终于,InfiniSynapse 最新版本正式推出了机器学习功能。
InfiniSynapse 在此之前具备访问各种数据源,支持对不同数据源的数据做join关联,同时具备特征工程的能力,在此基础上,机器学习的到来也就水到渠成。
InfiniSynapse 涵盖了主流算法,比如线性回归类算法LinearRegressionr, 分类算法诸如随机森林,XGBoost, 时序类算法 ARIMA 等。
今天我以金融领域的评分卡为例,来介绍在 InfiniSynapse 中如何使用机器学习来完成金融评分卡。
我们会使用UCI信用卡违约数据集,这是一个高质量的融评分卡数据集。根据用户的年龄,还贷等各种特征,来判断用户下一个是否会违约。
准备数据
首先我们要连接数据,点击 数据源/创建数据库:
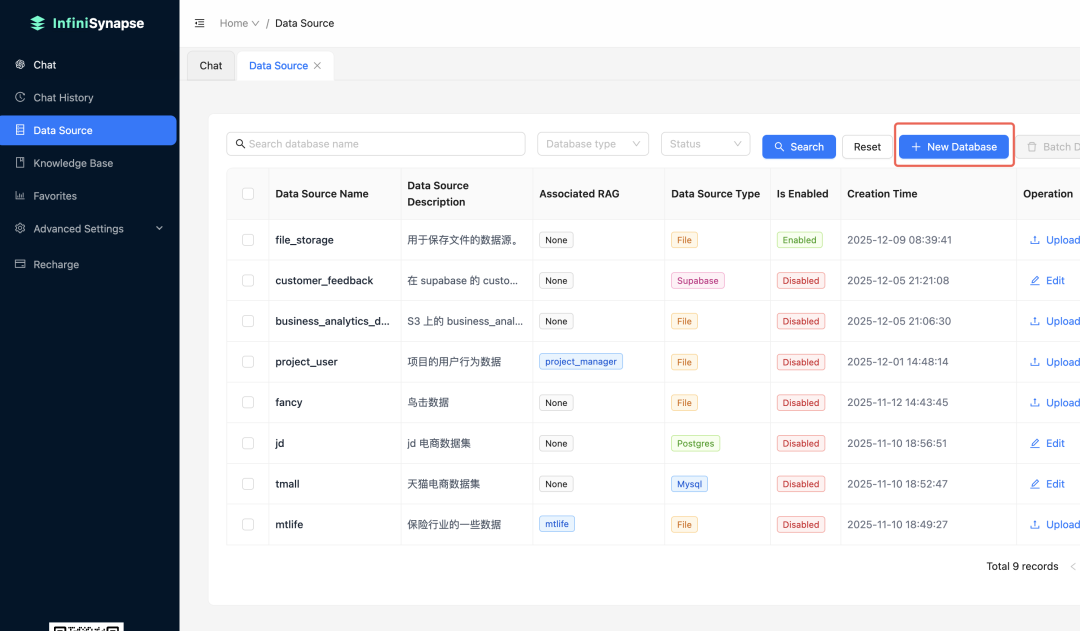
新建数据库 UCI_Credit_Card:
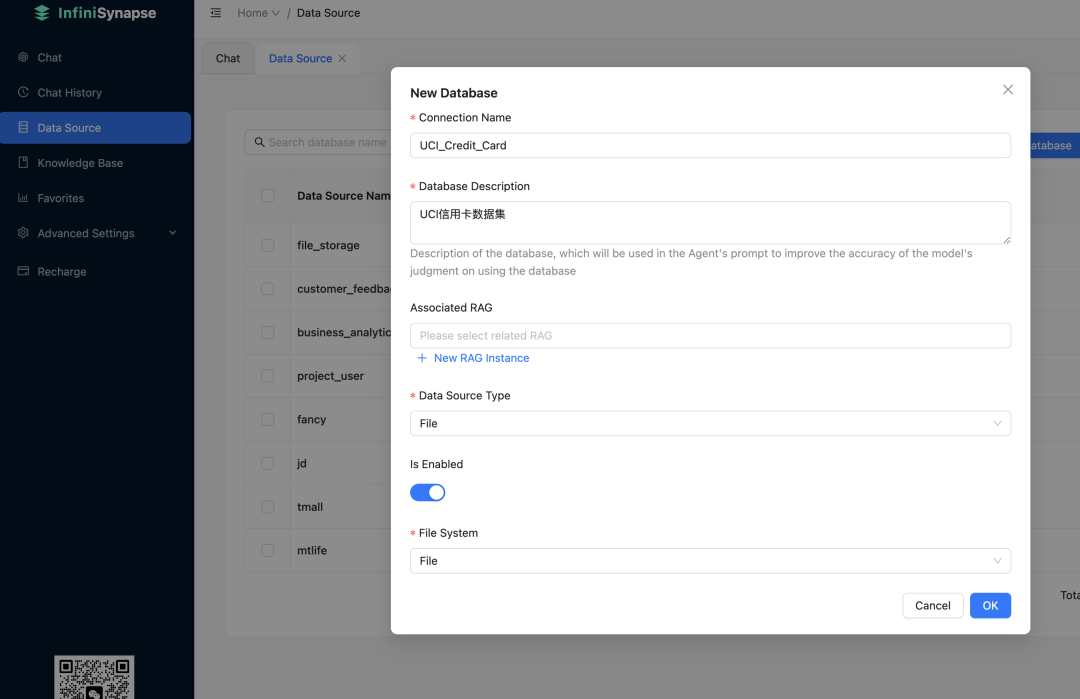
接着上传我们的UCI信用卡违约数据集:
