🔥 本文专栏:Linux网络
🌸作者主页:努力努力再努力wz


💪 今日博客励志语录 :
我们常苦苦寻找那个"正确"的选择,但或许,比选择更重要的是:鼓起勇气,让自己成为那个"使选择变正确"的人。
引入
在结束了Linux系统部分的学习之后,我们主要掌握了Linux的基本指令、进程与信号、进程间通信、线程等内容。通过这部分内容我们可以发现,它们主要围绕同一台设备上的一个或者多个进程展开。然而在当前的互联网时代,每一台计算机或设备都不是孤立存在的。正如人类具有社会属性,无法完全与世隔绝,当我们步入社会,必然需要与他人接触、建立联系、形成社交网络一样,计算机也需要与其他计算机进行通信,即数据交换。因此,计算机也不是一座"社交孤岛"。
由于计算机之间的通信涉及不同设备,要实现这种跨设备通信,就离不开我们今天要讨论的主题------ 网络 。在本篇博客中,我将从两个方面展开:首先带领大家认识 网络 ,并补充必要的 网络 基础知识;在具备一定基础后,我们将进一步学习 网络编程的相关内容。从本文开始,我们就正式进入Linux 网络 部分的学习阶段。
网络
根据上文可知,不同计算机之间存在着通信的需求。所谓通信,本质上就是数据交换。这里需要明确的是,计算机本身作为一种物理设备,并不直接产生通信需求;真正需要通信的,是运行在计算机上的进程。我们可以通过一个例子来理解:大家的电脑上通常安装了微信,作为社交软件,其核心功能正是通信。用户可以通过微信向其他用户发送消息,对方也可以回复消息。而微信本质上是一个进程,运行在不同的设备上。假设用户A向用户B发送一条消息,其背后的过程是:用户A设备上的微信进程生成数据,经过网络传输,最终送达用户B设备上的微信进程。
这里需要明确的是,如果用户A的电脑并未启动微信,即微信进程并未运行,那么该设备是否还会向用户B的设备发送数据?结合现实经验可知,这是不可能的。同样,手机等移动设备也经常进行数据通信。例如,我们常通过手机上的抖音应用观看短视频。这一过程涉及手机向抖音服务器发送请求,服务器接收请求后,将对应视频数据传回手机。若未打开抖音应用,手机自然不会向服务器发送任何请求。
因此,我们可以得出结论:不同计算机或设备之间需要通信,本质上并非计算机本身需要通信,而是其上运行的进程需要通信。所以说,不同设备之间的通信,实质是进程间通信。
提到" 进程间通信 "这一专业术语,大多数读者应不陌生。在学习Linux系统时,我们曾接触过进程间通信的相关内容。但需注意的是,Linux中讨论的进程间通信,通常指同一台设备上不同进程之间的通信;而本文所讨论的,是不同设备上进程之间的通信。尽管场景不同,两者并非毫无关联。我们可以从同一设备内的进程间通信出发,推广至不同设备间的进程通信。下面首先回顾同一设备内的进程间通信。
在同一设备中,由于进程具有独立性,实现进程间通信的核心思路是创建一份共享资源,使通信双方都能访问该资源。其中一个进程向共享资源中写入数据,另一个进程从中读取数据,从而实现通信。这类共享资源可以是管道、共享内存、消息队列等形式。可以理解为,数据通过共享资源这一媒介,从一个进程传递到目标进程。
基于同一设备内进程通信的原理,我们可以推及不同设备间进程的通信。在这种情况下,数据需要经过某种介质进行传输。类比声音传播:一人对另一人说话时,声音需通过空气、液体或固体等介质,才能传到对方耳中。数据通信同样如此,也需要依赖介质完成传输。
通信介质和设备
我们知道,通信设备之间传输的各种数据,在计算机中本质上是由0和1组成的二进制序列。为了将这些二进制数据从一个设备传送到另一个物理上隔离的设备,就需要将其转换为物理信号,例如电信号或光信号。这些信号通过特定的物理传输介质进行传播,最终被目标设备接收。
负责将二进制数据转换为物理信号(并反向转换)的设备是计算机中的网卡。网卡能够将数字信号转换为适于传输的物理信号,同时也具备接收物理信号并将其还原为二进制数据的能力。需要注意的是,网卡是物理信号的产生和接收设备,并不是传输介质本身。
接下来,我们将介绍几种常见的物理信号传输媒介,首先从 同轴电缆 开始。
同轴电缆 的结构包含一根中心的铜导线,外层依次包覆绝缘层和屏蔽层。二进制数据以电信号的形式在铜导线中传播。多个设备可以连接到同一根同轴电缆上。由于所有设备共享同一传输介质,一个设备发出电信号时,电信号会沿着电缆向两端传播,因此连接在该电缆上的所有设备都会接收到信号,这种传输方式称为 广播 。
设备间的通信通常是点对点的,也就是涉及一个发送方和一个接收方。通过同轴电缆传输时,情况类似于教室中的老师点名:老师喊"张三"时,虽然目标是张三,但全班学生都能听到。同样地,连接在同一电缆上的所有设备都会收到某一设备发出的数据。而这里的数据,除了携带数据本身,还会携带接收者的身份标识信息,每个设备在接收到电信号后,会先将其转换回二进制数据,然后检查数据中携带的目标标识信息。若标识与自身不匹配,设备会丢弃该数据;只有匹配时才会接收。
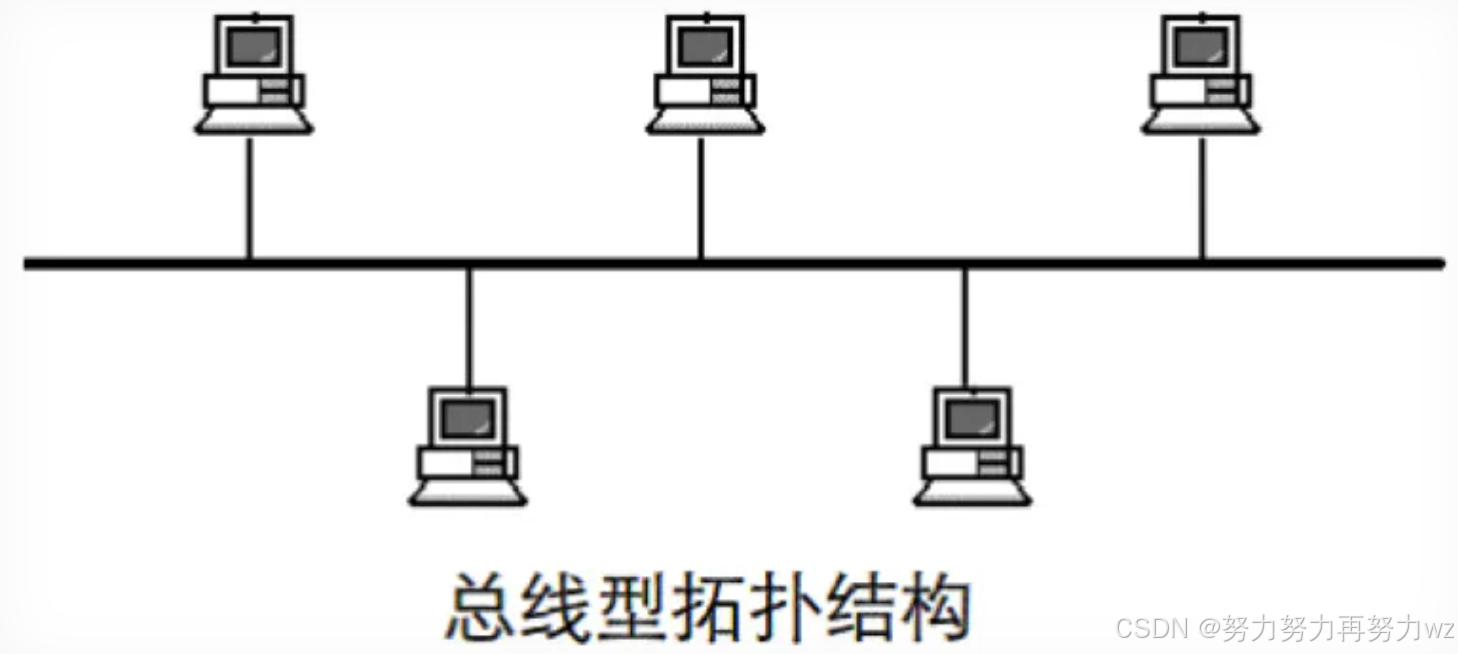
这种通过共享介质连接的设备构成了总线型拓扑。该结构会引发一个关键问题: 数据冲突 。
由于所有设备通过同一根电缆发送数据,在信号转换过程中,通常约定高电平(如 2.5V--5V)表示"1",低电平(如 0V 至 -2.5V)表示"0"。如果多个设备同时发送信号,它们产生的电压会在电缆上叠加,可能导致合成电压超出正常范围(例如高于 5V 或低于 -2.5V),或处于无法识别的中间电平。接收设备无法将异常电压正确解析为 0 或 1,从而造成数据损坏,即发生数据冲突。这种情况下,整个总线构成一个冲突域。
这种情况与多线程并发访问共享资源导致的数据竞争问题非常相似。在软件层面,我们常用互斥锁实现串行访问以保障数据一致性;在硬件层面,解决数据冲突的核心思路也是将并发访问转为串行访问。具体方法是:设备在发送数据前先检测电缆上是否有信号传播。若检测到信号,说明介质忙,设备会等待直至电缆空闲再尝试发送。
然而,由于信号传播存在延迟,该方法仍无法彻底避免冲突。例如,一个设备可能在信号尚未到达检测点时误判电缆空闲并开始发送,从而导致冲突。为此,引入了二次避免机制:设备在发送过程中持续监听电缆,若检测到电压异常(冲突发生),则立即停止发送,并执行退避算法后重试。这一机制即为 CSMA/CD(载波侦听多路访问/冲突检测)。
那么,这里简要介绍一下退避算法 。在以太网中,当网卡发送一个数据帧后未能成功,便会启动重传机制。网卡会记录当前尝试传输该数据帧的次数,记为重传次数 k。k 通常会设定一个上限值,一般为 16 次;若超过该次数仍未能成功传输,网卡将放弃该数据帧的发送。
在每次重传之前,设备需要等待一段随机时间,这段等待时间通过退避算法计算得出。具体过程如下:首先计算出退避窗口大小为 2^k,然后在区间 0, 2\^k 中随机选取一个整数 r。接着,将 r 乘以一个固定的时隙长度(slot time),该值通常为 5.12 微秒。最终得到的 r * 5.12u s 即为设备需要等待的时间。
等待结束后,设备会重新尝试监听信道,并在信道空闲时再次发送数据。这种机制有效降低了多个设备在重传时发生再次碰撞的概率。
在此基础上,我们引入第二种传输介质------ 双绞线 。
双绞线 由内部两根绝缘的铜导线绞合而成,外部包裹绝缘层和屏蔽层。将两根导线绞合的主要目的是增强抗电磁干扰的能力。现代常用的双绞线通常由2对或4对绞合铜导线组成,其中一对可用于数据传输,另一对可用于数据接收。若两台计算机通过一根 双绞线 直接相连,该 双绞线 属于共享介质,但与同轴电缆不同之处在于,数据的发送和接收分别在两对不同的导线中进行,因此不会因同时发送而产生数据冲突。这意味着双方可以在这条 双绞线 上实现全双工通信。

在实际网络通信中,设备间的通信往往不是固定点对点的,而是可能需要与多个设备进行通信。通信的前提是建立 通信信道 ,正如从一个地区向另一个地区发送快递,需要先修建连接两地的高速公路。计算机通常配备网线接口,用于插入网线,而网线的另一端连接另一台设备。若一台计算机需要与多个设备通信,由于硬件接口数量有限,不可能为每个连接都提供一个独立接口。这时就需要引入一种设备------ 集线器 。

集线器提供多个网线接口,用于连接双绞线。双绞线一端插入集线器,另一端连接设备。通过 集线器,一个设备能够与多个不同设备建立连接,这些设备共同构成一个局域网。在物理连接上, 集线器及其所连设备形成星型拓扑结构。
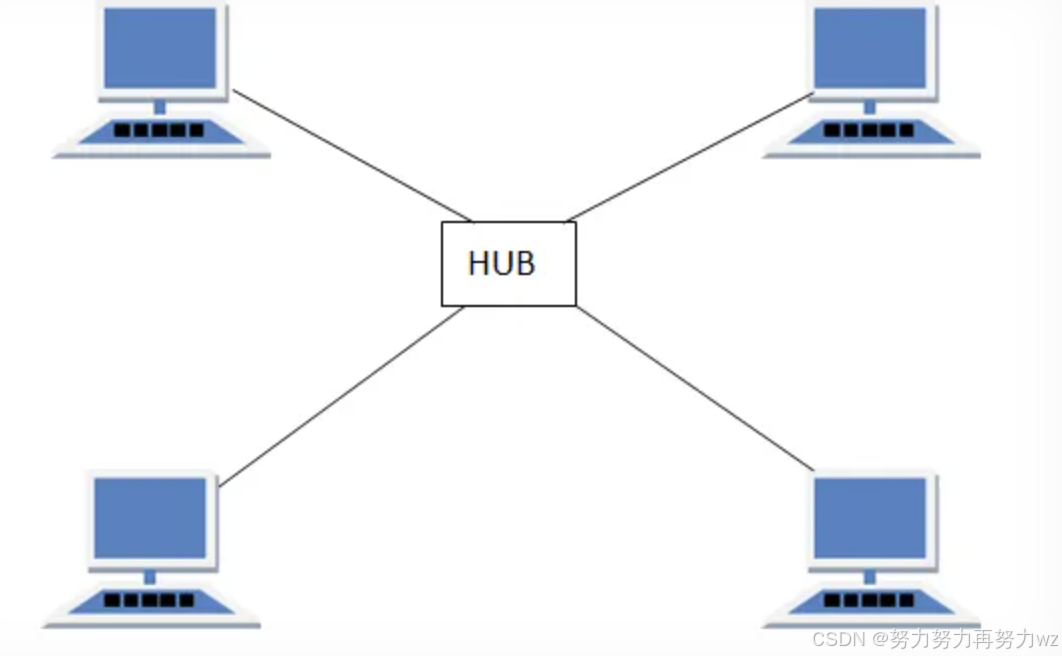
需要注意的是,尽管 集线器连接多个设备,其通信方式仍是广播式的:当某一设备发送数据至 集线器, 集线器接收数据后会将信号放大。这是因为电信号在传输过程中会因电阻发热导致能量损耗和信号衰减。放大后的信号将被转发到除来源端口外的所有其他端口,使得所有连接设备都能收到该数据。尽管设备与集线器之间的双绞线支持全双工通信, 集线器内部实际上相当于一条共享总线,因此整个局域网仍以半双工方式工作,存在数据冲突的可能。冲突域集中在集线器内部,而非整个网络。因此,虽然物理拓扑是星型,逻辑上仍可视为 总线型拓扑,冲突检测仍采用CSMA/CD机制。
由此可见, 集线器并未实现真正的点对点通信,即数据只能被目标设备接收,而非被所有设备广播。尽管非目标设备在正常情况下会丢弃非己数据,但通过特定抓包软件可使网卡不丢弃数据,从而截获通信内容,带来安全风险。这种局限性促使了新设备的出现------ 交换机。 交换机的核心能力是能够实现数据的精准转发。关于双绞线如何配合交换机实现该机制,我们将在后续内容中补充必要知识后再进一步阐述。
网络协议栈
实际上,设备之间的通信本质上是进程间的通信。为了帮助读者快速建立直观理解,我们仍然借助一个生活中的例子进行说明。
进程间通信通常采用点对点通信,会涉及一个发送方和一个接收方。发送方向接收方传输数据的过程,可以类比为从成都寄送一个快递给新疆的朋友。这里的关键在于,我们并不会亲自乘坐飞机将快递直接送到对方手中------正如现实生活中大家所习惯的,我们通常会将包裹交给楼下的菜鸟驿站。驿站将包裹送往成都市的分拣中心,分拣中心再将其装车,经由高速公路运往下一个城市的分拣中心。经过多次中转,快递最终到达目标城市的分拣中心,分拣中心确认收货地址位于该城市后,便会安排派送,最终快递送达朋友手中。
这个例子模拟的正是网络通信的基本流程。那么第一个值得思考的问题是:为什么数据不直接从起点发送到终点,而是需要经过多个中间节点(分拣中心)进行中转?
虽然在现实生活中,确实可以使用飞机等运输工具实现点对点直达运输,但在计算机通信中,数据本质上是一串二进制序列,通过网络接口卡(网卡)转换为物理信号(如电信号、光信号或电磁波)进行传输。这些信号在传输过程中会受物理距离的限制而逐渐衰减。例如,电信号在电缆中传输时会因电阻发热造成能量损失;电磁波虽无需物理介质,但在空间中传播时也会因障碍物阻挡或扩散而减弱从而导致数据损坏。因此,设备之间无法实现"一端直达另一端"的通信方式,信号必须在传输过程中被中继放大,才能保证数据的完整可达。
这正是上述例子中"分拣中心"所起的作用:它们相当于网络中的中继设备(如路由器或交换机),接收信号后对其进行整形、放大,再转发至下一节点,从而确保信号能够长距离传输而不至失真损坏。通过这样逐段接力传输,数据最终才能准确送达目标设备。
需要注意的是,数据由设备上的进程产生,最终也由设备上的进程接收处理。如上所述,数据会经由网卡转换为物理信号,通过传输介质经过多个中继节点,最终到达目标设备。
那么,我们将视角聚焦于 发送方 。我们知道, 发送方 需要准备数据,最终将其转换为物理信号,通过传输介质并经由多个节点的转发到达目的地。这里需要注意的关键点是:发送方所准备的内容并不仅仅是数据本身,还会携带额外的信息。
假设我要从成都寄送一个花瓶到新疆。在寄送快递时,毫无疑问会包含花瓶本身,但同时还会附带一项"约定"------即告知 接收方 ,所寄物品是花瓶,收到时需轻拿轻放,避免打碎。这个约定就是为了告诉接收方应如何处理最终收到的数据。除了约定之外,还会携带另一项关键信息,即接收方的身份与地址。因此,发送方实际发出的数据,除了数据本身,还包含这些额外的信息。
我们知道,这些数据最终必须通过底层硬件(即网卡)转换为物理信号,才能放入传输介质进行传输。而计算机是一个具有层级结构的体系,进程无法直接与硬件交互,不能直接将数据写入 网卡 并令其转换为物理信号。这是因为进程通常代表用户,若进程能够直接操作硬件并修改其中的数据,意味着用户可随意访问和修改硬件数据,必将带来各种安全风险。
因此,在上层软件与下层硬件之间存在一个屏障,即 操作系统 。操作系统可类比为银行的前台服务人员:服务人员向客户提供选项(如存钱、取钱),客户选择其中一项(如取钱)后,由服务人员响应请求,而不是让客户亲自进入银行金库随意取款。
同理,当一个进程需要与另一台设备通信时,它要发送的数据最终也需通过网卡转换为物理信号发送出去。根据上文,进程无法直接与硬件交互,因此操作系统会向上层进程提供特定的系统调用接口。进程通过调用这些接口,将待发送的数据交给操作系统,再由操作系统转交给硬件(网卡),最后由网卡将数据转换为物理信号发出。
由此可见,从进程产生数据到最终发送的整个流程,以进程为起点, 自顶向下 贯穿操作系统,最终到达硬件。因此我们可以明确,数据的发送过程必然是一个 层级化 的过程。
同理,我们将视角转向 接收方 。接收方最终通过网卡接收数据,将物理信号转换为数字信号(即一串二进制序列)。注意,网卡不会直接将这串二进制序列交付给上层进程,因为正如前文所述,上层应用无法直接与硬件交互,中间存在操作系统这一屏障。因此,数据的交付过程与发送过程是 对称 的,即 自底向上 贯穿操作系统,最终交付给上层应用进行消费。
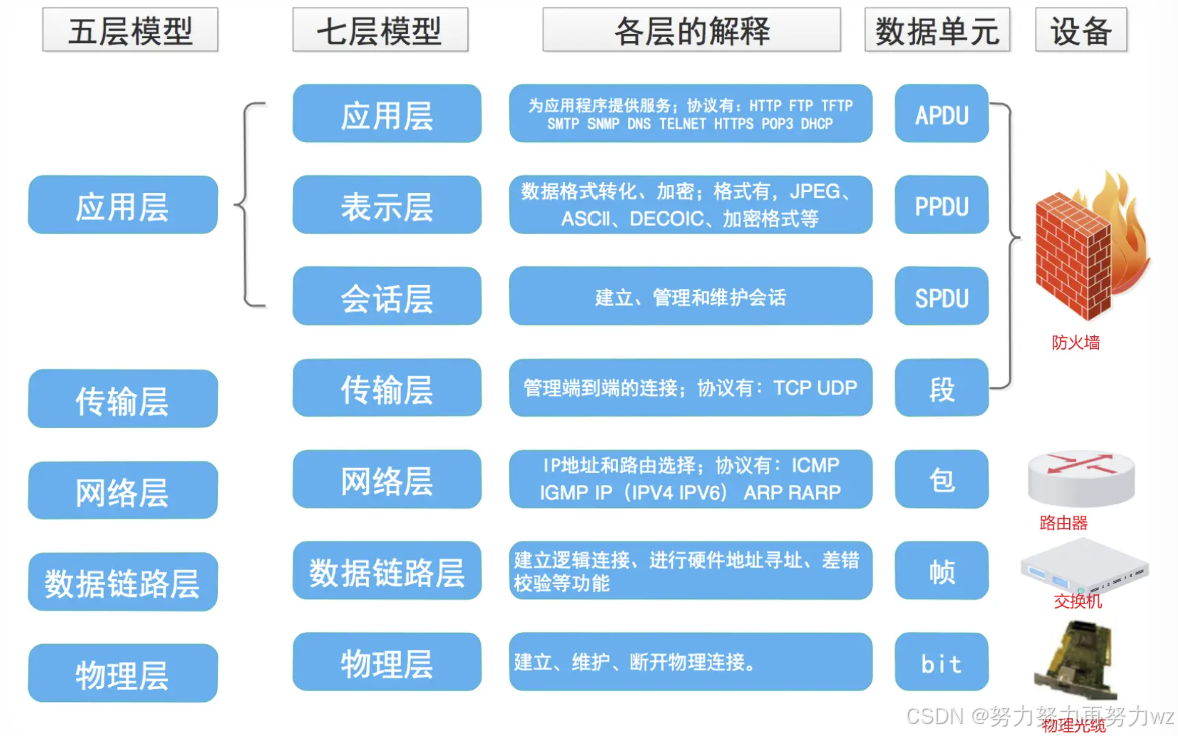
既然数据的发送与接收都是层级化的过程,我们就可以用一个层级模型来描述它们。这里引入 OSI 七层模型,是由国际标准化组织ISO定制的,从高到低依次为:应用层、表示层、会话层、传输层、网络层、数据链路层和物理层。

OSI 七层模型详细描述了数据发送与接收过程中各层所负责的工作。结合前文,我曾提到设备最终发出的数据除了数据本身,还会携带额外信息,这些信息有一个专业术语,即协议。协议是通信双方的一种约定。我们仍以一个例子来理解:
假设我要从成都寄一封信到新疆。首先,写好信的内容后,除了提供内容本身,我还需告知对方信件所使用的语言。在将信纸装入信封时,我需要在信封上额外标注这封信是葡萄牙语还是英语,以便对方能按正确语言解读内容------这就是应用层协议的作用。
若我担心信件内容涉及隐私,可能被他人窥看,我可以将信件内容的格式打乱并进行加密,通过采取特定的算法。此时,我需要再套上一层信封,告知对方我所使用的数据格式和加密方式。这种格式和加密方式只有我们双方知晓,即我们之间规定的协议,外人将无法正确解析信件内容------这就是表示层协议的作用。于是,我在已封装好的信件外又加了一层信封,标注了数据格式与加密方式。
除了上述内容,接下来还必须再包装一层信封,其上标注收件人地址。可以看出,OSI七层模型中每一层各司其职,实现各自的功能,且层与层之间是 低耦合 的。下层只需为上层提供固定的接口(即服务),上层处理完数据后,只需调用下层的接口即可。这种低耦合的分层实现方式具有显著优势:若某一层的实现方式发生改变,只要接口保持不变,上层就完全不受影响。
例如,我们将信件层层打包后,最终交给菜鸟驿站,再由其送往本地分拣中心。菜鸟驿站只需提供一个货架(即接口),我们将打包好的信件放在货架上即可,无需关心后续流程。无论菜鸟驿站今天用电瓶车还是明天用大客车来运输货架上的货物,亦或是底层传输介质使用双绞线还是电磁波,只要"货架"这个接口存在,上层的实现就丝毫不受影响。我们仍按原方式将信件层层打包,最终放到货架上即可。
需指出的是,OSI模型只是一个参考模型,旨在帮助我们更好地理解网络通信中数据发送与接收的过程。而在实际中广泛运用的是 TCP/IP 五层协议(常称为TCP/IP协议栈),它才是真正实践中使用的模型
TCP/IP协议栈
我们知道,在实际应用中更常使用的是 TCP/IP 协议栈,而不是 OSI 七层模型。那么读者可能会首先产生一个疑问:TCP/IP 协议栈与 OSI 七层模型之间有什么区别?实际上,TCP/IP 协议可以看作是对 OSI 七层模型中某些层次的合并。例如,它将应用层、表示层和会话层统一归为应用层。通常将 TCP/IP 视为四层而非五层模型的原因,是数据链路层和物理层有时也被合并为网络接口层(或称物理层)。
OSI 模型不适用于实际部署的主要原因,是其分层过于细致,导致实现复杂。而 TCP/IP 的分层方式则与数据在设备间的发送和接收过程密切相关。我们知道,数据发送从进程开始,自顶向下贯穿操作系统的各层,最终到达硬件;接收过程则与之对称。因此,我们可以将 OSI 的七层模型映射到计算机系统的层级架构上:应用层、表示层和会话层的功能通常由上层的应用程序进程负责,因为这些层次往往需要根据用户具体需求进行个性化设计和实现,与业务逻辑紧密相关;传输层和网络层的功能则由操作系统实现,这两层的功能相对固定,不依赖于具体应用,因此适合由操作系统统一维护以保证稳定性;而数据链路层和物理层,则主要由底层硬件(例如网卡)实现。
正因如此,TCP/IP 协议的结构更符合实际通信的需求,在实践中被广泛采用。
在后续讨论中,我们将统一采用 TCP/IP 模型来描述数据在设备间的发送与接收过程。 TCP/IP 协议栈的每一层都对应特定的协议,正如前文所述,各层之间是 低耦合 的。所谓 低耦合 ,指的是上层无需关心下层的具体实现方式,而下层也无需理解上层传来的数据内容。每一层仅负责本层的协议处理,不涉及其他层的协议细节。为了帮助理解,我们仍以打电话为例进行说明。
在电话通信过程中,通话双方可以约定使用某种语言(如中文或英文)进行交流。一旦建立起通信协议,双方会认为自己在直接与对方交谈。但实际上,通信并非直接进行,而是通过电话设备中转------电话将声音转换为数字信号,再转为电磁波发送至另一方电话,接收方电话再将电磁波还原为数字信号,最后转换为声音。整个过程是对称的。
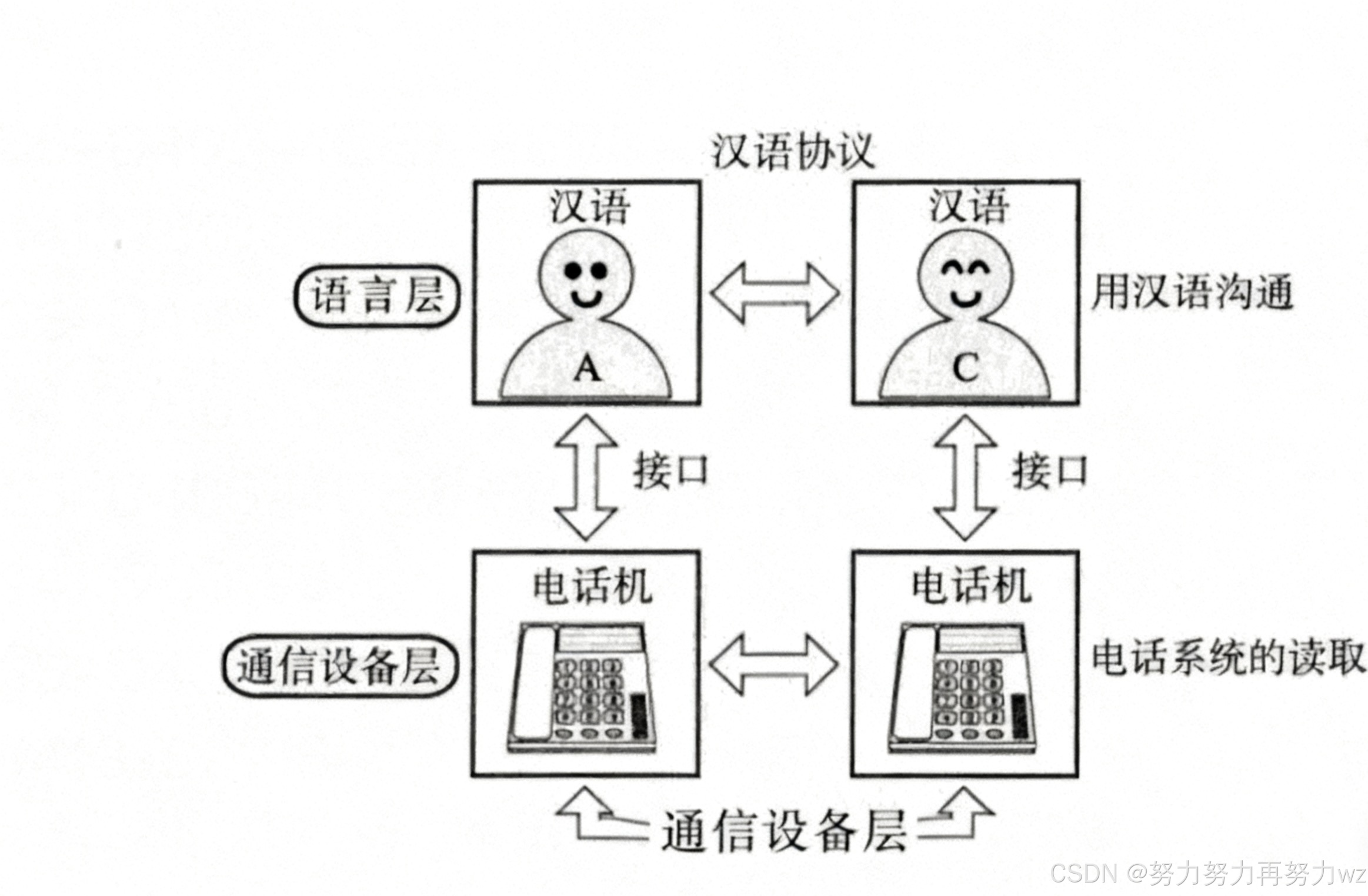
我们之所以感觉是在与对方直接对话,而非与电话设备交流,正是因为每一层仅关注本层的协议。对于上层(即通信双方)而言,只关心对方所说的内容以及所使用的语言。这些内容(即数据)会被传递至下一层(电话设备)。而电话设备并不关心上层数据的具体含义,仅负责在本层添加相应协议信息(如目标电话号码),再将数据传递至更下层。每一层都重复类似的过程:接收上层数据,添加本层协议,再继续传递。这个过程类似于将一封信逐层装入不同信封。
在接收端,过程正好相反:数据从底层开始逐层解封。由于封装过程是从上至下依次进行,解封时则从最外层(底层)开始,逐层剥离协议,将数据向上传递。每一层只处理本层对应的信封信息,解封后将其交予上层。最终,通信的另一端获得原始数据,且完全感知不到底层各层的处理过程。这种分层处理的方式,正是TCP/IP协议栈的核心优势之一。
根据上文可知,数据从发送设备发出后,通常会经过多个中间节点------即所谓的"中转站",通过它们逐级转发,最终到达目标设备。在之前的讨论中,我使用了" 中转站 "这一比喻性概念,但尚未具体说明其实际所指。现在,在了解了 TCP/IP 模型之后,我们可以明确:" 中转站 "实际上对应的就是 路由器 。 路由器 在网络传输过程中所扮演的角色,正是中转或转发数据。
既然 路由器 承担中转功能,那么它必然具备接收和发送数据的能力。回顾前文,设备的数据发送和接收过程都可以通过 TCP/IP 五层模型进行描述:数据发送遵循自顶向下的方向,而接收过程则对称地自底向上进行。路由器本质上也是一类具备数据收发能力的网络设备,因此同样可以借助 TCP/IP 模型进行分析。不过,路由器并不具备完整的五层结构,而仅包含下三层------即 网络层 、 数据链路层 和 物理层 。
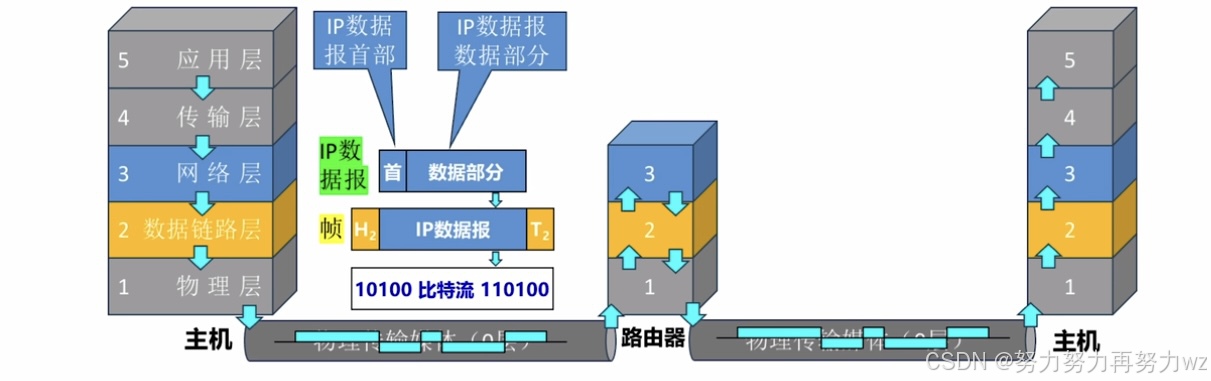
路由器 之所以仅工作在下三层,而不包含应用层和传输层,原因在于其作为中转设备的角色定位。我们可以借助快递分拣中心的比喻来理解:分拣中心只关心包裹需要发往哪个城市,而不关心其具体内容是一封信还是一件玩具。同样,路由器主要负责数据的路由转发,不涉及数据内容本身,因此自然不涉及应用层。
进一步来说, 路由器 也不包含 传输层 功能,因为传输层主要服务于通信的 端点 (发送方和接收方)。举个例子:当我们收到快递时,若发现物品在运输过程中损坏,我们可以选择签收或要求寄件人重新发货。这一决策应由收件人或寄件人做出,而与中间的运输节点无关。 中转站 仅负责物流传递,尽管过程中可能出现损坏,但责任并不在中转站,而通常由寄件方承担。对应到网络传输,传输层的一项重要功能是提供可靠性保障,例如在数据损坏时,接收方可请求发送方重传。路由器则是一个"纯粹"的传输工具,不检查数据是否损坏,也不参与差错恢复,其核心任务是将数据正确 路由 到目标地址。因此, 路由器 仅需工作于 TCP/IP 模型的下三层。
既然路由器负责数据转发,理解其工作原理就必须掌握一个关键概念: IP 地址与MAC地址。只有具备这两个前置知识,才能深入理解路由器的工作机制。
首先介绍 IP 地址。我们可以将 IP 地址定义为设备的标识符。理解 IP 地址时,可将其类比为现实中的地址。例如,若要从成都寄送快递到新疆,在发出快递前必须填写收件人的具体地址,如"新疆省乌鲁木齐市天山区幸福街"。这个地址的作用就类似于 IP 地址,用于标识网络中唯一的通信设备。
由于网络中存在大量设备,为确保数据准确发送至设备A而非设备B或设备C,必须为每个设备分配唯一的标识符,即 IP 地址。因此,理论上每个设备的 IP 地址在全球范围内是唯一的。正如收件人的地理位置具有唯一性------全世界不会存在两个完全相同的地理地址------ IP 地址的唯一性保证了数据能够准确送达目标设备,而不会误传至其他设备。
目前最常见且广泛使用的 IP 地址是32位的IPV4 地址。由于采用32位二进制序列, IPV4 最多可表示约42亿个地址。在互联网尚未普及的20世纪90年代,仅有军方、政府等少数机构接入网络,因此当时的设计思路是为每个设备分配一个唯一的IPV4 地址。然而,随着互联网技术的迅速发展和广泛普及,我国网民规模已达11亿,且每人可能拥有多个联网设备,显然IPV4 地址已无法满足全球设备的接入需求。为此,引入了子网划分 技术。
上文提到,我们可以通过集线器或交换机连接多个设备,使它们能够在局域网内相互通信。由集线器或交换机连接的设备集合称为局域网。然而,局域网内的设备不仅需要内部通信,还需与其他局域网的设备进行通信。这就好比每个地区(局域网)不能封闭自守,而需与其他地区保持联系。路由器的作用正是连接这些局域网------通常通过连接交换机实现,同时路由器之间也可以相互连接。
一旦交换机连接到路由器,该局域网便接入更广泛的网络,不再是信息孤岛,能够与全球其他局域网进行通信。这些局域网通过路由器互联,形成更大的网络,即我们所说的互联网 。
我们知道,由于 IP 地址本身无法为每个设备分配一个全局唯一的标识,因此引入了子网划分技术。在早期的子网划分方案中, IP 地址被划分为 A类 、 B类 和 C类 。 IP 地址本质上是一个 32 位的二进制序列,该序列由两部分组成:网络号和主机号。以地址类比为例,假设"乌鲁木齐市天山区幸福街"是一个完整的地址,那么"乌鲁木齐市"可视为网络号,"天山区幸福街"则对应主机号。整个地址"乌鲁木齐市天山区幸福街"就相当于一个 IP 地址。在同一个城市(如乌鲁木齐市)内的所有收件人,其地址前缀(即"新疆省乌鲁木齐市")是相同的,区别仅在于具体的区和街道。类似地,由交换机连接的多个设备构成一个局域网,这个局域网就可以比作"乌鲁木齐市"。因此,位于同一局域网的设备具有相同的网络号,即网络前缀一致,这标志着它们属于同一个网络。为了确保每个设备的 IP 地址全局唯一,我们还需要使同一局域网内各设备的主机号互不相同。
在 A、B、C 三类地址中,32 位二进制数的最高几位被用作类别标识:A 类地址的最高位固定为 0,B 类地址的最高两位为 10,C 类地址的最高三位为 110。对应地,A 类地址的第一个字节范围为 1 到 126,B 类为 128 到 191,C 类为 192 到 223。
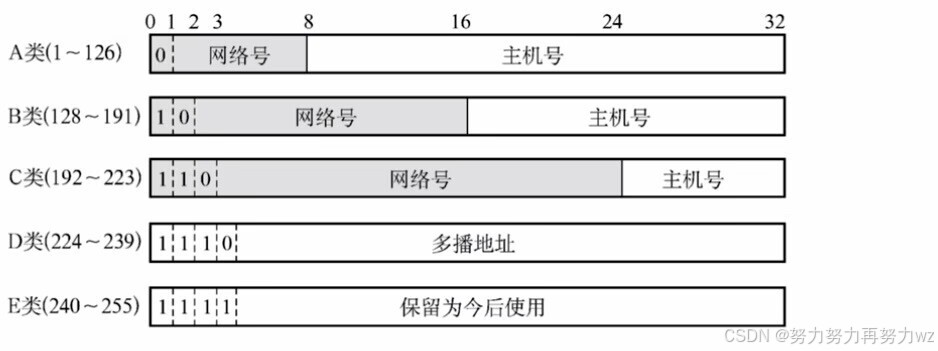
从结构上看,A 类地址的网络位占 8 位,主机位占 24 位;B 类地址的网络位为 16 位,主机位为 16 位;C 类地址的网络位为 24 位,主机位为 8 位。主机位的长度决定了一个网络内可容纳的最大主机数量,其计算公式为
2 主机位数 − 2 2^{\\{主机位数}} - 2 2主机位数−2
减去 2 的原因是:主机位全为 0 的地址用于标识网络本身,不可用作设备地址;而主机位全为 1 的地址为广播地址,用于向该网络中的所有设备发送数据,同样不能分配给具体设备。
据此,A类地址 最多可容纳约 1677 万个地址,B类地址 约为 6.5 万个,C类地址 则为 254 个。因此,A类地址 通常分配给超大型企业或组织,B类地址 适用于高校或研究机构,而C类地址 则主要用于小型公司。
由于 A 类和 B 类地址可容纳的设备数量极大,为便于管理,常会进一步进行子网划分,即将一个大的网络划分为多个较小子网。划分子网后,原本由"网络号 + 主机号"构成的 32 位 IP 地址,变为"网络号 + 子网号 + 主机号"的结构,其中子网号是从原主机位中划分出来的。以下通过一个例子帮助理解子网划分的过程。
假设我们申请了一个 A 类地址,并希望将其划分为 4 个子网。每个子网需有唯一的子网标识。由于 2^2 = 4 ,因此我们需要 2 位作为子网号。A 类地址原有 24 位主机位,现在将前 2 位用作子网号,剩余 22 位仍作为主机位。这 4 个子网分别对应子网号 00、01、10 和 11。通过这样的方式,我们便实现了对原始网络的子网划分。
cpp
[8位网络号] + [2位子网号] + [22位主机号] 例:
cpp
子网0: 10.0.0.0 (子网号 00 )
子网1: 10.64.0.0 (子网号 01 )
子网2: 10.128.0.0 (子网号 10 )
子网3: 10.192.0.0 (子网号 11 )然而,该技术存在一个显著的缺陷,即会造成 IP 地址的浪费。举例来说,若申请一个 A 类地址网段(如 10.0.0.0/8),则实际获得从 10.0.0.1 到 10.255.255.254 的地址范围,共计约 1677 万个 IP 地址。同样地,若申请一个 B 类地址网段(如 172.16.0.0/16),则拥有从 172.16.0.1 到 172.16.255.254 的地址,约 6.5 万个。假设一个组织仅有 100 台主机,却申请了一个 A 类地址,将导致大量地址未被使用;同理,若仅有 500 台主机的组织申请一个 B 类地址,也会造成地址浪费。这种浪费的核心原因在于,A 类、B 类地址中网络号和主机号的位数是固定的,无法根据实际需求灵活调整。为此,引入了 无类别域间路由 ( CIDR )机制。
在 CIDR 机制中,不再有传统的 A、B、C 类地址的严格划分,网络号和主机号的位数也不再固定。为了在分配 IP 地址时准确标识网络部分和主机部分,需要引入" 子网掩码 "这一概念。
子网掩码由一连串连续的 " 1 " 和 " 0 " 组成,其中 "1" 对应 网路号 部分,"0" 对应 主机号 部分。通过将 IP 地址与子网掩码进行"与"运算,即可确定其所属的网络地址。若已获得一个地址段,可以进一步将其划分为多个子网,划分方式如下:首先确定所需子网数量 n,接着确定满足 2^m ≥ n 的最小整数值 m,该 m 即为子网号的位数。此时,将原主机号的高 m 位用作子网号,剩余位仍为主机号。
为了使读者更好地理解子网划分,这里我们通过一个具体示例进行讲解:
假设你是一家公司的网络管理员,公司获得了一个 IP 地址块 192.168.1.0/24 。现在需要为以下四个部门划分子网,每个部门所需的主机数量如下:
- 技术部:需要支持 60 台主机
- 市场部:需要支持 30 台主机
- 财务部:需要支持 20 台主机
- 行政部:需要支持 10 台主机
我们拥有一个地址块 192.168.1.0/24 ,需要划分出四个子网。通常,为了使地址分配更加高效,我们会按照每个子网所需主机数从大到小的顺序依次进行划分。因此,我们首先为技术部(60 台主机)划分子网,接着是市场部、财务部,最后是行政部。
- 技术部子网划分
首先计算技术部所需的主机数量。一个子网中可用的主机数计算公式为:
可用主机数 = 2 主机位数 − 2 可用主机数 =2^{主机位数} - 2 可用主机数=2主机位数−2
技术部需要 60 台主机,因此:
2 6 − 2 = 62 > = 60 2^6 - 2 = 62 >= 60 26−2=62>=60
由此可知,主机位至少需要 6 位。
IPv4 地址总长度为 32 位,分为网络位和主机位。若主机位为 6,则网络位为:
32 - 6 = 26
因此,技术部的网络前缀长度为 /26。
接下来确定该子网的 IP 地址范围。在 192.168.1.0/24 地址块中,第一个可用的 /26 子网是 192.168.1.0/26 。其网络地址为 192.168.1.0 ,广播地址为 192.168.1.63 (主机位全 1)。可分配的主机地址范围是 192.168.1.1 至 192.168.1.62 。
因此,技术部使用的地址范围为:
192.168.1.1/26 -- 192.168.1.62/26 ,子网掩码为 255.255.255.192 。
- 市场部子网划分
接下来为市场部(需 30 台主机)划分子网。同样根据公式:
2^5 - 2 = 30
满足需求,因此主机位为 5 位,网络前缀长度为 /27。
下一个可用的子网起始地址,为上一个子网(192.168.1.0/26)的广播地址加 1,即 192.168.1.64。因此,市场部的子网为 192.168.1.64/27 。其网络地址为 192.168.1.64 ,广播地址为 192.168.1.95 ,可用地址范围为 192.168.1.65 至 192.168.1.94 。
因此,市场部可使用的地址范围为:
192.168.1.65/27 -- 192.168.1.94/27 ,子网掩码为 255.255.255.224 。
之后,可以重复上述步骤,继续为财务部和行政部划分相应的子网。
在变长子网划分( VLSM)中,我们采用无类域间路由( CIDR)的思想,其核心是"网络前缀 + 主机位"的划分方式,而不再像传统有类网络那样固定使用A、B、C类及对应的标准子网掩码。在VLSM方案中,我们关注的是 网络前缀的长度(如 /26、/27),并根据实际需要的主机位数来确定子网大小,从而更灵活、高效地利用IP地址空间。
那么,我们已经了解了 IP 地址的基本含义:它是用于唯一标识接入网络的设备的。我们可以将 IP 地址类比为现实中的地址,例如"新疆维吾尔自治区乌鲁木齐市天山区幸福街"。不同的是,IP 地址是一个 32 位的二进制数,通常划分为网络前缀和主机号两部分。网络前缀用于标识设备所属的局域网,而主机号则用于区分该局域网中的具体设备。
除了 IP 地址,前文还提到了 MAC 地址。那么,MAC 地址究竟是什么?它与 IP 地址之间又存在哪些区别?
