文章目录
-
- 进程调度与环境变量:Linux内核的智慧
- 一、进程切换机制
-
- [1.1 什么是进程切换](#1.1 什么是进程切换)
- [1.2 CPU的上下文是什么](#1.2 CPU的上下文是什么)
- [1.3 上下文切换的过程](#1.3 上下文切换的过程)
- [1.4 时间片的概念](#1.4 时间片的概念)
- [1.5 上下文切换的代价](#1.5 上下文切换的代价)
- [二、Linux 2.6 O(1)调度算法](#二、Linux 2.6 O(1)调度算法)
-
- [2.1 为什么需要O(1)调度](#2.1 为什么需要O(1)调度)
- [2.2 优先级范围](#2.2 优先级范围)
-
- [2.2.1 实时优先级(0--99)](#2.2.1 实时优先级(0–99))
- [2.2.2 普通优先级(100--139)](#2.2.2 普通优先级(100–139))
- [2.3 O(1)调度的数据结构](#2.3 O(1)调度的数据结构)
-
- [2.3.1 runqueue:每个CPU独立的运行队列](#2.3.1 runqueue:每个CPU独立的运行队列)
- [2.3.2 prio_array:优先级数组](#2.3.2 prio_array:优先级数组)
- [2.4 O(1)查找算法详解](#2.4 O(1)查找算法详解)
- [2.5 active与expired队列](#2.5 active与expired队列)
-
- [2.5.1 active:当前可执行任务队列](#2.5.1 active:当前可执行任务队列)
- [2.5.2 expired:等待下轮调度的任务](#2.5.2 expired:等待下轮调度的任务)
- [2.6 O(1)调度完整流程](#2.6 O(1)调度完整流程)
- [2.7 O(1)调度器的优势](#2.7 O(1)调度器的优势)
- [2.8 可视化理解](#2.8 可视化理解)
- [2.9 问题总结](#2.9 问题总结)
- 三、环境变量深入理解
-
- [3.1 什么是环境变量](#3.1 什么是环境变量)
- [3.2 为什么需要环境变量](#3.2 为什么需要环境变量)
-
- [3.2.1 PATH环境变量](#3.2.1 PATH环境变量)
- [3.3 常见的环境变量](#3.3 常见的环境变量)
- [3.4 查看环境变量](#3.4 查看环境变量)
- [3.5 设置环境变量](#3.5 设置环境变量)
-
- [3.5.1 临时设置(当前终端有效)](#3.5.1 临时设置(当前终端有效))
- [3.5.2 永久设置](#3.5.2 永久设置)
- [3.6 环境变量的组织方式](#3.6 环境变量的组织方式)
- [3.7 在C程序中获取环境变量](#3.7 在C程序中获取环境变量)
-
- [3.7.1 方法1:main函数的第三个参数](#3.7.1 方法1:main函数的第三个参数)
- [3.7.2 方法2:全局变量environ](#3.7.2 方法2:全局变量environ)
- [3.7.3 方法3:getenv函数(推荐)](#3.7.3 方法3:getenv函数(推荐))
- [3.8 设置环境变量:putenv和setenv](#3.8 设置环境变量:putenv和setenv)
- [3.9 环境变量的继承性](#3.9 环境变量的继承性)
- [3.10 普通(本地)变量vs环境变量](#3.10 普通(本地)变量vs环境变量)
- [3.11 环境变量的实际应用](#3.11 环境变量的实际应用)
-
- [3.11.1 添加自己的程序到PATH](#3.11.1 添加自己的程序到PATH)
- [3.11.2 配置编译器路径](#3.11.2 配置编译器路径)
- [3.11.3 项目配置](#3.11.3 项目配置)
- [3.12 Shell内建命令与环境变量](#3.12 Shell内建命令与环境变量)
-
- [3.12.1 为什么有些命令必须是内建命令?](#3.12.1 为什么有些命令必须是内建命令?)
- [3.12.2 内建命令与外部命令的执行流程差异](#3.12.2 内建命令与外部命令的执行流程差异)
- [3.12.3 如何判断一个命令是否为内建命令?](#3.12.3 如何判断一个命令是否为内建命令?)
