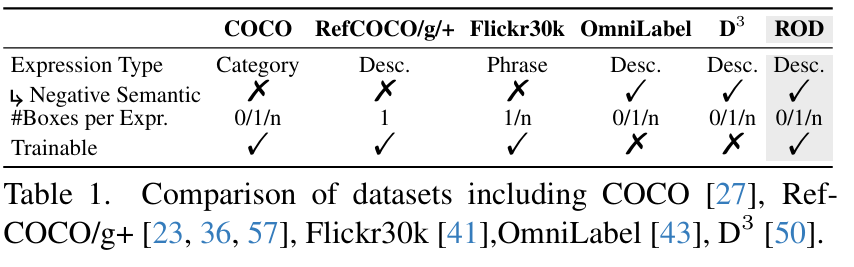
摘要
多模态大语言模型(MLLMs)已展现出强大的语言理解和生成能力,在指代(referring)和定位(grounding)等视觉任务上表现卓越。然而,由于任务类型限制和数据集稀缺,现有的 MLLMs 仅能定位图像中存在的目标,无法有效拒绝不存在的目标,导致预测结果不可靠。本文提出了 ROD-MLLM,一种用于可靠目标检测的新型 MLLM,支持自由形式的语言描述。我们提出了一种基于查询的定位机制来提取低层次目标特征。通过将全局和目标级别的视觉信息与文本空间对齐,我们利用大语言模型(LLM)进行高层次理解并做出最终的定位决策,从而克服了常规检测器在语言理解方面的局限性。为了增强基于语言的目标检测能力,我们设计了一个自动化的数据标注流水线,并构建了名为 ROD 的数据集。该流水线利用现有 MLLMs 的指代能力和思维链(chain-of-thought)技术,生成对应零个或多个目标的多样化表达,解决了训练数据短缺的问题。在包括指代、定位和基于语言的目标检测在内的多种任务上的实验表明,ROD-MLLM 在 MLLMs 中取得了最先进的性能。尤其值得注意的是,在基于语言的目标检测任务中,我们的模型在 D3 基准上比现有 MLLMs 提升了 +13.7 AP,并超越了大多数专用检测模型,特别是在需要复杂语言理解的场景中。
1. 引言
多模态大语言模型(MLLMs)已展现出卓越的视觉理解能力。其出色的多任务处理和泛化能力使其在智能设备56、自动驾驶16, 51和智能医疗48等领域具有广阔的应用前景。通过丰富的视觉指令微调,许多方法10, 31, 54, 63, 65在图像描述46、视觉问答1和视觉对话11等任务上表现出色。然而,这些方法仅在全局层面处理粗粒度的视觉信息。
为了增强细粒度的视觉理解,许多方法追求区域级感知,实现了基于目标表达的定位。然而,如图1所示,所有这些方法都存在两个缺点:表达语义的丰富性和目标数量的多样性。实现视觉定位5, 17, 35, 52, 55, 62的方法主要集中在指代表达理解(REC)任务23, 36, 57上,该任务假设给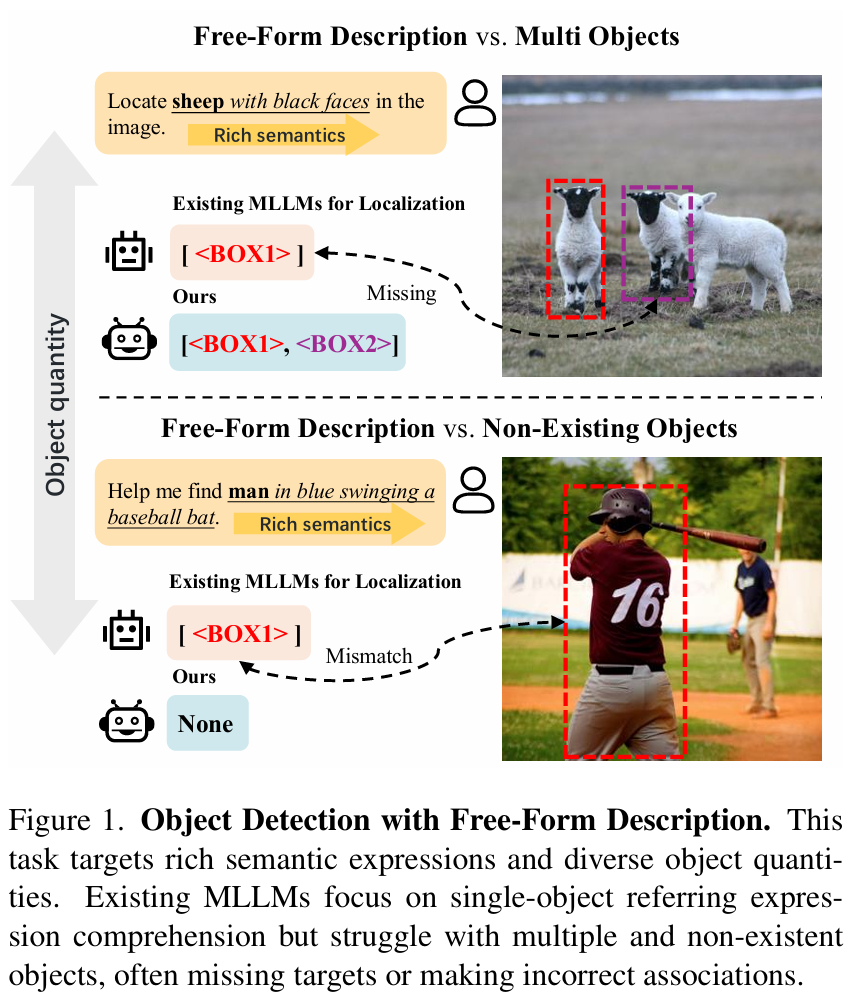
定的目标描述对应图像中的唯一目标,从而忽略了存在多个匹配目标或描述目标不存在的场景。
少数初步实现目标检测的方法61能够进行多目标定位并拒绝不存在的目标,但它们在目标表达的语义丰富性方面受限,主要集中在简单类别(例如,人、自行车)上。在实际场景中,一段文本描述可能对应图像中的多个目标,也可能不对应任何目标。错误的关联会导致模型输出偏离用户的真实意图,从而导致任务失败。因此,我们需要在 MLLMs 中实现一种更可靠的定位任务,即基于语言的目标检测。它可以根据用户的自然语言描述,在图像中定位所有(零个、一个或多个)满足要求的目标。
