基本信息
题目:A Survey on 3D Gaussian Splatting
来源:arXiv 2024
学校:浙江大学
是否开源:https://github.com/guikunchen/Awesome3DGS
摘要:三维高斯泼溅( GS )已成为辐射领域的一种变革性技术。与主流的隐式神经模型不同,3D GS使用数百万个可学习的3D高斯进行显式场景表示。结合可微分渲染算法,该方法实现了实时渲染和前所未有的可编辑性,使其成为三维重建和表示的潜在游戏规则改变者。在本文中,我们首次系统地综述了3D GS的最新进展和重要贡献。我们首先详细探究了3D GS产生的潜在原理和背后的驱动力,为理解其意义做了铺垫。我们讨论的一个重点是3D GS的实际应用性。 通过实现前所未有的渲染速度,3D GS开辟了大量的应用,从虚拟现实到交互式媒体等。此外,本文还对领先的3D GS模型进行了比较分析,并在各种基准任务中进行了评估,以突出它们的性能和实际效用。调查最后指出了当前的挑战,并提出了未来研究的潜在途径。通过这项调查,我们旨在为新手和经验丰富的研究人员提供有价值的资源,以促进在外显辐射领域的进一步探索和发展。
1 Introduction
基于图像的三维场景重建的目标是将拍摄场景的视图或视频集合转换为可计算处理、分析和操作的数字三维模型。这个难以解决且长期存在的问题是机器理解现实世界环境复杂性的基础,有助于3D建模和动画、机器人导航、历史保存、增强/虚拟现实和自动驾驶等广泛的应用。
三维场景重建的旅程很早就开始于深度学习的热潮之前,早期的工作主要集中在光场和基本的场景重建方法 14、57、112上。然而,++这些早期的尝试由于依赖于密集采样和结构化捕获而受到限制,导致在处理复杂场景和光照条件时面临重大挑战++ 。运动产生的结构的出现 206 以及随后在多视角立体视觉 55 算法的发展为三维场景重建提供了一个更加鲁棒的框架。尽管取得了这些进展,++但这些方法仍然面临着新奇视角合成和纹理丢失的问题++。NeRF代表了这一进程中的一个量子飞跃。通过利用深度神经网络,NeRF实现了空间坐标到颜色和密度的直接映射。NeRF的成功取决于它能够创建连续的、立体的场景功能,并以前所未有的逼真度产生结果。然而,与任何新兴技术一样,这种实现也付出了代价:1 )计算强度。基于NeRF的方法是计算密集型的 52、161 ,通常需要大量的训练时间和大量的资源来绘制,特别是对于高分辨率的输出。 2 )可编辑性。对隐式表示的场景进行操作是具有挑战性的,因为直接修改神经网络的权重并不直观地与场景的几何或外观属性的变化有关。
正是在这种背景下,3D Gaussian抛雪球( GS ) 96 应运而生,它不仅是一种增量式的改进,而且是一种重新定义场景表示和渲染边界的颠倒性方法。虽然NeRF在创建真实感图像方面表现出色,但对更快、更高效的渲染方法的需求日益明显,特别是对延迟高度敏感的应用程序(例如,虚拟现实和自动驾驶)。3D GS通过引入一种先进的、显式的场景表示方法来解决这一需求,该方法使用空间中数百万个可学习的3D高斯对场景进行建模。 与隐式的、基于坐标的模型 154、204 不同,3D GS采用显式表示和高度并行化的工作流程,便于更高效的计算和绘制。3D GS的创新之处在于其独特地融合了可微分渲染和基于点绘制技术 176、187、270、317的优点。通过使用可学习的3D高斯来表示场景,它保留了连续体积辐射场的强拟合能力,这对于高质量图像合成至关重要,同时避免了与基于NeRF的方法(例如,计算昂贵的射线追踪,以及在空空间中不必要的计算)相关的计算开销。