- 四、总结与展望
进程调度与环境变量:Linux内核的智慧
💬 欢迎讨论:这是Linux系统编程系列的第三篇文章,我们将揭开Linux进程调度的神秘面纱,理解O(1)调度算法的精妙设计,并深入学习环境变量机制。如果有任何疑问,欢迎在评论区交流!
👍 点赞、收藏与分享:如果这篇文章对你有帮助,请点赞、收藏并分享给更多的朋友!
🚀 承上启下:建议先学习前两篇文章,理解进程的基本概念和状态转换,这样学习调度算法会更轻松。
一、进程切换机制
在上一篇文章中,我们提到了并发(Concurrent)的概念:单核CPU通过快速切换进程来实现多任务。那么,进程切换到底是如何实现的呢?
1.1 什么是进程切换
进程切换,也叫上下文切换(Context Switch),是指CPU从执行一个进程切换到执行另一个进程的过程。
想象这样的场景:
你正在做数学作业(进程A),突然老师让你去帮忙搬书(进程B)。你需要:
- 记住数学题做到哪一步了(保存进程A的状态)
- 合上数学书(暂停进程A)
- 去搬书(执行进程B)
- 搬完书回来(进程B结束)
- 翻开数学书,继续刚才的进度(恢复进程A)
这个过程就类似于进程切换。
1.2 CPU的上下文是什么
CPU的上下文主要包括:
1. 寄存器的值
- 通用寄存器(EAX、EBX、ECX等)
- 程序计数器(PC,存储下一条指令的地址)
- 栈指针(SP,指向当前栈顶)
- 状态寄存器(标志位)
2. 进程的内核栈
3. 内存管理信息
- 页表指针
- 虚拟地址空间信息
这些信息构成了进程运行的"现场"。
1.3 上下文切换的过程
让我们详细看看上下文切换的步骤:
步骤1:保存当前进程的上下文
cpp
// 伪代码示意
保存当前进程的寄存器到PCB中 {
PCB->eax = CPU.eax;
PCB->ebx = CPU.ebx;
PCB->eip = CPU.eip; // 程序计数器
PCB->esp = CPU.esp; // 栈指针
// ... 其他寄存器
}步骤2:选择下一个要运行的进程
cpp
// 从就绪队列中选择优先级最高的进程
next_process = 调度算法选择();步骤3:恢复新进程的上下文
cpp
// 从PCB中恢复寄存器的值
CPU.eax = next_process->PCB->eax;
CPU.ebx = next_process->PCB->ebx;
CPU.eip = next_process->PCB->eip;
CPU.esp = next_process->PCB->esp;
// ... 其他寄存器步骤4:跳转到新进程继续执行
cpp
// CPU从新的程序计数器位置开始执行
跳转到 CPU.eip 指向的地址;
如上,在 Linux 早期版本( 0.11)的源码中,进程的上下文信息会被保存在 task_struct 内的 tss(Task State Segment)结构中。tss 由硬件定义,用于保存 CPU 各通用寄存器、段寄存器、堆栈指针、指令指针等状态,用来支持 Intel 早期的硬件任务切换机制。
需要注意的是,随着 Linux 内核的演进,现代 Linux 已不再依赖硬件的 TSS进行上下文切换(除了必要的特权级堆栈切换等用途)。这是因为:
- 硬件任务切换机制过于复杂且在性能上无法满足现代系统需求;
- 软件完全控制的上下文切换具有更高的灵活性和效率;
- 当代处理器结构更复杂,进程/线程需要保存的状态远超最初的 TSS 设计能力。
因此如今的 TSS 每 CPU 只有一份,仅用于:
- 特权级切换(用户态 → 内核态)
- 保存 RSP0(内核栈指针);
而所有进程上下文真正的保存位置:task_struct → thread_struct。虽然TSS 的位置和作用发生了变化,但这并不影响我们理解其本质:上下文切换的本质依然是保存当前 CPU 寄存器到 PCB,再从另一个 PCB 恢复寄存器。
1.4 时间片的概念
如果进程一直占用CPU不释放怎么办?这就需要时间片(Time Slice)机制。
时间片是分配给每个进程的CPU时间,通常是几毫秒到几十毫秒。当进程的时间片用完后,操作系统会:
- 触发时钟中断
- 强制进行上下文切换
- 让其他进程获得CPU
在Linux中,可以通过/proc/sys/kernel/sched_rr_timeslice_ms查看时间片长度:
bash
cat /proc/sys/kernel/sched_rr_timeslice_ms
# 输出:100(表示100毫秒)1.5 上下文切换的代价
上下文切换并不是免费的,它有一定的开销:
1. 直接开销
- 保存和恢复寄存器需要时间
- 切换内存映射(页表切换)
- 内核调度算法的执行时间
2. 间接开销
- CPU缓存失效(Cache Miss)
- TLB(页表缓存)失效
因此,过于频繁的上下文切换会降低系统性能。这也是为什么调度算法的效率如此重要。
二、Linux 2.6 O(1)调度算法
现在我们来学习Linux 2.6内核中的经典调度算法:O(1)调度器。这个算法的设计非常巧妙,值得深入学习。
2.1 为什么需要O(1)调度
在讲算法之前,我们先思考一个问题:如何快速找到优先级最高的进程?
