2025年10月9日,R语言世界明星人物Hadley Wickham,发长文回顾R语言Data science主流工具tidyverse的过去20年的演进之路、现状与未来展望!

Hadley Wickham是ggplot2、devtools、dplyr、reshape等Data science主流工具的核心开发者,这篇文章对想了解R语言Data science主流生态非常有帮助!
下面原文翻译!文中的"我"指Hadley Wickham。
1 介绍
与我们的宇宙不同,tidyverse并非起源于宇宙大爆炸,而是通过一系列软件包的逐步积累最终凝聚成一个远超其各部分之和的整体。本文将从我的视角追溯 tidyverse 的演进历程,从最初激发 tidyverse 雏形软件包的灵感来源入手,逐步展现其如何发展成为一个完整的生态系统。我将探讨 tidyverse 的独特之处,重点介绍我最引以为豪的贡献,并分析它如何从一个个人项目发展成为一个由 Posit 团队和活跃社区共同支持的协作项目。最后,我将展望 tidyverse 的现状,并分享我对它未来的展望。
本文总结了近 20 年的软件包开发历程,涵盖了 26 个软件包的 500 多个版本。这意味着本文必然有所删减,再加上我记忆力有限,很可能遗漏了一些重要细节。如果您发现任何重要遗漏,请告知我,以便我进行修正!
2 在 tidyverse 出现之前
虽然 tidyverse 是在 2016 年才正式命名的,但构成它的大部分包其实早在之前就已经创建完成,如图1所示。在本节中,我将探讨 tidyverse 的诞生历程,这段旅程与我的职业生涯密不可分。我将从我成长过程中的一些重要经历讲起,然后继续讲述我的博士生涯,期间我创建了 reshape 和 ggplot 包。接下来,我们将回顾我的职业生涯,首先是在莱斯大学,在那里,教学工作促使我的想法变得更加具体和易于理解;之后,我加入了 RStudio(现更名为 Posit),在那里我获得了充分的自由和资源,得以深入探索包的开发。
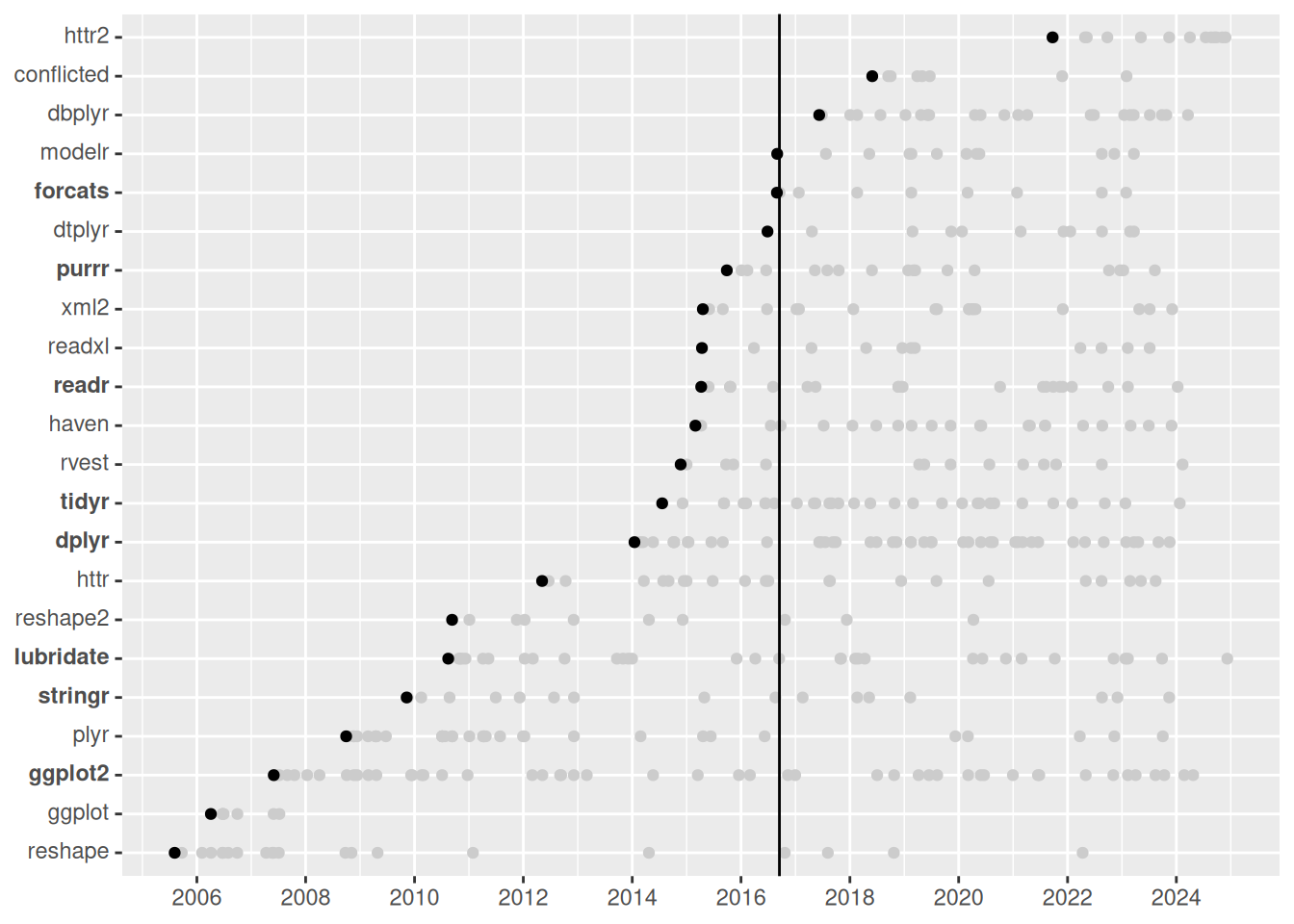
图 1:tidyverse 软件包及其重要前身的初始版本。垂直线表示 tidyverse 软件包的发布时间。核心 tidyverse 软件包在 y 轴标签中以粗体显示。黑点代表初始版本,灰点代表后续版本
2.1 我的成长
我从小就很幸运,能接触到电脑,这要感谢我的父亲¹,也因此培养了我对电脑和编程的浓厚兴趣。父亲的工作涉及数据库,所以我很幸运,比一般人更早地就能和他深入探讨关系数据库设计和科德第三范式。这让我开始大量使用桌面数据库管理系统 Microsoft Access,并最终找到了一份兼职数据库开发工作。这份工作在我后来处理拟合统计模型所需的数据时发挥了至关重要的作用。
我从母亲那里学到,行善无需征求他人的许可²。这意味着,当我遇到我认为可以解决的数据分析问题时,我不仅感到有能力解决它们,还能将我的解决方案分享给全世界。我的父母也让我坚信,拥有资源的人有道德义务帮助那些资源匮乏的人,这使得这些解决方案自然而然地以开源软件的形式进入世界。
在攻读博士学位之前,我最后一段重要的学习经历是在奥克兰大学攻读统计学本科,而奥克兰大学正是 R 语言(R Core Team 2024)的诞生地。不出所料,我的许多课程都是用 R 语言授课的,这意味着我从 2003 年就开始使用 R 语言,当时的版本是 1.6.2。回顾我最早的 R 代码很有意思:这些文件使用 .rb.txt扩展名,赋值语句混用 `&`=和<-`&`,而且空格格式非常不统一。
2.2 博士生涯(2004-2008)
本科学习让我对统计学产生了浓厚的兴趣,而我父亲的博士学位是在康奈尔大学获得的,所以去美国攻读博士学位似乎顺理成章。这最终让我选择了爱荷华州立大学(ISU),并拜师于戴安娜·库克和海克·霍夫曼两位导师。
在爱荷华州立大学,我很幸运地获得了农业试验站的咨询助理职位,在那里我帮助其他院系的博士生进行数据分析。这项工作让我面临两个至今仍困扰着我的挑战:
-
协作数据分析中最难的部分不是找到正确的统计模型,而是将数据转换成实际可用的形式。为了应对这一挑战,reshape 包应运而生。它首先将各种输入数据集转换为"熔融"形式,然后可以将其"铸造"成所需的形式,从而简化了对它们的处理³。
-
我常常发现很难将脑海中构想的图形用基础图形或格子图形(Sarkar 2008)转换成代码。与此同时,我正在阅读《图形语法》(Wilkinson 2012),并发现其可视化理论非常引人入胜。但当时唯一可用的实现非常昂贵,所以我决定尝试用 R 语言自己编写一个。这促成了 ggplot2 的诞生,后来又有了 ggplot2。我很幸运地遇到了 Lee Wilkinson,他给予了我的工作极大的支持⁴。
如果没有Di和Heike的帮助,这项工作不可能完成。他们让我专注于我 认为最重要的研究方向⁵,无论它是否符合传统统计学博士论文的模式。他们教会了我几乎所有关于探索性数据分析的知识,对我的R包用户界面提出了许多富有见地的反馈,并通过小组会议、邀请演讲嘉宾和参加学术会议等方式,营造了一个极其丰富的学术氛围。当我过于明显地流露出对理论统计学实用性的不屑,导致我完成博士论文中更传统的部分时,他们也给予了我支持。我在爱荷华州立大学的研究最终以我的博士论文《探索数据和模型的实用工具》为题完成,这篇论文总结了我开始收集的R包及其背后的理念。
2.3 莱斯大学任教(2008-2012)
从爱荷华州立大学毕业后,我在莱斯大学找到了一份工作。在那里,我最宝贵的经历是教授Stat405课程------"数据分析导论" 。我教授这门课四次(2009-2012),发现反复向新学生讲授相同的主题非常有益。这帮助我发现学生难以理解的概念和难以使用的工具,并且我能够看到自己每年在教学和工具使用方面的改进所带来的影响。这促使我创建了 stringr( 2009)和lubridate(2010,与 Garrett Grolemund 合作)包,因为我发现许多学生难以掌握 R 基础包中字符串和日期时间操作的特殊情况。这也激发了我对 tidy 数据和分组操作的研究,最终形成了 tidyr 和 dplyr 包,我将在下一节中讨论它们。