3D GS的引入不仅仅是技术上的进步;它代表了我们在计算机视觉和图形学中如何处理场景表示和渲染的一个根本性转变。通过在不影响视觉质量的情况下实现实时渲染功能,3D GS为虚拟现实等应用提供了多种可能性并且增强现实能够实时电影化渲染并超越 3、88、92、171。这项技术不仅可以增强现有的应用,而且可以实现由于计算限制而以前不可行的新应用。此外,3D GS的显式场景表示为控制物体和场景动态提供了前所未有的灵活性,这在涉及复杂几何和变化光照条件的复杂场景 141、191、291中至关重要。这种可编辑性水平,结合训练和渲染过程的效率,将3D GS定位为塑造相关领域未来发展的变革性力量。
为了帮助读者跟上3D GS的快速发展,我们提供了关于3D GS的第一份调查,它系统地、及时地收集了关于该主题的最重要的文献。鉴于3D GS是一个非常新的创新( c. f.图1),本调查特别关注其原理和多样性。
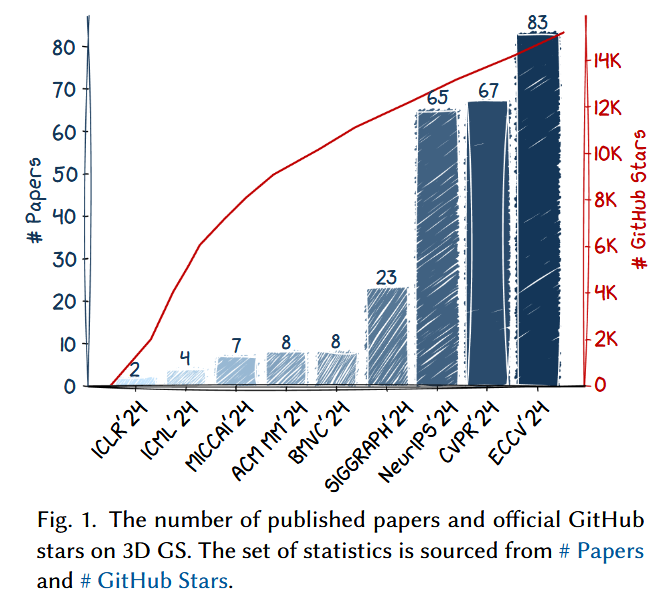
自提出以来出现的发展和贡献。我们系统地回顾了3D GS的奠基时期,所选的工作主要来自顶级会议。我们的分析集中在自2023年至2024年引入以来的最初研究爆炸,涵盖了形成该领域的理论基础、里程碑式的发展和早期应用。承认3D GS的新生但迅速发展的特性,这项调查不可避免地是一种偏颇的观点,但我们努力提供一个平衡的视角,以反映该领域的当前状态和未来潜力。 我们的目的是封装主要的研究趋势,并为渴望了解和贡献这一快速发展领域的研究人员和实践者提供有价值的资源。本次调查与现有文献 8、35、46、242的区别主要体现在以下几个方面:
- 通过建立明确的分类和框架,我们提供了第一个从宏观层面审视3D GS的系统和全面的综述。这种高层次的系统化有助于研究人员识别从特定论文评论中可能看不到的趋势和潜在方向。我们的组织结构为理解不同方法如何在3D GS生态系统中相互关联和构建提供了一个路线图。
- 本文是第一个也是唯一一个对3D GS的理论背景和基本原理进行深入研究的综述。全面的覆盖使该领域对新来者更加平易近人,同时为经验丰富的研究人员提供了有价值的见解。
- 为了确保我们的调查在这个快速发展的领域中保持相关性并提供长期价值,我们维护了两个动态的GitHub仓库:一个遵循我们调查的组织结构,另一个包括与分析数据进行全面的性能比较。
8 Yanqi Bao, Tianyu Ding, Jing Huo, Yaoli Liu, Yuxin Li, Wenbin Li, Yang Gao, and Jiebo Luo. 2024. 3d gaussian splatting: Survey, technologies, challenges, and opportunities. arXiv preprint arXiv:2407.17418 (2024).
35 Anurag Dalal, Daniel Hagen, Kjell G Robbersmyr, and Kristian Muri Knausgård. 2024. Gaussian Splatting: 3D Reconstruction and Novel View Synthesis, a Review. IEEE Access (2024).
46 Ben Fei, Jingyi Xu, Rui Zhang, Qingyuan Zhou, Weidong Yang, and Ying He. 2024. 3d gaussian splatting as new era: A survey. IEEE Trans. Vis. Comput. Graph. (2024).
242 Tong Wu, Yu-Jie Yuan, Ling-Xiao Zhang, Jie Yang, Yan-Pei Cao, Ling-Qi Yan, and Lin Gao. 2024. Recent advances in 3d gaussian splatting. Comput. Vis. Media (2024), 1--30.