假设系统中有1000个就绪进程,最朴素的做法是:
cpp
// 遍历所有进程,找到优先级最高的
for(int i = 0; i < 1000; i++) {
if(process[i].priority > max_priority) {
max_priority = process[i].priority;
best_process = &process[i];
}
}这种方法的时间复杂度是O(n),进程越多,选择越慢。
如果每次调度都要遍历所有进程,在进程数达到几千甚至上万时,调度本身就会成为系统的瓶颈。
O(1)调度算法的核心思想就是:无论有多少个进程,都能在常数时间内找到下一个要运行的进程。
2.2 优先级范围
在进入 O(1) 调度算法之前,我们先明确一个基础事实:Linux 的调度优先级分为"实时任务"和"普通任务"两大类,它们属于完全不同的调度体系。
现代通用计算机多采用分时系统(Time-Sharing) ,调度器通过快速切换 CPU 让多个任务"看起来同时执行"。而在车载系统、工业控制、医疗设备等对时间敏感的场景,系统必须具备实时性(Real-Time),因此 Linux 扩展了实时调度策略,使其在嵌入式与车载领域也能被广泛使用。
Linux 的优先级区间如下:
2.2.1 实时优先级(0--99)
- 数字越小优先级越高
- 使用实时调度策略(SCHED_FIFO / SCHED_RR)
- 绝对高于普通任务,普通任务永远无法抢占实时任务
- 这不是本文重点,在此就不展开了
2.2.2 普通优先级(100--139)
普通任务使用 CFS 或(历史上)O(1) 调度器管理。优先级与 nice 值的关系如下:
bash
priority = 120 + nice- nice = -20 → priority = 100(最高普通优先级)
- nice = 0 → priority = 120(默认)
- nice = 19 → priority = 139(最低)
注意:普通任务之间的优先级不是严格抢占关系。 即使 priority=120,也可能在某些情况下抢占 priority=100(因为 CFS 根据 vruntime 选择任务,而不是单纯优先级数字)。
2.3 O(1)调度的数据结构
Linux 2.6 ~ 2.6.23 使用的是 O(1) 调度器,它的核心设计是:无论系统中有多少进程,都能在固定时间内找到最高优先级的可运行任务。
O(1) 调度器的数据结构是理解其算法的关键。
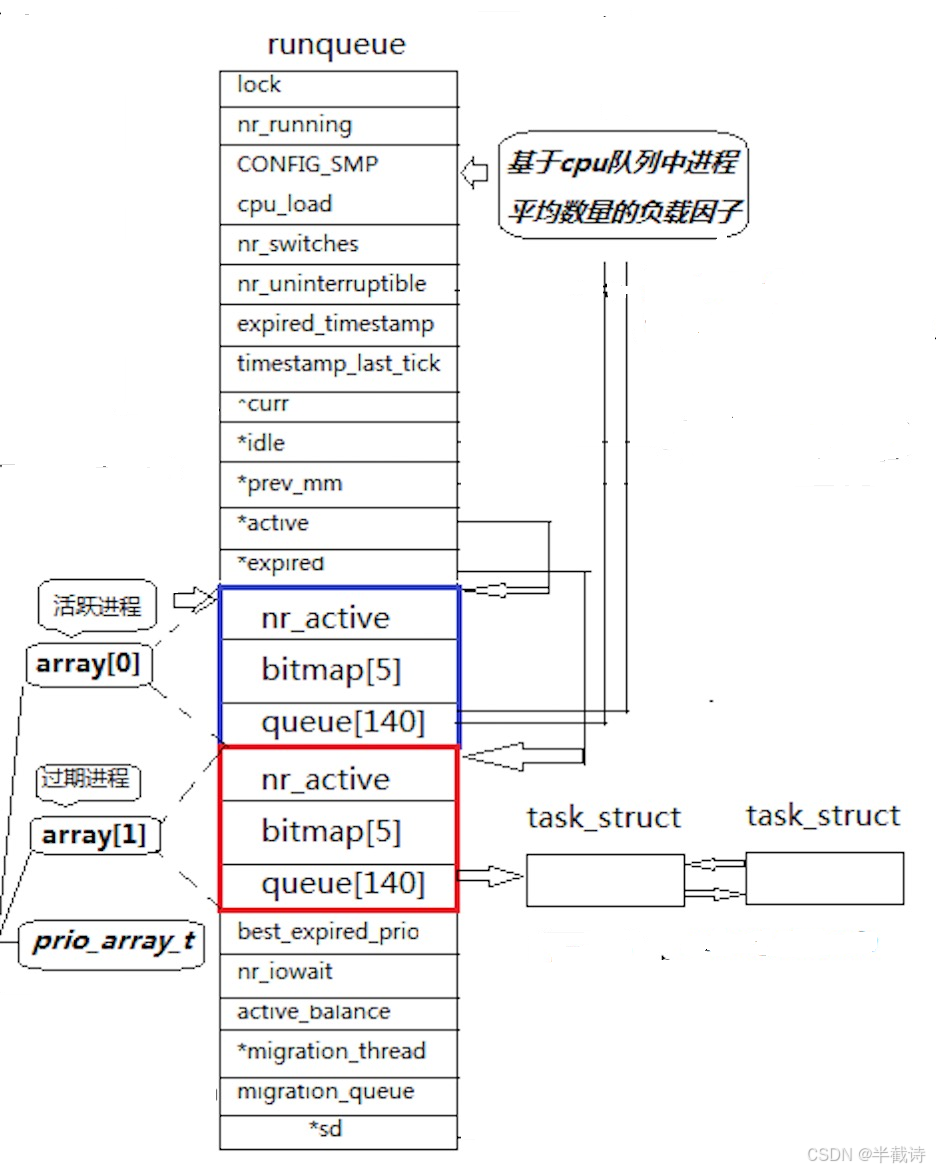
2.3.1 runqueue:每个CPU独立的运行队列
在多核 CPU 中,每个 CPU 都有一个独立的运行队列(runqueue),以减少锁竞争。
cpp
struct runqueue {
