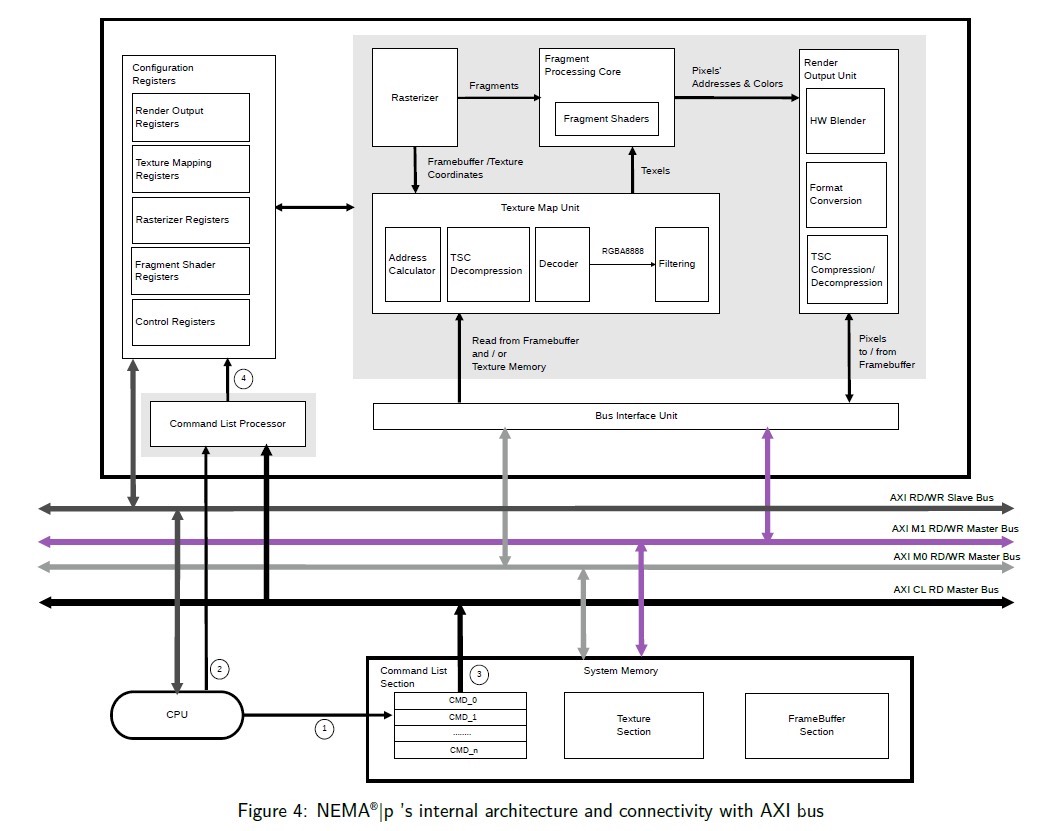
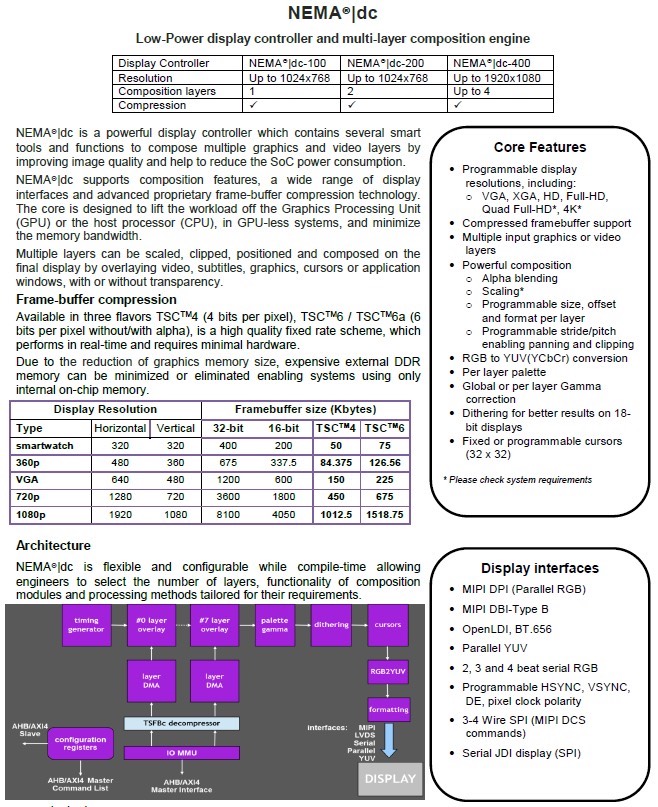
NEMA_p GPU NEMA | dc 2022 verilog/systemverilog实现

最近在硬件设计的世界里遨游,碰到了NEMAp GPU这个挺有意思的玩意儿。NEMAp GPU听起来就感觉很有科技感,它在图形处理方面应该有着独特的优势。今天就来和大家唠唠怎么用Verilog/SystemVerilog来实现它,中间还会穿插一些代码和简单的分析。
项目背景
先说说NEMA吧,在文档里有 "NEMA | dc" 这样的标识,并且年份是2022。虽然目前不太清楚这里面 "dc" 具体代表啥,也许是某种特定的版本或者设计思路,但这并不影响我们去实现NEMA_p GPU。Verilog和SystemVerilog是硬件描述语言里的两大主力,用它们来实现硬件设计是再合适不过了。
初步构思
在开始写代码之前,得先有个大致的思路。对于NEMA_p GPU这样的项目,我们需要把它拆分成一个个小模块,就像搭积木一样,每个模块完成一个特定的功能。比如,可能会有数据处理模块、图形渲染模块等等。
简单示例代码及分析
模块定义示例
verilog
module nema_p_gpu (
input wire clk,
input wire rst,
input wire [31:0] data_in,
output wire [31:0] data_out
);
// 这里可以添加模块内部的逻辑
reg [31:0] internal_data;
always @(posedge clk or posedge rst) begin
if (rst) begin
internal_data <= 32'b0;
end else begin
internal_data <= data_in;
end
end
assign data_out = internal_data;
endmodule代码分析
上面这段代码定义了一个简单的 nemapgpu 模块。首先看模块的端口:
clk:时钟信号,这可是硬件设计里的核心,所有的操作都要跟着时钟的节拍来。rst:复位信号,当它有效时,会把模块内部的状态重置。data_in:32位的输入数据,这就是要进入模块进行处理的数据。data_out:32位的输出数据,是模块处理完后输出的结果。
在模块内部,我们定义了一个32位的寄存器 internaldata**来保存数据。always 块是一个时序逻辑块,它会在时钟上升沿或者复位信号有效时触发。当复位信号有效时,internal data 会被清零;否则,它会把输入数据 datain**保存下来。最后,通过 assign 语句把 internal data 的值赋给输出端口 data_out。

这只是一个非常简单的示例,真正的NEMA_p GPU实现肯定要复杂得多。可能需要处理大量的图形数据,涉及到更复杂的算法和逻辑。
后续挑战
在实现NEMA_p GPU的过程中,肯定会遇到不少挑战。比如,如何优化代码以提高性能,如何处理数据的并发和同步等等。但这也正是硬件设计的魅力所在,不断地解决问题,让自己的设计更加完善。

总之,NEMA_p GPU的Verilog/SystemVerilog实现是一个充满挑战和乐趣的过程。后续我会继续深入研究,和大家分享更多的代码和经验。希望这篇博文能给对硬件设计感兴趣的小伙伴一些启发。