Springboot多数据源配置
- 示例详解
- [@DS 注解](#@DS 注解)
SpringBoot 多数据源,指在单个 SpringBoot 应用中同时配置、管理并按需使用多个数据库连接(数据源) 的场景,每个数据源对应独立的数据库实例、不同库名,核心是解决单一数据源无法满足业务诉求的问题。
实际开发中常遇到多库场景如下:
主从分离:主库(master)负责写操作(insert/update/delete),从库(slave)负责读操作(select);
多业务库:不同业务模块对应不同的数据库;
分库分表:按规则拆分到不同数据库。
下面通过示例对springboot多数据源配置执行流程进行详细介绍
示例详解
基于 dynamic-datasource-spring-boot-starter 实现,该框架封装了 AbstractRoutingDataSource、AOP、ThreadLocal 等底层逻辑,是业界最常用的动态多数据源方案。
在 pom.xml 中添加依赖
xml
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.5.0</version>
</dependency>dynamic-datasource-spring-boot-starter 是 MyBatis-Plus 封装的轻量级组件,无需手动编写复杂的数据源路由代码,只需简单配置即可实现多数据源切换,是 Spring Boot 中多数据源的主流解决方案。
application.yml 配置文件配置多数据源

spring.datasource.dynamic 开启动态数据源配置,替代原生 spring.datasource 单数据源的配置逻辑