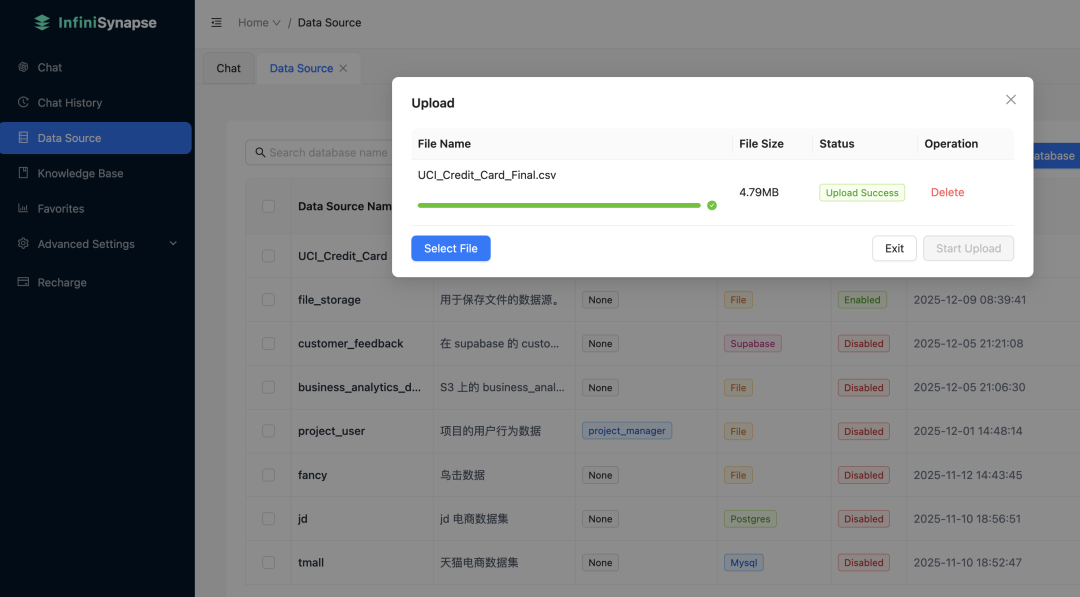
了解数据和算法
然后我们先了解下当前数据集的情况:
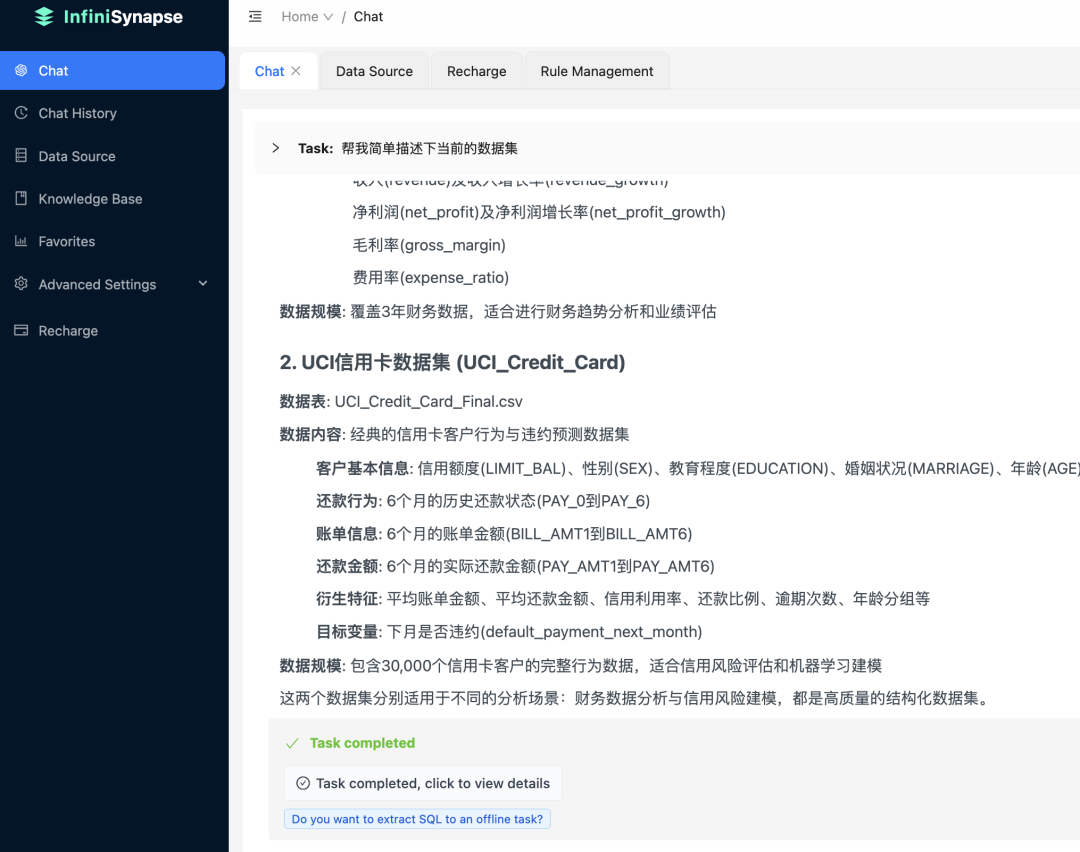
询问下 InfiniSynapse 有没有和评分卡相关的机器学习算法:
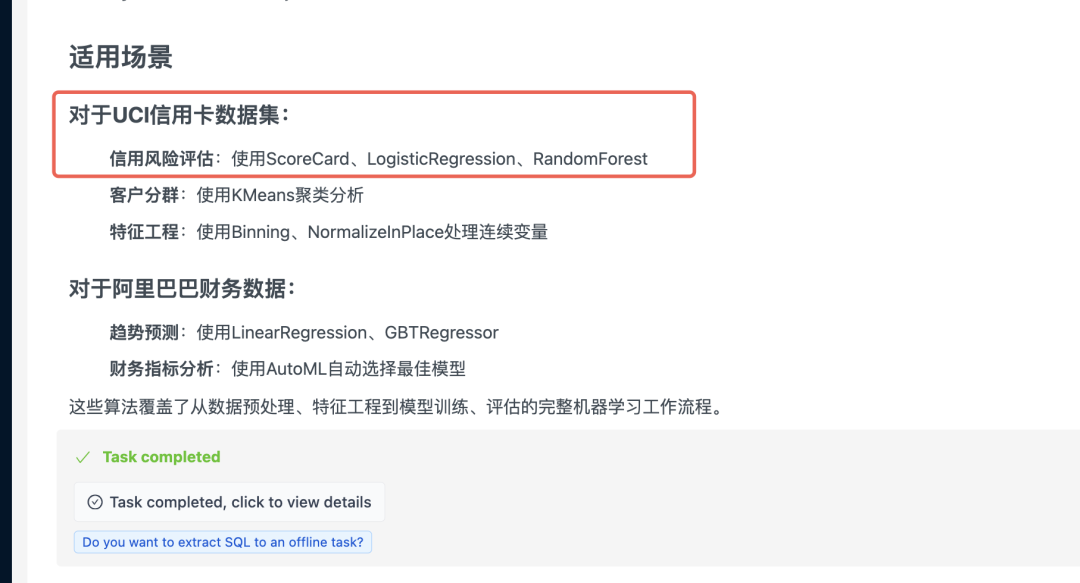
可以看到,InfiniSynapse 会告诉你,我们有专门的一个 ScoreCard算法(该算法内部使用了线性回归来做预测),并且说明了该算法的用途和场景。
