
文章目录
- 摘要
- 一、引言
- 二、4D场景重建。
- 三、预备知识
- [四、VGGT 中的经验观察](#四、VGGT 中的经验观察)
- [五、基于Gram Similarity 的动态特征提取](#五、基于Gram Similarity 的动态特征提取)
- 六、基于投影梯度的mask提炼
- 七、基于早期mask的4D重建
- 实验
标题:《VGGT4D: Mining Motion Cues in Visual Geometry Transformers for 4D Scene Reconstruction》
项目:https://3dagentworld.github. io/vggt4d/
来源:香港科技大学(广州)2Horizon Robotics
摘要
动态场景4D重建的挑战性:它需要将动态物体与静态背景进行稳健的分离。虽然像 VGGT 这样的3D基础模型能提供精确的3D几何结构,但当移动物体占主导时,其性能会显著下降。现有的4D方法通常依赖外部先验知识、复杂的后优化过程或需要在4D数据集上进行微调。VGGT4D无需训练,其扩展了3D基础模型 VGGT 以实现稳健的4D场景重建。方法受到一个关键启发: VGGT 的全局注意力层已经隐式地编码了丰富的、逐层的动态线索。为了获得能够分离静态和动态元素的mask,通过格拉姆相似性挖掘并放大全局动态线索,并在时间窗口内聚合 。为了进一步锐化mask边界,引入了一种由投影梯度驱动的微调策略。随后将这些精确的mask整合到 VGGT 的早期推理中,有效减轻了姿态估计和几何重建中的运动干扰。在六个数据集上,VGGT4D在动态物体分割、相机姿态估计和密集重建方面表现优异。此外,它还支持超过500帧序列的单次推理。
一、引言
基于视觉输入重建动态物体的4D场景一直是个难题。这是因为移动物体不仅会降低姿态估计精度,还会干扰背景几何建模,且其运动常与相机运动相互交织,导致3D场景呈现中出现严重伪影。因此,如何建模动态特性对于实现稳健的4D重建至关重要。
