摘要
本周课程介绍了领域自适应(Domain Adaptation)的基本概念与必要性。当训练数据与测试数据分布不一致时,模型性能会显著下降,领域自适应旨在解决此问题。课程重点讲解了领域对抗训练方法,通过特征提取器与领域分类器的对抗学习,使模型学习到领域不变的特征表示,从而提升模型在新数据分布上的泛化能力。
Abstract
This week's lesson introduces the basic concepts and necessity of Domain Adaptation. When the distribution of training data differs from that of test data, model performance drops significantly. Domain Adaptation aims to address this issue. The lesson focuses on the Domain Adversarial Training method, where adversarial learning between a feature extractor and a domain classifier enables the model to learn domain-invariant feature representations, thereby enhancing the model's generalization ability on new data distributions.
一.领域自适应的必要性
到目前为止学习了解到许多机器学习的模型,所以训练分类器完全不是一个问题。若要训练一个数字分类器,只要有训练资料就可以训练好一个模型然后应用在测试资料上就结束了。
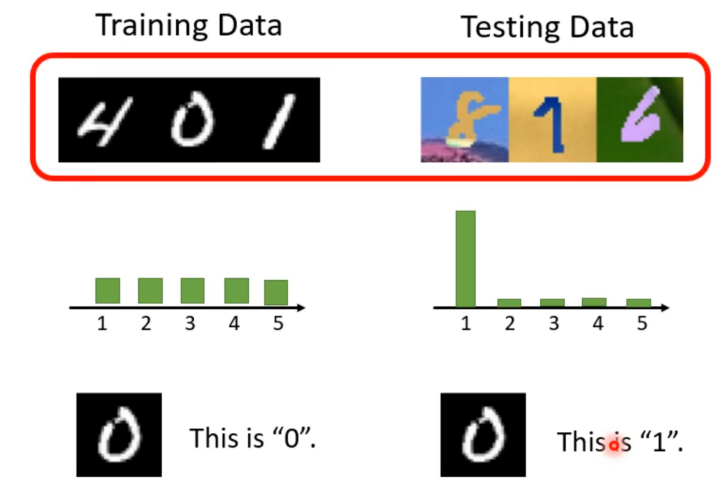
