
在深度学习的模型构建中,数据增强(Data Augmentation)通常被视为提升模型性能和鲁棒性的"关键武器"。然而,是否所有增强技术在任何情况下都能带来正向收益?模型架构的容量(Capacity)和卷积类型(Convolution Types)又如何影响增强技术的效果?
Sabeesh Ethiraj 和 Bharath Kumar Bolla 的研究论文 Augmentations: An Insight into their Effectiveness on Convolution Neural Networks 中深入探讨了数据增强、模型参数量与卷积类型之间的复杂关系,揭示了在不同场景下选择增强策略的一些依据。
打破"通用"的迷思
数据增强的能力通常取决于两个因素:模型架构和增强类型。这份工作展示出,增强技术具有很强的数据集特异性,并不是所有的增强手段都能必然产生正向效果。
随着移动端和边缘计算的需求增加,轻量级模型(如使用深度可分离卷积的模型)日益重要。目前,很少有研究专门评估增强技术、模型容量与卷积类型这三者之间的关系。因此,这份研究的核心目标在于:
- 寻找不变性(Invariance):识别那些无论架构、参数量如何变化,表现始终一致的增强技术。
- 评估卷积差异:对比标准 3x3 卷积与深度可分离卷积(Depth-wise Separable Convolutions)在不同增强下的表现。
- 探究容量效应:分析模型参数量的多少如何改变增强技术的效果(协同或对抗)。
从轻量到复杂的全面覆盖