2 BACKGROUND
在本节中,我们首先给出辐射场( Sec。2 . 1 )的简要表达式,包括隐式和显式两种形式。Sec。2 . 2进一步建立了与相关渲染算法和术语的联系。对于辐射场,场景重建和表示以及渲染方法的全面概述,请参阅 63、100、222、230、248的优秀调查,以获得更多的见解。
2.1 Radiance Field
- Implicit Radiance Field.
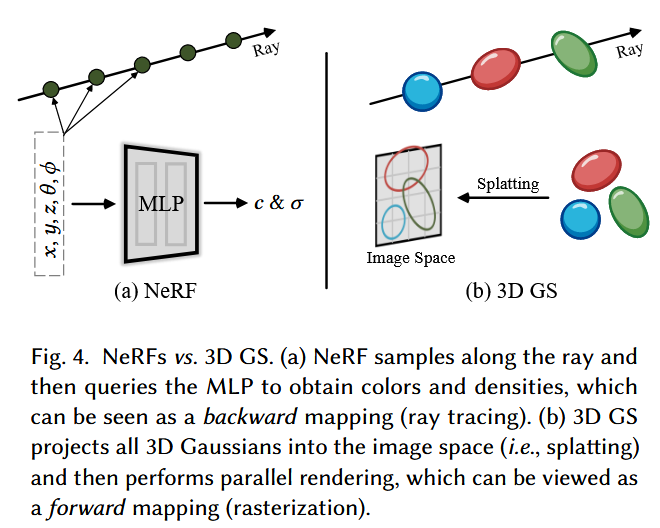
一个隐式的辐射场表示场景中的光分布,而不需要显式地定义场景的几何形状。在深度学习时代,神经网络经常被用来学习一个连续的体场景表示 152、168 。最突出的例子是NeRF 154 。在NeRF (图4a )中,使用一个或多个MLP将一组空间坐标( x , y , z)和观察方向( θ , φ)映射为颜色c和体积密度σ:
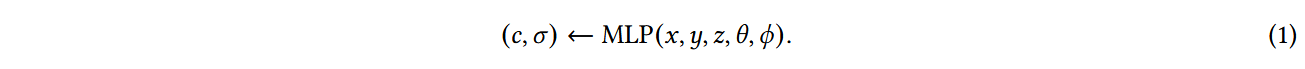
这种格式允许对复杂场景进行可微且紧凑的表示,尽管常常以体积射线行进带来的高计算负载为代价。值得注意的是,颜色c是方向依赖的,而体积密度σ不是 154 。
- Explicit Radiance Field.
一个显式的辐射场直接表示光在一个离散的空间结构中的分布,例如一个体素网格或一组点 49、212 。该结构中的每个元素存储了其各自位置的辐亮度信息。这允许直接和通常更快地访问辐射数据,但以更高的内存使用率和潜在的低分辨率为代价。与隐式辐亮度场类似,显式辐亮度场写为:

其中数据结构可以是体、点云等格式。数据结构对方向颜色的编码主要有两种方式。一种是对高维特征进行编码,然后由轻量级MLP解码。另一种是直接存储方向基函数的系数,如球谐函数或球高斯函数,其中最终的颜色计算为这些系数和观察方向的函数。
- 3D Gaussian Splatting: Best-of-Both Worlds.
