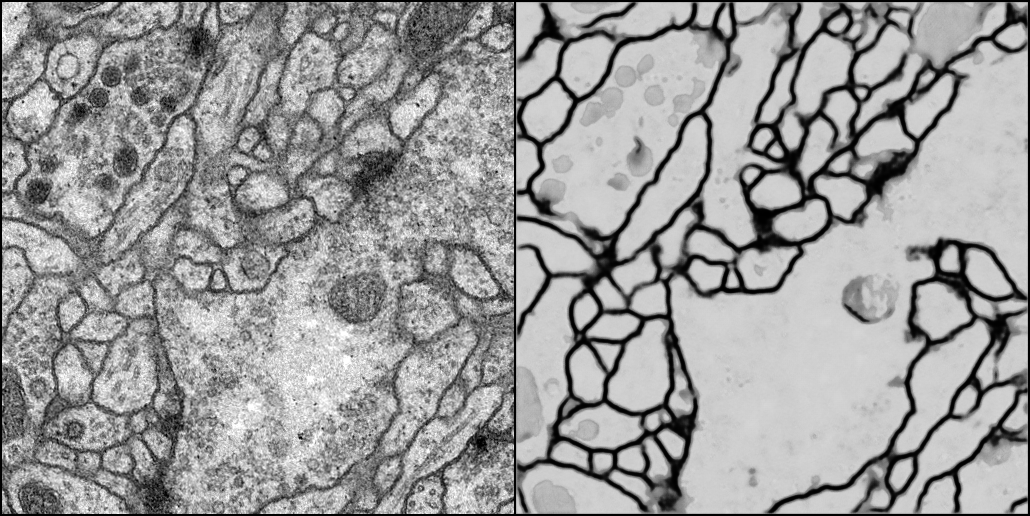
U-Net 是深度学习领域经典的图像分割架构,因结构呈 "U" 型而得名,最初用于医学图像分割,如今已成为各类分割、生成任务的核心框架。例如输入ISBI 2012 EM数据集果蝇第一龄幼虫的腹侧神经索(VNC)神经元细胞,最后输出细胞的分割图。
2.U-Net三部分
U-Net 分为编码器(左侧下采样) 、瓶颈层、** 解码器(右侧上采样)** 三部分:
(1)编码器(Contracting Path)
或叫收缩路径,提取 "做分割需要的信息"
收缩路径的 "卷积 + 池化",本质是把图像从 "像素级细节" 抽象成 "语义级特征":
- 每轮卷积(conv 3x3+ReLU):提取局部特征(比如 ISBI 图像里的 "细胞边缘纹理""区域亮度");
- 每轮最大池化(max pool 2x2):缩小图像尺寸,同时保留 "最关键的特征"(比如细胞的大致区域),并增加通道数(从 64→128→256...)------ 通道数越多,能记录的 "语义信息" 越丰富(比如 "这是细胞团""这是背景区域")。
到收缩路径末尾,图像尺寸最小(比如 32×32),但通道数最多(比如 1024)------ 此时特征图里存的是 "整张图的全局语义"(知道哪里是细胞、哪里是背景)。
瓶颈层(Bottleneck)其实就算在收缩路径的末尾, 网络最深层,用3×3卷积+ReLU进一步压缩特征,捕捉最抽象的全局信息。
(2)解码器(Expansive Path)
或者叫扩展路径(把 "语义信息" 还原到 "像素级")
扩展路径的 "反卷积 + 特征拼接",是把抽象的语义信息,重新映射回每个像素的位置:
- 反卷积(up-conv 2x2):把小尺寸特征图放大(比如 32×32→64×64),相当于 "给语义信息分配像素位置";
- 特征拼接(copy and crop):把收缩路径对应层的 "细节特征"(比如细胞边缘)拼接到当前层 ------ 这一步是关键!既保留了 "全局语义"(知道这里是细胞),又补充了 "局部细节"(知道细胞的边缘在哪里)。
每轮扩展后,图像尺寸越来越大,通道数越来越少(从 1024→512→256...)------ 语义信息被逐步 "细化" 到每个像素附近。
(3)最后一层输出层(给每个像素打 "分割标签")
扩展路径末尾后,U-Net 会加一个1x1 卷积(conv 1x1):
- 1x1 卷积的作用是 "分类":把当前特征图的通道数,转换成 "类别数"(比如 ISBI 是二分类,通道数从 64→2,或直接输出 1 通道 + Sigmoid);
- 最终每个像素对应的通道值,就是 "该像素属于某类的概率"(比如 0.9 代表这个像素是细胞,0.1 代表是背景)。
3.conv 3×3卷积 计算方式
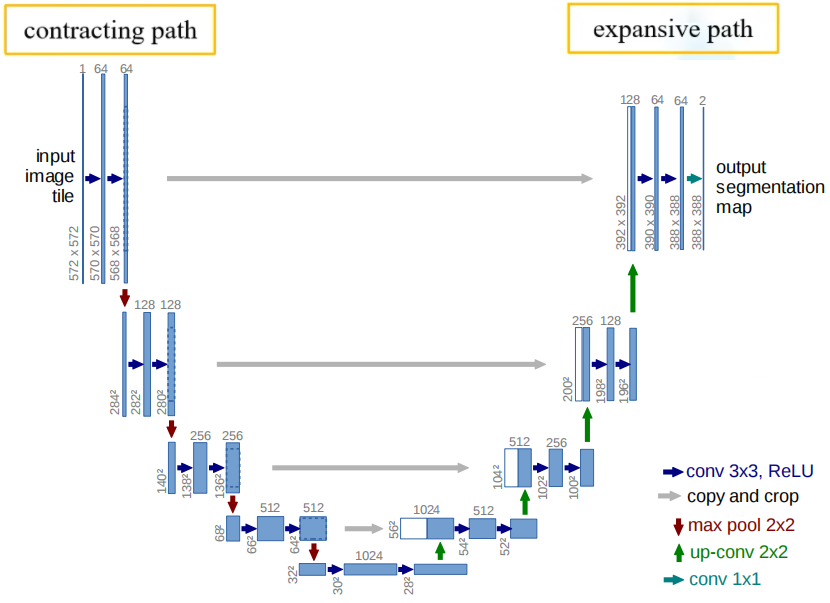
conv 3×3详细解释,以第一个conv 3x3 × 2 为例:
左上角卷积层:图像大小572×572→570×570→568×568没什么好解释的,因为没有padding边缘填充,所以每次卷积完少了外面一圈像素,解释一下通道数1→64→64
先看1→64:输入的图片的输入通道数是 1(也就是每张图像有1个特征图),所以每个卷积核的通道维度是 1(也就是每组卷积核只有1个卷积核),"3×3×1"卷积核(3×3× 输入通道数 ),输出通道是64(要输出的每张图像要有64个特征图),所以需要64组"3×3×1"卷积核,即要使用64 个 "3×3×1" 的卷积核对每个1通道图像卷积,也就是64 个3×3 的卷积核对每个(1通道)图像卷积得到64个特征图,即每个图64通道