unsigned int nr_running; // 正在运行(就绪)的进程数
struct prio_array *active; // 活动队列
struct prio_array *expired; // 过期队列
struct prio_array arrays[2]; // 两个 prio_array 的实际存储
// ... 其他字段
};runqueue 内部最重要的是两个队列:active 和 expired。
2.3.2 prio_array:优先级数组
是 O(1) 调度器的核心结构:
cpp
struct prio_array {
unsigned int nr_active; // 当前队列中的进程数
unsigned long bitmap[5]; // 位图,标记 140 个优先级队列哪些非空
struct list_head queue[140]; // 优先级为 0~139 的任务链表
};1)queue140:优先级队列数组
每个下标对应一个优先级:
- queue0 ------ 优先级 0
- queue100 ------ 优先级 100
- queue139 ------ 优先级 139
同优先级的任务按照 FIFO 排列。
2)bitmap5:快速定位非空队列
140 个队列如果逐个遍历会很慢,于是 O(1) 调度器使用了位图:
- 5 个 32 位整数 → 共 160 bit,可覆盖 140 个优先级
- 对应关系如下:
bash
bitmap[0] → 0~31
bitmap[1] → 32~63
bitmap[2] → 64~95
bitmap[3] → 96~127
bitmap[4] → 128~159(只用到 139)某个优先级队列非空 → 对应 bit = 1。
通过 CPU 指令(如 BSF/ffs)即可 O(1) 找到第一个非空队列的优先级。

2.4 O(1)查找算法详解
调度器的核心目标:在 O(1) 时间找到当前最高优先级可运行任务。
伪代码如下:
cpp
int find_first_bit(unsigned long *bitmap) {
for(int i = 0; i < 5; i++) {
if(bitmap[i] != 0) {
int bit = ffs(bitmap[i]); // 找到最低位的1
return i * 32 + bit;
}
}
return -1;
}调度流程:
cpp
int idx = find_first_bit(active->bitmap);
struct task_struct *next =
list_entry(active->queue[idx].next, struct task_struct, run_list);为什么是 O(1)?