primary 用于指定默认数据源的别名,当代码中没有显式指定使用哪个数据源时,自动使用 master 数据源
strict 用于配置数据源匹配的严格模式,控制未匹配到指定数据源时的行为
datasource: {master/slave_1} 配置多个独立的数据源,每个子节点是数据源别名
product 表在 mybatis_plus 数据库里
java
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Product {
private Long id;
private String name;
private Integer price;
}
java
@Mapper
public interface ProductMapper extends BaseMapper<Product> {
}person 表在 springboot 数据库里
java
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
@TableId
private Long pid;
private String pname;
private String addr;
private Long gender;
private Date birth;
}
java
@Mapper
public interface PersonMapper extends BaseMapper<Person> {
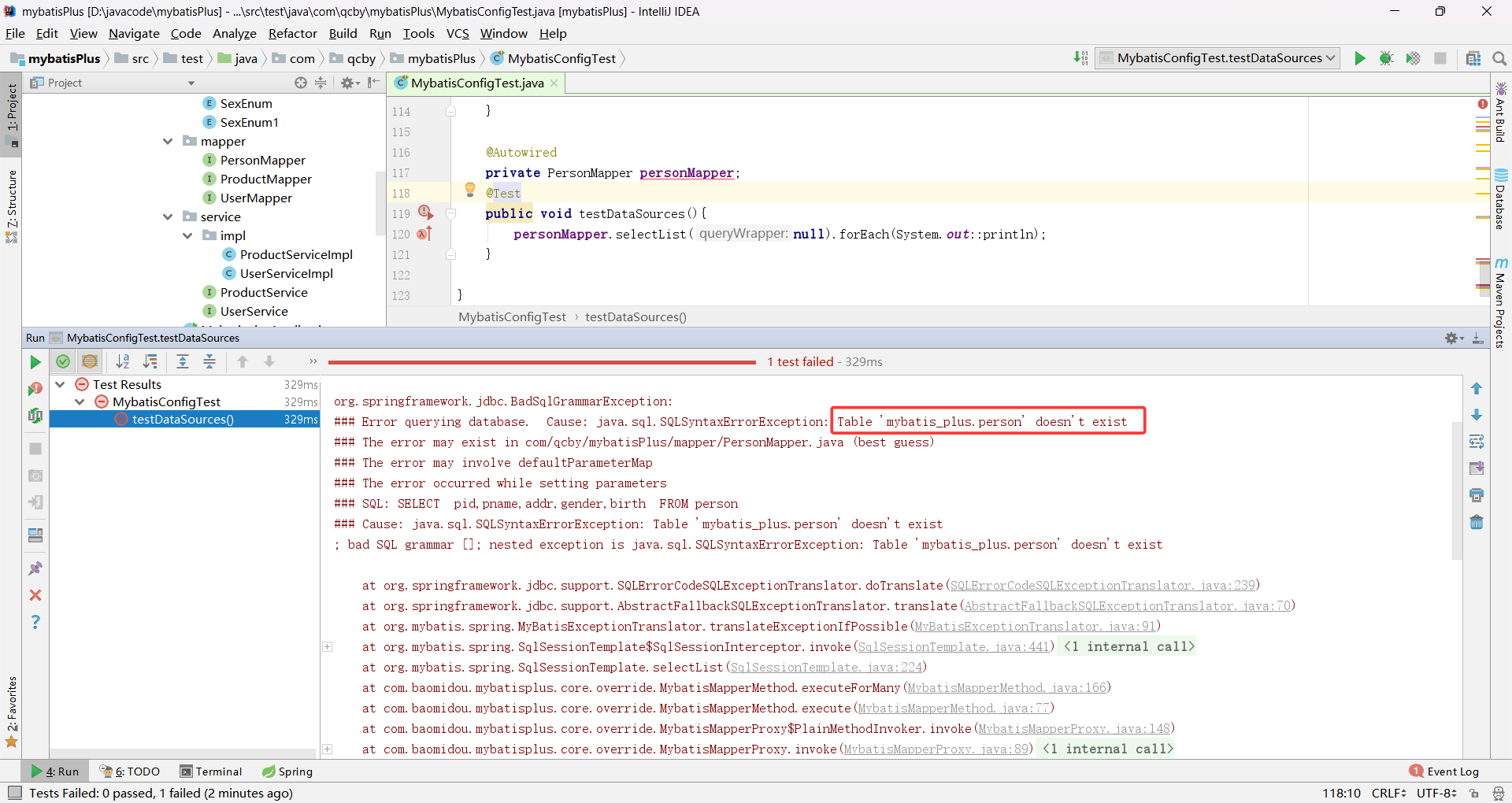
}当设置 primary: master 查找 person 表中的数据会报异常 Table 'mybatis_plus.person' doesn't exist