3D GS 96 是一种显式辐射场,具有隐式辐射场的优点。具体来说,它利用可学习的3D高斯作为数据结构的基本要素,充分利用了两种范式的优点。值得注意的是,3D GS直接为每个高斯编码不透明度α,而不是先建立密度σ,然后根据该密度计算不透明度的方法。与之前的重建工作一样,在多视图图像的监督下优化3D高斯来表示场景。这种基于3D高斯的可微分渲染结合了基于神经网络的优化和显式结构化数据存储的优点。
2.2 Context and Terminology
- Volumetric rendering
目的是通过整合沿相机射线的辐射,将3D体积表示转换为图像。相机射线r ( t )可以参数化为:r ( t ) = o + td,t∈ t near , tfar,其中o表示射线原点(相机中心),d表示射线方向,t表示近、远截平面之间沿射线的距离。像素颜色C ( r )是通过沿射线r ( t )的线积分计算的,数学表达式为 154 :
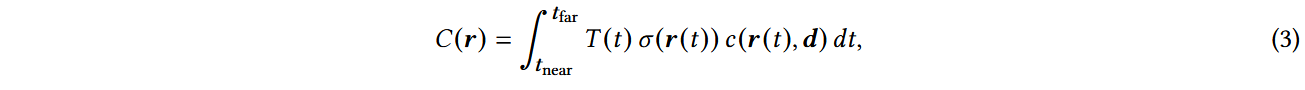
其中σ ( r ( t ) )为点r ( t )处的体积密度,c ( r ( t ),d )为该点处的颜色,T ( t )为透射率。Raymarching通过沿射线进行系统的"步进",以离散的间隔采样场景的属性,直接近似体绘制积分。NeRF 154 同样秉承射线追踪的精神,引入重要性采样和位置编码来提高合成图像的质量。在提供高质量结果的同时,光线跟踪的计算代价是昂贵的,特别是对于高分辨率图像。
- Point-based rendering
表示另一类渲染算法,其中3D GS引入了一个值得注意的实现。其最简单的形式 58 是将固定大小的点云栅格化,这引入了空洞和渲染伪影等弊端。Seminal工作通过各种方法解决了这些限制,包括:i )使用空间范围为 187 , 316 \~ 318的散点图元,以及ii )最近将神经特征直接嵌入到点中,用于后续基于网络的渲染 4、190 。3D GS使用包含显性属性(例如,颜色和不透明度)的3D Gaussian作为点基元,而不是隐含的神经特征。渲染方法,即基于点的α混合(如式( 1 )所示)。 5 ),具有与NeRF风格的体绘制相同的图像生成模型(等式3 ) 96 ,但具有明显的速度优势。这种优势源于算法的根本差异。NeRFs对每个像素沿一条射线近似一个线积分,需要昂贵的采样。基于点的方法采用栅格化的方式渲染点云,其本质上受益于并行计算策略 106 。
3 3D GAUSSIAN SPLATTING: PRINCIPLES
3D GS在不依赖深度神经网络的情况下,提供了实时、高分辨率图像绘制的突破。本部分旨在提供3D GS的基本见解。我们首先在3.1节详细阐述了3D GS如何合成给定结构良好的3D高斯图像,即3DGS的正向过程。然后,我们在3.2节介绍了如何在Sec中为给定的场景获得良好构造的3D高斯,即3D GS的优化过程。
3.1 Rendering with Learned 3D Gaussians
考虑一个由(数百万)个优化的3D高斯表示的场景。其目标是由指定的相机位姿生成一幅图像。回忆起NeRFs通过计算要求的体积射线匹配,每像素采样3D空间点来实现这一任务。这种范式与高分辨率图像合成相矛盾,无法实现实时渲染,特别是对于计算资源有限的平台 96 。相比之下,3D GS首先将这些3D高斯投影到一个基于像素的图像平面上,这个过程被称为"抛雪球" 316、318 ( c. f.图4b)。然后,3D GS对这些高斯进行排序,并计算每个像素的值。如图4所示,NeRFs和3D GS的渲染可以看作是彼此的逆过程。接下来,我们从定义3D高斯开始,它是3D GS中场景表示的最小元素。接下来,我们描述了这些3D高斯如何用于可微渲染。 最后,我们介绍了3D GS中使用的加速技术,这是快速渲染的关键。
• Properties of 3D Gaussian.
一个3D高斯由其中心(位置) μ,不透明度α,3D协方差矩阵Σ和颜色c来表征。c用球谐函数表示,与视角相关。所有属性都是可学习的,并通过反向传播进行优化。
• Frustum Culling
给定一个指定的相机位姿,该步骤确定哪些3D高斯在相机的视锥体之外。通过这样做,给定视图之外的3D高斯将不参与后续计算。
• Splatting
在这一步中,三维空间中的3D高斯(椭球)被投影到2D图像空间(椭圆)。投影过程包括两个变换:首先,利用视角变换将3D高斯从世界坐标转换到相机坐标,然后通过投影变换的近似将这些高斯散布到2D图像空间。在数学上,给定描述3D高斯空间分布的3D协方差矩阵Σ和观察变换矩阵W,通过计算2D高斯投影的2D协方差矩阵Σ′。
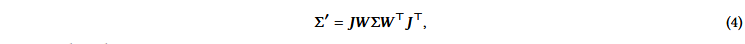
其中J是射影变换 96、316 的仿射逼近的Jacobian。不禁要问,为什么这里不使用基于标准相机内参数的射影变换。这是因为它的映射不是仿射的,因此不能直接投影Σ。3D GS采用文献 316 提出的仿射变换,利用泰勒展开式(见Sec . 4 . 4 in 316 )的前两项(包括J )近似射影变换。
• Rendering by Pixels.