再看64→64:因为输入通道数是 64(每张图像有64个特征图),所以每个卷积核的通道维度是 64(也就是每组卷积核只有64个卷积核),"3×3×64"卷积核,大白话就是"3×3×64"卷积核 相当于一组卷积核,每组有64个3×3的卷积核;一组卷积核对一张64通道的图片卷积,过程就是这组的64个卷积核对该图的64个特征图分别卷积后再相加得到1个特征图,输出通道是64,所以需要64组"3×3×64"卷积核,即要使用64 个 "3×3×64" 的卷积核对每个64通道图像卷积,(64 个 "3×3×64" 的卷积核 = 64组卷积核,每组有64个3×3卷积核)也就是每组64 个3×3 的卷积核对每个(64通道)图像卷积得到64个特征图再相加成为1张特征图,一共64组就得到64个特征图,即每个64通道图像有64个特征图(++输出通道++ 是几 就需要几 组卷积核,这里输出通道是64 就有64 组"3×3×64"卷积核;++输入通道++ 是几 则每一组卷积核就有几个卷积核)
二.U-Net架构流程详解
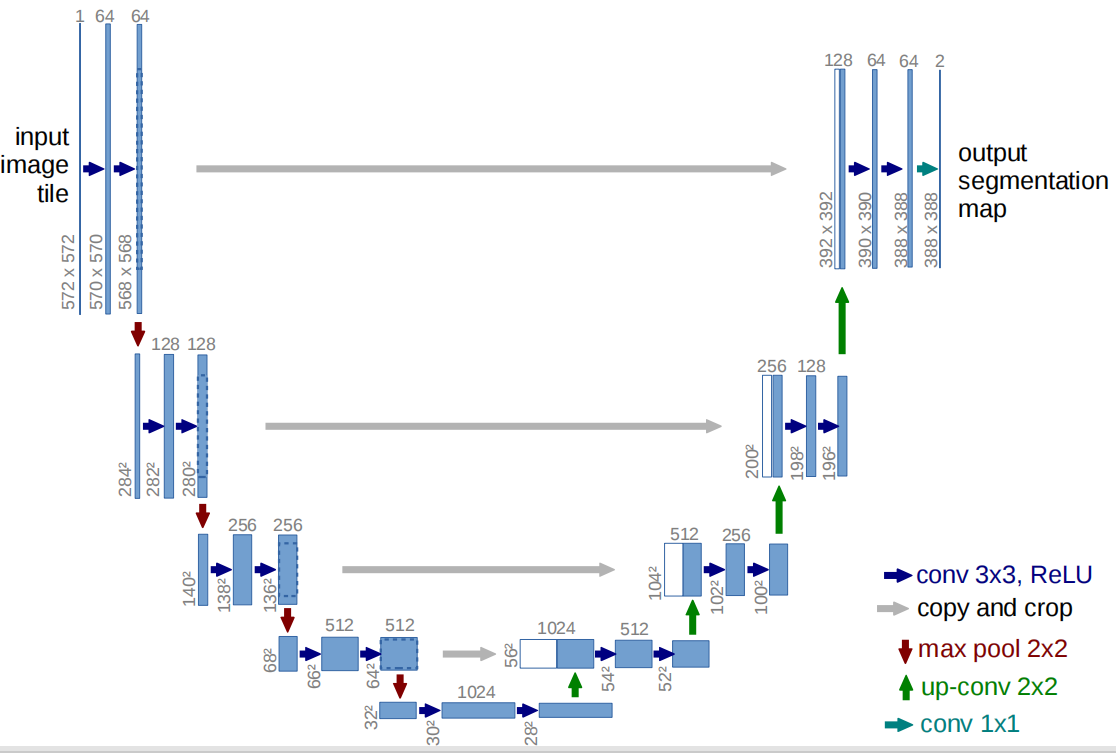
0.架构图中核心信息
- 蓝色竖条:上方数字 = 通道数,下方数字 = 特征图尺寸(宽 × 高),蓝色竖条是多通道特征图;
- 箭头含义:
- 🔵
conv 3x3, ReLU:3×3 卷积 + ReLU(每轮卷积会让尺寸缩减 2,因为无 padding); - 🟤
max pool 2x2:2×2 最大池化(池化就是下采样,尺寸减半); - 🟢
up-conv 2x2:2×2 反卷积(即上采样,尺寸翻倍); - ⚪
copy and crop:复制编码器特征图,裁剪后与解码器特征图拼接(通道数相加); - 🔵
conv 1x1:1×1 卷积(调整通道数为分类数)。
- 🔵
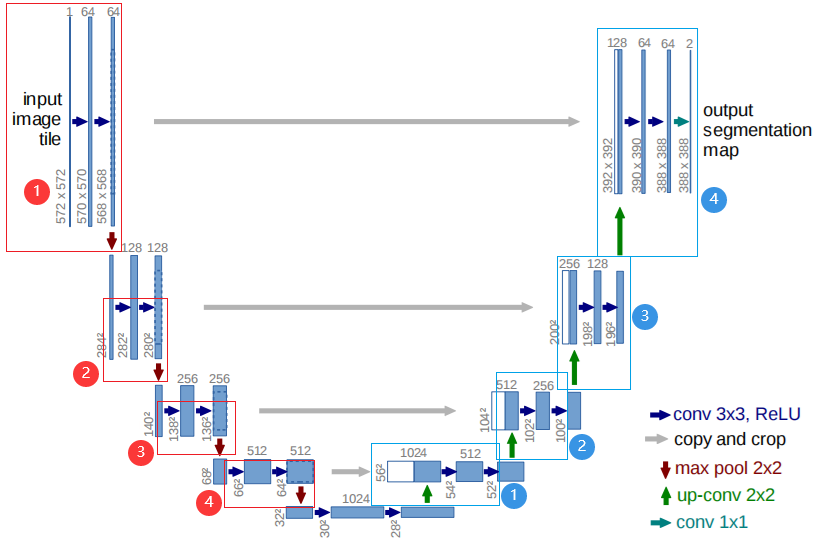
1.编码器(左侧:下采样流程;看红色序号)
以输入572×572为起点,逐步压缩尺寸、增加通道数:(红色序号为编码器对应步骤)
步骤 0:输入层
- 输入:
input image tile,通道数 = 1 ,尺寸 = 572×572(图中 "572×572")。
步骤 1:第 1 次卷积 + 池化
- 🔵
conv 3x3, ReLU×2(两次卷积):- 输入通道 = 1 → 输出通道 =64;(使用64×"3×3×1"卷积核,64组卷积核无论卷积几次都是得到64个特征图(得到的图片是64通道图片),卷积一次得到64个特征图,卷积两次也是64个特征图,即64通道)
- 尺寸:因为没有padding边缘填充,所以每轮 3×3 卷积缩小一圈,即行列各缩减 2,
572×572→570×570→568×568;
- 🟤
max pool 2x2(最大池化):- 尺寸从
568×568→284×284(池化尺寸减半,通道数不变); - 通道数不变保持 64。
- 尺寸从
步骤 2:第 2 次卷积 + 池化
- 🔵
conv 3x3, ReLU×2:- 输入通道 = 64 → 输出通道 =128;(使用128×"3×3×64"卷积核)
- 尺寸从
284×284→282×282→280×280;
- 🟤
max pool 2x2:- 尺寸从
280×280→140×140(减半); - 通道数保持 128。
- 尺寸从
步骤 3:第 3 次卷积 + 池化
- 🔵
conv 3x3, ReLU×2:- 输入通道 = 128 → 输出通道 =256;
- 尺寸从
140×140→138×38→136×136;
- 🟤
max pool 2x2:- 尺寸从
136×136→68×68(减半); - 通道数保持 256。
- 尺寸从
步骤 4:第 4 次卷积 + 池化
- 🔵
conv 3x3, ReLU×2:- 输入通道 = 256 → 输出通道 =512;
- 尺寸从
68×68→66×66→64×64;
- 🟤
max pool 2x2:- 尺寸从
64×64→32×32(减半); - 通道数保持 512。
- 尺寸从
2.瓶颈层(最底部)
- 🔵
conv 3x3, ReLU×2:- 输入通道 = 512 → 输出通道 =1024;
- 尺寸从
32×32→30×30→28×28(图中 "28");
3.解码器(右侧:上采样 + 拼接流程;看蓝色序号)
从瓶颈层28×28开始,逐步放大尺寸、减少通道数:看蓝色序号
步骤 1:第 1 次上采样 + 拼接 + 卷积
- 🟢
up-conv 2x2上采样:- 通道数不变