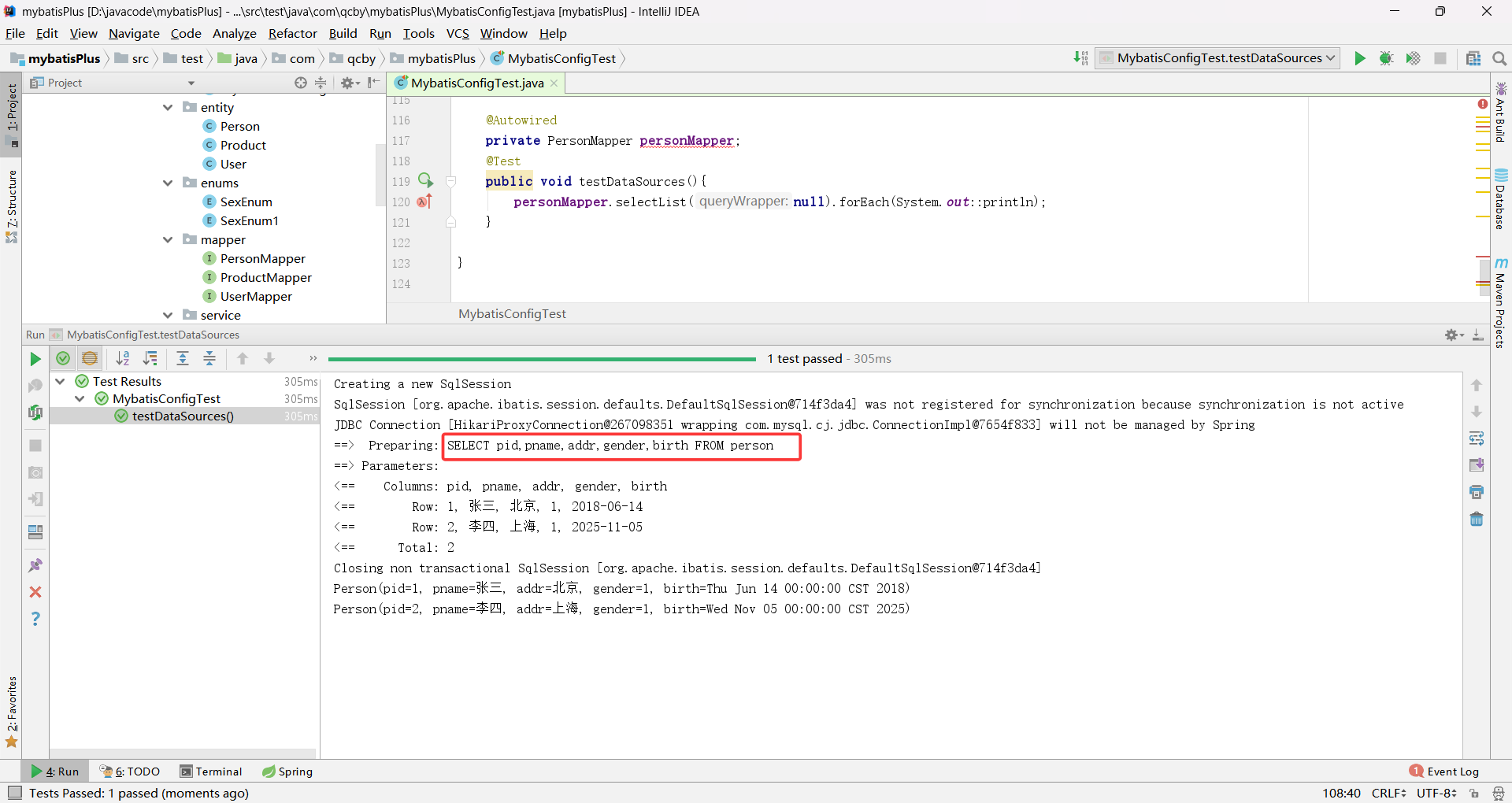
设置 primary: slave_1 查找 person 表中的数据即可成功
@DS 注解
@DS 注解是由多数据源框架 dynamic-datasource-spring-boot-starter 提供的声明式数据源路由注解,其核心是通过注解的 value 属性指定数据源标识(该标识与配置文件中预定义的数据源名称一一映射),以声明式方式明确注解标注范围内的数据库操作需路由至该标识对应的数据源执行,若未显式指定 value 或未标注该注解,则默认路由至框架配置的默认数据源。
在多数据源架构实践中,@DS 注解标注于 Service 层
java
public interface ProductService extends IService<Product> {
}
java
@DS("master")
@Service
public class ProductServiceImpl extends ServiceImpl<ProductMapper, Product> implements ProductService {
}
java
public interface PersonService extends IService<Person> {
}
java
@DS("slave_1")
@Service
public class PersonServiceImpl extends ServiceImpl<PersonMapper, Person> implements PersonService {