传统的SfM 和MVS 方法依赖于多视图刚性和光度恒定性。动态区域违反这些假设,导致对应关系和束调整下降,经常引发失败。像 VGGT 32 这样的3D基础模型能够快速、准确地估计3D几何和相机姿态,但它们主要是在静态场景假设下训练和推断的,缺乏明确的机制来解析移动物体。当动态因素占主导时,这种动态与静态的耦合会导致重建脆弱和姿态漂移。
尽管现有方法在4D重建领域已取得进展,但仍存在两大局限:(1) 需要进行大量迭代微调,导致运行时间和内存开销显著增加 18:Robust consistent video depth estimation,40:Uni4d:Unifying visual foundation models for 4d modeling from a single video,44:Structure and motion from casual videos;(2) 依赖外部模块(如光流41、深度21、语义分割13),这不仅增加了集成难度,还使性能对模块质量及领域偏移敏感。近期研究探索了高效的前馈架构16,33,36,37,41,42,但大多数仍需在高质量动态数据集上进行大规模训练或微调,而这类数据集的整理成本高昂且规模有限。
为解决上述问题,本文旨在探究:是否可在无需额外训练的情况下,为3D基础模型赋予4D重建能力?
实现这一目标的初步步骤是Easi3R 6,它是DUSt3R 34的一个无需训练的扩展,通过分析解码器注意力的空间和时间统计特性来分割动态mask。然而,Easi3R基于成对交叉注意力架构,只能捕捉局部特征的交互。这种设计导致时间范围较短,且生成的mask在不同帧之间不一致,在动态-静态界面处产生边界错误,导致深度漂移和重建点云中的漂浮伪影。此外,其核心假设即违反极线几何的token会受到低关注度,这一假设无法推广到 VGGT ,因为后者通过全局注意力聚合多个视图的信号。
VGGT4D,将预训练的 VGGT 模型扩展到4D场景重建,而无需进一步重新训练。灵感源于原始 VGGT 中层间趋势的一致性实证:浅层Transfomer层捕捉显著的运动信息,这些信息在深层中逐渐减弱。
与Easi3R的成对注意力统计不同,我们的多帧、layer感知注意力挖掘推广到 VGGT ,并产生全局一致、稳健的动态mask。