首先,我们为 MAC 地址下一个定义:它也是用于唯一标识一台主机的标识符。既然 IP 地址已经能够唯一标识一台主机,为什么还需要 MAC 地址?这是否显得冗余?
实际上, MAC 地址的存在并非冗余,而是具有其不可替代的作用。我们可以通过一个比喻来帮助理解:IP 地址好比一个人的家庭住址,而 MAC 地址则相当于其身份证号码。家庭住址是可以变更的------例如,今年你住在四川省成都市金牛区,明年若搬至天府新区,住址就发生了变化。但无论住址如何变化,你的身份证号码是固定且唯一的,不会随住址的改变而改变。
同理,对于网络设备而言,当它接入不同的局域网时,其 IP 地址会发生变化,因为不同局域网通常具有不同的网段。然而,该设备的 MAC 地址是固定不变的,并且在全局范围内唯一。所谓"全局唯一",是指每个设备在全球严格拥有一个不重复的 MAC 地址。而 IP 地址则可能重复使用,其原因与后文将介绍的 NAT 技术有关,涉及公网 IP 和私有 IP 的概念(私有 IP 允许重复)。
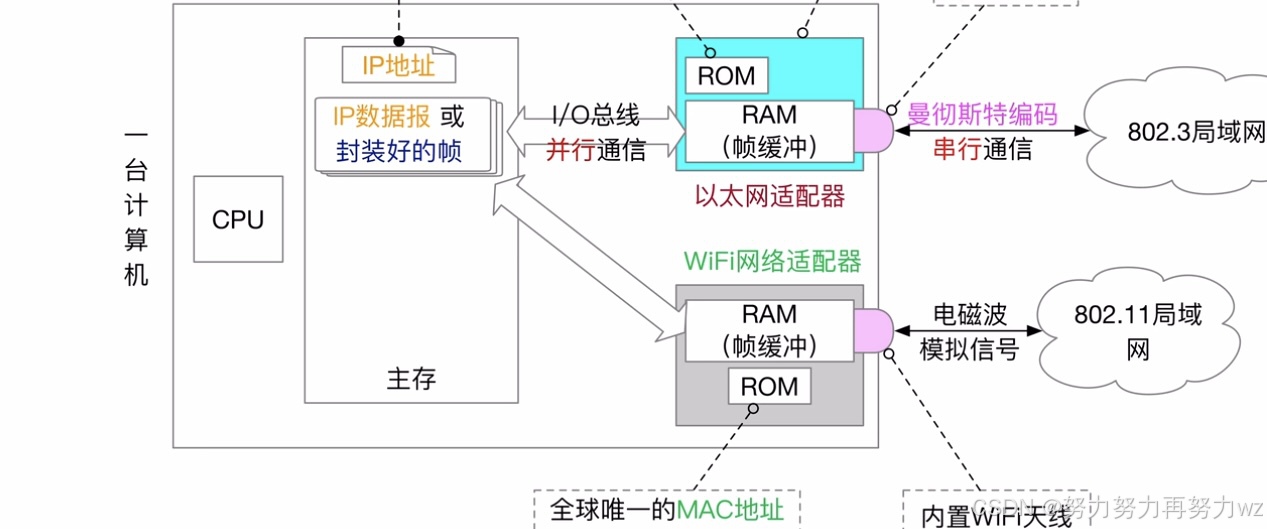
从结构上看,IP 地址是 32 位的二进制序列,而 MAC 地址则为 48 位。每个网卡在出厂时即被赋予一个唯一的 48 位 MAC 地址。其中前 24 位为厂商识别码(OUI),任何生产网卡的厂商都必须向 IEEE(电气和电子工程师学会)申请并购买一个固定的识别码;后 24 位则由厂商自行分配给自己所生产的网卡。
网卡内部结构上包含 ROM 芯片(只读存储器)和 RAM 芯片(随机存储器) 两部分。 RAM 作为缓冲区,分为输入缓冲区和输出缓冲区:待发送至传输介质的数据暂存于输出缓冲区,而接收自其他设备的数据则存于输入缓冲区。 RAM 通过总线从内存中获取经过应用层、传输层和网络层处理的数据,存入输出缓冲区,最终转换为物理信号发送至传输介质。 ROM 中存储的即是该网卡的 48 位 MAC 地址。
了解了 IP 地址与 MAC 地址的基本概念后,我们可以进一步明确数据在网络中传输的整体框架。数据最初由进程产生,交由传输层处理。操作系统负责传输层与网络层的封装:内核在收到来自应用层的数据后,并不关心数据内容本身,而是在其头部添加传输层协议头。假设原始数据长度为 m 字节,添加的协议头为 k 字节,则此时形成 m+k 字节的 报文段 (Segment)。关于协议头具体内容,后续将详细展开。
传输层处理完成后,数据被递交至网络层。网络层继续在已有报文段头部添加网络层协议头。该协议头中包含关键信息,如源 IP 地址与目标 IP 地址(这仅是网络层协议的部分内容)。假设网络层头部长为 n 字节,则最终形成总长为 m+k+n 字节的 IP数据包 (IP Packet)。网络层协议中除 IP 地址外的其他字段,也将在后文详细说明。
网络层的主要功能是进行 路由选择 ,即决定将数据包转发至哪个 下一跳设备 。为实现这一功能,网络层维护一个 路由表 。路由表 的每个条目通常包含以下几项:目标IP地址 、子网掩码 、接口名称 (或编号)以及下一跳地址 。
在网络层封装目标 IP 地址后,还需查询路由表以确定数据包的转发路径。查询过程中,利用子网掩码对目标 IP 地址进行按位与运算,提取网络号。系统会选择与目标网络号完全匹配的路由条目。如果发现存在多个完全匹配的路由表条目,则匹配网络前缀最长的
例:
cpp
目标网络 子网掩码 下一跳 接口
127.0.0.0 255.0.0.0 0.0.0.0 lo
192.168.1.0 255.255.255.0 0.0.0.0 eth0
192.168.2.0 255.255.255.0 192.168.1.1 eth0
10.0.0.0 255.0.0.0 192.168.1.254 eth0
0.0.0.0 0.0.0.0 192.168.1.1 eth0
假设现有一个目标 IP 地址为 192.168.2.10 的数据包需要进行路由选择。路由器将按照路由表的条目顺序,依次将目标 IP 地址与各条目的子网掩码进行按位与运算,计算出对应的网络前缀,再与路由条目中的目标网络进行匹配。
- 首先匹配第一条:
198.168.2.10 & 255.0.0.0 = 198.0.0.0,结果为192.0.0.0,与目标网络
127.0.0.0不匹配。 - 接着匹配第二条:
198.168.2.10 & 255.255.255.0 = 198.168.2.0,结果为198.168.2.0,与目标网络192.168.1.0不匹配。 - 然后匹配第三条:
198.168.2.10 & 255.255.255.0 = 198.168.2.0,结果为198.168.2.0,与目标网络192.168.2.0仍不匹配。注:尽管网络部分格式相似,但198.168.2.0与192.168.2.0
属于不同网络地址,因此不匹配。 - 继续匹配第四条:
198.168.2.10 & 255.0.0.0 = 198.0.0.0,结果为198.0.0.0,与目标网络
10.0.0.0不匹配。 - 最后匹配第五条(默认路由):
198.168.2.10 & 0.0.0.0 = 0.0.0.0,结果为0.0.0.0,与目标网络0.0.0.0匹配成功。
因此,该数据包将通过默认路由发出,从接口 eth0 转发至下一跳地址 192.168.1.1 。
一台设备可以配备多个网卡(网络接口),数据可以从不同的网络接口发出。在 Linux 操作系统中,每个网络接口通常对应一个设备名称(例如 eth0),每个接口也需要由操作系统进行管理。内核采用"先描述,再组织"的方式来管理这些接口,即为每个网络接口维护一个对应的结构体,其中记录该接口的详细属性(包括名称等)。在 Linux 中,这个结构体是 struct net_device ,并通过哈希表或链表等数据结构进行组织。
借助这些接口信息,内核能够确定将数据通过系统总线写入哪个网卡的缓冲区
cpp
// include/linux/netdevice.h
struct net_device {
char name[IFNAMSIZ]; // 接口名: "eth0", "wlan0"
unsigned char *dev_addr; // MAC地址
unsigned char perm_addr[MAX_ADDR_LEN]; // 永久MAC地址
unsigned char addr_assign_type; // MAC地址分配类型
unsigned char addr_len; // 地址长度
int ifindex; // 接口索引
unsigned int flags; // 接口标志
unsigned int mtu; // 最大传输单元
// ...
// IP相关配置
struct in_device __rcu *ip_ptr; // IPv4配置
struct inet6_dev __rcu *ip6_ptr; // IPv6配置
// 链表
struct list_head dev_list; // 全局设备链表节点
struct hlist_node name_hlist; // 名称哈希链表
struct hlist_node index_hlist; // 索引哈希链表
// 接口操作
const struct net_device_ops *netdev_ops; // 操作函数
// ...
};至于上文提到的 lo 接口,它并非特指某个具体的物理网卡设备,而是代表一个环回网络(loopback network)。在环回网络中,数据并不会实际发送到外部网络,而是直接在本机内部传递,其目标进程也位于同一设备上。因此,当操作系统识别到数据包的出口是lo 接口时,不会将其写入网卡的发送缓冲区,数据也不会经过数据链路层和物理层,而是直接递交给目标进程。该数据包会从网络层返回到传输层依次解封装,相当于在网络层和传输层之间形成环回。
环回地址所使用的网段也有特定规范,主要集中在 127.0.0.0/8 这一 A 类地址段,即环回 IP 地址的范围为 127.0.0.0 到 127.255.255.255 。只要一个 IP 地址处于该范围内,即可认定为环回地址。
局域网通常由一台交换机及与其连接的多个设备构成。交换机的每个端口连接一个设备。在有线网络(如以太网)中,设备通过双绞线连接到交换机的某一端口。数据从网卡发出后,经双绞线传输至交换机。与集线器(Hub)的广播方式不同,交换机能够进行精准的点对点转发,将数据帧仅发送至目标设备所连接的端口,因此交换机具备数据接收与转发的能力。任何能够接收和发送网络数据的设备,均可用 TCP/IP 模型进行描述。
交换机工作在 TCP/IP 模型的下两层,即物理层与数据链路层。在此背景下,MAC 地址的作用便凸显出来。如前所述,传输层和网络层会依次为数据封装各自的协议头部,这些操作由操作系统内核实现。数据链路层则会在上层封装的 IP 数据报基础上添加帧头与帧尾。帧头中包含源MAC地址、目标MAC地址和类型字段,其中类型字段用于指示网络层所使用的协议(如 IPv4 或 IPv6)。帧尾则包含校验码,用于检测数据传输过程中是否出错。若校验失败,数据链路层会直接丢弃该帧,并由发送方的传输层负责重传。

有读者可能会疑惑:这里数据链路层封装的帧头包含一个Type类型字段,其值表示着上层使用的协议,也就是网络层使用的协议,既然 TCP/IP 模型强调各层之间的低耦合,为何数据链路层会知晓上层协议的类型?实际上,尽管很多人认为帧的封装由网卡完成,即操作系统将 IP 数据报写入网卡的发送缓冲区后由网卡添加帧头帧尾,但实际在数据写入网卡之前,帧头的封装工作已由操作系统内核在系统的 内存中完成,然后写入到网卡的缓冲区,网卡只是负责发送。源 MAC 地址可直接从网卡的 ROM 中读取,而目标 MAC 地址则对应下一跳设备的 MAC 地址,该映射关系通过 ARP表获取。 ARP表 记录了 IP 地址与 MAC 地址的对应关系。若表中无下一跳 IP 的 MAC 记录,主机会广播一个 ARP请求帧 ,并将其目标 MAC 地址设置为特殊的广播地址:FF:FF:FF:FF:FF:FF ,类型字段标记为 ARP(0x0806),询问"IP 地址为 x.x.x.x 的设备,请回复你的 MAC 地址"。Apr请求帧会发送到交换机中,而接下来就会涉及交换机的工作原理:
每个设备通过网线连接到交换机的特定端口,端口具有唯一编号。交换机内部维护一张 MAC 地址表,记录端口与所连接设备 MAC 地址的映射关系。需要注意的是,该表初始为空,不像路由表那样预设子网信息,而是通过自学习机制动态构建。
自学习机制的过程如下:当数据帧从某一端口进入交换机时,交换机会识别帧头中的源 MAC 地址,并将该地址与端口的对应关系记录到 MAC 地址表中。随后,交换机检查目标 MAC 地址:若表中存在对应条目,则将帧转发至相应端口;若不存在,则向所有端口广播该帧(除接收端口外)。非目标设备在收到帧后会检查目标 MAC 地址,若非自身地址则丢弃。通过持续记录各端口发出的单播或多播或者 ARP请求 等帧的源 MAC 地址,交换机逐步建立完整的 MAC地址表 。
MAC地址表示例:
cpp
MAC地址 端口 老化计时器(秒)
AA:BB:CC:11:22:33 1 120
DD:EE:FF:44:55:66 3 30
11:22:33:AA:BB:CC 5 200
... ... ...交换机:

需要注意的是,MAC地址表中的条目具有时效性。因设备可能随时断开或重新连接,端口所关联的 MAC 地址会动态变化。每个条目在创建时被赋予一个时间戳,超时后自动清除。若在有效期内同一端口接入新设备,并发送源 MAC 不同的帧,交换机将更新该端口对应的 MAC 地址。这种机制体现了交换机的动态学习能力,也是自学习设计的必要性所在。
需要注意的是,ARP表中的每个条目都具有
时效性。由于设备可能接入不同的局域网,先前记录的IP地址与MAC地址的映射关系会因此失效。为此,每个ARP表条目都设有一个状态标记(如REACHABLE、STALE、DELAY、PROBE、FAILED),并在超时后自动清理相应条目。以下为Linux内核中ARP表条目的数据结构示例及其状态定义:
cppstruct neighbour { struct neighbour __rcu *next; // 哈希表链表 struct net_device *dev; // 网络接口 u8 primary_key[0]; // IP地址 u8 ha[ALIGN(MAX_ADDR_LEN, sizeof(unsigned long))]; // MAC地址 u8 nud_state; // 状态标记 unsigned long updated; // 最后更新时间戳 unsigned long used; // 最后使用时间戳 unsigned long confirmed; // 最后确认时间戳 struct rcu_head rcu; struct neigh_ops *ops; // 操作函数 // ... }; // ARP条目的状态定义 enum { NUD_NONE = 0x00, // 初始状态,无任何信息 NUD_INCOMPLETE = 0x01, // 正在解析,已发送ARP请求但未收到响应 NUD_REACHABLE = 0x02, // 可达,条目有效且新鲜 NUD_STALE = 0x04, // 陈旧,可能失效,下次使用时需验证 NUD_DELAY = 0x08, // 延迟验证,等待使用 NUD_PROBE = 0x10, // 正在验证,已发送ARP请求 NUD_FAILED = 0x20, // 解析失败 // ... };这些状态反映了条目在地址解析与维护过程中所处的不同阶段,并驱动相应的超时与更新机制。
与 集线器 (Hub)相比,集线器下所有设备处于半双工模式,因其内部为共享总线结构。而交换机在物理层面为每个连接提供独立并发通道,支持全双工通信。尽管交换机避免了数据冲突,但仍可能出现阻塞情况:当多个设备同时向同一端口发送数据时,后到的帧将进入端口队列等待;若队列满,后续帧将被丢弃。
想必读者对"以太网"这一专业术语已有耳闻。所谓以太网,指的是基于双绞线等有线介质,并通过交换机等通信设备连接所构成的局域网。其核心不仅在于使用有线介质与相关设备,更在于它规范了数据在局域网中的寻址方式------即通过上文提到的MAC地址进行寻址,同时也规定了数据帧的格式。因此,以太网本质上是一个数据链路层协议,它明确了传输介质、寻址机制、帧格式以及访问控制方法,例如之前提到的CSMA/CD协议,就是用于解决数据传输冲突的典型机制。
相比之下,无线局域网在寻址与主机定位方面与以太网有所不同。因此,无线局域网必然具备自身的数据链路层协议,其中包含适用于无线环境的数据帧格式、访问控制机制以及相应的传输介质规范。
那么,数据从一个设备传输到另一个设备的整体流程已较为清晰。如前文所述,网络层的功能是负责路由选择,即根据IP地址确定数据应转发至哪一个下一跳设备。对于主机而言,操作系统负责实现网络层功能,并在内部维护一张简化的 路由表 。该路由表通常仅包含少数条目,主要包括环回网络与直连网络以及默认网关。所谓直连网络,即指该设备所属的子网。其中默认网关的IP地址一般设置为 0.0.0.0 ,子网掩码也为 0.0.0.0 。
那么读者可能会产生一个疑问:网络层的核心功能是路由,这需要查询
路由表。对于主机设备而言,其路由表通常较为简单,一般只包含三个条目:环回网络、直连网络以及默认网关。这里可能存在一种场景,即目标 IP 地址正是本机 IP 地址,这种情况下通信是正常的------数据实际上是发送给同一台设备上的不同进程。但问题的关键在于,如果目标 IP 地址位于直连网络中,我们知道这个数据包显然不应被写入网卡并向外发送,而它在
路由表中又确实会匹配到"直连网络"这一条目。那么系统究竟是如何避免将其发送到网络接口的呢?这就需要进一步细化路由的具体流程。当数据包到达网络层后,在进行
路由表匹配之前,系统会先执行一项检查:判断目标 IP 地址是否等于本机的某个 IP 地址。如果相等,则不会继续匹配路由表,而是直接交由本地协议栈处理,类似于环回网络的处理方式。前文提到,网络接口是一种设备,操作系统需要管理这些设备。管理的方式通常是"先描述,再组织"------即为每个网络设备定义一个
struct net_device结构体,记录其名称、MAC 地址等详细属性,并通过哈希表或链表进行组织。因此,一旦路由表匹配成功,系统便可获取对应的接口名称,进而定位到相应的struct net_device结构体,从而得到该网络接口的 MAC 地址,完成数据帧封装,最终写入网卡缓冲区。
cpp// 数据结构关系: struct net_device { char name[16]; // 接口名称,如 "eth0", "wlan0" unsigned char *dev_addr; // MAC 地址 struct in_device *ip_ptr; // 指向 IP 配置结构 // ... }; struct in_device { struct net_device *dev; // 指向所属网络设备 struct in_ifaddr *ifa_list; // 指向 IP 地址链表的头节点 // ... }; struct in_ifaddr { struct in_ifaddr *ifa_next; // 链表中的下一个节点 __be32 ifa_address; // IP 地址 __be32 ifa_mask; // 子网掩码 __be32 ifa_broadcast; // 广播地址 // ... };在
struct net_device中,ip_ptr字段指向一个管理 IP 配置的链表。链表的每个节点是一个struct in_ifaddr结构体,记录了该网络接口对应的 IP 地址、子网掩码和广播地址等信息。这意味着一个网络接口可以拥有多个 IP 地址。因此,在进行
路由表匹配之前,内核会遍历所有网络接口关联的 IP 地址链表,检查目标 IP 地址是否与其中任一地址相等。如果相等,则不进行路由表匹配,直接由本地处理;否则,继续进行路由表匹配,并根据结果决定是否从网卡发出。
cppnet_device ("eth0") | |-- ip_ptr (struct in_device* 类型, 指向 IP 配置容器) | | v | struct in_device | | | |-- ifa_list (struct in_ifaddr* 类型, 指向 IP 地址链表头) | | v 第一个 struct in_ifaddr 节点 | | |-- IP: 192.168.1.100/24 #"eth0"的第一个IP | | |-- ifa_next (指向下一个节点) | | | | | v | | 第二个 struct in_ifaddr 节点 #"eth0"的第二个IP | | |-- IP: 192.168.1.101/24 | | |-- ifa_next (假设为 NULL,链表结束) | | ` | net_device("eth1") | | ----ip_ptr ........... [关系总结] 1. 一个 net_device (如 eth0) 包含一个 ip_ptr。 2. ip_ptr 指向一个 in_device 结构,该结构管理此设备的所有 IP 层配置。 3. in_device 中的 ifa_list 指针,指向一个 in_ifaddr 结构体链表。 4. 链表中的每个 in_ifaddr 节点存储一个具体的 IP 地址配置(如地址/掩码)。 5. 节点的 ifa_next 指针将各个 IP 地址配置连接成链表。图中示例有两个 IP。在实际使用中,我们可以为同一网络接口配置多个 IP 地址,例如在 Linux 中:
cpp# 为 eth0 配置多个 IP 地址 $ sudo ip addr add 192.168.1.100/24 dev eth0 $ sudo ip addr add 192.168.1.101/24 dev eth0 label eth0:0 $ sudo ip addr add 10.0.0.100/24 dev eth0 label eth0:1此时内核中的数据结构组织大致如下:
cppstruct in_device (eth0) | |--> ifa_list | | | v | struct in_ifaddr | | | |--> ifa_address: 192.168.1.100/24 | |--> ifa_label: "eth0" | |--> ifa_next: --> (指向下一个 in_ifaddr) | | | v | struct in_ifaddr | | | |--> ifa_address: 192.168.1.101/24 | |--> ifa_label: "eth0" | |--> ifa_next: --> (指向下一个 in_ifaddr) | | | v | struct in_ifaddr | | | |--> ifa_address: 127.0.0.1/100 | |--> ifa_label: "eth0:1" | |--> ifa_next: NULL | |--> (in_device 其它成员...)通过这种方式,系统能够在路由之前就识别出目标地址为本机地址的数据包,并直接将其交给上层协议栈处理,从而避免不必要的网络发送操作。
当数据到达网络层,并在其头部封装网络层协议后,下一步即确定应转发至哪一个设备。此时需查询 路由表 。若目标IP与直连网络 匹配 ,则接下来需要获取该目标IP对应的 MAC地址 ,即查询 ARP表 。若表中存在对应条目,则直接封装帧头与帧尾,随后通过网卡发送至交换机。交换机会查询其 MAC地址表 ,若找到对应条目,则将数据帧从相应端口转发出去;若未找到,则向除接收端口外的所有其他端口 广播 该帧。
如果 ARP表 中没有对应条目,主机会发送一个 ARP请求帧 ,广播至同一子网内(除发送端口外)的所有设备。目标设备收到该请求后会回复ARP响应,从而使源主机获得目标IP对应的MAC地址,并更新本地的ARP表。随后,主机将数据封装 帧头 与 帧尾 ,交由 交换机 转发至目标设备。整个过程不涉及路由器。
cpp
[主机A]------->[交换机]--------->[主机B]
同一子网通信拓扑结构主机路由表示例:
cpp
目标网络 子网掩码 网关 接口
127.0.0.0 255.0.0.0 0.0.0.0 lo (环回)
192.168.1.0 255.255.255.0 0.0.0.0 eth0 (直连)
0.0.0.0 0.0.0.0 192.168.1.1 eth0 (默认网关)如果通信设备位于不同子网,则目标IP不会匹配直连网络的路由表条目,数据将被发往默认网关 ,即路由器 。交换机的一个端口通常会与路由器的某个端口相连,而路由器具有多个端口,可分别连接不同交换机或其他路由器。每个路由器端口均具备独立的MAC地址。
此时,源主机首先查询ARP表 ,确认是否已存有默认网关的MAC地址。若不存在,则向路由器发送ARP请求,路由器回应其端口的MAC地址。随后,主机将该MAC地址作为目标MAC封装到帧头中。
若ARP表 中已有默认网关的MAC地址,则主机直接将封装好的数据帧发送至交换机。交换机根据MAC地址表,从对应端口将数据转发至路由器的端口。
路由器内部维护的路由表通常比主机路由表复杂得多,其中记录了多个子网的网段、子网掩码及对应的转发接口。路由器接收到数据帧后,首先在物理层将信号转换为数字数据,随后上传至数据链路层。该层检查帧的校验码,若检测到差错则丢弃该帧;若无误,则剥离帧头与帧尾,将数据上交至网络层。
在网络层,路由器提取目标IP地址,并与路由表 进行匹配,以决定应从哪个端口转发。此时,路由器需确定下一跳设备的MAC地址,因为原始数据帧的目标MAC地址仅为路由器自身端口的地址。路由器重复类似主机的地址解析过程:查询ARP表,若没有对应下一跳IP的MAC地址,则发送ARP广播请求。
cpp
[主机A]---------->[交换机1]------------>[路由器]---------->[交换机2]--------->[主机B]
子网1 子网2
不同子网通信拓扑结构路由器路由表示例:
cpp
目标网络 子网掩码 网关 接口
192.168.1.0 255.255.255.0 0.0.0.0 eth0
10.0.0.0 255.255.255.0 0.0.0.0 eth1
172.16.0.0 255.255.0.0 10.0.0.254 eth1
0.0.0.0 0.0.0.0 203.0.113.1 eth2而当路由器发现目标IP地址不在任何直连子网网段内,而属于其他局域网时,下一跳设备就是路由器。此时数据帧将被转发给路由器,并由路由器获取下一跳设备的MAC地址,获取方式与之前所述一致。
cpp
[主机A]------------>[交换机]----------->[路由器A]--------------->[路由器B]------->[.....]