在研究3D GS的最终版本之前,我们首先详细阐述了它的更简单的形式,以便深入了解它的基本工作机制。给定一个像素x的位置,它与所有重叠高斯的距离,即这些高斯的深度,可以通过观察变换矩阵W来计算,形成一个排序的高斯列表N,然后使用α混合来计算该像素的最终颜色:
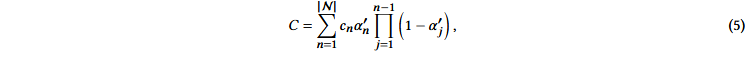
其中cn是学习过的颜色。最终的不透明度α′n是学习到的不透明度αn和高斯的乘法结果,定义如下:
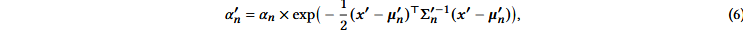
其中x′和μ′n是投影空间中的坐标。一个合理的担忧是,与NeRFs相比,所描述的渲染过程可能较慢,因为生成所需的排序列表是很难并行化的。诚然,这种担忧是有道理的;当使用这种简单的逐像素方法时,渲染速度会受到很大的影响。为了实现实时渲染,3DGS做出了一些让步以适应并行计算。
• Tiles (Patches).
为了避免对每个像素求高斯的成本计算,3D GS将精度从像素级转移到面片级细节,其灵感来自于基于瓦片的栅格化 106 。具体来说,3D GS最初将图像划分为多个互不重叠的图块(图块)。图3b提供了瓦片的插图。每个瓦片由16 × 16像素组成,如文献 96 所述,3DGS进一步确定哪些瓦片与这些投影的高斯相交。考虑到一个投影高斯可能覆盖多个瓦片,一种逻辑方法涉及复制高斯,为每个副本分配一个标识符(即,一个瓦片ID)用于相关的瓦片。
• Parallel Rendering.
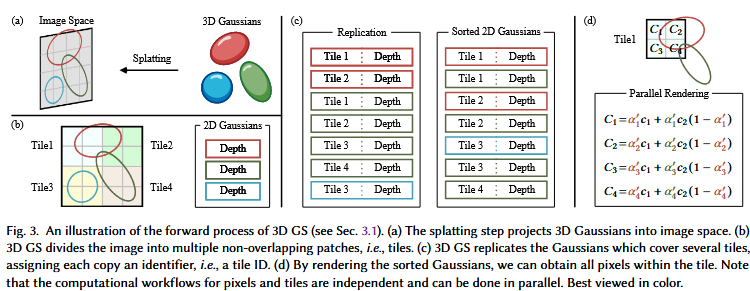
复制后,3D GS将各自的瓦片ID与每个高斯从视图变换中获得的深度值相结合。这导致了一个未排序的字节列表,其中上位代表瓦片ID,下位代表深度。通过这样做,排序列表可以直接用于渲染(即, alpha复合)。图3c和图3d提供了这些概念的可视化展示。值得注意的是,渲染每个瓦片和像素是独立发生的,这使得这个过程非常适合并行计算。另外一个好处是,每个瓦片的像素可以访问一个公共的共享内存,并保持一个统一的读取序列(图5 ),从而可以并行执行alpha合成,提高了效率。在官方实现原文 96 ,该框架将瓦片和像素的处理分别类比为CUDA编程架构中的块和线程。
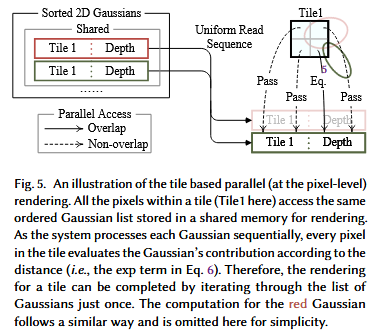
简而言之,3D GS在渲染过程中引入了一些近似,以提高计算效率,同时保持高标准的图像合成质量。
3.2 Optimization of 3D Gaussian Splatting
3DGS的核心是设计一个优化过程,以构建一个丰富的3D高斯集合,以准确地捕捉场景的本质,从而促进自由视点绘制。一方面,通过可微的光栅化来优化3D高斯的属性,以拟合给定场景的纹理。另一方面,能够很好地表示给定场景的3D高斯个数是事先未知的。下面介绍如何优化Sec中每个高斯的性质。3 . 2 . 1以及如何自适应地控制Sec中高斯的密度。3 . 2 . 2 .这两个过程在优化工作流中交错进行。 由于在优化过程中有许多手动设置的超参数,为了清晰起见,我们省略了大部分超参数的符号。
3.2.1 Parameter Optimization
• Loss Function.