- bitmap 长度固定(5 个 unsigned long) → 常数时间
- ffs 指令本身就是 O(1)
- 从链表头取第一个任务 → O(1)
因此整体查找时间与系统进程数量无关。
2.5 active与expired队列
O(1) 调度器使用双队列机制实现时间片管理。
2.5.1 active:当前可执行任务队列
所有还有剩余时间片的任务放在 active 中。
当某任务时间片用完:
- 重新计算时间片
- 移入 expired 队列
2.5.2 expired:等待下轮调度的任务
当 active 队列空了:
cpp
swap(active, expired);只交换两个指针,完全 O(1)。
2.6 O(1)调度完整流程
bash
1. 时钟中断
2. 当前任务时间片减 1
3. 如果时间片用完 → 放入 expired
4. 调用 schedule()
5. 从 bitmap 找到最高优先级队列(O(1))
6. 从该队列取第一个任务(FIFO)
7. 上下文切换
8. 新任务运行2.7 O(1)调度器的优势
1)查找速度极快 O(1)
不随任务数量增长。
2)支持多优先级公平轮转
同优先级的任务按 FIFO 轮流执行。
3)多核扩展性好
每个 CPU 一个 runqueue,减少锁竞争。
4)结构紧凑、缓存友好
数组 + 位图,访问局部性好。
2.8 可视化理解
bash
runqueue (CPU0)
┌──────────────────────────────────────────┐
│ active ───┐ expired ───┐ │
└───────────┼──────────────────────┼────────┘
▼ ▼
┌────────────────┐ ┌────────────────┐
│ prio_array │ │ prio_array │
│ bitmap[5] │ │ bitmap[5] │
│ queue[140] │ │ queue[140] │
│ ... │ │ ... │
└────────────────┘ └────────────────┘任务用完时间片后进入 expired,active 空后两者 O(1) 交换。
2.9 问题总结
1)为什么叫 O(1) 调度?
因为查找最高优先级任务的时间是固定的、常数级,与任务数量无关。
2)为什么有 active/expired 两个队列?为了 O(1) 重新分配时间片,不需要遍历所有任务。
3)O(1) 调度器为什么被 CFS 替代?优先级固定、可能造成饥饿、不够公平、不适应现代负载。
4)bitmap 为什么高效?通过 ffs/BSF 指令可以一条指令找到最高优先级的非空队列。
三、环境变量深入理解
学完调度算法,我们来学习另一个重要概念:环境变量。
3.1 什么是环境变量
环境变量是操作系统用来存储系统配置信息的一种机制。它们是键值对,存储在进程的内存空间中。
可以把环境变量理解为进程的"配置文件":
- 键(Key):变量名,如
PATH、HOME - 值(Value):变量的内容,如
/usr/bin:/bin
3.2 为什么需要环境变量
让我们通过一个实际例子理解环境变量的作用。
3.2.1 PATH环境变量
当你在终端输入命令ls时,系统如何知道ls程序在哪里?