不同局域网通信的拓扑结构⭐补充1:DHCP(动态主机配置协议,其是应用层协议)
我们知道,主机可以接入不同的局域网。当一台主机新接入一个局域网时,它并不知道自己的
IP地址IP以及默认网关。由于无法获知这些信息,主机也就无法构建路由表。因此,它需要先获取自己的 IP 地址和默认网关。采取的措施是发送DHCP数据包,该数据包封装在UDP报文中(UDP是什么会在后文详细讲解,其是一个传输层协议),其类型标识为DHCP协议。在初始请求阶段,源 IP 地址为0.0.0.0,目标 IP 地址为255.255.255.255,即广播地址。这样,网络中的DHCP服务器都会收到这个广播帧。DHCP数据包的内容相当于主机声明:"我不知道自己的 IP 地址,请为我分配一个,并告知我子网掩码、默认网关以及你的IP地址。"DHCP 服务器收到请求后,会从地址池中选择一个可用的 IP 地址,将其与子网掩码、默认网关及服务器自身的 IP 地址一并封装在DHCP Offer报文中,发送回主机。主机收到服务器提供的配置信息后,会发送一个
确认报文,表明其确认使用这个 IP 地址。DHCP 服务器收到此确认后,会正式将该 IP 地址标记为已分配,并在一定时间内不会分配给其他主机。这个 IP 地址具有时效性,称为"租期"。一旦租期即将到期,主机需要向 DHCP 服务器发起续租请求,申请延长该 IP 地址的使用时间。因此,整个 DHCP 地址分配与确认的过程,通常被称为"
四次报文交换"(或"DHCP 交互四步骤")。其流程如下:首先,客户端广播DHCP Discover报文以寻找可用服务器;服务器回应DHCP Offer报文,提供一个可用的 IP 地址配置;客户端若接受该配置,则发送DHCP Request报文进行确认;最后,服务器回复DHCP Ack报文,正式确认地址分配,并启动租期计时。此时,客户端可以开始使用该 IP 地址。
cpp
四次握手示例:
时间轴: 客户端启动 ── Discover ── Offer ── Request ── Ack :开始使用
(客户端请求) (服务端提供)(客户端需要)(服务端确认)需要注意的是,
DHCP Discover报文是广播发送的,因此网络内可能存在多个DHCP服务器收到请求,并各自回复DHCP Offer。客户端通常会收到多个服务器提供的 IP 地址选项,一般会选择最先到达的 Offer,某些客户端实现也会根据租期长短进行选择。在客户端做出选择后,它会向选中的服务器发送 Request 报文,其他服务器则会因未收到确认而释放之前预分配的地址。校园网广泛采用
DHCP技术来实现接入设备的自动配置。每次我们连接校园网,本质上是向网络中的DHCP服务器发起地址请求。这也解释了为什么当主机进入待机或休眠一段时间后重新唤醒,可能会发现网络连接已断开------这是因为分配给主机的 IP 地址租期已到期,而待机期间主机无法主动续租。在正常使用过程中,主机会在租期到期前自动向服务器发起续租请求,以维持地址的有效性。DHCP服务通常集成在路由器或交换机中,由其内置的DHCP服务器功能提供。在家庭网络中,
DHCP服务一般由无线路由器提供。现代无线路由器是集路由器、交换机和无线接入点(AP)功能于一体的多功能设备。家庭中的设备连接无线路由器,相当于先连接到其内置的交换机端口,再由交换机与路由器模块进行内部通信。这种拓扑结构与上文所述的模型本质上一致。因此,无线路由器能够同时完成交换机在数据链路层的点对点转发,以及路由器在网络层的路由寻址工作。
⭐补充2:NAT(网络地址转化)我们知道,IPv4地址总数约为42亿,但当前接入网络的设备数量已远超该上限,因此产生了
NAT(Network Address Translation,网络地址转换)技术,其目的是提高IP地址的利用率。这便引入了公网IP地址与私有IP地址的概念。若某个局域网采用
NAT技术,则局域网内的设备会使用私有IP地址。私有IP地址被规定集中在以下三个网段:私有地址段:
cpp- 10.0.0.0/8: 10.0.0.0 -- 10.255.255.255 - 172.16.0.0/12: 172.16.0.0 -- 172.31.255.255 - 192.168.0.0/16: 192.168.0.0 -- 192.168.255.255在采用
NAT技术的网络中,主机内核会维护一张路由表,其中通常包含默认网关、直连网络及环回网络等条目。此处的直连网络一般配置为上述私有地址段。当设备需要与同一子网或不同子网内的其他设备通信时,会使用私有IP地址作为通信地址,从而实现在私有网络内部进行寻址与路由。如果通信目标位于不同局域网,设备发出的数据包会首先到达
默认网关(即路由器)。路由器收到数据包后,会先查询自身的路由表并进行匹配。若匹配到默认路由条目,则表示该数据包需转发至外部网络,此时将进行地址转换:路由器将数据包的源IP地址(私有IP)替换为公网IP地址,因为跨局域网的路由必须借助公网IP地址。转换完成后,数据包从路由器的WAN口发出。当路由器收到从公网返回的数据包时,同样先进行
路由表匹配。若匹配到指向其下某一局域网的条目,则说明目标设备位于该局域网内,路由器会将数据包中的目标IP地址(公网IP)转换回对应的私有IP地址,再转发给目标设备。但这里存在一个关键问题。在说明该问题之前,需先引入"
端口号"的概念。IP地址用于标识一台设备,而设备间的通信实质上是进程间的通信。设备收到数据包并经上层协议解封装后,需将其递交给某个特定进程。一台设备上可能运行多个进程,因此需要为每个进程分配一个唯一标识符,即端口号。因此,我们发送的数据包不仅包含源/目的IP地址、源/目的MAC地址,还包含源端口与目的端口。在采用NAT的局域网中,所有设备共享同一个公网IP地址。尽管各设备的私有IP不同,但其使用的端口号可能相同。如果NAT只进行IP地址转换,则可能出现多个内部连接映射到同一个"
公网IP:端口"对的情况。例如,私有IP地址为192.168.1.10的设备A上的端口为5000的进程向百度发起请求,同时私有IP地址为192.168.1.20的设备B上的端口也为5000的进程也向百度发起请求。若路由器仅修改IP地址,两者将映射为相同的公网IP与端口组合,比如61.135.169.125:5000。当百度返回数据包时,路由器将无法确定应将其转发给哪个内部设备。因此,
NAT设备会维护一张NAT 映射表,为每个"私有IP:端口"对分配一个唯一的公网端口号。在分配前,会先查询该"私有IP:端口"是否已有对应表项,如有则复用,否则新增一条映射。当路由器收到外部返回的数据包时,便查询该映射表,将目标IP与端口转换为对应的私有IP与端口。示例:
cpp实际转换过程: 设备A1(192.168.1.10:5000) → 路由器分配端口30001 → 61.135.169.125:30001 设备A2(192.168.1.20:5000) → 路由器分配端口30002 → 61.135.169.125:30002 路由器NAT映射表: | 内网IP:端口 | 公网IP:端口 | 目标服务器 | |------------|-------------|----------| | 192.168.1.10:5000 | 61.135.169.125:30001 | 8.8.8.8.80 | | 192.168.1.20:5000 | 61.135.169.125:30002 | 8.8.8.8.80 |
cpp设备发起请求 → 路由器收到 #内网到外网 ↓ 路由器检查NAT表 ↓ 如果新连接 → 分配新公网端口 ↓ 记录映射:[内网IP:端口] ⇄ [公网IP:新端口] ↓ 修改数据包源地址 ↓ 转发到外网 --------------------- 路由器收到外网回包 #外网到内网 ↓ 提取目标IP:端口(公网IP:端口) ↓ 查NAT表:公网端口 → 对应内网IP:端口 ↓ 修改数据包目标地址 ↓ 转发到对应内网设备因此,
NAT技术虽然提高了IP地址的利用率,但也带来了额外的开销,包括维护NAT映射表以及修改IP报文头部中的地址与端口信息。因此,部分局域网可能会选择不采用NAT技术。
至此,我们便能理解 MAC地址 与 IP地址 各自的作用:MAC地址 用于在相邻设备之间进行寻址,如同节点间的局部导航;而IP地址则像是一个方向标,指示数据的最终目的地。举个例子,假设有一个快递从成都发往乌鲁木齐,它会先到达成都市相邻的下一个节点。你可以将其想象为询问当地分拣中心:"我要去乌鲁木齐,下一站该怎么走?"分拣中心会询问你从哪里来、到哪里去,你回答"从成都金牛区来,到乌鲁木齐去"。分拣中心随后查看"地图"------即 路由表 ,告诉你:"接下来请前往都江堰。"到达都江堰后,你再次询问当地分拣中心同样的问题,回答"从成都市来,到乌鲁木齐去,请问下一站该去哪?"对方则指示:"前往兰州市。"此过程不断重复,直至抵达最终目的地乌鲁木齐。
cpp
成都 -------->都江堰分拣中心 ------->兰州分拣中心 → ... → 乌鲁木齐分拣中心--->快递员-> 收件人
↑ ↑ ↑ ↑ ↑ ↑
源IP 路由器1 路由器2 路由器N 交换机 目标IP
源MAC MAC(成都→都江堰) MAC(都江堰→兰州) MAC(...→乌鲁木齐) 目标MAC
源IP:成都 源IP:成都 源IP:成都
目标IP:乌鲁木齐 目标IP:乌鲁木齐 目标IP:乌鲁木齐由此我们可以看出,在网络中以数据帧为单位进行通信时,其源MAC地址与目标MAC地址在每一段链路中都会不断变化,但源IP地址与目标IP地址始终保持不变。因此, IP地址 与MAC地址 是协同工作的: IP地址 指引数据的最终方向,而相邻节点之间的实际数据传输则依靠 MAC地址 完成。
至此,相信你已经理解了数据从发送设备出发,经过中间路由器逐跳转发,最终到达目标设备的整个过程。如果我们把理解整个流程的核心细节视为一个完整的学习目标,那么目前已经完成了约70%到80%。剩下的部分主要涉及网络层与传输层的具体细节,这些内容在本文中尚未展开讨论。接下来,我将围绕网络层和传输层,继续讲解你需要掌握的核心知识。
网络层协议
接下来我们讨论 网络层协议 。根据上文,我们已经知道网络层协议的核心在于路由,即借助 路由表 确定转发的 下一跳设备 。当数据从应用层产生后,它会自顶向下依次经过 传输层 、 网络层,最后到达 数据链路层和 物理层。每一层都会在数据头部添加各自的 协议字段 。上文提到,在网络层也会添加一个固定格式的协议字段,并且其核心内容必然包括源IP地址与目标IP地址。
不过,源IP地址和目标IP地址只是该协议字段的一部分。接下来,我们来具体了解网络层协议包含哪些字段:
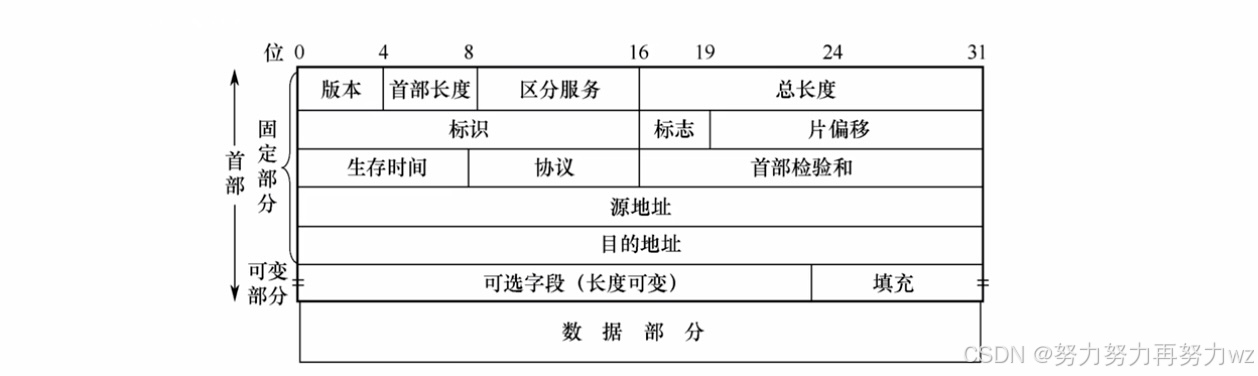
上图展示的是网络层协议(以 IPv4 为例)的格式。我们不需要掌握每一个字段,这里重点介绍几个核心部分:
版本:标识当前 IP 数据报使用的 IP 版本,例如 IPv4 或 IPv6。首部长度:表示 IP 数据报报头的长度,单位是4字节。该字段占4比特,取值范围为 5--15,对应报头长度为 20--60 字节。最小值为20字节,即 IP 报头的固定部分;最大 60 字节中多出的部分为可选字段。
可选字段通常用于特殊控制,一般了解即可,例如:
cpp
// 可选字段示例
enum ip_option_type {
IPOPT_END = 0x00, // 选项列表结束
IPOPT_NOOP = 0x01, // 无操作
IPOPT_SECURITY = 0x82, // 安全选项
IPOPT_LSRR = 0x83, // 松散源路由
IPOPT_SSRR = 0x89, // 严格源路由
IPOPT_RR = 0x07, // 记录路由
IPOPT_TIMESTAMP = 0x44, // 时间戳
IPOPT_RA = 0x94, // 记录路由(流ID)
};
- 总长度:指整个IP数据报(报头 + 数据部分)的长度,单位是 1字节,字段占 16 比特,因此 IP 数据报最大长度为 65535 字节。最小长度为 20 字节,即只有报头而无数据。
需要注意的是,虽然 IP 数据报最大可达 65535 字节,但在实际传输时,数据链路层会将其封装为帧,再由网络接口转换为物理信号发送到传输介质。不同的物理网络有各自的最大传输单元限制,即一次能够发送的数据上限。例如,以太网的MTU 一般为 1500 字节。
为此,内核会为每个网络接口(对应 struct net_device 结构体)记录其 MTU 值。如果一个 IP 数据报的长度超过了接口的 MTU,则必须在传输前进行分片。每个分片会独立发送,并在接收端重新组合为原始数据报。为了正确重组,每个分片必须携带相同的标识,以标识它们属于同一个原始数据报。
这类似于邮寄一本 300 页的书:邮局每次最多寄 100 页,因此你将书分为三个包裹,每个包裹贴上相同标签(如"张三的书"),收件人收到后根据标签将三部分合并为一本书。
在网络中,标识字段由发送方生成。你可能会问:如果两个不同发送方恰好使用了相同的标识值,是否会导致分片混淆?实际上,IP 数据报的重组并不仅仅依据标识字段,而是依据一个四元组:
cpp
重组键 = (标识, 源IP, 目标IP, 协议)这个组合在同一个连接中具有唯一性,因此不同数据报即使标识相同,也不会在重组时发生冲突。
下面是一个分片过程的示例:
cpp
# 发送端构造一个大包
原始数据报 = {
"标识": 12345, # 发送方生成的唯一ID
"总长度": 4000, # 超过以太网MTU(1500)
"数据": 4000字节的数据
"源IP": "192.168.1.100",
"目标IP": "10.0.0.1"
}
# 路径上的路由器发现MTU=1500,执行分片
# 注意:每个分片都有自己的IP头,但共享相同的"标识"
分片1 = {
"标识": 12345, # 与原始包相同
"总长度": 1500,
"分片偏移": 0, # 包含原始数据的0-1479字节
"更多分片标志": 1, # 1=后面还有分片
"数据": 原始数据[0:1480]
}
分片2 = {
"标识": 12345,
"总长度": 1500,
"分片偏移": 185, # 1480/8 = 185
"更多分片标志": 1,
"数据": 原始数据[1480:2960]
}
分片3 = {
"标识": 12345,
"总长度": 1040, # 最后一片
"分片偏移": 370, # 2960/8 = 370
"更多分片标志": 0, # 0=这是最后一个分片
"数据": 原始数据[2960:4000]
}现在读者可能会产生一个疑问:由于MTU限制,一个IP数据报会被分片,而IP数据报由报头和数据两部分构成,那么是否每个分片都必须携带完整的IP报头?
一种可能的想法是,只需第一个分片携带IP报头,后续分片可以只包含数据。但若采用这种方式,每个分片在封装成帧后转发至下一跳设备(如路由器),如果该分片不是第一个分片,则路由器在剥离帧头帧尾后,由于缺少网络层协议头部,无法将其递交给网络层处理。此时路由器只能等待所有分片到齐、重组为完整IP数据报后,才能进行路由转发。
然而,这种做法存在明显问题。路由器通常从多个端口接收数据帧,若需等待同一数据报的所有分片到齐后再统一转发,在等待期间会积压大量分片,不仅占用大量内存,还会引入显著的重组与路由时延。因此,这种方式在实际网络中是不可行的。
事实上,每个分片都会携带一个完整的IP报头,使得每个分片都可视为一个独立的IP数据报。网络层仅关注IP报头(即网络层协议信息),而不关心数据部分。当下一跳设备收到数据帧后,会立即剥离帧头和帧尾,将IP数据报交给网络层;网络层查询路由表后,立即将其重新封装成帧,转发至下一跳设备。
cpp
发送方:
原始数据报 (4000字节, MTU=1500) → 分片 → 分片1(1500) + 分片2(1500) + 分片3(1040)
传输路径:
路由器R1 → 收到分片1 → 立即转发
路由器R1 → 收到分片2 → 立即转发
路由器R1 → 收到分片3 → 立即转发
接收方:
等待所有分片到达 → 重组 → 交给上层分片重组工作由目标主机完成。由于每个分片都是独立的IP数据报,目标主机在收到数据帧后,剥离帧头与帧尾,递交给网络层。网络层首先判断该数据报是否为完整数据报,检查IP报头中的标志字段和片偏移字段。其中,MF标志表示该分片之后是否还有更多分片(MF=1表示还有;MF=0表示这是最后一片);片偏移则指示该分片在原始数据报中的位置(以8字节为单位)。以下通过一个例子进一步说明MF标志与片偏移的含义:
cpp
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| | DF|MF | 片偏移 |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+假设发送方要发送一个总长度为4000字节的IP数据报,而MTU为1500字节,因此该数据报无法一次性发送,必须分片。这4000字节是总长度,其中包括20字节的IP报头,因此数据部分长度为3980字节。MTU为1500字节,意味着每个分片的最大长度为1500字节。由于每个分片都包含20字节的IP报头,因此每个分片的数据部分最大为1480字节。
接下来计算所需分片数量:用数据部分长度3980字节除以1480字节,得到商为2,余数为1020字节。这意味着需要3个分片,其中前两个分片长度为1500字节,最后一个分片长度小于1500字节。
片偏移字段占13位,其单位是8字节。因此最大可表示的偏移量为(2^13 - 1)× 8 = 65528字节,接近IP数据报的最大长度。
具体分片如下:
第一个分片:片偏移 = 0,MF = 1,总长度 = 1500字节(报头20字节,数据1480字节)。
第二个分片:片偏移 = 1480 / 8 = 185,MF = 1,总长度 = 1500字节。
第三个分片:片偏移 = 2960 / 8 = 370,MF = 0,总长度 = 1020(数据)+ 20(报头)= 1040字节。
cpp
原始数据:
总长度(total_len)= 4000字节
IP头部(header_len)= 20字节
数据长度(data_len)= 4000 - 20 = 3980字节
MTU = 1500字节
计算每个分片最大数据长度:
max_data = mtu - header_len = 1500 - 20 = 1480字节
但必须是8的倍数:1480 ÷ 8 = 185 → 185 × 8 = 1480字节 ✓
计算分片数量:
3980 ÷ 1480 = 2.68 → 向上取整 = 3个分片
计算每个分片的偏移和长度:
分片1:
偏移 = 0字节
数据长度 = 1480字节
总长度 = 1480 + 20 = 1500字节
MF标志 = 1(有更多分片)
分片2:
偏移 = 185
数据长度 = 1480字节
总长度 = 1480 + 20 = 1500字节
MF标志 = 1(有更多分片)
分片3:
偏移 = 370
数据长度 = 3980 - 1480 - 1480 = 1020字节
总长度 = 1020 + 20 = 1040字节
MF标志 = 0(最后一个分片)接收方收到IP数据报后,剥离帧头和帧尾,首先检查MF标志和片偏移:
若MF ≠ 0,说明该分片不是最后一个,数据报不完整,需等待后续分片;
若MF = 0 但片偏移 ≠ 0,说明该分片是最后一个,但数据报仍不完整(缺少前面部分)。
以上两种情况均需将分片放入重组缓冲区。缓冲区通常以链表形式组织,每个节点按片偏移排序,并由一个结构体管理。该结构体包含指向链表头部的指针、已接收数据总长度,以及一个标识字段(四元组),用于区分不同原始数据报的分片。
cpp
// 分片缓冲区数据结构
#define MAX_FRAGMENTS_PER_PACKET 32
#define REASSEMBLY_TIMEOUT 30000 // 30秒超时
// 单个分片描述
struct ip_fragment {
uint16_t offset; // 偏移量(字节)
uint16_t len; // 数据长度
uint8_t *data; // 分片数据指针
bool received; // 是否已接收
time_t arrival_time; // 到达时间
struct ip_fragment *next;
};
// 重组缓冲区(一个原始数据报的所有分片)
struct ip_reassembly_buffer {
// 重组键(四元组)
struct {
uint16_t id; // 标识字段
uint32_t saddr; // 源IP
uint32_t daddr; // 目标IP
uint8_t protocol; // 协议类型
} key;
// 分片链表(按偏移排序)
struct ip_fragment *fragments;
// 重组状态
uint16_t total_len; // 完整数据报长度
uint16_t received_len; // 已接收数据长度
bool has_first; // 是否有第一个分片
bool has_last; // 是否有最后一个分片
uint8_t *frag_bitmap; // 分片位图(用于快速检查空洞)
time_t create_time; // 创建时间
time_t last_update; // 最后更新时间
};上述仅是分片重组的简化模型。实际系统中(例如Linux内核)会采用更高效的数据结构(如红黑树、哈希表)实现,但理解此模型有助于掌握重组的基本原理。
此外还需注意,网络中数据传输以帧为单位。若传输过程中出现差错,数据链路层检测到错误后会直接丢弃该帧。因此,接收方会为每个重组缓冲区维护一个超时计时器。若长时间未收到某个分片,将丢弃整个缓冲区的分片,释放资源。
除了MF 标志,IP报头中还有一个DF (Don't Fragment)标志。该标志由发送方设置,若DF =1,则表示该IP数据报不允许被分片。
cpp
接收分片处理流程:
┌─────────────────┐
│ 收到IP数据报 │
└────────┬────────┘
│
▼
┌─────────────────┐
│ 检查分片标志 │
│ - MF标志 │
│ - 分片偏移 │
└────────┬────────┘
│
┌────┴────┐
▼ ▼
完整数据报 是分片
│ │
▼ ▼
┌─────────┐ 查找重组缓冲区
│ 直接处理 │ │
└─────────┘ ▼
┌───────────┐
│ 创建新缓冲区 │
└─────┬─────┘
│
▼
将分片插入链表
(按偏移排序)
│
▼
更新缓冲区状态
│
▼
检查是否可以重组?
│
┌─────┴─────┐
▼ ▼
否 是
│ │
▼ ▼
等待更多分片 执行重组
│
▼
合并所有分片
(使用第一个分片头部)
│
▼
重新计算校验和
│
▼
交给传输层协议
│
▼
清理重组缓冲区本文最后要介绍并理解的一个字段是生存时间,即TTL 。TTL 值定义了一个数据包在网络上最多可以经过的路由器数量。每经过一个路由器,TTL 值就会减 1。TTL 字段的主要作用是防止路由环路 的产生。下面通过一个比喻来说明环路是如何形成的:
假设你想去乌鲁木齐市天山区幸福街。你先到达城市 A,询问当地人该怎么走,对方告诉你应该前往城市 B。到达城市 B 后,你再次询问,对方指引你去城市 C。但当你到达城市 C 并询问时,当地人却告诉你应该返回城市 A。
类似地,在网络中,路由环路 通常源于错误的路由配置或恶意攻击。以下是一个典型的路由环路 示例:
cpp
一个目标为 10.1.1.5 的数据包到达路由器 A。
A 查询自身路由表,发现"前往 10.1.1.0/24 网段的下一跳应发往 B",于是将包转发给 B。
B 查询路由表,认为"前往 10.1.1.0/24 的下一跳是 C",于是转发给 C。
C 查询路由表,错误地记录"前往 10.1.1.0/24 的下一跳是 A",于是又将包发回 A。
数据包回到 A 后,A 再次查表,仍然将其发往 B......
如此一来,这个数据包将在 A -> B -> C -> A 的三角环路中被无限循环转发。为解决这一问题,TTL 机制被引入。每个数据包在出发时都带有初始 TTL 值,每经过一个路由器,TTL 值减 1。若 TTL 大于 0,路由器正常转发该数据包;若 TTL 减至 0,路由器则丢弃该数据包,从而避免数据包在网络中无限循环。
而以上就是我们需要了解并且认识的网络层协议的各个字段
传输层协议
在了解了网络层协议各字段的具体细节之后,接下来我将进一步补充传输层协议的相关内容。传输层主要包括两个核心协议:TCP (传输控制协议)和UDP (用户数据报协议)。下文将针对这两个协议的关键机制与特点展开详细说明。
TCP协议
首先,我们讲解 TCP 协议。应用层产生的数据首先经过传输层,传输层会在应用层数据的头部添加自己的协议首部。如果传输层采用TCP 协议,则会在数据头部添加一个 TCP首部 。接下来,我们需要理解并掌握TCP 协议中几个关键的字段。我们先来看一下TCP首部 的结构:
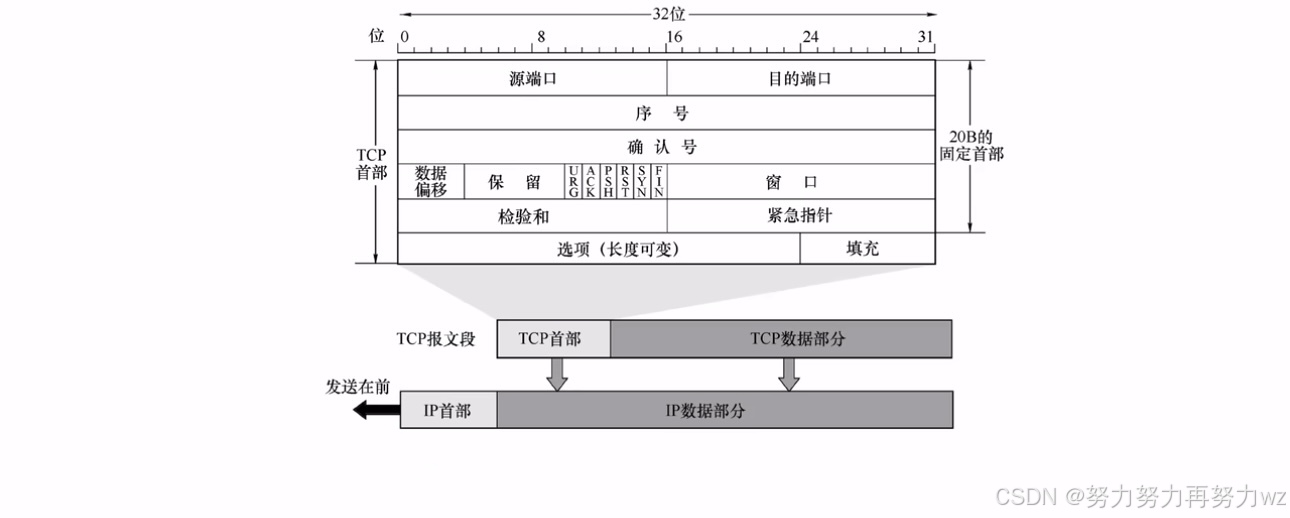
其中最核心的字段是源端口号 和目的端口号 。上文已简要提及端口号 的概念,由于设备间的通信本质上是进程间的通信 ,虽然我们通过IP地址 和 MAC地址 可以定位到具体设备,但最终数据需要交付给设备上运行的特定进程 。
我们可以用一个比喻来理解:假设有一个快递需要送到"北京市南关区幸福街",这个地址对应一栋建筑。快递送达建筑后,还需要进一步确定交给建筑内的哪个部门,每个部门有一个编号作为标识。建筑保安根据这个编号,就能将快递交给对应的部门。
类似地,端口号 用于标识同一设备中的不同进程。需要注意的是,IP 地址和 MAC 地址是全局唯一的,而端口号 仅在单个设备 内唯一,仅用于区分 该设备上的不同进程。因此,不同设备上的不同进程完全可以使用相同 的端口号 ,这是正常且不影响通信的。
我们通过"IP地址+端口号 "这个二元组,唯一标识网络中不同设备上的不同进程。
有读者可能会产生疑问:既然端口号 是用于标识进程的,而在 Linux 系统中,进程的 PID 也唯一标识一个进程,为什么不用"IP 地址 + PID"作为二元组,而要额外引入端口号 ?
这里需要注意,网络通信不仅限于同类型操作系统之间。例如,Windows 主机与 Linux 主机之间也需要通信。如果使用操作系统自己定义的进程标识符(如 PID),则不同操作系统的标识机制不同,会导致网络协议栈与具体操作系统实现强耦合 。这意味着不同操作系统需要实现各自独立 的网络协议栈。更关键的是,为了实现跨系统通信,例如 Linux 设备要与 Windows 设备通信,Linux 系统还需了解 Windows 系统对进程标识符的具体实现。假设未来 Windows 操作系统更新,其内部的进程标识机制发生改变,那么 Linux 系统的网络协议栈也必须随之修改适配。这种因一方改动而牵动多方的强依赖关系,显然会显著增加系统的复杂性 和维护成本 。
因此,引入端口号 是为了与操作系统解耦 。无论设备运行什么操作系统,只要它需要接入网络并与其他设备通信,就必须实现标准 的网络协议栈。也就是说,不同操作系统在进程管理、文件系统等模块上可以完全不同,但它们的网络模块(即网络协议栈)必须一致 。这样无论什么操作系统,其网络协议栈都是相同的,大大降低了维护成本。即使操作系统后续更新,也不会影响网络协议栈的实现。
因此,TCP首部 中的源端口号表示发送方设备的进程端口号 ,目的端口号 表示接收方设备的进程端口号。端口号字段占 16 位,取值范围为 1~65535。
理解了传输层协议最核心的字段后,接下来需要认识序号字段。序号字段的存在是因为传输层会对TCP报文段进行分段 。
读到"分段 "一词,可能有读者会联想到网络层对 IP 数据报的分片 。需要注意的是,网络层分片的依据是最大传输单元(MTU),而传输层分段的依据是最大段大小 (MSS ),MSS 位于 TCP首部 的选项字段中,其值取决于 MTU,目的是尽量避免网络层的分片 。
cpp
MSS = MTU - IP 首部长度(20) - TCP 首部长度(20)
标准以太网中:MSS = 1500 - 20 - 20 = 1460 字节每个分段都会携带一个序列号 ,用于标识该分段在原始数据字节流中的位置。需要注意的是,第一个分段的序列号 并非从 0 开始,而是随机初始化为一个非零值。后续分段的序列号 依次累加前一个分段的数据长度,其计算公式如下:
第 n 个分段的序列号 = 第 ( n − 1 ) 个分段的序列号 + 第 ( n − 1 ) 个分段的数据长度 第n 个分段的序列号 = 第 (n-1)个分段的序列号 + 第(n-1)个分段的数据长度 第n个分段的序列号=第(n−1)个分段的序列号+第(n−1)个分段的数据长度
示例如下:
cpp
分段1: 序列号 = 1000, 数据长度 = 1460, 数据字节范围 [1000, 2459]
分段2: 序列号 = 2460, 数据长度 = 540, 数据字节范围 [2460, 2999]使用序列号 的好处之一是处理延迟 或重复 的报文。例如,某个分段因延迟较晚到达目标设备,而此时该设备已结束与前一设备的通信,并与新设备建立连接。新设备发送的数据起始序列号为 5000,而旧分段序列号为 2000,目标设备识别其非当前期望的序列号范围,便会将其丢弃。
此外,每个分段都包含完整 的 TCP 首部,其中含有序列号 字段,使得接收方的传输层能够根据序列号对乱序到达 的 TCP 分段进行重排 、重组,并最终在剥离 TCP 首部后,将正确的数据顺序交给应用层。
那么接下来要了解的字段就是确认号 字段,那么这个字段一般则是要和一个标志位也就是Ack 标志位配合使用,那么Ack 标志位只占据1比特,那么其就只有两个值:0或者1,那么如果Ack 标志位为0,代表确认号 的值是无效的,如果Ack 的值为1,其确认号 的值是有效的,那么代表该TCP报文段是一个Ack 报文段,那么Ack报文段可以不携带任何的数据部分,而Ack 报文段的作用就是代表目标主机收到了你发来的数据,那么确认号的计算方式,就是已收到的最后一个字节序号加一:
cpp
确认号 = 期望收到的下一个字节的序号= 已收到的最后一个字节的序号 + 1那么知道了什么是确认号 以及序列号 之后,那么我们便能够理解TCP协议最为关键的一个环节,便是三次握手
TCP三次握手
TCP协议面向点对点 的通信。在双方正式开始传输有效数据之前,需要先建立连接 ,这个建立连接的过程称为 TCP三次握手 。在具体讲解三次握手之前,我们先理解为什么需要三次握手。这里我们借用一个生活中的例子来帮助读者理解:
当我们给别人打电话时,通常开口第一句话是"喂",对方往往也会回应"喂"。这两句"喂"本身并不传递实际信息,却是通话中一个常见的习惯。之所以有这样的习惯,是因为我们说"喂"是为了确认对方能否听到我们的话,而对方回"喂"则是在确认他收到了我们的"喂",同时也让我们确认能听到他的声音。
这个过程就类似于TCP 的三次握手。双方在正式通信之前进行这样一个环节,目的是确认彼此的 通信能力正常 ,避免出现一方说了一大段话后,才发现另一方因手机信号问题根本没有接收到任何信息。
因此,我们可以理解TCP三次握手的意义:用于检验通信双方的 收发能力 是否正常。如果正常,双方就能成功建立连接,进而进行后续正式的数据传输。用"三次握手"来形容这一建立连接的过程非常形象。接下来,我们具体看看这三次握手分别代表什么。
首先需要明确,通信双方通常扮演固定的角色: 客户端 和 服务端 。例如,微信用户之间的消息传递,会先经过 服务端,再由 服务端转发给 客户端。因此,通信本质上是 客户端与服务端之间的通信。
在文章开头已经强调过,设备间的通信实质上是进程间的通信。我们设备上运行的进程(如微信、QQ、王者荣耀等)属于客户端进程。如果主机上没有运行任何客户端进程,则该主机不会与其他主机通信。因此,建立连接的过程总是由客户端主动发起,而不是服务端主动向客户端发起连接。
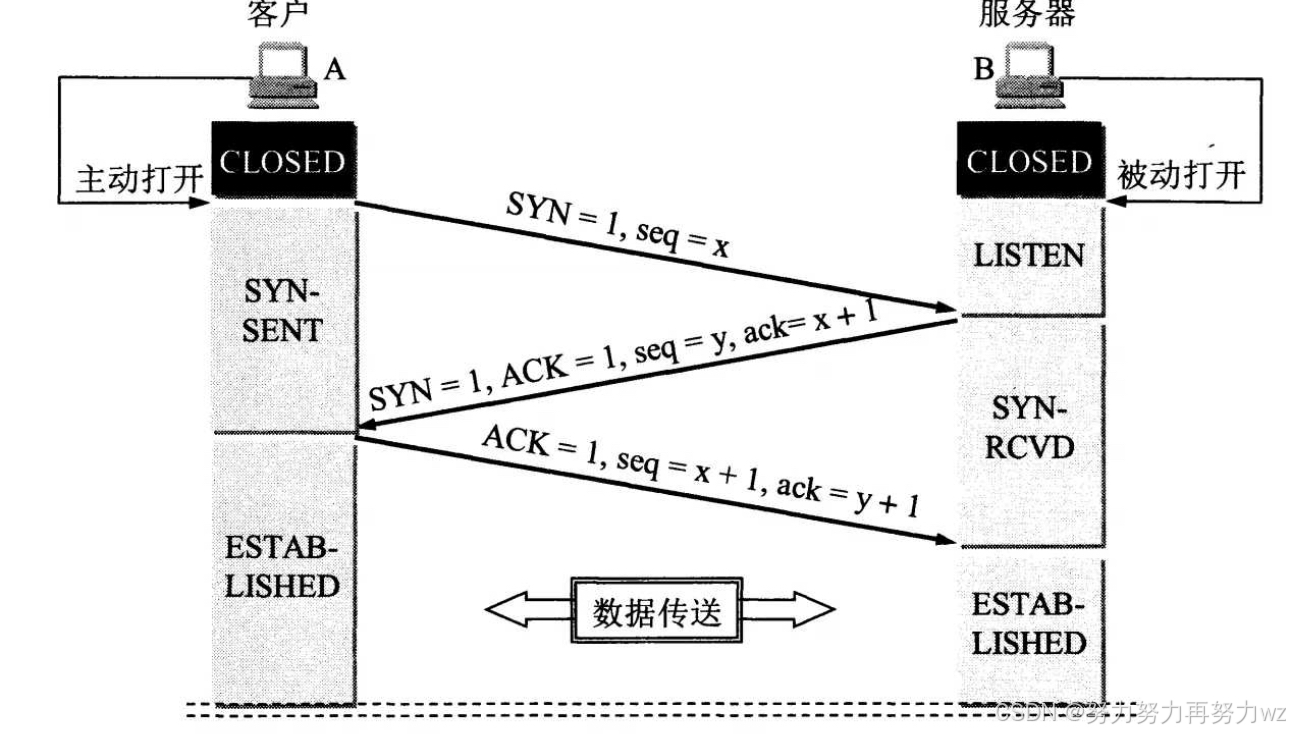
所谓的第一次握手,是指客户端向服务端发送一个连接请求报文段。这个报文段称为SYN报文段,其中SYN标志位被置为1。SYN置1表示这是一个用于发起连接的报文,其含义可理解为"我希望与你建立连接"。由于这是通信开始后的第一个报文,此前没有发送任何数据,因此其确认号Ack无实际意义,通常置为0。此外,第一次握手还有一个关键作用:为该SYN报文设置一个初始序列号(假设为x)。因此,该报文的内容可概括为:SYN=1,ACK=0,序列号seq=x。
服务端收到SYN报文后,得知有客户端希望建立连接,便会回复一个确认报文。与普通数据报文不同,这个报文同时设置了SYN和A标志位,称为SYN-ACK报文。该报文发回客户端,其含义是:"我已收到你序列号为x的SYN报文,我同意建立连接。请你确认,如果确定连接,请向我发送一个序列号为x+1的报文。"
服务端向客户端发送的这个SYN-ACK报文就是第二次握手。它不仅是对客户端连接请求的响应,同时服务端也为本次连接设定了一个初始序列号(假设为y)。因此,第二次握手的报文内容为:SYN=1,ACK=1,确认号ack=x+1,序列号seq=y。
客户端收到服务端发来的SYN-ACK报文后,会进行最终确认,向服务端发送一个ACK报文(注意这里不是SYN-ACK报文,而是将SYN置0,仅保留ACK)。这表示连接已建立完成,可以开始正式通信。该ACK报文的内容是:"我已收到你序列号为y的报文,最终确认与你建立连接。"这个由客户端发送给服务端的ACK报文即为第三次握手,其标志位为:SYN=0,ACK=1,序列号seq=x+1,确认号ack=y+1。
服务端收到客户端发来的ACK报文后,TCP连接正式建立,双方即可开始传输有效数据。
此时读者可能会问:为什么是三次握手,而不是两次或四次?上文已说明,三次握手的核心目的是确认双方的通信能力正常。这里的"通信能力"包括接收能力和发送能力两个方面。第一次握手由客户端发起,验证了客户端的发送能力;第二次握手由服务端发出,验证了服务端的接收能力和发送能力;第三次握手由客户端发出,验证了客户端的接收能力,并完成了序列号的同步。通过这三次交互,双方均确认了对端的收发能力正常,从而为可靠通信打下基础。
可靠性传输
在数据通信中,当数据帧在传输过程中发生差错时,数据链路层检测到差错后会直接丢弃该数据帧。由于一个数据帧通常对应一个 TCP报文段,该报文段也因此丢失。此时,通信的任何一方都不会无限期等待。TCP 协议设计了超时重传机制来处理这类情况。
具体来说,当一端向另一端发送数据时,接收方在成功收到数据后必须返回一个 ACK(确认)报文,以告知发送方数据已接收。如果某个 TCP报文段丢失,接收方将无法发送对应的ACK。发送方会为每个已发出的报文段启动一个计时器,若在设定时间内未收到相应的ACK(即超时),发送方会认为该报文段已丢失,并重新发送相同的 TCP报文段。
这就是超时重传的基本过程。在实际实现中,通常还会设定一个最大重传次数(在Linux上一般是 15 次),超过此次数后便不再重传,并认为连接异常。
此外,还存在另一种情况:ACK 报文可能因网络延迟未能在超时时间内到达发送方,导致发送方进行了重传,而接收方实际上已经收到了原始报文。此时,接收方会收到重复的 TCP报文。TCP 接收端会维护一个字段,记录期望接收的下一个字节的序列号,并通过比较该字段与到达报文的序列号来决定如何处理:
- 如果序列号等于期望值,说明是正常接收的报文;
- 如果序列号小于期望值,说明是重复的旧报文,直接丢弃;
- 如果序列号大于期望值,说明是新的、但顺序超前的报文,可先存入接收缓冲区,等待之前缺失的报文到达。
以下为该处理流程的示意:
cpp
接收方维护:
- 期望接收的下一个序列号
- 按序列号排序的接收缓冲区
当收到数据包时:
1. 检查序列号
2. 如果序列号 < 期望接收的下一个序列号 → 这是旧包,丢弃
3. 如果序列号 = 期望接收的下一个序列号 → 正常接收,交付上层并更新期望序列号
4. 如果序列号 > 期望接收的下一个序列号 → 新包但非预期,暂存至缓冲区通过上述机制,TCP 能够在不可靠的 IP 传输基础上实现可靠的数据交付,同时有效处理报文丢失、重复和乱序等情况。
TCP四次挥手
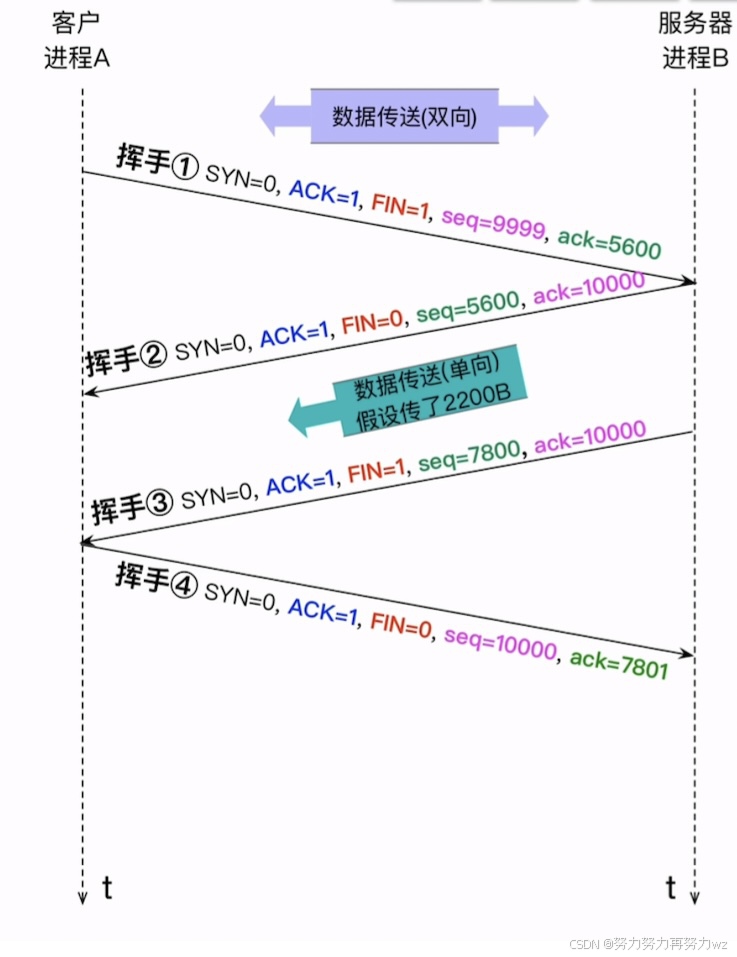
既然双方可以建立连接,自然也支持断开连接。这个断开连接的过程被称为"四次挥手 "。与TCP三次握手是由客户端主动发起连接不同,挥手过程既可由客户端发起,也可由服务端发起。握手时发送的是SYN 报文段,而挥手时发送的则是FIN报文段。所谓FIN 报文段,是指其首部中的FIN 标志位被设为1,用以表示这是一个用于断开连接的数据包。
假设客户端主动向服务端发送了一个FIN 报文段,表示它将停止向服务端发送数据。在发送这个FIN 报文段之前,客户端与服务端已经进行了一段时间的通信,因此服务端可能已经向客户端发送了一些数据。假设在发送FIN 之前,服务端最后发送的报文段序列号为y+n ,那么客户端此时发送的FIN 报文段含义为:"我将停止向你发送数据"。该FIN报文段设置FIN =1,ACK =1,假设其序列号为x+n ,确认号为y+n+1 。这是第一次挥手。
服务端收到该FIN 报文段后,需要对其进行确认,于是发送一个ACK 报文段作为响应,含义是:"我已收到你的断开请求,你可以停止发送数据"。这个ACK报文段设置FIN =0,ACK =1,序列号为y+n+1 ,确认号为x+n+1 。这是第二次挥手。
需要注意的是,经过前两次挥手,仅是单向断开 了连接------在上述场景中,是客户端到服务端方向的连接被断开,而服务端到客户端的连接仍然保持。这意味着服务端仍可继续向客户端发送数据。此时,客户端虽然不能向服务端发送有效数据,但仍需发送纯ACK 报文段来确认收到的数据,这类ACK报文段不携带任何应用数据,因此其序列号保持不变,一直为x+n+1 。
如果服务端也决定断开连接,它会发送一个FIN-ACK报文段,含义是:"我也要断开连接了"。该报文段设置FIN=1,ACK=1,序列号为y+n+m,确认号为x+n+1。这是第三次挥手。客户端收到后,会回复一个ACK报文段,确认服务端的FIN,从而完成双向连接的断开。这是第四次挥手。
整个过程背后还涉及通信双方的状态转换,这部分内容将在后文讲解TCP socket时进一步补充。
UDP协议
在了解了TCP协议 后,接下来我们介绍UDP协议 。读者很自然会问:TCP和UDP有哪些区别?