一旦完成图像的合成,就可以测量渲染图像与真实图像之间的差异。利用l1和D - SSIM损失函数对所有可学习参数进行随机梯度下降优化:
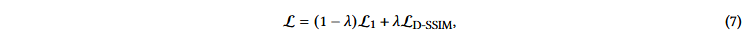
• Parameter Update.
3D高斯函数的大部分性质可以直接通过反向传播来优化。值得注意的是,直接优化协方差矩阵Σ会导致非半正定矩阵,这将不符合通常与协方差矩阵相关的物理解释。为了避免这个问题,3D GS选择优化一个四元数q和一个3D向量s。式中:q和s分别表示旋转和尺度。该方法允许协方差矩阵Σ重构如下:
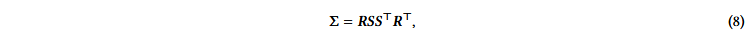
式中:R为由四元数q导出的旋转矩阵,S为由diag ( s )给出的缩放矩阵。可以看到,有一个复杂的计算图来获得不透明度α,即q和s↦→Σ,Σ↦→Σ′,Σ′↦→α。为了避免自动微分的代价,3D GS导出了q和s的梯度,以便在优化过程中直接计算它们。
3.2.2 Density Control.
• Initialization
3D GS从SfM或随机初始化的稀疏点的初始集合开始。需要注意的是,良好的初始化对收敛性和重建质量至关重要 29 。然后,采用点稠密化和剪枝来控制3D高斯的密度。
29 Kai Cheng, Xiaoxiao Long, Kaizhi Yang, Yao Yao, Wei Yin, Yuexin Ma, Wenping Wang, and Xuejin Chen. 2024. GaussianPro: 3D Gaussian Splatting with Progressive Propagation. In Proc. ACM Int. Conf. Mach. Learn.
• Point Densification
在点稠密化阶段,3D GS自适应地增加高斯的密度,以更好地捕捉场景的细节。该过程关注于几何特征缺失的区域或高斯过于分散的区域。致密化过程将以(即,经过一定次数的训练迭代)为间隔进行,重点关注那些具有大视野空间位置梯度(也就是说,超过某一特定阈值)的高斯。要么在欠重建区域克隆小高斯,要么在过重建区域拆分大高斯。为了进行克隆,创建一个高斯的副本,并向位置梯度移动。对于分裂,用两个较小的高斯代替一个大的高斯,通过一个特定的因子减小它们的尺度。该步骤寻求高斯在三维空间中的最优分布和表示,提高了重建的整体质量。
• Point Pruning
点剪枝阶段涉及去除多余的或影响较小的高斯,可以看作是一个正则化过程。它是通过消除在世界空间或视图空间中实际上是透明的(当α低于某一特定的阈值时)和那些过大的高斯来执行的。此外,为了防止输入相机附近的高斯密度不合理地增加,高斯的alpha值在一定的迭代次数后被设置为接近于零。这允许可控地增加必要的高斯密度,同时实现冗余高斯的剔除。 该过程不仅有助于节省计算资源,而且可以确保模型中的高斯对场景的表示保持精确和有效。
4 3D GAUSSIAN SPLATTING: DIRECTIONS
尽管3D GS已经取得了令人印象深刻的里程碑,但仍有很大的改进空间,例如数据和硬件需求,渲染和优化算法,以及在下游任务中的应用。在接下来的章节中,我们试图对所选取的扩展版本进行阐述。这些是:I )稀疏输入的3DGS ( Sec。4 . 1 ),II )存储高效的3DGS( Sec。4 . 2 ),III )真实感3DGS( Sec。4 . 3 ),IV )改进的优化算法( Sec。4 . 4 ),V )具有更多特性的3D Gaussian ( SEC . 4 . 5 )、VI )混合表示 ( Sec。4 . 6 )、Vii )新的渲染算法( Sec。4 . 7 )。虽然我们谨慎地选择了几个关键的方向,但我们承认这不可避免地是一种偏颇的观点。在Github中给出了一个更全面的集合.