所以像数字辨识这么简单的问题,在基准语料库(Benchmark Corpus)上实现正确率就可以达到99.5%,但是假设现在测试资料与训练资料的分布不一样这时得到的正确率就会非常低,只有57.5%。

而这种训练资料与测试资料分布不一样的情况就称为领域偏移(Domain Shift)。因为在正常情况下训练资料与测试资料的分布是一样的,这就会导致模型正确率很高的错觉。而在实际上用在真实应用上时,当测试资料与训练资料有一点差异时模型能不能做的好就是未知数了。
为了让在训练资料与测试资料分布不一样的情况下的结果能够更好,这就要用到领域自适应的技术。
二.领域自适应分类
领域自适应技术也可以看作是迁移学习(Transfer Learning)的一种。同时领域自适应也有学多种类型,前面说到的只是其中一个模型输入的资料分布变化的情况。输入分布有变化是一种可能性,对应到另外一个可能性------输出的分布变化。还有一种更罕见的状况就是输入与输出的分布可能是一样的,但是它们之间的对应关系发生变化。
而我们这里就专注输入资料分布发生变化。后面就认为训练资料来自源领域,测试资料来自目标领域。目前情况就是有一部分有标注的训练资料来自源领域,但是现在的目标是在这些资料上训练出来的模型可以用在不一样的领域上。
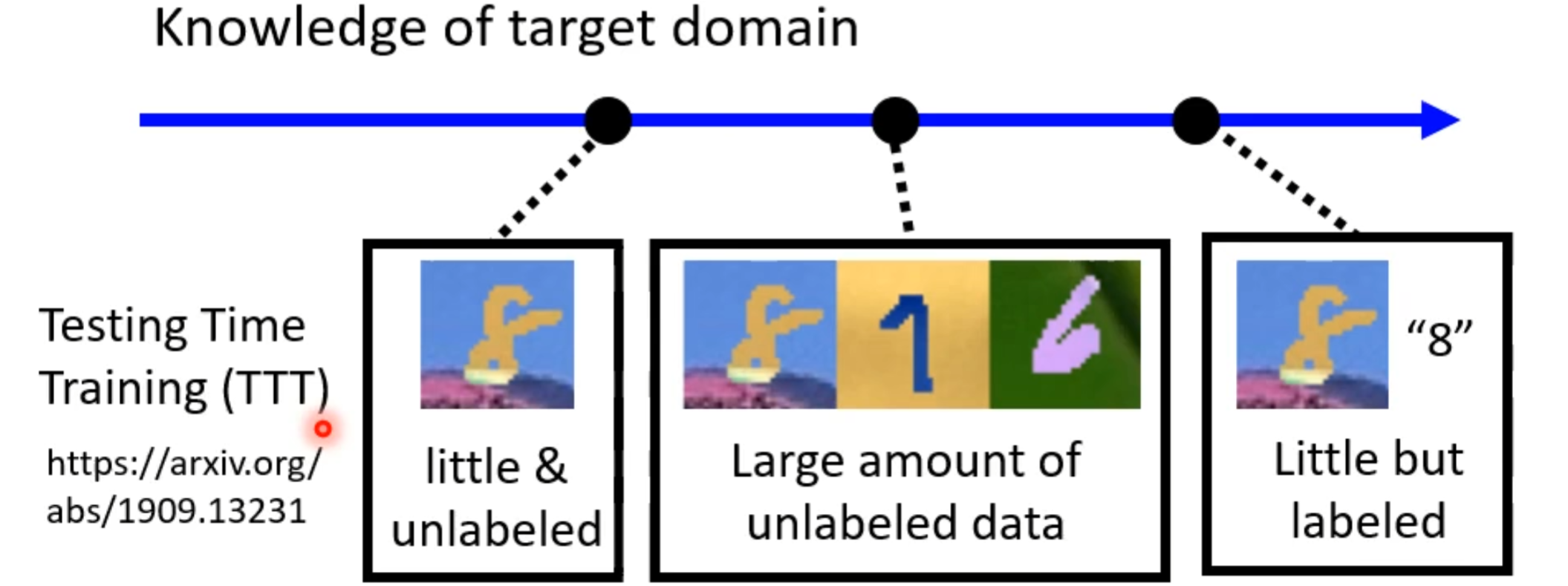
若要将模型用在不一样的领域上,在训练时就必须要对另外一个领域也就是测试资料所在的目标领域有所了解,随着了解的不同我们就会有不同的领域自适应方法。
了解最多的就是假设在目标领域上有点资料并且有对应标签,这种状况在领域自适应里面比较容易处理的,这时我们就可以通过这些有标注资料对训练好的模型进行微调。但是在这种情况下因为已知的目标资料量非常少,所以在这些资料上不要过多迭代,要小心避免过拟合。
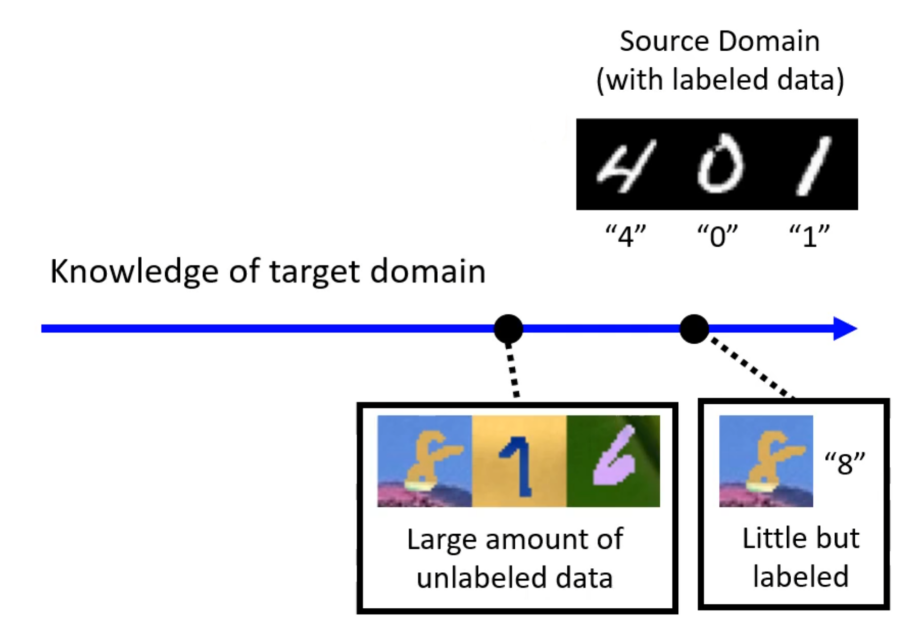