首先,最明显的区别在于协议字段。如果使用UDP协议,会在应用层传来的数据前添加一个UDP报头 。我们来看一下UDP报头 的结构:
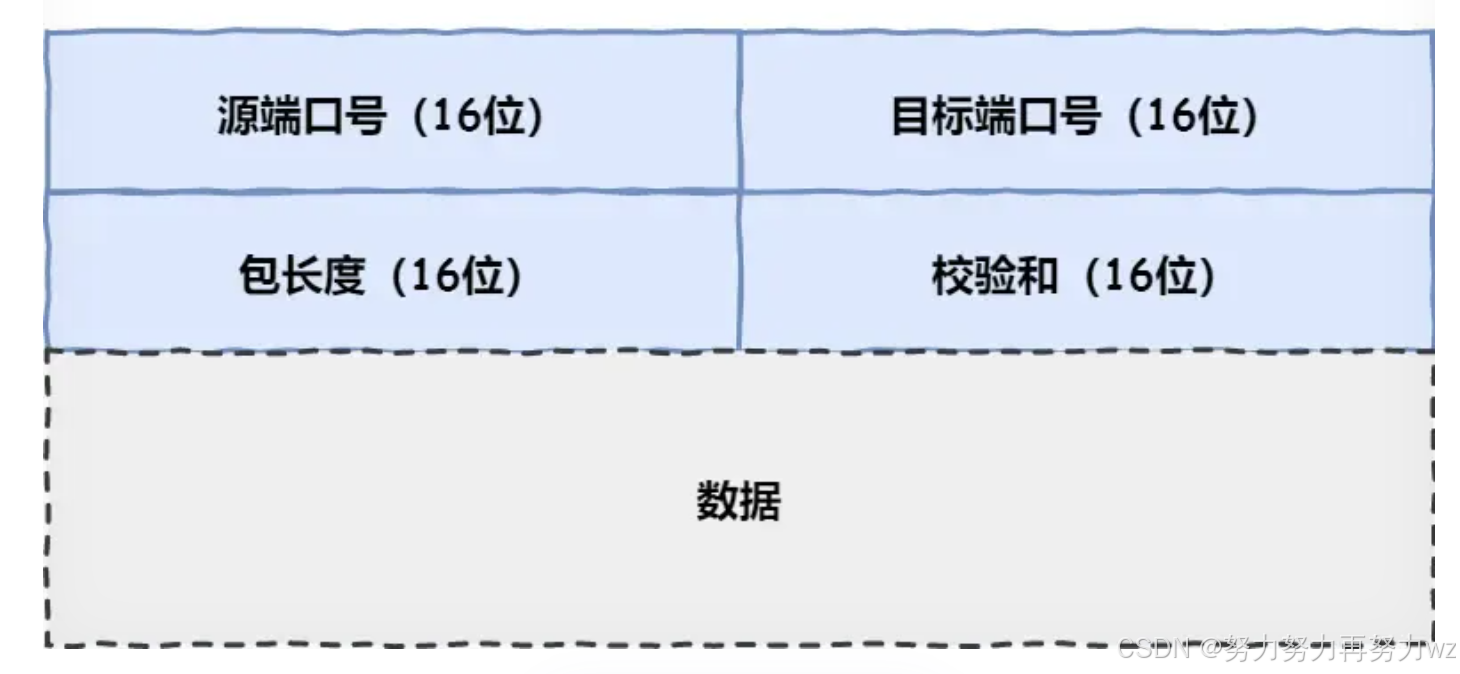
可以看出,UDP报头 比TCP报头 简单得多。TCP报头长度在20到60字节之间,而UDP报头 固定为8 字节。其中最关键的是源端口号 和目的端口号 。长度字段指UDP首部与数据部分的总长度 ,占16比特,因此UDP数据报最大长度为65535字节。由于UDP报头固定且字段少,因此UDP数据报比TCP更简单 、更轻量 。
但不要因为UDP报头简单就低估它,这种简洁也带来其特点:UDP提供不可靠传输 。
前文提到,TCP报头复杂是因为要保证可靠传输,这主要依靠序列号和确认号等机制实现。而UDP报头只有源端口、目的端口、长度和校验和等少数字段,不具备这些保障机制。
因此UDP的传输是不可靠 的。所谓不可靠,是指UDP只负责将数据发送到目标主机,如果传输过程中出现差错,虽然传输层可以通过校验和检测到错误,但UDP不会像TCP那样触发重传,而是直接丢弃 出错的数据报。
另外,UDP协议本身不具备类似TCP的流量控制与分段机制。这意味着,如果应用层下发的数据报文长度过大,UDP会将其作为一个整体传给网络层,从而可能在网络层进行分片处理。分片后的数据包在到达目的主机后,再在网络层重组为完整的UDP报文段,并交付给传输层。
此外,UDP在通信前不需要像TCP那样建立连接。TCP通过"三次握手"确认双方的收发能力正常后才开始传输数据,而UDP则直接开始发送数据。可以类比为打电话时不先问"喂,能听到吗?",而是直接说"你今天过得怎么样?"。正因为没有建立连接的过程,也没有出错重传机制,UDP被视为不可靠传输。
读到此处,可能会有疑问:既然UDP不可靠,而TCP能保证数据正确送达,那我们是否应该总是选择TCP?
需要指出的是,可靠性是有代价的。为了保证可靠,TCP需要在收到数据后发送ACK确认,如果未收到确认则重传,通信前还需建立连接,结束后要释放连接(四次挥手)。这使得TCP的通信流程比UDP更长、更复杂。相比之下,UDP非常简单:有数据就发送,没有就不发,无需额外通知。
另外,TCP是点对点的传输,一个连接只能用于两个固定进程之间的通信。若要与多个不同进程通信,需建立多个TCP连接。而UDP支持与任意进程通信,也能接收来自任意进程的数据。它可以向单播地址(指定IP和端口)发送数据,也可以向多播地址发送,此时同一子网内的多个设备都能收到该数据包。因此,像直播这类需要同时向多个主机发送相同数据的场景,常采用UDP多播。
cpp
需要可靠传输吗?
├── 是:数据必须完整、按序到达(如文件传输、网页)
│ └── 选择TCP
└── 否:可以容忍少量丢失,但需要低延迟
├── 实时性要求极高(如游戏、语音)
└── 选择UDP以上便是UDP协议的核心内容,其设计确实十分简洁。
至此,我们已经掌握了传输层的关键协议(TCP与UDP)及其特点。有了这些理论基础,接下来便可以进入下一个重要主题:网络编程。
网络编程
那么前面铺垫了这么久,就是为了网络编程准备的,那么在正式写代码之前,我们一定得需要补充一些计算机网络的相关知识,这样我们才能知道我们编写的每一行代码,其目的是什么,并且这行代码其底层大概会做什么,那么只有具备网络的原理之后,我们才能明白刚才所说的目的以及其底层的行为,这样才能更好的帮组我们编写并且理解我们写的代码
那么在正式编写代码之前,那么首先我来明确一下接下来我们要编写的代码会实现一个什么样的内容:
我们要编写两个程序,那么这两个程序要进行通信,那么与之前进程间通信不同的是,那么这里这两个进程之间不是通过管道或者共享内存进行通信,而是通过网络进行通信,通信的两个进程一方会担任客户端的角色,另一方会担任服务端的角色
而客户端进程则是主动发送数据包到达服务端,那么服务端则是作为被动的一方,接收客户端发来的数据包,然后对客户端发来的数据包的内容解析并且处理,再将处理的数据发送给客户端,而这就是接下来我们代码要实现的核心内容
而上文我说了,那么我们传输层有两种协议,分别是UDP协议以及TCP协议,所以意味着这里客户端与服务端之间可以采取UDP协议或者TCP协议进行通信,而这里首先我会先讲解如何实现采取UDP协议的进程间通信,因为UDP要比TCP更简单,那么讲解完UDP之后,那么我会再来讲解用TCP协议实现通信
UDPsocket
基于上文所述,我们理解到所编写的代码核心是实现进程间通信,而通信的两个进程位于不同设备上,其中一方作为客户端,另一方作为服务端。本文首先讲解客户端进程以及服务端进程的具体代码实现之前,我们得先认识几个必要的接口。
socket
在客户端-服务端通信模型中,客户端的主要职责是主动发起请求,即向服务端发送数据包,由服务端进行处理。服务端则负责接收来自客户端的请求数据,执行相应处理,并将处理结果返回给客户端。无论进程扮演客户端还是服务端的角色,其通信流程的第一步都是相同的:创建套接字。
这就引入了网络编程中需要掌握的第一个重要概念------ 套接字 。什么是套接字呢?
根据前文,任何设备从网络接收或发送数据的过程,都可以通过TCP/IP模型来描述。应用层(即进程产生的数据)会依次经过 传输层 和 网络层 的加工处理。 传输层和 网络层 由操作系统实现,而应用层则由程序员负责。套接字的第一个属性是作为" 描述符 ",用于描述 传输层 和 网络层 的相关属性。因此, 套接字 是一个结构体,其内部包含众多字段,用于记录 网络层 和 传输层 的属性。这些属性在上文已作说明,与传输层(如UDP报文头)和网络层(如IP数据报报头)的各个字段密切相关。
除了作为描述符, 套接字 的第二个属性是" 容器 "。应用层产生的数据会保存到 套接字 中,之后交由传输层和网络层(即内核)加工处理;而接收到的数据在经过网络层和传输层协议字段剥离后,得到的应用层数据也会存放到这个"容器"------即 套接字 中。
因此, 套接字 的本质是"描述符"+"容器"。既然它会记录传输层和网络层的相关属性(具体为协议的各个字段),而传输层有不同协议(如UDP、TCP),网络层也有不同协议(如IPv4、IPv6),我们可以通过修改 套接字 的属性,来规定数据以何种方式加工和处理,相当于确定一份" 运输合同 "。
理解了套接字的概念后,如何在代码层面创建 套接字 ?这需要调用 socket接口。
socket头文件:<sys/types.h> 和 <sys/socket.h>
声明:int socket(int domain, int type, int protocol);
返回值:成功返回非负整数,失败返回
-1(并设置errno)
调用 socket 接口会同时完成两件事:一是确定" 运输合同",即选择传输层和网络层协议;二是创建" 容器"。从参数可以看出,第一个参数指定网络层协议(如IPv4或IPv6),第二个参数指定 套接字类型(决定传输层协议),第三个参数一般设为 0,表示使用给定域和套接字类型的默认协议。该接口底层会创建一个 struct socket结构体,其具备了上文所述的"描述符+容器"功能。
cpp
应用程序
↑↓
┌─────────────────┐
│ 套接字API(socket)│ ← 创建一个"描述符+容器"即套接字
├─────────────────┤
│ 传输层(TCP/UDP)│
├─────────────────┤
│ 网络层(IP) │
├─────────────────┤
│ 链路层(以太网) │
├─────────────────┤
│ 物理层(网卡) │
└─────────────────┘
cpp
struct socket {
// 1. 套接字状态
socket_state state; // SS_FREE, SS_UNCONNECTED, SS_CONNECTING, SS_CONNECTED
// 2. 协议族信息
struct proto_ops *ops; // 协议操作函数表
unsigned short type; // 套接字类型
unsigned int flags; // 套接字标志
// 3. 文件系统关联
struct file *file; // 关联的文件结构
struct sock *sk; // 网络层套接字结构
// 4. 等待队列
wait_queue_head_t wait; // 等待队列
//.....
};socket 接口的前两个参数,在底层用于设置 socket 结构体的对应字段。该结构体中最核心的是 sk 字段,它指向 sock 结构体。 sock 结构体的各个字段详细记录并描述了网络层和传输层的属性,内核正是通过它来管理套接字对应的网络与传输层状态。可以这样比喻: socket结构体像是汽车的外壳,而 sock 结构体则是内部的发动机。
cpp
// 简化的struct sock(实际很复杂)
struct sock {
// 通用部分
struct sock_common __sk_common;
// 协议特定数据
union {
struct inet_sock inet; // IPv4套接字
struct inet6_sock inet6; // IPv6套接字
struct unix_sock unix; // UNIX域套接字
};
// 发送/接收缓冲区
struct sk_buff_head sk_receive_queue; // 接收队列
struct sk_buff_head sk_write_queue; // 发送队列
// 套接字选项
unsigned int sk_sndbuf; // 发送缓冲区大小
unsigned int sk_rcvbuf; // 接收缓冲区大小
// ... 更多成员
};要创建一个使用IPv4协议并采用UDP协议的套接字,需要正确设置socket接口的参数。对于第一个参数,其类型为整型,但内核将其定义为一系列宏:
cpp
// 在 <sys/socket.h> 中的定义
#define AF_UNSPEC 0 /* 未指定 */
#define AF_UNIX 1 /* Unix域套接字 */
#define AF_INET 2 /* IPv4 Internet协议 */
#define AF_AX25 3 /* AX.25协议 */
#define AF_IPX 4 /* IPX协议 */
#define AF_APPLETALK 5 /* AppleTalk协议 */
#define AF_NETROM 6 /* 从Amateur Radio NET/ROM */
#define AF_BRIDGE 7 /* 多协议桥接 */
//......此处我们需要使用IPv4协议,因此应传入宏 AF_INET 。
对于第二个参数,内核同样将其处理为宏:
cpp
// 在 <sys/socket.h> 中定义的类型宏
#define SOCK_STREAM 1 /* 流式套接字,可靠,有序,双向 */
#define SOCK_DGRAM 2 /* 数据报套接字,不可靠,有边界的消息 */
#define SOCK_RAW 3 /* 原始套接字 */
#define SOCK_RDM 4 /* 可靠递送消息 */
#define SOCK_SEQPACKET 5 /* 有序分组套接字 */
#define SOCK_PACKET 10 /* 底层数据包接口(已过时) */流式套接字( SOCK_STREAM )对应 TCP 协议,而数据报套接字( SOCK_DGRAM )对应 UDP 协议。
了解这些之后,我们可以进一步理解 socket 接口的底层行为:它实际上创建了一个 struct socket 结构体。需要注意的是,前文给出的 struct sock 是简化定义,并非内核实际用于管理套接字的完整结构。由于传输层和网络层各自有不同的协议,各协议所需的字段也各不相同,因此无法用单一结构体来描述所有协议,每个协议必然有自己特有的结构体,包含该协议专有的成员。
无论何种协议,都会有一个缓冲区用于存储应用层发送的数据以及加工后的数据,这部分内容由 struct sock 结构体管理。其中的关键字段包括发送队列和接收队列,它们本质上都是链表,链表中的每个节点存储经过加工处理的数据包。
struct sock还会记录发送缓冲区与接收缓冲区的总大小(以字节为单位),以及两个队列中的节点数量。
cpp
struct sock {
// 1. 队列(管理数据包)
struct sk_buff_head sk_receive_queue; // qlen记录节点个数
struct sk_buff_head sk_write_queue; // qlen记录节点个数
// 2. 内存分配(管理字节数)
unsigned int sk_rmem_alloc; // 接收缓冲区已分配字节
unsigned int sk_wmem_alloc; // 发送缓冲区已分配字节
// 3. 容量限制
int sk_rcvbuf; // 接收缓冲区最大字节
int sk_sndbuf; // 发送缓冲区最大字节
};对于队列(即链表)中的每个节点,除了指向前驱与后继节点的指针外,还包含一组数据指针和偏移量,用于定位各层协议头部及数据部分。此外,节点中还包含实际的数据内容,涵盖各层协议头部与载荷。
cpp
struct sk_buff {
// 1. 链表管理
struct sk_buff *next; // 指向下一个sk_buff
struct sk_buff *prev; // 指向上一个sk_buff
// 2. 缓冲区指针
unsigned char *head; // 缓冲区起始地址
unsigned char *data; // 当前数据开始地址
unsigned char *tail; // 当前数据结束地址
unsigned char *end; // 缓冲区结束地址
// 3. 协议头偏移量(关键!)
unsigned int mac_header; // 以太网头偏移
unsigned int network_header; // IP头偏移
unsigned int transport_header; // TCP/UDP头偏移
// 4. 元数据
unsigned int len; // 数据长度
__u16 protocol; // 协议类型
// ... 其他字段
};需要注意,在创建队列节点时,内核会直接分配整个 IP 数据包的空间。即使在填充协议字段之前,就已经预留了网络层、传输层协议头部及数据部分的空间。这是一种以空间换时间的策略,通过四个指针(head 、data 、tail、end )来管理缓冲区。其中head指向整个 IP 数据包的起始位置,tail指向数据尾部,end指向缓冲区的结束位置。这三个指针是固定的,实际的数据定位通过移动data 指针实现。
内核维护一组偏移量,分别表示从head 起始位置到 MAC 头、IP 头和传输层头部的距离。在封装协议字段时,通过head 加上对应偏移量得到data 的位置,再填充相应字段;解封装则是对称的逆向过程。
cpp
内存布局(发送数据时创建):
┌─────────────────────────────────────────────┐
│ 头部预留空间 │ 以太网头 │ IP头 │ UDP头 │ 应用数据 │ 尾部预留空间 │
└─────────────────────────────────────────────┘
↑ ↑ ↑ ↑ ↑ ↑ ↑
head mac_hdr ip_hdr udp_hdr data tail end
# 封装过程:
初始状态(只有应用数据):
[预留][应用数据][预留]
data/tail
添加UDP头:
[预留][UDP头][应用数据][预留]
data tail
添加IP头:
[预留][IP头][UDP头][应用数据][预留]
data tail
添加以太网头:
[预留][以太网头][IP头][UDP头][应用数据][预留]
data tail
--------------------------------------------------------
# 解封过程:
收到完整数据包:
[预留][以太网头][IP头][UDP头][应用数据][预留]
data tail
剥离以太网头:
[预留][以太网头][IP头][UDP头][应用数据][预留]
data tail
剥离IP头:
[预留][以太网头][IP头][UDP头][应用数据][预留]
data tail
剥离UDP头:
[预留][以太网头][IP头][UDP头][应用数据][预留]
data/tail尽管 Linux 内核由 C 语言实现,但在处理不同协议对应的结构体时,采用了面向对象中继承的思想。网络层位于传输层之下,对应管理网络层协议字段的结构体是inet_sock ,其第一个成员是struct sock 结构体,相当于将struct sock 嵌入其中作为基类。
inet_sock会根据网络协议类型有不同的实现,但除第一个成员相同外,其余均为特定协议专有字段。以 IPv4 对应的inet_sock 结构体为例,其中必然包含目标 IP 地址和源 IP 地址等字段。
cpp
struct udp_sock { // UDP层
struct inet_sock { // IP层
struct sock { // 传输层基类
// 通用套接字信息
};
__be32 inet_daddr; // 目标IP
__be32 inet_saddr; // 源IP
__be16 inet_dport; // 目标端口
__be16 inet_sport; // 源端口
};
// UDP特有字段
int corkflag; // 是否启用corking
int pending; // 待处理数据
// ... 没有端口号相关字段
};最后是udp_sock 结构体,它继承自inet_sock ,因为传输层位于网络层之上。其第一个成员是inet_sock,其余成员为 UDP 协议的特有字段
需要注意的是,socket接口返回的值是一个文件描述符。这是因为Linux遵循"一切皆文件"的设计哲学,而套接字对应的socket结构体是内核层面的数据结构,操作系统不能直接向用户暴露操作该结构体的接口。因此,内核采取的方法是:在用户层映射一个文件,用该文件代表对应的套接字。用户通过操作文件,间接操作内核中的socket结构体,从而实现了解耦。
既然内核实际管理套接字是通过socket结构体,那么file结构体就必须与socket结构体建立关联。因此,file结构体中的private_data指针就指向了对应的socket结构体。同时,file结构体中的文件操作函数表(file_operations)也指向socket对应的操作函数表。在后文讨论TCP套接字时,我们会看到它直接复用了文件的操作接口,例如read和write,这也体现了多态的特性。
cpp
// 在file结构体中
struct file {
// ... 其他字段 ...
// 关键指针:指向具体的驱动/子系统数据结构
void *private_data; // 对于socket,这里指向struct socket*
// 文件操作函数表
const struct file_operations *f_op;
// ...
};
--------------------
内核空间:
fd → 进程文件描述符表 → struct file* → struct socket* → struct sock*
↑ ↑ ↑ ↑ ↑
用户可见 系统维护 file结构体 socket结构体 sock结构体由此可见,socket接口在底层所做的工作并不仅仅是创建一个socket结构体。它还会根据调用时传递的参数,设置对应的操作函数表,创建具有继承关系的sock结构体及file结构体,并将file结构体与socket结构体正确关联起来。
bind
根据上文,我们已经了解了如何创建一个套接字。然而,仅仅调用 socket接口就像刚买了一部手机却尚未安装电话卡------此时手机没有电话号码,其他手机无法获知它的号码,因而无法与之通信。
调用 bind接口可以形象地理解为给这部新手机装上电话卡,使得其他手机能够拨打该号码并建立通话。对套接字而言,其"电话号码"就是由 IP 地址 + 端口号 构成的二元组。我们需要为套接字绑定这样一个二元组,并将其告知对方,从而能够与对方完成通信。
内核为用户层提供了一个 struct sockaddr_in 结构体,允许用户设置要绑定的 IP 地址、端口号以及协议类型。前文提到,不同协议对应的 sock 结构体是不同的,这里同样如此:如果使用不同的网络层协议,对应的
struct sockaddr_in结构体各字段的组成也会不同,但它们的第一个字段都是相同的,类型为 sin_family_t (本质上是一个整数),用于标识地址族:
cpp
// IPv4 地址结构
struct sockaddr_in {
sa_family_t sin_family; // 地址族: AF_INET
in_port_t sin_port; // 端口号(网络字节序)
struct in_addr sin_addr; // IP 地址(网络字节序)
unsigned char sin_zero[8]; // 填充,使大小与 sockaddr 相同
};
// 大小:16 字节
struct in_addr {
in_addr_t s_addr; // 32 位 IPv4 地址
};
--------------------------------------------------------------
// IPv6 地址结构
struct sockaddr_in6 {
sa_family_t sin6_family; // 地址族: AF_INET6
in_port_t sin6_port; // 端口号(网络字节序)
uint32_t sin6_flowinfo; // IPv6 流标签
struct in6_addr sin6_addr; // IPv6 地址
uint32_t sin6_scope_id; // 接口范围 ID
};
// 大小:28 字节
struct in6_addr {
unsigned char s6_addr[16]; // 128 位 IPv6 地址
};
- 函数:
bind- 头文件:<sys/types.h> 与 <sys/socket.h>
- 声明:int bind(int sockfd, const struct sockaddr* addr, socklen_t addrlen);
- 返回值:成功返回
0,失败返回-1(并设置errno)
需要注意的是,所创建的套接字可能支持 IPv4 协议,也可能支持 IPv6 协议,而这两种协议对应不同的地址结构体。 bind 需要能够识别传入的结构体类型。由于这些结构体的第一个字段都是地址族(address family),因此可通过该字段进行辨识。 bind 的第二个参数类型为 struct sockaddr* ,该通用地址结构的第一个字段与 sockaddr_in 的第一个字段相同。因此,在传递 struct sockaddr_in 指针给 bind 时,需要将其强制转换为 struct sockaddr* 。
bind 会根据第一个字段的值确定实际的地址族,并在内部进行相应的类型转换。
cpp
// 通用地址结构
struct sockaddr { // 通用地址结构
sa_family_t sa_family; // 地址族
char sa_data[14];// 地址数据
};
// 大小:16 字节在调用 bind 之前,我们首先需要创建并初始化一个 struct sockaddr_in 结构体(该结构体定义在 <netinet/in.h> 中),指定要绑定的 IP 地址和端口。初始化时,首先设置第一个字段 sin_family来指定地址族,接着设置第二个字段 sin_port 来指定端口号。
端口号字段占 16 位,因此端口范围是 1 到 65535。需要注意的是,端口号不能任意绑定:1 到 1023 是特权端口,绑定这些端口需要 root 权限;1024 到 49151 是注册端口,供普通用户注册使用;49152 到 65535 是动态/私有端口。
端口的作用是标识设备上的不同进程,这是一种一对一的关系:一个端口只能对应一个进程的套接字,但一个进程可以拥有多个套接字(即对应多个端口)。内核会维护一个哈希表来管理这种映射关系。
这里需要引入 网络命名空间 的概念。网络命名空间记录了设备在网络层的所有相关信息,例如路由表、网络设备、哈希表等。每个网络命名空间都是独立的。操作系统遵循"先描述,再组织"的方式来管理底层硬件,例如通过 struct net_device描述网络接口,而网络接口只是网络命名空间的一个组件。网络命名空间对应 struct net结构体,其中维护了一个链表,链表节点即为 struct net_device 。此外,网络命名空间还维护了哈希表,其中每个元素的键是(IP, 端口)二元组,值是对应 sock结构体的地址。不同协议(如 UDP、TCP)拥有各自的哈希表。
我们知道,传递给 bind 函数的第一个参数是文件描述符。文件描述符本质上是进程文件描述符表(即一个指向 file 结构体的指针数组)中的索引,通过该索引可以定位到对应的 file 结构体。file 结构体中有一个成员 private_data ,它关联着一个 socket 结构体。而 socket结构体内部有一个指针字段 sk ,指向 sock 结构体。因此,通过文件描述符可以最终定位到对应的 sock 结构体,并将其地址作为值填入相应的哈希表中。
cpp
用户空间调用 bind(fd, ...)
↓
文件描述符 fd(整数,如 3)
↓
进程的文件描述符表(fd_array)
↓
struct file* 指针
↓
struct file 结构体
↓
file->private_data → struct socket*
↓
struct socket 结构体
↓
socket->sk → struct sock*
↓
struct sock 结构体
↓
插入哈希表:value = sock 的地址bind 调用时,内核会先定位到套接字所属的网络命名空间,再根据套接字类型找到对应的协议哈希表,接着检查该二元组键值是否已存在。若存在,则绑定失败。
cpp
bind → 找到套接字的网络命名空间
→ 找到协议的哈希表
→ 检查(IP, 端口)是否冲突
→ 不冲突则绑定成功一台设备可以拥有多个网络命名空间,每个网络命名空间都包含独立的网络设备、路由表、哈希表等,相当于一个独立的网络协议栈。网络空间就类似于Linux的环境变量,描述了进程运行的网络环境,在 Linux 中,容器技术就利用了这一机制,每个容器可以拥有自己虚拟的网络设备和对应的路由表。
cpp
// 简化的网络命名空间结构
struct net {
// 进程可见的网络设备列表
struct list_head dev_base_head;
struct hlist_head *dev_name_head;
struct hlist_head *dev_index_head;
// 协议相关的哈希表
struct inet_hashinfo tcp_hashinfo; // TCP连接哈希表
struct udp_table *udp_table; // UDP表
struct raw_hashinfo raw_hashinfo; // RAW socket表
// 路由表
struct fib_table *fib_main;
struct fib_table *fib_local;
// 防火墙规则
struct xt_table *iptable_filter;
struct xt_table *iptable_mangle;
struct xt_table *iptable_nat;
// 网络命名空间引用计数
refcount_t passive; // 被动引用
refcount_t count; // 主动引用
// 命名空间ID
unsigned int nsid;
};
-----------------------------------------------
物理主机:
├── 默认网络命名空间
│ ├── 物理网卡:eth0
│ ├── 路由表
│ └── TCP/UDP哈希表
│
├── 容器A网络命名空间
│ ├── 虚拟网卡:veth0
│ ├── 虚拟路由表
│ └── 独立的TCP/UDP哈希表
│
└── 容器B网络命名空间
├── 虚拟网卡:veth1
├── 虚拟路由表
└── 独立的TCP/UDP哈希表
---------------------------------------------
// 示例:两个独立命名空间中的哈希表
命名空间 A 的 UDP 哈希表:
端口 1128 → 192.168.1.1:1128
端口 1167 → 192.168.1.1:1167
命名空间 B 的 UDP哈希表:
端口 1128 → 10.0.0.1:1128
端口 1167 → 10.0.0.1:1167
// 这两个哈希表完全独立,因此端口 80 可在两个命名空间中同时使用。在客户端程序中,通常不会显式调用 bind 来为套接字绑定一个固定端口。这是因为客户端程序一般运行在不同的设备上,而编写客户端的程序员无法预知其他客户端的具体实现。如果程序员在代码中为客户端套接字硬编码或手动指定一个端口号,那么当两个客户端位于同一网络环境,且使用相同的传输层协议(例如 UDP)时,若它们从同一网络接口收发数据,就会出现 IP 地址和端口号完全相同的情况。这将导致其中一个客户端绑定失败。因此,对于客户端而言,通常将端口号的分配交由内核自动处理,以避免此类冲突。
sendto
在学习前两个接口后,我们已经能够成功创建套接字。套接字准备就绪后,即可正式向另一台设备上的进程发送数据。发送数据通过 sendto 接口实现:
sendto- 头文件: <sys/types.h>和 <sys/socket.h>
- 声明:ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen);
- 返回值:成功返回实际发送的字节数,失败返回
-1(并设置errno)
sendto 的第一个参数是套接字文件描述符。该接口首先会校验文件描述符的有效性,若没有问题,则通过文件描述符定位到对应的 file 结构体,再通过 file 结构体找到其关联的 socket 结构体,最终通过 socket 结构体内部的指针定位到 struct sock 结构体。正如前文所述, sock 结构体在此处起到"容器"的作用,用于暂存应用层数据以及经过传输层和网络层加工处理后的数据。
我们通常会准备一个缓冲区(一般以数组形式)来存放应用层待发送的数据,然后将该数组的首地址传递给
sendto ,这对应第二个参数 buf 。第三个参数 len 则为要发送的数据长度。
第四个参数 flags 是发送标志位,通常设置为 0 ;其他选项在目前阶段暂不涉及,后续学习中会进一步展开。
最后两个参数的类型为 struct sockaddr* 与 socklen_t(本质就是一个无符号整形:在 <sys/socket.h> 中的典型定义:typedef unsigned int socklen_t; ) ,这里由于内核无法预知调用方具体使用哪一种地址结构体(如 struct sockaddr_in ),因此将参数类型声明为通用的 struct sockaddr* 。内核在写入地址信息时,会先检查该结构体中的地址族(address family)字段,从而识别出具体的地址类型,而这两个参数都属于输入型参数。由于数据报需要发送到另一台设备上的目标进程,因此必须通过这两个参数指明目标 IP 地址和端口号,以确定接收方的位置。
接下来简要说明 sendto的底层操作流程。通过文件描述符,可以在进程的文件描述符表(本质上是一个指针数组)中找到对应的 file 结构体,进而关联到 socket结构体。 socket 结构体中有一个 sk 指针指向 sock 结构体,从而最终定位到 sock 结构体。
sock 结构体的主要功能是提供缓冲区,其内部维护两个队列(本质上是链表),链表的每个节点是一个
sk_buff 结构体。 sendto 定位到 sock 结构体后,会创建一个新节点,将应用层数据(来自 buf )拷贝到该节点的数据区,并将其插入发送队列。队列首部的节点会最先被取出并发送,同时系统会更新当前缓冲区总大小与节点数量。至于目标 IP 地址和端口号(由最后两个参数提供),会在传输层和网络层处理时,分别用于设置 UDP 报头中的目的端口和 IP 报头中的目的 IP 地址。
根据前文内容,对于客户端而言,程序员通常无需显式调用 bind 来指定端口号,这项工作实际上由 sendto 在内部完成:如果检测到套接字尚未绑定端口,内核会自动为其分配一个未被使用的端口号。
recvfrom
既然已经介绍了发送数据包的接口,接下来我们认识接收数据的接口------ recvfrom :
recvfrom- 头文件:<sys/socket.h>
- 函数声明:ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,struct sockaddr *src_addr, socklen_t *addrlen);
- 返回值:成功时返回实际接收的数据长度,失败时返回
-1(并设置errno)。
- 第一个参数
sockfd是套接字对应的文件描述符,用于定位内核中该套接字对应的sock结构体。 - 第二个参数
buf是接收缓冲区,通常是一个数组,用于存放接收到的数据。 - 第三个参数
len指定缓冲区的最大长度,避免溢出。 - 第四个参数
flags是标志位,一般设置为0;其他选项在现阶段无需深入。 - 最后两个参数
src_addr和addrlen与sendto不同:在recvfrom中它们是输出型参数。
src_addr的类型为struct sockaddr*,内核在收到数据包后,会解析其 IP 和 UDP 头部,提取发送方的 IP 地址与端口号,并填写到src_addr所指向的地址结构体(如sockaddr_in)中。由于调用前无法预知发送方的地址结构,内核会通过sockaddr中的地址族(address family)字段来判断具体的结构类型。
这样,调用方即可通过 src_addr 获取发送数据包的进程的 IP 地址与端口号。
recvfrom 的底层执行流程
以下是 recvfrom 的简要内部过程:
- 检查
sockfd有效性,通过文件描述符表找到对应的file结构体,进而定位到内核的socket及底层
sock结构体。 sock结构体内维护了一个接收队列sk_receive_queue(本质是链表),每个节点为sk_buff(套接字缓冲区)。系统从队头取出一个sk_buff。- 将其数据区中应用层数据拷贝到用户传入的缓冲区
buf。 - 解析该
sk_buff对应的 IP 报头与 UDP 报头,获取源 IP 和源端口。 - 将这些地址信息填入
src_addr指向的地址结构体。 - 更新接收队列的长度与节点计数。
- 返回读取的字节数。
调用过程可简化为以下流程:
cpp
用户调用 recvfrom(fd, buf, len, flags, src_addr, addrlen)
↓
1. 通过 fd → file → socket → sock
↓
2. 从 sk_receive_queue 获取队首的 sk_buff
↓
3. 复制应用层数据到用户缓冲区 buf
↓
4. 从 IP/UDP 头部提取源地址与端口
↓
5. 填充到 src_addr 指向的结构体
↓
6. 返回读取的字节数close
最后一个要介绍的接口是 close 。该接口本质上属于文件操作系统调用,但在套接字上下文中,其作用不仅限于关闭文件描述符,还涉及释放套接字相关的内核资源。
我们知道,调用 socket 接口时,内核不仅会创建表示通信实体的内核结构(如 struct sock 和 struct socket ),还会在用户层关联一个 file 结构体。当通信结束时,必须及时释放这些套接字资源,这正是
close 接口的主要职责。
close 接口并非仅仅关闭文件描述符,它还会释放 struct socket 结构体及其相关资源,例如端口号。由于端口号是有限系统资源,释放套接字时会将其回收以供其他连接使用。具体而言,每个 file 结构体包含一个文件操作函数表(即一个函数指针数组),其中包含一个 close (或 release )函数指针。对于套接字,该指针指向与 socket 结构体关联的操作函数表中的关闭函数。
因此,调用 close 接口时,内核会执行以下操作:
- 减少文件的引用计数;
- 若引用计数降为0,则释放文件描述符;
- 调用内核中对应的释放函数,清理缓冲区、回收端口号;
- 最终释放
socket结构体。
其调用流程可概括如下:
cpp
用户态: close(fd)
↓
内核: sys_close(fd)
↓
fput() // 减少文件引用计数
↓
f_op->release() // 调用文件操作表的 release 方法
↓
sock_close() // socket 专用的 close 函数
↓
sock_release()
↓
sock->ops->release() // 协议族的 release 函数
---------------------------------------------------
内核释放操作主要包括:
1. 释放端口号
2. 清理接收与发送缓冲区队列
3. 释放 socket 结构体那么至此我已经介绍完了编写一个UDP的服务端进程以及客户端进程必要的接口,那么掌握了这些接口之后,那么我们便可以正式编写服务端进程以及客户端进程,那么这里我首先先来介绍一下服务端进程
UDP服务端(1)
udpserver.h
在具体编写代码之前,我们首先需要明确整体框架。对于服务端进程,第一步通常是创建一个套接字,即调用 socket 接口。若创建成功,则尝试将该套接字绑定到一个 IP 地址与端口号,这需要初始化 struct sockaddr_in结构体,并将其传递给 bind 接口。在 socket和 bind 都成功之后,服务端便可开始通信。
一般来说,服务端进程的通信逻辑应当设计为一个持续运行的循环。以网络游戏为例,无论凌晨或夜晚,玩家通常都能正常登录并运行游戏,这说明服务端应保持 24 小时持续运行,除非因更新等特定原因才会退出。因此,这里我们可以采用一个 while 循环来实现。
这里的通信逻辑设计得较为简单:在通信前,先准备一个缓冲区数组,然后调用 recvfrom接口接收客户端发来的数据包,并将消息打印到显示器上。若客户端退出,则服务端无需一直等待接收消息,此时应退出循环,并调用 close 接口清理资源。以下是服务端进程的基本框架示意:
cpp
socket
│
▼
bind
│
▼
while(1)通信
│
▼
close在上述基本流程的基础上,我们可以进一步进行结构化封装。尽管整个流程本身并不复杂,读者在理解后可能很快就能调用相关接口编写代码,但这里我们尝试以更优雅的方式实现------使用 C++ 并以面向对象的方式进行设计。
具体而言,可以将服务器抽象为一个对象,通过 udpserver 类来描述。服务器需要调用 socket 创建套接字,并调用 bind 绑定端口号与 IP 地址,因此该类的成员变量可包括套接字的文件描述符、IP 地址及端口号。
类的构造函数接收要绑定的 IP 地址和端口号,并用它们初始化对应的成员字段。此外,我们还可以设计一个
init 函数,其内部实现创建套接字并进行绑定,即调用 socket 和 bind 接口。该函数返回 bool 类型,若套接字创建和绑定成功,则返回 true 。
接下来,可以设计一个 run函数,其中包含通信的主体逻辑------即一个持续运行的 while 循环。为了更灵活地控制循环,可将循环条件与一个 bool 类型的成员变量关联。构造函数中将该变量初始化为 false ,而在 run 函数中将其设为 true 并进入循环。
最后,在析构函数中实现资源清理,即调用 close 接口。至此,我们便得到了一个面向对象方式封装的服务端进程框架。
cpp
class udpserver
{
public:
udpserver(std::string _ip, uint16_t _port)
: serverip(_ip)
, port(_port)
, socketfd(-1)
, isrunning(false)
{}
bool init()
{
// 创建 socket 并绑定
}
bool run()
{
// 通信循环
}
~udpserver()
{
if (socketfd >= 0)
{
close(socketfd);
}
}
private:
int socketfd;
std::string serverip;
uint16_t port;
bool isrunning;
};那么接下来,我们来具体来完善udpserver的具体细节,也就是各个模块:
init
那么,init 模块负责创建套接字并将其绑定到指定的IP地址和端口。因此,首先需要调用 socket 接口。由于我们使用IPv4协议和UDP类型的套接字,调用 socket 时,第一个参数应传递 AF_INET ,第二个参数传递 SOCK_DGRAM ,第三个参数设为 0 即可。
调用 socket 后,必须检查其返回值。如果返回 -1 ,表示创建失败,服务器进程无法继续后续工作,此时应返回 false 。这里我引入了日志机制来记录运行信息。如果 socket 调用失败,会输出错误信息;默认输出到显示器,但也可配置为输出到文件。在返回 false 之前,会先记录日志。一旦 init 返回 false ,程序将立即退出,并返回一个非零的退出码。我将退出码设计为枚举变量,其中定义了多个枚举常量来对应不同错误情况,它们的值均为非零。
如果套接字创建成功,则向显示器打印一条创建成功的日志信息。接着,需要调用 bind 来绑定IP地址和端口号。在调用 bind 之前,需初始化 struct sockaddr_in 结构体,以指定要绑定的地址信息。
struct sockaddr_in 的第一个字段应设置为 AF_INET ,表示我们使用的是IPv4地址族对应的结构体。接下来设置端口号。端口号占16位,而 sockaddr_in 中端口号字段的数据类型是 uint16_t 。
这里需要注意一个关键点:字节序(大小端)问题。下面为不熟悉此概念的读者简要解释。
字节序指的是数据在内存中存储的字节顺序。数据在内存中以字节为单位存储,每个字节都有一个地址,数据从低地址到高地址排列。对于 int 、 long 等多字节整型数据,它们会连续占用多个地址。由于整型数据中不同字节具有不同的权重(高位字节权重高,低位字节权重低),因此存在两种存储方式:一种是将权重较高的字节放在高地址,权重较低的字节放在低地址(大端序);另一种则相反,将权重较低的字节放在低地址,权重较高的字节放在高地址(小端序)。
例如,对于一个32位整数 0x12345678 (十六进制),其存储方式如下:
cpp
字节序 地址+0 地址+1 地址+2 地址+3
大端 0x12 0x34 0x56 0x78
小端 0x78 0x56 0x34 0x12需要注意的是,字节序仅规定了多字节数据在内存中的存储顺序,大端序和小端序本身并无效率优劣之分。一台主机可以采用其中任一种字节序。
当数据包从一台设备发送到另一台设备时,由于不同设备可能采用不同的字节序,如果一台大端主机接收到来自小端主机的数据包,并直接将其按大端序解析,就会因字节序相反而导致错误。
为此,网络传输中做了统一规定:任何要发送到网络的数据包,无论主机原本采用大端序还是小端序,都必须先转换为大端序再发送。因此,大端序也被称为网络字节序。
内核提供了 <arpa/inet.h> 头文件,其中包含用于主机字节序与网络字节序之间转换的函数:
cpp
// 主机字节序 → 网络字节序
uint16_t htons(uint16_t hostshort);
// 参数:hostshort 是主机字节序的16位整数
// 返回值:转换后的网络字节序(大端序)整数
// 网络字节序 → 主机字节序
uint16_t ntohs(uint16_t netshort);
// 参数:netshort 是网络字节序(大端序)的16位整数
// 返回值:转换后的主机字节序整数因此,在将端口号赋值给 struct sockaddr_in 的对应字段之前,应先调用 htons 函数将其转换为网络字节序。
另一点需要注意的是IP地址的转换。我们通常以点分十进制字符串的形式表示IP地址(例如"192.168.1.100" ),这符合人类的阅读和书写习惯,因此代码中IP地址的类型设为 string 。然而,数据报IP头中的源地址和目的地址都是32位整数。因此,我们需要将点分十进制字符串转换为32位整型,并且同样要转换为网络字节序。
虽然可以手动实现转换函数,但内核已在 <arpa/inet.h> 中提供了相关函数,能够同时完成字符串到整型的转换以及主机字节序到网络字节序的转换:
cpp
in_addr_t inet_addr(const char *cp);
// 功能:将点分十进制字符串转换为32位网络字节序整数
// 返回:网络字节序的IP地址
// 注意:该函数已过时,不推荐使用
//不能表示255.255.255.255(与INADDR_NONE冲突)
//不返回错误码,错误时返回INADDR_NONE(-1)
int inet_aton(const char *cp, struct in_addr *inp);
// 功能:将字符串转换为网络字节序二进制IP,并存入inp指向的结构
// 返回:成功返回1,失败返回0
// 推荐使用此函数替代inet_addr()
char *inet_ntoa(struct in_addr in);
// 功能:将网络字节序二进制IP转换为字符串
// 返回:指向静态缓冲区的指针
// 注意:该函数不可重入,线程不安全因此,我们可以调用 inet_addr 或更推荐的 inet_aton 函数,将字符串形式的IP地址转换为网络字节序的32位整型地址。
完成以上步骤后,即可正确初始化 struct sockaddr_in 结构体。接着调用 bind 接口,将初始化后的结构体地址传入(注意需强制类型转换为 struct sockaddr* )。之后判断 bind 的返回值:若成功,则继续后续流程;若失败,则记录日志并返回 false 。注意,由于此时套接字已成功创建,在返回 false 之前,必须释放套接字资源,即调用 close 接口,并将 socketfd 设为无效值 -1 。
如果 bind 成功,则 init 工作完成,日志会输出绑定成功的信息,并返回 true 。一旦 init 成功,便可调用后续的 run 方法,开始进行通信。
cpp
#pragma once
#include<iostream>
#include<string>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include"log.hpp"
log log;
enum
{
Socket_Error=1,
Bind_Error,
};
class udpserver
{
public:
udpserver(std::string _ip , uint16_t _port)
:serverip(_ip)
, port(_port)
, socketfd(-1)
,isrunning(false)
{
}
bool init()
{
socketfd = socket(AF_INET,SOCK_DGRAM,0);
if (socketfd < 0)
{
log.logmessage(Fatal, "socket error");
return false;
}
log.logmessage(info, "create socket successfully");
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(port);
server.sin_addr.s_addr = inet_addr(serverip.c_str());
if (bind(socketfd, (struct sockaddr*)&server, sizeof(server)) < 0)
{
log.logmessage(Fatal,"blind error");
close(socketfd);
socketfd=-1;
return false;
}
log.logmessage(info,"bind successfully");
return true;
}
//....