- 尺寸从
28×28→56×56(与下采样相反)。 - 上采样使用转置卷积:
- 举例:输入数据2×2,转置卷积为右边2×2卷积核,步长为2。每个像素都要乘上卷积核得到一个2×2的区域,然后根据步长进行对应位置相加
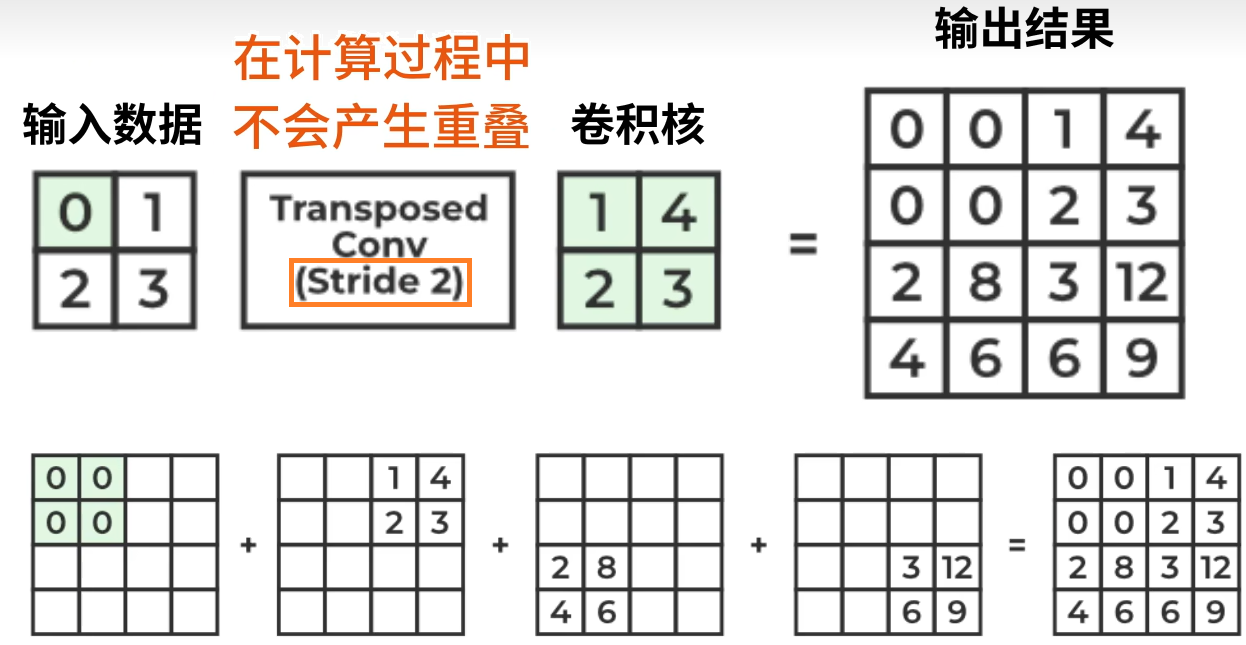
- 若步长为1,则重叠部分需要叠加

- 举例:输入数据2×2,转置卷积为右边2×2卷积核,步长为2。每个像素都要乘上卷积核得到一个2×2的区域,然后根据步长进行对应位置相加
- ⚪
copy and crop:- 复制编码器第 4 次卷积后的特征图(尺寸
64×64、通道数 512); - 裁剪:
64×64→56×56(从上下左右边缘各裁掉4 个像素,然后只要中间的56×56像素,匹配上采样尺寸);下图这么裁,只要红框里面56×56像素: 
- 裁剪以后尺寸就一样了,就可以在 "通道维度" 上拼接了,直接通道数相加,相当于特征图变多了从512张→1024张了,拼接后通道数 = 512+512=1024。
- 复制编码器第 4 次卷积后的特征图(尺寸
- 🔵
conv 3x3, ReLU×2:- 输入通道 = 1024 → 输出通道 =512(使用512×"3×3×1024"卷积核,512组卷积核无论卷积几次都是得到512个特征图(得到的图片是512通道图片),卷积一次得到512个特征图,卷积两次还是512个特征图,即512通道);
- 尺寸从
56×56→54×54→52×52;
步骤 2:第 2 次上采样 + 拼接 + 卷积
- 🟢
up-conv 2x2上采样:- 通道数不变;
- 尺寸从
52×52→104×104(上采样尺寸翻倍)。
- ⚪
copy and crop:- 复制编码器第 3 次卷积后的特征图(尺寸
136×136、通道数 256); - 裁剪:
136×136→104×104(从边缘各裁 16 个像素),裁剪参考下图 
- 裁剪以后尺寸就一样了,就可以在 "通道维度" 上拼接了,直接通道数相加,相当于特征图变多了从256张→512张了,拼接后通道数 = 256+256=512。
- 复制编码器第 3 次卷积后的特征图(尺寸
- 🔵
conv 3x3, ReLU×2:- 输入通道 = 512 → 输出通道 =256;(使用256×"3×3×512"卷积核,256组卷积核无论卷积几次都是得到256个特征图(得到的图片是256通道图片),卷积一次得到256个特征图,卷积两次还是256个特征图,即256通道)
- 尺寸从
104×104→102×102→100×100;
步骤 3:第 3 次上采样 + 拼接 + 卷积
- 🟢
up-conv 2x2:- 通道数不变;
- 尺寸从
100×100→200×200。
- ⚪
copy and crop:- 复制编码器第 2 次卷积后的特征图(尺寸
280×280、通道数 128); - 裁剪:
280×280→200×200(从边缘各裁 40 个像素); - 拼接后通道数 = 128+128=256。
- 复制编码器第 2 次卷积后的特征图(尺寸
- 🔵
conv 3x3, ReLU×2:- 输入通道 = 256 → 输出通道 =128;
- 尺寸从
200×200→198×198→196×196(图中 "196");
步骤 4:第 4 次上采样 + 拼接 + 卷积
- 🟢
up-conv 2x2:- 通道数不变;
- 尺寸从
196×196→392×392。
- ⚪
copy and crop:- 复制编码器第 1 次卷积后的特征图(尺寸
568×568、通道数 64); - 裁剪:
568×568→392×392(从边缘各裁 88 个像素); - 拼接后通道数 = 64+64=128。
- 复制编码器第 1 次卷积后的特征图(尺寸
- 🔵
conv 3x3, ReLU×2:- 输入通道 = 128 → 输出通道 =64;
- 尺寸从
392×392→390×390→388×388;
4.输出层
- 🔵
conv 1x1:- 输入通道 = 64 → 输出通道 =2(对应 2 分类任务,通道数从 64→2,或直接输出 1 通道 + Sigmoid);