在本文中,我们提出了 ROD-MLLM,一种用于基于自由形式语言进行可靠目标检测的 MLLM。我们的动机之一是,尽管 LLM 通过大量参数和预训练3, 39展现出了强大的语言能力,但要实现精确的目标定位需要额外的、显著的训练成本35, 61。一些现有的检测器26, 38可以对简单的类别短语执行开放词汇检测(OVD),但在理解复杂语义方面受到语言模型12, 33的限制。因此,我们旨在将基于语言的目标检测解耦为低层次定位和高层次理解两个阶段。我们使用一个开放词汇检测器作为低层次定位器,将其与用户的查询结合以获取候选目标。通过 ROI Align18 提取后,局部目标特征被投影到语言空间,然后与全局视觉特征一起送入 LLM。LLM 结合全局和局部视觉特征以及用户的文本指令进行高层次理解,通过选择符合条件的目标或拒绝不存在的目标来做出最终的定位决策。
此外,为了实现模型对自由形式描述的检测能力,我们设计了一个自动化的标注流水线来构建一个基于语言的目标检测数据集 ROD,以解决该领域训练集的缺乏问题。与通用检测任务不同,基于语言的目标检测因其完全开放集的语言描述而特别具有挑战性。基于现有的检测44和定位41数据集,我们使用 MLLMs 生成丰富的目标描述,并提出了一种基于思维链(COT)的条件判断方法,将描述与目标边界框进行匹配,从而实现基于描述的零到多目标定位。
得益于架构的改进和新构建的数据集,我们推动了 MLLMs 中的基于语言的目标检测。我们在多个基准上评估了 ROD-MLLM,包括基于语言的检测、REC 和区域描述。与现有的 MLLMs 相比,我们的方法在 OmniLabel43 上实现了 +9.7 的 AP 提升,在 D350 上实现了 +13.7 的 AP 提升,甚至超过了大多数专用检测方法。
我们的主要贡献如下:
- 我们提出了 ROD-MLLM,一种能够执行基于语言的目标检测的多模态大语言模型。它能够基于自由形式的语言描述进行统一的目标定位,并能拒绝不存在的目标。
- 我们设计了一个用于语言检测的自动化标注流水线,并构建了包含超过 50 万对目标描述-图像的 ROD 数据集。该数据集能有效提升对自由目标描述的检测能力,缓解了通用 MLLMs 只能执行 REC 任务的不足。
- 我们在与目标定位和生成相关的多个基准上进行了实验,包括基于语言的目标检测、REC 和区域描述。结果表明,与其它 MLLMs 相比,我们的方法在这些任务上均表现出优越的性能。
2. 相关工作
2.1 基于语言的目标检测
基于语言的目标检测将传统封闭集检测27, 44的固定类别扩展到自由形式的描述,使其更具挑战性。一些视觉-语言模型14, 26, 32将此任务重新定义为区域-短语匹配任务。它们采用受 CLIP42 启发的区域级对比学习,并统一了定位和检测数据集。尽管这些专用模型在基于语言的目标检测方面取得了一些初步进展,但它们对 BERT12 等普通语言模型的依赖限制了其语言理解能力,难以处理复杂的描述。为了评估这一新的挑战性任务,已经提出了几个手动标注的基准,如 OmniLabel43 和 D350。它们包含了由人类设计的丰富目标表达,并带有多样化的边界框标注。然而,目前还没有专门用于训练以增强模型在基于语言的目标检测能力的数据集。