~udpserver()
{
if (socketfd > 0)
{
close(socketfd);
}
}
private:
int socketfd;
std::string serverip;
uint16_t port;
bool isrunning;
};run
接下来是 run方法的实现。在该方法中,首先判断 socketfd 是否有效。若有效,则将布尔类型的
isrunning 变量设为 true 。进入 while 循环之前,需要完成两项准备工作:
- 准备一个输入缓冲区,用于保存客户端发来的数据包。
- 由于服务器需要知道消息来自哪一个客户端(以便将处理后的数据返回给对应客户端),因此必须获取该客户端的 IP 地址与端口号。上文介绍
recvfrom接口时提到,其最后两个参数为输出型参数。为此,这里需要定义一个struct sockaddr_in结构体,并将其所有字段初始化为 0。该结构体将用于保存客户端的 IP 地址和端口号。
完成上述准备工作后,即可进入 while 循环,开始通信。
循环内部首先调用 recvfrom 接口,传入缓冲区以及之前定义的 struct sockaddr_in 结构体的地址(注意需强制类型转换为 struct sockaddr* )。接着检查 recvfrom 的返回值。此处我们将选项字段设为 0,即采用阻塞等待模式。若 socket 接收队列为空,程序将阻塞,直到队列非空时被唤醒。此时,系统会弹出队首节点,并将其数据区中的应用层数据拷贝到输入缓冲区。
需检查 recvfrom 的返回值:若返回值为 -1 ,则表示接收异常,无法继续进行后续收发工作,此时打印日志信息并退出循环。若返回值非 -1 ,则继续执行。服务端的通信逻辑通常是一个死循环,但若客户端不再发送任何请求,服务端也应当具备退出的机制。在本实现中,客户端会向服务端发送一个字符串,若该字符串内容为 "quit" ,则服务端退出循环。需要注意的是,这种设计在实际多客户端场景中并不合理------因为一个客户端断开不应导致服务端停止对其他客户端的服务。此处由于服务端只为一个客户端服务,因此做此设计。实际生产中需支持多客户端并发处理。
接着,通过 strcmp 函数比较字符串内容。若为 "quit" ,则服务端退出;否则继续后续流程。为便于观察通信过程,服务端会将收到的数据包打印到显示器,包括客户端的 IP地址 、 端口号以及发送的消息。之后进入数据处理环节。
数据处理部分采用了模块化设计,不将具体逻辑直接嵌入循环中,而是封装为一个独立函数。该函数返回类型为 std::string ,参数也为 std::string ,因为本例中约定客户端与服务端之间传输的数据均为字符串类型。接下来,将定义一个包装器(callable wrapper),用于接收返回值类型为 std::string 、参数为
std::string 的可调用对象。具体可调用对象的实现位于 udpserver.cpp 中。该文件会引入 udoserver.h ,因此我们需进一步完善 udpserver 类:将包装器作为成员变量,并在构造函数中增加对应参数。这样, udpserver.cpp 可以定义任意处理逻辑的可调用对象,并将其传递给 udpserver 对象的构造函数,使得 run 方法能够执行特定的处理逻辑。处理后的结果(字符串)将通过 sendto 发送回对应客户端。最后检查 sendto 的返回值,若为 -1 则表示发送失败,打印日志信息并退出。
cpp
#pragma once
#include<iostream>
#include<vector>
#include<string>
#include<cstring>
#include <sys/socket.h>
#include<functional>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include"log.hpp"
#define buffer_size 1024
log log;
typedef std::function<std::string(std::string order)> func_t;
enum
{
Socket_Error=1,
Bind_Error,
Recv_Error,
Send_Error,
};
class udpserver
{
public:
udpserver(std::string _ip , uint16_t _port,func_t _func)
:serverip(_ip)
, port(_port)
, socketfd(-1)
,isrunning(false)
,func(_func)
{
}
bool init()
{
//........
}
bool run()
{
if(socketfd<0)
{
log.logmessage(Fatal,"socket not create");
return false;
}
isrunning = true;
char buffer[buffer_size];
struct sockaddr_in client;
memset(&client, 0, sizeof(client));
socklen_t clientlen=sizeof(client);
std::cout<<"udp server is running...."<<std::endl;
while (isrunning)
{
int n=recvfrom(socketfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&client, &clientlen);
if (n < 0)
{
log.logmessage(Fatal, "rec error");
exit(Recv_Error);
}
buffer[n]='\0';
if(strcmp(buffer,"quit")==0)
{
log.logmessage(info,"server quit");
break;
}
char clientip[64];
inet_ntop(AF_INET,&client.sin_addr,clientip,sizeof(clientip));
uint16_t clientport=ntohs(client.sin_port);
log.logmessage(info,"recieve from %s:%d : %s",clientip,clientport,buffer);
std::string result=func(buffer);
n=sendto(socketfd,result.c_str(),result.size(),0,(struct sockaddr*)&client,clientlen);
if(n<0)
{
log.logmessage(Fatal,"send error");
exit(Send_Error);
}
}
return true;
}
~udpserver()
{
if (socketfd > 0)
{
close(socketfd);
}
}
private:
int socketfd;
std::string serverip;
uint16_t port;
bool isrunning;
func_t func;
};udpserver.cpp
基于上文已实现的 udpserver 类,接下来将完成 udpserver.cpp 的实现。该源文件需包含 udpserver.h 头文件。程序首先需要获取网络接口的IP地址与指定的端口号。由于程序运行于Linux环境,我们将通过命令行方式启动,因此IP与端口号应通过命令行参数传递给UDP服务器进程。程序随后解析这些参数,并创建套接字绑定至对应的IP地址和端口。
需要注意的是,一台主机可能配备多个网络接口(即网卡),数据包可能发往不同的接口。因此,可将服务端绑定的IP地址设为 0.0.0.0 。这是一个特殊地址,表示监听所有可用网络接口。因此,在实际使用时只需通过命令行指定端口号(例如 x ),服务器套接字即可接收发送到该端口的所有数据包,无论来自哪个网络接口。
udpserver.cpp 的第一步是获取命令行参数。命令行参数以字符串形式传递,因此程序需检查参数个数。由于我们将服务端IP固定为 0.0.0.0 ,只需指定一个端口号参数,因此包括程序名在内,参数总数应为2。若参数数量不正确,程序应输出错误信息并返回非零退出码。
cpp
#include "udpserver.h"
void usage(const char* program_name)
{
std::cout << "usage: " << program_name << " port" << std::endl;
}
int main(int argc, char* argv[])
{
if (argc != 2)
{
usage(argv[0]);
exit(UsageWrong);
}
uint16_t port = std::stoi(argv[1]);
UdpServer server(_default, port, echo);//_default为"0.0.0.0",在udpserver.h中定义
//.....................
return 0;
}
若参数正确,则解析端口号并将其转换为网络字节序(通过 htons() 函数)。接着定义请求处理函数。我们约定客户端发送的数据为Linux shell命令。服务器收到数据包(即待执行命令)后,首先检查命令内容。为防止客户端恶意执行危险操作(如 rm 命令随意删除文件),我们可在 check_order() 函数中定义禁止执行的命令清单并进行比对。该函数返回布尔值,若为 true ,则允许执行该命令。
命令执行可通过创建子进程并调用进程替换接口来完成。这里我们也可直接使用 popen() 接口,其内部会创建子进程与管道。通过指定模式参数,可控制管道的读写关系:例如使用模式 "r" 时,父进程以只读方式获取管道,子进程的标准输出被重定向至管道写端;而 "w" 模式会创建管道和子进程,并将子进程的标准输入重定向到管道的读端。父进程获得一个指向管道写端的文件流指针,随后可通过 "fwrite" 等函数将命令或数据写入该管道。子进程则从管道读端读取输入,执行相应命令,并将结果输出到标准输出(例如显示器)。
popen() 成功时返回 FILE* 类型的管道文件指针。
popen- 头文件:<stdio.h>
- 函数声明:FILE *popen(const char *command, const char *mode);
- 返回值:成功时返回指向
FILE,失败时返回NULL(并设置errno)。
在本实现中,我们将采用 "r" 模式,即将命令传递给子进程执行,并将其输出通过管道返回给父进程。随后检查 popen() 返回值,若非 NULL ,则使用 fread() 读取管道内容(即命令执行结果),将其转换为字符串并返回。
这里我还定义了另一个简单的请求处理函数 echo 。该函数将接收到的客户端数据包内容添加服务器端标识信息后返回。具体实现时,通过 std::string 的拼接操作,在原始消息前附加服务器说明字符串(如 "server echo") ,并返回结果。
处理函数定义完成后, main() 函数将创建 udpserver 对象,依次调用 init() 和 run() 方法。若其中任一调用返回 false ,则程序返回非零退出码以示错误。
cpp
#include "udpserver.h"
void usage(const char* program_name)
{
std::cout << "usage: " << program_name << " port" << std::endl;
}
std::string echo(std::string message)
{
std::string echo_message = "server echo: " + message;
return echo_message;
}
bool check_order(const std::string& _order)
{
std::vector<std::string> unvalid_orders = {"rm", "shutdown", "kill"};
size_t pos = _order.find(" ");
std::string token = _order.substr(0, pos);
for (auto& order : unvalid_orders)
{
if (token == order)
{
return false;
}
}
return true;
}
std::string handler_function(std::string order)
{
if (check_order(order))
{
FILE* fd = popen(order.c_str(), "r");
if (fd == nullptr)
{
log.logmessage(Fatal, "popen error");
exit(Popen_Error);
}
char buffer[buffer_size];
fread(buffer, 1, sizeof(buffer), fd);
pclose(fd);
return buffer;
}
log.logmessage(Warning, "unvalid order: %s", order.c_str());
return "";
}
int main(int argc, char* argv[])
{
if (argc != 2)
{
usage(argv[0]);
exit(UsageWrong);
}
uint16_t port = std::stoi(argv[1]);
UdpServer server(_default, port, echo);
if (server.init())
{
if (!server.run())
{
exit(Recv_Error);
}
}
else
{
exit(Socket_Error);
}
return 0;
}UDP服务端源码(1)
log.hpp:
cpp
#include<iostream>
#include<string>
#include<time.h>
#include<stdarg.h>
#include<fcntl.h>
#define SIZE 1024
#define screen 0
#define File 1
#define ClassFile 2
enum
{
info,
debug,
warning,
Fatal,
};
class log
{
private:
std::string memssage;
int method;
public:
log(int _method = screen)
:method(_method)
{
}
void logmessage(int leval, char* format, ...)
{
char* _leval;
switch (leval)
{
case info:
_leval = "info";
break;
case debug:
_leval = "debug";
break;
case warning:
_leval = "warning";
break;
case Fatal:
_leval = "Fatal";
break;
}
char timebuffer[SIZE];
time_t t = time(NULL);
struct tm* localTime = localtime(&t);
snprintf(timebuffer, SIZE, "[%d-%d-%d-%d:%d]", localTime->tm_year + 1900, localTime->tm_mon + 1, localTime->tm_mday, localTime->tm_hour, localTime->tm_min);
char rightbuffer[SIZE];
va_list arg;
va_start(arg, format);
vsnprintf(rightbuffer, SIZE, format, arg);
char finalbuffer[2 * SIZE];
snprintf(finalbuffer, sizeof(finalbuffer), "[%s]%s:%s", _leval, timebuffer, rightbuffer);
int fd;
switch (method)
{
case screen:
std::cout << finalbuffer << std::endl;
break;
case File:
fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd >= 0)
{
write(fd, finalbuffer, sizeof(finalbuffer));
close(fd);
}
break;
case ClassFile:
switch (leval)
{
case info:
fd = open("log/info.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
write(fd, finalbuffer, sizeof(finalbuffer));
break;
case debug:
fd = open("log/debug.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
write(fd, finalbuffer, sizeof(finalbuffer));
break;
case warning:
fd = open("log/Warning.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
write(fd, finalbuffer, sizeof(finalbuffer));
break;
case Fatal:
fd = open("log/Fat.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
break;
}
if (fd > 0)
{
write(fd, finalbuffer, sizeof(finalbuffer));
close(fd);
}
}
}
};udpserver.h:
cpp
#pragma once
#include<iostream>
#include<vector>
#include<string>
#include<cstring>
#include <sys/socket.h>
#include<functional>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include"log.hpp"
#define buffer_size 1024
log log;
std::string _default="0.0.0.0";
typedef std::function<std::string(std::string order)> func_t;
enum
{
Usagewrong = 1,
Socket_Error,
Bind_Error,
Recv_Error,
Send_Error,
Popen_Error,
Wait_Error,
};
class udpserver
{
public:
// 构造函数:初始化UDP服务器
udpserver(std::string _ip , uint16_t _port,func_t _func)
// 初始化成员变量
:serverip(_ip) // 设置服务器IP地址
, port(_port) // 设置服务器端口号
, socketfd(-1) // 初始化socket文件描述符为-1,表示未初始化
,isrunning(false) // 初始化运行状态为false,表示服务器未启动
,func(_func) // 设置回调函数,用于后续处理接收到的数据
{
// 构造函数体为空,所有初始化工作都在初始化列表中完成
}
/* 初始化UDP套接字并进行绑定*/
bool init()
{
// 创建UDP套接字
socketfd = socket(AF_INET,SOCK_DGRAM,0);
if (socketfd < 0)
{
// 记录套接字创建失败的错误日志
log.logmessage(Fatal, "socket error");
return false;
}
// 记录套接字创建成功的日志
log.logmessage(info, "create socket successfully");
// 初始化服务器地址结构体
struct sockaddr_in server;
memset(&server, 0, sizeof(server)); // 将结构体清零
// 设置地址族为IPv4
server.sin_family = AF_INET;
// 设置端口号,htons将主机字节序转换为网络字节序
server.sin_port = htons(port);
// 设置IP地址,inet_addr将点分十进制IP转换为网络字节序
server.sin_addr.s_addr = inet_addr(serverip.c_str());
// 绑定套接字到指定地址和端口
if (bind(socketfd, (struct sockaddr*)&server, sizeof(server)) < 0)
{
log.logmessage(Fatal,"blind error");
close(socketfd);
socketfd=-1;
return false;
}
log.logmessage(info,"bind successfully");
return true;
}
/*运行UDP服务器,接收和处理客户端数据*/
bool run()
{
// 检查socket是否有效
if(socketfd<0)
{
// 记录致命错误日志:socket未创建
log.logmessage(Fatal,"socket not create");
return false;
}
// 设置服务器运行状态为true
isrunning = true;
// 定义接收数据的缓冲区
char buffer[buffer_size];
// 定义客户端地址结构体并初始化
struct sockaddr_in client;
memset(&client, 0, sizeof(client));
// 设置客户端地址长度
socklen_t clientlen=sizeof(client);
// 输出服务器运行提示信息
std::cout<<"udp server is running...."<<std::endl;
// 主循环:服务器运行状态下持续接收数据
while (isrunning)
{
// 从socket接收数据
int n=recvfrom(socketfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&client, &clientlen);
// 接收数据错误处理
if (n < 0)
{
// 记录致命错误日志:接收错误
log.logmessage(Fatal, "rec error");
exit(Recv_Error);
}
// 确保字符串正确终止
buffer[n]='\0';
// 检查是否收到退出命令
if(strcmp(buffer,"quit")==0)
{
// 记录信息日志:服务器退出
log.logmessage(info,"server quit");
break;
}
// 获取客户端IP地址
char clientip[64];
inet_ntop(AF_INET,&client.sin_addr,clientip,sizeof(clientip));
// 获取客户端端口号(从网络字节序转换为主机字节序)
uint16_t clientport=ntohs(client.sin_port);
// 记录接收到的数据信息
log.logmessage(info,"recieve from %s:%d : %s",clientip,clientport,buffer);
// 处理接收到的数据
std::string result=func(buffer);
// 将处理结果发送回客户端
n=sendto(socketfd,result.c_str(),result.size(),0,(struct sockaddr*)&client,clientlen);
// 发送数据错误处理
if(n<0)
{
// 记录致命错误日志:发送错误
log.logmessage(Fatal,"send error");
exit(Send_Error);
}
}
// 返回成功
return true;
}
// 析构函数:用于释放UDP服务器对象占用的资源
~udpserver()
{
// 检查套接字描述符是否有效(大于0表示有效)
if (socketfd > 0)
{
// 关闭套接字,释放系统资源
close(socketfd);
}
}
private:
int socketfd;
std::string serverip;
uint16_t port;
bool isrunning;
func_t func;
};udpserver.cpp:
cpp
#include"udpserver.h"
void usage(const char* program_name)
{
std::cout<<"usage:"<<program_name<<" port"<<std::endl;
}
std::string echo(std::string message)
{
std::string echo_message="server echo:"+message;
return echo_message;
}
/* 检查输入的命令是否有效*/
bool check_order(const std::string& _order)
{
// 定义无效命令列表
std::vector<std::string> unvalid_orders={"rm","shutdown","kill"};
// 查找命令中的空格位置
size_t pos=_order.find(" ");
// 获取命令部分(空格前的字符串)
std::string token=_order.substr(0,pos);
// 遍历无效命令列表进行检查
for(auto& order:unvalid_orders)
{
// 如果匹配到无效命令,返回false
if(token==order)
{
return false;
}
}
// 如果命令有效,返回true
return true;
}
/*执行系统命令并返回命令执行结果的函数
*/
std::string handler_function(std::string order)
{
// 检查命令是否有效
if(check_order(order))
{
// 使用popen执行命令并读取输出
FILE* fd=popen(order.c_str(),"r");
// 检查popen是否成功执行
if(fd==nullptr)
{
// 记录致命错误日志
log.logmessage(Fatal, "popen error");
// 返回popen错误码
exit(Popen_Error);
}
// 定义缓冲区大小
char buffer[buffer_size];
// 从文件流中读取数据到缓冲区
fread(buffer, 1, sizeof(buffer), fd);
// 关闭文件流
pclose(fd);
// 返回读取到的内容
return buffer;
}
// 记录警告日志,命令无效
log.logmessage(warning,"unvalid order:%s",order.c_str());
// 返回空字符串
return "";
}
int main(int argc, char* argv[])
{
// 检查命令行参数数量是否正确
// 程序需要且仅需要一个参数(端口号)
if (argc != 2)
{
// 如果参数数量不正确,显示程序使用方法
usage(argv[0]);
// 以错误状态码退出程序
exit(Usagewrong);
}
// 将命令行参数中的端口号字符串转换为16位无符号整数
uint16_t port = std::stoi(argv[1]);
// 创建UDP服务器实例
// 参数说明:
// _default - 默认配置
// port - 监听端口
// echo - 回调函数,用于处理接收到的数据
udpserver server(_default, port, echo);
// 初始化服务器
if (server.init())
{
// 如果初始化成功,启动服务器运行
if(!server.run())
{
// 如果服务器运行失败,以接收错误状态码退出
exit(Recv_Error);
}
}
else
{
// 如果服务器初始化失败,以套接字错误状态码退出
exit(Socket_Error);
}
// 程序正常结束
return 0;
}UDP客户端
对于客户端进程,其核心功能是向服务端进程发送请求,因此客户端需要获取服务端的IP地址与端口号。通常的实现会将IP地址和端口号固化在程序中,但考虑到程序运行于Linux环境,进程通常通过命令行启动,并可通过命令行参数传递配置信息。因此,我们可以将服务端的IP地址和端口号通过命令行参数传递给客户端进程。
命令行输入本质是一个字符串,命令行解释器会以空格为分隔符,将其拆分为指令部分与参数部分,并保存到字符数组中传递给进程。因此,客户端进程的第一个步骤就是解析该字符数组。在解析之前,需先判断命令行参数的个数。此处参数包括 IP 地址和端口号,因此参数数量应为 3(程序名本身也算一个)。若参数数量不为 3,则应打印使用说明并退出;若为 3,则提取 IP 地址和端口号,并调用 std::stoi 将端口号从字符串转换为整型。
cpp
#include <iostream>
#include <cstring>
#include <arpa/inet.h>
#include <string>
#include <sys/socket.h>
#include <unistd.h>
#include <netinet/in.h>
#include "log.hpp"
#define BUFFER_SIZE 1024
Log logger; // 日志对象
enum {
UsageWrong = 1,
SocketError,
SendError,
RecvError
};
void usage(const char* program_name) {
std::cout << "Usage: " << program_name << " <server_ip> <port>" << std::endl;
}
int main(int argc, char* argv[]) {
if (argc != 3) {
usage(argv[0]);
exit(UsageWrong);
}
std::string serverIp = argv[1];
uint16_t port = std::stoi(argv[2]);
// ...
return 0;
}接下来是创建套接字,即调用 socket 系统调用。需检查其返回值:若返回 -1,则无法继续执行,应记录错误日志并退出;若创建成功,则记录日志表明套接字已就绪,可进入通信阶段。
在进入主循环之前,还需定义一个 struct sockaddr_in 结构体并初始化,将之前获取的 IP 地址和端口号填入对应字段。需注意将端口号转换为网络字节序(调用 htons ),IP 地址也需调用 inet_addr 进行转换。此外,应准备好用于存储用户输入的缓冲区。
完成结构体与缓冲区的初始化后,即可进入通信循环。这里使用 std::cin.getline() 从标准输入读取一行内容(以换行符结束)到缓冲区。 getline 会跳过前导换行符,且不会将换行符存入缓冲区。接着,我们将缓冲区数据的地址和长度传给 sendto 函数,并将之前初始化的 struct sockaddr_in 结构体作为目标地址传入,指明数据发往的服务端地址。
客户端发送的数据来自用户键盘输入,且客户端与服务端约定通信内容为字符串。用户可能仅输入回车而不提供任何内容,此时缓冲区为空。因此在调用 sendto 前,应先检查缓冲区中字符串的长度:若长度为 0,则直接跳过本次循环;若非 0,则调用 sendto 发送。
调用 sendto 后,需检查其返回值。若返回 -1,说明发送失败,此时应记录错误日志,关闭套接字并退出。另外,若客户端希望主动结束通信,可输入 " quit" 字符串。因此,在发送后可通过 strcmp 判断缓冲区内容是否为 " quit ",若是,则退出循环。
若非退出指令,则表示客户端向服务端发送了一条有效数据(例如 Linux 命令)。随后,客户端调用 revfrom 等待服务端的响应,传入输出缓冲区与地址结构体。若 recvfrom 返回 -1,说明接收失败,应记录错误日志、清理套接字资源并退出。最后,将接收到的数据打印输出,并继续循环。以上即为客户端实现的所有关键细节。
cpp
while (1)
{
std::cout<<"please input message to send:"<<std::endl;
std::cin.getline(buffer,buffer_size);
size_t len=strlen(buffer);
if(len==0)
{
continue;
}
int n=sendto(socketfd, buffer, len, 0, (struct sockaddr*)&server, serverlen);
if (n < 0)
{
log.logmessage(Fatal, "Send error");
close(socketfd);
exit(Send_Error);
}
if (strcmp(buffer,"quit")==0)
{
log.logmessage(info,"client quit");
break;
}
n=recvfrom(socketfd,buffer,sizeof(buffer),0,(struct sockaddr*)&server,&serverlen);
if(n<0)
{
log.logmessage(Fatal,"recv error");
close(socketfd);
exit(Recv_Error);
}
buffer[n]='\0';
std::cout<<"server response: "<<buffer<<std::endl;
}而这里我们需要知道要查看本主机的网络接口的相关信息,比如IP地址,那么这里我们可以通过在命令行输入ifcongfig来查看,其会列出所有网络接口的详细信息,包括IP地址以及子网掩码等等,那么这里我们就可以看到我这台主机有一个物理网络结论,其IP地址是10.2.24.4,那么这里我们就让服务端绑定到该ip地址,并且提供一个端口号
UDP客户端源码(1)
client.cpp:
cpp
#include<iostream>
#include<cstring>
#include <arpa/inet.h>
#include<string>
#include<sys/socket.h>
#include<unistd.h>
#include<netinet/in.h>
#include"log.hpp"
#define buffer_size 1024
log log;
enum
{
Usagewrong = 1,
Socket_Error,
Send_Error,
Recv_Error,
};
void usage(const char* program_name)
{
std::cout<<"usage: "<<program_name<<" <server_ip> <port>"<<std::endl;
}
int main(int argc, char* argv[])
{
// 检查命令行参数数量,需要3个参数:程序名、服务器IP、端口号
if (argc != 3)
{
usage(argv[0]); // 打印使用说明
exit(Usagewrong); // 退出程序
}
// 从命令行参数获取服务器IP和端口号
std::string serverip = argv[1];
uint16_t port = std::stoi(argv[2]); // 将字符串转换为整数
// 创建UDP套接字
int socketfd = socket(AF_INET, SOCK_DGRAM, 0);
if (socketfd < 0)
{
log.logmessage(Fatal, "socket error"); // 记录错误日志
exit(Socket_Error); // 退出程序
}
// 设置服务器地址结构
struct sockaddr_in server;
memset(&server, 0, sizeof(server)); // 清零结构体
server.sin_family = AF_INET; // IPv4协议
server.sin_port = htons(port); // 端口号转换为网络字节序
server.sin_addr.s_addr = inet_addr(serverip.c_str()); // IP地址转换
socklen_t serverlen = sizeof(server); // 地址结构长度
// 缓冲区用于存储发送和接收的数据
char buffer[buffer_size];
// 主循环:持续发送和接收消息
while (1)
{
// 提示用户输入消息
std::cout << "please input message to send:" << std::endl;
std::cin.getline(buffer, buffer_size); // 获取用户输入
size_t len = strlen(buffer);
// 如果输入为空,继续等待输入
if (len == 0)
{
continue;
}
// 发送消息到服务器
int n = sendto(socketfd, buffer, len, 0, (struct sockaddr*)&server, serverlen);
if (n < 0)
{
log.logmessage(Fatal, "Send error"); // 记录错误日志
close(socketfd); // 关闭套接字
exit(Send_Error); // 退出程序
}
// 检查是否要退出
if (strcmp(buffer, "quit") == 0)
{
log.logmessage(info, "client quit"); // 记录退出日志
break; // 跳出循环
}
// 接收服务器响应
n = recvfrom(socketfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&server, &serverlen);
if (n < 0)
{
log.logmessage(Fatal, "recv error"); // 记录错误日志
close(socketfd); // 关闭套接字
exit(Recv_Error); // 退出程序
}
// 处理接收到的数据
buffer[n] = '\0'; // 添加字符串结束符
std::cout << "server response: " << buffer << std::endl; // 打印服务器响应
}
// 关闭套接字
close(socketfd);
return 0;
}运行截图:
UDP服务端(2)
我们知道,UDP 协议的特点之一是不可靠传输,这意味着在检测到数据差错时,UDP 会直接丢弃数据包,而不提供重传机制。UDP 的另一重要特性是其通信不是点对点(连接导向)的,即一个 UDP 套接字可以与任意数量的客户端套接字通信。在上文的场景中,我们尚未利用这一特性,因此接下来我们将基于 UDP 的通信特点,实现一个广播服务器。
我们只需在原有服务端程序的基础上进行修改,整体架构保持不变。首先创建一个服务器对象,并调用其
init 方法。该方法会创建套接字并绑定 IP 地址和端口号。 init 方法执行成功后,再调用 run 方法启动通信过程。
run 方法的核心仍是循环结构。在循环开始前,我们先准备一个接收缓冲区,并定义一个 struct sockaddr_in结构体作为输出参数,用于获取发送数据包的客户端地址与端口信息。此外,这里还将使用一个哈希表,用于记录曾经向本服务器发送过消息的客户端信息。哈希表的键(key)设为 string 类型,由 IP 地址和端口拼接而成;值(value)则对应客户端的 struct sockaddr_in 结构体。
为此,我们实现一个 add_client方法,用于将接收到的客户端信息插入哈希表中。该方法首先根据 IP 和端口生成键值,接着检查该键是否已存在于哈希表中。若不存在,则将客户端的地址结构体插入哈希表。
cpp
void add_client(struct sockaddr_in& addr)
{
std::string ip = inet_ntoa(addr.sin_addr);
uint16_t port = ntohs(addr.sin_port);
std::string key = ip + " : " + std::to_string(port);
if (clientmap.find(key) == clientmap.end())
{
clientmap[key] = addr;
log.logmessage(info, "new client added: %s", key.c_str());
}
}在 while 循环中,首先调用 revfrom 接口接收客户端发来的数据包,接着调用 add_client 方法将客户端加入哈希表。随后对数据进行处理:如果客户端希望结束通信,则会发送字符串 "quit" 。服务器一旦识别到该字符串,便会根据其 IP 和端口从哈希表中移除该客户端。需要注意的是,这里的设计基于一个前提:与服务端通信的客户端数量是事先固定的。若哈希表为空,说明所有客户端均已退出,此时服务端结束循环。
但在实际场景中,服务端应能持续接收任意数量客户端的请求。因此更合理的逻辑是:仅将发送 "quit" 的客户端移出哈希表,之后继续处理其他请求,并允许新客户端加入。
若接收到的字符串不是 "quit" ,则说明其为有效数据。接下来调用预先传入的可调用对象(包装器)对数据进行处理,其返回值为 string 类型(双方事先约定数据格式为字符串)。之后,将处理结果通过 broadcast 函数广播给哈希表中记录的所有客户端。
broadcast 函数遍历哈希表,对其中每一个客户端调用 sendto 接口发送处理后的消息。
cpp
void broadcast_message(const std::string& message)
{
for (auto& client : clientmap)
{
int n = sendto(socketfd, message.c_str(), message.size(), 0,
(struct sockaddr*)&client.second, sizeof(client.second));
if (n < 0)
{
log.logmessage(Fatal, "send error to %s", client.first.c_str());
exit(Send_Error);
}
log.logmessage(info, "send message to %s: %s", client.first.c_str(), message.c_str());
}
}UDP服务端源码(2)
udpserver.h:
cpp
#pragma once
#include<iostream>
#include<vector>
#include<string>
#include<cstring>
#include <sys/socket.h>
#include<functional>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include<unordered_map>
#include"log.hpp"
#define buffer_size 1024
log log;
std::string _default="0.0.0.0";
typedef std::function<std::string(std::string order)> func_t;
enum
{
Usagewrong = 1,
Socket_Error,
Bind_Error,
Recv_Error,
Send_Error,
Popen_Error,
Wait_Error,
};
class udpserver
{
public:
udpserver(std::string _ip , uint16_t _port,func_t _func)
:serverip(_ip)
, port(_port)
, socketfd(-1)
,isrunning(false)
,func(_func)
{
}
/**初始化UDP套接字并绑定到指定端口和IP地址*/
bool init()
{
// 创建UDP套接字
socketfd = socket(AF_INET,SOCK_DGRAM,0);
if (socketfd < 0)
{
// 记录错误日志并返回失败
log.logmessage(Fatal, "socket error");
return false;
}
// 记录成功创建套接字的日志
log.logmessage(info, "create socket successfully");
// 初始化服务器地址结构体
struct sockaddr_in server;
memset(&server, 0, sizeof(server)); // 清零结构体
server.sin_family = AF_INET; // 设置地址族为IPv4
server.sin_port = htons(port); // 设置端口号,htons将主机字节序转换为网络字节序
server.sin_addr.s_addr = inet_addr(serverip.c_str()); // 设置IP地址
// 绑定套接字到指定地址和端口
if (bind(socketfd, (struct sockaddr*)&server, sizeof(server)) < 0)
{
// 记录绑定错误日志
log.logmessage(Fatal,"blind error");
// 关闭套接字并重置文件描述符
close(socketfd);
socketfd=-1;
return false;
}
// 记录绑定成功的日志
log.logmessage(info,"bind successfully");
// 返回初始化成功
return true;
}
/**
* 添加客户端函数
* 该函数用于将新的客户端地址信息添加到客户端映射表中
*/
void add_client(struct sockaddr_in& addr)
{
// 将IPv4地址转换为字符串格式
std::string ip=inet_ntoa(addr.sin_addr);
// 将网络字节序的端口号转换为主机字节序
uint16_t port=ntohs(addr.sin_port);
// 创建客户端的唯一标识符,由IP地址和端口号组成
std::string key=ip+" : "+std::to_string(port);
// 检查客户端是否已存在于映射表中
if(clientmap.find(key)==clientmap.end())
{
// 如果客户端不存在,则将其添加到映射表中
clientmap[key]=addr;
// 记录新客户端添加的日志信息
log.logmessage(info,"new client added:%s",key.c_str());
}
}
/**从客户端映射中移除指定key对应的客户端*/
void remove_client(const std::string& key)
{
// 在客户端映射中查找指定key的迭代器
auto it=clientmap.find(key);
// 检查是否找到对应的客户端
if(it!=clientmap.end())
{
// 如果找到,则从映射中移除该客户端
clientmap.erase(it);
// 记录客户端移除的日志信息
log.logmessage(info,"client removed:%s",key.c_str());
}
}
/**
* 广播消息函数
* 该函数将输入的消息发送给所有连接的客户端
*/
void broadcast_message(const std::string& message)
{
// 遍历客户端映射表,向每个客户端发送消息
for(auto& client:clientmap)
{
// 使用sendto函数发送消息,记录发送的字节数
int n=sendto(socketfd,message.c_str(),message.size(),0,(struct sockaddr*)&client.second,sizeof(client.second));
// 检查发送是否成功
if(n<0)
{
// 如果发送失败,记录致命错误日志并退出程序
log.logmessage(Fatal,"send error to %s",client.first.c_str());
exit(Send_Error);
}
// 记录成功发送消息的日志
log.logmessage(info,"send message to %s:%s",client.first.c_str(),message.c_str());
}
}
/**运行UDP服务器的主循环函数*/
bool run()
{
// 检查socket是否有效
if(socketfd<0)
{
log.logmessage(Fatal,"socket not create"); // 记录致命错误:socket未创建
return false;
}
// 设置服务器运行状态为true
isrunning = true;
// 定义接收数据的缓冲区和客户端地址结构
char buffer[buffer_size];
struct sockaddr_in client;
memset(&client, 0, sizeof(client)); // 初始化客户端地址结构
// 定义客户端地址长度并初始化
socklen_t clientlen=sizeof(client);
// 输出服务器运行提示信息
std::cout<<"udp server is running...."<<std::endl;
// 服务器主循环
while (isrunning)
{
// 从socket接收数据
int n=recvfrom(socketfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&client, &clientlen);
// 检查接收数据是否出错
if (n < 0)
{
log.logmessage(Fatal, "rec error"); // 记录致命错误:接收错误
exit(Recv_Error);
}
// 将新客户端添加到客户端列表
add_client(client);
// 确保字符串正确终止
buffer[n]='\0';
// 检查客户端是否发送退出命令
if(strcmp(buffer,"quit")==0)
{
// 获取客户端IP和端口
std::string ip=inet_ntoa(client.sin_addr);
uint16_t port=ntohs(client.sin_port);
// 构建客户端唯一标识键
std::string key=ip+" : "+std::to_string(port);
// 从客户端列表中移除该客户端
remove_client(key);
// 检查是否所有客户端都已退出
if(clientmap.empty())
{
isrunning=false; // 设置服务器运行状态为false
log.logmessage(info,"all client quit,server exit"); // 记录信息:所有客户端退出,服务器关闭
break;
}
continue; // 跳过后续处理,继续下一次循环
}
// 获取客户端IP地址
char clientip[64];
inet_ntop(AF_INET,&client.sin_addr,clientip,sizeof(clientip));
// 获取客户端端口号(从网络字节序转换为主机字节序)
uint16_t clientport=ntohs(client.sin_port);
// 记录接收到的消息
log.logmessage(info,"recieve from %s:%d : %s",clientip,clientport,buffer);
// 处理接收到的数据
std::string result=func(buffer);
// 向所有客户端广播处理结果
broadcast_message(result);
}
return true;
}
~udpserver()
{
if (socketfd > 0)
{
close(socketfd);
}
}
private:
int socketfd;
std::string serverip;
uint16_t port;
bool isrunning;
func_t func;
std::unordered_map<std::string, struct sockaddr_in> clientmap;
};udpserver.cpp:
cpp
#include"udpserver.h"
void usage(const char* program_name)
{
std::cout<<"usage:"<<program_name<<" port"<<std::endl;
}
std::string echo(std::string message)
{
std::string echo_message="server echo:"+message;
return echo_message;
}
bool check_order(const std::string& _order)
{
std::vector<std::string> unvalid_orders={"rm","shutdown","kill"};
size_t pos=_order.find(" ");
std::string token=_order.substr(0,pos);
for(auto& order:unvalid_orders)
{
if(token==order)
{
return false;
}
}
return true;
}
std::string handler_function(std::string order)
{
if(check_order(order))
{
FILE* fd=popen(order.c_str(),"r");
if(fd==nullptr)
{
log.logmessage(Fatal, "popen error");
exit(Popen_Error);
}
char buffer[buffer_size];
fread(buffer, 1, sizeof(buffer), fd);
pclose(fd);
return buffer;
}
log.logmessage(warning,"unvalid order:%s",order.c_str());
return "";
}
int main(int argc, char* argv[])
{
// 检查命令行参数,程序需要2个参数:程序名和端口号
if (argc != 2)
{
usage(argv[0]); // 打印程序使用说明
exit(Usagewrong); // 参数错误,退出程序
}
// 将字符串形式的端口号转换为整型
uint16_t port = std::stoi(argv[1]);
// 创建UDP服务器实例
// 参数:默认IP地址(_default)、端口号(port)、回调函数(echo)
udpserver server(_default, port, echo);
// 初始化服务器
if (server.init())
{
// 服务器初始化成功,启动服务器
if (!server.run())
{
// 如果服务器运行失败,退出程序
exit(Recv_Error);
}
}
else
{
// 服务器初始化失败,退出程序
exit(Socket_Error);
}
// 程序正常结束
return 0;
}Windows客户端
如上文所述,运行在不同操作系统上的设备之间之所以能够正常通信,是因为它们的网络协议栈遵循相同的标准。基于此,我们可以尝试编写一个运行在 Windows 上的客户端进程,使其能够与 Linux 服务端进程进行通信。在上文中我们已经实现了 Linux 客户端,而客户端的框架与流程基本是固定的,主要包括以下几个步骤:创建套接字,若创建成功,则准备一个用于记录服务端地址的结构体以及输入缓冲区,之后进入一个循环,通过 sendto 接口向服务端发送请求,发送完成后调用 recvfrom 接口等待并接收服务端处理后的数据,并将其保存到缓冲区中。
由于不同操作系统的网络协议栈一致,因此 Windows 客户端的核心逻辑与 Linux 客户端完全相同,仅在少数实现细节上存在差异。网络通信所依赖的几个核心接口,例如创建套接字的 socket 接口、绑定 IP 地址和端口的 bind 接口,在 Windows 中同样存在,区别主要在于对返回值的处理方式; sendto 与 recvfrom 接口也保持一致。
在 Windows 中,与网络编程相关的函数(如 socket 和 bind )位于 winsock 动态库中。我们需要通过以下编译指令告知编译器链接该库,其中 lib 为注释,其后为库的名称:
cpp
#pragma comment(lib, "ws2_32.lib")此外,Windows 相比 Linux 多出了库的初始化与清理环节:
cpp
// Windows 特有初始化与清理
WSADATA wsaData;
WSAStartup(MAKEWORD(2, 2), &wsaData); // 初始化 Winsock
WSACleanup(); // 清理 Winsock此处 WSADATA 类型的变量是一个结构体,其中包含了要链接的 Winsock 库的详细信息:
cpp
typedef struct WSAData {
WORD wVersion; // 期望的 Winsock 版本
WORD wHighVersion; // 支持的最高 Winsock 版本
char szDescription[WSADESCRIPTION_LEN + 1]; // 库描述信息
char szSystemStatus[WSASYS_STATUS_LEN + 1]; // 系统状态信息
unsigned short iMaxSockets; // 最大套接字数(已过时)
unsigned short iMaxUdpDg; // 最大 UDP 数据报大小(已过时)
char FAR *lpVendorInfo; // 厂商信息(已过时)
} WSADATA;WSAStartup 函数负责执行相关初始化操作,例如检查当前库是否已加载、请求的版本是否可用等。其第一个参数为请求的版本号,由宏 MAKEWORD 生成,该宏将主版本号与次版本号通过位运算合并为一个字节:
cpp
// 假设主版本 = 2 (0x02),次版本 = 2 (0x02)
BYTE major = 2; // 0000 0010
BYTE minor = 2; // 0000 0010
// 位运算过程:
// minor << 8 = 0000 0010 0000 0000
// major = 0000 0000 0000 0010
// 按位或 = 0000 0010 0000 0010 = 0x0202完成库的链接与初始化后,下一步是调用 socket 接口创建套接字。需要注意的是该接口的返回值:在 Linux 中, socket 返回一个非零的文件描述符;而在 Windows 中, socket 返回一个表示套接字的无符号整型标识符,其类型被定义为 SOCKET ,错误则用常量 INVALID_SOCKET 表示。
cpp
// 在 WinSock2.h 中可以查到如下定义:
typedef unsigned int u_int;
typedef u_int SOCKET; // SOCKET 实际为无符号整数
// 错误码定义
#define INVALID_SOCKET (SOCKET)(~0) // 0xFFFFFFFF
#define SOCKET_ERROR (-1)
cpp
#include<iostream>
#include<thread>
#include<atomic>
#include<string>
#include<cstring>
#include <winsock2.h>
#include <ws2tcpip.h>
#pragma comment(lib, "ws2_32.lib") // 链接 Winsock 库
#define buffer_size 1024
#pragma comment(lib,"ws2_32.lib")
enum
{
Start_Error = 1,
Socket_Error,
Bind_Error,
Send_Error,
Recv_Error,
};
int main()
{
WSADATA wsaData;
if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0)
{
std::cout << "start error" << std::endl;
exit(Start_Error);
}
SOCKET socketfd = socket(AF_INET, SOCK_DGRAM, 0);
if (socketfd == INVALID_SOCKET)
{
std::cout << "socket error" << std::endl;
exit(SOCKET_ERROR);
}
//...