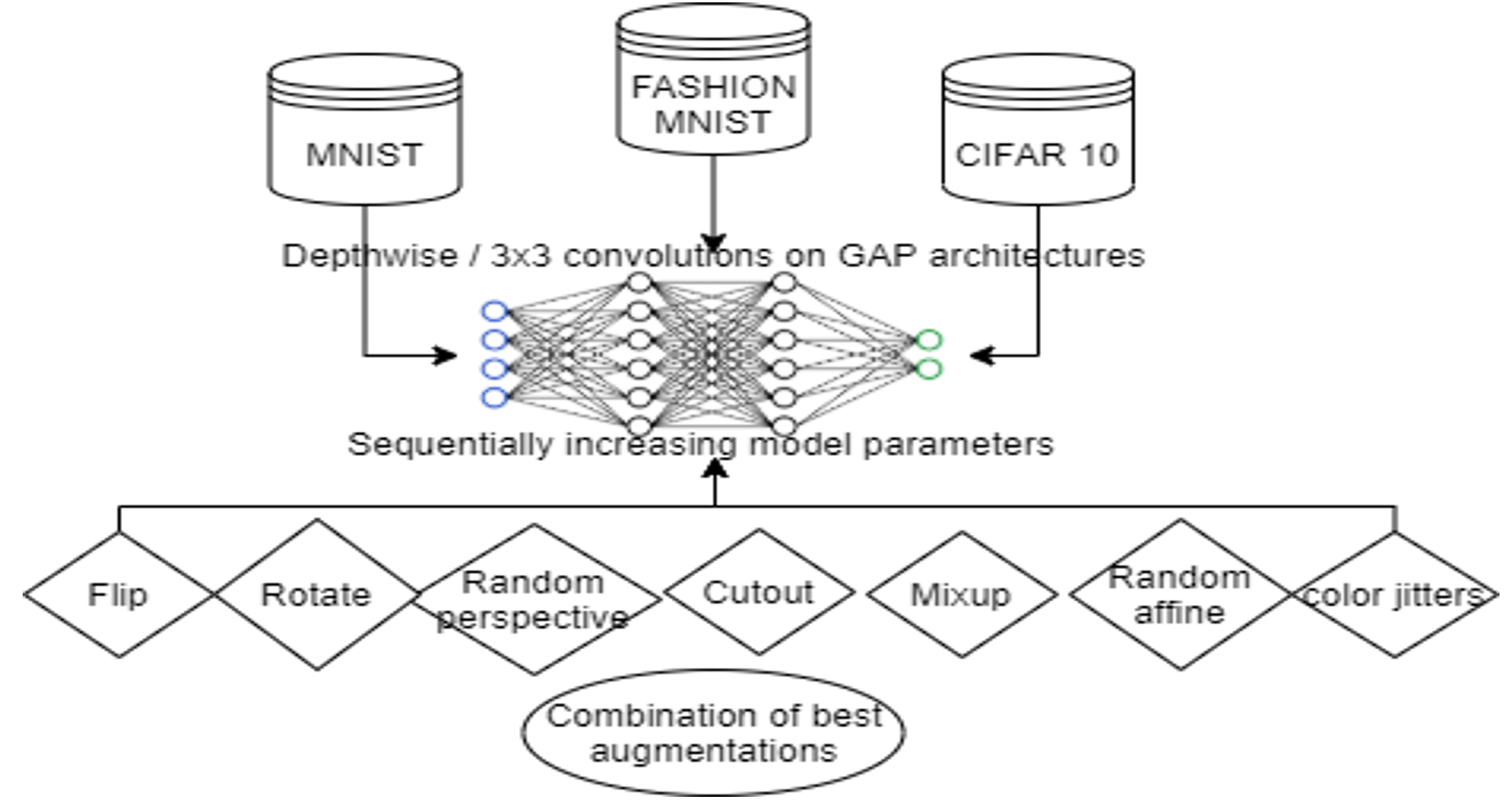
为了确保结论的普适性,研究设计了涵盖不同维度变量的实验 :
- 数据集:这份工作中,作者们选择了三个小规模,但是复杂度递增的数据集:
- MNIST(简单,灰度数字)
- Fashion MNIST (FMNIST)(中等,灰度服饰)
- CIFAR-10(较复杂,彩色物体)
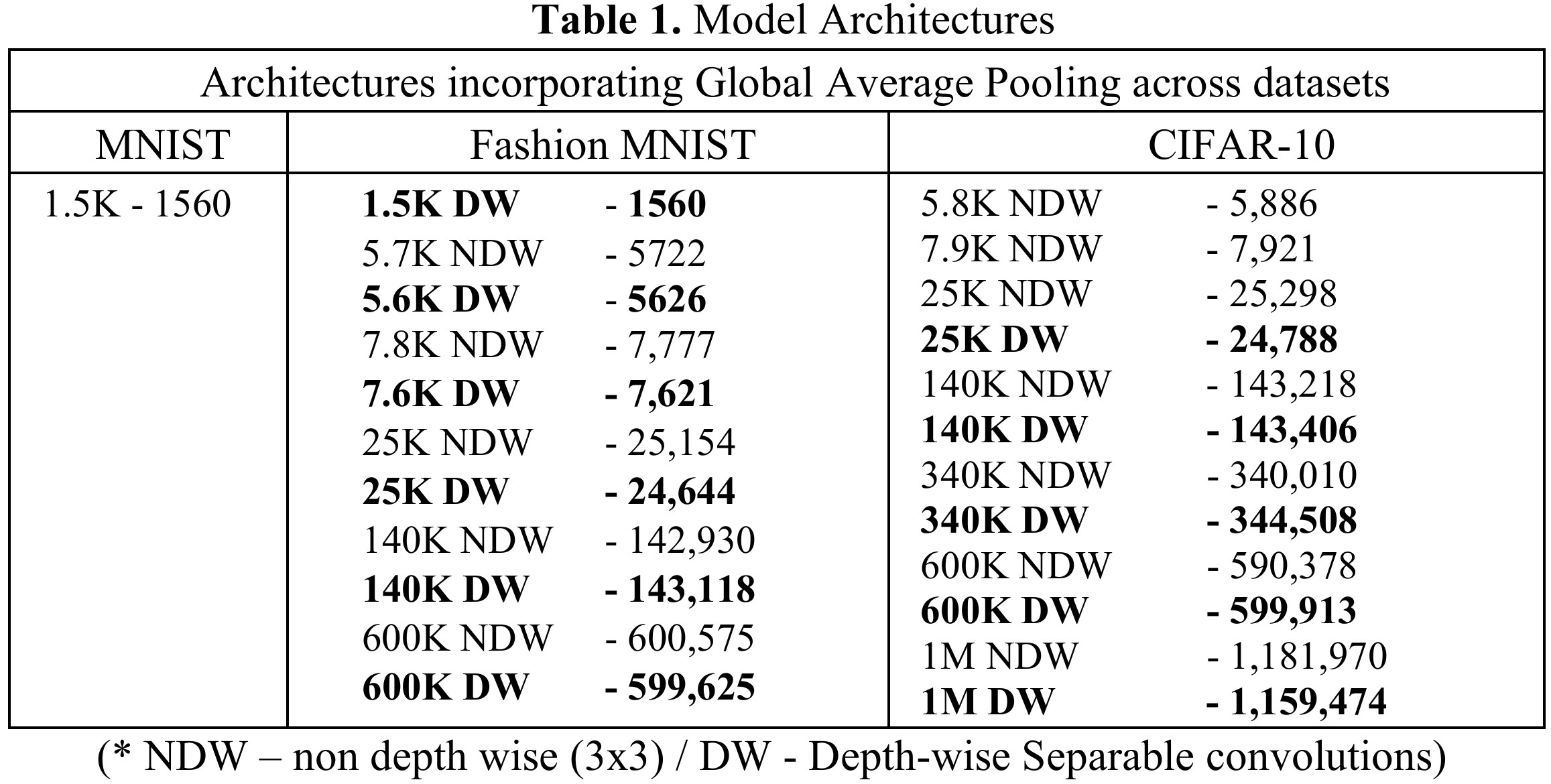
- 模型架构:作者们构建了一系列参数量从1.5K到1M+不等的模型。这些模型利用了全局平均池化(GAP)技术来减少参数,并分别使用了两种卷积模块进行对比:
- 标准 3x3 卷积
- 深度可分离卷积(Depth-wise Separable Convolutions):旨在通过结合深度卷积和点卷积来减少训练参数。
- 增强技术库:
- 基础变换:随机旋转 (Rotation, 10度范围内)、随机水平翻转 (Random Horizontal Flip)。
- 形变与色彩:随机仿射 (Random Affine)、随机透视 (Random Perspective)、颜色抖动 (Color Jitters)。
- 高级正则化:Cutout(随机遮挡 8x8 区域)、Mixup(混合样本与标签)。
实验发现
更一致的表现:Cutout 与水平翻转
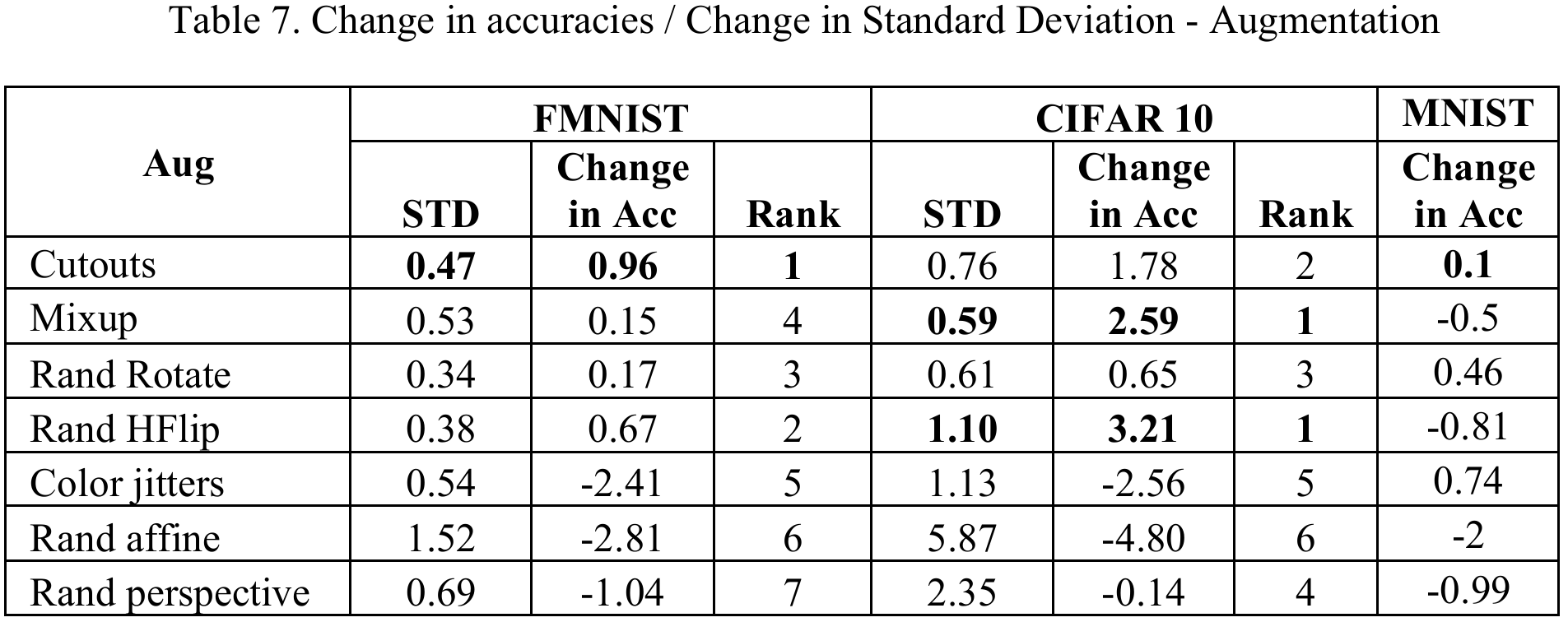
实验对不同架构应用了各种增强技术,并根据准确率变化的均值和标准差进行了排名。