据我们所知,我们是第一个提出用于生成基于语言的目标检测训练数据的自动化标注流水线的团队,该流水线利用 MLLMs 在指代和推理方面的能力来生成描述并与边界框进行匹配。
2.2 用于定位的 MLLMs
最近的进展使 MLLMs 能够获得目标定位能力,从而促进更细粒度的视觉任务。这些定位任务可分为两类:定位(grounding)和检测(detection)。大多数 MLLMs 更侧重于前者。Shikra5 通过将边界框文本化在 MLLMs 中实现了指代对话。Pink52 进一步在指代理解中引入了更多推理。MiniGPT-v24 结合了各种定位任务,如 REC、对象解析和定位。Ferret55 专注于指代和定位任务。而 Groma35 通过解耦定位实现了更精确的视觉定位。然而,这些方法只处理图像中存在的对象,当给定不存在对象的描述时,往往会建立错误的视觉关联。Griffon60 开始在 MLLMs 内部实现检测任务,初步实现了对不存在对象的拒绝。然而,由于典型检测数据集的范围有限,它仅在检测简单类别方面表现出色,无法在基于语言的目标检测上表现良好。与所有先前的方法不同,我们的方法在 MLLMs 内部实现了基于语言的目标检测。它能够根据自由形式的语言描述定位图像中所有符合条件的对象,并能拒绝不匹配的对象。
3. 方法
在本节中,我们介绍 ROD-MLLM 的架构,如图2所示。它由两部分组成:低层次定位和高层次理解,将在第3.1节和第3.2节中分别解释。
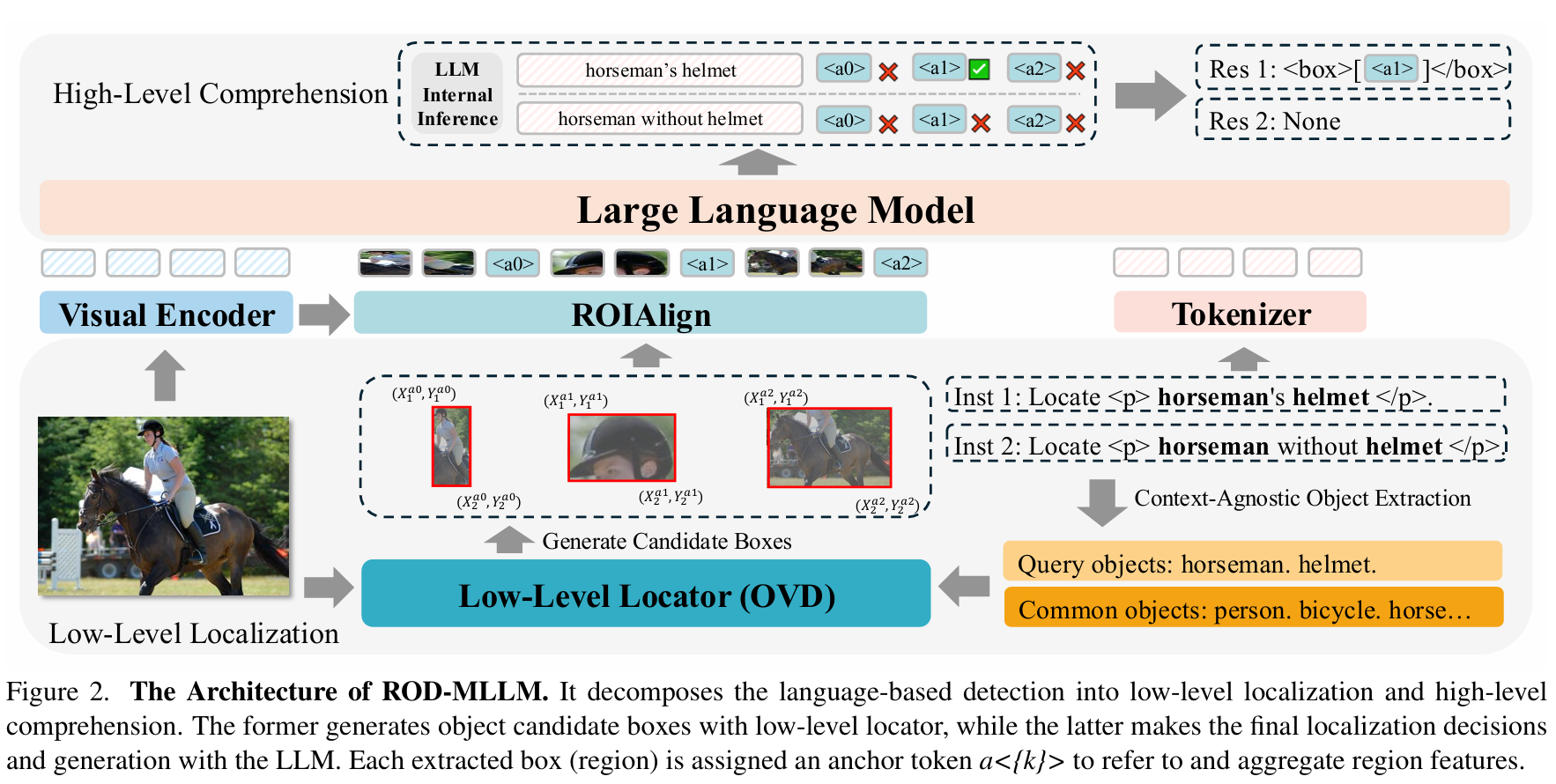
3.1 低层次定位
基于查询的定位。在语言模型中表示对象坐标的主流方式有三种:特殊坐标标记6, 47、文本坐标框5, 55, 61,以及 Groma35 提出的解耦坐标框提取方法。为了保证检测框的精度,我们遵循第三种方法。然而,Groma 为了获得一个类别无关的区域建议网络(RPN)而产生了巨大的训练成本,这限制了其对新奇对象的泛化能力37。与之不同,我们提出了基于查询的定位机制。具体来说,我们首先将基于语言的检测简化为开放词汇检测(OVD),以召回候选对象,这适用于现有的开放词汇检测器。如图2下半部分所示,我们从用户查询中提取位于特殊标签 <p> 和 </p> 之间的对象表达式,并使用 N-gram 提取提及的对象,然后将这些对象作为文本查询提供给低层次定位器(OVD)以提取候选框 BBB:
B=L(I,Oquery,Ocommon)(1) B = \mathcal{L}(I, O_{\text{query}}, O_{\text{common}}) \quad (1) B=L(I,Oquery,Ocommon)(1)
其中 L\mathcal{L}L 是低层次定位器,III 是图像,OqueryO_{\text{query}}Oquery 是查询对象集合,OcommonO_{\text{common}}Ocommon 是来自 COCO27 的常见对象集合,当没有查询对象时,用于增强正常的 VQA 感知。该过程不仅利用了低层次定位器强大的定位能力,还避免了其在理解复杂句子上下文方面的不足。此外,查询对象提取机制减少了无关候选框的数量,从而降低了视觉信息上下文的长度,减轻了计算负担。