而本次主要了解的情况就是在,目标领域上有大量资料但是没有是没有对应标注的。
三.领域自适应的简单实现
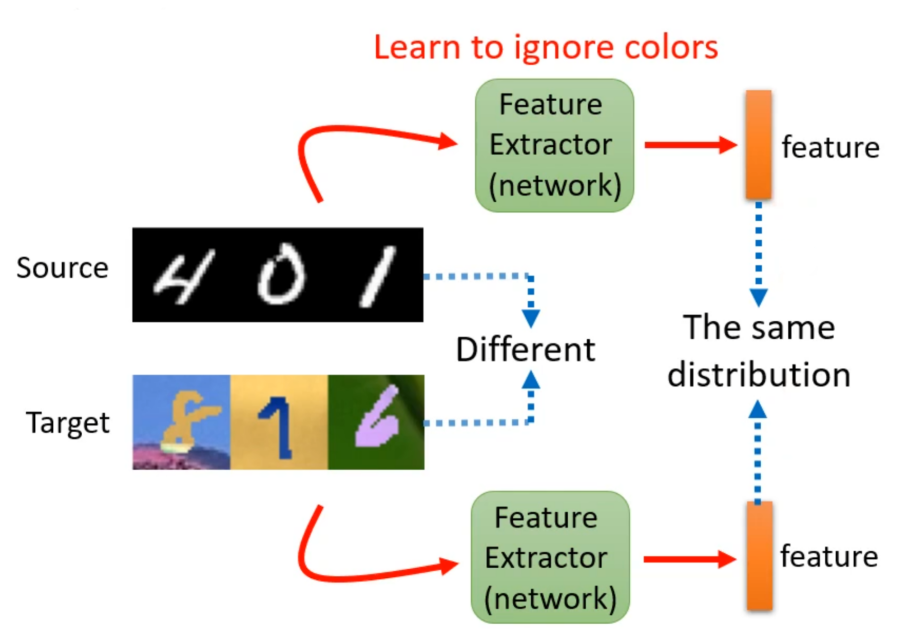
对于这种情况最基础的想法就是找一个特征提取器(Feature Extractor)。特征提取器其实也是一个网络,这个network拿一个图片作为输入,然后输出一个向量。虽然源和目标领域表面上看着不一样,但是特征提取器会除去它们不一样的部分,只取出它们共同的部分,也就是无视颜色问题。
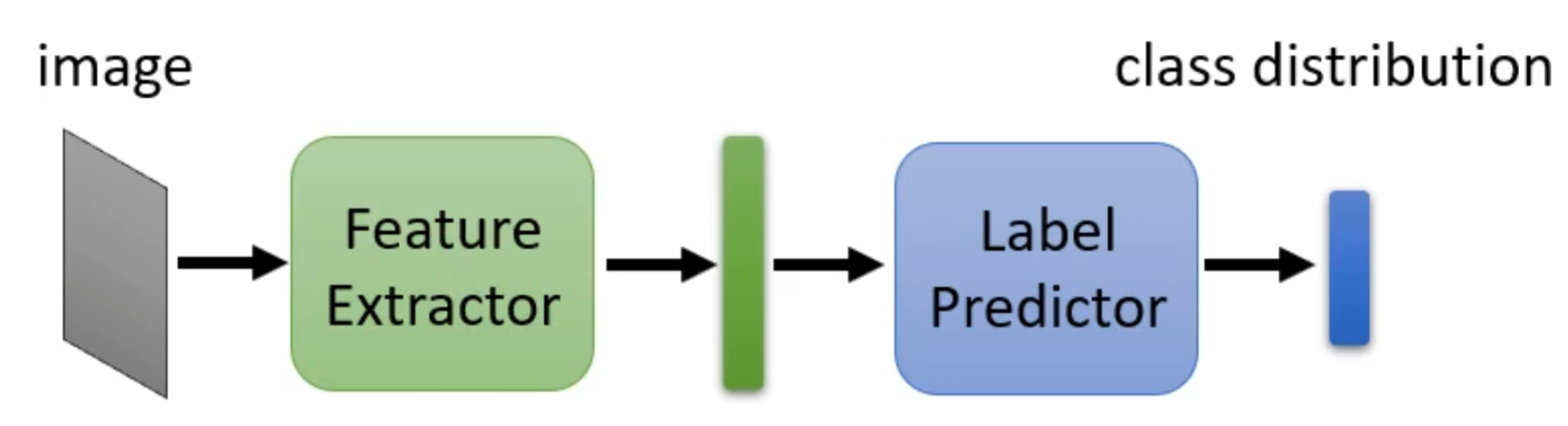
现在的问题就转为如何找出这样的特征提取器,对此我们可以将一个一般的分类器分成特征提取器和标签预测器(Label Predictor)两个部分。就如图像分类器其就是输入一张图片然后输出其分类结果,若其有十层,我们可以假设前五层为特征提取器后五层为标签预测器。
