1. 介绍一下 Redis 的常用数据结构及应用场景
💡 知识点解析:
Redis 不仅仅是 KV 数据库,它的 Value 可以是多种类型。
-
String: 最基本,存字符串/数字。场景:缓存、计数器、Session。
-
Hash: 类似 Java HashMap。场景:存对象(用户信息的多个字段)。
-
List: 双向链表。场景:消息队列、栈、文章列表。
-
Set: 无序去重集合。场景:抽奖、点赞、共同好友(交集)。
-
ZSet (Sorted Set): 带分数的 Set。场景:排行榜。
-
其实还有下面这几个但是不常用:
-

🗣️ 面试参考回答:
"Redis 最常用的五种数据结构包括:
-
String(字符串): 最常用的类型,用于缓存 JSON 序列化对象、实现计数器(incr)、分布式锁(setnx)以及存储 Session 信息。
-
Hash(哈希): 适合存储对象类型的数据,比如用户信息(Name, Age),可以单独修改某个字段,节省内存。
-
List(列表): 底层是双向链表,常用于实现简单的消息队列(LPUSH/RPOP)或者按照时间顺序存储的文章列表。
-
Set(集合): 用于存储不重复的数据,可以做全局去重(如抽奖名单),也可以通过计算交集来实现'共同好友'功能。
-
ZSet(有序集合): 也就是 Sorted Set,它给每个元素加了一个 Score 属性,常用于实现各种排行榜(如热搜榜、游戏排名)。"
2. 介绍 Redis 的持久化机制
💡 知识点解析:
Redis 是内存数据库,断电数据会丢,所以需要存到硬盘。
-
RDB (Redis Database): 快照。每隔一段时间把内存里的数据 dump 成一个文件。优点:恢复快;缺点:会丢最后一段时间的数据。
-
AOF (Append Only File): 日志。每执行一条写命令,就记录下来。优点:数据全;缺点:文件大,恢复慢。
🗣️ 面试参考回答:
"Redis 提供了两种持久化机制:RDB 和 AOF。
-
RDB(快照模式): 它是 Redis 默认的持久化方式。它会在指定的时间间隔内 ,将内存中的数据集快照写入磁盘。
-
优点: 恢复速度快,适合做备份。
-
缺点: 安全性稍差,如果服务器宕机,会丢失最后一次快照后的数据。
-
-
AOF(追加文件模式): 它会把服务器执行的每一条写命令都记录到日志文件中。
-
优点: 数据安全性高,最多只丢一秒的数据(取决于配置)。
-
缺点: 文件通常比 RDB 大,且恢复速度慢。
-
在生产环境中,我们通常会混合使用 :开启 AOF 来保证数据安全,同时保留 RDB 以便快速恢复。开启混合持久化后,当 AOF 文件重写时:
- 将当前内存数据以 RDB 格式写入新 AOF 文件的开头
- 后续增量数据以 AOF 格式追加到文件末尾
3. Redis 的数据如何和 MySQL 进行同步?
💡 知识点解析:
数据库改了,缓存怎么改?
-
模式: Cache Aside Pattern(旁路缓存)。
-
策略: 更新数据库,然后删除缓存(而不是更新缓存)。
-
为什么删? 防止并发更新导致脏数据;懒加载思想。
-
如果删失败了? 延时双删(Double Delete)或 消息队列重试。
🗣️ 面试参考回答:
"我们在项目中一般采用 具体的策略是:先更新数据库,然后直接删除缓存。
具体来说:
- 写操作时 ,先更新 MySQL,再 删除对应的 Redis 缓存(而不是更新缓存,避免并发脏读);
- 读操作时,先查 Redis,如果未命中,再查 MySQL,并将结果回填到 Redis。
为什么是删除而不是更新? 是为了防止并发修改时产生脏数据,也是为了避免频繁更新那些'只写不读'的数据,浪费性能。
如果要求强一致性 ,我们会采用'延时双删 '策略(更新库 -> 删缓存 -> 等几秒 -> 再删一次),或者干脆使用 消息队列 监听 MySQL 的 Binlog来异步更新缓存。"

4. 缓存穿透的概念以及解决方案
💡 知识点解析:
-