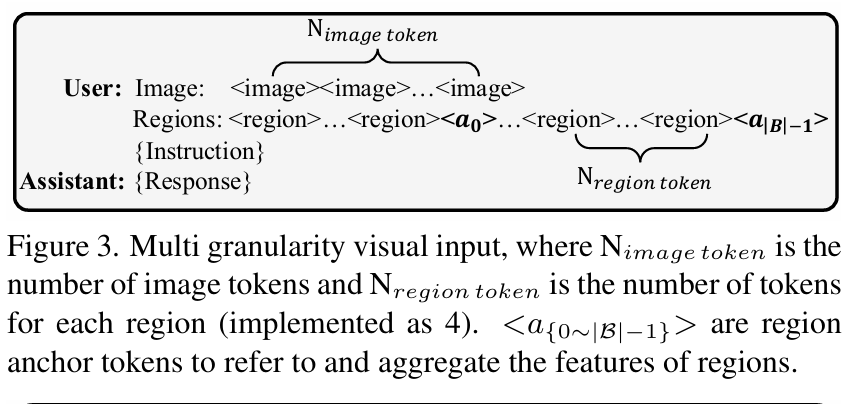
多粒度视觉输入。给定一张图像 III,它被视觉编码器 fVf_VfV 编码以获得多层特征 EI1∼LE^{1\sim L}_IEI1∼L,其中 LLL 是视觉编码器的层数。我们在 EIL−1E^{L-1}_IEIL−1 上使用一个两层 MLP 投影器来获得语言空间中的全局图像嵌入 EIgE^g_IEIg。对于由基于查询的定位器获得的候选框集 BBB,我们从多层特征中构建一个三层特征金字塔 EI12,18,L−1E^{12,18,L-1}_IEI12,18,L−1 并取平均值以提取区域特征。然后,我们使用 8×88\times88×8 ROI Align18 根据边界框坐标提取区域视觉特征 ER∈RB×8×8E_R \in \mathbb{R}^{ B \times8\times8}ER∈RB×8×8。与之前的方法35, 62, 63通过下采样或平均池化将一个区域特征嵌入到单个文本标记中的做法不同,我们将一个区域划分为 2×22\times22×2 的块,并将每个块通过一个 MLP 层以获得一个文本标记。使用更多的标记来编码一个区域,使得 LLM 能够拥有更细粒度的局部信息。如图3所示,LLM 有两种粒度的视觉输入:全局和区域特征标记。在每个区域的标记之后,我们使用一个区域锚点标记 <a_i> 来聚合区域信息并用于区域引用。
3.2 高层次理解
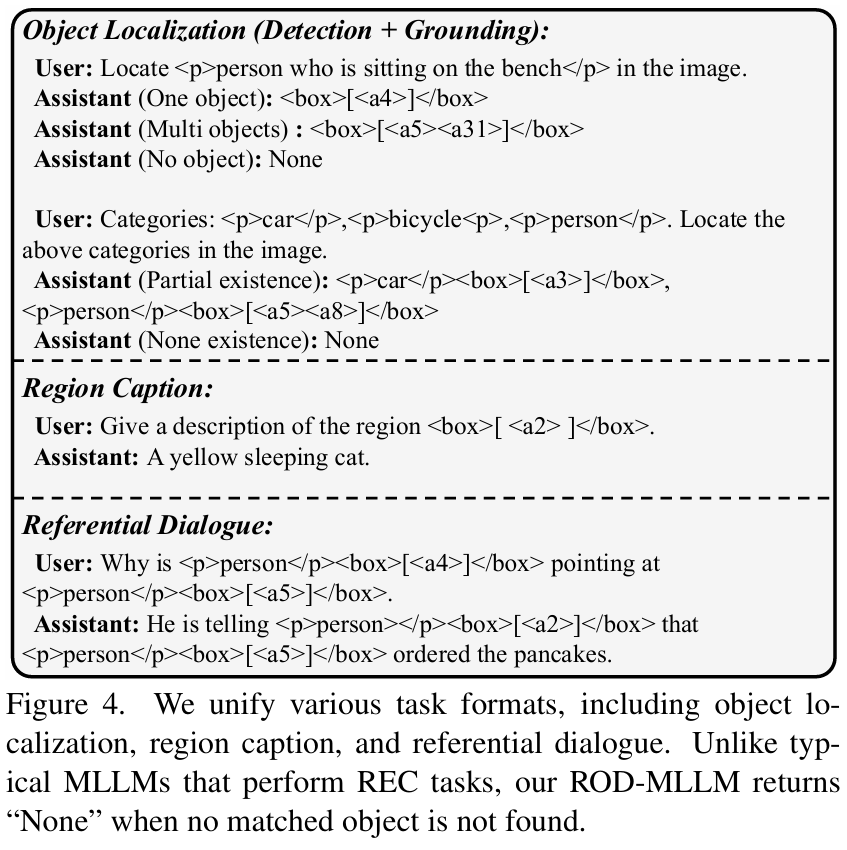
使用 LLM 统一指代、定位和检测。我们采用 LLM Vicuna 7B9 对低层次定位结果进行高层次理解。如图2顶部所示,对于给定的文本表达式,LLM 利用其强大的语言理解能力,判断每个区域是否符合要求并提供最终输出。同样地,当提供一个区域锚点标记时,LLM 可以解释相关的图像内容,从而实现区域描述和指代对话等任务。如图4所示,我们的框架统一了多种任务形式,如指代、定位和检测。其中,标签 <p> 和 </p> 用于包裹表达式。<box>\[\]</box> 中的每个锚点标记用于引用具有坐标的特定区域。特别是,当图像中没有符合要求的对象时,LLM 将输出 "None"。
置信度分数计算。在检测任务中,通常使用平均精度(AP)来衡量性能。这要求模型为每个预测的边界框输出置信度分数以便进行排序。与判别式模型检测器不同,我们使用基于生成的锚点标记的置信度计算方法如下:
P(tm)=exp(zm,tm)∑j=1Vexp(zm,j)(4) P(t^m) = \frac{\exp(z_{m,t^m})}{\sum_{j=1}^{ V } \exp(z_{m,j})} \quad (4) P(tm)=∑j=1Vexp(zm,j)exp(zm,tm)(4)