bash
$ ls
# 系统需要找到 /bin/ls 这个文件系统不可能在整个硬盘中搜索ls,那样太慢了。它使用PATH环境变量来指定搜索路径:
bash
$ echo $PATH
/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin当你输入ls时,系统会:
- 在
/usr/local/bin中查找ls - 没找到,在
/usr/bin中查找 - 没找到,在
/bin中查找,找到了! - 执行
/bin/ls
这样就避免了全盘搜索,大大提高了效率。
3.3 常见的环境变量
1. PATH:命令搜索路径
bash
$ echo $PATH
/usr/local/bin:/usr/bin:/bin2. HOME:用户主目录
bash
$ echo $HOME
/home/username3. SHELL:当前使用的Shell
bash
$ echo $SHELL
/bin/bash4. USER:当前用户名
bash
$ echo $USER
username5. PWD:当前工作目录
bash
$ echo $PWD
/home/username/project3.4 查看环境变量
查看单个环境变量:
bash
echo $变量名查看所有环境变量:
bash
env输出示例:
bash
HOME=/home/user
PATH=/usr/local/bin:/usr/bin:/bin
SHELL=/bin/bash
USER=user
PWD=/home/user
...3.5 设置环境变量
3.5.1 临时设置(当前终端有效)
bash
# 设置变量(注意:这只是普通变量,不是环境变量)
MY_VAR="hello"
# 导出为环境变量
export MY_VAR
# 或者一步完成
export MY_VAR="hello"3.5.2 永久设置
修改配置文件:
针对当前用户:
bash
# 编辑 ~/.bashrc 或 ~/.bash_profile
vim ~/.bashrc
# 添加
export MY_VAR="hello"
# 使配置生效
source ~/.bashrc针对所有用户:
bash
# 编辑 /etc/profile (需要root权限)
sudo vim /etc/profile
# 添加
export MY_VAR="hello"3.6 环境变量的组织方式
环境变量在内存中是如何组织的呢?
每个进程都有一个环境变量表(environment table),它是一个字符指针数组,每个指针指向一个环境字符串。

bash
环境表(char **environ)
┌────┐
│ ●──┼──→ "PATH=/usr/bin:/bin"
├────┤
│ ●──┼──→ "HOME=/home/user"
├────┤
│ ●──┼──→ "SHELL=/bin/bash"
├────┤
│ ●──┼──→ "USER=user"
├────┤
│NULL│ (结束标记)
└────┘3.7 在C程序中获取环境变量
有三种方式可以在C程序中访问环境变量。
3.7.1 方法1:main函数的第三个参数
cpp
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{
printf("所有环境变量:\n");
for(int i = 0; env[i] != NULL; i++) {
printf("%s\n", env[i]);
}
return 0;
}3.7.2 方法2:全局变量environ
cpp
#include <stdio.h>
int main(int argc, char *argv[])
{
extern char **environ; // 声明全局变量
printf("所有环境变量:\n");
for(int i = 0; environ[i] != NULL; i++) {
printf("%s\n", environ[i]);
}
return 0;
}3.7.3 方法3:getenv函数(推荐)
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
char *path = getenv("PATH");
if(path) {
printf("PATH = %s\n", path);
}
char *home = getenv("HOME");
if(home) {
printf("HOME = %s\n", home);
}
return 0;
}3.8 设置环境变量:putenv和setenv
putenv:
cpp
#include <stdlib.h>
int main()
{
// 注意:字符串必须是静态的或动态分配的
putenv("MY_VAR=hello");
printf("%s\n", getenv("MY_VAR")); // 输出:hello
return 0;
}setenv:
cpp
#include <stdlib.h>
int main()
{
// 更安全的方式
setenv("MY_VAR", "hello", 1); // 1表示覆盖已存在的变量
printf("%s\n", getenv("MY_VAR")); // 输出:hello
return 0;
}3.9 环境变量的继承性
环境变量有一个重要特性:子进程会继承父进程的环境变量。
让我们通过实验验证:
步骤1:设置一个环境变量
bash
export MY_TEST="parent_value"步骤2:编写测试程序
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
char *val = getenv("MY_TEST");
if(val) {
printf("MY_TEST = %s\n", val);
} else {
printf("MY_TEST 不存在\n");
}
return 0;