}在多数据源配置场景中,将 @DS 注解集中标注于 Service 层,而非延伸至 Mapper 层,核心原因可从分层职责、事务管理、执行效率三个层面逐层解析,确保逻辑连贯且贴合技术实现原理:
- 从核心职责与底层执行机制来看:Service 层是业务逻辑编排与事务控制的核心载体,是数据源选择的决策层;而 Mapper 层(DAO 层)的定位仅为 SQL 执行与数据对象映射,无需参与业务决策,其所需的数据库连接,本质是由底层的动态数据源提供。具体来说,框架会通过 AOP 机制拦截标注 @DS 的 Service 方法,在方法执行前,将注解指定的数据源标识存入 ThreadLocal 上下文,待 Mapper 层执行 SQL 时,动态数据源会自动从 ThreadLocal 读取该标识,进而路由至对应数据源获取连接,方法执行完成后,框架会自动清除 ThreadLocal 中的数据源标识,避免线程池复用导致的数据源污染。整个过程中,Mapper 层无需感知数据源的路由逻辑,仅需专注于 SQL 执行,因此无需额外修改。
- 从事务管理的一致性要求来看:Spring 中事务注解 @Transactional 通常与 Service 层绑定,而数据源选择需与事务上下文保持强一致性。若在 Service 层标注 @DS,可确保整个 Service 方法执行周期内,所有数据库操作(包括多次调用不同 Mapper 的场景)均复用同一数据源,从根本上规避事务内数据源切换引发的跨库事务失效、数据一致性异常等问题。反之,若将 @DS 标注于 Mapper 层,极易出现同一 Service 事务内不同 Mapper 调用指向不同数据源的情况,直接破坏事务的原子性与数据一致性,甚至导致事务回滚失效,违背事务管理的核心目标。