其中 TTT 是 LLM 的输出标记,包含区域锚点标记 {tm,tn,...}\{t^m, t^n, ...\}{tm,tn,...}。ZmZ_mZm 表示第 mmm 个标记位置的 logits(VVV 是词汇表长度),通过 softmax 转换为概率。该标记概率被用作置信度分数 Ctm∈0,1C_{t^m} \in 0, 1Ctm∈0,1。
4. 数据标注流水线
目前,大多数检测数据集25, 27, 44都是为预定义的简单类别设计的,而基于语言的目标检测数据集 OmniLabel43 和 D350 仅用于评估。为了解决数据稀缺问题,我们设计了一个自动化的标注流水线。我们专注于那些已经具有边界框标注的数据集,具体包括检测(第4.1节)和定位(第4.2节)数据集。
4.1 从检测数据集构建数据
步骤1:对象描述生成。如图5(左)所示,我们使用 Objects365 数据集44 作为检测数据源。通过限制实例的数量(不超过10个)和 IoU(< 0.5),我们为 Objects365 中的类别采样了10万张图像。由于检测数据集只提供简单的类别,我们将它们扩展为语言描述。一个有用的特点是,虽然当前的 MLLMs 很难根据描述找到所有实例,但它们在反向任务上表现出色,即根据给定的坐标生成描述。因此,我们选择 InternVL2-76B7, 8 来生成描述,因为它对坐标有很强的理解能力。对于一个图像-对象类别-坐标三元组 ⟨I,O,C⟩\langle I, O, C \rangle⟨I,O,C⟩,我们将其输入 InternVL2-76B 以生成一个对象描述。最终,我们获得了一个对象描述集合 SdescS_{\text{desc}}Sdesc。
步骤2:描述条件分解。对于 SdescS_{\text{desc}}Sdesc 中的一个描述和一个对象,直接使用 MLLM 来确定它们在语义上是否匹配很容易导致幻觉。受视觉-语言组合性15, 22, 58的启发,我们将一个描述分解为几个必须满足的条件,以降低后续判断的难度。如图5所示,描述"在泳池边缘附近游泳的海豚"可以被分解为三个条件。一个对象满足一个描述,当且仅当它满足所有条件。通过少样本上下文学习,LLM DeepSeek28 能够准确地将描述分解为条件。
步骤3:基于COT的条件判断。利用前一步得到的对象描述条件,我们为每个描述标注两张图像:源图像(作为正样本,对象存在)和一个随机采样的同类别的图像(很可能不匹配描述,作为负样本)。为了提高标注准确性,我们提出了一种基于思维链(COT)的条件判断方法。我们将对象列表和条件输入到 MLLM 中,要求它评估每个对象是否满足特定条件。MLLM 首先将对象在图像中的实际情况描述为理由,然后给出其关于对象是否满足条件的判断。然后,我们获得了一组对象描述及其匹配或不匹配的对象集。
4.2 从定位数据集构建数据
定位数据集的标注包括两个步骤:
步骤1:生成存在的对象。Flickr30K Entities41 为每张图像提供了五个标题,并为标题中的实体提供了坐标框标注,如图5(右)所示。通常,现有方法仅将此数据集用于短语定位任务,忽略了其丰富的语言上下文。我们将其转换为一个专注于单对象描述的基于语言的检测数据集。具体来说,我们将每张图像的标题集 C={c1,c2,...,c5}C=\{c_1, c_2, ..., c_5\}C={c1,c2,...,c5} 输入到 LLM DeepSeek28 中,并标记标题中的实体。我们手动设计示例以指导 LLM 将实体扩展为描述性短语,这些短语捕捉了对象的属性、状态、动作和关系的丰富信息。对于每张图像,我们生成大约5个现有对象的描述。

步骤2:生成不存在的对象。为了实现基于语言的检测,我们挖掘不存在的对象以创建在类别上一致但在语义上不一致的混淆缺席对象。这增强了模型区分相似对象的能力。我们指导 LLM 生成与标题中对象相似但有细微差别的对象。例如,在图5(右图)中,"喂猫的人"就是一个混淆的缺席对象。拒绝它需要模型理解主要目标是"人",并认识到"喂养"关系中的对象是"狗"而不是"猫"。我们还指导 LLM 生成带有否定语义(例如,without, that is not)的描述以增强理解。
最终,我们分别从检测和定位数据集中获得了20万和30万对描述-图像对,并将这个更可靠的对象检测数据集命名为 ROD。如表1所示,与其他数据集相比,ROD 具有丰富的表达类型和多样化的边界框数量。
5. 实验
在本节中,我们首先详细介绍 ROD-MLLM 的实现(第5.1节)。然后,我们从多个任务对其进行评估:基于语言的目标检测(第5.2节)、基本指代和定位(第5.3节)以及通用指代表达理解(第5.4节)。最后,我们进行了消融实验(第5.5节)并给出了定性分析(第5.6节)。
5.1 实现细节
模型设置。我们使用 CLIP ViT-L-336px42 作为视觉编码器,Vicuna-7B v1.59 作为 LLM。OWLv238 作为低层次定位器,在消融研究中也测试了 Grounding DINO-T32(第5.5节)。对于边界框提取,我们使用 {1,2,L}\{1,2,L\}{1,2,L}-gram 从用户输入中识别查询对象,其中 LLL 是用户查询中的单词长度。边界框经过 NMS(阈值为0.6)过滤,保留置信度分数高于0.12的最多100个框。
训练设置。ROD-MLLM 的训练包括两个阶段:预训练对齐和指令微调。在第一阶段,我们以1e-4的学习率和128的批量大小训练图像和区域投影器2个epoch,其他部分保持冻结。在第二阶段,我们为 LLM 引入 LoRA20 模块,使用相同的学习率和批量大小训练1个epoch。LoRA 参数设置为秩128和 alpha 256。
数据集。我们收集并统一了多个数据集到先前划定的任务格式中,重点关注全局和区域视觉特征对齐的预训练。对于全局对齐,我们使用 LAION-CCSBU45 中的55.8万对图像-标题对。对于区域对齐,我们利用 COCO27 和 Objects36544 进行单目标和密集检测训练,使用我们自动标注的数据 ROD 进行基于语言的目标检测。此外,我们使用 RefCOCO/+/g23, 36, 57、gRefCOCO29 和采样的 GRIT-20M40 进行 REC,使用 Flickr30K Entities41 进行接地描述。Visual Genome24 用于单目标和密集区域描述,以对齐区域锚点标记。在指令微调阶段,大部分数据来自预训练数据,并引入了 LLaVA Instruct 665K30 和 VCR59 用于全局和区域对话。
