(1)数据库设计的三大范式
1NF:字段是原子性的,不能再分;
2NF:非主键字段都依赖于主键;
3NF:非主键字段不能一一确定,如学生信息,班级、班主任,通过班级可以唯一确定班主任;
(2)count(1)、count(*) 与 count(列名) 的区别?
count(1):把表的行数值设置为 1,并统计,不忽略 null;
count(*):统计所有行数,不忽略 null;
count(列名):统计指定列名的行数,忽略 null 的行;
执行速度:
count(列名),列名是主键,查询效率三者中最快;
(3)SQL 查询语句的执行顺序是怎么样的?
DQL 执行顺序:from => on => join => where => group by => cube|rollup => having => select => distinct => order by => limit
DQL 书写顺序:select => distinct => from => join => on => where => group by => having => order by => limit
(4)InnoDB 和 MylSAM(读作:卖艾三木) 主要有什么区别?
存储结构:InnoDB 在磁盘上存储两个文件(.frm .idb),MylSAM 在磁盘上存储成三个文件;
事务支持:InnoDB 提供事务支持;MyISAM 不支持事务;
最小锁颗粒:InnoDB 支持行级锁;MyISAM 只支持表级锁,更新时会锁住整张表;
底层结构:InnoDB 是 B+ 树;MyISAM 索引是 B 树;
主键必需:InnoDB 如果没有主键或者非空唯一索引,会自动生成主键;MyISAM 允许没有任何索引和主键的表存在;
外键支持:InnoDB 支持外键;MyISAM 不支持外键;
(5)binlog 和 redo log 有什么区别?
内容:binlog 记录所有修改操作,redo log 只记录事务的修改操作;
记录时间:binlog 记录修改操作的时刻,redo log 记录事务的开始和结束时间;
作用:binlog 用于数据恢复、数据库备份和主从复制等功能,redo log 用于事务的原子性和持久性;
存储位置:binlog 存储在 MySQL 服务器上,redo log 存储在 InnoDB 的存储引擎中;
(6)执行计划(explain)怎么看?
使用 explain 后面跟查询的 SQL 语句,
重点是 type 列,表示该查询的方式,是查询性能的体现。
按效率排序:system > const > eq_ref > ref > range > index > all
阿里巴巴《Java开发手册》中推荐规范:至少要达到 range 级别,要求是 ref 级别,const 最好。
(7)简单说下索引的分类?
主键索引(pk)、唯一索引(uk)、普通索引(手动创建的 idx)、组合索引(组合的 idx);
(8)什么字段适合/不适合建立索引(SQL 调优的数据库设计方面)?
(1)频繁作为查询条件的字段适合建立索引,where、join、order by 后面的字段;
(2)组合索引,应该把散列度高的值放在前面;
(3)值过长的字段,使用前缀索引;
(4)区分度低的字段,不建议创建索引;
(5)频繁更新的字段,不建议创建索引;
(6)不建议无序的值(身份证号、UUID)建立索引;
参看博客:MySQL数据库给表添加索引、怎么给数据库某个字段建立一个前缀索引
(9)索引哪些情况下会失效呢?(SQL优化:SQL语句)
(1)使用了 or;
(2)使用了 like;
(3)索引字段上使用(! = 或者 < >,not in);
(4)索引字段上使用 is null ,is not null;
(5)字段类型是字符串,没有用引号括起来,造成隐式类型转换,索引失效;
(6)联合索引,查询的条件列不是联合索引中的第一个,最左匹配原则失效;
(7)在索引列上使用内置函数;
(8)对索引列运算;
(9)关联查询,关联的字段编码格式不一样;
(10)优化器估计全表扫描要比索引快,不用索引(查询数据量少、但查询涉及的数据量大,使用索引可能不值得);
(10)一棵 B+ 树能存储多少条数据?
三层 B+ 树,大概可以存 2200 万条记录,查询最多产生 3 次 IO。
(11)为什么用 B+ 树而不用 B 树?
B+ 树是 B 树的变种,B 树能解决的问题,B+ 树也可以。
B+ 树扫库、扫表能力更强,IO 次数更少、排序能力更强、效率更加稳定。
B+ 树,叶子结点存数据,非叶子节点存键值,叶子节点之间用双向指针连接,底层的叶子节点形成一个双向有序链表。
B 树,每个节点都存数据和索引,存储的索引数量少。
(12)聚簇索引与非聚簇索引的区别?