具体的,首先通过聚合选定浅层、中层和深层的token gram相似性统计量,并结合时间窗口,逐帧生成动态mask,形成动态显著性信号。随后采用投影梯度感知策略对信号进行优化,生成清晰且稳定的掩码 ,可明确区分动态与静态区域。在推理阶段,我们仅在浅层抑制动态图像token,有效减少运动干扰,从而实现不受干扰的姿态估计和4D重建。
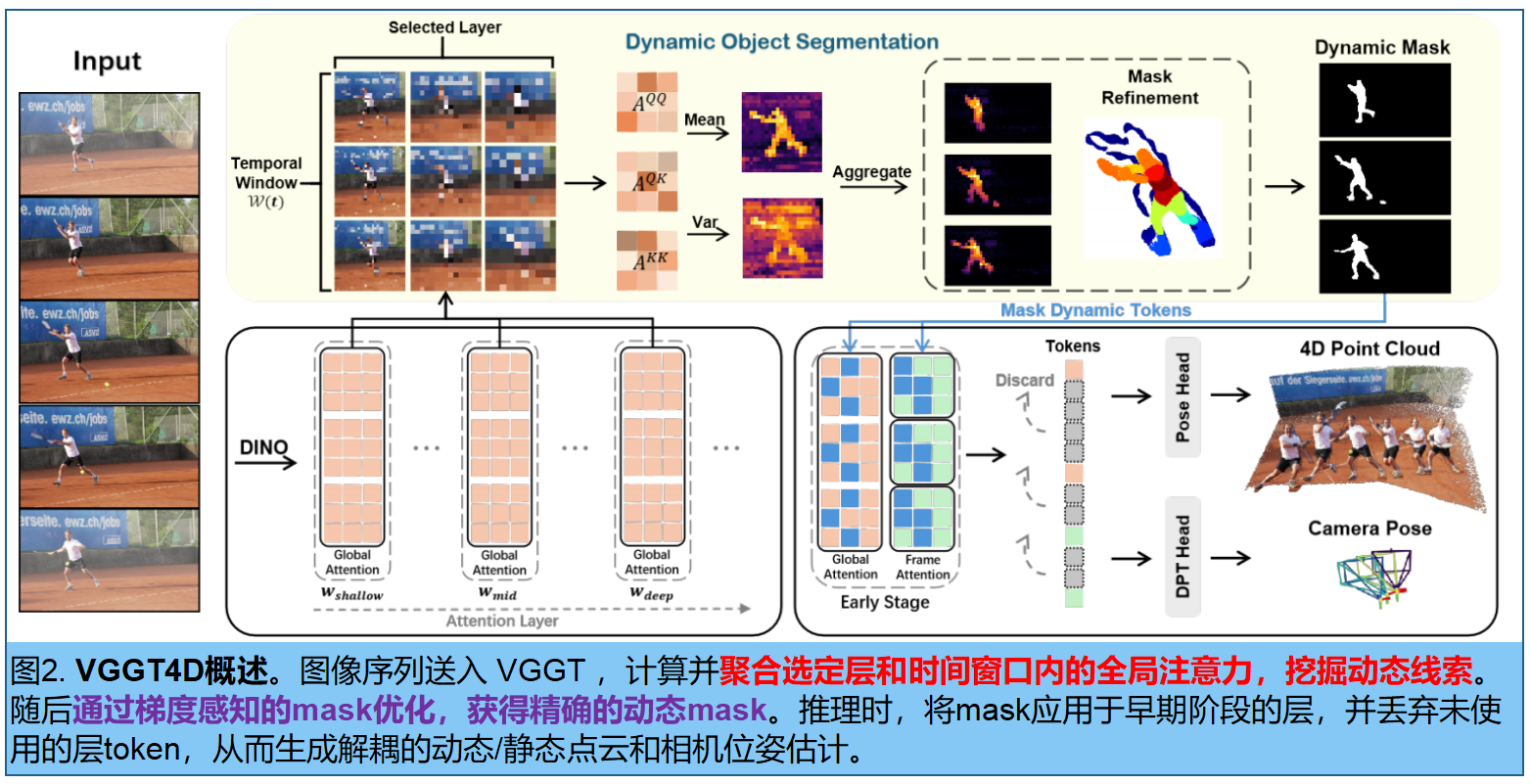
针对六个动态数据集的实验表明,该方法在动态物体分割、相机姿态估计及密集点云重建方面表现优异,且能单次处理超过500帧的序列数据,主要贡献总结如下:
-
- 无需额外训练的 VGGT 4D感知。挖掘 VGGT 全局注意力中潜在的运动线索,为3D基础模型赋予4D感知能力,无需额外训练。
-
- 一致的动态-静态解耦流程。方法聚合 VGGT 注意力中的Gram相似性统计,并通过梯度感知精炼来增强显著性信号,生成稳定4D重建的mask。
-
- 优越性能与泛化能力。我们的方法在动态分割、姿态估计和4D重建的六个动态数据集上均优于现有模型。同时,该方法还能在单次处理中成功处理长序列(500+帧)。
二、4D场景重建。
早期的方法通常依赖于RGB-D传感器,这限制了其在现实场景中的应用15,24。大量方法联合估计深度、姿态和残差运动(通常在静止区域使用运动mask),包括自监督变体12,14,23,39以及测试时或基于优化的方案,如CasualSAM44和Robust- CVD 18。更近期的流程,例如MegaSaM 21,通过利用强大的单目深度先验,在动态视频上实现了稳健的姿态和重建,而Uni4D 40则通过多阶段束调整整合多个视觉基础模型,以获得高质量的4D结果。这些方法虽然有效,但依赖于强大的先验和繁重的测试时优化,这限制了可扩展性。最近的工作通过学习到的先验或注意力适应来减少或替代测试时优化:MonST3R 41在动态数据上微调并利用光流;DAS3R 37增强DPT头部以实现前馈运动mask;CUT3R 33在混合静态/动态数据上微调MASt3R以实现快速重建;Easi3R6在推理过程中适应注意力以在DUSt3R上进行无训练的4D重建。尽管取得了进展,大多数流程仍需要微调或第二阶段后处理,且无训练变体往往与特定骨干网络紧密耦合,在长序列上可能变得不稳定。