- 尺寸保持
388×388; - 最终输出:
output segmentation map,通道数 = 2,尺寸 = 388×388。
(1)通道数从 64→2 的完整输出过程 :利用2组"1×1×64"的卷积核把通道从64→2,即每个像素有两个通道值,假设规定通道0对应"是背景"的概率、通道1对应"是细胞"的概率(后续****训练过程中卷积核的权重通过学习确定通道的语义 ------ 模型会自动把其中一个通道优化为背景打分、另一个为细胞打分 )。卷积后通道 0 值 = 0.2,通道 1 值 = 3.5;对每个像素的 2 个通道值做 Softmax 运算 ,代入P(类别i) = e^得分i / (e^得分0 + e^得分1)公式,背景概率≈ 0.0357、细胞概率≈ 0.9643。取最大值 :对每个像素的 2 个概率值,选择 "概率更大的类别" 作为该像素的最终标签,0.9643>0.0357,则该像素标签 = 1(细胞)。生成最终分割掩码: 所有像素完成标签赋值后,原本的 [B, 2, H, W] 特征图,会转换成 [B, 1, H, W] 的单通道二值掩码:
- 掩码中每个像素值只有 0(背景)或 1(细胞);
- 可视化时,1 对应白色(细胞区域),0 对应黑色(背景),就是最终看到的分割结果。
- 最终输出的就是一个标着分割线的图像
(2)
loss = criterion(outputs, masks)
三.主流U-Net
主流U-Net多了padding与BN
- 在每一次conv 3×3卷积操作前都加上padding边缘填充,使得图片尺寸不会改变,对原版U-Net的影响:在瓶颈层图片尺寸变化是
32×32→30×30→28×28,padding以后尺寸不再变化仍然是32×32,上采样后变成64×64,这样拼接时就不用在裁剪了直接拼接,这就是好处,后续编码器仍然使用这个尺寸,会使最终得到的原本388×388的输出图片仍然与输入图片尺寸保持一致,则输出图片尺寸仍然是572×572 - 在conv 3×3与ReLu中间加上BN操作
四.重叠分块策略(Overlap-tile strategy)
1.分块
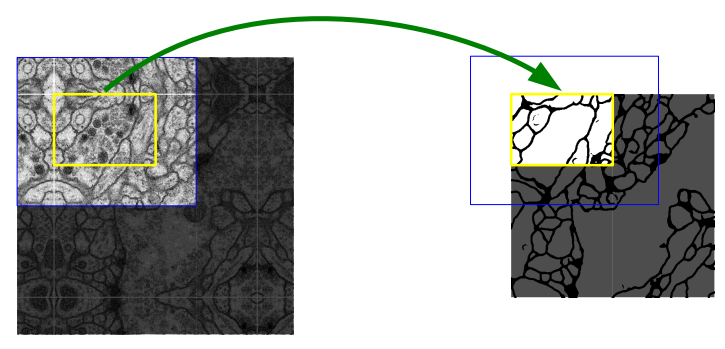
这张图展示的是 U-Net 原论文中提出的重叠分块策略(Overlap-tile strategy)",核心是解决大尺寸图像(比如电子显微镜 EM 堆叠的神经元图像)无法直接输入模型的问题 **,具体逻辑如下:
(1)为什么需要这个策略?
U-Net 的输入尺寸是固定的(比如原论文中的 572×572),但实际要分割的图像(比如神经元 EM 图)通常远大于这个尺寸,直接输入会导致内存不足。因此需要把大图像拆分成多个 "分块" 处理,但普通分块会导致块与块之间的分割边界不连续 ------ 重叠分块策略就是为了实现 "无缝分割"。
(2) 图中元素的含义
- 蓝色区域 :是模型的输入分块(比如 572×572 的尺寸);
- 黄色区域 :是我们需要预测的目标区域(比如中间的 388×388 区域);
- 绿色箭头:表示 "预测黄色区域,需要蓝色区域作为输入"------ 因为 U-Net 的卷积会 "裁切" 边缘(无 padding 时),直接预测黄色区域会丢失边缘信息,所以需要更大的蓝色区域作为输入,利用边缘的上下文信息。
(3)具体操作步骤
- 分块 :++把大图像拆成多个重叠的蓝色分块++(每个分块尺寸是模型输入尺寸);
- 补全缺失数据 :++如果分块在图像边缘(比如图像左上角),缺失的输入数据通过镜像填充(mirroring)来补全,可以看出黄色框区域是左上角,那么黄色框左边和上边部分都是以原图边缘为对称轴进行镜像复制的++;
- 预测并拼接:对每个蓝色分块输入 U-Net,只取中间的黄色区域作为有效预测结果,最后把所有黄色区域拼接起来,得到完整的大图像分割结果。
2.重叠
每次分块处理时块与块之间要重叠一部分
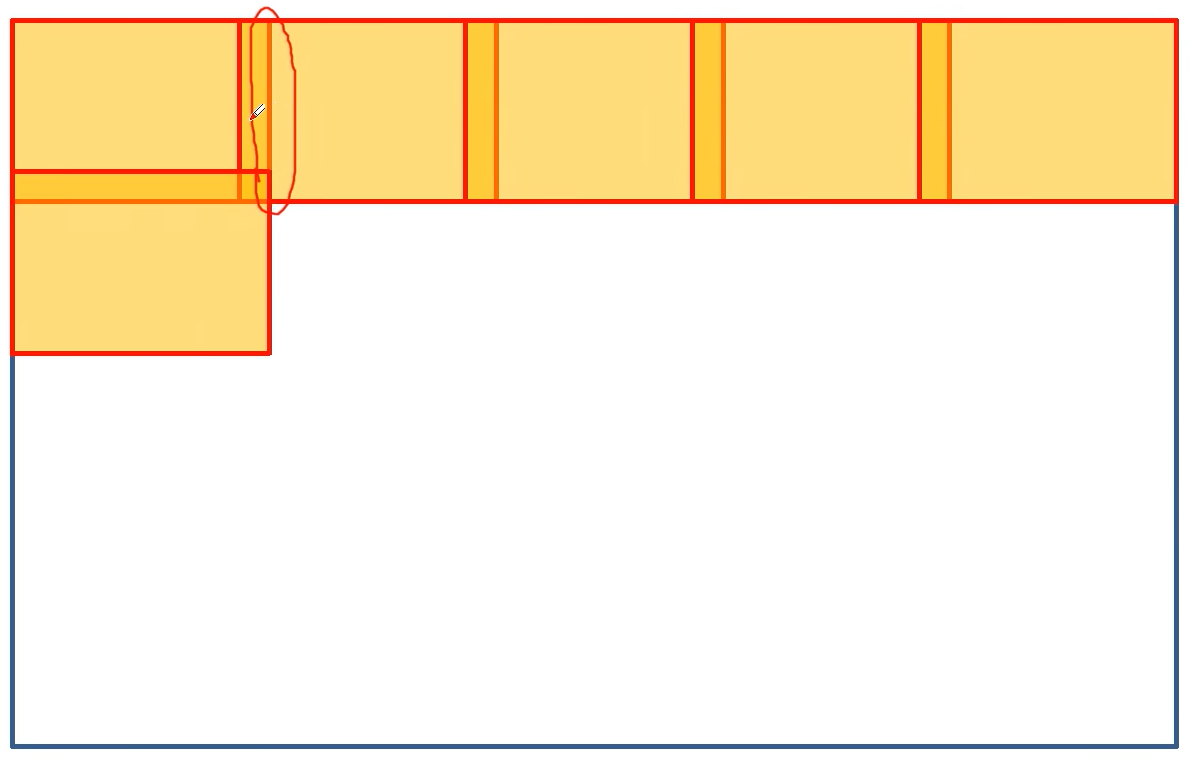
(1)为什么需要 "重叠"?