- 最佳表现:Cutout和随机水平翻转是表现最一致的技术。无论模型容量或卷积类型如何变化,它们不仅能提升准确率,且标准差最小(稳定性高)。
- 增强悖论(Augmentation Paradox):并非所有增强都是有益的。随机仿射、颜色抖动和随机透视在 MNIST 和 FMNIST 数据集上表现出了负面影响,即所谓的"增强悖论"。
- Mixup的特异性:Mixup在CIFAR-10上取得了最高的准确率(归功于其类别分布),但在MNIST上反而降低了模型性能。
3x3 vs. 深度可分离卷积
研究揭示了参数量对卷积类型优劣的决定性影响:
- 低参数区间(Low Parameters):标准 3x3 卷积 优于深度可分离卷积。这是因为 3x3 卷积在浅层网络中具有更好的特征提取能力。
- 高参数区间(High Parameters):当参数量较高(如 >600K)时,深度可分离卷积 反超了 3x3 卷积。原因是深度可分离卷积在相同参数预算下允许构建更深的网络层数。
- 增强的弥合作用:有趣的是,数据增强能够显著缩小这两种卷积架构之间的准确率差距,尤其是在架构趋于饱和时。
参数量会影响模型对增强的敏感度
模型容量(参数量)直接影响了模型对增强技术的敏感度:
- 大模型的鲁棒性:随着参数量的增加,模型对"负面"增强技术(如颜色抖动、仿射变换)的抵抗力增强。统计数据显示,高参数架构的准确率标准差较低,意味着它们更能容忍不理想的增强策略。
- 小模型的脆弱性:在低参数模型中,负面增强技术的破坏力被放大,表现为标准差显著增加。
组合增强下的协同与对抗