三、预备知识
DUSt3R 。DUSt3R 34 是一个预训练的Transformer模型,专为无姿态的密集3D重建设计。它仅处理两张输入图像,并通过成对交叉注意力计算它们之间的像素级密集对应关系。
Easi3R。Easi3R 6 将DUSt3R扩展到4D重建任务。它利用了DUSt3R对极线不一致像素分配低注意力的经验观察,使Easi3R能够从注意力图中无监督地推导出动态区域mask。
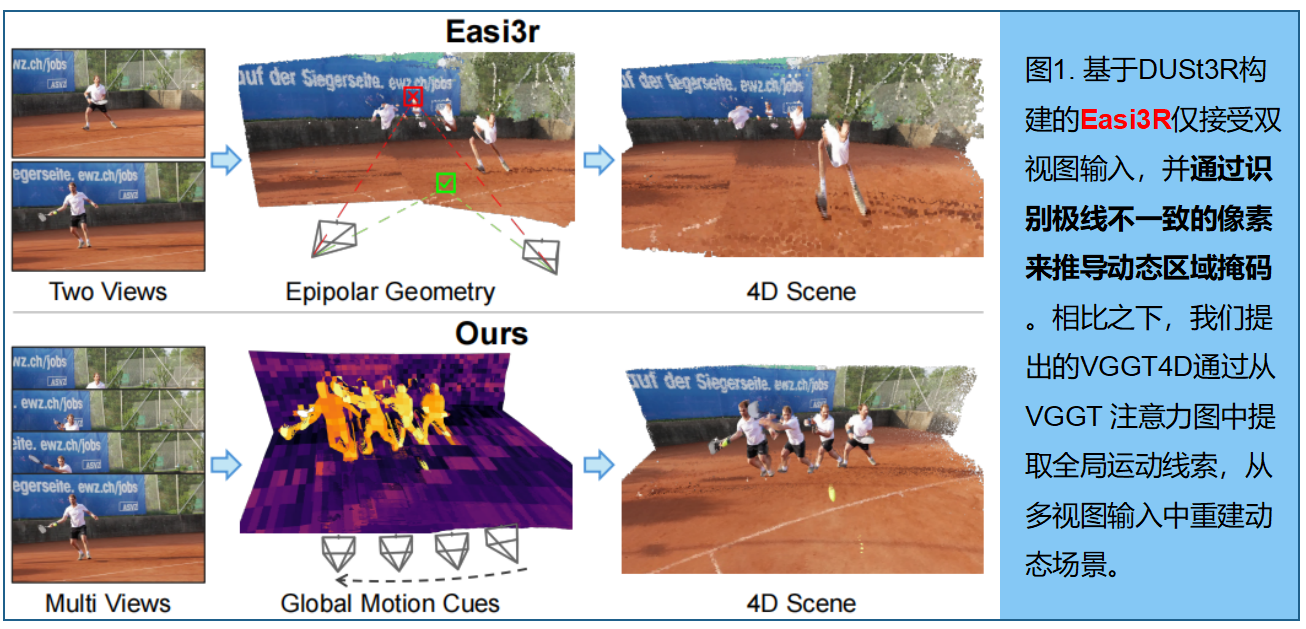
VGGT 。 VGGT 32 是DUSt3R的增强版本,可处理多张输入图像并联合估计多视图姿态和密集几何结构。它同时采用帧间和帧内注意力机制,使token能够跨帧聚合语义连贯的证据,从而实现更一致的3D重建。
提出的VGGT4D的动机。然而,由于Easi3R基于DUSt3R框架构建,其仅限于成对图像输入,难以有效处理多视图输入。为克服这一局限,我们提出VGGT4D,将 VGGT 从静态多视图重建扩展到4D动态场景重建。
四、VGGT 中的经验观察
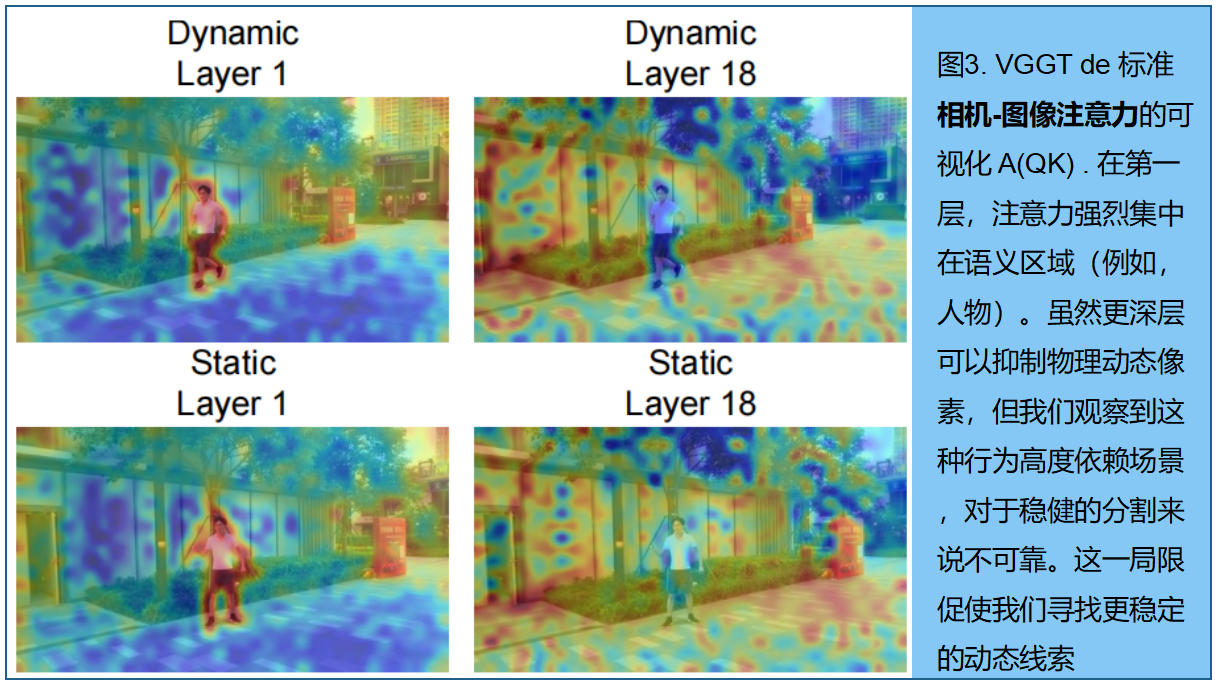
我们首先考察 VGGT 是否能够感知动态像素。如图3 ,可视化了相机token与图像token之间的注意力图。结果表明静态区域和动态区域之间有明显的分离:浅层对语义动态对象(如人)反应强烈,而深层则逐渐抑制多视图几何不一致的像素。这些结果表明, VGGT 对物理运动敏感,并隐式地编码了动态线索。
然而,这种现象具有高度场景依赖性,仅在特定token和layer中出现。同时,图像token间的注意力图包含大量高层次语义噪声,导致直接提取结果不可靠。为实现动态对象mask的一致性与鲁棒性识别,我们提出以下流程,以无训练方式完成4D重建。
五、基于Gram Similarity 的动态特征提取
Easi3R直接从标准注意力图中提取动态mask:
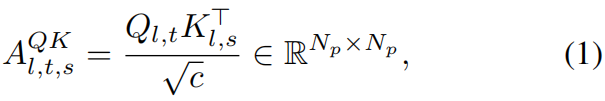
其中 c c c为特征维度, l l l表示层索引, t t t和 s s s为不同帧的索引, N p N_p Np为token数。
然而, A Q K A^{QK} AQK 本质上将动态运动与纹理和语义响应混合在一起,从而降低了运动线索的清晰度。为了放大由运动引起的分布差异,我们计算Gram相似性 Q Q ⊤ QQ^⊤ QQ⊤和 K K ⊤ KK^⊤ KK⊤:
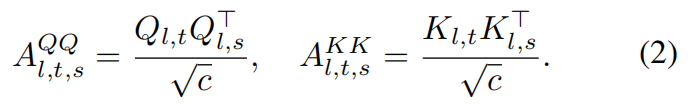
这些自相似性矩阵有效增强了原本隐含在Q和K中的动态线索。
为了聚合时间信息,采用跨帧的帧间滑动窗口策略 ,定义为 W ( t ) = W(t)= W(t)={ t − n , . . . , t − 1 , t + 1 , . . . , t + n t - n,...,t - 1,t + 1,...,t + n t−n,...,t−1,t+1,...,t+n}。在此窗口内及跨越浅层、中层和深层的三层结构中计算Gram Similarity 的均值(S)和方差(V):
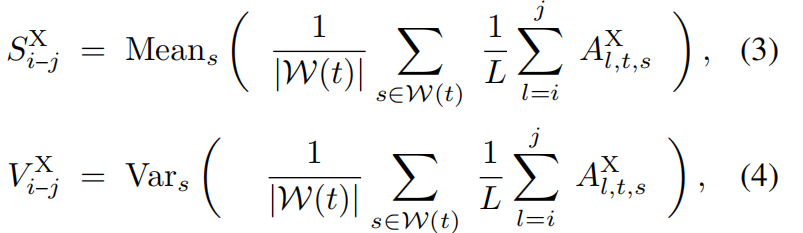
其中 X ∈ X∈ X∈{ Q Q , Q K , K K QQ ,QK ,KK QQ,QK,KK}, i i i 和 j j j 分别表示起始层和结束层索引。
最后,通过挖掘的统计信息,构建动态显著性图 Dyn:
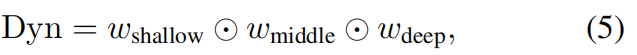
通过元素级乘法,三个因子捕捉互补线索:
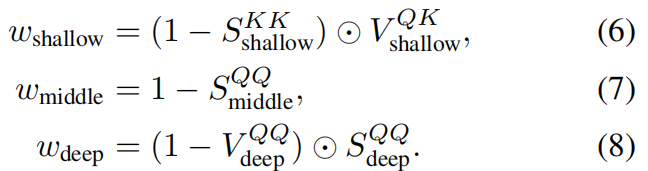
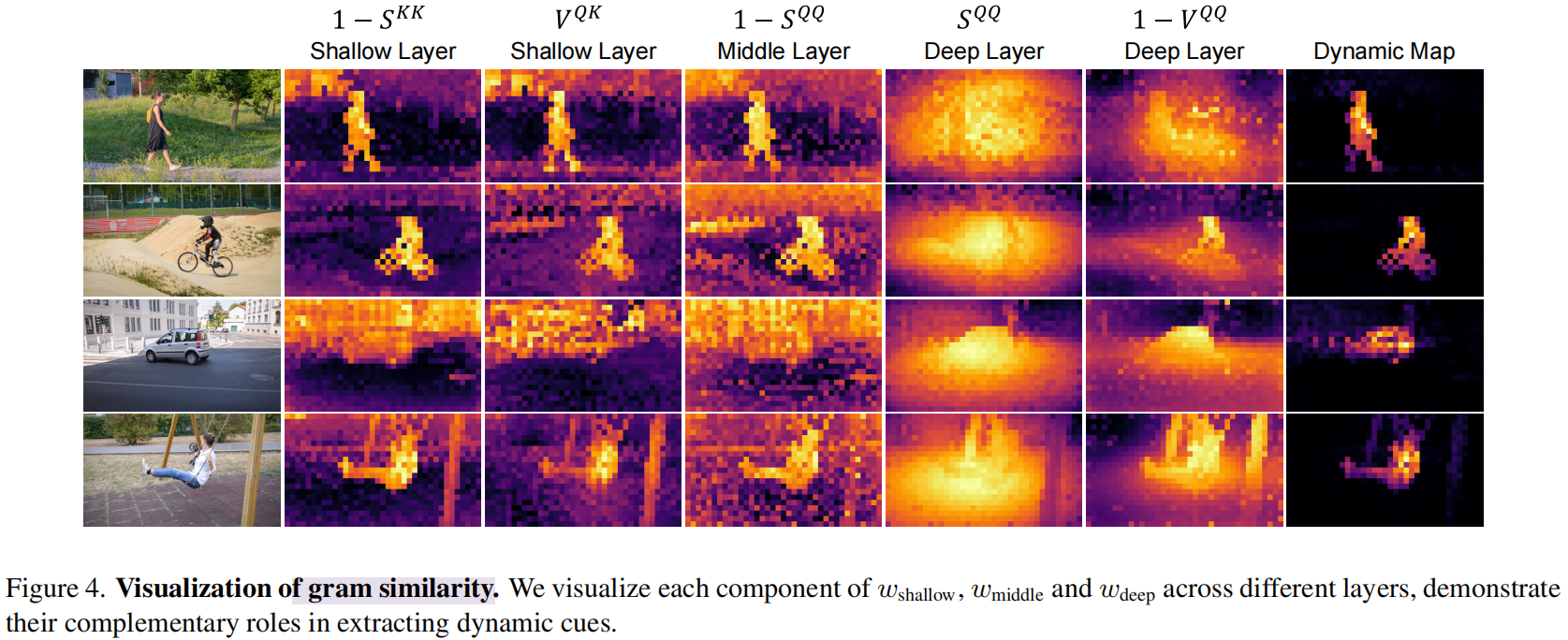
如图4,浅层捕捉语义显著性,中层识别运动不稳定性,深层作为空间先验来抑制异常值。通过阈值化获得每帧动态mask,即 M t = D y n \> α M_t = Dyn \> α Mt=Dyn\>α,并用特征聚类进行微调。
六、基于投影梯度的mask提炼