普通分块(无重叠)处理大图像时,每个分块的边缘特征是 "孤立的"(没有相邻分块的上下文信息),分割后块与块的边界会出现明显断裂(比如神经元图像中,块边缘的神经纤维会断开)。
而 ++"重叠" 让每个分块的边缘区域能借用相邻分块的上下文信息,最终只取分块中间 "不受边缘干扰的区域" 作为有效结果,拼接后就不会有断层++。
(2)"重叠" 的具体操作
以图中的分块为例:
- ++每个分块(比如蓝色区域)会覆盖相邻分块的一部分区域(图中红框里的重叠带);++
- ++对每个分块,模型只输出中间的非重叠区域(比如黄色区域)作为有效分割结果;++
- ++把所有分块的 "中间黄色区域" 拼接起来,就能得到完整、无缝的大图像分割结果++。
(3)重叠区域的大小怎么定?
重叠区域的宽度等于U-Net 卷积操作导致的 "边缘裁切宽度":比如原 U-Net 的 conv 3×3 无 padding,每次卷积会裁切 2 个像素,经过多次卷积后,输入分块(572×572)的有效输出区域是中间 388×388------ 此时重叠区域的宽度就是(572−388)/2=92像素。
简单说:"重叠" 是用分块间的重复区域,换来了分割结果的 "无缝衔接",是处理大图像时的关键技巧。
3.若padding、根本不用考虑边缘问题
若使用主流U-Net,加上了padding边缘填充操作,输出图像尺寸与输入图像尺寸保持一致,则不用再考虑上面的边缘问题了!
五.历程代码讲解
1.ISBI 2012 EM数据集
该数据集的图像均来自果蝇一龄幼虫腹侧神经索的连续切片透射电子显微镜影像,数据集包含训练集和测试集两部分,且两部分均由 30 张 512×512 像素的 8 位灰度图组成
| 文件名 | 功能描述 |
|---|---|
| train-volume.tif | 训练集原始影像,为 8 位灰度图,包含 30 张 512×512 像素的切片图像 |
| train-labels.tif | 训练集对应的像素级标注图,采用黑白二值标注(人工标注),白色代表细胞区域,黑色代表细胞膜区域 |
| test-volume.tif | 测试集原始影像,规格与训练集一致,但对应的分割标注结果不公开,需提交算法预测结果给组织者评估 |
测试集没有公开标注如何评估训练效果?其实在 ISBI 2012 EM 数据集的实验中,大家并不会依赖未公开的测试集标注,而是通过训练集的拆分 + 可视化 + 定量指标这几种核心方式来判断模型效果。
2.load_tif 中处理图像文件对象
(1)img是代表整个 TIFF 文件的对象,但不是物理文件本身。
- 物理文件:你电脑里的
train-volume.tif是物理图像文件,它躺在硬盘里,不运行程序也存在; ima是PIL 的Image对象(图像对象,是文件级对象):运行img = Image.open("train-volume.tif")后,程序会把这个文件的关键数据加载到内存,生成img对象 ------++它就像这个物理文件的 "内存分身",你对img做的操作(比如seek(5)、resize())不会直接改硬盘里的原文件++ ,除非调用img.save()把修改后的img写回硬盘。
python
#自定义的 TIFF 文件加载方法(详解见大标题五->2.)