对于这两部分的训练,源领域中的资料是有标签的,从而对源领域资料进行训练时就是和训练一般分类器一样,通过特征提取器和标签预测器后产生正确答案。但是对于目标领域中的资料由于没有标签,所以不能像上面一样正常训练,而是将这些资料输入进特征提取器得到的向量拿出希望与源领域中资料通过特征提取器得到的对应向量之间没有差异。
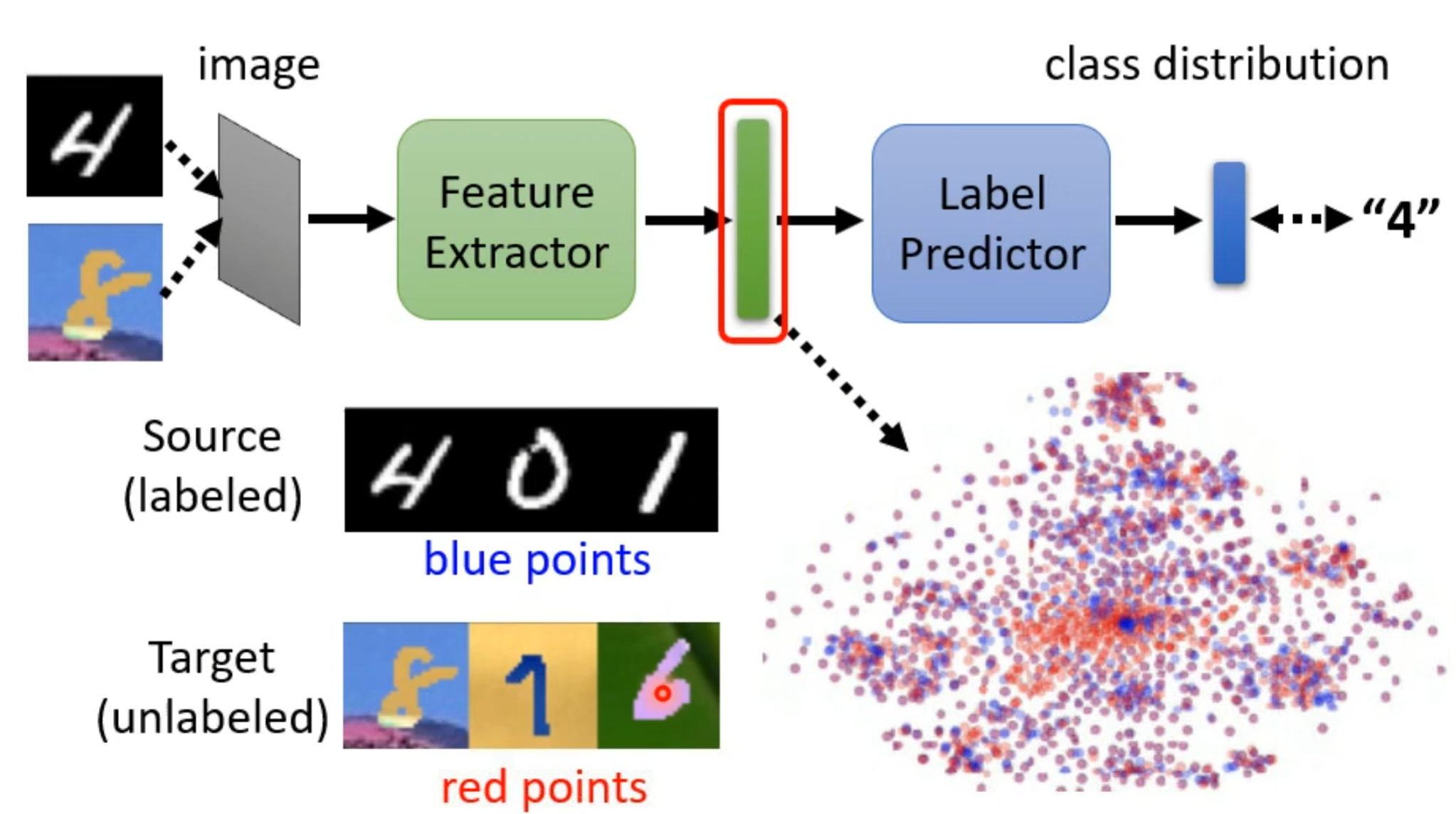
就如上图,为了使得蓝点与红点之间分不出差异就要用到领域对抗训练技术(Domain Adversarial Training)。就是再训练一个领域分类器,其输入是特征提取器输出的向量,并对这向量进行判断是来自源领域还是目标领域。而特征提取器的学习目标就是要骗过领域分类器。
这就与之前学习的生成对抗网络非常相似,其中特征提取器就对应生成器,标签预测器就对应判别器。
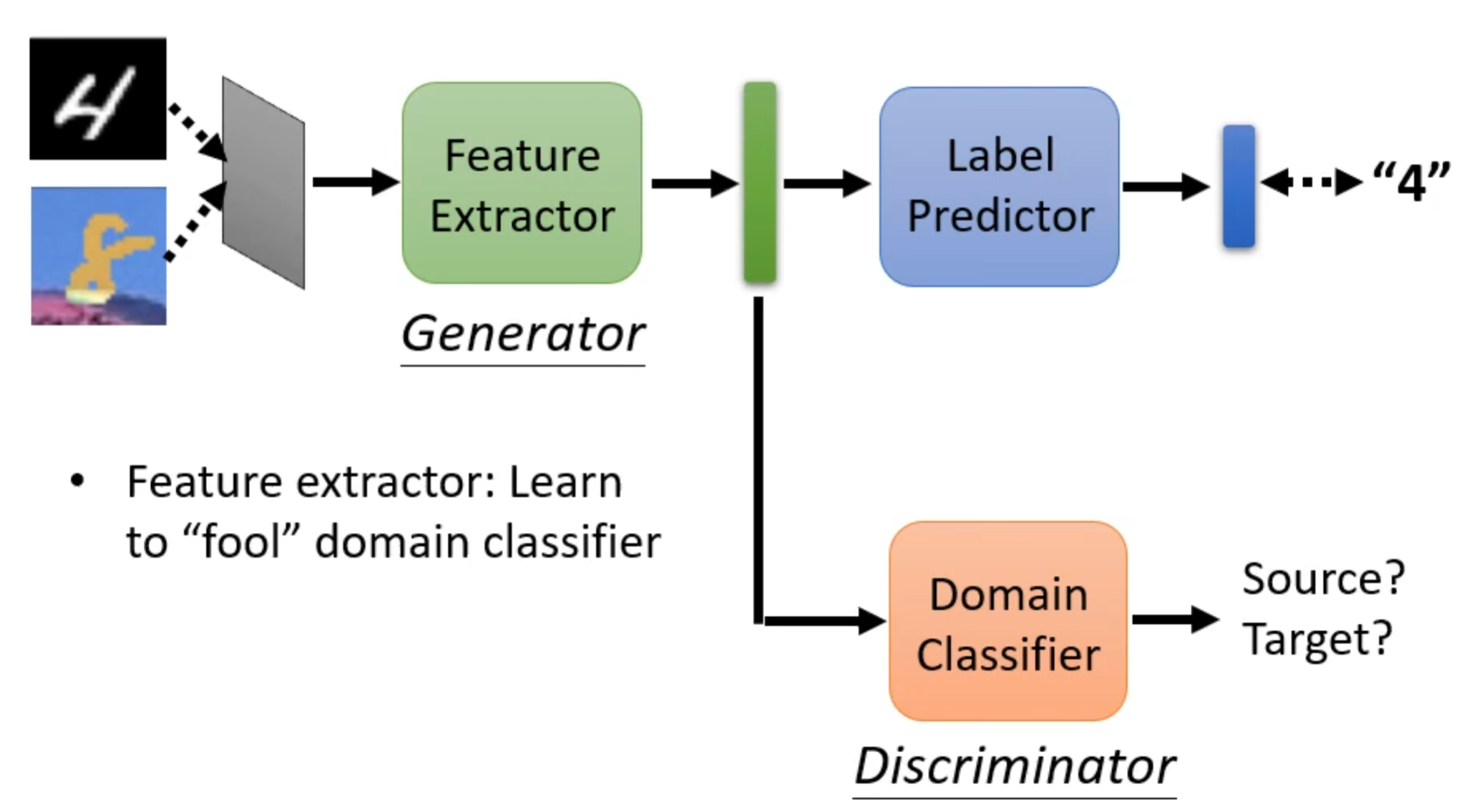
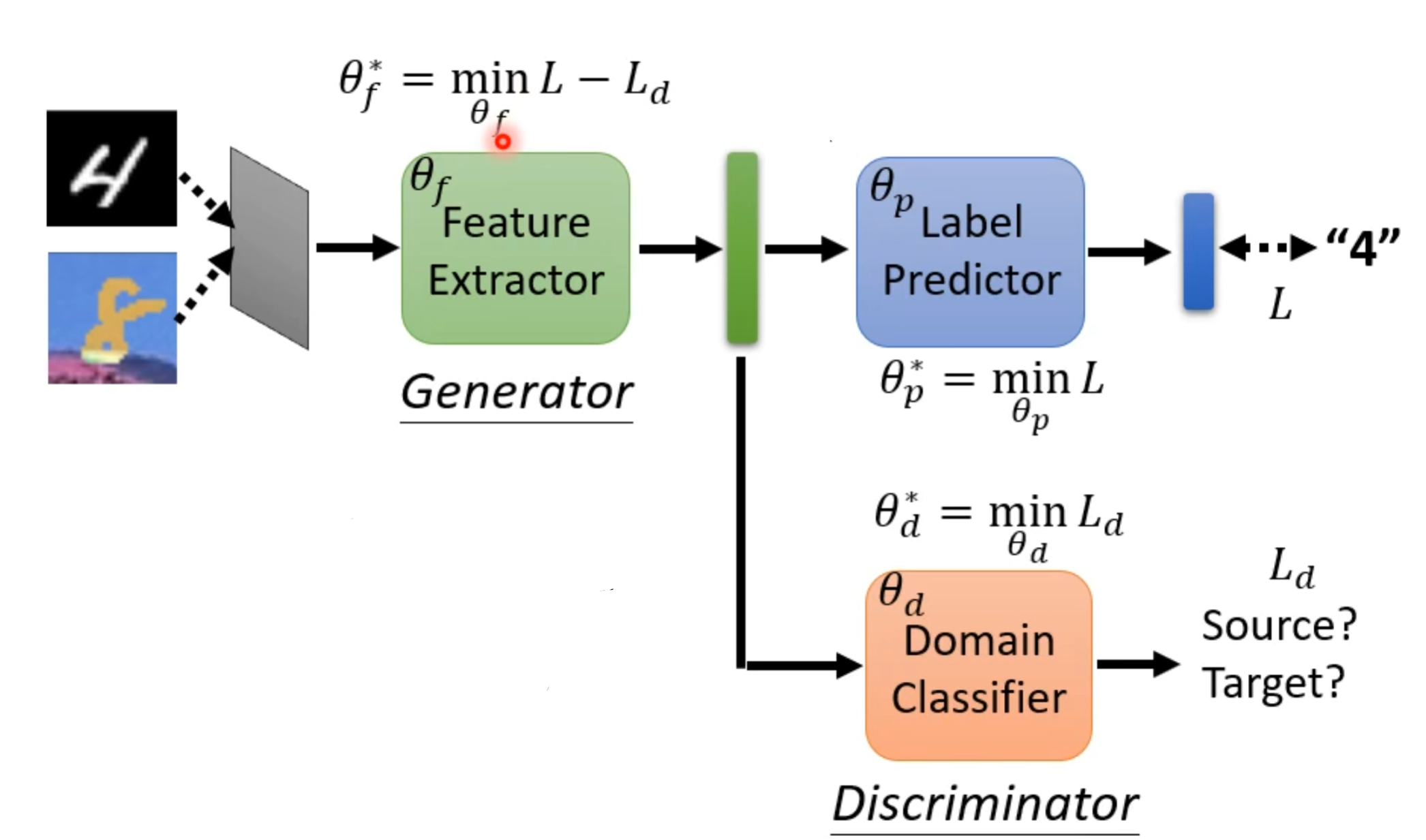