5.2 基于语言的检测评估
评估基准和指标。我们在两个基于语言的检测基准 OmniLabel43 和 D350 上进行零样本评估。对于 OmniLabel,我们评估描述的平均精度(AP-d),包括细粒度指标,如正描述的 AP-dP 和不同长度(≤3, 4~8, >8)描述的 AP-dS/M/L。对于 D3,AP 指标分为存在(Pres)和缺席(Abs,例如,没有水果的冰箱)描述,以及一个综合指标(Full)。
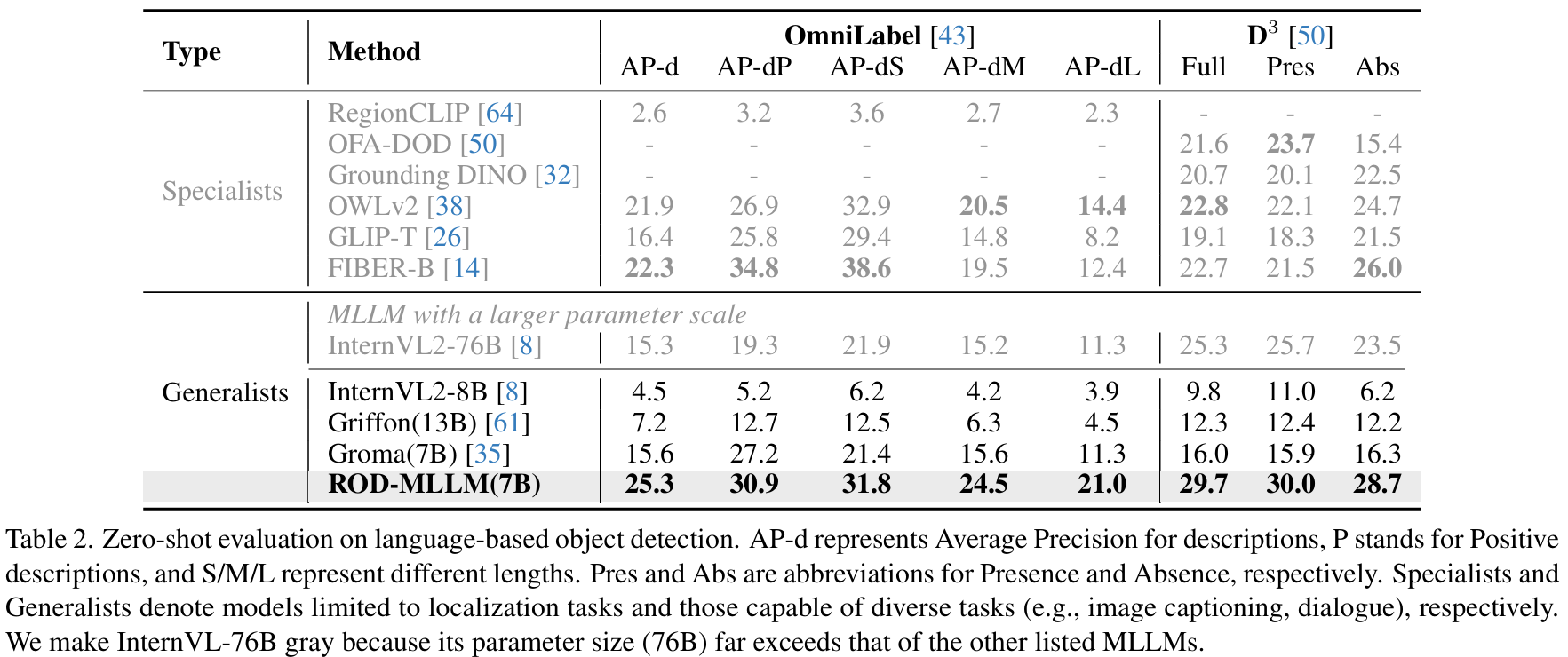
评估结果。如表2所示,我们的方法显著优于现有的 MLLMs。具体来说,在 OmniLabel 数据集上,我们在自由形式对象描述检测(AP-d)方面比所有类似规模的 MLLMs 取得了显著的提升(+9.7 AP)。我们的模型使用 OWLv238 作为低层次定位器,但实现了更高的 AP(21.9 到 25.3),证明了 LLM 中高层次理解的有效性。值得注意的是,尽管 FIBER-B14 在更大的对象检测数据集上进行了训练,并且在 AP-dS 和 AP-dP 上表现更好,但在涉及否定描述(AP-d)和长文本(AP-dM 和 AP-dL)的指标上,其表现远不如我们的 ROD-MLLM。这突显了 ROD-MLLM 在理解更复杂对象描述方面的优势。
在强调语言描述的 D350 基准上,我们相对于专用模型和通用 MLLMs 都取得了明显优势。与 MLLMs 相比,我们的 AP 提升了86%(16.0 到 29.7)。尽管我们使用 InternVL-76B 进行自动数据标注,但我们却在 D3 上取得了更好的性能,证明了将检测数据标注转换为区域描述和基于 COT 的条件判断的有效性。我们的方法在存在(Pres)和缺席(Abs)描述指标上也优于专用模型(29.7 vs. 22.8),展示了在未见描述上的强大泛化能力。
5.3 基本指代和定位评估
区域描述要求模型描述指令中提供的坐标框内的内容,例如"描述区域 \
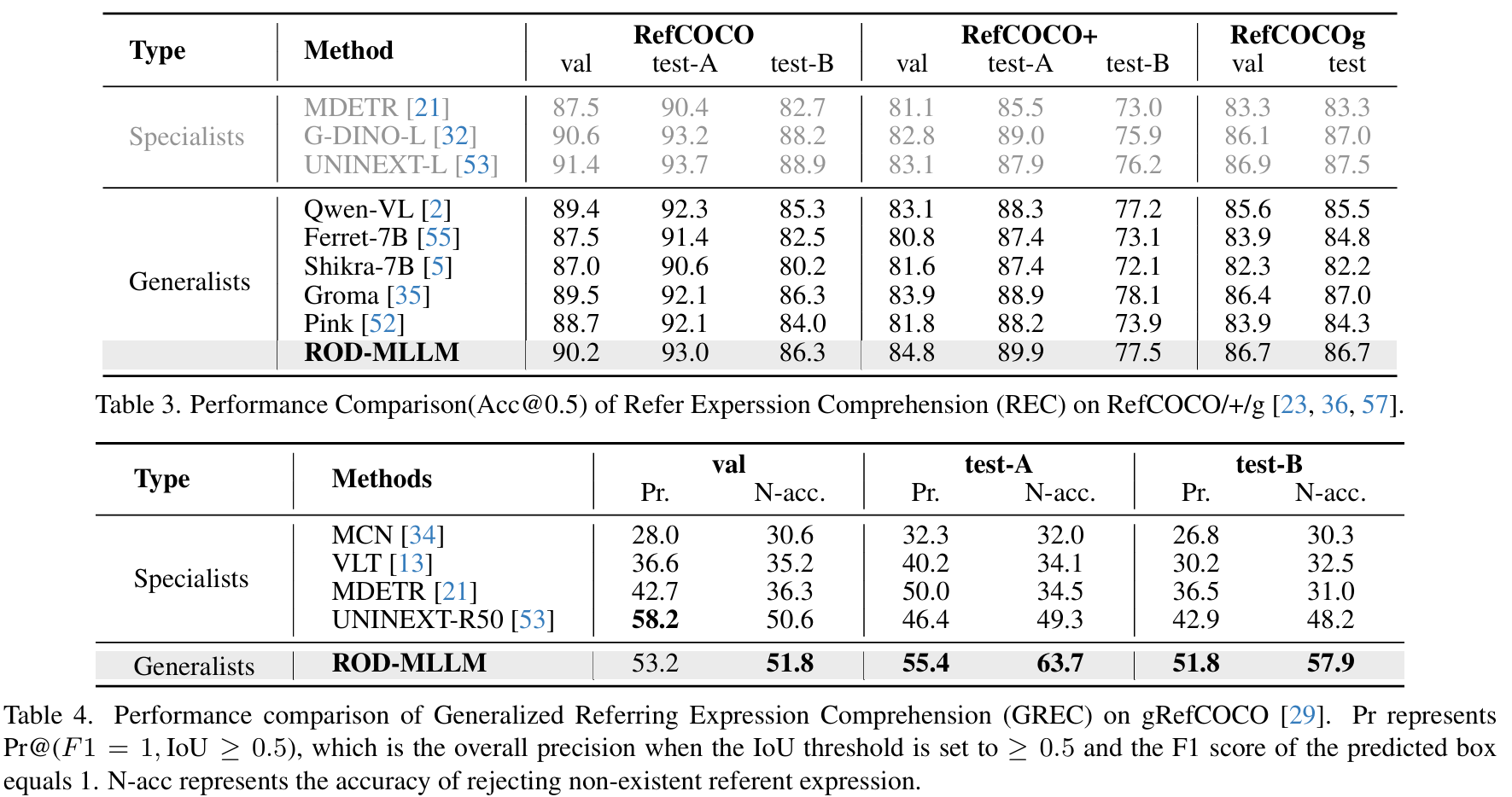
REC。与基于语言的目标检测相比,REC 专注于定位单个指代对象。我们在 RefCOCO/+g 数据集23, 36, 57上进行评估。值得注意的是,由于输出对象数量的不同,REC 与检测任务存在冲突61。为了缓解这一点,我们在指令中添加了"用区域回答"。如表3所示,ROD-MLLM 优于大多数其他 MLLMs,表明它在提高检测性能的同时保持了出色的 REC 能力。
5.4 通用 REC (GREC) 评估