在此期间,ggplot2 的受欢迎程度持续上升,尽管它不被视为研究项目,因此我的部门并不重视它,但我仍然设法抽出时间来参与其中。与社区的交流让我保持动力,并不断强化我对开源软件开发价值的信念,因为它能够帮助其他人更好地进行数据分析。在此期间,我开始与 Garrett Grolemund(我的博士生)和 Winston Chang(自由职业者)合作。对 tidyverse 而言,最重要的是,Garrett 开发了 lubridate (Grolemund 和 Wickham,2011),而 Winston 则致力于 ggplot2 的开发,实现了诸如 `geom_1`geom_dotplot()和`geom_2` 之类的新几何图形geom_violin(),以及诸如主题和底层面向对象编程系统等重要基础设施。我很幸运,现在仍然能与 Garrett 和 Winston 在 Posit 共事。
在莱斯大学期间,我申请科研经费几乎毫无进展。美国国家科学基金会(NSF)的统计部门很难理解我的工作为何重要,而且他们在软件类科研经费的评审方面经验不足。我很幸运地从BD(一家医疗技术公司)和谷歌获得了一些小额资助,用于继续开发plyr、reshape和ggplot2,但这远远低于我预期获得的资金数额。以下是我提交给BD的最终报告中的一段话,它概括了我当时的想法:
BD 的慷慨支持使我得以对 plyr、reshape 和 ggplot2 进行多项性能改进,并着手开发下一代交互式图形。如果没有这样的支持,我很难投入时间进行这些项目,因为它们与我的研究成果没有直接关联。您的支持不仅为我提供了开展这些重要优化所需的资金,也向统计学界传递了一个强有力的信号:这项工作意义重大。
我也参与了软件包开发工具的开发工作,尽管这项工作同样缺乏任何"研究"价值。由于我当时开发了相当多的软件包,因此投资开发能够帮助我更快开发出更可靠软件的工具就显得很有意义。这促成了 testthat (2009) 和 devtools (2011) 软件包的诞生,以及我接手 roxygen2 软件包 (2011) 的维护工作。
2.4 RStudio工作(2012年至今)
2012年,我离开莱斯大学,加入RStudio(现更名为Posit),从事软件工程实践备受重视的工作,不再需要撰写论文或申请科研经费。这源于我在R语言和统计学会议上与RStudio创始人JJ Allaire的多次交流,也让我有时间和自由去学习C++------这门重要的工具对于编写高性能代码以及将R语言与现有的C/C++库集成至关重要。我很幸运能得到JJ的指导,这使我的C++技能突飞猛进。总而言之,我在RStudio的最初几年里,开发出了大量新软件包,因为我既有时间专注于我认为重要的事情,也有能力投入到那些在学术界不被重视的编程技能中。
最重要的新包是 dplyr。dplyr 的诞生源于我对使用 plyr 包解决各种分组数据框问题的不满。这些问题通常很容易解释,但使用现有工具却很难解决。例如,假设你有一个 babynames 数据集,想要计算每个名字在每种性别和年份组合中的排名。解决这个问题需要用到 `dplyr`函数plyr::ddply(),其中dd前缀 `_` 表示输入和输出都是数据框。`dplyr` 函数ddply()有三个参数:要处理的输入数据框、如何将其拆分(按年份和性别变量)以及我们想要对每个部分执行的操作(修改)。
code-with-copy
library(babynames)
ranked <- plyr::ddply(babynames, c("year", "sex"), function(df) {
plyr::mutate(df, rank = rank(-n))
})
head(ranked, 10)
#> year sex name n prop rank
#> 1 1880 F Mary 7065 0.07238359 1
#> 2 1880 F Anna 2604 0.02667896 2
#> 3 1880 F Emma 2003 0.02052149 3
#> 4 1880 F Elizabeth 1939 0.01986579 4
#> 5 1880 F Minnie 1746 0.01788843 5
#> 6 1880 F Margaret 1578 0.01616720 6
#> 7 1880 F Ida 1472 0.01508119 7
#> 8 1880 F Alice 1414 0.01448696 8
#> 9 1880 F Bertha 1320 0.01352390 9
#> 10 1880 F Sarah 1288 0.01319605 10这段代码对新手来说缺乏吸引力,因为它要求他们理解函数和函数式编程的基础知识。这意味着,如果你在教授 R 语言,即使其底层任务很简单,而且是你希望在数据分析学习初期就能掌握的技能,你也只能在学期后期才能讲解这段代码。
dplyr 的出现使得你可以这样编写代码:
code-with-copy
library(dplyr)
babynames |>
group_by(year, sex) |>
mutate(rank = rank(desc(n)))
#> # A tibble: 1,924,665 × 6
#> # Groups: year, sex [276]
#> year sex name n prop rank
#> <dbl> <chr> <chr> <int> <dbl> <dbl>
#> 1 1880 F Mary 7065 0.0724 1
#> 2 1880 F Anna 2604 0.0267 2
#> 3 1880 F Emma 2003 0.0205 3
#> 4 1880 F Elizabeth 1939 0.0199 4
#> 5 1880 F Minnie 1746 0.0179 5
