写在前面,自从发现拿到json解析后的文件中有我们想要的信息后,我稍微有点迷上这种方法,但是拿到内容后要怎么拿到想要的信息呢,字典列表相互嵌套,我头都晕了
方法:首先就是把json解析后的文本保存成.json的形式
这里展现的是微博的一个热搜页面

下面这个代码就是拿到想要的信息后保存下来,我们爬虫不要过度,要合法的爬取,礼貌的爬取
python
import requests
import json
url="https://weibo.com/ajax/side/hotSearch"
headersvalue={
'User-Agent':"自己的",
"Referer":"自己的"
}
r=requests.get(url,headers=headersvalue)
data=r.json()
print(data)
with open('weibo.json',"w",encoding="utf-8") as f:
json.dump(data,f,indent=4,ensure_ascii=False)可以看到一个文件的格式,是一个字典,下面的解释我就直接写在代码里面

详解1:
python
#拿这里面的信息hotgovs,首先看大结构,是一个字典,里面的键值对有{"ok":1,"data":xxx,"logs":xxx,}
#我们要拿的东西在这个字典的键data对应的值里,字典取值用键,所以先选择这个键data['data'],拿到它的值,发现它的值也是一个一个字典
#继续根据你要的值找键
toptitle=data['data']['hotgovs'][0]["word"].strip("#")
print(f'置顶标题:{toptitle}')
#这里我们发现有一个realtime的键,值是一个列表,列表里装的元素是一个一个字典,字典有我们想要的标题还有热度之类的信息
#所以我们写一个循环,来遍历这个列表,列表的遍历有两种方法
#方法1:直接遍历
data=data['data']['realtime']
#这里遍历,item都是一个一个字典元素,所以取值还是用键值对