现在再用符号进行表示,令标签预测器参数为θp,领域分类器参数为θd,特征提取器参数为θf。对应前面内容就是如下图:
接着我们就看看在原始论文中领域对抗训练的结果如何。
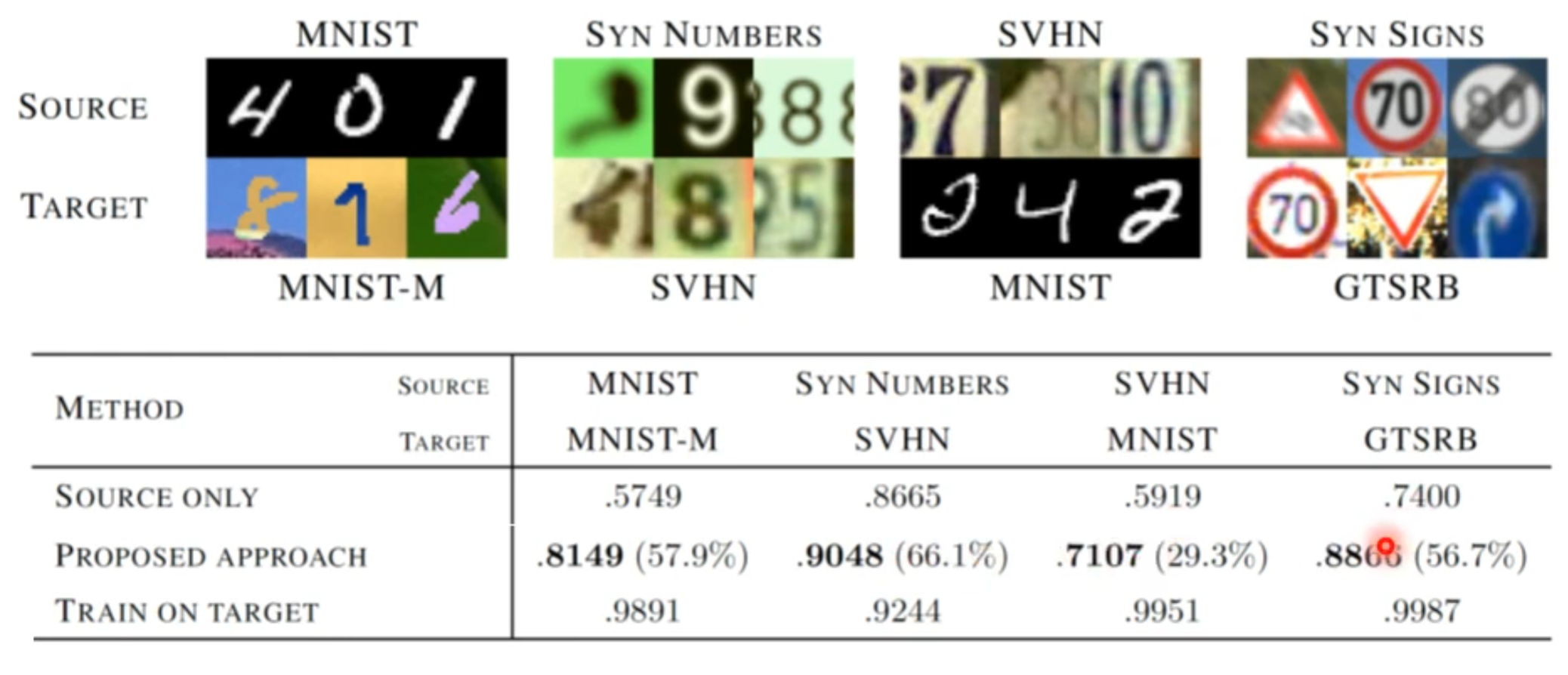
我们可以看到图片中上半部分是源领域的图片,下半部分是目标领域的图片。如果是拿目标领域中的图片进行训练,源领域中图片作为测试则结果是表格中最后一行,每个任务正确率都有90%以上,若反过来则最后的正确率就掉了很多,也就是表格中的第一行。但是做了领域对抗训练之后正确率就会有所提升,也就是表格中的第二行。
但是上面这个想法还是有点小问题,就如下面所表示。
以蓝色的圆与三角形代表源领域上的两个分类,并用边界将两者分开,对于目标领域就只有一个方块类别。而我们的训练目标就是要让正方形的分布与圆和三角形合起来的分布越接近越好。
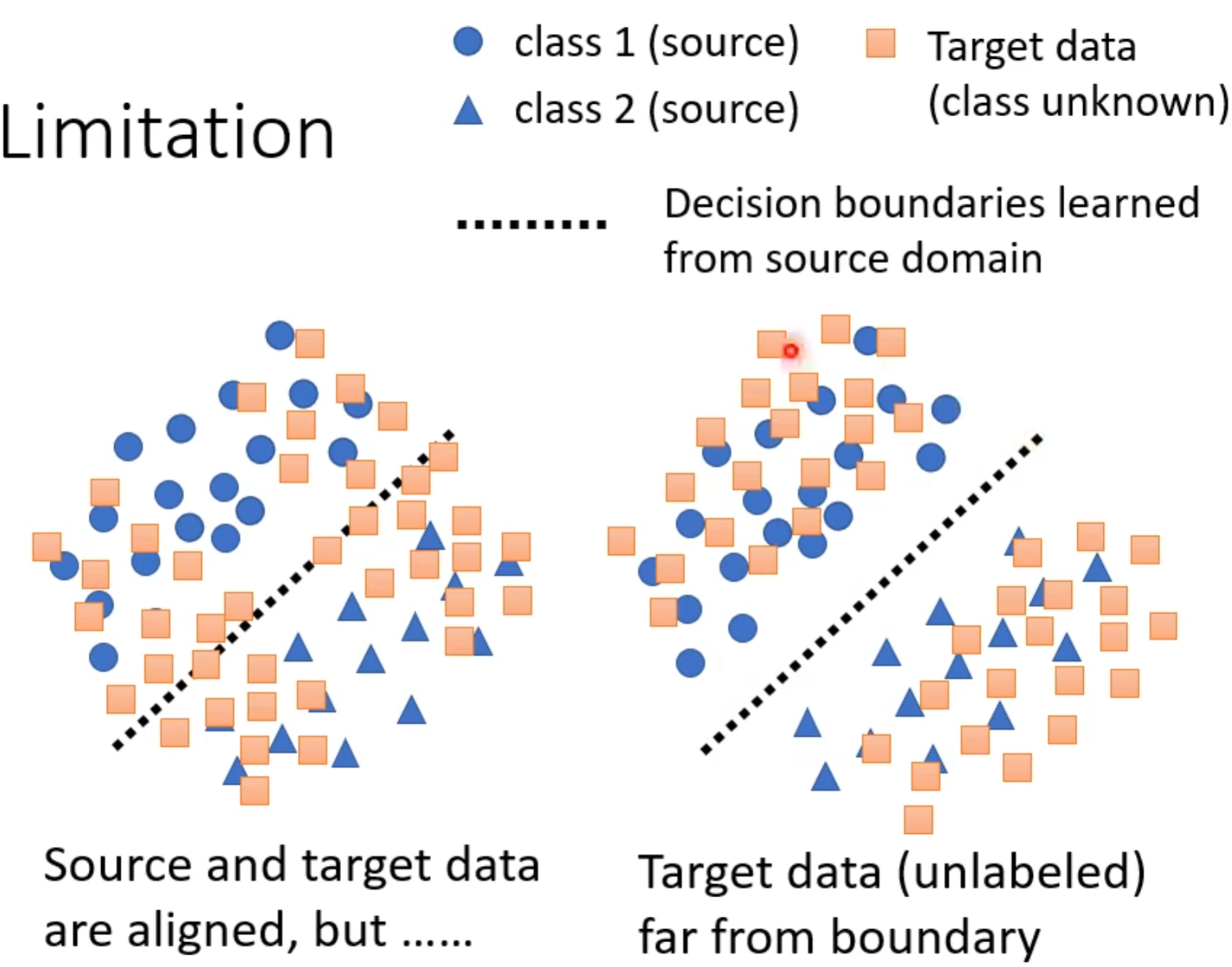