ViT层提取的mask 比较粗糙,导致4D重建中出现"漂浮物"。我们的核心观点是:当动态物体的三维点被投射到其他视图的静态区域时,会产生较大的几何误差和光度误差 。定义投射到视图 i i i的三维点的几何损失:
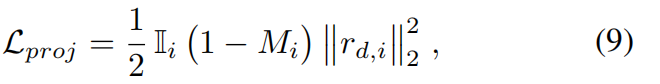
其中 r d , i = d i − D i ( u i , v i ) r_{d,i} = d_i − D_i(u_i,v_i) rd,i=di−Di(ui,vi), M i M_i Mi为初始动态mask, I i I_i Ii为可见性mask, r d , i r_{d,i} rd,i为投影深度di与深度图Di之间的深度残差。
该残差 r d , i r_{d,i} rd,i相对于三维点坐标的梯度,较大几何梯度的点可能具有动态性 。该梯度 ∇ r d , i ∇r_{d,i} ∇rd,i取决于投影雅可比矩阵和目标深度图的空间梯度。
为获得稳健评分,对所有N个视图的投影梯度进行聚合:
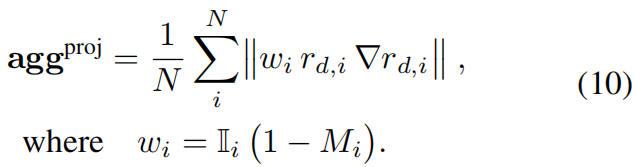
区域(如平面墙面或地面)中可能不可靠,因为深度梯度在此类区域缺乏信息价值。因此,我们通过聚合光度残差对其进行补充:
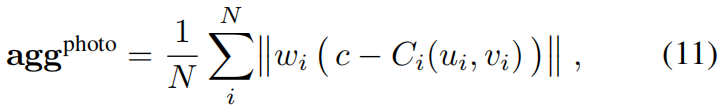
其中 c c c 为该点的颜色, C i C_i Ci 为视图 i i i 中采样的颜色。
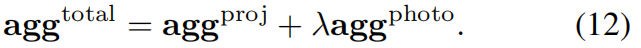
如果 a g g t o t a l > τ agg^{total}> τ aggtotal>τ ,则该点标记为动态。这种梯度感知的细化有效地锐化了mask边界。此外还应用了点云过滤和空间聚类以提高鲁棒性。
七、基于早期mask的4D重建
通过将动态mask,整合到 VGGT 中进行推理,可排除动态干扰,使相机位姿估计和4D点云重建更加稳健。
动态像素引入了几何不一致性。然而,简单地在所有层中屏蔽所有动态token是有害的。 VGGT 已经学会了部分减弱动态信号;全面屏蔽会使模型进入分布外状态,放大错误并移除有效的静态区域