通用 REC (GREC)19, 29 专注于多个或不存在目标的指代理解(例如,妈妈和孩子)。我们仅将此任务与专用模型进行比较,因为典型的 REC 用 MLLMs 只能定位单个对象。与基本 REC 不同,指标 Pr@(F1=1, IoU ≥ 0.5) 非常严格,它要求所有预测框和真实框 (GT) 之间的一对一匹配且 IoU ≥ 0.5 才算正确预测。N-acc 用于衡量拒绝不存在指代表达的准确性。
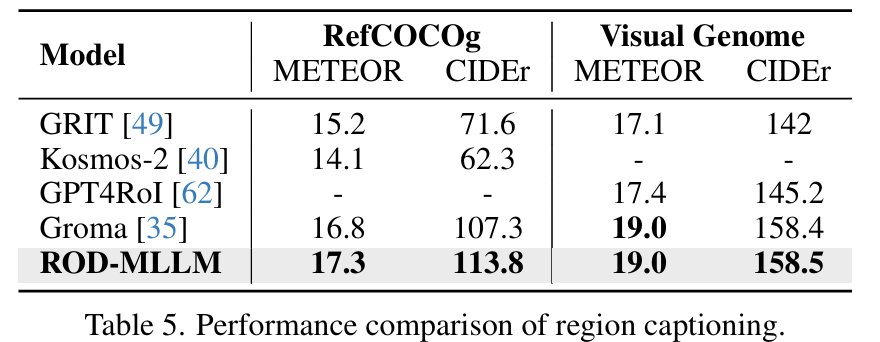
如表4所示,ROD-MLLM 在大多数指标上优于现有方法。在 testA 和 testB 分割上,ROD-MLLM 分别将 Pr 指标提高了10.8%和20.7%,并实现了更高的 N-acc,证明了其在拒绝不存在指代方面的有效性。从表3和表4可以看出,MDETR21 和 ROD-MLLM 在 GREC 和 REC 之间的性能差距更大(+25% vs. +3%),验证了 LLM 在理解更复杂表达式方面的优势。
5.5 消融研究
ROD 数据集。在表6的下半部分,我们考察了不同构建方式的 ROD 数据集的影响。与没有 ROD 数据集的 Base 模型相比,各种 ROD 数据集都提供了类似的显著改进(+4.6 AP 和 D3 Full 上的 +3.8),显示了我们自动化标注流水线的有效性。混合这些数据集进一步提升了收益(+4.9 AP),可能是因为缓解了单一标注数据源的过拟合问题。
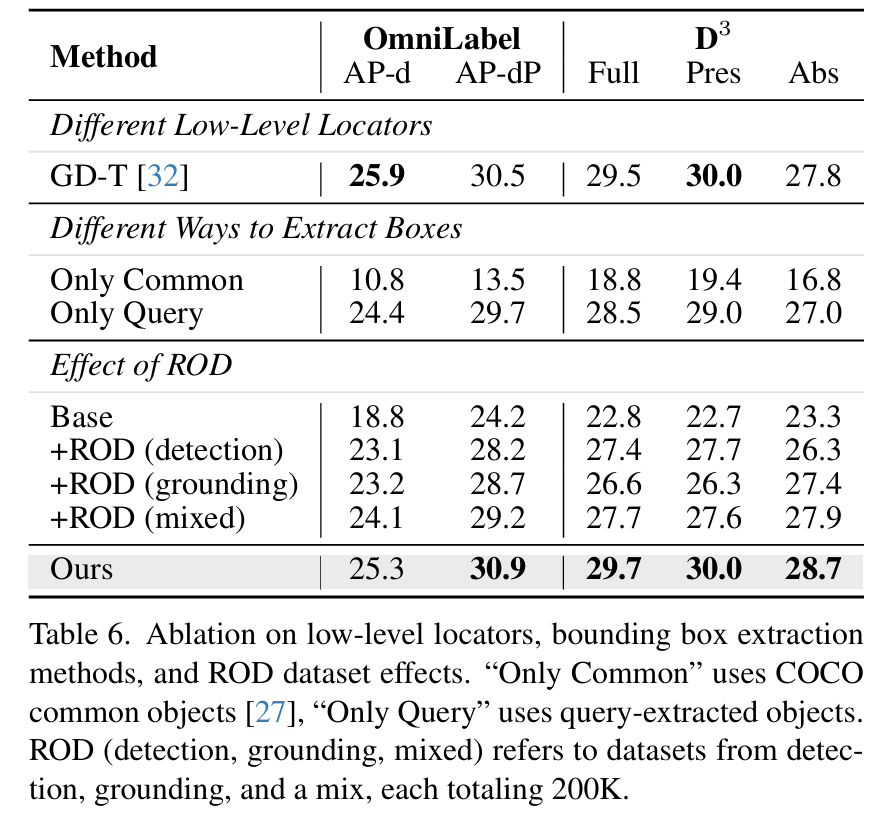
不同的低层次检测器。如表6的第一部分所示,将 OWLv238 替换为 Grounding DINO-T32 作为低层次定位器表明,最终指标的波动不超过1个百分点。这验证了 ROD-MLLM 不依赖于特定的 OVD。低层次定位器仅作为候选框提取器,内容理解由 LLM 处理。
提取框的不同方式。我们对各种框提取方法进行了实验。如表6所示,仅使用常见对象作为候选框会显著降低性能,因为固定的对象类别难以召回用户查询的所有相关对象。相比之下,基于查询的对象框保持了大部分性能,突显了我们基于查询的定位的有效性。
5.6 定性结果
我们在图6中展示了定性结果。像 Griffon61 和 Groma35 这样的 MLLMs 总是检测一个或所有对象,而不考虑具体的语义。我们使用的低层次定位器 OWLv238 在准确解释描述方面也存在困难,因为它只适用于类别短语定位。在图6 b) 中,我们的模型正确识别出热气球并未着陆,因此检测结果为 None。在案例 d) 中,涉及复杂的否定语义,我们的模型成功地在三人中过滤出了目标。这些例子表明,我们的方法相比现有方法具有更优越的理解和定位能力。

6. 结论
我们介绍了 ROD-MLLM,一种专为使用自由形式语言进行更可靠目标检测而设计的多模态大语言模型。它利用基于查询的低层次定位方法,准确提取相关对象以供高层次理解。为了解决数据集限制问题,我们设计了一个自动化的标注流水线并构建了 ROD 数据集,该数据集包含了丰富的对象描述和各种数量的相应边界框。ROD-MLLM 在基于语言的目标检测中的强大性能凸显了其在更广泛和更多样化的定位应用中的潜力。