#> 6 1880 F Margaret 1578 0.0162 6
#> 7 1880 F Ida 1472 0.0151 7
#> 8 1880 F Alice 1414 0.0145 8
#> 9 1880 F Bertha 1320 0.0135 9
#> 10 1880 F Sarah 1288 0.0132 10
#> # ℹ 1,924,655 more rowsdplyr 的设计以 `a` filter()、mutate()`b` 和 ` c` 等动词为核心summarise(),这些动词的名称都体现了它们各自的用途。每个动词都专注于做好一件事,并且设计成可以与其他动词组合使用,从而解决复杂的问题。虽然 dplyr 确实需要一些全新的概念,但我发现学生们学习起来比学习函数式编程要容易得多。dplyr 从 SQL 中汲取了很多灵感,包括 `a` 这样的术语GROUP BY和 `b` 这样的函数,但我同时也想避免 SQL 的一些问题,例如在指定要使用的表之前就指定变量名,以及根据过滤条件coalesce()需要使用三个不同的子句(`a` WHERE、HAVING`b` 和 `c` )。QUALIFY
dplyr 的早期发展得益于 Romain François 的贡献(最初是 RStudio 的外包人员,后来成为正式员工)。凭借他精湛的 C++ 技能,dplyr 的运行速度也远超 plyr,确保了学习 dplyr 后能够立即获得回报<sup> 9 </sup> 。dplyr 的一个特别出色的特性是,它支持使用相同的语法处理不同的后端。例如,可以使用 dbplyr<sup> 10</sup> (2017) 来操作 SQL 数据库,该包不会直接运行 R 代码,而是生成 SQL 代码并在数据库中执行。
在此期间,我也开始思考数据如何导入 R,首先从数据库入手。我接手了 Seth Falcon (2013) 的 DBI 和 RSQLite 包的维护工作,创建了 bigrquery (2015) 来处理 Google 的 BigQuery 数据库,并从当时已停止维护的 RPostgresSQL (2015) 中 fork 出了 RPostgres。这项工作是与 Kirill Müller 合作完成的,他现在在 R 联盟的资助下维护着大部分数据库生态系统。在数据库之后,我还研究了其他各种数据源,包括网络爬虫(rvest,2014)、Excel(readxl,2015)、矩形文本文件(readr,2015)、SPSS/SAS/Stata(haven,2015)和 XML(xml2,2015)。如果没有我新掌握的 C++ 技能,所有这些包都不可能实现,因为它们都依赖于与现有 C 库的紧密集成。
大约在这个时候,我在R语言社区开始变得小有名气。这促成了我在Reddit(2015年)和Quora (2016年)上举办的几次颇受欢迎的线上问答活动,如果你想了解我当时的想法,可以去看看这些活动。
3 tidyverse 早期岁月
虽然 tidyverse 的大部分组件包在 2015 年就已经存在,但 tidyverse 本身尚未命名和定义。在本节中,你将了解 tidyverse 这个名称的由来、tidyverse 组件包背后的通用原则,以及我是如何帮助人们学习如何使用它的。
3.1 为 tidyverse 命名
随着我开发的软件包越来越多,社区需要一个统称来指代它们。许多人开始称这些软件包为"Hadleyverse" ¹¹,但我个人觉得这个名字非常难听。于是,我开始集思广益,想出一个自己喜欢的"官方"名称,候选名称包括 sleekverse、dapperverse 和 deftverse¹² 。现在回想起来,tidyverse 这个名字似乎显而易见,我真不明白自己当初为什么花了那么多时间和精力去想名字。
总的来说,我仍然很满意这个名字,但有一点我不喜欢:它暗示 tidyverse 之外的一切都是 messyverse。我不认为这是真的:tidyverse 只是完成这项工作的其中一种方法,我认为使用其他工具并没有错(事实上,通常不可能只使用 tidyverse 来进行分析)。
我在 2016 年 6 月 29 日 useR 大会的主题演讲中宣布了这个名称。几个月后的 9 月,我发布了tidyverse 包。这个包有两个主要目标:
-
为了方便用户使用一行代码安装 tidyverse 中的所有软件包
install.packages("tidyverse"),这使得用户可以轻松获得一个"开箱即用"的数据科学环境,这在教学中尤其有用。 -
为了方便加载最常用的软件包,您可以
library(tidyverse)一次性输入命令,而无需逐个加载。初始版本加载了 ggplot2、dplyr、tidyr、readr、purrr 和 tibble,然后 1.2.0 版本(2017 年 9 月)添加了 forcats 和 stringr,2.0.0 版本(2023 年 3 月)添加了 lubridate 13。
图 2总结了 tidyverse 的当前状态,并根据我们的数据科学过程模型进行了细分。
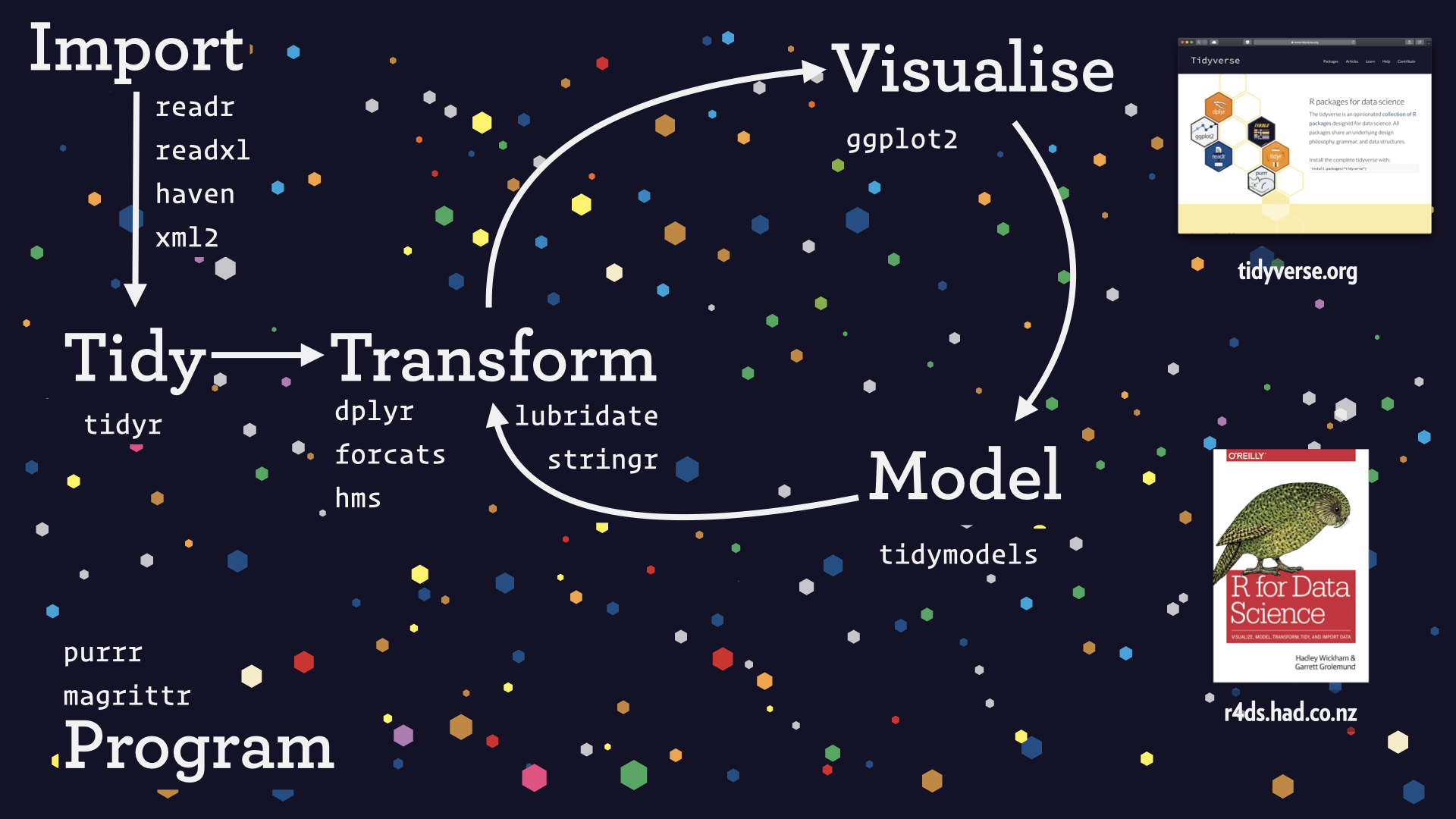
图 2:tidyverse 的软件包,其组织方式基于我构建的数据科学工作流模型的部分版本。缺失的步骤是沟通,这需要借助 tidyverse 之外的工具,例如 Quarto 和 Shiny。此图出自我在 2020 年发表的题为"数据科学的乐趣"的演讲。
3.2 定义 tidyverse
tidyverse 的命名引发了一些更深层次的问题:tidyverse 究竟是什么?tidyverse 中各个包的统一原则是什么?在我的 useR 演讲中,我提到了三个统一原则:
- 统一的数据结构。
- 统一的API。
- 支持参考透明度。
我认为前两条原则很简单:如果一个新工具使用你已经熟悉的数据结构和接口,那么学习起来就更容易。但是,支持引用透明性意味着什么呢?这就涉及到整洁求值原则,我们将在4.4 节中详细讨论。
那一年,我多次重复了关于 tidyverse 的介绍,到 2016 年 12 月,我进一步提炼了其核心原则,总结为以下四点:
- 共享数据结构(例如整洁的 tibble)。
- 制作简单的乐曲(例如使用管道)。
- 拥抱函数式编程(而不是 for 循环)。
- 为读者写作。
最后一点尤其受到这句话的启发:
编写程序时,必须先考虑人能否阅读,机器能否执行只是次要的。------
哈尔·阿贝尔森
我认为这对于数据科学代码来说是一个尤为重要的原则,因为能够阅读、理解和评估用于执行分析的代码至关重要。理想情况下,你不仅要用代码解决问题,还要记录解决问题的过程,以便你(以及其他人)能够理解你所采取的路径。
自那时起,我一直在不断完善 tidyverse 的定义,你可以在Tidy 设计原则中看到我的最新版本。在撰写本文时,tidyverse 的四个原则是:
-
它是以人为中心的,也就是说,tidyverse 的设计初衷就是为了支持人类数据分析师的活动。
-
它具有一致性,因此你从一个函数或包中学到的知识可以应用于另一个函数或包,并且你需要记住的特殊情况的数量尽可能少。
-
它具有可组合性,允许您将复杂的问题分解成小部分来解决,支持快速的探索性迭代循环,以找到最佳解决方案。
-
它具有包容性,因为 tidyverse 不仅仅是软件包的集合,它还是使用这些软件包的人们的社区。
3.3 如何学习tidyverse
一旦我确定了 tidyverse 框架,自然而然地就会问自己:"如何学习它?" 这个问题的答案最终汇集成书------ 《R 语言数据科学》 (Wickham 和 Grolemund,2017;Wickham、Çetinkaya-Rundel 和 Grolemund,2023)。我之所以写书,是因为我相信书籍是传播重要理念的最佳途径之一;线性结构能够引导读者循序渐进地学习,并且有足够的篇幅深入细节。同样重要的是,这本书应该面向所有人开放,无论他们是否有能力支付费用。因此,我所有的书都采用双重出版模式:一个由我制作的免费 HTML 版本,以及一个由商业出版社出版的付费纸质版本。
《R语言数据科学》一书非常受欢迎。它的销量很好,但对我来说更重要的是,很多人访问了它的官方网站¹⁴。这本书最让我喜欢的一点是它被翻译成了多种语言,包括俄语、波兰语、日语、繁体中文和简体中文。我尤其喜欢社区翻译版本(西班牙语、意大利语、土耳其语和葡萄牙语),因为它们是由志愿者翻译并免费提供给全世界的。
4 关键创新
到目前为止,我已经追溯了 tidyverse 的发展历程,但我也想探讨一下这一过程中涌现的一些具体创新。这些创新不仅仅是编程方面的成就:它们代表了思考和处理数据的新方式,并帮助围绕 tidyverse 构建了一个社区。我挑选了五项我特别引以为豪的贡献------tidy data、tibbles、pipe、tidy evaluation 和 hex stickers。让我们依次来了解这些关键发展。
4.1 整洁的数据
我一直强烈地感觉到,组织数据存在一种"正确"的方法,这种方法能让后续的分析工作变得更加轻松。在查看数据集时,我通常能够判断哪种形式最有效。但我很难向别人解释我的做法,在尝试向学生传授我的方法时也屡屡碰壁。最终,我总结出了整洁数据的三个原则¹⁵ ,并在Wickham ( 2014 )中进行了阐述:
- 每个变量都放在一列中。
- 每条观察结果按行排列。
- 每个值都放在一个单元格中。
这个定义似乎适用于不同学术背景的人,即使他们没有对变量和观测值给出精确的定义。鉴于它们的简洁性,我很难理解为什么我花了这么长时间才弄明白。这也是统计学文献中的一个奇怪空白:这是极少数真正描述如何构建数据以进行统计分析的论文之一。
整洁数据的定义与tidyr16紧密相关,tidyr 是一个帮助用户整理数据的软件包。该软件包最初提供了 `std::return`gather()和 `std::return`spread()函数,但许多人(包括我!)很难记住哪个函数是哪个,以及它们的参数是如何工作的。此外,它们的设计不够灵活,无法处理我们后来在实践中发现的所有问题。在tidyr 1.0.0pivot_longer() (2019) 中,我们通过引入新的 `std::return`和`std::return` 函数解决了其中的许多问题pivot_wider()。这些新名称来源于(非正式的)用户调研,我请我的 Twitter 粉丝描述两种数据转换操作。您可以在https://github.com/hadley/table-shapes了解更多关于这项研究的信息。
tidyr 1.0.0 还扩展了包的功能范围,新增了"矩形化"(rectangling)功能,这是一个将层级数据转换为整齐矩形的新术语。当时,随着越来越多的数据来自 JSON Web API(这些 API 往往会生成深度嵌套的数据结构),这项功能变得越来越重要。您可以在tidyr 的矩形化 vignette中了解更多关于该问题以及 tidyr 提供的解决方案的信息。
4.2 tibble数据结构
整洁数据提供了一个理论框架,用于高效地组织数据。但你还需要一个实用的数据结构来存放这些数据。R 基础包提供了数据框(DataFrame),但我发现它存在一些小问题,增加了不必要的麻烦。为了解决这些问题,我创建了 tibble,它是数据框的扩展,并进行了一些小的修改:
-
当处理包含大量行或列的数据集时,数据框可能会在控制台中输出大量信息。在旧版本的 R 中,您甚至无法取消这些显示,这很容易导致您在处理大型数据集时被锁定在控制台之外。而 tibble 只会打印少量行和列,这些行和列足以在一个屏幕上显示。您始终可以显式地请求更多数据,但默认设置可以使您的分析工作流程更加灵活。
-
在教学过程中,我发现学生对列类型的概念理解不够清晰,甚至有时我自己也会搞不清楚某一列究竟是日期、字符串还是因子。为了避免这个问题,tibble 会在列名下方显示(缩写的)变量类型。
-
如果出现这种情况
data.frame(x = c(NA, "<NA>")),就无法从打印输出中区分这两个值。Tibble 使用颜色作为辅助通道,以确保不会将缺失值和具有相同打印表示形式的字符串混淆。 -