现象: 查一个根本不存在的数据(如 id = -1)。缓存没有,数据库也没有。请求会直接打穿到数据库。如果有黑客一直刷,数据库就挂了。
-
解决:
-
缓存空对象: 既然没有,我就存个
null到 Redis,设个短过期时间。 -
布隆过滤器 (Bloom Filter): 一个很长的二进制向量。请求先问过滤器"这东西可能存在吗?",如果过滤器说"绝对不存在",就直接拦截。
-
🗣️ 面试参考回答:
"缓存穿透是指查询一个根本不存在的数据,缓存层和数据库层都不会命中。如果不加处理,大量的请求会直接打到数据库,导致数据库压力过大。
解决方案主要有两种:
-
缓存空对象: 当数据库查不到数据时,我们将 null 值存入 Redis,并设置一个较短的过期时间(如 5 分钟),防止同一个 ID 反复攻击。
-
布隆过滤器: 在缓存之前加一层布隆过滤器。它能快速判断一个 Key 是否一定不存在。如果判断不存在,直接拦截请求,不访问存储层。"

5. 缓存雪崩的概念以及解决方案
💡 知识点解析:
-
现象: 雪崩是大面积 的。比如 Redis 宕机了,或者一大批 Key 在同一时间集体过期。所有请求瞬间涌向数据库。
-
解决:
-
过期时间加随机值: 别让大家一起死。
-
高可用: 哨兵、集群。
-
限流降级: 别查库了,直接返回错误。
-
🗣️ 面试参考回答:
"缓存雪崩是指 Redis 中大量的 Key 在同一时间集中过期,或者 Redis 服务直接宕机,导致大量请求瞬间到达数据库,压垮数据库。
解决方案:
-
设置随机 TTL: 在设置过期时间时,加上一个随机值(比如 1-5 分钟),避免 Key 集中失效。
-
搭建高可用集群: 使用哨兵或 Redis Cluster 模式,防止单点故障。
-
多级缓存: 增加本地缓存(Guava Cache/Caffeine)作为二级缓冲。
-
服务降级: 也就是使用 Sentinel 等组件进行限流,当流量过大时直接返回兜底数据。"
6. 缓存击穿的概念以及解决方案
💡 知识点解析:
-
现象: 击穿是单点 突破。一个热点 Key(比如明星出轨新闻)突然过期了,此时几万个并发请求同时过来查这个 Key。
-
解决:
-
互斥锁 (Mutex Lock): 只有第一个人能去查库,其他人等着。
-
逻辑过期: Key 不设 TTL,但在 Value 里存一个时间。发现"逻辑过期"了,后台开个线程去更新,当前请求先返回旧数据。
-
🗣️ 面试参考回答:
"缓存击穿是指一个被高并发访问的热点 Key 突然过期,导致瞬间大量的并发请求穿透缓存直达数据库。
解决方案:
-
互斥锁(Mutex Lock): 比如使用
setnx。当发现缓存失效时,不是立刻去查库,而是先尝试获取锁。谁抢到锁,谁去查库并回写 Redis,其他人等待或重试。 -
逻辑过期: 不给热点 Key 设置物理过期时间(TTL),而是将过期时间存放在 Value 数据中。查询时如果发现数据逻辑过期了,就启动一个异步线程去重建缓存,当前请求直接返回旧数据,保证高可用。"
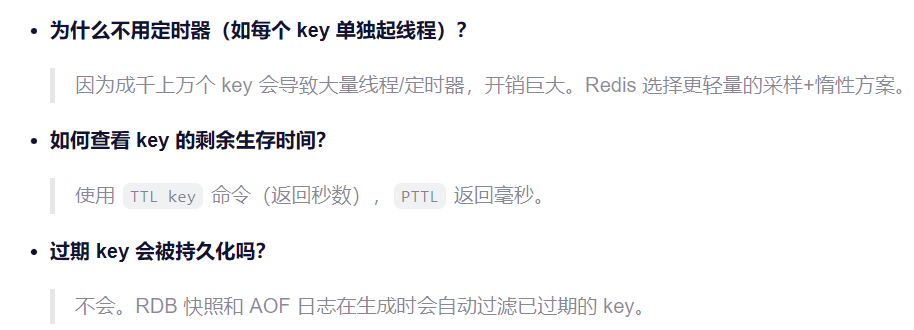
7. Redis 如何判断一个 KEY 是否过期? & 8. 数据过期策略有哪些?
💡 知识点解析:
Redis 怎么知道哪些 Key 该删了?
-
它不会给每个 Key 起个定时器(太耗 CPU)。
-
策略:
-
惰性删除 (Lazy): 查的时候顺便看一眼,过期了就删。
-
定期删除 (Periodic): 每隔 100ms 随机抽一批查查,过期的删掉。
-
🗣️ 面试参考回答:
Redis 判断 key 是否过期,是通过内部的过期字典 记录每个 key 的过期时间戳 。当访问 key 时,会检查当前时间是否超过该时间戳,若超时则视为过期并删除------这叫惰性删除。
同时,Redis 还会每秒多次随机采样 一部分带过期时间的 key,主动清理已过期的数据,称为定期删除。
这种 '惰性 + 定期' 的混合策略,既避免了不必要的 CPU 消耗,又能有效回收内存,是 Redis 高性能的关键设计之一。
可能追问:
9. Redis 的内存淘汰策略有哪些?
💡 知识点解析:
内存满了(达到 maxmemory)怎么办?需要踢人。
-
noeviction: 不删,直接报错(默认,但生产很少用)。
-
allkeys-lru: 所有 Key 里,删最久没用的(最常用)。
-
volatile-lru: 设置了过期时间的 Key 里,删访问频率最低。
-
random: 随机删。
🗣️ 面试参考回答:

策略选择建议
- 缓存场景 :理论上所有数据都可以淘汰,所以优先使用
allkeys-lru或allkeys-lfu,避免内存写满导致服务不可用。 - 存在数据长期保存场景 :部分未设置过期时间的数据是要长期保存的,为了保留关键数据,所以使用
volatile-lru或volatile-lfu。 - 严格数据保护 :使用
noeviction,但需确保有监控和扩容机制。
10. Redis 集群有哪些方案?
💡 知识点解析:
-
主从模式: 1主N从。主写从读。但主挂了需要人工处理。
-
哨兵模式 (Sentinel): 主从 + 监控。主挂了自动选新的主。
-
分片集群 (Cluster): 多主多从。数据分片存储。适合大数据量。
🗣️ 面试参考回答:
"Redis 主要有三种集群方案:
-
主从复制模式: 一个 Master 负责写,多个 Slave 负责读。实现了读写分离,但无法自动故障恢复。
-
哨兵模式 (Sentinel): 在主从的基础上加入了哨兵组件,实现监控和自动故障转移。
-
切片集群模式 (Redis Cluster): 官方推荐的方案。实现了数据的分布式存储(分片),支持海量数据,同时也具备高可用特性。"
11. 主从复制的概念以及数据同步的流程
💡 知识点解析:
-
全量同步: 第一次连接。Master 生成 RDB 发给 Slave。
-
增量同步: 后续同步。Master 把新的命令放在缓冲区(repl_backlog),传给 Slave。
🗣️ 面试参考回答:
"主从复制是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。
同步流程主要分两步:
-
全量同步: Slave 初始化连接 Master 时,Master 会执行
bgsave生成 RDB 文件发送给 Slave,Slave 加载 RDB。 -
增量同步: 全量同步完成后,Master 会将后续产生的新写命令(记录在 repl_backlog 缓冲区中)持续发送给 Slave,Slave 执行命令以保持同步。"
12. 什么是哨兵模式,哨兵模式的工作原理
💡 知识点解析:
哨兵就是"保安"。
-
监控: 每隔一秒发心跳包问 Master:"你活着吗?"
-
选主: 如果 Master 挂了,保安们开会投票,选一个新的 Slave 当 Master。
-
通知: 告诉客户端新的 Master 地址。
🗣️ 面试参考回答:
"哨兵(Sentinel) 是 Redis 的高可用解决方案。它是一个独立的进程,用于监控 Redis 实例。
工作原理包含三个步骤:
-
监控: 哨兵通过心跳机制,周期性地检测 Master 和 Slave 是否存活。
-
选主(故障转移): 当 Master 宕机时,哨兵之间会通过 Raft 算法进行投票,选出一个新的 Leader,然后从剩余的 Slave 中选出一个提升为新的 Master。
-
通知: 哨兵会将新的 Master 地址推送给客户端(Jedis/Lettuce),实现客户端的自动切换。"
13. 什么是分片集群?
💡 知识点解析:
Redis Cluster。
-
去中心化: 多个 Master,每个 Master 存一部分数据。
-
Slot(槽): 一共 16384 个槽。Key 算个 Hash 值得出在哪个槽,就去哪个 Master。
🗣️ 面试参考回答:
"分片集群(Redis Cluster) 是 Redis 提供的分布式数据库 方案,主要为了解决单机内存限制问题。
它引入了 哈希槽(Hash Slot) 的概念,总共有 16384 个槽。集群将这些槽平均分配给多个 Master 节点。
当存储 Key 时,Redis 会使用 CRC16 算法计算出 Key 对应的槽位,然后将数据存储到管理该槽位的节点上。这样就实现了海量数据的分布式存储。"
14. Redis 为什么快?
💡 知识点解析:
这是经典题。不要只说"纯内存"。
-
纯内存操作: 速度之源。
-
单线程模型(工作线程): 避免了多线程切换和锁竞争的开销。
-
IO 多路复用(Epoll): 一个线程管理多个 Socket 连接。
🗣️ 面试参考回答:
"Redis 性能极高(QPS 可达 10 万+),主要原因有三点:
-
基于内存: 所有数据都在内存中,运算速度极快。
-
单线程模型: Redis 的核心工作线程是单线程的,这避免了多线程上下文切换的开销,也不需要考虑各种复杂的锁竞争问题。
-
IO 多路复用: Redis 使用了 Epoll 机制,可以在一个线程中 同时处理多个客户端的网络 IO 请求,网络利用率非常高。"