def load_tif(self, path):
"""加载TIFF文件,返回[H, W]格式的图像列表"""
img = Image.open(path) #tiff文件保存在img中,img是整个 TIFF 文件的对象(包含文件里所有图片的元信息和数据)
images = [] #创建列表,用于存储 TIFF 中的所有切片
for i in range(img.n_frames):#n_frames表示一个图像文件中包含的 "页数"(即图像数量)
#(详解在大标题五->2.)这是处理多页图像的标准流程,目的是将分散的多页图像整合为一个统一的数组:
img.seek(i)
images.append(np.array(img))
#将列表转换为 numpy 数组,形状为[N, H, W, 1](N是切片数,H/W是图像高 / 宽,最后一维是通道数,灰度图为 1)。
return np.array(images)[..., np.newaxis] # [N, H, W, 1](2)处理**多页图像(文件级对象)**的标准流程
图像转 numpy 数组→加列表→返回numpy数组"
这是处理多页图像的标准流程,目的是将分散的多页图像整合为一个统一的数组,方便后续模型使用,具体原因:
①先单页处理
img.seek(i)每次只能定位到一张图像,我们先逐张处理:
- 先用
np.array(img)将当前页的图像转为 numpy 数组(形状为(H, W)); - 但此时只能得到单张图的数组,无法直接得到包含所有图像的数组。
②把单张图片加入列表
列表images相当于一个 "临时容器":
- 每处理一张图,就把它的数组
append到列表中,逐步收集所有图像; - 例如处理 30 张图后,列表会包含 30 个
(512, 512)的数组,形式为[arr0, arr1, ..., arr29]。
③列表转 numpy 数组
模型需要的是一个统一的多维数组(而非分散的列表):
- 用
np.array(images)将列表转换为形状为(30, 512, 512)的 numpy 数组; - 这个数组的维度是
(样本数, 高度, 宽度),符合模型对批量数据的输入要求(后续还会添加通道维度)。
(3) return np.array(images)..., np.newaxis
np.array(images):把列表转为三维批量数组(N, H, W);[...]:保留原有所有维度的全部数据;np.newaxis:在最后一维插入长度为 1 的新维度(通道维度);- 整体作用:将数组从
(N, H, W)转为(N, H, W, 1),适配模型对通道维度的要求。 [..., np.newaxis]替代[:, :, :, np.newaxis],替换了臃肿的写法。因为这里要加入通道维度,所以务必写上[:, :, :, np.newaxis],如果直接return np.array(images)就加不上通道维度了。
3.图像和标签的像素值归一化问题
(1)图像归一化
像素值:0-255 ---> 0, 1 ---> -1, 1
因为深度学习模型(尤其是基于卷积、激活函数的模型)在输入数据符合均值为 0、方差为 1 的分布时,收敛最快、最稳定,所以最终是为了缩放到[-1, 1]来优化模型训练。
而缩放要使用transform管道缩放,而transforms.Normalize(mean, std)的公式是(input - mean) / std,这个函数的**前提是输入已经缩放到 0-1。**所以像素值要想0-255---> -1, 1 就要先缩放0-255 ---> 0, 1。
python
transform = transforms.Compose([
transforms.Normalize((0.5,), (0.5,)) # 归一化到[-1,1]
]) transforms.ToTensor()0-255 ---> 0, 1 ---> -1, 1 ---> 0, 1 解释:
最终显示要按 0, 1 来显示黑白像素
(2)标签归一化
标签不能归一化
类class ISBI2012Dataset的__getitem__函数中不应该加下面这两句话:
python
# if self.transform:
# mask = self.transform(mask)这句是错的,BCELoss 要求标签必须在0,1区间内,所以masks标签不能被transforms.Normalize((0.5,), (0.5,))归一化到-1,1,删掉即可
4.torch.save(model.state_dict()............)
python
# 保存模型
torch.save(model.state_dict(), os.path.join(save_dir, "unet_isbi2012.pth"))
#把 model.state_dict()(模型参数字典)作为 "要保存的内容",
#通过 torch.save() 保存到 os.path.join(...) 拼接出的文件路径里。
print(f"训练完成!模型和结果保存在 {save_dir} 文件夹")(1)state_dict()函数
model.state_dict() 是 PyTorch 中模型参数的 "字典快照" ------ 简单说,它把模型里所有可学习的参数(比如卷积核权重、BN 层的均值 / 方差、全连接层的权重等)以「键值对」的形式打包成一个字典,方便保存、加载和复用。
函数名字的含义
- state:模型的 "状态",特指所有可训练的参数(权重、偏置、BN 层的统计量等);
- dict :字典结构,
key是参数所属的层名称(比如conv1.weight),value是参数对应的张量(Tensor)。
以本 U-Net 为例,model.state_dict() 里的内容大概长这样:
python
{
"inc.double_conv.0.weight": 张量(64, 1, 3, 3), # 第一个卷积层的权重
"inc.double_conv.0.bias": 张量(64), # 第一个卷积层的偏置
"inc.double_conv.1.weight": 张量(64), # BN层的权重
"inc.double_conv.1.bias": 张量(64), # BN层的偏置
"inc.double_conv.1.running_mean": 张量(64), # BN层的运行均值
... # 后续所有层的参数
"outc.conv.weight": 张量(1, 64, 1, 1), # 输出层1×1卷积的权重
"outc.conv.bias": 张量(1) # 输出层的偏置
}(2)save函数:
把参数一: 训练好的 U-Net 模型的所有可学习参数(权重、偏置等),保存到**参数二:**指定路径的.pth 文件中,方便后续加载复用
→ 把 model.state_dict()(模型参数字典)作为 "要保存的内容",通过 torch.save() 保存到 os.path.join(...) 拼接出的文件路径里。
历程代码:
历程不是全对的,后面我的简洁代码才是全部正确的,都是本人自己修改并跑过的!
python
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from PIL import Image
import requests
from zipfile import ZipFile
import io
# ===================== 1. 数据集下载与预处理 =====================
#下载不了,只能去掉这个下载函数了,手动导入数据集!!!
def download_isbi2012():
"""下载ISBI 2012 EM数据集(U-Net原论文数据集)"""
url = "https://www.dropbox.com/s/3d83b5e2zflx8j0/isbi2012.zip?dl=1"
save_path = "./isbi2012" # data_dir/save_path:存放「原始 ISBI 数据集」
os.makedirs(save_path, exist_ok=True)
# os.makedirs创建结果文件夹,避免路径不存在的错误。
# exist_ok:当要创建的目录save_dir已经存在时,是否抛出错误。
# 当exist_ok=True时:如果save_dir已经存在,不会报错,会忽略创建操作;
# 当exist_ok=False(这是默认值)时:如果save_dir已经存在,会抛出FileExistsError错误。
# 检查训练集文件是否已下载,避免多次运行代码造成重复下载
if not os.path.exists(os.path.join(save_path, "train-volume.tif")):
# os.path.exists:判断括号中的路径是否存在
# os.path.join:将保存的目录路径save_path和文件名拼接成一个完整的文件路径,
# 避免手动处理路径分隔符(如 Windows 的\和 Linux 的/)带来的问题
print("正在下载ISBI 2012 EM数据集...")
# 发送 GET 请求下载数据集,返回的response包含文件字节流。
response = requests.get(url)
# 将字节流(即下载的数据集)转换为 ZIP 文件对象,zf为压缩文件句柄。
with ZipFile(io.BytesIO(response.content)) as zf:
zf.extractall(save_path) # 解压 ZIP 文件到save_path文件夹。
print("数据集下载完成!")
return save_path
# 定义 ISBI 2012 数据集的加载类,继承 PyTorch 的Dataset基类。
class ISBI2012Dataset(Dataset):
"""ISBI 2012 EM数据集加载类"""
def __init__(self, data_dir, train=True, transform=None):
self.data_dir = data_dir # 保存数据集路径
self.train = train # 保存训练 / 测试模式到类变量
self.transform = transform
# 加载数据(TIFF格式,包含多个切片)
if train:
# 加载训练集图像(TIFF 文件),调用load_tif方法。
# load_tif:下面的自定义的 TIFF 文件加载方法
self.images = self.load_tif(os.path.join(data_dir, "train-volume.tif"))
# 加载训练集标签(TIFF 文件),标签是神经元的分割掩码。
self.masks = self.load_tif(os.path.join(data_dir, "train-labels.tif"))
else:
self.images = self.load_tif(os.path.join(data_dir, "test-volume.tif"))