}接下来是准备用于记录服务端 IP 地址和端口号的 struct sockaddr_in 结构体。在 Linux 程序中,通常可通过命令行参数获取服务端信息;而在本 Windows 客户端中,我们选择将 IP 地址和端口号硬编码到代码中。初始化该结构体时,需要使用 htons 函数将端口号转换为网络字节序,该函数在 Windows 与 Linux 中一致。将字符串形式的 IP 地址转换为网络字节序的 32 位整数,可使用 inet_addr 或 inet_aton 函数,这些函数在两种平台上也保持一致。
初始化 struct sockaddr_in 后,进入通信主循环:在 while 循环中,通过 cin.getline 获取用户输入的应用层数据,调用 sendto 发送至服务端,再通过 recvfrom 等待并接收服务端响应。
然而,在当前场景中,服务端为广播服务器,它同时处理多个客户端(如 Linux 客户端与 Windows 客户端)的请求,并将处理结果转发给所有客户端。若沿用上述循环设计,会存在一个明显缺陷:循环会先等待用户输入,发送数据后调用 recvfrom 等待服务端响应;在此期间,若服务端向该客户端广播数据,客户端可能因仍阻塞在 cin.getline 而无法及时接收并显示广播消息。
实际上,数据的发送与接收是两个相互独立、不互相依赖的操作:接收广播数据无需等待下一次用户输入,发送数据也不必等到收到广播后才能进行。因此,可将发送与接收分别放在两个线程中执行,即定义两个函数
send_messgae 与 rev_message ,分别负责读取用户输入并发送数据,以及接收服务端广播并输出到显示器。
cpp
std::atomic<bool> isrunning;
void send_message(SOCKET socketfd, struct sockaddr_in server)
{
char buffer[buffer_size];
while (isrunning) {
std::cout << "please Enter message :" << std::endl;
std::cin.getline(buffer, sizeof(buffer));
int len = strlen(buffer);
if (len == 0)
{
continue;
}
int serverlen = sizeof(server);
int n = sendto(socketfd, buffer, len, 0, (struct sockaddr*)&server, serverlen);
if (n == SOCKET_ERROR)
{
std::cout << "send error" << std::endl;
isrunning.store(false);
break;
}
if (strcmp(buffer, "quit") == 0)
{
std::cout << "client quit" << std::endl;
isrunning.store(false);
break;
}
}
}
void recv_message(SOCKET socketfd)
{
char buffer[buffer_size];
struct sockaddr_in from_addr;
int from_len = sizeof(from_addr);
DWORD timeout = 3000;
if (setsockopt(socketfd, SOL_SOCKET, SO_RCVTIMEO, (const char*) & timeout, sizeof(timeout)) == SOCKET_ERROR)
{
std::cout << "setsockopt error" << std::endl;
isrunning.store(false);
return;
}
while (isrunning.load())
{
int n = recvfrom(socketfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&from_addr, &from_len);
if (n == SOCKET_ERROR)
{
int error = WSAGetLastError();
if (error == WSAETIMEDOUT)
{
continue;
}
isrunning.store(false);
break;
}
buffer[n] = '\0';
std::cout << "server response :" << buffer << std::endl;
}
}这里需要注意一个关键细节:我们将数据包的发送与接收分别放在两个不同的线程中执行,这两个线程代表不同的执行流。在 send_message 函数对应的线程中,有一个环节是检查用户输入的字符串是否为 "quit" 。如果匹配,则调用 sendto 将消息发送给服务端,之后直接退出循环,线程结束。但这会导致 recv_message 线程因 recvfrom 接口而一直阻塞在接收操作上,无法正常退出。因此,两个线程之间需要一种同步机制。
为此,我们将两个线程中 while 循环的条件变量设计为一个共享的全局 bool变量 isrunning 。当 send_message 线程退出前,会将 isrunning 设为 false 。但即便如此,另一个线程仍然可能因为
recvfrom 的阻塞而无法及时检测到该变化并退出循环。
为解决这一问题,我们引入 setsockopt 接口。
- 函数:
setsockopt- 头文件:<sys/types.h> 与 <sys/socket.h>
- 声明:int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);"
- 返回值:成功返回
0,失败返回-1并设置errno。
理解 setsockopt 接口的一个比喻是:套接字就像一部手机,而 setsockopt 就是为这部手机设置特定功能。其中:
-
第一个参数是套接字描述符。
-
第二个参数指定选项的协议层,常见选项如:
cppSOL_SOCKET // 通用套接字选项 IPPROTO_TCP // TCP 协议选项 IPPROTO_IP // IPv4 协议选项 IPPROTO_IPV6 // IPv6 协议选项 -
第三个参数指定具体选项名称。
-
第四个参数是输入型参数,指向要设置的选项值。
-
第五个参数是选项值的长度。
这里我们需要在 SOL_SOCKET 层级设置 SO_RCVTIMEO 选项:
cpp
SO_RCVTIMEO // 接收超时(struct timeval)
SO_SNDTIMEO // 发送超时(struct timeval)设置该选项后,系统会启动一个定时器。 recvfrom 的默认行为是阻塞等待,当套接字接收队列为空时,线程会进入可中断睡眠状态。设置超时后,如果在该时间段内没有数据到达,定时器到期会唤醒线程。线程被唤醒后,会检查唤醒原因:如果是因定时器到期(即超时),则会设置相应的错误码并返回。
下面是设置超时后 recvfrom 的内部逻辑示意:
cpp
调用 recvfrom()
↓
检查接收队列
↓
if (队列为空) {
↓
if (非阻塞模式) {
return EAGAIN/EWOULDBLOCK
} else {
↓
// 设置进程状态
设置当前进程状态 = TASK_INTERRUPTIBLE (可中断睡眠)
// 添加到socket的等待队列
将当前进程添加到 sk->sk_sleep 等待队列
↓
if (设置了SO_RCVTIMEO) {
// 创建并启动定时器
定时器.到期时间 = 当前时间 + sk->sk_rcvtimeo
定时器.回调函数 = recv_timeout_handler
激活定时器(定时器)
}
↓
// 放弃CPU,让出控制权
schedule() // 进程进入睡眠状态
// ========== 进程被唤醒 ==========
// 从这里开始是进程被唤醒后执行的代码
↓
// 从等待队列移除
从 sk->sk_sleep 移除当前进程
设置当前进程状态 = TASK_RUNNING
↓
// 检查唤醒原因
if (signal_pending(当前进程)) {
// 被信号中断
return -EINTR
}
↓
if (定时器已到期) {
// 被定时器唤醒(超时)
return -EAGAIN // 或-ETIMEDOUT
}
↓
// 否则,是被数据到达唤醒
// 继续处理数据
// 并且重置定时器
}
}
↓
// 队列不为空,处理数据
skb = 弹出队首节点(sk_receive_queue)
拷贝数据到用户空间(skb->data, 用户缓冲区)
返回拷贝的字节数我们需要为定时器设置一个适当的超时时间。在 Windows 客户端中,超时值通过 DWORD 类型(4 字节整数)指定,单位为毫秒。需注意,之前给出的函数原型是基于 Linux 的,而 Windows 的 setsockopt 原型在倒数第二个参数(选项值)的类型上有所不同:Linux 使用 const void* ,而 Windows 使用 char* 。此外,在 Linux 中,超时值需通过 struct timeval 结构体指定,该结构体包含 tv_sec (秒)和 tc_usec (微秒)两个字段,总超时时间为两者之和:
cpp
#include <sys/time.h>
struct timeval {
time_t tv_sec; // 秒
suseconds_t tv_usec; // 微秒(1秒 = 1,000,000微秒)
};
// tv_usec 的取值范围应为 0 到 999,999(即小于1秒),系统会自动处理超出范围的赋值。设置好超时时间后,在 Windows 中将其作为 DWORD 类型,在 Linux 中作为 struct timeval 结构体,传递给 setsockopt 函数。相应地,我们需要修改 rec_message 函数的逻辑:检查 recvfrom 的返回值,如果返回 SOCKET_ERROR ,则进一步检查错误码。如果错误码表示超时(Windows 中为 WSAETIMEDOUT ),此时应继续循环;若是其他错误,则设置 isrunning 为 false 并退出循环。在 Linux 中,错误码通过 errno 获取;在 Windows 中,则需调用 WSAGetLastError函数获取。
此处还需要注意一个关键问题:作为客户端,我们通常不手动绑定端口,而由系统在首次调用 sendto 时自动分配。但本例中, sendto 在 send_message 线程中调用,而 recvfrom 在另一个线程中调用,两个线程的调度顺序不确定。若 recv_message 线程先被调度,此时套接字尚未绑定端口,将导致接收失败。因此,必须在创建线程之前,在主线程中调用 bind 为套接字显式分配一个端口。可将端口号设为 0,表示请求系统自动分配。
在云服务器环境下, ifconfig 命令显示的通常是其私有 IP 地址(例如我这里的 10.2.24.4 ),该地址仅在云服务商的内部网络中有效。因此,位于外部网络(如本地)的 Windows 客户端在连接时,必须使用服务器对应的公网 IP 地址,而非其私有 IP。这一点在配置客户端时需要特别注意。
cpp
int main()
{
WSADATA wsaData;
if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0)
{
std::cout << "start error" << std::endl;
exit(Start_Error);
}
SOCKET socketfd = socket(AF_INET, SOCK_DGRAM, 0);
if (socketfd == INVALID_SOCKET)
{
std::cout << "socket error" << std::endl;
exit(SOCKET_ERROR);
}
struct sockaddr_in client_addr;
memset(&client_addr, 0, sizeof(client_addr));
client_addr.sin_family = AF_INET;
client_addr.sin_addr.s_addr = INADDR_ANY;
client_addr.sin_port = 0; // 由系统自动分配端口
if (bind(socketfd, (struct sockaddr*)&client_addr, sizeof(client_addr)) == SOCKET_ERROR) {
std::cout << "bind error: " << WSAGetLastError() << std::endl;
closesocket(socketfd);
WSACleanup();
exit(Bind_Error);
}
//......
}UDP客户端源码(2)
Windows客户端源码 :
cpp
#include<iostream>
#include<thread>
#include<atomic>
#include<string>
#include<cstring>
#include <winsock2.h>
#include <ws2tcpip.h>
#pragma comment(lib, "ws2_32.lib") // 链接Winsock库
#define buffer_size 1024
#pragma comment(lib,"ws2_32.lib")
enum
{
Start_Error = 1,
Socket_Error,
Bind_Error,
Send_Error,
Recv_Error,
};
std::atomic<bool> isrunning;
void send_message(SOCKET socketfd, struct sockaddr_in server)
{
char buffer[buffer_size]; // 定义缓冲区用于存储用户输入的消息
// 循环运行,直到isrunning标志为false
while (isrunning) {
std::cout << "please Enter message :" << std::endl; // 提示用户输入消息
std::cin.getline(buffer, sizeof(buffer)); // 获取用户输入
int len = strlen(buffer); // 计算输入消息的长度
// 如果输入为空,则跳过当前循环
if (len == 0)
{
continue;
}
int serverlen = sizeof(server); // 获取服务器地址结构体的大小
// 通过UDP发送消息
int n = sendto(socketfd, buffer, len, 0, (struct sockaddr*)&server, serverlen);
// 发送失败处理
if (n == SOCKET_ERROR)
{
std::cout << "send error" << std::endl; // 输出错误信息
isrunning.store(false); // 设置运行标志为false
break; // 退出循环
}
// 检查是否输入了退出命令
if (strcmp(buffer, "quit") == 0)
{
std::cout << "client quit" << std::endl; // 输出客户端退出信息
isrunning.store(false); // 设置运行标志为false
break; // 退出循环
}
}
}
/*接收网络消息的函数*/
void recv_message(SOCKET socketfd)
{
// 定义接收缓冲区
char buffer[buffer_size];
// 定义 sockaddr_in 结构体,用于存储发送方地址信息
struct sockaddr_in from_addr;
// 初始化地址长度
int from_len = sizeof(from_addr);
// 设置接收超时时间为3000毫秒
DWORD timeout = 3000;
// 设置套接字接收超时选项
if (setsockopt(socketfd, SOL_SOCKET, SO_RCVTIMEO, (const char*) & timeout, sizeof(timeout)) == SOCKET_ERROR)
{
// 设置超时选项失败,输出错误信息
std::cout << "setsockopt error" << std::endl;
// 停止运行标志
isrunning.store(false);
return;
}
// 循环接收消息,直到isrunning标志为false
while (isrunning.load())
{
// 通过recvfrom接收数据
int n = recvfrom(socketfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&from_addr, &from_len);
// 接收失败处理
if (n == SOCKET_ERROR)
{
// 获取错误码
int error = WSAGetLastError();
// 如果是超时错误,继续循环
if (error == WSAETIMEDOUT)
{
continue;
}
// 其他错误,停止运行并退出循环
isrunning.store(false);
break;
}
// 添加字符串结束符
buffer[n] = '\0';
// 打印接收到的消息
std::cout << "server response :" << buffer << std::endl;
}
}
/* 主函数:初始化网络环境,创建UDP套接字,绑定本地地址,连接服务器,创建发送和接收线程,并进行线程管理*/
int main()
{
// 初始化Windows Socket环境
WSADATA wsaData;
if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0)
{
std::cout << "start error" << std::endl;
exit(Start_Error);
}
// 创建UDP套接字
SOCKET socketfd = socket(AF_INET, SOCK_DGRAM, 0);
if (socketfd == INVALID_SOCKET)
{
std::cout << "socket error" << std::endl;
exit(SOCKET_ERROR);
}
// 设置客户端地址结构体
struct sockaddr_in client_addr;
memset(&client_addr, 0, sizeof(client_addr)); // 清零地址结构体
client_addr.sin_family = AF_INET; // 使用IPv4地址
client_addr.sin_addr.s_addr = INADDR_ANY; // 接受任意网络接口的连接
client_addr.sin_port = 0; // 让系统自动分配端口
// 绑定套接字到本地地址
if (bind(socketfd, (struct sockaddr*)&client_addr, sizeof(client_addr)) == SOCKET_ERROR) {
std::cout << "bind error: " << WSAGetLastError() << std::endl;
closesocket(socketfd);
WSACleanup();
exit(Bind_Error);
}
// 设置服务器地址信息
struct sockaddr_in server;
memset(&server, 0, sizeof(server)); // 清零地址结构体
server.sin_family = AF_INET; // 使用IPv4地址
server.sin_port = htons(8888); // 设置服务器端口号(网络字节序)
inet_pton(AF_INET, "49.233.1.185", &server.sin_addr); // 服务器IP地址
int serverlen = sizeof(server); // 服务器地址结构体长度
char buffer[buffer_size]; // 数据缓冲区
// 设置运行标志为true
isrunning.store(true);
// 创建发送和接收线程
std::thread thread_send(send_message, socketfd, server);
std::thread thread_recv(recv_message, socketfd);
// 等待线程结束
thread_send.join();
thread_recv.join();
// 清理资源
closesocket(socketfd);
WSACleanup();
return 0;
}相应地,我们需要对 Linux 客户端进程进行修改,将消息的发送与接收分别置于不同的线程中。对于负责接收消息的线程,我们需要引入超时处理机制。这是因为,当发送消息的线程退出时,会将全局的布尔变量isrunning 设置为 false ,但接收线程由于 recvfrom 默认的阻塞行为,可能无法及时检测到 isrunning 的变化,从而一直阻塞在 recvfrom 调用中。
因此,我们应当为接收套接字设置一个超时定时器。当 recvfrom 陷入阻塞时,线程会进入可中断的睡眠状态。一旦超时,定时器会唤醒该线程,使其继续执行。随后,线程会检查输入队列是否为空。如果队列为空且本次唤醒是由于超时引起的, recvfrom 将返回一个错误码。此时我们需要检查其返回值:如果返回值小于 0,并且错误码为超时相关的错误(如 EAGAIN 或 EWOULDBLOCK ),则应继续执行循环,以便再次检查 while 循环条件(即 isrunning 的状态),从而安全退出。
需要注意的是,传递给 setsockopt 函数的超时参数是一个 struct timeval 结构体。因此,在正式进入 while 循环之前,除了准备输入缓冲区外,还必须初始化一个 struct timeval 结构体并设置合适的超时时间。
Linux的客户端源码:
cpp
#include<iostream>
#include<cstring>
#include<thread>
#include<atomic>
#include <arpa/inet.h>
#include<string>
#include<sys/socket.h>
#include<unistd.h>
#include<netinet/in.h>
#include<sys/time.h> // 包含timeval结构
#include<errno.h> // 包含errno变量
#include"log.hpp"
#define buffer_size 1024
log log;
std::atomic<bool> isrunning;
enum
{
Usagewrong = 1,
Socket_Error,
Send_Error,
Recv_Error,
};
void usage(const char* program_name)
{
std::cout<<"usage: "<<program_name<<" <server_ip> <port>"<<std::endl;
}
/*发送消息的函数 */
void send_message(int socketfd,struct sockaddr_in server)
{
char buffer[buffer_size]; // 定义发送消息的缓冲区
// 循环运行,直到isrunning为false或用户选择退出
while (isrunning) {
std::cout << "please Enter message :" << std::endl; // 提示用户输入消息
std::cin.getline(buffer, sizeof(buffer)); // 获取用户输入
int len = strlen(buffer); // 获取输入消息的长度
// 如果输入为空,则跳过本次循环
if (len == 0)
{
continue;
}
int serverlen = sizeof(server); // 获取服务器地址结构体的大小
// 发送消息到服务器
int n = sendto(socketfd, buffer, len, 0, (struct sockaddr*)&server, serverlen);
// 如果发送失败,记录错误日志并退出循环
if (n <0)
{
log.logmessage(Fatal,"send error");
isrunning.store(false); // 设置运行标志为false
break;
}
// 如果用户输入"quit",记录日志并退出循环
if (strcmp(buffer, "quit")==0)
{
log.logmessage(info,"client quit");
isrunning.store(false); // 设置运行标志为false
break;
}
}
}
/* 接收消息的函数*/
void recv_message(int socketfd)
{
// 定义接收缓冲区
char buffer[buffer_size];
// 定义服务器地址结构体
struct sockaddr_in server;
// 清空服务器地址结构体
memset(&server, 0, sizeof(server));
// 设置服务器地址结构体长度
socklen_t serverlen = sizeof(server);
// 设置地址族为IPv4
server.sin_family = AF_INET;
// 设置接收超时时间结构体
struct timeval timeout;
timeout.tv_sec=1; // 设置超时秒数为1秒
timeout.tv_usec=0; // 设置超时微秒数为0
// 设置套接字接收超时选项
if(setsockopt(socketfd,SOL_SOCKET,SO_RCVTIMEO,&timeout,sizeof(timeout))<0)
{
// 记录致命错误日志
log.logmessage(Fatal,"setsockopt error");
// 停止运行标志
isrunning.store(false);
return;
}
// 当运行标志为true时,持续循环接收消息
while (isrunning.load())
{
// 从套接字接收数据
int n = recvfrom(socketfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&server, &serverlen);
// 如果接收数据失败
if (n < 0)
{
// 如果是超时错误,则继续循环
if(errno==EAGAIN || errno==EWOULDBLOCK)
{
continue;
}
// 记录致命错误日志
log.logmessage(Fatal,"recv error");
// 停止运行标志
isrunning.store(false);
// 退出循环
break;
}
// 在接收到的数据末尾添加字符串结束符
buffer[n] = '\0';
// 打印服务器响应消息
std::cout << "server response :" << buffer << std::endl;
}
}
int main(int argc, char* argv[])
{
// 检查命令行参数数量是否正确
// 程序需要3个参数:程序名、服务器IP地址和端口号
if (argc != 3)
{
usage(argv[0]); // 显示程序使用方法
exit(Usagewrong); // 退出程序
}
// 从命令行参数获取服务器IP地址
std::string serverip = argv[1];
// 从命令行参数获取端口号,并转换为整数
uint16_t port = std::stoi(argv[2]);
// 创建UDP套接字
// AF_INET: 使用IPv4协议
// SOCK_DGRAM: 使用UDP协议
// 0: 自动选择协议
int socketfd = socket(AF_INET, SOCK_DGRAM, 0);
if (socketfd < 0)
{
// 如果套接字创建失败,记录错误日志并退出
log.logmessage(Fatal, "socket error");
exit(Socket_Error);
}
// 设置服务器地址结构
struct sockaddr_in server;
memset(&server, 0, sizeof(server)); // 将结构体内存清零
server.sin_family = AF_INET; // 设置地址族为IPv4
server.sin_port = htons(port); // 设置端口号(转换为网络字节序)
server.sin_addr.s_addr = inet_addr(serverip.c_str()); // 设置IP地址
// 设置程序运行状态为true
isrunning.store(true);
// 创建发送消息线程
// 参数:套接字描述符、服务器地址
std::thread send_thread(send_message, socketfd, server);
// 创建接收消息线程
// 参数:套接字描述符
std::thread recv_thread(recv_message, socketfd);
// 等待发送线程结束
send_thread.join();
// 等待接收线程结束
recv_thread.join();
// 关闭套接字,释放资源
close(socketfd);
// 程序正常退出
return 0;
}运行截图:
TCPsocket
上文介绍了基于UDP套接字的网络通信,接下来我们将探讨TCP套接字的实现。在正式编写TCP套接字的相关代码之前,我们首先需要理解TCP套接字所涉及的核心系统调用及其底层机制。
socket
如前文所述,无论是使用UDP还是TCP套接字进行通信,第一步都是调用 socket 接口创建套接字。本文不再重复该接口的具体用法(上文已详细说明),而是重点讨论传入不同参数创建TCP类型套接字时背后的底层原理。
我们知道,调用 socket 接口会在内核中创建一个 socket 结构体。该结构体中包含一个名为 sk 的指针,其类型为 struct sock ,指向一个 sock 结构体。 sock 结构体是内核用于管理套接字对应的网络层和传输层状态的核心数据结构,记录了这两层相关的各类属性。
由于网络层和传输层可能采用不同的协议,而不同协议的字段定义也不同,因此描述这些层的结构体必然有所差异。换言之,TCP和UDP会对应不同的 sock 结构体。如前文所述,内核在设计时采用了继承的方式来实现这些结构体。
具体实现中,会定义一个基类 sock ,其作用主要作为一个"容器"或提供缓冲区。以UDP为例,其对应的 udp_sock 结构体继承自 sock ,并维护输入缓冲区和输出缓冲区。这两个缓冲区实质上是两个队列,其内部以双向链表形式组织,链表中的每个节点是一个 sk_buff 结构。除了指向前驱与后继节点的指针外, sk_buff 还包含一组指针( head 、 tail 、 end 、 data ),通过移动 data 指针可以实现协议的封装与剥离,这部分内容已在上文详细说明。
对于TCP,其对应的 tcp_sock 结构体同样继承自基类 sock ,继承而来的 sock 部分也提供输入缓冲区和输出缓冲区,作用与UDP中的类似。
但TCP协议有一个重要特性:分段。当待发送的数据报大于MSS(最大报文段长度)时,传输层会主动将其分成多个段,并为每个段分配一个序列号,以标识其在原始数据中的位置。这样做的目的是避免在网络层进行分片。分段后的数据报可能乱序到达目标主机并交付给传输层,因此TCP的缓冲区在设计上会维护一个有序队列 和一个无序队列(均为双向循环链表),同时保存一个期望接收的下一个字节的序列号。
传输层在收到分段时,会检查其序列号:
- 若等于期望的序列号,则直接将其放入有序队列尾部;
- 若小于期望序列号,说明是重复的数据报,直接丢弃;
- 若大于期望序列号,说明是乱序到达的数据报,则将其放入无序队列。
每当一个有序分段被接收后,传输层会更新期望接收的序列号,并遍历无序队列,将其中序列号与当前期望序列号匹配的分段移出,并按序插入有序队列尾部。此过程会持续直到无序队列为空或没有可匹配的分段。
这一过程即为传输层的重组。有序队列中的数据最终会被按序交付给应用层。
需要注意的是,为了保持 tcp_sock 与 udp_sock 所继承的顶层 sock 结构体完全一致,内核设计时将有序队列置于 sock 结构体中,而无序队列则放在TCP特有的 tcp_sock 结构体中。这样设计的目的,是让 socket
结构体的 sk 指针可以统一为 struct sock* 类型,无需关心其实际指向的是 tcp_sock 还是 udp_sock
。在需要时,可通过该指针先获取到基类 sock ,再通过强制类型转换识别出具体的协议特有结构体。否则,若引用字段类型不统一,将需要为不同协议实现不同的 socket 结构体,增加复杂度。这实质上是面向对象中多态思想的体现:统一上层接口,下层通过继承实现不同行为。
cpp
// 最底层:通用socket结构体
struct sock {
// 基础字段
struct sock_common __sk_common;
// 缓冲区队列
struct sk_buff_head receive_queue; // 接收队列(TCP中用作有序队列)
struct sk_buff_head write_queue; // 发送队列
// 协议相关操作
struct proto *sk_prot;
// 状态和标志
unsigned int sk_state;
// ... 其他通用字段
};在 sock 基类之上,是描述网络层的 inet_sock 结构体,其中包含目标IP、源IP、目标端口和源端口等字段。
cpp
// 网络层结构体,继承sock
struct inet_sock {
struct sock sk; // 内嵌sock,实现继承
// 网络层字段
__be32 daddr; // 目标IP
__be32 saddr; // 源IP
__be16 dport; // 目标端口
__be16 sport; // 源端口
__s16 ucinet_ttl; // TTL
// ... 其他IP相关字段
};对于UDP套接字,其在 inet_sock 之上再继承 udp_sock 结构体,因此UDP套接字的结构共三层:
sock → inet_sock → udp_sock 。
而TCP作为面向连接的可靠传输协议,其可靠性依赖于确认(ACK)与重传机制。发送方发送数据段后,接收方需返回ACK确认。若发送方未在定时器超时前收到ACK,则会触发重传。这些与连接管理、重传及拥塞控制相关的字段(如定时器)被定义在 inet_connection_sock 结构体中。
cpp
// 面向连接的socket结构体,继承inet_sock
struct inet_connection_sock {
struct inet_sock icsk_inet; // 内嵌inet_sock
// 连接管理
struct request_sock *icsk_accept_queue; // 接收队列
struct inet_bind_bucket *icsk_bind_hash;
// 重传和拥塞控制
__u8 icsk_ca_state; // 拥塞状态
__u8 icsk_retransmits; // 重传次数
// 定时器
struct timer_list icsk_retransmit_timer; // 重传定时器
struct timer_list icsk_delack_timer; // 延迟ACK定时器
// ... 其他连接相关字段
};最下层是 tcp_sock 结构体,它继承 inet_connection_sock ,其第一个字段即为内嵌的inet_connction_sock 对象,其余字段则用于描述TCP特有的状态,例如前文提到的"期望接收的下一个字节的序列号",以及专门用于存放乱序数据的无序队列。
cpp
// TCP特定结构体,继承inet_connection_sock
// TCP套接字的内存布局:
struct tcp_sock {
struct inet_connection_sock inet_conn; // 包含连接管理
struct inet_sock icsk_inet; // 包含IP信息
struct sock sk; // 基础sock
struct sk_buff_head sk_receive_queue; // 有序队列
struct sk_buff_head sk_write_queue; // 发送队列
struct sk_buff_head out_of_order_queue; // TCP特有的乱序队列
// ... 其他TCP特定字段(如序列号、窗口、状态等)
};以上结构体之间的继承关系可概括如下:
cpp
sock (通用套接字基础)
│
├── inet_sock (IP层)
│ │
│ ├── inet_connection_sock (面向连接)
│ │ │
│ │ └── tcp_sock (TCP特定)
│ │
│ └── udp_sock (UDP特定)
│
└── 其他协议族 (如AF_UNIX等)那么除了socket结构体,那么我们知道socket结构体是内核持有的,那么这里还会创建一个用户层的file结构,那么会通过这个file结构体的private data字段访问到关联的socket结构体,最终在访问到sock结构体
bind
接下来介绍bind 接口,本文将重点关注其底层行为,因为其调用方法已为大家所熟知。bind接口的主要功能是为创建的套接字绑定一个IP地址和端口号,本质上是在相应的哈希表中添加一个条目。前文曾说明,Linux中通过网络命名空间来隔离网络环境,其本质上是一个 struct net 结构体,用于描述一个独立的网络协议栈运行环境,包括网络接口、路由表以及哈希表等。
这个哈希表维护了套接字与IP地址、端口号之间的映射关系。在同一网络命名空间中,UDP套接字和TCP套接字分别使用独立的哈希表。如前所述,UDP哈希表的键是一个二元组,即IP地址和端口号。
而TCP协议是面向连接的,一个TCP连接唯一对应不同设备上的两个进程之间的通信。因此,TCP套接字对应的哈希表与UDP有所不同,其键的设计更为复杂。TCP进一步将哈希表划分为监听套接字哈希表和已连接套接字哈希表(监听套接字与已连接套接字的具体区别将在后文详细说明)。
对于监听套接字哈希表,其键仍为二元组,即IP地址和端口号。而对于已连接套接字哈希表,其键扩展为一个四元组,包括源IP地址、源端口号、目标IP地址、目标端口号,对应的值则是指向该TCP套接字的 sock 结构体的指针。
cpp
特性 UDP TCP
哈希表数量 1个 3个
键值 二元组 (IP, 端口) 监听:二元组;已连接:四元组
复杂度 简单,无连接状态 复杂,有连接状态管理
查找效率 平均 O(1) 平均 O(1),但需区分状态
-------------------------------------------------------------------------------------
struct net (网络命名空间)
├── udp_table[UDP_HTABLE_SIZE] // UDP哈希表
│ └── 每个桶包含 struct sock 链表
│ ├── 键值: (本地地址, 本地端口)
│ └── 值: struct sock* (UDP套接字)
├── tcp_listening_hash[TCP_LHTABLE_SIZE] // TCP监听哈希表
│ └── 每个桶包含 struct sock 链表
│ ├── 键值: (本地地址, 本地端口)
│ └── 值: struct sock* (监听套接字)
└── tcp_established_hash[TCP_EHTABLE_SIZE] // TCP已连接哈希表
└── 每个桶包含 struct sock 链表
├── 键值: (源地址, 源端口, 目的地址, 目的端口)
└── 值: struct sock* (已连接套接字)listen
在 TCP 协议中,当双方通过 TCP 进行通信时,在正式传输数据之前,会先执行一个关键步骤------建立连接,即 TCP 的三次握手。建立连接的主要目的是确认双方的收发能力,并交换初始序列号。一旦连接建立完成,双方即可开始正式通信。
有读者可能会认为,服务器在创建套接字后,会通过这个套接字直接处理来自不同客户端的连接请求,从中选择一个客户端进程建立连接,之后便用同一个套接字与对应的客户端套接字进行通信,即用一个套接字同时完成连接的建立与数据的传输。
但实际的设计并非如此。监听和通信这两个功能是分开的:由一个专门的套接字负责监听并接收来自各个客户端的连接请求,我们称之为监听套接字。
当某个客户端的连接建立成功后,系统会专门创建一个新的套接字,称为已连接套接字,专门用于与该客户端进程通信。而原来的监听套接字会继续监听其他客户端的连接请求。
这两者的关系可以用饭店的场景来类比:
- 监听套接字 好比站在门口揽客的服务员;
- 一旦成功引导客人进入,就会分配一个专属服务员(即已连接套接字)为其提供一对一服务;
- 而门口的揽客服务员继续接待其他新客人。
这样设计实现了解耦,将"建立连接"和"数据传输"两个流程分离,提升了系统的并发处理能力。
因此,TCP 套接字可分为两类:
- 监听套接字
- 已连接套接字
我们调用 socket() 接口创建的实际是监听套接字,而不是已连接套接字。这里读者可能会产生疑问:我们知道内核通过核心的 sock 结构体来管理套接字在网络层和传输层的状态,而 sock 结构的实现采用面向对象的继承方式:
- 最上层是通用的
sock结构,作为"容器"并提供缓冲区; - 接着是网络层协议相关的
inet_sock结构,继承自sock(第一个字段为sock); - 再是面向连接协议相关的
inet_connection_sock结构,继承自inet_sock; - 最后是 TCP 特有的
tcp_sock结构。
监听套接字与已连接套接字在结构上存在重要区别:
- 继承层级不同
监听套接字只有三层结构,到 inet_connection_sock 为止,没有 tcp_sock 层。
已连接套接字则有完整的四层结构。
这是因为监听套接字的核心任务是建立连接,而不负责主要的数据传输。 tcp_sock 中的字段主要用于数据传输控制,而监听套接字只需管理连接状态,因此无需第四层。
- 缓冲区使用不同
顶层的 sock 结构包含输入缓冲区和输出缓冲区,但监听套接字不会使用这些缓冲区。
在 inet_connection_sock 结构中,有一个关键字段指向连接请求队列:
cpp
struct inet_connection_sock {
struct inet_sock icsk_inet; // 必须作为第一个字段!