4.1 3DGS for Sparse Input
三维GS一个值得注意的问题是在观测数据不足的区域出现伪影。这一挑战是辐射场绘制中普遍存在的限制,其中稀疏数据往往导致重建不准确。从实际的角度来看,从有限的视点重建场景是非常有意义的,特别是对于用最少的输入来增强功能的潜力。
现有的方法可以分为两类。i )基于正则化的方法引入额外的约束,如深度信息,以增强细节和全局一致性 27、116、284、310。例如,DN Gaussian 116 引入了深度正则化方法来解决稀疏输入中的几何退化问题。FSGS 310 设计了一个高斯去池化过程用于初始化,同时还引入了深度正则化。为了提供几何线索,MVSplat 27 提出了一种代价体积表示方法。不幸的是,当处理有限数量的视图,甚至只处理一个视图时,正则化技术的效果往往会降低,这就导致了ii )基于泛化能力的方法使用学习到的先验 21 , 217 , 218 , 253。 一种方法是通过生成模型来合成额外的视图,可以无缝地集成到现有的重建管道中 194 。然而,这种增强策略是计算密集型的,并且内在地受限于所使用的生成模型的能力。另一个著名的范例使用前馈高斯模型直接生成一组3D高斯的属性。这种范式通常需要多个视图进行训练,但仅用一幅输入图像就可以重建3D场景。例如,PixelSplat 21 提出从稠密的概率分布中采样高斯。溅泼Image 218 引入了一个2D图像到图像网络,将输入图像映射到每个像素的3D高斯。 然而,由于生成的像素对齐高斯在空间中分布几乎均匀,它们难以用适当数量的高斯来表示高频细节和更平滑的区域。
3D GS对稀疏输入的挑战集中在先验的建模上,无论是通过深度信息、生成模型还是前馈高斯模型。基本的权衡在于对可用视图的过拟合和使用学习到的先验进行泛化。未来的研究可以探索控制这种权衡的自适应机制,可能是通过学习的置信度、上下文感知的先验选择、用户偏好等。此外,虽然目前的方法侧重于静态场景,但将这些方法扩展到动态场景是一个令人兴奋的研究前沿,特别是在处理时间一致性和运动引起的伪影方面。
4.2 Memory-efficient 3DGS
虽然3D GS表现出卓越的能力,但其可扩展性带来了巨大的挑战,特别是与基于NeRF的方法并列时。后者得益于只存储学习到的MLP的参数的简单性。在大规模场景管理的背景下,这种可扩展性问题变得日益尖锐,其中计算和存储需求大幅增加。因此,迫切需要在模型训练和存储过程中优化内存使用。
最近的研究主要集中在两个方面来提高存储效率。首先,几种方法专注于减少3D高斯 26、108、167 的数量。这些方法要么使用低影响高斯的策略剪枝,例如基于体积的掩蔽 108 ,要么使用通过聚类 141 、哈希网格 26 等获得的"局部锚点"中存储的相同属性来表示相邻的高斯。其次,研究人员开发了压缩高斯特性 26、108、163 的方法。例如,Niedermayr等人 163 将颜色和高斯参数压缩到紧凑的码本中,使用敏感性度量进行有效的量化和微调。 HAC 26 使用高斯分布预测每个量化属性的概率,然后设计了一个自适应量化模块。这些方向并不是相互排斥的;相反,一个框架可能会使用多种策略相结合的混合方法。
虽然目前的压缩技术已经实现了显著的存储缩减率(常受10 - 20 ×的因素影响),但仍然存在一些挑战。该领域特别需要在训练阶段提高记忆效率,可能通过量化感知的训练协议,开发场景不可知的可重用码本等。此外,优化压缩效率和视觉保真度之间的权衡仍然是一个开放的问题。