当多种增强技术组合使用时,会发生什么?
- 协同效应(Synergistic Effect):在高参数模型上,组合多种正向增强技术(如 Cutout + Flip + Mixup)产生了叠加增益,效果优于单一技术。
- 对抗效应(Antagonistic Effect):在低参数模型上,组合增强反而导致性能下降。这是由于小模型的学习能力有限,过多的数据变异反而构成了学习障碍。
总结
这项研究着重关注了增强技术与模型架构关系的研究,也为实际工程应用提供了重要指导:
- 首选基线:Cutout、随机水平翻转和随机旋转等增强技术对参数数量和卷积类型的变化均表现出一致的稳定性。考虑到计算成本和训练时间的权衡,随机水平翻转(Random Horizontal Flip)是一个简单且高效的基线选择,它在绝大多数情况下表现稳定。
- 轻量级模型的策略:对于部署在移动端、参数量较小的模型,应谨慎使用复杂的组合增强,因为这可能引发对抗效应。3x3 卷积在超低参数下可能表现更好(尽管在参数较少的架构上3x3卷积表现更优,但增强技术的应用有效弥合了这些架构之间的准确率差距)。
- 深层网络的优势:在过参数化架构上,多种增强技术的组合表现出良好效果,所有情况下均观察到协同效应。如果计算资源允许增加参数,使用深度可分离卷积构建更深的网络,并配合组合增强技术(如 Cutout + Mixup),能最大化模型的泛化能力。
- 平衡的艺术:在任何深度学习任务中,都需要在架构优势(如参数量、深度)和数据增强之间取得微妙的平衡,盲目堆叠增强技术并非总是有效。