/* 关键:监听套接字的队列结构 */
struct request_sock_queue icsk_accept_queue; // 连接请求队列
/* 包含两个子队列:
1. 半连接队列(SYN队列):存储SYN_RECV状态的连接
2. 全连接队列(Accept队列):存储ESTABLISHED但未被accept的连接
*/
/* 其他字段... */
};
struct request_sock_queue {
struct request_sock *rskq_accept_head; // 全连接队列头
struct request_sock *rskq_accept_tail; // 全连接队列尾
/* 半连接队列(SYN队列) */
struct listen_sock *listen_opt; // 指向半连接队列
int qlen; // 全连接队列当前长度
int max_qlen; // 全连接队列最大长度
/* 快速打开(TFO)相关 */
struct fastopen_queue *fastopenq; // 快速打开队列
};监听套接字通过这个连接请求队列来管理连接。该队列分为两部分:
- 半连接队列(SYN 队列):一般实现为哈希表,便于快速查找;
- 全连接队列(Accept 队列):本质是双向链表,每个节点是一个
"request_sock" 结构。
在 TCP 三次握手过程中:
- 客户端发送
SYN包; - 服务端回复
SYN-ACK; - 客户端回复
ACK,连接建立。
服务端的监听套接字负责接收 SYN 包。内核在收到 SYN 后,会提取其 TCP 头部和 IP 头部中的关键字段(如源端口、源 IP、序列号、TCP 选项等),填入一个 request_sock 结构体,然后将该结构体插入半连接队列。此时 SYN 数据包本身被丢弃,因为其数据部分无意义。
半连接队列采用哈希表实现,键值通常基于四元组生成:
参数 说明 作用
raddr 客户端 IP 地址 区分不同客户端机器
rport 客户端端口号 区分同一客户端的多个连接
rnd 随机种子 防止哈希碰撞攻击
synq_hsize 哈希表大小 取模运算对应的值即为request_sock 结构体:
cpp
struct request_sock {
// 链表指针
struct request_sock *dl_next; // 下一个节点
struct request_sock *dl_prev; // 上一个节点
// 指向已连接的sock(当三次握手完成后)
struct sock *sk;
// 引用计数
atomic_t rsk_refcnt;
// TCP特定字段
struct tcp_request_sock {
u32 snt_isn; // 发送初始序列号
u32 rcv_isn; // 接收初始序列号
u32 snt_synack; // 发送的SYN-ACK序列号
u32 rcv_nxt; // 期望接收的下一个序列号
// TCP选项
struct tcp_options_received tcp_opt;
// 时间戳
u32 snt_synack_stamp; // SYN-ACK发送时间
u32 rcv_tsecr; // 接收到的TSecr
};
// INET特定字段
struct inet_request_sock {
__be32 ir_rmt_addr; // 远程IP地址
__be32 ir_loc_addr; // 本地IP地址
__be16 ir_rmt_port; // 远程端口
__be16 ir_loc_port; // 本地端口
// TCP选项
u8 tstamp_ok; // 时间戳选项是否可用
u8 wscale_ok; // 窗口缩放选项是否可用
u8 sack_ok; // SACK选项是否可用
u8 ecn_ok; // ECN选项是否可用
u8 rcv_wscale; // 接收窗口缩放因子
u8 snd_wscale; // 发送窗口缩放因子
u32 ir_mark; // 标记值
u32 snd_wscale:4, // 发送窗口缩放因子
rcv_wscale:4; // 接收窗口缩放因子
};
};当三次握手完成,该连接对应的request_sock 会从半连接队列移入全连接队列。因此,虽然监听套接字也包含sock 结构,但不使用其中的数据缓冲区字段,这些缓冲区仅由已连接套接字使用。相应地,已连接套接字也不使用inet_connection_sock 中的连接队列。
结构对比可总结如下:
cpp
已连接套接字(4层结构):
┌─────────────────────────────────────────────┐
│ struct tcp_sock │ ← TCP特有字段
├─────────────────────────────────────────────┤
│ struct inet_connection_sock │ ← 面向连接协议通用字段
├─────────────────────────────────────────────┤
│ struct inet_sock │ ← IP协议相关字段
├─────────────────────────────────────────────┤
│ struct sock │ ← 通用套接字核心
│ ├─ sk_receive_queue (有效) │ ← 接收数据队列
│ ├─ sk_write_queue (有效) │ ← 发送数据队列
│ ├─ out_of_order_queue (有效) │ ← 乱序数据队列
│ └─ 其他字段... │
└─────────────────────────────────────────────┘
监听套接字(3层结构):
┌─────────────────────────────────────────────┐
│ struct inet_connection_sock (只有这个层次) │
├─────────────────────────────────────────────┤
│ struct inet_sock │
├─────────────────────────────────────────────┤
│ struct sock │
│ ├─ sk_receive_queue (空) │ ← 不接收数据
│ ├─ sk_write_queue (空) │ ← 不发送数据
│ ├─ 但会使用: │
│ │ - sk_state (TCP_LISTEN) │ ← 连接状态
│ │ - sk_prot (协议操作表) │ ← 处理函数
│ │ - sk_common (网络层信息) │ ← IP/端口
│ └─ 其他通用字段... │
└─────────────────────────────────────────────┘注意,调用socket() 创建的监听套接字初始状态为TCP_CLOSE 。这好比刚买的手机处于关机状态,无法接听电话。必须执行"开机"操作,即调用listen 函数,才能开始监听连接。
listen- 头文件:<sys/socket.h>
- 声明:int listen(int sockfd, int backlog);
- 返回值:成功返回
0,失败返回-1并设置errno。
listen() 在底层主要完成以下工作:
- 将
sock结构中的sk_state字段改为TCP_LISTEN; - 参数
backlog用于设置全连接队列的最大长度(通常默认为 5); - 初始化半连接队列与全连接队列。
三次握手在内核中的处理流程可概括如下:
cpp
客户端发送SYN
↓
服务端接收SYN
↓
创建request_sock
↓
放入半连接队列(哈希表)
↓
发送SYN-ACK
↓
等待客户端ACK
↓
收到ACK
↓
从半连接队列移除
↓
创建已连接套接字(完整4层结构)
↓
放入全连接队列(双向链表)
↓
应用层调用accept()从全连接队列获取连接通过这样的设计,TCP 实现了高效的连接管理与并发处理,监听套接字专注于接收新连接,而已连接套接字则专职于数据传输,二者各司其职,共同支撑起可靠的面向连接通信。
在同一个网络命名空间中,TCP 与 UDP 各自维护独立的哈希表来管理套接字。对于 TCP 而言,监听套接字 与 已连接套接字 也分别位于不同的哈希表中。这意味着,监听套接字和已连接套接字可以绑定到相同的端口号。
具体来说:
- 当一个套接字调用
listen()进入监听状态后,它会被注册到 监听哈希表 中。此表专门用于快速查找和接收新的连接请求(SYN 包)。 - 当三次握手完成,系统创建出一个已连接套接字时,该套接字会被放入 已连接套接字哈希表。此表用于管理所有活跃的 TCP 连接,以便高效地匹配传入的数据包。
由于这两个哈希表是独立且并行的,监听套接字和已连接套接字虽然共享同一个本地 IP 和端口(例如0.0.0.0:80 ),但内核可以根据数据包的类型(是新连接的 SYN,还是已建立连接的数据包)以及套接字的状态,正确地将其分发到对应的哈希表及套接字上。
这种设计正是实现 "一个服务端口同时处理新连接请求和已有连接数据" 的基石。它允许多个客户端通过同一个服务端口与服务器通信,而监听套接字始终在固定的端口上等待新的连接,实现了高效的端口复用。
accept
通过上文的介绍,我们已经理解了监听套接字与已连接套接字的区别。socket 接口用于创建监听套接字。假设现在服务端进程已依次调用 socket 和 listen 接口,此时监听套接字已成功建立,并可以开始接收客户端的连接请求。那么,已连接套接字是如何创建的呢?这便需要用到 accept 系统调用。
accept- 头文件:<sys/types.h> 与 <sys/socket.h>
- 函数声明:int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
- 返回值:成功时返回新的已连接套接字的文件描述符,失败时返回
-1并设置errno。
accept 接收一个监听套接字的文件描述符作为参数。接下来我们将深入分析其底层实现原理。
accept 的核心功能是创建已连接套接字。已连接套接字在内核中对应一个四层结构体(struct sock),除了创建该结构体外, accept 还会将其插入已连接套接字对应的哈希表中,并在其中建立相应表项。已连接套接字哈希表的键是一个四元组,包括源IP地址 、源端口 、目标IP地址 、目标端口,即客户端与服务器双方的地址信息。
对于服务器端(已连接套接字)的 IP 地址与端口,accept 会通过其第一个参数(监听套接字的文件描述符)找到对应的 socket 结构体,进而定位到内核中表示该监听套接字的 sock 结构体。接着,accept 会获取该监听套接字绑定的 IP 地址与端口号。由于监听套接字与已连接套接字使用独立的哈希表,已连接套接字可以复用监听套接字所绑定的地址与端口。
- 如果监听套接字绑定的是具体 IP 地址(例如 192.168.1.100),则已连接套接字将直接使用该 IP。
- 如果监听套接字绑定的是通配地址(0.0.0.0,即监听所有网络接口),则已连接套接字会根据实际接收到的 SYN 包中的目标 IP 地址,确定使用哪个网络接口的 IP,从而完成绑定。
获得服务器端的 IP 与端口后,accept 会访问监听套接字的全连接队列。若队列不为空,则取出队首元素,从中获取客户端的 IP 地址与端口,从而构造出完整的四元组,并将其插入已连接套接字的哈希表,随后内核会将对应的 sock 结构体的 sk_state 字段设置为 TCP_ESTABLISHED 。最后,accept 会为该已连接套接字创建对应的 file 结构体,并返回其文件描述符。
如果全连接队列为空,accept 在默认情况下会阻塞当前进程,直至有新连接进入队列后才被唤醒。
accept 的最后两个参数是输出型参数。当从全连接队列中取出 request_sock 结构体后,内核不仅利用其中的地址信息构造四元组,还会填充由调用方传入的 struct sockaddr_in 结构体,从而向应用程序返回客户端的 IP 地址与端口,以便识别是哪一个客户端发起了本次连接。
cpp
1. 通过文件描述符找到监听套接字
2. 检查监听套接字状态是否为 TCP_LISTEN
3. 从全连接队列取出连接请求
4. 获取客户端IP和端口(从request_sock)
5. 确定服务器IP和端口:
- 如果监听绑定特定IP:使用该IP
- 如果监听绑定0.0.0.0:使用实际接收数据包的接口IP
6. 创建已连接套接字(四层结构体)
7. 设置状态为 TCP_ESTABLISHED
8. 插入已连接哈希表(四元组为键)
9. 返回新的文件描述符connect
在服务器-客户端通信模型中,服务器通常是被动等待连接的一方,而客户端则主动向服务器发起连接请求。那么,对于客户端而言,是否需要像服务器那样分别使用监听套接字和已连接套接字呢?
答案是否定的。客户端不需要像服务器那样处理多个传入的连接请求,因此每一个套接字本身就可以直接代表一个连接。一旦该套接字通过 connect 与服务器的监听套接字成功建立连接,便可直接用于后续的数据通信,而无需再额外创建所谓的"已连接套接字"。
对客户端而言,建立连接的基本步骤如下:
首先调用 socket() 创建一个套接字,接着调用 connect() 函数发起连接。
connect 的作用是完成 TCP 的三次握手,与服务器建立连接。
connect- 头文件:<sys/types.h>与 <sys/socket.h>
- 声明:int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- 返回值:成功返回
0,失败返回-1并设置errno。
从 connect 接口的返回值也可以印证,客户端是复用一个套接字完成连接建立与数据通信的。读到此处,可能会产生一个疑问:前文提到,服务器调用 socket() 创建的是监听套接字,而非已连接套接字;服务器必须再调用 accept() 才能得到用于通信的连接套接字。并且,监听套接字对应一个三层(即不含 tcp_sock 层)的 sock 结构,而 TCP 通信所需的完整结构是四层的(包含 tcp_sock )。TCP 报文段可能会分段、乱序到达传输层,因此内核需要维护乱序队列和有序队列进行重组,这两者分别位于 tcp_sock 和通用的 sock 结构体中。如果监听套接字真的是三层结构,客户端进程如何能在连接建立后复用该套接字继续用于数据传输呢?
这个疑问非常合理。按照上述逻辑,如果监听套接字仅为三层结构,则确实无法直接用于后续通信,这暗示了实际情况可能有所不同。实际上,监听套接字在内核底层仍然是四层 sock 结构,只不过在"监听"状态下,其第四层( tcp_sock)中的字段并不被使用。之前所说的"三层结构",是一种逻辑结构,用于强调其在连接建立前不具备完整的 TCP 通信能力。
由此又引出另一个问题:既然监听套接字和连接套接字在结构上"看起来一样",内核如何区分它们?这主要依赖套接字的状态。对服务器而言,监听套接字的状态为 TCP_CLOSE 或 TCP_LISTEN 。只要处于这两种状态,内核就只访问其上三层字段,不触及 tcp_sock 中的内容。一旦进入 TCP_ESTABLISHED 状态,该套接字就转为连接套接字,此时会启用 tcp_sock 中的字段(如乱序队列),而不再访问 inet_connection_sock 中与连接队列相关的部分。这正是服务器能用同一套结构同时支持监听与已连接两种角色,却又互不干扰的关键机制。
对客户端而言,套接字的状态变化如下:
- 初始状态为
TCP_CLOSE; - 调用
connect()后,向服务器发送 SYN 包,状态转为TCP_SYN_SENT; - 收到服务器的 SYN-ACK 后,进入
TCP_ESTABLISHED,此时可使用tcp_sock相关字段。
cpp
// 客户端套接字状态转换
TCP_CLOSE
│
└─ connect() → TCP_SYN_SENT
├─ 成功收到SYN+ACK → TCP_ESTABLISHED
├─ 收到RST → TCP_CLOSE
└─ 超时重传失败 → TCP_CLOSE因此, connect的核心工作就是发送 SYN 报文,并驱动套接字状态从 TCP_CLOSE 向 TCP_SYN_SENT 及后续状态迁移。
其最后两个参数中, addr是输入型参数,指向目标服务器的地址(IP 和端口), addrlen 指明该地址结构体的长度。
read
在前文介绍过几个关键接口后,我们已经能够成功创建套接字并进行正式通信。TCP 连接的一个重要特征是面向字节流,其数据的读取和传输单位是字节;相比之下,UDP 的传输单位则是数据报。
读取用户发送的数据可通过复用 read 接口实现:
cpp
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);我们知道,创建套接字时也会在用户层创建对应的 file 结构体。该结构体会通过其内部的 private_data 字段关联到 socket 结构体,再通过 sokcet 结构体的 sk 字段定位到内核中核心的 sock 结构体。
file 的文件操作函数表本质上是一组函数指针,指向 socket 结构体中定义的操作函数。因此,当我们调用 read 接口时,我们会先准备一个输入缓冲区,并指定要读取的最大字节长度。
接下来, read 操作会定位到 sock 结构体中的有序接收队列。 sock 结构体内部维护一个指针,记录当前读取偏移量(即已拷贝数据的序列号)。系统会尝试从该序列号开始,向后读取 count 个字节,依次拷贝到用户缓冲区。如果已读取到当前队首节点(对应一个 TCP 段)的应用层数据结尾,则会弹出该节点,并继续读取后续节点。如果此时有序接收队列为空,进程将进入阻塞状态,直到队列非空后被唤醒。
以下是与读取偏移量相关的核心结构体字段示意:
cpp
// TCP sock 结构体中与接收和读取偏移相关的部分字段
struct tcp_sock {
// 序列号管理
u32 rcv_nxt; // 期望接收的下一个序列号
u32 copied_seq; // 已拷贝到用户空间的序列号
u32 rcv_wup; // 窗口更新序列号
// 接收队列
struct sk_buff_head out_of_order_queue; // 乱序队列
// 缓冲区管理
u32 rcv_wnd; // 接收窗口大小
u32 rcv_ssthresh; // 慢启动阈值
// ...
};其执行流程可简要概括为:
- 用户调用
read(fd,buf,count) - 通过
fd找到对应的file结构体 - 通过
file找到关联的socket结构体 - 通过
socket找到内核的sock结构体 - 检查
sk_receive_queue(有序接收队列) - 从队列中拷贝数据到用户空间缓冲区
- 更新
copied_seq(已拷贝序列号) - 如果某个
skb中的数据已全部读取,则将其从队列中移除
write
在上一节中,我们介绍了如何接收数据,接下来将说明发送数据所使用的接口,即通过系统调用 write 来实现:
cpp
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);关于 write 接口的底层原理,其仍然会通过文件描述符最终定位到对应的 sock 结构体。需要注意的是,这里涉及 TCP 的滑动窗口机制:接收方会告知发送方其当前的接收窗口大小,该窗口表示接收缓冲区中还可容纳的字节数,从而限制发送方可发送的数据量。
在写入数据前,系统会比较待发送的字节数 count 与当前可用发送窗口的大小:
- 如果
count小于等于发送窗口,则进一步检查发送队列尾部的剩余空间,并尝试先填满该空间,再将剩余待发送数据按照 MSS 进行分段,每段对应一个sk_buff结构体节点,加入发送队列。 - 如果
count大于发送窗口,则只发送相当于发送窗口大小的数据,之后等待接收方的确认。收到 ACK 后,更新发送窗口,并重复上述流程,直至全部数据发送完成。
具体流程可概括为以下步骤:
- 用户调用
write(fd,buf,count)。 - 通过文件描述符
fd找到对应的sock结构。 - 检查当前可用发送窗口大小。
- 若
count大于发送窗口,则仅发送窗口大小的数据。 - 检查发送队列尾部剩余空间,并优先填满。
- 将待发数据按 MSS 分段。
- 为每段创建
sk_buff节点,加入发送队列。 - 调用
tcp_push尝试发送。 - 若仍有数据未发送(即
count大于窗口),则等待 ACK。 - 收到 ACK 后,更新发送窗口。
- 重复步骤 3--10,直至所有数据发送完毕。
close
最后是 close 接口。该接口的作用是清理套接字资源。与UDP的 close 不同,TCP的 close 会触发四次挥手过程。主动调用 close 的一端会向对端发送一个FIN数据包,此时其状态切换为 FIN_WAIT1 。被动接收FIN的一端则进入 CLOSE_WAIT 状态,并回复一个ACK数据包。主动方收到该ACK后,状态转变为 FIN_WAIT2
。至此,前两次挥手完成,双方状态均已切换。
此时,主动关闭方无法再发送数据,而被动方仍可发送数据,连接处于单向切断状态。若被动方也调用 close
并发送FIN数据包,主动方收到后会进入 TIME_WAIT 状态,而被动方在发送FIN后则进入 LAST_ACK
状态。
主动方在收到FIN后,会发送最后一个ACK数据包。由于该ACK可能在传输中丢失,为确保对端能够收到,TCP设置了2MSL(Maximum Segment Lifetime)的等待时间窗口。如果对端未收到ACK,会因超时重传FIN;若主动方在2MSL内再次收到对端的FIN,便会重传ACK。如果在此窗口内未收到对端的FIN,则认为对端已成功收到ACK,此时主动方进入完全关闭状态。对端在收到ACK后,也进入完全关闭状态( CLOSE )。
连接完全关闭后,系统首先获取对应的 file 结构体,将其引用计数减1。若引用计数降至0,则释放该 file 结构体。接着通过 file 定位到 sock 结构体,生成连接四元组,并在哈希表中删除该已连接套接字对应的条目。最后,依次释放 sock 结构体和 socket 结构体。
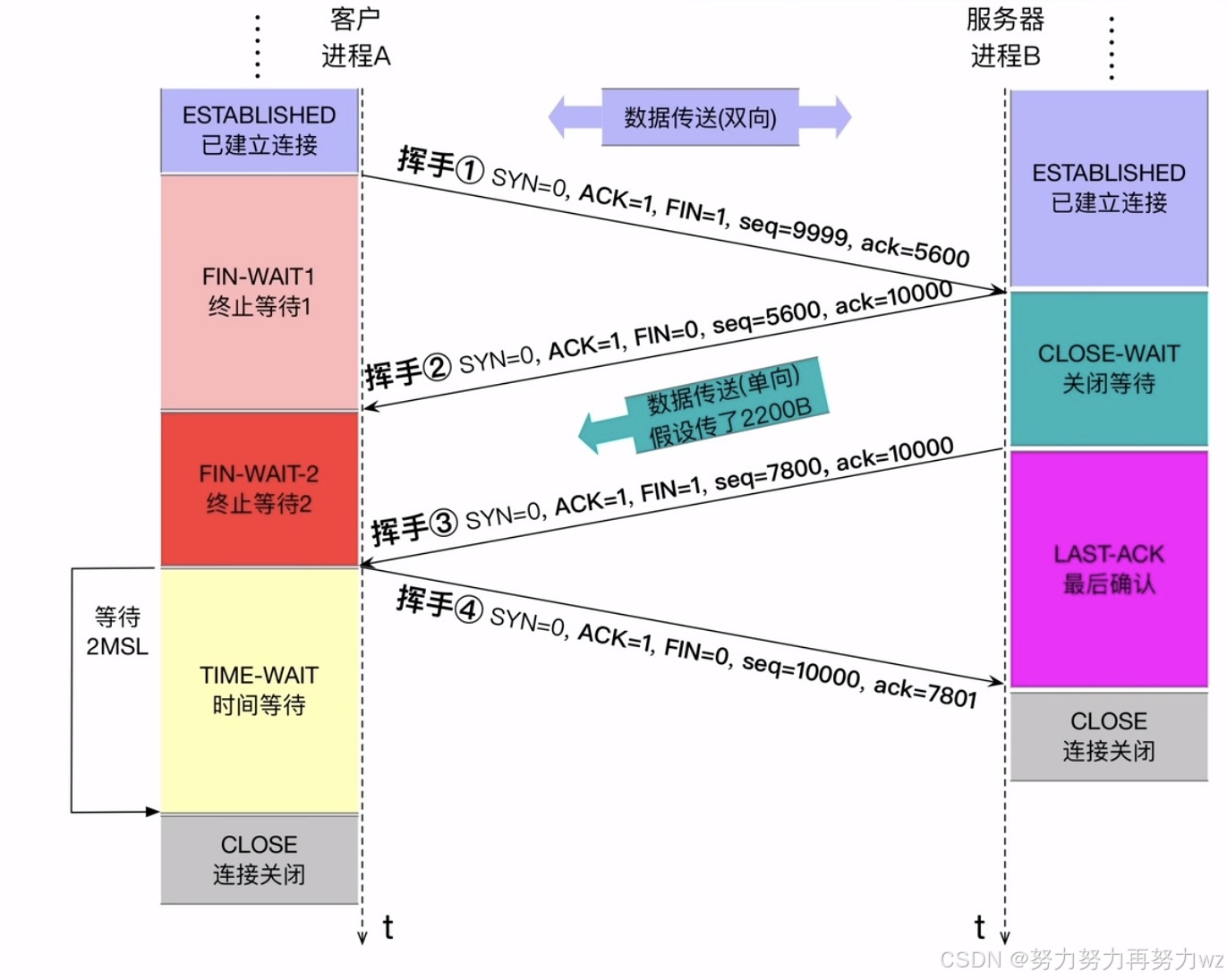
TCP服务端(1)
tcpserver.h
在掌握了上述核心系统调用接口之后,便可以着手设计与实现TCP服务端相关的代码。基于之前实现UDP服务端的经验,我们同样将TCP服务端设计为一个对象,即通过 tcpserver 类进行描述。该类封装了监听套接字相关的属性,例如监听套接字对应的文件描述符、IP地址及端口号。对于一个服务端进程而言,通常只需一个监听套接字即可满足需求。
cpp
#pragma once
#include<iostream>
#include<string>
#include<cstring>
#include<unistd.h>
#include<sys/socket.h>
#include<arpa/inet.h>
#include<netinet/in.h>
#include<thread>
#include"log.hpp"
#define buffer_size 1024
log log;
std::string _deafult = "0.0.0.0";
enum
{
Usage_Error=1,
Socket_Error,
Bind_Error,
Listen_Error,
Accept_Error,
};
class tcpserver
{
public:
tcpserver(std::string _ip , uint16_t _port)
:ip(_ip)
, port(_port)
{
}
}
//..........