我们提出一种早期阶段的mask策略。仅在浅层语义和中层(具体为第1-5层)对动态图像token进行mask处理。通过抑制这些层中动态token的Key 向量来实现。该方法可防止动态信息污染深层几何推理阶段,同时仍允许深层的层在其训练分布内运行。这种受控干预可产生稳定姿态及清晰、解耦的动态与静态点云。
实验
数据集 。我们在DAVIS25数据集上评估动态mask 估计。相机位姿估计在DyCheck11、TUM-Dynamics29、Sintel3、 VKITTI 4和Point Odyssey45上进行评估,我们选择了多个高度动态的视频序列。对于DyCheck,每4步采样一帧;对于TUM-Dynamics,每30步采样一帧。点云重建进一步在DyCheck上进行评估。为了测量长序列重建,我们使用了Point Odyssey45数据集,序列长度为500。
其他细节。所有实验均在单个 NVIDIA A6000 GPU上进行。我们还修改了 VGGT 的注意力算子。
长序列推理。在FastVGGT 28的基础上进行了改进。我们利用了 VGGT 预测头仅消耗特定层(即第5、12、18、24层)token的发现。因此,在推理过程中我们丢弃了其他层的所有中间token。这显著减少了内存占用,使得我们的方法能够在Point Odyssey 45上处理超过500帧的序列。我们在这一高效的长序列骨干网络上应用了动态token mask,进一步提高了准确性。
动态物体分割
结果如表1和图5。评估指标采用交并比(IoU)和边界F-measure作为评估指标,先对每个序列进行平均,再跨序列取平均。这些指标分别标记为JM和FM。为评估召回率,当IoU或边界F值超过0.5时定义为成功检索,并报告平均召回率JR和FR。
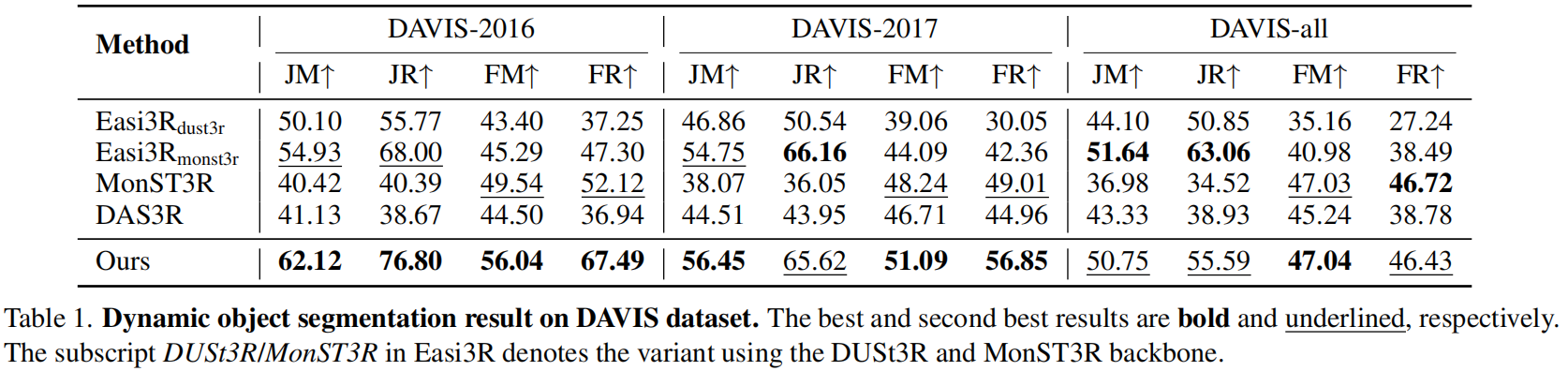

虽然Easi3Rmonst3r在DAVISall上表现出具有竞争力的召回率,但这源于MonST3R在光流上的后训练。我们的方法无需训练即可实现这些结果,仅需基于预训练的 VGGT 模型运行。
相机位姿估计