self.masks = None # 测试集无标签
# 自定义的 TIFF 文件加载方法(详解见大标题五->2.)
def load_tif(self, path):
"""加载TIFF文件,返回[H, W]格式的图像列表"""
img = Image.open(path) # tiff文件保存在img中,img是整个 TIFF 文件的对象(包含文件里所有图片的元信息和数据)
images = [] # 创建列表,用于存储 TIFF 中的所有切片
for i in range(img.n_frames): # n_frames表示一个图像文件中包含的 "页数"(即图像数量)
# (详解在大标题五->2.)这是处理多页图像的标准流程,目的是将分散的多页图像整合为一个统一的数组:
img.seek(i)
images.append(np.array(img))
# 将列表转换为 numpy 数组,形状为[N, H, W, 1](N是切片数,H/W是图像高 / 宽,最后一维是通道数,灰度图为 1)。
return np.array(images)[..., np.newaxis] # [N, H, W, 1]
def __len__(self): # 返回数据集的样本数量
return len(self.images)
def __getitem__(self, idx): # 根据索引idx获取单个样本,idx为样本索引
# 获取第idx个图像,转换为 float32 类型并归一化到[0,1](像素值原范围是 0-255):
img = self.images[idx].astype(np.float32) / 255.0 # 归一化到[0,1]
img = torch.from_numpy(img).permute(2, 0, 1) # [1, H, W]
# from_numpy:将 numpy 数组转换为 PyTorch 张量;
# 调整维度顺序,从[H, W, 1]变为[1, H, W](符合 PyTorch 的[通道数, 高, 宽]格式)。
# permute 参数 含义 旧维度 新维度
# 2 取原张量的第 2 维(通道数 C) H 1 (索引 2)
# 0 取原张量的第 0 维(高度 H) W H (索引 0)
# 1 取原张量的第 1 维(宽度 W) 1 W (索引 1)
# 调整原因:PyTorch 的深度学习框架(尤其是卷积层)对图像张量的维度顺序有强制要求,
# 必须是「通道数在前」,而从 NumPy 加载的图像默认是「通道数在后」。
if self.transform: # 如果有预处理函数,应用到图像上
img = self.transform(img)
if self.train:
# 获取第idx个标签,归一化到[0,1](标签是二值图像,0 为背景,1 为神经元)。
mask = self.masks[idx].astype(np.float32) / 255.0
# 转换为张量并调整维度为[1, H, W]
mask = torch.from_numpy(mask).permute(2, 0, 1)
#if self.transform: 这句是错的,BCELoss 要求标签必须在[0,1]区间内,所以masks标签不能被transforms.Normalize((0.5,), (0.5,))归一化到[-1,1]
# mask = self.transform(mask)
return img, mask # 如果是用于训练,就返回训练样本(图像 + 标签)
return img # 如果是用于测试,仅返回图像
# ===================== 2. 带Padding+BN的U-Net模型 =====================
class DoubleConv(nn.Module):
"""两次卷积+BN+ReLU,padding=1保证尺寸不变"""
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), # padding=1保持尺寸
nn.BatchNorm2d(out_channels), # 加入BN层
nn.ReLU(inplace=True),
# inplace=True的意思是"原地操作"
# inplace=False(默认):ReLU 会生成一个新的张量保存激活后的结果,原来的输入张量保持不变;
# inplace=True:ReLU 直接在原来的输入张量上进行修改,覆盖原始数据,不会额外创建新张量。
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
# 下采样模块
class Down(nn.Module):
"""下采样:MaxPool + DoubleConv"""
def __init__(self, in_channels, out_channels):
super(Down, self).__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2), # 尺寸减半,池化核的大小,表示2×2(若(2,3),表示核是2×3)
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
# 上采样模块
class Up(nn.Module):
"""上采样:转置卷积 + 拼接 + DoubleConv"""
def __init__(self, in_channels, out_channels):
super(Up, self).__init__()
# 转置卷积放大2倍,保持尺寸匹配
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
# x1是扩展路径上的多通道特征图,x2是与x1同层的收缩路径上的多通道特征图,尺寸一致
# 由class UNet中的前向传播传入参数
x1 = self.up(x1)
# 通道维度拼接,尺寸不变、通道数翻倍
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
# 输出层
class OutConv(nn.Module):
"""输出层:1x1卷积调整通道数"""
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return torch.sigmoid(self.conv(x)) # 分割任务用sigmoid
class UNet(nn.Module):
def __init__(self, n_channels=1, n_classes=1):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.inc = DoubleConv(n_channels, 64) # 512x512 → 512x512
self.down1 = Down(64, 128) # 512x512 → 256x256
self.down2 = Down(128, 256) # 256x256 → 128x128
self.down3 = Down(256, 512) # 128x128 → 64x64
self.down4 = Down(512, 1024) # 64x64 → 32x32
self.up1 = Up(1024, 512) # 32x32 → 64x64
self.up2 = Up(512, 256) # 64x64 → 128x128
self.up3 = Up(256, 128) # 128x128 → 256x256
self.up4 = Up(128, 64) # 256x256 → 512x512
self.outc = OutConv(64, n_classes) # 512x512 → 512x512(输出尺寸与输入一致)
def forward(self, x):
# 编码器(下采样)
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
# 解码器(上采样)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits # 输出尺寸512x512,与输入一致
# ===================== 3. 训练与结果保存 =====================
def train_and_test():
epochs = 10
# 有 GPU 则用 cuda,否则用 CPU。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
save_dir = "./isbi_results" # save_dir 存放「训练过程的结果」
os.makedirs(save_dir, exist_ok=True)
model_path = os.path.join(save_dir, "unet_isbi2012.pth")
# 1. 加载数据集
# ISBI 2012 不是 PyTorch 官方内置数据集,不能像datasets.MNIST那样直接引入,那就定义一个下载函数
data_dir = download_isbi2012() # 下载数据集, #data_dir/save_path:存放「原始 ISBI 数据集」
transform = transforms.Compose([
transforms.Normalize((0.5,), (0.5,)) # 归一化到[-1,1]
])
transforms.ToTensor()
# transform不需要添加transforms.ToTensor():
# 因为在ISBI2012Dataset的__getitem__方法中,已经手动完成了从 NumPy 数组到 Tensor 的转换
model = UNet(n_channels=1, n_classes=1).to(device) # 输入通道、输出通道数都为1
# 加载模型权重(存在则加载,跳过训练)
if os.path.exists(model_path):
model.load_state_dict(torch.load(model_path, map_location=device))
# 加载训练好的模型参数
# 先通过 torch.load() 读取磁盘上的参数文件,再通过 model.load_state_dict() 把参数
#"填充" 到模型中,map_location 保证参数能正确加载到指定设备(CPU/GPU)
# model_path:参数文件的路径
# map_location=device:指定参数加载到哪个设备(CPU/GPU)
print("已加载保存的模型,跳过训练直接测试")
else:
# 训练过程开始
print("开始训练...")