聚簇索引:既有索引,也有表的完整数据;
非聚簇索引:只有索引和建立索引的字段值;
一张表中,只能有一个聚簇索引,可以有多个非聚簇索引。
(13)回表了解吗
当使用辅助索引查询没有建立索引字段的值时,
需要的数据在辅助索引里没有,
要基于主键索引的查询,这个过程叫做回表。
参看博客:优化慢SQL案例(一)
(14)覆盖索引了解吗
如果查询的字段只用辅助索引就能查到,不去回表,叫做索引覆盖。
(15)什么是最左前缀原则 / 最左匹配原则?
在 InnoDB 的联合索引中,查询条件只有匹配了前/左边一个才能匹配下一个。
如,联合索引(a1, a2, a3),查询的条件只有符合联合索引的顺序,不能跳过,才能用到索引。
参看博客:MySQL组合索引,最左匹配原则失效
(16)MySQL 中有哪几种锁,列举一下?
按照锁颗粒度分:行锁、页锁、表锁;
按照兼容性分:共享锁、排他锁;
按照加锁机制分:乐观锁、悲观锁;
按照锁模式分:记录锁、间隙锁、next-key 锁、意向锁、插入意向锁;
(17)意向锁是什么知道吗?
没有意向锁,我们给表加锁时,判断表中是否有行锁,需要遍历表中的所有行,
有了意向锁,在给表加锁时,直接判断是否有意向锁就可以了。
等于说,意向锁的作用是来标识某张表是否有行锁。
(18)MySQL 的乐观锁和悲观锁了解吗?
乐观锁:认为数据的变动不太频繁,不会时时刻刻修改数据,天下太平;
悲观锁:认为被保护的数据极其不安全,时时刻刻都在改动,危机四伏;
(19)讲下 MySQL 事务的四大特性(ACID)?
原子性(A):事务是最小的操作单位,一个事务内的操作要么全都执行,要么都不执行;
一致性(C):数据在事务执行前后的状态是一致的,一致并不是没有改变,而是说初始状态 + 事务操作 = 预期结果。不论事务的执行情况如何,等式都成立。
隔离性(I):事务之间互相隔离,互不影响;
持久性(D):事务提交后,对数据的改变是持久化的。
参看博客:数据库事务
(20)事务的 ACID 靠什么保证?
原子性、持久性:由 redo log 保证,事务提交时,必须先将事务的所有日志写入,持久化,提交操作才算完成;
隔离性:通过数据库锁机制完成;
一致性:由 undo log 保证,记录事务的非查询操作,回滚时反向操作,恢复数据;
(21)事务的隔离级别有哪些,分别会有什么问题?
如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read Uncommited 读未提交 | 是 | 是 | 是 |
| Read Commited 读已提交 | 否 | 是 | 否 |
| Repeatable Read 可重复读【默认】 | 否 | 否 | 是 |
| Serialzable 串行化 | 否 | 否 | 否 |
脏读:A 事务读取到 B 事务未提交的数据;
不可重复读:同一个事务内,查询同一条记录,返回不同的结果;
幻读:事务 A 查询了某个范围内的数据,另一个事务 B 在同步往这个范围内插数据,导致 A 前后查询返回的结果集不一致;
(22)事务的各个隔离级别都是如何实现的?
读未提交:采取读不加锁,读不管其他事务读写;写不管其他事务读;
读已提交 & 可重复读:使用了 MVCC 技术,每个事务只能读取到它能看到的版本;
串行化:读、写都加锁;
(23)MVCC 了解吗?怎么实现的?
MVCC 是多版本并发控制,实现了数据库事务的读已提交、可重复读隔离级别,
是通过隐藏字段,ReadView、undo log 实现的。
ReadView 有四个字段:
m_ids:生成 ReadView 时当前系统中活跃的读写事务的事务 ID 列表;
min_trx_id:最小事务 ID;
max_trx_id:最大事务 ID;
creator_trx_id:生成该 ReadView 的事务 ID;
如果被访问的事务 ID 相等 creator_trx_id,可以访问;
如果被访问的事务 ID 小于 min_trx_id,可以访问;
如果被访问的事务 ID 大于 max_trx_id,不能访问;
如果被访问的事务 ID 处于 min_trx_id ~ max_trx_id 之间,再判断一下是不是在 m_ids 列表中,
在,说明创建 ReadView 时,生成该版本的事务还是活跃的,该版本不可以访问;
不在,说明创建 ReadView 时,生成该版本的事务已经被提交,该版本可以访问。
读已提交、可重复读,MVCC 实现的区别在于生成 ReadView 的时机不同,
读已提交,每次读取数据前都生成一个 ReadView,保证每次都能读到其他事务提交的数据;
可重复读,第一次读取数据时生成一个 ReadView,保证后续读取的结果完全一致;
(24)数据库读写分离了解吗?
将数据库读写操作分散到不同节点上,基本实现是搭建主从集群,一主一从、一主多从。
主负责读写,从负责读,主从之间进行数据同步。
参看博客:MySQL主从结构搭建
(25)读写分离的分配怎么实现?
以下两种方式可以实现:
(1)项目中配置两个数据库,代码中手动加载数据源,一个读主库,一个读从库,查询时手动指定使用哪个数据源;
(2)使用第三方工具,如 dynamic-datasource,可以使用注解的方式,指定 DAO 方法使用哪个数据库;
参看博客:自定义数据源实现读写分离、MySQL主从的应用
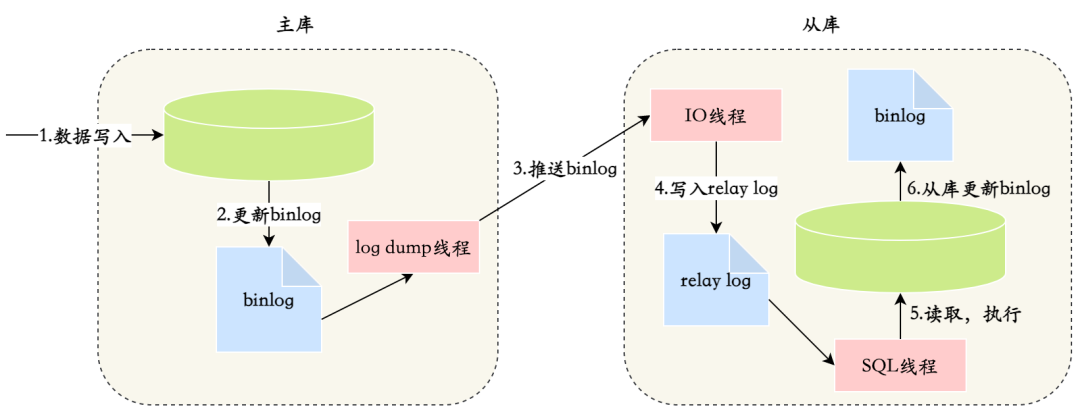
(26)主从复制原理了解吗?
(1)master 数据写入,更新 binlog
(2)master 创建一个 dump 线程向 slave 推送 binlog ;
(3)slave 连接到 master,创建一个 IO 线程接收 binlog,并记录到 relay log 中继日志中;
(4)slave 开启一个 SQL 线程读取 relay log 并在 slave 执行,完成同步;
(5)slave 记录自己的 binlog;
(27)主从同步延迟怎么处理?
(1)写操作后的读操作,指定主节点;
(2)读从节点未获取到数据,再读一遍主节点;
(3)关键业务读主节点,非关键业务读从节点;
(28)分库分表要怎么实现
分库,分库有两种类型,水平分库和垂直分库
-
水平分库:以字段为依据,按照一定策略(hash、range),将一个库中的数据拆分到多个库中;
-
垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中;
分表:
-
水平分表:按照策略,将一张表记录路由到不同的表上,常见的策略有范围、hash、配置路由;
-
垂直分表:根据业务相关性,拆分表字段,将一张表拆分为多张表;
常用的分库分表工具有,sharding-jdbc、Mycat
参看博客:Sharding-jdbc使用(一:水平分表)、Sharding-jdbc使用(二:水平分库)
(29)那你觉得分库分表会带来什么问题呢?
分库:事务、跨库 join;
分表:
(1)跨节点的 count、order by、group by 以及聚合函数的问题;
(2)数据迁移,容量规划,扩容等问题;
(3)全局 ID 唯一问题;
(30)水平分表有哪几种路由方式?
范围路由、Hash 路由、配置路由
(31)不停机扩容怎么实现?
第一阶段:在线双写、查询走老库;
第二阶段:在线双写,查询走新库;
第三阶段:旧库下线;
(32)百万千万级大表如何添加字段?
(1)中间表转换:创建新表,拷贝旧表结构,添加字段,再将旧表数据复制过来,删除旧表,修改新表表名为旧表表名;
(2)使用 pt-online-schema-change 工具,可以在线修改表结构,原理也是通过中间表;
(33)MySQL 数据库 cpu 飙升的话,要怎么处理呢?
使用 top 命令查看,是不是 MySQL 应用导致的;
如果是,连接 MySQL,使用 show processlist 查看 session 情况,确定是不是有消耗资源的 sql 在运行;
找出消耗高的 sql,查看执行计划是否准确,索引是否有缺失,数据量是否太大;
处理:
(1)kill 掉这些线程,同时观察 cpu 使用率是否有下降;
(2)进行相应调整,如加索引、改 sql、改内存参数;
(3)重新跑这些 sql;
结合业务分析,是不是突然有大量的 session 连接进来导致的,为什么连接数会激增,再做出相应的调整,如限制连接数等;
参看博客:MySQL查看连接情况