表2至表4显示,原始的 VGGT 已经是一个非常强大的基线方法,单独使用时就超越了许多专门的4D重建方法(例如MonST3R、DAS3R、CUT3R)。这表明其在多样化数据上的预训练隐式地教会了它对动态物体具有部分鲁棒性。
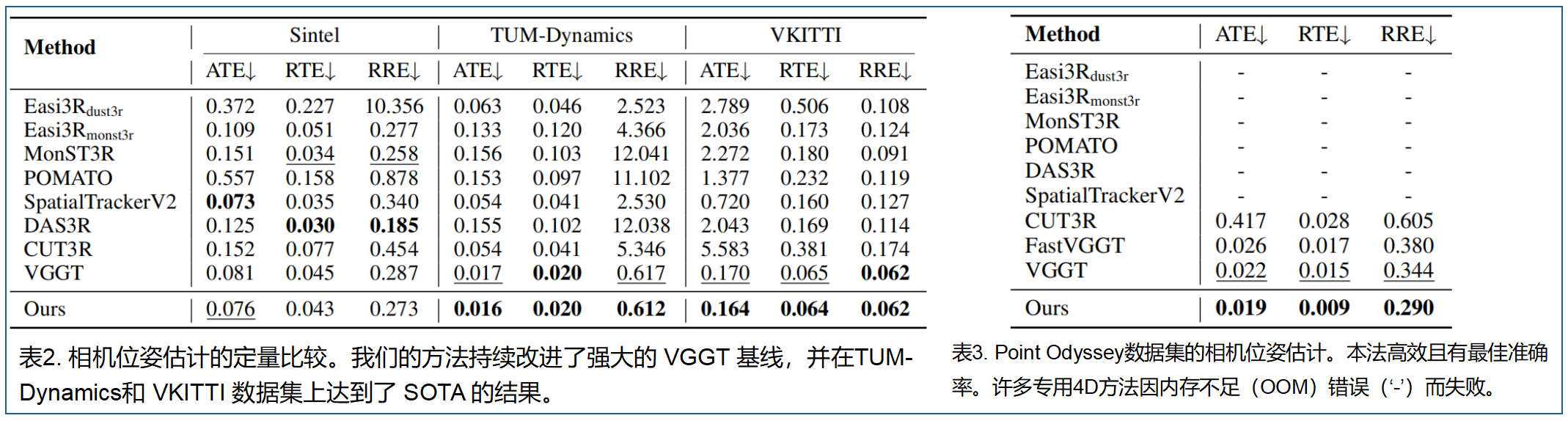
然而,这种鲁棒性并非完美。我们的方法VGGT4D在所有数据集上都持续优于这一强大的 VGGT 基线。在长序列的Point Odyssey基准测试(表3)中,我们不仅在所有指标上取得最佳结果,还保持了极高的效率。许多其他4D方法甚至无法处理这500帧的序列,因为出现了内存不足的错误。这表明 VGGT 的隐式补偿是不完整的。我们的显式、无需训练的动态-静态解耦成功地识别并消除了由运动引起的残余姿态不一致,从而获得更稳定和精确的相机轨迹,特别是在长而复杂的序列中
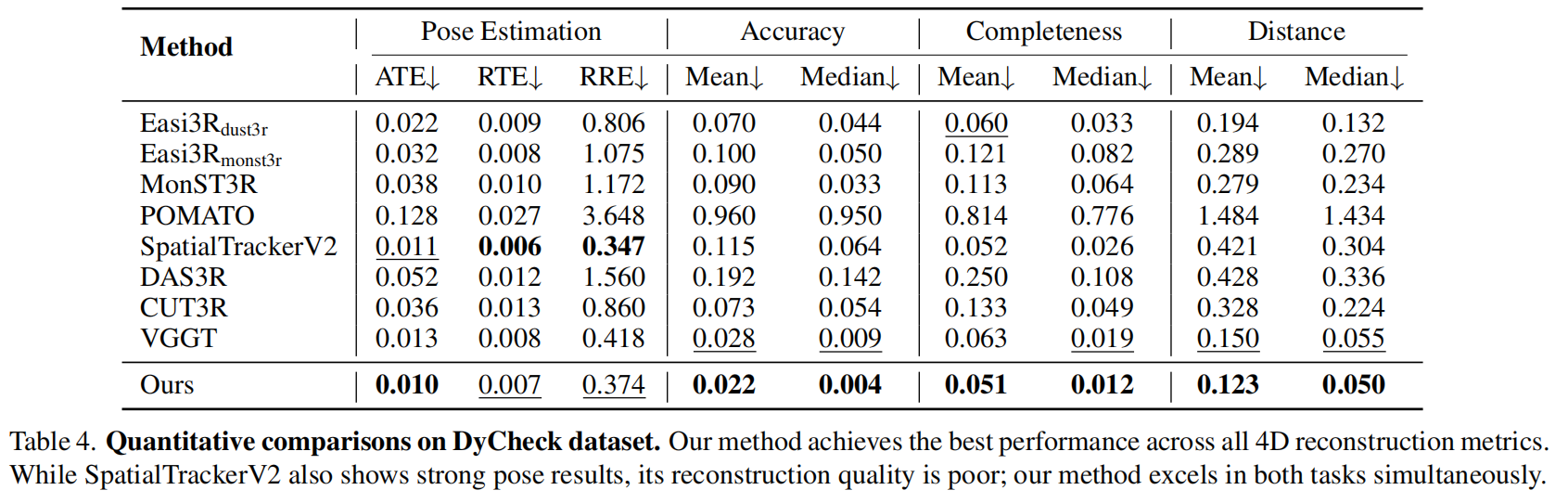
4D重建
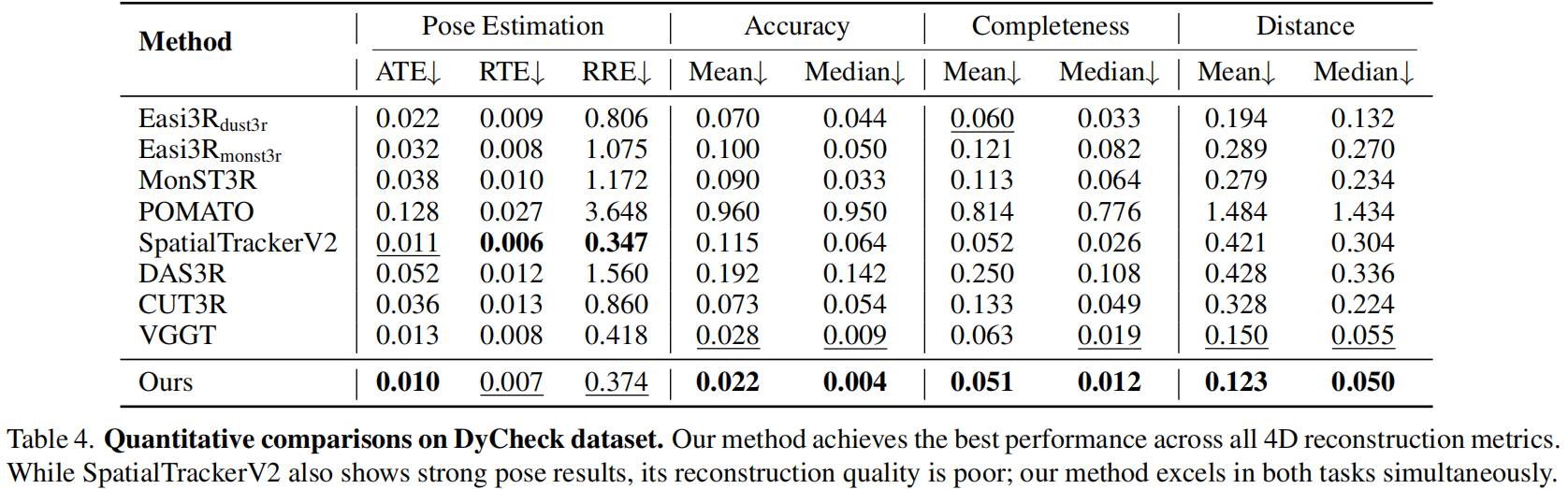
表4评估了DyCheck数据集的4D点云重建,图6中呈现了定性结果。我们的方法在所有重建指标(准确率、完整性和距离)上都取得了最佳性能。与强大的 VGGT 基线相比,改进显著,例如将中位数准确率误差从0.009降低到0.004,平均距离从0.150减少到0.123。这些数据在图6的视觉证据中得到了证实。像MonST3R和Easi3R这样的基线方法生成的重建结果噪声多且充满伪影。动态物体经常在静态场景中"鬼影"(第1、2行),而静态背景则显得支离破碎(第3行)。相比之下,我们的方法生成的静态点云更清晰可见,动态物体也更加连贯且分离良好(例如第4行中的人)。

这一质的飞跃源于:(1) 精准的动态mask能准确识别动态区域;(2) 梯度感知优化确保边界清晰,避免背景"漂浮物"干扰;(3) "早期mask"策略有效防止动态信息污染深度几何推理层,实现清晰分离。
#pic_center =60%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E