train_dataset = ISBI2012Dataset(data_dir, train=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
# 解释batch_size=2:ISBI 2012 数据集单样本尺寸512×512×1(像素数≈26 万)
# 而MNIST数据集单样本尺寸28×28×1(像素数≈784)
# 单batch 显存占用ISBI 2012:batch_size=2 → 2×26 万≈52 万像素
# MNIST:batch_size=64 → 64×784≈5 万像素
# 2. 初始化模型、损失函数、优化器
criterion = nn.BCELoss() # 二分类分割用BCELoss
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 3. 训练循环
model.train()
for epoch in range(epochs):
running_loss = 0.0 # 用于累计当前 epoch 的总损失
for i, (imgs, masks) in enumerate(train_loader):
imgs, masks = imgs.to(device), masks.to(device)
# 前向传播(输入输出尺寸均为512x512)
outputs = model(imgs)
loss = criterion(outputs, masks)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
# 保存输入、标签、输出图片(每10个batch保存一次)
if i % 10 == 0:
# 拼接图片:输入 + 标签 + 输出
imgs = (imgs + 1) / 2 # 还原到[0,1],对每一个像素值单独计算,自从数据集类里面/255.0以后就都是浮点值了,浮点值的有效亮度范围是[0,1]
masks = masks # 标签只能是0或1,已经在[0,1]则无需处理
outputs = outputs # 模型输出已通过 sigmoid 在 [0,1] 范围
comparison = torch.cat([imgs[:1], masks[:1], outputs[:1]], dim=0)
# 拼接 "输入图像、标签、输出结果"(各取 batch 中的第一张),便于对比。
# dim=0表示在样本维度拼接,形成 3 张图像的序列。
save_image(comparison.cpu(),
os.path.join(save_dir, f"epoch_{epoch}_batch_{i}.png"),
nrow=3, normalize=False)
# save_image:保存拼接后的图像到本地
# comparison.cpu():将张量移回 CPU(保存图像需在 CPU 上操作)
# os.path.join(save_dir, f"epoch_{epoch}_batch_{i}.png"):保存路径,图像名字包含轮次和 batch 号
# nrow=3:每行显示 3 张图像(输入、标签、输出);
# normalize=False:不自动归一化(已手动处理到 [0,1])。
# 打印训练信息
avg_loss = running_loss / len(train_loader) # 计算当前 epoch 的平均损失
print(f"Epoch [{epoch + 1}/{epochs}], Loss: {avg_loss:.4f}")
# 显示当前轮次和平均损失(保留 4 位小数),/ 不是数学除法,只是普通的字符串分隔符,作用是 "分隔当前轮数和总轮数",[]也只是美观
# 保存模型
torch.save(model.state_dict(), model_path)
# 把 model.state_dict()(模型参数字典)作为 "要保存的内容",
# 通过 torch.save() 保存到 os.path.join(...) 拼接出的文件路径里。
print(f"训练完成!模型和结果保存在 {save_dir} 文件夹")
# 测试过程
print("开始测试...")
test_result_dir = os.path.join(save_dir, "test_results") # 存放测试结果
os.makedirs(test_result_dir, exist_ok=True)
test_dataset = ISBI2012Dataset(data_dir, train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
model.eval()
with torch.no_grad():
for idx, imgs in enumerate(test_loader):
imgs = imgs.to(device)
outputs = model(imgs)
imgs_vis = (imgs + 1) / 2
save_image(torch.cat([imgs_vis, outputs], dim=0), # 第1个参数:要保存的图像张量
os.path.join(test_result_dir, f"test_sample_{idx}.png"), # 第2个参数:保存路径/文件对象
nrow=2, # 第3个参数:每行显示的图像数量
normalize=False) # 第4个参数:是否自动归一化张量值到[0,1]
print(f"测试完成,结果保存至: {test_result_dir}")
if __name__ == "__main__":
train_and_test()简介代码输出:
python
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import os
from torchvision.utils import save_image
from torch.utils.data import DataLoader,Dataset
import requests
from zipfile import ZipFile
import io
from torchvision import transforms
from PIL import Image
class ISBI2012Dataset(Dataset):
def __init__(self, data_dir, train=True, transform=None):
self.data_dir = data_dir
self.train = train
self.transform = transform
if train:
self.images = self.load_tif(os.path.join(data_dir, "train-volume.tif"))
self.masks = self.load_tif(os.path.join(data_dir, "train-labels.tif"))
else:
self.images = self.load_tif(os.path.join(data_dir, "test-volume.tif"))
self.masks = None
def load_tif(self, path):
img = Image.open(path)
images = []
for i in range(img.n_frames):
img.seek(i)
images.append(np.array(img))
return np.array(images)[..., np.newaxis]
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img = self.images[idx].astype(np.float32) / 255.0
img = torch.from_numpy(img).permute(2, 0, 1)
if self.transform:
img = self.transform(img)
if self.train:
mask = self.masks[idx].astype(np.float32) / 255.0
mask = torch.from_numpy(mask).permute(2, 0, 1)
# if self.transform:
# mask = self.transform(mask)
return img, mask
return img
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
def __init__(self, in_channels, out_channels):
super(Up, self).__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return torch.sigmoid(self.conv(x))
class UNet(nn.Module):
def __init__(self, n_channels=1, n_classes=1):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512)
self.up2 = Up(512, 256)
self.up3 = Up(256, 128)
self.up4 = Up(128, 64)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
def train_and_test():
epochs=10
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
save_dir="./isbi_results"
os.makedirs(save_dir,exist_ok=True)
model_path=os.path.join(save_dir, "unet_isbi2012.pth")
#data_dir = download_isbi2012()
transform = transforms.Compose([
transforms.Normalize((0.5,), (0.5,))
])
model=UNet(n_channels=1,n_classes=1).to(device)
if os.path.exists(model_path):
model.load_state_dict(torch.load(model_path,map_location=device))
print("已加载保存的模型,跳过训练直接测试")
else:
print("开始训练......")
train_dataset = ISBI2012Dataset("Y:/pycharm/isbi2012_data", train=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
model.train()
for epoch in range(epochs):
running_loss = 0.0
for i, (imgs, masks) in enumerate(train_loader):
imgs=imgs.to(device)
masks=masks.to(device)
outputs = model(imgs)
loss = criterion(outputs, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(train_loader)
print(f"Epoch[{epoch + 1}/{epochs}],平均损失Loss:{avg_loss:.4f}")
torch.save(model.state_dict(), model_path)
print(f"训练完成!模型和结果保存在 {save_dir} 文件夹")
print("开始测试......")
test_dataset=ISBI2012Dataset("Y:/pycharm/isbi2012_data", train=False, transform=transform)
test_loader=DataLoader(test_dataset,batch_size=1,shuffle=False)
model.eval()
test_result_dir=os.path.join(save_dir,"test_results")
os.makedirs(test_result_dir,exist_ok=True)
with torch.no_grad():
for i,imgs in enumerate(test_loader):
imgs=imgs.to(device)
outputs=model(imgs)
imgs_vis=(imgs+1)/2
imgs_vis=imgs_vis.cpu()
outputs=outputs.cpu()
save_image(torch.cat([imgs_vis,outputs],dim=0),
os.path.join(test_result_dir,f"test_sample_{i}.png"),
nrow=2,
normalize=False)
print(f"测试完成,结果保存至: {test_result_dir}")
if __name__ == "__main__":
train_and_test()输出结果: