它是现代C++编程中使用最频繁、性能最高的容器之一,理解其工作原理至关重要。
1. 核心概念:什么是 unordered_map?
std::unordered_map 是一个无序的关联式容器 ,存储的是键值对 。它的核心特性与 std::set 形成鲜明对比:
-
键的唯一性 :每个键(key)在容器中是唯一的,不允许重复。
-
无序性 :元素在容器中没有任何特定的顺序 ,不会像
map那样自动排序。元素的排列顺序由哈希函数决定,并且在插入时可能会动态变化。 -
哈希表实现 :基于哈希表 实现,这使得其平均情况下的查找、插入、删除操作达到了常数时间复杂度 O(1)。
2. 底层实现:哈希表
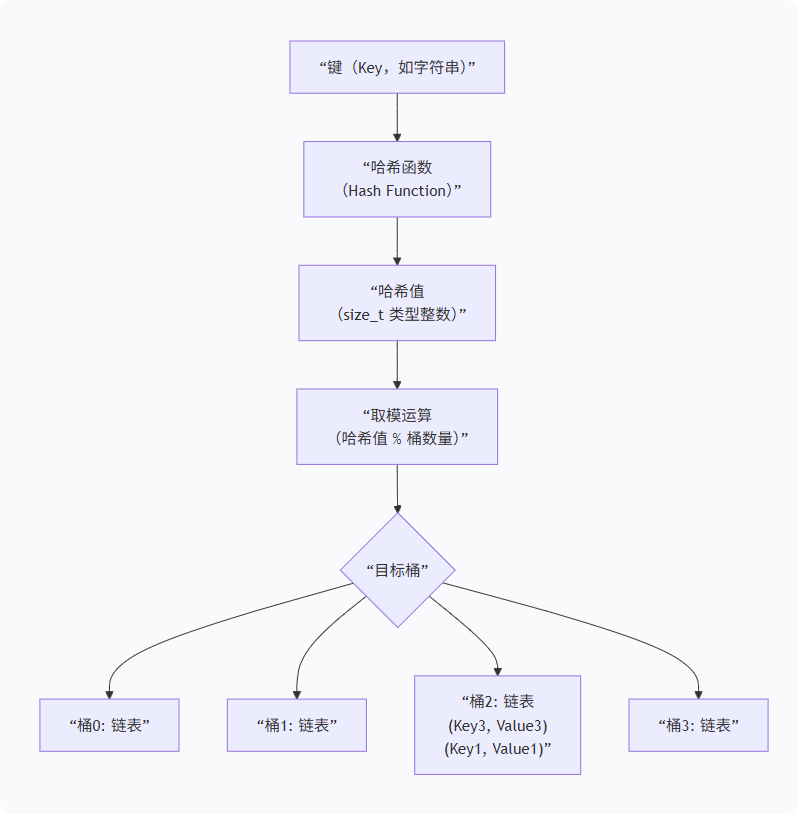
这是理解 unordered_map 所有行为的基石。一个典型的实现包含以下几个关键部分:
-
桶数组:一个固定大小或可动态扩容的数组。数组的每个位置称为一个"桶"。
-
哈希函数 :将任意大小的键(key)映射到一个固定大小的"哈希值"。理想情况下,不同的键应产生不同的哈希值。
-
映射到桶:通过对哈希值进行取模等操作,决定键值对应该放入哪个桶中。
-
解决冲突 :当两个不同的键被哈希到同一个桶时,就发生了"哈希冲突"。
unordered_map通常采用 "链地址法" ,即每个桶里维护一个链表(或小型向量),将哈希到同一桶的所有元素链接起来。
下图清晰地展示了其工作原理:
3. 基本用法与代码示例
cpp
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main() {
// 1. 初始化
unordered_map<string, int> studentScores = {
{"Alice", 95},
{"Bob", 80},
{"Charlie", 88}
};
// 2. 插入元素(多种方式)
studentScores["David"] = 92; // 方式1: 使用下标运算符(若键不存在则创建)
studentScores.insert({"Eve", 85}); // 方式2: 使用 insert 成员函数
studentScores.emplace("Frank", 90); // 方式3: 高效的原位构造,避免拷贝
// 注意:使用下标运算符访问不存在的键会插入该键(值被默认初始化)
cout << "Score of 'Unknown': " << studentScores["Unknown"] << endl; // 输出 0,并插入了("Unknown", 0)
// 3. 访问与查找元素
// 使用下标(注意上述副作用)
cout << "Alice's score: " << studentScores["Alice"] << endl;
// 推荐:使用 find() 安全查找(无副作用)
auto it = studentScores.find("Bob");
if (it != studentScores.end()) { // 判断是否找到
cout << "Found Bob, score: " << it->second << endl; // it->first 是 key, it->second 是 value
} else {
cout << "Bob not found." << endl;
}
// 4. 遍历(无序!顺序不可预测且可能随时间变化)
cout << "\nAll students (unordered):" << endl;
for (const auto& pair : studentScores) { // pair 是 std::pair<const string, int>
cout << pair.first << ": " << pair.second << endl;
}
// 5. 删除元素
studentScores.erase("Unknown"); // 通过键删除
// 也可以通过迭代器删除: studentScores.erase(it);
// 6. 常用信息
cout << "\nBucket count: " << studentScores.bucket_count() << endl;
cout << "Load factor: " << studentScores.load_factor() << endl; // 平均每个桶的元素数
cout << "Size: " << studentScores.size() << endl;
return 0;
}4. 进阶特性与性能调优
自定义键类型
如果你的键是自定义类型(如结构体),你必须为其提供两样东西:
-
自定义哈希函数 :告诉
unordered_map如何计算你的类型的哈希值。 -
自定义相等比较函数 :告诉
unordered_map如何判断两个键是否相等。
cpp
struct Person {
string name;
int id;
};
// 1. 定义哈希函数(仿函数)
struct PersonHash {
size_t operator()(const Person& p) const {
// 组合现有类型的哈希值(这是一个简单示例,生产环境需更严谨)
return hash<string>()(p.name) ^ (hash<int>()(p.id) << 1);
}
};
// 2. 定义相等比较(仿函数)
struct PersonEqual {
bool operator()(const Person& a, const Person& b) const {
return a.name == b.name && a.id == b.id;
}
};
// 使用自定义类型作为键
unordered_map<Person, string, PersonHash, PersonEqual> personMap;性能调优参数
你可以在构造时预分配资源,以优化性能:
-
初始桶数量:预留足够多的桶,减少重建哈希表的次数。
-
最大负载因子 :当
负载因子 = size() / bucket_count()超过此阈值时,容器会自动增加桶的数量并重建哈希表(这是一个相对昂贵的操作)。
cpp
// 预留至少128个桶,当负载因子超过0.75时进行重哈希
unordered_map<string, int> tunedMap(128);
tunedMap.max_load_factor(0.75);
// 或者一次性预留空间:创建后立即 rehash
tunedMap.reserve(100); // 提示容器准备容纳大约100个元素5. 核心特点总结与对比
| 特性 | std::unordered_map |
std::map |
std::vector<std::pair> |
|---|---|---|---|
| 底层实现 | 哈希表 | 红黑树 | 动态数组 |
| 元素顺序 | 无序(取决于哈希) | 严格按键排序 | 插入顺序 |
| 查找复杂度(平均) | O(1) | O(log n) | O(n) |
| 查找复杂度(最坏) | O(n)(所有键冲突时) | O(log n) | O(n) |
| 内存开销 | 较高(桶数组+链表/节点) | 较高(树节点指针) | 低(连续内存) |
| 迭代器稳定性 | 插入可能使所有迭代器失效(重哈希时) | 除删除元素外均稳定 | 插入可能导致全部失效 |
| 关键用途 | 快速键值查找,不关心顺序 | 需要有序遍历的键值对 | 需要保持插入顺序的键值对 |
6. 典型应用场景
-
高速缓存 :用键快速查找缓存的结果(如
std::unordered_map<std::string, CacheEntry>)。 -
词频统计 :遍历文本,用
unordered_map<string, int>统计每个单词出现的次数。 -
数据库索引模拟:内存中建立某个字段到记录的快速映射。
-
去重计数:检查对象是否已存在并关联附加信息。
7. 需要特别注意的"陷阱"
-
下标运算符
[]的副作用 :map[key]如果 key 不存在,会自动插入 一个键值对(键为key,值为该类型的默认值)。因此,在只做"查找"时,务必使用find()方法。 -
最坏情况性能:如果哈希函数很差或数据特殊,导致大量冲突,性能会退化成 O(n)。对于自定义类型,设计一个好的哈希函数至关重要。
-
无序性 :其遍历顺序是不可预测的,并且在不同平台、不同时间运行都可能不同。不要依赖其内部顺序。
-
迭代器失效 :插入操作可能导致重哈希 ,从而使所有迭代器失效(而不仅仅是插入位置)。删除操作只会使指向被删除元素的迭代器失效。
8. 与 unordered_set 的关系
unordered_map 存储的是键值对,而 unordered_set 只存储单个值(可视为只有键没有值的 unordered_map)。它们的底层实现(哈希表)和核心特性(无序、O(1)平均查找)是完全一致的。
简单记忆 :当你需要存储一个可快速查找的集合 时用 unordered_set;当你需要存储一个可快速通过键查找关联值 的字典 时用 unordered_map。
理解 unordered_map 的关键在于掌握哈希表的原理 ,并牢记其 "无序" 和 "O(1)平均访问" 的特性。它在现代C++高性能编程中是不可或缺的工具。