重要信息
时间: 2026年1月23-25日
地点:中国-合肥



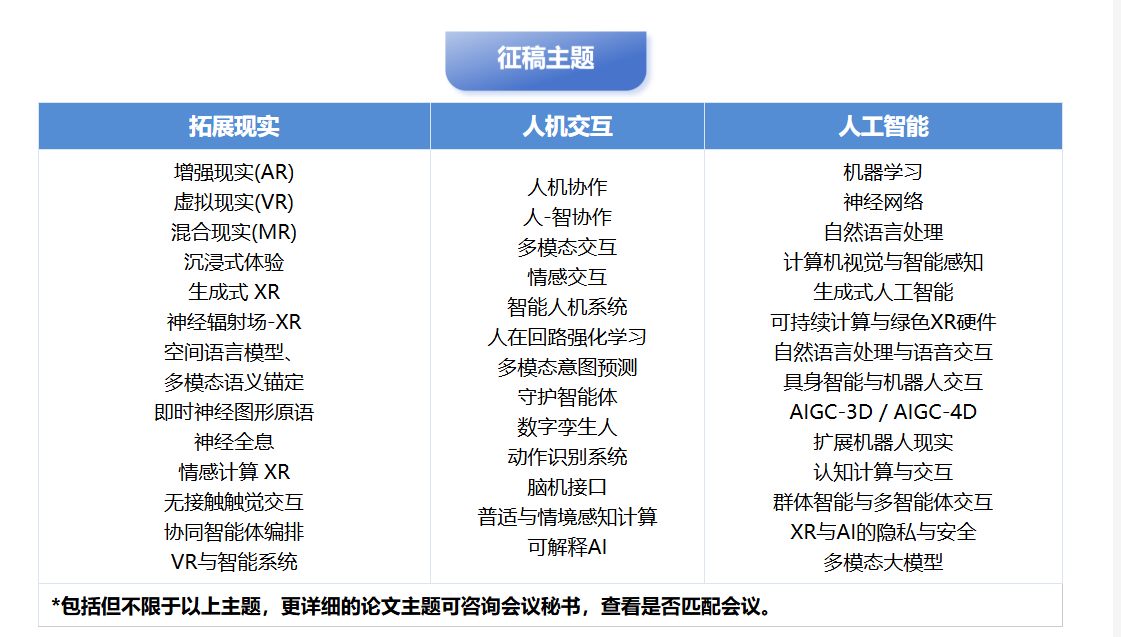
征稿主题
一、XRHCIAI 核心技术体系概述
拓展现实(XR)、人机交互(HCI)与人工智能(AI)的融合是下一代智能交互技术的核心方向,也是 XRHCIAI 2026 研讨会聚焦的核心领域。三者的协同不仅重构了人机交互的范式,更推动了从虚拟仿真到智能决策全链路的技术革新。以下从技术维度拆解三者的核心关联与技术栈:
| 技术领域 | 核心技术方向 | 关键应用场景 | 技术挑战 |
|---|---|---|---|
| 拓展现实(XR) | 空间定位与映射、虚实融合渲染、多模态感知 | 工业元宇宙、沉浸式教育、医疗手术仿真 | 低延迟渲染、空间精度不足、硬件轻量化 |
| 人机交互(HCI) | 自然语言交互、手势 / 眼动识别、情感计算 | 智能座舱、无障碍交互、虚拟数字人 | 交互意图理解、跨模态融合鲁棒性 |
| 人工智能(AI) | 大模型多模态理解、强化学习、实时推理 | XR 内容生成、交互意图预测、环境自适应 | 端侧算力受限、模型轻量化、隐私保护 |
二、XR 与 AI 融合的核心技术实践
2.1 空间感知与 AI 定位算法
XR 设备的核心能力之一是空间定位,传统 SLAM(同步定位与建图)算法在复杂环境下易出现漂移,结合 AI 的特征提取与动态校正可显著提升精度。以下是基于深度学习的 SLAM 特征点优化 Python 实现示例:
python
运行
import cv2
import numpy as np
import torch
import torch.nn as nn
# 定义特征点提取与优化网络
class FeatureOptimizer(nn.Module):
def __init__(self, in_channels=256, num_keypoints=100):
super(FeatureOptimizer, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 128, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.fc = nn.Linear(64 * 8 * 8, num_keypoints * 2) # 输出关键点坐标
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.max_pool2d(x, 2)
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, 2)
x = x.flatten(1)
x = self.fc(x)
return x.reshape(-1, 100, 2) # [batch, num_keypoints, (x,y)]
# SLAM特征点校正流程
def optimize_slam_keypoints(slam_keypoints, frame_img, model):
# 预处理图像
img = cv2.resize(frame_img, (64, 64))
img_tensor = torch.from_numpy(img).permute(2, 0, 1).float().unsqueeze(0) / 255.0
# 模型预测优化后的特征点
with torch.no_grad():
optimized_keypoints = model(img_tensor).squeeze(0).numpy()
# 融合原始SLAM特征点与优化结果(加权融合)
fused_keypoints = 0.7 * optimized_keypoints + 0.3 * slam_keypoints
return fused_keypoints
# 示例调用
if __name__ == "__main__":
# 初始化模型
model = FeatureOptimizer()
# 模拟SLAM输出的特征点(100个关键点)
slam_keypoints = np.random.rand(100, 2) * 64
# 模拟XR设备采集的帧图像
frame_img = np.random.rand(64, 64, 3) * 255
frame_img = frame_img.astype(np.uint8)
# 优化特征点
optimized = optimize_slam_keypoints(slam_keypoints, frame_img, model)
print(f"优化前特征点均值:{np.mean(slam_keypoints):.2f}")
print(f"优化后特征点均值:{np.mean(optimized):.2f}")2.2 多模态交互意图理解
AI 驱动的多模态意图理解是 XR 人机交互的核心,通过融合语音、手势、眼动等信号,精准识别用户交互意图。以下是基于 Transformer 的多模态意图分类实现:
python
运行
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
# 多模态意图分类模型
class MultimodalIntentClassifier(nn.Module):
def __init__(self, num_intents=10, hidden_dim=768):