}步骤3:运行程序
bash
gcc test.c -o test
./test
# 输出:MY_TEST = parent_value子进程(test程序)成功获取到了父进程(shell)的环境变量!
3.10 普通(本地)变量vs环境变量
这是一个容易混淆的点。让我们做个实验:
bash
# 设置普通变量(没有export)
MY_VAR="hello"
# 运行测试程序
./test # 在test程序中无法获取MY_VAR
# 导出为环境变量
export MY_VAR="hello"
# 再次运行
./test # 现在可以获取到MY_VAR了区别:
- 普通(本地)变量:只在当前shell中有效,不会传递给子进程
- 环境变量:会传递给子进程
3.11 环境变量的实际应用
3.11.1 添加自己的程序到PATH
假设你写了一个程序myapp,想在任何目录下都能直接运行:
bash
# 方法1:将程序移到PATH目录
sudo cp myapp /usr/local/bin/
# 方法2:将程序目录添加到PATH
export PATH=$PATH:/home/user/myapps3.11.2 配置编译器路径
bash
# GCC编译时查找头文件的路径
export C_INCLUDE_PATH=/usr/local/include
# 链接库的路径
export LD_LIBRARY_PATH=/usr/local/lib3.11.3 项目配置
很多项目使用环境变量进行配置:
bash
# 数据库连接
export DB_HOST="localhost"
export DB_PORT="3306"
export DB_USER="root"
# 应用程序读取这些配置
char *host = getenv("DB_HOST");3.12 Shell内建命令与环境变量
在学习环境变量时,我们会注意到某些命令(如 cd、export、alias)并没有对应的可执行文件:
这些命令被称为 Shell 内建命令(builtin command)。它们与环境变量有着密切关系,也是理解 Shell 行为的重要部分。
3.12.1 为什么有些命令必须是内建命令?
因为外部程序无法修改当前 Shell 进程的状态。
例如:
① cd 必须修改当前 Shell 的工作目录
如果 cd 是一个外部程序:
- 外部程序运行在子进程中
- 子进程修改自己的 cwd
- 父进程(bash)不会变化
所以 cd 只能由 bash 自己执行,也就是内建命令。
② export 必须修改当前 Shell 的环境变量表
环境变量属于 bash 进程自己的用户态内存:
bash
bash 进程:
environ = ["PATH=...", "HOME=...", ...]如果 export 是外部程序:
- 外部程序是子进程,无法修改父进程的环境变量表
- 修改也不会影响 bash 自己
因此:
只有内建命令才能修改 bash 的环境变量。
③ alias、jobs、exit 等都依赖 shell 自身状态
例如:
alias修改的是 bash 的解析规则jobs查看的是 bash 的作业控制表exit需要终止的是 bash 自己
这些都无法通过独立程序实现。
3.12.2 内建命令与外部命令的执行流程差异
当你输入命令时:
bash
bash 解析命令
|
|-- 内建命令:直接在 bash 进程内部执行
|
|-- 外部命令:fork → execve 加载程序 → 子进程运行因此:
- 内建命令修改的是 bash 当前进程的状态
- 外部命令运行在 子进程 中,对 bash 没有影响
这就是为什么:
export MY_VAR=hello会让后续程序看到 MY_VAR- 但在外部程序中
setenv()或修改变量,不会影响 bash
3.12.3 如何判断一个命令是否为内建命令?
可以使用 type:
bash
type cd
cd is a shell builtin
type ls
ls is /bin/ls💡 总结一句话:
内建命令用于修改 shell 自身的状态(目录、环境、别名、作业控制),而外部命令运行在子进程中,无法影响父进程的环境。
四、总结与展望
通过本篇文章,我们深入学习了:
- 进程切换机制:理解了上下文切换的本质是保存和恢复CPU寄存器,以及时间片的作用
- Linux 2.6 O(1)调度算法:掌握了runqueue、prio_array的精巧设计,理解了如何用bitmap实现常数时间查找
- 活动队列与过期队列:学会了双队列机制如何保证公平性和高效性
- 环境变量机制:理解了环境变量的组织方式、继承性和实际应用
在下一篇文章中,我们将深入学习程序地址空间和虚拟内存,这是理解进程隔离和内存管理的关键知识。我们会回答:为什么父子进程的变量地址相同但内容不同?虚拟地址是如何映射到物理地址的?
💡 思考题:
- 为什么O(1)调度器要使用两个队列(active和expired),而不是一个队列?
- 如果系统中有10000个进程,bitmap需要多大的空间?
- 子进程能修改父进程的环境变量吗?为什么?
- 如果你要开发一个需要高优先级运行的程序,应该如何设置nice值?
以上就是关于Linux进程调度与环境变量的内容,下一篇我们将揭开虚拟内存的神秘面纱!