- 从执行流程与性能优化的角度来看:Service 层是 Mapper 层调用的上游入口,在 Service 方法执行前通过 AOP 完成数据源标识设置,能从源头保障整个业务流程的数据源统一;而若将数据源切换的拦截点置于 Mapper 层,会导致每次调用 Mapper 都触发一次数据源切换,这不仅会增加频繁切换带来的性能开销,还可能因同一业务流程内数据源反复变更,破坏数据访问逻辑的连贯性,引发数据读取不一致、SQL 执行异常等不可预期的问题。
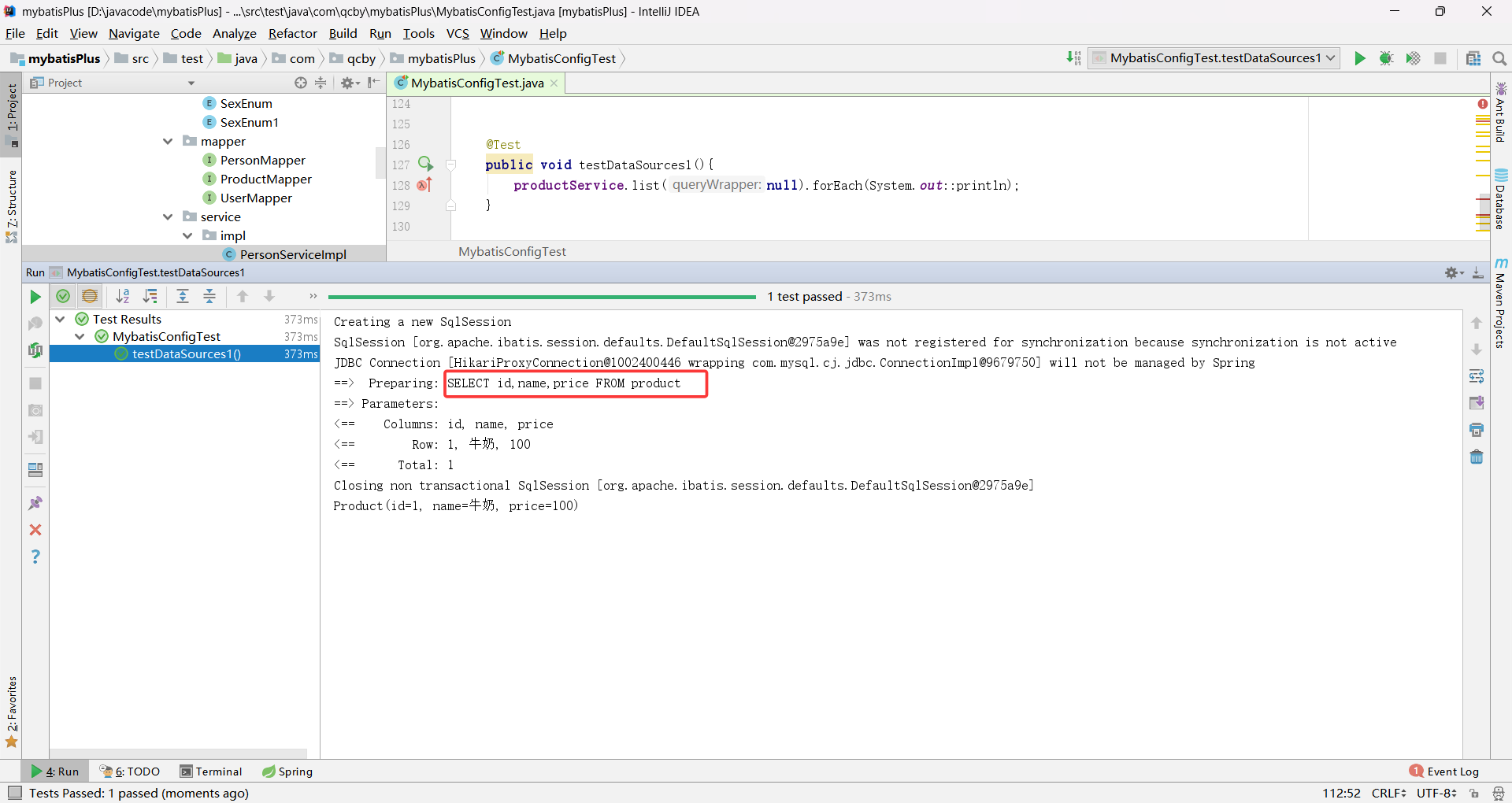
测试类:
java
@SpringBootTest
public class MybatisConfigTest {
@Autowired
private ProductService productService;
@Test
public void testDataSources1(){
productService.list(null).forEach(System.out::println);
}
}
java
@SpringBootTest
public class MybatisConfigTest {
@Autowired
private PersonService personService;
@Test
public void testDataSources2(){
personService.list(null).forEach(System.out::println);
}
}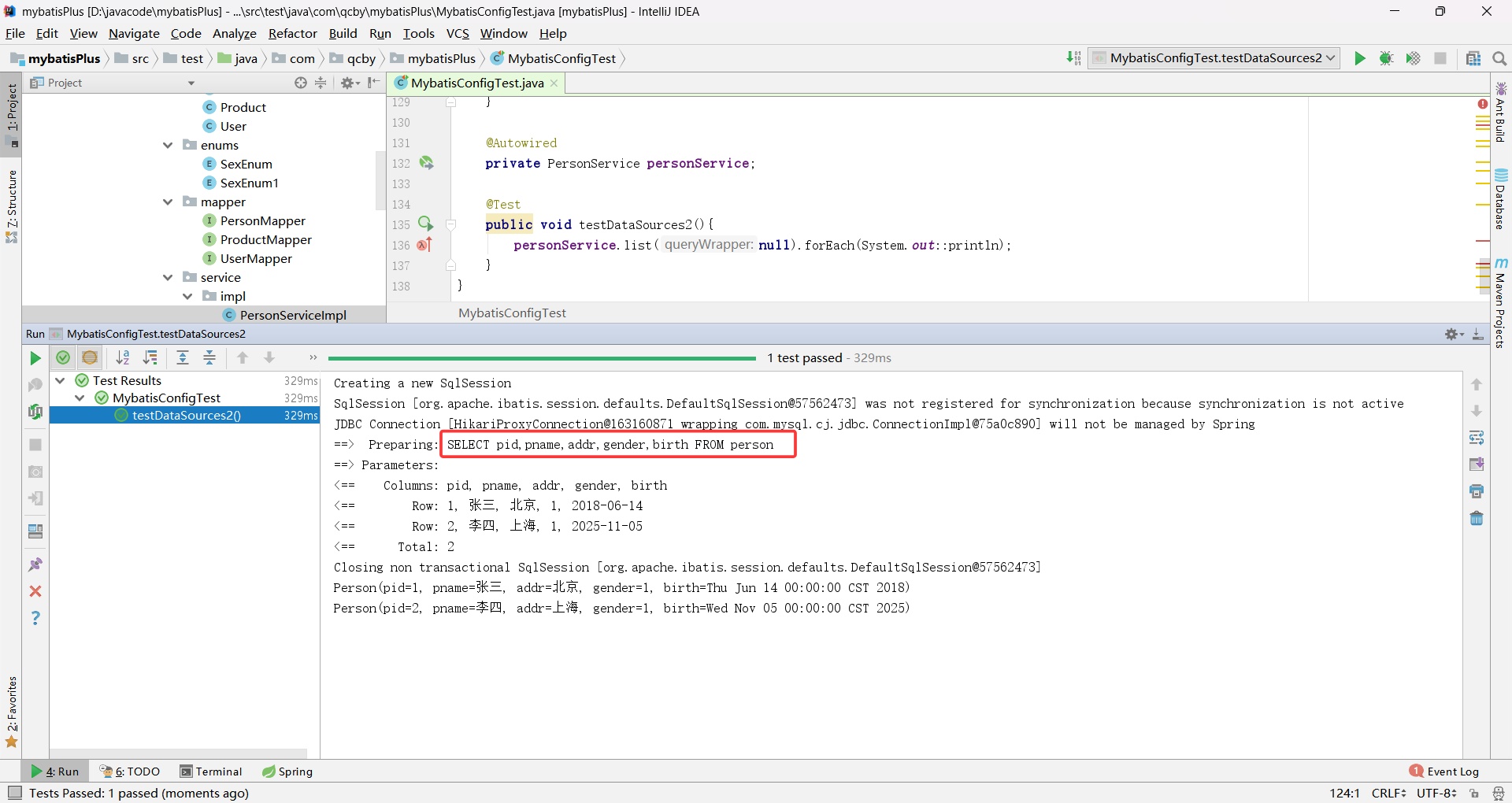
调用方法时框架自动将数据库连接切换到对应库,Mapper 层操作实体类的 SQL 会在目标库执行,全程无需修改实体类、Mapper 层代码,仅通过注解即可完成跨库操作。