private:
int listen_socketfd;
std::string ip;
uint16_t port;
};接下来设计 tcpserver 类的框架。其构造函数用于初始化IP地址与端口号,以供后续创建的监听套接字绑定使用。通常,我们会将套接字绑定到 0.0.0.0 ,以监听所有网络接口上的SYN数据包。接着是 init 方法,其主要完成监听套接字的创建以及IP地址与端口号的绑定操作。若创建或绑定失败,会记录相应错误日志并返回非零错误码;成功时也会输出对应的日志信息。
cpp
void init()
{
listen_socketfd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_socketfd < 0)
{
log.logmessage(Fatal, "socket error");
exit(Socket_Error);
}
log.logmessage(info, "create socket successfully");
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(port);
server.sin_addr.s_addr = inet_addr(ip.c_str());
if (bind(listen_socketfd, (struct sockaddr*)&server, sizeof(server)) < 0)
{
log.logmessage(Fatal,"bind error");
close(listen_socketfd);
listen_socketfd=-1;
exit(Bind_Error);
}
log.logmessage(info,"bind successfully");
}相较于UDP套接字,TCP套接字在通信前需额外进行连接建立的过程。因此,我们将建立连接这一环节单独设计为 start 成员函数。该方法主要调用 listen 接口,使套接字状态从 TCP_CLOSED 转换为 TCP_LISTEN 。接着检查 listen 的返回值:若小于0,表示调用失败,记录错误日志、将监听套接字的文件描述符置为无效值,并返回非零错误码;若返回0,则说明套接字已进入监听状态。
随后,程序进入一个无限循环,持续监听客户端发来的SYN数据包。当与某个客户端成功完成三次握手后,连接被放入全连接队列,此时 accept 接口可从队列中取出该连接,并返回对应的已连接套接字文件描述符。该循环的设计使服务端能够持续接受不同客户端的连接请求。
需注意的是,此处设计为服务端向客户端提供长服务,即客户端在主动退出前会持续与已连接套接字进行通信。因此,一旦建立连接并创建已连接套接字,便会立即进入通信环节。若将通信逻辑同样置于循环中,服务端进程将无法响应其他客户端的连接请求。
由此可见,连接建立与通信处理应是两个独立且互不干扰的任务。为此,我们将通信部分封装为单独的线程执行。线程本质上即用户态函数,这里我们预先准备了 run 函数,其内部即为通信相关的上下文逻辑。
cpp
void start()
{
struct sockaddr_in _client;
memset(&_client, 0, sizeof(_client));
_client.sin_family = AF_INET;
socklen_t clientlen=sizeof(_client);
size_t id = 0;
int n=listen(listen_socketfd,5);
if(n<0)
{
log.logmessage(Fatal,"listen error");
exit(Listen_Error);
}
while (true)
{
log.logmessage(info, "listen successfully");
int fd = accept(listen_socketfd, (struct sockaddr*)&_client, &clientlen);
if (fd < 0)
{
log.logmessage(Fatal, "accept error");
close(listen_socketfd);
listen_socketfd=-1;
exit(Accept_Error);
}
log.logmessage(info, "accept successfully");
std::thread connect_thread(run, clientData{ fd, _client }, id++);
connect_thread.detach();
}
}通信线程需要获取已连接套接字的文件描述符及相关地址信息。因此,我们将已连接套接字的文件描述符与客户端对应的 struct sockaddr_in 结构体封装为 clientData 结构体,并作为参数传递给 run 函数。
run 函数的核心是一个无限循环。在进入循环前,需先准备输入缓冲区。循环内首先调用 read 接口读取数据至缓冲区(此处约定服务端与客户端以字符串形式通信)。接着检查 read 的返回值:若小于0,记录错误日志并退出;若大于0,则返回值表示成功读取的字节数。为防止客户端未在字符串末尾添加终止符,我们会在读取的有效数据后显式添加 '\0' 。
当 read 接口返回0时,需特别注意其背后的连接关闭过程。此时,若客户端已调用 close() 而服务端尚未调用,客户端会向服务端已连接的套接字发送一个FIN段,随后进入 FIN_WAIT_1 状态。服务端收到该FIN段后,会回复ACK并进入 CLOSE_WAIT 状态,客户端收到该ACK后则进入 FIN_WAIT_2 状态。至此,连接处于半关闭状态,即仅完成了四次挥手的前两次。
当一端收到FIN段后,会唤醒因调用 read 而阻塞的进程。 read 在执行时,会在检查接收缓冲区之前先检查套接字状态。如果套接字处于半关闭状态,并且接收缓冲区中已无数据可读,则 read 会返回0。因此,若 read 返回0,表明对端已关闭连接,即不再与本端通信。此时,本端也应调用 close() 关闭套接字。
一旦服务端也调用 close() 关闭连接,便会发出FIN段并进入 LAST_ACK 状态,客户端收到后回复ACK并进入 TIME_WAIT 状态,服务端收到ACK后进入 CLOSED 状态。客户端在经过2MSL等待后,也最终进入 CLOSED
状态。至此,四次挥手完整完成。在此过程中,服务端可在调用 close() 后打印一条连接关闭的日志信息,然后安全退出。
cpp
客户端调用close() → 发送FIN → 进入FIN_WAIT1
服务端收到FIN → 发送ACK → 进入CLOSE_WAIT
客户端收到ACK → 进入FIN_WAIT2
服务端read返回0 → 服务端调用close() → 发送FIN → 进入LAST_ACK
客户端收到FIN → 发送ACK → 进入TIME_WAIT
服务端收到ACK → 进入CLOSE
客户端等待2MSL → 进入CLOSE随后,将接收到的数据输出至日志,并进行简单处理(如在字符串前添加服务端标识信息),再通过 write 接口将处理后的字符串发回客户端。若 write 返回值小于0,同样记录错误日志并退出循环。
cpp
class clientData
{
public:
int acc_socketfd;
struct sockaddr_in client;
};
void run(clientData con,int id)
{
log.logmessage(info, "connect_thread %d is running",id);
char buffer[buffer_size];
while (1)
{
int n = read(con.acc_socketfd, buffer, sizeof(buffer));
if (n < 0)
{
log.logmessage(Fatal, "connect_thread %d read error",id);
close(con.acc_socketfd);
break;
}else if(n==0)
{
log.logmessage(info, "connect_thread %d close",id);
close(con.acc_socketfd);
break;
}else{
buffer[n] = '\0';
log.logmessage(info, "connect_thread %d recive a message : %s",id, buffer);
std::string response="server echo:"+std::string(buffer);
n=write(con.acc_socketfd,response.c_str(),response.size());
if(n<0)
{
log.logmessage(Fatal,"connect_thread %d write error",id);
close(con.acc_socketfd);
break;
}
}
}
}在 start 方法中,一旦 accept 成功,便立即初始化 clientData 结构体,创建新线程处理该连接,并将线程设置为分离状态。之后主循环继续执行 accept ,以接受新的连接请求。
tcpserver.cpp:
接下来是服务端主程序 tcpserver.cpp 的编写。该文件首先引入 tcpserver.h 头文件。在 Linux 系统中,进程通常通过命令行启动,并可经由命令行参数获取配置信息,例如监听套接字需要绑定的 IP 地址与端口号。本例中默认将套接字绑定到 0.0.0.0 ,因此只需通过命令行参数传入端口号即可。
命令行本身是用户输入的字符串, shell (命令解释器)在获取该字符串后,会以空格为分隔符将其划分为命令名与参数两部分。此处命令名为可执行文件名,参数即为端口号,因此参数总数应为 2。分割后的字符串将以字符串数组形式传递给进程的 main 函数。
因此, tcpserver.cpp 首先检查参数个数:若参数数量不等于 2,则打印错误提示信息并返回非零退出码;若符合要求,则解析第二个参数(端口号)------该参数为字符串类型,需通过 std::stoi() 函数转换为整型。
接着,程序创建一个 tcpserver 对象,向其构造函数传入默认 IP 地址与端口号,并依次调用 init() 与 start() 方法。以上便是 tcpserver.cpp 的基本实现逻辑。
cpp
#include"tcpserver.h"
void usage(const char* programname)
{
std::cout << "usage :" << programname << " <port> " << std::endl;
}
int main(int argc, char* argv[])
{
if (argc != 2)
{
usage(argv[0]);
exit(Usage_Error);
}
uint16_t port=std::stoi(argv[1]);
tcpserver server(_deafult,port);
server.init();
server.start();
return 0;
}TCP服务端源码(1):
tcpserver.h:
cpp
#pragma once
#include<iostream>
#include<string>
#include<cstring>
#include<unistd.h>
#include<sys/socket.h>
#include<arpa/inet.h>
#include<netinet/in.h>
#include<thread>
#include"log.hpp"
#define buffer_size 1024
log log;
std::string _deafult = "0.0.0.0";
enum
{
Usage_Error=1,
Socket_Error,
Bind_Error,
Listen_Error,
Accept_Error,
};
class clientData
{
public:
int acc_socketfd;
struct sockaddr_in client;
};
/*处理客户端连接的线程函数*/
void run(clientData con, int id)
{
// 记录线程启动信息
log.logmessage(info, "connect_thread %d is running", id);
// 创建数据接收缓冲区
char buffer[buffer_size];
// 持续处理客户端请求的循环
while (1)
{
// 从客户端套接字读取数据
int n = read(con.acc_socketfd, buffer, sizeof(buffer));
// 处理读取错误情况
if (n < 0)
{
// 记录致命错误
log.logmessage(Fatal, "connect_thread %d read error",id);
// 关闭客户端套接字
close(con.acc_socketfd);
// 退出循环
break;
}
// 处理客户端关闭连接情况
else if (n == 0)
{
// 记录连接关闭信息
log.logmessage(info, "connect_thread %d close",id);
// 关闭客户端套接字
close(con.acc_socketfd);
// 退出循环
break;
}
// 处理正常数据接收情况
else
{
// 添加字符串终止符,确保正确处理接收到的数据
buffer[n] = '\0';
// 记录接收到的消息
log.logmessage(info, "connect_thread %d recive a message : %s", id, buffer);
// 构建回显响应消息
std::string response = "server echo:" + std::string(buffer);
// 向客户端发送响应
n = write(con.acc_socketfd, response.c_str(), response.size());
// 处理写入错误情况
if (n < 0)
{
// 记录致命错误
log.logmessage(Fatal, "connect_thread %d write error",id);
// 关闭客户端套接字
close(con.acc_socketfd);
// 退出循环
break;
}
}
}
}
class tcpserver
{
public:
tcpserver(std::string _ip , uint16_t _port)
:ip(_ip)
, port(_port)
{
}
/* 初始化服务器监听套接字
* 该函数负责创建并配置服务器监听套接字,包括:
* 1. 创建TCP套接字
* 2. 绑定服务器IP地址和端口号
* 3. 错误处理和日志记录*/
void init()
{
// 创建TCP套接字
// AF_INET: 使用IPv4协议
// SOCK_STREAM: 使用TCP协议
// 0: 自动选择协议类型
listen_socketfd = socket(AF_INET, SOCK_STREAM, 0);
// 检查套接字创建是否成功
if (listen_socketfd < 0)
{
// 记录套接字创建失败的致命错误
log.logmessage(Fatal, "socket error");
// 退出程序,返回套接字错误码
exit(Socket_Error);
}
// 记录套接字创建成功信息
log.logmessage(info, "create socket successfully");
// 初始化服务器地址结构体
struct sockaddr_in server;
// 将结构体内存清零,确保没有脏数据
memset(&server, 0, sizeof(server));
// 设置服务器地址参数
server.sin_family = AF_INET; // 使用IPv4协议
server.sin_port = htons(port); // 设置端口号,htons转换字节序
server.sin_addr.s_addr = inet_addr(ip.c_str()); // 设置IP地址,转换字符串格式
// 将套接字绑定到指定地址和端口
if (bind(listen_socketfd, (struct sockaddr*)&server, sizeof(server)) < 0)
{
// 记录绑定失败的致命错误
log.logmessage(Fatal, "bind error");
// 关闭已创建的套接字
close(listen_socketfd);
// 重置套接字描述符为无效值
listen_socketfd = -1;
// 退出程序,返回绑定错误码
exit(Bind_Error);
}
// 记录绑定成功信息
log.logmessage(info, "bind successfully");
}
/* 启动服务器,开始监听和接受客户端连接
* 该函数实现服务器的核心功能:
* 1. 设置监听队列
* 2. 持续接受客户端连接
* 3. 为每个连接创建独立的处理线程*/
void start()
{
// 初始化客户端地址结构体
struct sockaddr_in _client;
memset(&_client, 0, sizeof(_client)); // 清零结构体
_client.sin_family = AF_INET; // 设置为IPv4协议族
socklen_t clientlen = sizeof(_client); // 客户端地址结构体长度
size_t id = 0; // 连接ID计数器,用于标识不同连接
// 设置监听队列,最大等待连接数为5
int n = listen(listen_socketfd, 5);
if (n < 0)
{
// 记录监听失败的致命错误
log.logmessage(Fatal, "listen error");
// 退出程序,返回监听错误码
exit(Listen_Error);
}
// 主循环:持续接受新的客户端连接
while (true)
{
// 记录服务器正在监听状态
log.logmessage(info, "listen successfully");
// 接受新的客户端连接
// 参数:监听套接字、客户端地址结构体指针、地址结构体长度指针
int fd = accept(listen_socketfd, (struct sockaddr*)&_client, &clientlen);
if (fd < 0)
{
// 记录接受连接失败的致命错误
log.logmessage(Fatal, "accept error");
// 关闭监听套接字
close(listen_socketfd);
// 重置套接字描述符为无效值
listen_socketfd = -1;
// 退出程序,返回接受错误码
exit(Accept_Error);
}
// 记录成功接受新连接
log.logmessage(info, "accept successfully");
// 创建新线程处理客户端连接
// 参数:处理函数、客户端数据结构、连接ID
std::thread connect_thread(run, clientData{ fd, _client }, id++);
// 分离线程,使其独立运行
// 主线程不需要等待子线程结束
connect_thread.detach();
}
}
// 析构函数,用于释放tcpserver类的资源
~tcpserver()
{
// 检查监听套接字描述符是否有效
if(listen_socketfd==-1)
{
// 如果套接字描述符有效,则关闭套接字
close(listen_socketfd);
}
}
private:
int listen_socketfd;
std::string ip;
uint16_t port;
};tcpserver.cpp:
cpp
#include"tcpserver.h"
void usage(const char* programname)
{
std::cout << "usage :" << programname << " <port> " << std::endl;
}
int main(int argc, char* argv[])
{
// 检查命令行参数个数是否正确
// 程序需要且仅需要一个端口号参数
if (argc != 2)
{
// 打印程序使用方法
usage(argv[0]);
// 退出程序,返回参数错误码
exit(Usage_Error);
}
// 将命令行参数(端口号)从字符串转换为整数
uint16_t port = std::stoi(argv[1]);
// 创建TCP服务器实例
// 参数:默认IP地址,用户指定的端口号
tcpserver server(_deafult, port);
// 初始化服务器
// 包括创建套接字、绑定地址等操作
server.init();
// 启动服务器
// 开始监听和接受客户端连接
server.start();
// 程序正常退出
return 0;
}TCP客户端(1)
接下来是实现TCP客户端。运行在Linux上的进程通常通过命令行启动,因此我们可以通过命令行传递配置信息,例如服务端的IP地址和端口号。命令行参数本质上是字符串,shell 会以空格为分隔符,将字符串划分为命令名和参数,并存入字符串数组传递给进程的 main 函数。这里的参数包括程序名、IP 地址和端口号,因此参数个数应为3。客户端进程首先应检查参数个数是否正确,若不正确则打印错误信息并以非零退出码退出。
若参数个数正确,则获取IP地址和端口号,并使用 std::stoi 将端口号从字符串转换为整型。接着,调用 socket 接口创建套接字,并检查其返回值。若返回值小于0,表示套接字创建失败,此时应打印错误日志并返回非零退出码。若创建成功,则进入下一步:连接服务端。
在调用 connect 之前,需先准备并初始化一个对应服务端进程的地址结构体,将之前获取的IP地址和端口号填入相应字段。初始化完成后,将套接字文件描述符和该地址结构体传递给 connect 接口,并检查其返回值。若返回值小于0,则调用 close 清理套接字资源,打印错误日志并退出;若等于0,则进入通信环节。
在通信开始前,需要准备一个输出缓冲区。随后进入 while 循环,执行通信核心逻辑。客户端发送给服务端的数据来自用户键盘输入的字符串,因此首先调用 std::cin.getline 函数获取用户输入,并存入输出缓冲区。
在调用 write 接口前,需检查用户输入的字符串内容。这里会使用 strcmp 函数进行比较,若用户输入为 "quit" ,则表示客户端希望终止本端通信,此时应调用 close 并退出循环。
若用户输入的不是 "quit" ,说明是有效内容,将缓冲区内的字符串发送给服务端。之后检查 write 的返回值,若小于0,表示写入失败,无法继续通信,此时应打印错误日志、调用 close 清理套接字资源并退出。
最后一步是调用 read 接口接收服务端处理后的结果,将得到的字符串存回输出缓冲区。注意,在调用 read 前应先清空缓冲区,读取后再将缓冲区内的字符串打印到显示器上。以上便是客户端进程的核心逻辑。
TCP客户端源码(1)
client.cpp:
cpp
#include<iostream>
#include<unistd.h>
#include<sys/socket.h>
#include<sys/types.h>
#include<arpa/inet.h>
#include<netinet/in.h>
#include<string>
#include<cstring>
#include"log.hpp"
#define buffer_size 1024
log log;
enum
{
Usage_Error=1,
Socket_Error,
Connect_Error,
Write_Error,
Read_Error,
};
void usage(const char* programname)
{
std::cout << "usage : " << programname << " <ip> <port>" << std::endl;
}
/*
* 实现一个简单的TCP客户端,功能包括:
* 1. 连接到指定的服务器
* 2. 发送用户输入的消息
* 3. 接收并显示服务器的响应*/
int main(int argc, char* argv[])
{
// 检查命令行参数个数是否正确
// 需要提供服务器IP和端口号两个参数
if (argc != 3)
{
// 打印程序使用方法
usage(argv[0]);
// 退出程序,返回参数错误码
exit(Usage_Error);
}
// 获取服务器IP地址
std::string ip = argv[1];
// 获取服务器端口号并转换为整数
uint16_t port = std::stoi(argv[2]);
// 创建TCP套接字
int socketfd = socket(AF_INET, SOCK_STREAM, 0);
if (socketfd < 0)
{
// 记录套接字创建失败的致命错误
log.logmessage(Fatal, "socket error");
// 退出程序,返回套接字错误码
exit(Socket_Error);
}
// 初始化服务器地址结构体
struct sockaddr_in server;
memset(&server, 0, sizeof(server)); // 清零结构体
server.sin_family = AF_INET; // 设置IPv4协议
server.sin_port = htons(port); // 设置端口号(转换字节序)
server.sin_addr.s_addr = inet_addr(ip.c_str()); // 设置IP地址
socklen_t serverlen = sizeof(server); // 地址结构体长度
// 连接到服务器
int connect_result = connect(socketfd, (struct sockaddr*)&server, serverlen);
if (connect_result < 0)
{
// 记录连接失败的致命错误
log.logmessage(Fatal, "connect error");
// 关闭套接字
close(socketfd);
// 退出程序,返回连接错误码
exit(Connect_Error);
}
// 创建消息缓冲区
char buffer[buffer_size];
// 主循环:处理用户输入和服务器的响应
while (true)
{
// 提示用户输入消息
std::cout << "please Enter message: " << std::endl;
// 获取用户输入
std::cin.getline(buffer, sizeof(buffer));
int len = strlen(buffer);
// 处理空输入
if (len == 0)
{
continue;
}
// 检查是否要退出程序
if (strcmp(buffer, "quit") == 0)
{
// 记录客户端退出信息
log.logmessage(info, "client quit");
break;
}
// 发送消息到服务器
int write_result = write(socketfd, buffer, len);
if (write_result < 0)
{
// 记录写入失败的致命错误
log.logmessage(Fatal, "write error");
// 退出程序,返回写入错误码
exit(Write_Error);
}
// 清空缓冲区,准备接收服务器响应
memset(buffer, 0, sizeof(buffer));
// 读取服务器响应
int read_result = read(socketfd, buffer, sizeof(buffer));
// 处理读取错误
if (read_result < 0)
{
// 记录读取失败的致命错误
log.logmessage(Fatal, "read error");
// 退出程序,返回读取错误码
exit(Read_Error);
}
// 处理服务器断开连接
else if (read_result == 0)
{
// 记录服务器断开连接信息
log.logmessage(info, "server disconnect");
break;
}
// 处理正常接收到的数据
else
{
// 添加字符串终止符
buffer[read_result] = '\0';
// 显示服务器响应
std::cout << buffer << std::endl;
}
}
// 关闭套接字
close(socketfd);
// 程序正常退出
return 0;
}运行截图:
TCP服务端(2)
tcpserver.h :
在本版本的服务端设计中,我们需解决一个关键问题:原设计中,服务端为每个客户端提供的是长服务。只要客户端不主动断开,为其创建的套接字就会一直保持连接以进行通信。然而,端口号是一种有限的系统资源。当服务端需要并发处理大量客户端的连接请求时,可能导致端口耗尽。因此,在实际场景中,服务端通常向客户端提供的是短服务。
所谓短服务,是指客户端向服务端的已连接套接字发送一个请求,服务端接收并处理该请求后,将响应结果返回给客户端,随即主动结束本次通信。换言之,服务端在一次连接中仅处理一个请求。客户端在收到响应后,也应主动关闭连接。若需再次发送请求,则必须重新调用 connect 接口建立新连接,服务端会为其分配新的套接字以提供下一次短服务。
明确这一点后,我们即可基于原有代码进行修改。整体上, tcpserver 类的框架保持不变。考虑到端口资源的有限性及短服务的特性,我们可以引入线程池机制。
此时,已连接套接字与客户端之间的通信内容可作为线程的上下文。我们可以预先创建一批线程,而主线程则负责生产任务。每个任务对应一次短服务,即一次完整的请求-响应交互。这里使用 Task 类来描述一个任务,其中封装了通信所需的相关信息:已连接套接字的文件描述符,以及记录客户端地址信息的结构体。
Task 类的 run 方法包含了通信的具体逻辑。由于是短服务,其内部不再使用死循环,而是处理完一次请求后即结束。具体的短服务内容将在后续详细说明。
cpp
class Task
{
public:
Task() {}
Task(int _socketfd, struct sockaddr_in _client)
: socketfd(_socketfd)
, client(_client)
{}
void run()
{
// 短服务处理逻辑
}
private:
int socketfd;
struct sockaddr_in client;
};线程池本质上是生产者-消费者模型的一个实现。在本设计中,生产者是服务端进程的主线程,其主要工作包括:
- 创建线程池对象(该线程池被设计为单例类,需通过静态成员方法获取实例)。
- 调用线程池的
start方法,该方法会初始化并启动一批工作线程。 - 不断接受客户端连接,每成功建立一个连接(即
accept返回后),就创建一个Task对象,并将其提交给线程池。
线程池内部维护一个环形缓冲区(通常由数组实现),生产者通过 push 方法将任务放入缓冲区,消费者(工作线程)则通过 pop 方法获取任务并执行。这部分逻辑应放置在 tcpserver 的 start 方法中。
cpp
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <thread>
#include "log.hpp"
#define BUFFER_SIZE 1024
extern log logger;
std::string default_ip = "0.0.0.0";
enum ErrorCode {
Usage_Error = 1,
Socket_Error,
Bind_Error,
Listen_Error,
Accept_Error,
Open_Error,
};
#include "Threadpool.h"
class tcpserver
{
public:
tcpserver(std::string _ip, uint16_t _port)
: ip(_ip)
, port(_port)
, listen_socketfd(-1)
{}
void init()
{
// 创建监听套接字、绑定地址等初始化操作
}
void start()
{
threadpool::getinstance().start();
struct sockaddr_in client_addr;
memset(&client_addr, 0, sizeof(client_addr));
client_addr.sin_family = AF_INET;
socklen_t addr_len = sizeof(client_addr);
// 将套接字置于监听状态
int ret = listen(listen_socketfd, 5);
if (ret < 0) {
logger.logmessage(Fatal, "listen error");
close(listen_socketfd);
listen_socketfd = -1;
exit(Listen_Error);
}
while (true) {
logger.logmessage(Info, "listening...");
int conn_fd = accept(listen_socketfd, (struct sockaddr*)&client_addr, &addr_len);
if (conn_fd < 0) {
logger.logmessage(Fatal, "accept error");
close(listen_socketfd);
listen_socketfd = -1;
exit(Accept_Error);
}
logger.logmessage(Info, "accept successfully");
// 创建任务并提交到线程池
Task task(conn_fd, client_addr);
threadpool::getinstance().push(task);
}
}
~tcpserver()
{
if (listen_socketfd != -1) {
close(listen_socketfd);
}
}
private:
int listen_socketfd;
std::string ip;
uint16_t port;
};环形缓冲区通过数组实现,生产者和消费者各自维护一个索引。生产者将任务放入当前索引位置后递增索引;消费者从索引位置取出任务后递增索引。当缓冲区为空时,消费者阻塞等待;当缓冲区满时,生产者阻塞等待。由于采用多消费者模式,消费能力通常高于生产能力,因此常见的情况是消费者等待。
生产者和消费者之间的同步通过两个信号量实现:一个表示空闲槽位数量,另一个表示有效任务数量。当信号量值为0时,相应线程会阻塞。此外,由于多个消费者线程可能同时访问缓冲区,需要通过互斥锁保证操作的原子性。
cpp
class threadpool
{
public:
static threadpool& getinstance() {
static threadpool instance;
return instance;
}
Task pop() {
// 消费者取出任务
}
void push(const Task& t) {
// 生产者放入任务
}
private:
threadpool(int max_thread_num = MAX_SIZE, int max_task_num = MAX_SIZE)
: max_threads(max_thread_num)
, consumer_idx(0)
, producer_idx(0)
, max_tasks(max_task_num)
{
task_queue.resize(max_tasks);
pthread_mutex_init(&queue_mutex, NULL);
sem_init(&task_count, 0, 0); // 初始无任务
sem_init(&free_slots, 0, max_tasks); // 初始全为空闲
}
static void* worker_thread(void* arg) {
threadpool* pool = (threadpool*)arg;
while (true) {
Task task = pool->pop();
task.run();
}
return NULL;
}
std::vector<Task> task_queue;
int max_threads;
pthread_mutex_t queue_mutex;
int max_tasks;
int consumer_idx;
int producer_idx;
sem_t task_count; // 当前有效任务数
sem_t free_slots; // 当前空闲槽位数
};对于服务端, start 方法的主要修改在于:获取线程池实例,将监听套接字设为监听状态,然后循环接受客户端连接。每接受一个连接,就创建对应的 Task 对象并提交给线程池,主线程随即继续监听。
其他方法如 init 则保持不变,仍负责创建监听套接字、绑定地址等初始化工作。若 socket 或 bind 调用失败,会记录错误日志、清理资源并退出。
tcpserver.cpp :
接下来设计服务端的主程序。在 Linux 环境中,进程通常通过命令行启动,并可通过命令行参数传递配置信息。这里我们将服务端监听的 IP 地址和端口号通过参数传入。通常,服务端监听 0.0.0.0 以接受所有网络接口的连接,因此我们只需在命令行中指定端口号。
主程序首先检查参数个数是否为2(程序名 + 端口号)。若不是,则打印使用说明并以非零状态退出。命令行参数以字符串形式传递,因此需要将端口号字符串转换为整数(使用 std::stoi )。随后创建 tcpserver 对象,依次调用其 init 和 start 方法启动服务。
cpp
#include "tcpserver.h"
#include "log.hpp"
log logger;
file_reader reader;
void usage(const char* prog_name) {
std::cout << "Usage: " << prog_name << " <port>" << std::endl;
}
int main(int argc, char* argv[]) {
if (argc != 2) {
usage(argv[0]);
exit(Usage_Error);
}
uint16_t port = std::stoi(argv[1]);
tcpserver server(default_ip, port);
server.init();
server.start();
return 0;
}在明确了服务器端整体框架与实现细节后,目前唯一尚未阐述的部分是服务器向客户端提供的短服务。接下来,我们将聚焦于这一短服务的具体设计与实现。
此处的短服务可沿用先前的设计思路:服务器接收客户端发送的字符串,经处理后添加服务器标识信息,再返回给客户端,随后服务终止。本次我在原有基础上对该短服务进行了调整,将其功能确定为字典查询。
具体而言,我们会创建一个文本文件,其中每行包含一个二元组,分别为英文单词及其中文释义。客户端请求内容为一个英文单词,服务器在接收到该数据后,将在文本文件中查找匹配的英文单词,并将其对应的中文释义返回给客户端,随后服务结束。

因此,我们首先需要准备一个文本文件,其中包含若干行这样的二元组。接着,我将字典查询功能也封装为一个对象,通过 file_reader 类来描述。这部分会涉及 C++ 的文件操作。C++ 作为一门面向对象的语言,将各种 I/O 操作视为流对象,文件 I/O 也不例外,其标准库提供了 ifstream 与 ofstream 两个类,分别用于文件读取与文件写入。在本设计中, file_reader 类将封装一个 ifstream 对象。
file_reader 类的构造函数接收一个字符串参数,表示字典文件名,随后调用 ifstream 的 open 方法打开该文件,并通过 is_open 方法检查是否打开成功。若打开成功,则输出相应日志;若失败,则记录错误日志并退出程序。
文件成功打开后,下一步是初始化数据结构。由于文件内容为二元组形式,我选用哈希表进行存储,其中键为英文单词,值为对应的中文释义。因此,我们需要读取文件内容并初始化该哈希表,这部分逻辑放置在 getvalue 方法中。
标准库中的 getline 函数用于从流对象中读取数据。我们将 ifstream 对象传递给 getline ,该函数会从与文件关联的内核缓冲区中读取数据,加载到流对象内部维护的流缓冲区中(通常为 4KB)。文件以行为单位存储,每行末尾有换行符。Linux 系统中换行符为 "\n" ,Windows 中则为 \r\n 。 \r 将文件指针定位至行首, \n 将其移至下一行。当读取至行尾(即换行符)且流缓冲区未满时,文件指针会移至下一行继续读取,直至流缓冲区填满或抵达文件末尾。随后,流缓冲区中的字符将被逐个插入到 string 对象中,遇到换行符时停止,且换行符不会被存入 string 。
再次调用 getline 时,会先检查流缓冲区是否为空。若非空,则继续逐字节读取直至换行符;若为空,则从文件的内核缓冲区加载新数据至流缓冲区。 getline 返回流对象本身,并通过类型转换运算符重载返回布尔值:流状态正常时为 true ,出错时为 false 。
整个数据读取流程可概括为:
cpp
磁盘文件
↓ 块读取(4KB+)
内核缓冲区
↓ 内存复制
流缓冲区(streambuf)
↓ 逐个字符
getline读取
↓
string对象借助 while 循环,我们可以逐行读取文件内容到 string 对象中。在循环体内,我们对每行字符串进行分割。由于二元组格式为"英文:中文",因此以":"为分隔符,提取英文部分作为键,中文部分作为值,插入哈希表中。
cpp
class file_reader
{
public:
file_reader(std::string _filename = filename)
{
fin.open(_filename);
if (!fin.is_open())
{
logger.logmessage(Fatal, "file open error");
exit(Open_Error);
}
logger.logmessage(info, "file open successfully");
getvalue();
}
void getvalue()
{
std::string line;
while (std::getline(fin, line))
{
auto pos = line.find(":");
std::string map_key = line.substr(0, pos);
std::string map_value = line.substr(pos + 1);
data_map[map_key] = map_value;
}
}
// ...
private:
std::ifstream fin;
std::unordered_map<std::string, std::string> data_map;
};此外, file_reader 类还提供一个 translate 方法,接收一个键(英文单词),查询哈希表中是否存在该键。若存在,则返回对应的中文字符串;若未找到,则返回 "unknown" 。
cpp
std::string translate(const std::string& key)
{
auto it = data_map.find(key);
if (it != data_map.end())
{
return it->second;
}
return "unknown";
}析构函数负责关闭文件。 file_reader 类的实现位于 init.hpp 文件中。其他文件(如 Task.h )需引用该文件,以便创建 file_reader 对象。在 Task 类的 run 方法中,首先调用 read 读取客户端发送的字符串(即待查询的单词),根据 read 的返回值进行相应处理:若返回值小于 0,记录错误日志并退出;若等于 0,表示客户端已关闭连接,直接退出;若大于 0,则调用 file_reader 的 translate 方法获取翻译结果,并通过 write 返回给客户端。
cpp
void run()
{
std::string key;
char buffer[1024];
int n = read(socketfd, buffer, sizeof(buffer));
if (n < 0)
{
logger.logmessage(Fatal, "read error");
close(socketfd);
return;
}
else if (n == 0)
{
logger.logmessage(info, "client disconnect");
close(socketfd);
return;
}
else
{
buffer[n] = '\0';
key = buffer;
logger.logmessage(info, "recive a message:%s", buffer);
std::string response = reader.translate(key);
n = write(socketfd, response.c_str(), response.size());
if (n < 0)
{
logger.logmessage(Fatal, "write error");
close(socketfd);
return;
}
}
}TCP服务端源码(2)
tcpserver.h:
cpp
#pragma once
#include<iostream>
#include<string>
#include<cstring>
#include<unistd.h>
#include<sys/socket.h>
#include<arpa/inet.h>
#include<netinet/in.h>
#include<thread>
#include"log.hpp"
#define buffer_size 1024
extern log logger;
std::string _deafult = "0.0.0.0";
enum
{
Usage_Error=1,
Socket_Error,
Bind_Error,
Listen_Error,
Accept_Error,
Open_Error,
};
#include"Threadpool.h"
class tcpserver
{
public:
tcpserver(std::string _ip, uint16_t _port)
:ip(_ip)
, port(_port)
{
}
void init()
{
// 创建TCP套接字
// AF_INET: 使用IPv4协议族
// SOCK_STREAM: 使用TCP协议
// 0: 自动选择协议类型
listen_socketfd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_socketfd < 0)
{
// 如果套接字创建失败,记录致命错误日志并退出程序
logger.logmessage(Fatal, "socket error");
exit(Socket_Error);
}
// 记录套接字创建成功的日志
logger.logmessage(info, "create socket successfully");
// 配置服务器地址信息
struct sockaddr_in server;
// 初始化server结构体为0
memset(&server, 0, sizeof(server));
// 设置地址族为IPv4
server.sin_family = AF_INET;
// 将端口号从主机字节序转换为网络字节序
server.sin_port = htons(port);
// 将IP地址字符串转换为网络字节序的二进制格式
server.sin_addr.s_addr = inet_addr(ip.c_str());
// 将套接字与指定的IP地址和端口号绑定
if (bind(listen_socketfd, (struct sockaddr*)&server, sizeof(server)) < 0)
{
// 如果绑定失败,记录错误日志
logger.logmessage(Fatal,"bind error");
// 关闭已创建的套接字,释放资源
close(listen_socketfd);
// 将套接字描述符设置为无效值
listen_socketfd=-1;
// 退出程序
exit(Bind_Error);
}
// 记录绑定成功的日志
logger.logmessage(info,"bind successfully");
}
void start()
{
// 启动线程池,准备处理客户端请求
threadpool::getinstance().start();
// 初始化客户端地址结构体
struct sockaddr_in _client;
memset(&_client, 0, sizeof(_client));
_client.sin_family = AF_INET;
socklen_t clientlen = sizeof(_client);
size_t id = 0;
// 将套接字设置为监听模式
// 第二个参数5表示等待连接队列的最大长度
int n = listen(listen_socketfd, 5);
if(n < 0)
{
// 监听失败,记录错误日志
logger.logmessage(Fatal, "listen error");
// 关闭套接字,释放资源
close(listen_socketfd);
listen_socketfd = -1;
// 退出程序
exit(Listen_Error);
}
// 主循环:不断接受客户端连接
while (true)
{
// 记录监听成功的日志
logger.logmessage(info, "listen successfully");
// 接受客户端连接请求
// accept会阻塞直到有新的连接到来
// 返回一个新的套接字描述符用于与该客户端通信
int fd = accept(listen_socketfd, (struct sockaddr*)&_client, &clientlen);
if (fd < 0)
{
// 接受连接失败,记录错误日志
logger.logmessage(Fatal, "accept error");
// 清理资源并退出
close(listen_socketfd);
listen_socketfd = -1;
exit(Accept_Error);
}
// 记录成功接受连接的日志
logger.logmessage(info, "accept successfully");
// 创建任务对象,包含客户端套接字描述符和地址信息
Task T(fd, _client);
// 将任务推入线程池的任务队列中,由线程池中的工作线程处理
threadpool::getinstance().push(T);
}
}
~tcpserver()
{
if(listen_socketfd!=-1)
{
close(listen_socketfd);
}
}
private:
int listen_socketfd;
std::string ip;
uint16_t port;
};Task.h:
cpp
#pragma once
#include <iostream>
#include"init.hpp"
extern file_reader reader;
extern log logger;
class Task
{
public:
Task()
{
}
Task(int _socketfd, struct sockaddr_in _client)
:socketfd(_socketfd)
,client(_client)
{
}
void run()
{
// 声明用于存储客户端消息的字符串key
std::string key;
// 定义缓冲区,用于存储从客户端读取的数据
char buffer[1024];
// 从套接字读取客户端发送的数据
// 参数:socketfd-套接字描述符,buffer-数据缓冲区,sizeof(buffer)-缓冲区大小
// 返回值:实际读取的字节数
int n = read(socketfd, buffer, sizeof(buffer));
if (n < 0)
{
// 读取失败,记录致命错误日志
logger.logmessage(Fatal, "read error");
// 关闭套接字,释放资源
close(socketfd);
return;
}
else if (n == 0)
{
// 读取返回0表示客户端已断开连接
logger.logmessage(info, "client disconnect");
// 关闭套接字
close(socketfd);
return;
}
else
{
// 在数据末尾添加字符串结束符,确保字符串正确性
buffer[n] = '\0';
// 将接收到的数据转换为字符串
key = buffer;
// 记录接收到的消息内容
logger.logmessage(info, "recive a message:%s", buffer);
// 使用reader对象翻译/处理接收到的消息
std::string response = reader.translate(key);
// 将处理后的响应发送回客户端
// 参数:socketfd-套接字描述符,response.c_str()-要发送的数据,response.size()-数据长度
n = write(socketfd, response.c_str(), response.size());
if (n < 0)
{
// 写入失败,记录致命错误日志
logger.logmessage(Fatal, "write error");
// 关闭套接字
close(socketfd);
return;
}
}
}
private:
int socketfd;
struct sockaddr_in client;
};Threadpool.h:
cpp
#include<pthread.h>
#include<semaphore.h>
#include<string>
#include<vector>
#include"Task.h"
#define max_size 10
class threadpool
{
public:
static threadpool& getinstance()
{
static threadpool instance;
return instance;
}
Task pop()
{
// 等待元素信号量,确保队列中有任务可取
// 如果队列为空,线程会在此处阻塞
sem_wait(&element);
// 获取互斥锁,确保对队列的访问是线程安全的
// 防止多个线程同时访问队列造成数据竞争
pthread_mutex_lock(&mutex);
// 从队列中取出当前任务
// c_index是当前消费位置的下标
Task data = q[c_index];
// 更新消费位置下标
// 使用取模运算实现循环队列
c_index = (c_index + 1) % Max_task_size;
// 释放互斥锁,允许其他线程访问队列
pthread_mutex_unlock(&mutex);
// 增加空间信号量,表示队列中多了一个空闲位置
// 通知可能等待的生产者可以继续添加任务
sem_post(&space);
// 返回取出的任务
return data;
}
void push(const Task& T)
{
// 等待空间信号量,确保队列中有空闲位置
// 如果队列已满,线程会在此处阻塞,直到有消费者取出任务
sem_wait(&space);
// 将新任务T放入队列的当前位置
// p_index是生产者位置的下标
q[p_index] = T;
// 更新生产者位置下标
// 使用取模运算实现循环队列,当到达末尾时回到开头
p_index = (p_index + 1) % Max_task_size;
// 增加元素信号量,表示队列中多了一个任务
// 通知可能等待的消费者可以取出新任务
sem_post(&element);
}
~threadpool()
{
pthread_mutex_destroy(&mutex);
sem_destroy(&element);
sem_destroy(&space);
}
threadpool(const threadpool&)=delete;
threadpool& operator=(const threadpool&)=delete;
private:
threadpool(int max_num = max_size, int max_task_size = max_size)
:Max_size(max_num)
,c_index(0)
,p_index(0)
,Max_task_size(max_task_size)
{
q.resize(Max_task_size);
pthread_mutex_init(&mutex,NULL);
sem_init(&element,0,0);
sem_init(&space,0,Max_task_size);
}
static void* handlertask(void* args)
{
// 将传入的void*参数转换为线程池对象指针
// args是在创建线程时传入的线程池对象指针
threadpool* tp = (threadpool*)args;
// 工作线程的主循环
// 线程会持续运行,直到程序结束
while(1)
{
// 从线程池的任务队列中取出一个任务
// 如果队列为空,pop函数会阻塞等待,直到有新任务
Task task = tp->pop();
// 执行取出的任务
// 调用Task对象的run方法处理具体的业务逻辑
task.run();
}
// 理论上这行代码不会被执行到,因为while(1)是无限循环
// 但为了函数完整性,仍然保留返回语句
return NULL;
}
std::vector<Task> q;
int Max_size;
pthread_mutex_t mutex;
int Max_task_size;
int c_index;
int p_index;
sem_t element;
sem_t space;
};init.hpp
cpp
#include<fstream>
#include<string>
#include<unordered_map>
#include"log.hpp"
extern log logger;
std::string filename="text.txt";
class file_reader
{
public:
// file_reader类的构造函数
// 参数:_filename - 要打开的文件名,默认值为全局变量filename
file_reader(std::string _filename=filename)
{
// 尝试打开指定的文件
// 使用ifstream对象fin进行文件操作
fin.open(_filename);
// 检查文件是否成功打开
if(!fin.is_open())
{
// 文件打开失败,记录致命错误日志
logger.logmessage(Fatal, "file open error");
// 退出程序,使用Open_Error作为退出码
exit(Open_Error);
}
// 文件打开成功,记录信息日志
logger.logmessage(info, "file open successfully");
// 调用getvalue()函数读取文件内容
// 这个函数应该在类中定义,用于处理文件的具体读取逻辑
getvalue();
}
void getvalue()
{
// 定义字符串变量用于存储每一行的内容
std::string line;
// 使用getline逐行读取文件内容,直到文件末尾
// fin是文件输入流对象,line用于存储读取的一行内容
while(std::getline(fin, line))
{
// 查找分隔符":"的位置
// find返回分隔符第一次出现的迭代器位置
auto pos = line.find(":");
// 提取键(key)部分
// substr(0, pos)获取从开头到分隔符位置的所有字符
std::string map_key = line.substr(0, pos);
// 提取值(value)部分
// substr(pos+1)获取从分隔符后一位开始到行尾的所有字符
std::string map_value = line.substr(pos + 1);
// 将解析出的键值对存入map中
// 使用[]操作符插入或更新map中的元素
data_map[map_key] = map_value;
}
}
// 翻译函数:根据给定的键查找对应的值
// 参数:key - 要查找的键,以const引用方式传递,避免拷贝
// 返回值:如果找到对应的值则返回该值,否则返回"unknown"
std::string translate(const std::string& key)
{
// 在map中查找指定的键
// find()返回一个迭代器,指向找到的元素,若未找到则返回end()
auto it = data_map.find(key);
// 检查是否找到了对应的键
// it != data_map.end() 表示找到了匹配的键值对
if(it != data_map.end())
{
// 找到了键,返回对应的值
// it->second 访问迭代器指向的元素的值部分
return it->second;
}
// 如果没有找到对应的键,返回默认值"unknown"
return "unknown";
}
~file_reader()
{
fin.close();
}
private:
std::ifstream fin;
std::unordered_map<std::string,std::string> data_map;
};
extern file_reader reader;TCP客户端(2)
而这里接下来就是实现第二个版本的客户端,那么我们知道这里服务端提供给客户端的服务是短服务 ,也就是处理一次请求,不会持续通信,所以这里对于而我们知道TCP是点对点通信,那么由于这里是短服务,那么服务端的已连接套接字响应了客户端的请求之后,那么就关闭了,所以这里对于客户端来说,一旦收到了客户端发来的数据之后,一定得关闭套接字,然后再创建一个新的套接字然后再与服务端建立连接即调用 connect接口,然后又发出新的请求
所以这里调用socket接口以及connect接口以及close都在一个while循环挡住,在调用write接口之前,会准备一个输出缓冲区,那么进入while循环内,那么调用完socket以及connect接口之后,那么就是调用std::cin.getline获取用户的键盘输入,然后保存到输出缓冲区,在调用write接口之前,还是会检查字符串的内容是否是"quit" ,如果是,那么就直接诶退出循环,不是,那么说明缓冲区的字符串是有效内容,接着就调用write接口将缓冲区的有效字符串发送服务端,然后检查返回值,如果小于,打印错误日志信息,并且调用close清理套接字,然后退出,正常的话,就调用read,然后接收服务端发来的字符串,然后检查read的返回值,如果大于0,那么在字符结尾手动添加 '\0' ,并将字符串打印到显示器
TCP客户端源码(2)
cpp
#include<iostream>
#include<unistd.h>
#include<sys/socket.h>
#include<sys/types.h>
#include<arpa/inet.h>
#include<netinet/in.h>
#include<string>
#include<cstring>
#include"log.hpp"
#define buffer_size 1024
log log;
enum
{
Usage_Error=1,
Socket_Error,
Connect_Error,
Write_Error,
Read_Error,
};
void usage(const char* programname)
{
std::cout << "usage : " << programname << " <ip> <port>" << std::endl;
}
int main(int argc, char* argv[])
{
// 检查命令行参数数量
// 程序需要3个参数:程序名、服务器IP、端口号
if (argc != 3)
{
// 参数数量不正确,显示使用说明
usage(argv[0]);
// 退出程序,返回使用错误码
exit(Usage_Error);
}
// 从命令行参数获取服务器IP地址
std::string ip = argv[1];
// 从命令行参数获取端口号,并转换为整数
uint16_t port = std::stoi(argv[2]);
// 主循环:持续处理用户请求
while(true)
{
// 创建TCP套接字
// AF_INET: IPv4协议族
// SOCK_STREAM: TCP协议
int socketfd = socket(AF_INET, SOCK_STREAM, 0);
if (socketfd < 0)
{
// 套接字创建失败,记录错误日志
log.logmessage(Fatal, "socket error");
// 退出程序,返回套接字错误码
exit(Socket_Error);
}
// 设置服务器地址结构
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET; // IPv4协议
server.sin_port = htons(port); // 端口号(转换为网络字节序)
server.sin_addr.s_addr = inet_addr(ip.c_str()); // IP地址(转换为网络字节序)
socklen_t serverlen = sizeof(server);
// 连接到服务器
int connect_result = connect(socketfd, (struct sockaddr*)&server, serverlen);
if (connect_result < 0)
{
// 连接失败,记录错误日志
log.logmessage(Fatal, "connect error");
// 关闭套接字
close(socketfd);
// 退出程序,返回连接错误码
exit(Connect_Error);
}
// 准备缓冲区用于存储用户输入
char buffer[buffer_size];
// 提示用户输入消息
std::cout << "please Enter message: " << std::endl;
// 获取用户输入
std::cin.getline(buffer, sizeof(buffer));
int len = strlen(buffer);
// 检查输入是否为空
if (len == 0)
{
// 空输入,继续下一轮循环
continue;
}
// 检查用户是否要退出
if (strcmp(buffer, "quit") == 0)
{
// 记录退出日志
log.logmessage(info, "client quit");
// 退出主循环
break;
}
// 发送消息到服务器
int write_result = write(socketfd, buffer, len);
if (write_result < 0)
{
// 发送失败,记录错误日志
log.logmessage(Fatal, "write error");
// 退出程序,返回写入错误码
exit(Write_Error);
}
// 清空缓冲区,准备接收服务器响应
memset(buffer, 0, sizeof(buffer));
// 读取服务器响应
int read_result = read(socketfd, buffer, sizeof(buffer));
if (read_result < 0)
{
// 读取失败,记录错误日志
log.logmessage(Fatal, "read error");
// 退出程序,返回读取错误码
exit(Read_Error);
}
else if (read_result == 0)
{
// 服务器断开连接
log.logmessage(info, "server disconnect");
// 退出主循环
break;
}
else
{
// 成功接收到服务器响应
buffer[read_result] = '\0'; // 添加字符串结束符
// 显示服务器响应
std::cout << "server response :" << buffer << std::endl;
}
// 关闭当前连接的套接字
close(socketfd);
}
// 程序正常退出
return 0;
}
运行截图:
结语
那么这就是本文关于网络以及网络编程的全部内容,那么本文的信息密度以及知识密度极高,那么十分感谢耐心看到这里的读者,我下一期会继续更新网络编程的相关内容,我会持续更新,希望你能够多多关照,本期博客制作不易,如果对你有帮组的话,还请三连加关注,你的支持,就是我创作的最大动力!