就如上右边效果要比左边好,也就是说既然知道三角形与圆的分界线在哪,那就让正方形远离分界线。
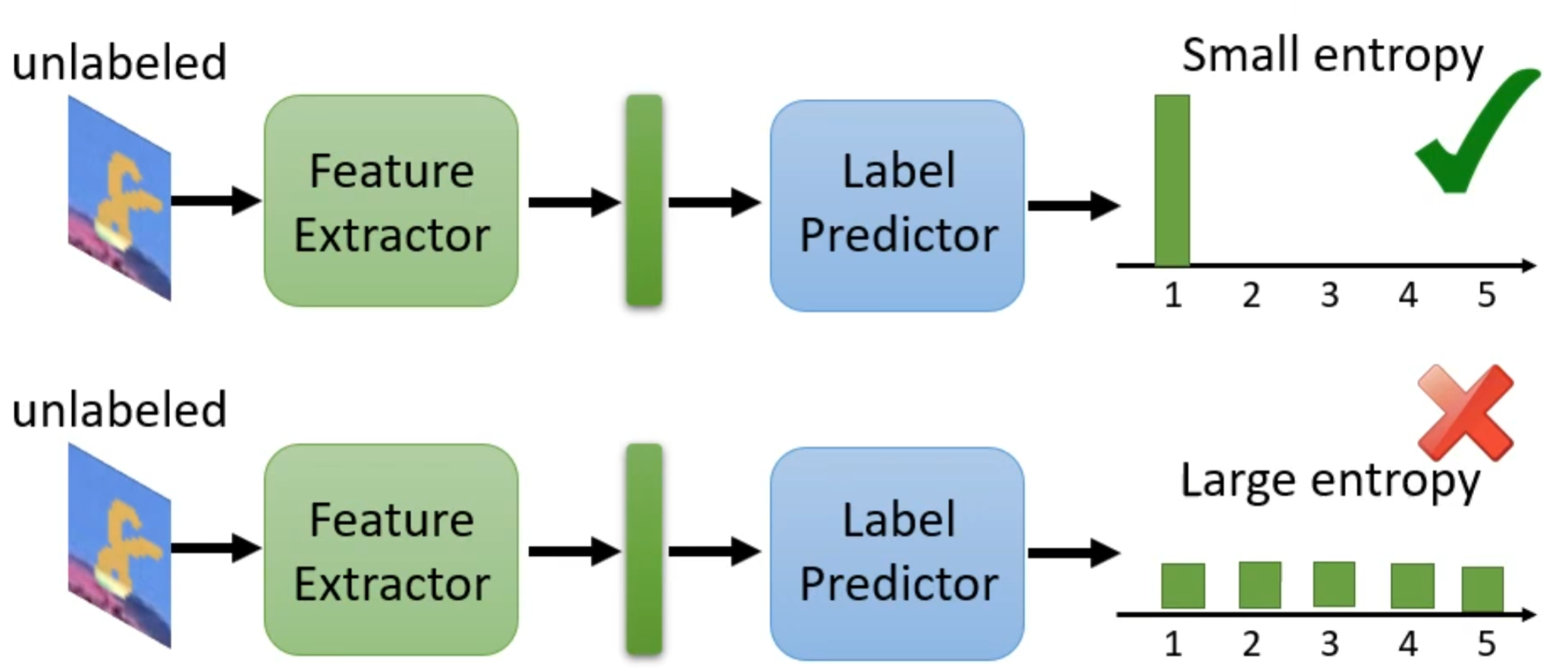
为了让方形远离分界线,可以用一个最简单的方法,就是现在有一堆没有标签的资料经过前面的分类器得到的结果尽可能集中这样就离分界线越远,若结果每一个类别都非常接近就表示离分界线越近。
接着还有一个更严重的问题,前面说有一大堆没有标签的资料,若是现在目标领域不止没有标签而且资料只有一点。这也不是没有方法可以解决,可以使用测试时训练方法(Testing Time Training,TTT)。
总结
本课重点阐述了领域自适应的核心目标:解决因数据分布差异导致的模型性能下降问题。通过引入领域对抗训练等关键方法,模型能够学习更具通用性的特征表示,从而提升其在实际应用中的适应性与鲁棒性。该方法为模型在跨领域任务中的有效迁移提供了重要技术路径。