基础数据框在技术上支持嵌套数据结构,例如列本身就是数据框,或者列本身就是数据框列表。但它们的打印效果很差,难以使用。Tibbles 致力于以更易读的方式呈现这些更复杂的数据类型,使其在需要时更易于使用。
tibble 还解决了几个子集处理方面的陷阱,这些陷阱很容易导致在编写包代码时出现不易察觉的错误。例如,如果df`is` 是一个数据框,那么:
-
df[, cols]可以根据内容返回向量或数据框col。 -
df$x使用部分匹配,因此如果列x不存在但列xyz存在,它将默默地返回df$xyz。
如果df`tibble` 是一个 tibble 对象,那么这两个问题都不会发生,因为df[]`tibble` 总是返回另一个 tibble 对象,并且df$x从不进行部分匹配。这就是为什么我开玩笑地把 tibble 描述为数据框的懒惰且脾气暴躁的版本。
tibble 最初诞生于 dplyr 包中,最初被命名为tbl_dfs,但并未明确其发音。2014年, Kevin Ushey提议将其发音为 tibble-diffs,tibble 部分便沿用至今。随着 tibble 的实用性和复杂性不断提升,它们需要更大的空间来扩展,因此在 2016 年被提取出来,成为一个独立的包。
tibble 数据结构比我预想的更具争议性。它们破坏了旧软件包中的代码,我对有效数字格式的强烈意见也引起了社区的一些不满。虽然争议似乎已经基本平息,但如今我在引入新的数据结构时更加谨慎。新数据结构的开销远高于新函数或新软件包,因此应该尽量减少使用,除非有明显的计算优势。
4.3 管道
无论单个操作多么复杂和精细,通常最直接决定系统性能的还是粘合剂的质量。
------哈尔·阿贝尔森
管道很快成为 tidyverse 代码的标志性特征之一。它允许你将函数组合(例如 f(g(x))))重写为一系列线性转换(例如 x |> g() |> f()),这使得常见的数据分析编程模式更易于阅读。
我最初在 dplyr 中实现了管道符,时间是 2013 年 10 月,当时我将其命名为 `<R>` %.%。2014年 1 月我发布 dplyr时,得知 Stefan Milton Bache 也一直在思考类似的问题,并创建了 magrittr 包。magrittr 包使用 ` %>%<R>` 而不是 `<R> %.%`,这更容易输入(因为你可以一直按住 Shift 键<sup> 17 </sup> ),而且功能更全面。因此,我迅速转向使用 magrittr,并弃用了 `<R>` %.%。起初我对这种新语法持谨慎态度,但用户很快就掌握了它,而且我发现它也很容易教授。你可以在 Adolfo Álvarez 的精彩博文"水管工、链条和著名画家:R 语言中管道运算符的(更新版)历史"中了解更多关于管道符早期历史的信息。
如今,得益于协作努力,R 基础版本中已支持管道功能。2016 年,Lionel Henry提出了新的语法,并为 R 编写了一个补丁。Jim Hester 在 2017 年的统计计算方向大会上向 R 核心团队展示了该补丁。此次展示获得了积极反响,但 R 核心团队花了些时间才完全认可管道的实用性。三年后,Luke Tierney 将基础管道添加到 R 4.1(2020 年),随后在 R 4.2 中添加了占位符语法,并在 R 4.3 中加入了对 `<T>`、`<T>`和`<T>` 的支持。由于 R 可以修改解析器,基础管道拥有更完善的语法,$包括更清晰的占位符。随着基础管道的成熟,tidyverse 正在逐步从 `<T>` 转向`<T>` ,这一过程需要数年时间才能完成。[``[[``|>``_``%>%``|>
有趣的是,如果我早点发现管道(pipe),ggplot2 就没必要出现了,因为 ggplot 本身就是基于函数组合的。我当时就意识到函数组合的用户界面不够友好,但如果那时我发现了管道,ggplot 就可以直接使用它,而不用像+ggplot2 那样进行切换。你可以试试 ggplot,或者了解一下为什么 ggplot2 不能切换到管道。
4.4 整洁的评价
tidyverse 中最具挑战性的特性之一是整洁求值。在深入探讨技术细节之前,首先有必要了解整洁求值存在的意义。以 dplyr 代码为例df |> mutate(z = x + y)。这段代码之所以如此简洁,是因为变量名( `a`、`b`和 `c` )在 `dplyr` 内部是默认存在的;如果没有这种默认机制,你就需要重复编写 `dplyr ( xa , b)` ,例如 `dplyr(a, b)`。这种在数据上下文中工作的模式受到了 R 基础函数(例如 `dplyr( a, b)` 和 `dplyr(a, b ) `)的启发。y``z``df``df``df$z <- df$x + df$y``subset()``transform()``with()
虽然整洁求值让交互式数据分析变得轻松愉快,但当你想要编写使用这些工具的函数时,却会带来一些挑战。假设你编写了以下重复的代码,并且遵循"三法则",你想把这些重复部分提取到一个函数中:
code-with-copy
df1 |>
group_by(g1) |>
summarise(mean = mean(a))
df2 |>
group_by(g2) |>
summarise(mean = mean(b))
df3 |>
group_by(g3) |>
summarise(mean = mean(c))你可以尝试用通常的方法编写函数,并得到以下代码:
code-with-copy
grouped_mean <- function(df, group_var, summary_var) {
df |>
group_by(group_var) |>
summarise(mean = mean(summary_var))
}
df1 |> grouped_mean(g1, a)
#> Error in `group_by()`:
#> ! Must group by variables found in `.data`.
#> ✖ Column `group_var` is not found.这段代码无法运行,因为 dplyr 会查找名为 `data` 的变量,而不是你想要的group_var变量 `environment` 。我想我们现在知道如何简洁地定义这个问题了:我们用"变量"这个词来指代两种不同的东西。数据变量 是统计变量,存在于数据框内部,例如`data` 或 `environment` 。环境变量 是计算机科学变量,存在于(例如)全局环境中,例如 `environment`或 `environment` 。整洁求值面临的根本挑战是处理数据变量(例如 `data` )存储在环境变量(例如 `environment` )中的情况。a``g1``a``df1``df2``g1``group_var
我们花了大约五年时间才提供彻底解决这个问题所需的工具。我的工作始于 dplyr 0.3.0 版本(2014 年),当时引入了lazyeval包。这项工作包含三个部分:
lazyeval::lazy()允许您捕获存储在环境变量中的数据变量,从而生成一个显式的惰性对象。lazyeval::interp()允许您将惰性对象插入到更大的表达式中,从而创建一个新的惰性对象。- 每个 dplyr 函数都有一个以下划线结尾的变体,该变体接受惰性对象。
最终得到的解决方案如下所示:
code-with-copy
grouped_mean <- function(df, group_var, summary_var) {
group_var <- lazyeval::lazy(group_var)
summary_var <- lazyeval::lazy(summary_var)
df |>
group_by_(group_var) |>
summarise_(mean = lazyeval::interp(~ mean(summary_var), summary_var))
}这种方法虽然可行,但略显笨拙。此外,2016 年 7 月,我得知之前赖以lazy()生存的技术将在未来的 R 版本中不再受支持,这迫使我不得不重新寻找解决方案。幸运的是,Lionel Henry 近期加入了我的团队,他提出了许多改进方案。最终,我们开发出了一个名为 tidy evaluation(简称 tidyeval)的新框架,并将其引入到 dplyr 0.6.0 版本(2017 年)。
rlang包提供了整洁的求值方式,并引入了两个新工具:
-
enquo()允许您"引用"环境变量,从而创建一个显式的 quosure 对象。 -
!!(发音为 bang-bang)允许您"取消引用"或将引用插入到更大的表达式中。
这种方法很有吸引力,因为每个 dplyr 函数都可以调用自身enquo(),这意味着我们不再需要为每个函数编写两个版本。由此产生了以下解决方案:
code-with-copy
grouped_mean <- function(df, group_var, summary_var) {
df |>
group_by(!!enquo(group_var)) |>
summarise(mean = mean(!!enquo(summary_var)))
}整洁的评估方法包含坚实的理论基础,这让我们更加确信我们的实现是正确且完整的。我仍然认为理论非常重要,但经验告诉我们,很少有 R 用户愿意学习理论。在 2017 年和 2018 年,我曾在世界各地就 tidyeval 做了 12 次演讲,试图说服其他人将 tidyeval 应用于他们自己的代码。但这远没有我预期的效果好,社区中也普遍存在着关于 tidyeval 太难的抱怨。
这再次促使我们重新审视设计方案,并在 2019 年年中提出了一种名为"拥抱"(embracing)的新方法。这种方法只引入了一个新的运算符{ },用于在环境变量引用数据变量时。虽然 ` enquo()and` 和 `or`!!仍然在后台使用,但现在只需要学习一小段新的语法。这使得 `:` 的实现变得非常简单grouped_mean():
code-with-copy
grouped_mean <- function(df, group_var, summary_var) {
df |>
group_by({{ group_var }}) |>
summarise(mean = mean({{ summary_var }}))
}我们也忽略了一些常见问题,这些问题用现有工具解决起来出乎意料地困难,需要进行一些小的改进并完善文档。现在我们有了一本无需任何理论知识的实用指南aes_string(),关于 tidyval 的抱怨似乎也平息了。在最终确定使用 tidy 评估之前,我们还尝试了一些其他方法,这里没有提及。例如,ggplot2 有一个使用字符串输入的函数,我们也尝试过一些 R 的基础工具,比如 tidyvalbquote()和 tidyval eval()。然而,由于一些令人沮丧的原因,这些方法都不太合适,而这些原因现在都已湮没在历史长河中:我后悔没有做好更详细的记录。
4.5 Hex logos
谈到 tidyverse 的历史,就不能不提Hex logos。虽然Hex logos的早期历史如今已模糊不清,但据我所知,我和 Stefan Milton Bache 大约在 2014 年19 月通过https://hexb.in 共同发现了Hex logos。我个人觉得这种形状非常吸引人,它可以平铺在笔记本电脑背面,而且它的规格还能确保每个人的贴纸尺寸和方向都相同(尖端朝下!)。
我相当确定第一个Hex logos是 magrittr 的20 号图标,由 Stefan 于 2014 年 12 月设计。不久之后,我完全接受了Hex logos贴纸的想法,并在设计师 Greg Swinehart 的帮助下开始为一些重要的软件包制作图标;你可以在图 3中看到 ggplot2 图标的两个早期版本。到 2016 年年中,我们已经开始为 RStudio 的活动批量订购这些图标,并且我们开始看到社区中其他软件包也使用十六进制图标。
图 3:ggplot2 六边形徽标的两个早期版本。我找不到任何关于第一个版本(左图)创作者的记录,但考虑到六边形的方向不正确,我推测是我创作的。第二个版本(右图)是我与 Garrett Grolemund 共同创作的。
如今,大量的软件包都有自己的 logo,我非常欣赏软件包作者们在设计中展现出的创造力和多样性!我喜欢用十六进制贴纸来构建社区:人们看到你的笔记本电脑,就能立刻认出你是 R 社区的一员,并了解你使用 R 的用途。我听说过很多这样的故事:人们仅仅因为认出了贴纸就主动与陌生人攀谈起来。它们的作用类似于交换卡片,图 4展示了我这些年来收集的一些贴纸。

图 4:我办公室里展示的一块六边形贴纸板。
5 Posit 的 tidyverse
tidyverse 的命名恰逢我在 RStudio(现 Posit)组建团队,也标志着该项目从最初主要由我一人开发,发展成为拥有众多全职贡献者的项目。如果没有 Posit 的支持,这一切都不可能实现。Posit 作为一家公益公司,为这项工作提供了资金支持。我非常幸运能在这样一个使命与我自身价值观高度契合的机构工作。
tidyverse 团队目前包括 Lionel Henry、Jenny Bryan、Gábor Csárdi、Mine Çetinkaya-Rundel、Thomas Lin Pedersen、Davis Vaughan、George Stagg 和 Teun Van den Brand,以及下文所述的 tidymodels 团队。Jim Hester、Mara Averick、Romain Francois、Tracy Teal 和 Andy Teucher 已离开 Posit 的全职岗位,但他们中的许多人仍然活跃在社区中,并且他们仍然是更广泛的"tidyverse 团队"的重要成员。
团队的使命十分广泛,远不止于 tidyverse 项目本身:我们希望将 R 打造成进行数据科学的最佳环境。我们并不排斥其他编程语言(当然,在适当的情况下我们也会使用它们),但我们热爱 R,相信 R,并且坚信,要想有所作为,就必须保持专注。
为了实现这一目标,我们最直接运用的技能是编程技能:我们编写大量的 R 代码(以及少量的 C、C++、Rust 和 Javascript)来创建软件包。我们的目标不仅限于 tidyverse 软件包,因为我们意识到仅靠 tidyverse 无法完成太多分析,大多数分析都需要额外的专用工具。因此,我们致力于帮助每一位 R 软件包开发者创建更高质量的软件包。您可以在《高级 R语言》和《R 软件包》等书籍以及支持软件包开发相关任务的 devtools 系列软件包中看到我们的工作成果。该系列软件包对软件包开发实践产生了深远的影响:截至撰写本文时,约有 9,000 个软件包使用 testthat 进行单元测试,约有 12,000 个软件包使用 pkgdown 创建软件包网站,约有 16,000 个软件包使用 roxygen2 生成文档。
但如果你的代码无人知晓,那么它再好用也无济于事。因此,我们认为市场推广和教育与编程同等重要,所有团队成员都应通过撰写博客文章、书籍、演讲、举办研讨会等方式为我们的推广工作做出贡献,从而帮助建设和支持 R 社区。我们也是一个注重流程的团队,我们会尽力将流程记录下来,以便其他人也能从中受益。这项工作包括:
-
我们的软件包发布检查清单(由此处应填写创建者姓名创建
usethis::use_release_issue())确保我们遵循标准流程,最大限度地提高成功提交到 CRAN 的几率。随着我们发现新问题,我们的流程也在不断完善;随着我们找到自动化方法来减少手动步骤,我们的流程也在不断精简。 -
我们力求保持代码格式的一致性,因此将我们的选择记录在了tidyverse 风格指南中。这可能是 R 社区中最常用的风格指南。
-
我们花费大量时间进行代码审查(包括内部和外部审查),因此我们制定了代码审查指南,以保持我们自身工作的一致性,并帮助新贡献者了解预期内容。这项工作由 Davis Vaughan 主导。
-
我们正在逐步完善一份关于tidyverse API 设计原则的文档。这对我们来说很有帮助,因为它能让我们更容易记住设计决策,并在多个地方以相同的方式重复应用它们;同时,它也能帮助社区了解可以应用到他们自己代码中的可复用模式。
由于我们的任务范围广泛,最近我们花在 tidyverse 包上的时间减少了,花在更广泛的数据科学工作上的时间增加了;我将在本文的结尾部分回到我们目前的重点领域。
在 tidyverse 团队中,tidymodels 团队的任务更为具体:改进数据科学家进行统计建模和机器学习所需的工具。tidymodels 团队成立于 2016 年底,当时 Max Kuhn 加入 RStudio,此前我们曾就如何支持统计和机器学习建模进行过初步探讨。如今,tidymodels 团队由 Max、Hannah Frick 和 Emil Hvitfeldt 组成,Simon Couch 和 Julia Silge 等前成员也曾是团队成员。Max 因其在 caret 包方面的工作而成为该团队的不二人选。caret 为基本的预测建模任务(例如性能指标和重采样)提供了功能,并在多个建模包中提供了一致的用户界面。基于这项工作,Max 希望创建一个更具扩展性的框架,以集成更高级的工具,例如更复杂的预处理和后处理以及删失回归模型。最终形成的软件包集合被命名为 tidymodels。 tidymodels 的一个显著特点是它轻松随意的命名方式和趣味十足的包名设计。例如,对于一个与 caret 风格相似的包,Max 最初的想法是将其代号命名为"carrot"(胡萝卜),以迷惑外部用户。我建议使用"parsnip"(欧防风),最终这个名字被沿用下来。
6 Tidyverse社区
tidyverse 超越了其技术基础,代表着更为宏大的意义:一个充满活力的全球社区,由实践者、教育者和用户组成,他们运用这些工具解决现实世界的问题。虽然 Posit 的核心团队提供管理和核心软件开发专业知识,但 tidyverse 的真正力量源于其多元化的用户和贡献者社区。
tidyverse 社区的独特之处不仅在于其规模和影响力,更在于其互助互学的文化。无论你是 R 语言的初学者,还是正在探索这些工具的无限可能,你都能在这里找到一个乐于助人的社区。这种协作精神创造了一个良性循环,学习成果在各个方向流动:新用户带来全新的视角和挑战固有观念的问题,而经验丰富的实践者则分享深刻的见解,推动整个生态系统的发展。
对于我们这些 tidyverse 开发者来说,社区既是动力也是指引。你们的成功激励着我们,你们的挑战指引着我们的努力方向,你们的创造力不断拓展着我们对可能性的认知。本节将探讨这个社区的各个层面------从它在不同社交平台上的演变,到社区贡献者在塑造和改进 tidyverse 本身中所发挥的关键作用。
6.1 社交媒体和社区空间
早期的 R 社区以传统的邮件列表为中心,特别是 r-help 和 r-devel 邮件列表。虽然这些列表对早期的 R 用户来说非常宝贵,但它们也反映了当时的学术统计计算文化------技术严谨,但往往对新手不太友好<sup> 21</sup>。这种环境促使人们创建了其他交流空间,例如 2008 年创建的 ggplot2 邮件列表,该列表明确旨在为学习数据可视化的用户提供更具支持性的环境。
但真正的变革始于社区向更现代平台的迁移。Stack Overflow 成为提问和解答编程问题的重要资源,尽管一些自封的版主存在一些不良风气,但总体而言,它仍然是一个友好的环境。Twitter 在 2010 年至 2022 年间发挥了尤为重要的变革作用。#rstats 标签创建了一个空间,用户可以在这里分享实用技巧、庆祝成功并建立人脉。Twitter 上的 R 社区以其支持性和友好的氛围而闻名,这与其他技术社区不太友好的环境形成了鲜明对比。我认为这很大程度上归功于 R 用户的多样性,而R-Ladies、R Forwards、Minorities in R和rainbowR等组织极大地促进了这种多样性。
如今,R 社区大多已转移到 Mastodon、LinkedIn 和 Bluesky 等新平台。我个人觉得 Bluesky 特别实用;虽然这个平台仍在不断发展完善,但它已经成为一个充满活力的中心,维系着 R 社区的独特联系。
6.2 社区贡献者
如果没有社区的贡献,tidyverse 就不会有今天的成就。为了促进这种协作精神,我们积极鼓励并赞扬各种规模的贡献,从修复小 bug 到增强主要功能,我们都乐于接受。支持开发者社区的关键工具之一是 Tidyverse 开发者日,该活动于2019 年启动。这些实践活动提供了一个友好的环境,参与者可以在其中学习如何为 tidyverse 做贡献,并在大量实践指导下解决实际问题。虽然 COVID-19 疫情导致这些活动在2020 年后暂停,但我们已于2024 年恢复举办,并计划将其打造为每年在 posit::conf 大会之后举行的年度活动。
大多数外部贡献者往往贡献少量但意义重大的成果。少数外部贡献者会在多年内投入大量时间和精力。我们通过授予他们包作者身份来表彰这些贡献者。这会将他们正式纳入包元数据(因此他们在 CRAN、包网站和包引用中都会被明确提及),并赋予他们对 GitHub 仓库的写入权限。您可以在我们的tidyverse 治理模型中了解更多关于作者(及其他角色)的权利和责任。
许多软件包作者都是学者,而学术界的衡量标准是引用次数,因此我们在 2019 年撰写了Wickham 等人 ( 2019 )的论文。这使得引用整个 tidyverse 变得容易<sup> 22</sup>,并给予可能从中受益的 tidyverse 维护者学术认可。按字母顺序排列的作者是:Mara Averick、Jennifer Bryan、Winston Chang、Lucy McGowan、Romain François、Garrett Grolemund、Alex Hayes、Lionel Henry、Jim Hester、Max Kuhn、Thomas Pedersen、Evan Miller、Stephan Bache、Kirill Müller、Jeroen Ooms、David Robinson、Dana Seidel、Vitalie Spinu、Kohske Takahashi、Davis Vaughan、Claus Wilke、Kara Woo 和 Hiroaki Yutani。截至撰写本文时,该论文已被引用超过 16,000 次。
自我们发表那篇论文以来,我们又新增了一些维护者,例如 Maximilian Girlich (tidyr, dbplyr)、Mark Fairbanks (dtplyr)、Ryan Dickerson (dtplyr)、Olivier Roy (pkgdown)、Danny Smith (haven)、Maxim Shemanarev (ragg) 和 Teun van den Brand (ggplot2)。
7 维护tidyverse
过去几年,我觉得 tidyverse 已经相当成熟了。它当然并不完美,但感觉我们已经搭建好了所有主要框架,剩下的工作主要是解决各个框架之间的一些细微不一致之处。总的来说,tidyverse 现在的目标是巩固和维护,而不是发展壮大。
为了实现这一目标,我们开展了三个主要项目:
-
2019年,我们制定了R版本支持策略(包括当前版本、开发版本以及之前的四个版本)。结合R的年度发布周期,这意味着我们将支持五年的R版本。这项策略至关重要,因为许多大型企业仍在使用较旧的R版本,但仍然希望能够使用最新、功能最强大的软件包版本。
-
在 2020 年和 2021 年初,我们制定了生命周期策略。tidyverse 的早期阶段以快速迭代和不向后兼容的变更为特征。这使我们能够快速地朝着更好的用户界面发展,但社区认为这种变化速度过快。生命周期策略有助于我们清晰地传达不同功能的状态,并明确承诺向后兼容。
-
2021 年底,我们将大部分 tidyverse 软件包的许可协议重新更改为 MIT 协议。这提高了软件包之间的一致性,使那些在法律方面较为保守的组织更容易相信使用 tidyverse 的风险很小。这一决定是在与社区进行广泛磋商后做出的,包括在 GitHub 上与社区成员进行的讨论,社区成员在讨论中分享了他们不同的观点。
我希望未来能做出另一项可维护性方面的改进:版本控制(Editions )。版本控制的理念是,您可以运行类似这样的代码tidyverse::edition(2025)来选择采用我们截至(例如)2025 年的最佳实践。版本控制使我们能够引导您使用我们认为最佳的 API,并允许您在不破坏现有代码的情况下更改次优行为。例如,我们可以使用版本控制来更改 ggplot2 中的默认配色方案。我们知道这些配色方案可以改进,但如果不破坏大量现有图表,我们就无法更改默认值。
8 接下来会发生什么?
随着 tidyverse 的日趋成熟,tidyverse 团队投入创新精力的领域也开始发生变化。我们的使命是广泛的,我们愿意勇往直前,无论这条路通往何方,即使是那些我们知之甚少的全新领域。目前,我们团队正在探索以下三个新领域:
-
Positron是一个全新的数据科学集成开发环境 (IDE),由 RStudio 的同一团队打造。tidyverse 团队深度参与了 Positron 的 R 语言工具开发 。这令人振奋,因为它赋予我们新的技能,使我们能够在最合适的地方创建代码界面,并在更适合的地方创建图形用户界面。
-
R语言在生产环境中的应用。如果你在工业界工作,大多数分析并非通过撰写一份一次性报告就能完成。相反,你通常会生成一个持续运行数月甚至数年的动态项目。这就是将代码部署到生产环境的挑战所在,而目前由于诸多琐碎细节,这项工作似乎比预期要困难得多。这些细节包括:当代码部署到服务器上时,如何配置数据库身份验证,这些任务会分散你进行数据科学工作的精力。我相信,通过与Posit其他团队的合作,我们可以解决其中许多问题。
-
大型语言模型在数据科学中的应用 。如今,大型语言模型(LLM)无疑将对数据科学的运作方式产生变革性影响。我们认为它们是数据科学家的宝贵助手,而非替代品,是能够帮助您在需要时获得帮助并自动完成繁琐任务的工具。我们在该领域的工作仍处于起步阶段,但其中一项成果是ellmer 包,它允许您在 R 中使用来自不同提供商的 LLM。
回顾 tidyverse 过去二十年的发展历程,真是令人欣喜。它最初只是个人解决数据分析难题的一系列方案,如今已发展成为远超我想象的庞大体系------一个充满活力的生态系统,帮助全球数百万用户更高效地处理数据。我们优秀的社区成员每天都以他们的创造力、慷慨和热情激励着我。
展望未来,我对 R 语言和 tidyverse 的未来比以往任何时候都更加充满信心。LLM 等新技术的出现为数据科学的普及和应用提供了新的机遇。尽管 tidyverse 的核心包可能已经日趋成熟,但仍有无数的机会可以减少摩擦、提高一致性,并帮助人们更有效地解决实际问题。
我依然热爱 R 语言,热爱编程,最重要的是,热爱与这个了不起的社区一起工作。让我们共同期待未来 20 年,让数据科学更平易近人、更强大、更有趣!