for item in data:
#这样写有一个非常大的缺点,如果遍历到这个元素,没有这个键的话就会报错keykerror
realpos=item["realpos"]
word=item["word"]
num=item["num"]
print(realpos)
print(word)
print(num)可以看到遍历到第7个元素报错了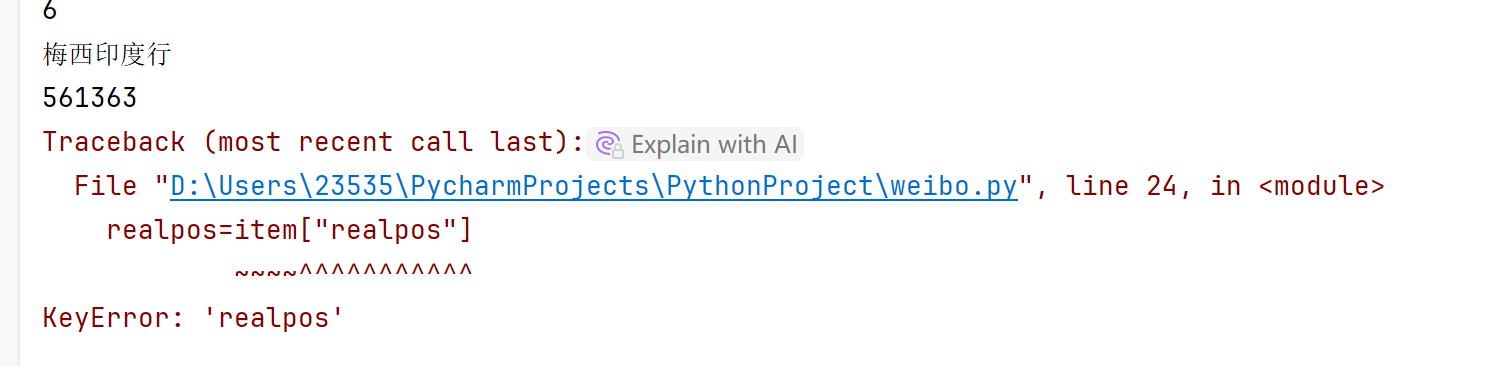
找一下就会发现第七个元素不是我们要找的热点排行榜里面的,大概率是条广告
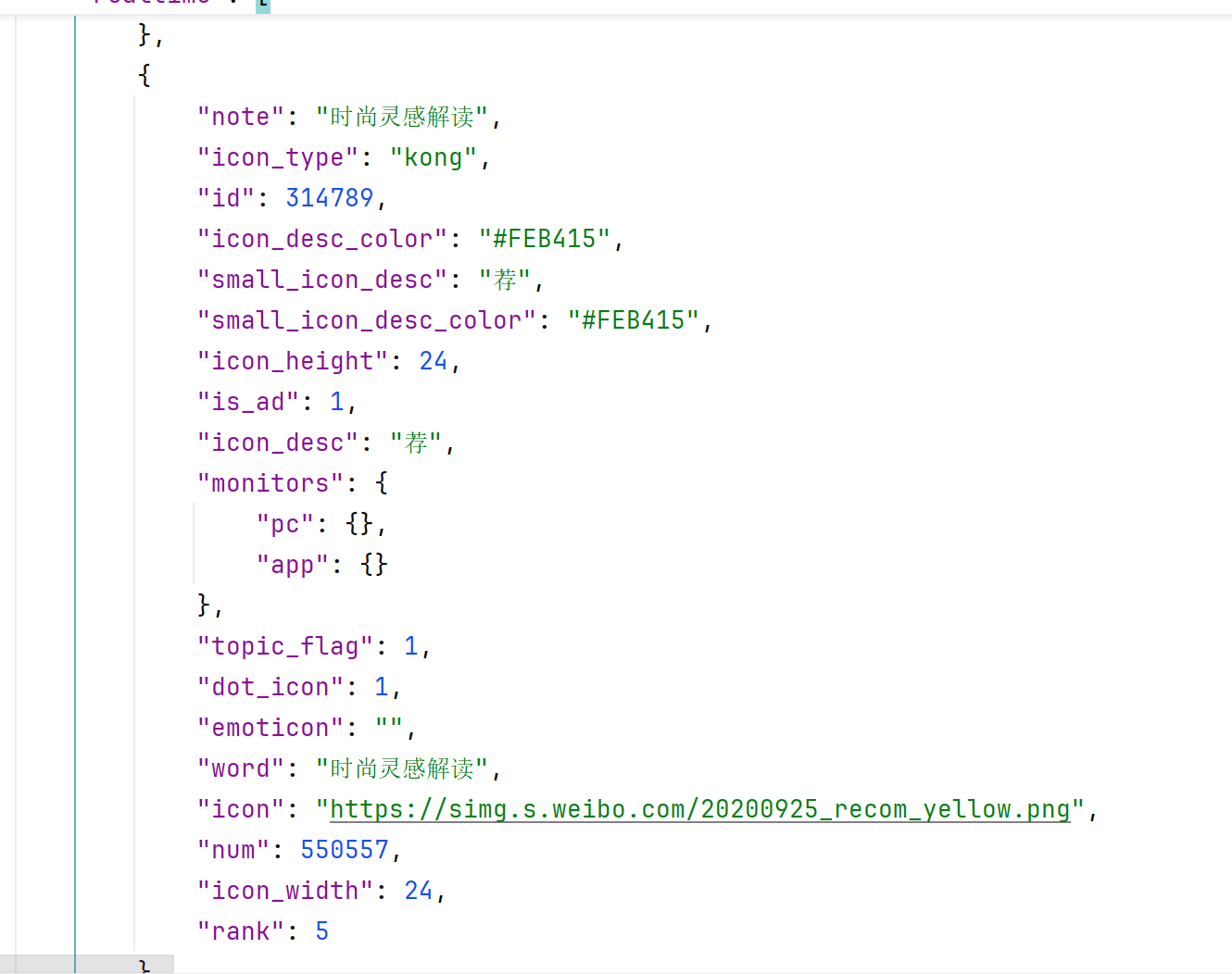
详解2:
python
#方法1:直接遍历
data=data['data']['realtime']
#这里遍历,item都是一个一个字典元素,所以取值还是用键值对
for item in data:
#这样写有一个非常大的缺点,如果遍历到这个元素,没有这个键的话就会报错keykerror
# realpos=item["realpos"]
# word=item["word"]
# num=item["num"]
#所以保险起见,我们取字典的值用get()方法,是字典的专属方法
realpos=item.get('realpos','空')
word=item.get('word','空')
num= item.get('num', '空')
print(realpos)
print(word)
print(num)
#方法二:用enumerate方法遍历,这个方法返回的是元组,是索引加元素的组合
for index,item in enumerate(data):
print(f"第{index}个热点")
realpos = item.get('realpos', '空')
word = item.get('word', '空')
num = item.get('num', '空')
print(realpos)
print(word)
print(num)