super(MultimodalIntentClassifier, self).__init__()
# 文本分支(BERT)
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 手势特征分支
self.gesture_fc = nn.Sequential(
nn.Linear(128, hidden_dim),
nn.ReLU(),
nn.Dropout(0.1)
)
# 眼动特征分支
self.eye_fc = nn.Sequential(
nn.Linear(64, hidden_dim),
nn.ReLU(),
nn.Dropout(0.1)
)
# 融合层
self.fusion = nn.Linear(hidden_dim * 3, hidden_dim)
# 意图分类层
self.classifier = nn.Linear(hidden_dim, num_intents)
def forward(self, text, gesture_feat, eye_feat):
# 文本编码
text_inputs = self.tokenizer(text, return_tensors='pt', padding=True, truncation=True)
text_emb = self.text_encoder(**text_inputs).pooler_output # [batch, 768]
# 手势特征编码
gesture_emb = self.gesture_fc(gesture_feat) # [batch, 768]
# 眼动特征编码
eye_emb = self.eye_fc(eye_feat) # [batch, 768]
# 多模态融合
fused = torch.cat([text_emb, gesture_emb, eye_emb], dim=1)
fused = torch.relu(self.fusion(fused))
# 意图分类
logits = self.classifier(fused)
return logits
# 示例调用
if __name__ == "__main__":
# 初始化模型
model = MultimodalIntentClassifier(num_intents=5)
# 模拟输入:文本、手势特征、眼动特征
text_input = ["open the virtual menu", "rotate the 3d model"]
gesture_feat = torch.randn(2, 128) # 2个样本,128维手势特征
eye_feat = torch.randn(2, 64) # 2个样本,64维眼动特征
# 预测意图
with torch.no_grad():
outputs = model(text_input, gesture_feat, eye_feat)
pred_intents = torch.argmax(outputs, dim=1)
print(f"预测意图标签:{pred_intents.numpy()}")
print(f"意图概率分布:{torch.softmax(outputs, dim=1).numpy()}")三、HCI 与 AI 的协同优化方向
3.1 端侧 AI 轻量化技术
XR 设备受限于算力和功耗,端侧 AI 模型轻量化是落地关键。核心技术包括:
- 模型量化:将 32 位浮点模型转换为 8 位整型,降低显存占用(如下表);
- 模型剪枝:移除冗余神经元和权重;
- 知识蒸馏:将大模型知识迁移到小模型。
| 轻量化策略 | 精度损失 | 推理速度提升 | 显存占用降低 | 适用场景 |
|---|---|---|---|---|
| 8 位量化 | <1% | 2-3 倍 | 70%+ | 实时渲染、意图识别 |
| 通道剪枝 | 1-2% | 1.5-2 倍 | 50%+ | 特征提取、姿态估计 |
| 知识蒸馏 | <0.5% | 1.2-1.5 倍 | 40%+ | 多模态理解、决策推理 |
3.2 情感化人机交互
AI 驱动的情感计算让 XR 交互更具人性化,通过分析用户语音语调、面部表情、生理信号(心率、皮电),动态调整交互策略。核心流程:
- 多模态情感特征采集(XR 传感器);
- 情感特征提取与融合;
- 情感状态分类(开心 / 愤怒 / 疲劳等);
- 交互策略自适应调整(如降低操作复杂度、调整虚拟场景氛围)。
四、技术挑战与未来趋势
4.1 核心挑战
- 跨模态数据对齐:不同模态数据(视觉 / 语音 / 触觉)的时空同步问题;
- 低功耗实时计算:XR 设备算力与功耗的平衡;
- 隐私保护:用户交互数据(生理、行为)的安全与合规;
- 泛化能力:模型在不同场景、不同用户群体的适配性。
4.2 未来趋势
- 具身智能:XR+AI 结合具身认知,实现物理世界与虚拟世界的统一交互;
- 脑机接口(BCI)融合:直接通过脑电信号实现 XR 交互,突破外设限制;
- 生成式 AI 赋能 XR 内容:AIGC 自动生成 XR 场景、虚拟数字人、交互逻辑;
- 边缘云协同:端侧轻量化推理 + 云端大模型训练,兼顾实时性与能力上限。
五、国际交流与合作机会
作为国际学术会议,将吸引全球范围内的专家学者参与。无论是发表研究成果、聆听特邀报告,还是在圆桌论坛中与行业大咖交流,都能拓宽国际视野,甚至找到潜在的合作伙伴。对于高校师生来说,这也是展示研究、积累学术人脉的好机会。