开始工作
不过我自己实测,发现ScoreCard 依赖的 Binning 算法在当前的这个版本效率有点差,所以我决定直接采用SQL 做特这个特征工程,然后使用随机森林之类的分类算法来做预测。

InfiniSynapse 开始做特征工程:
接着使用训练模型:
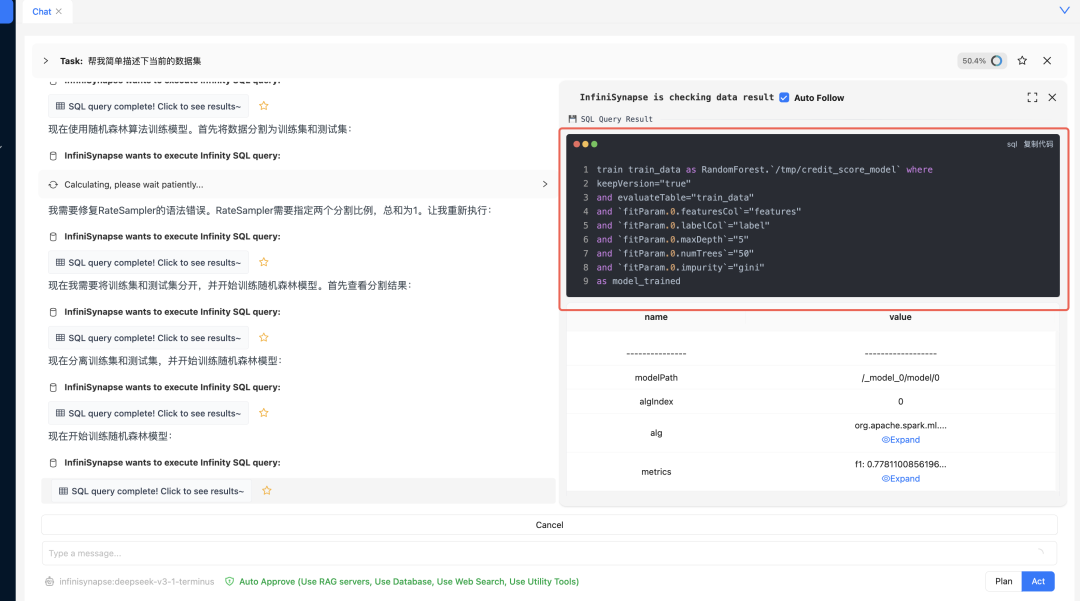
评估模型效果:
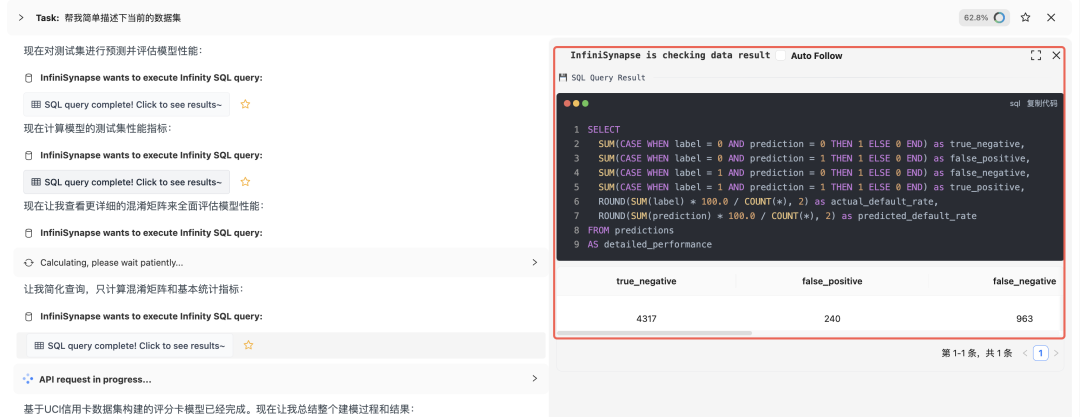
测试集效果:
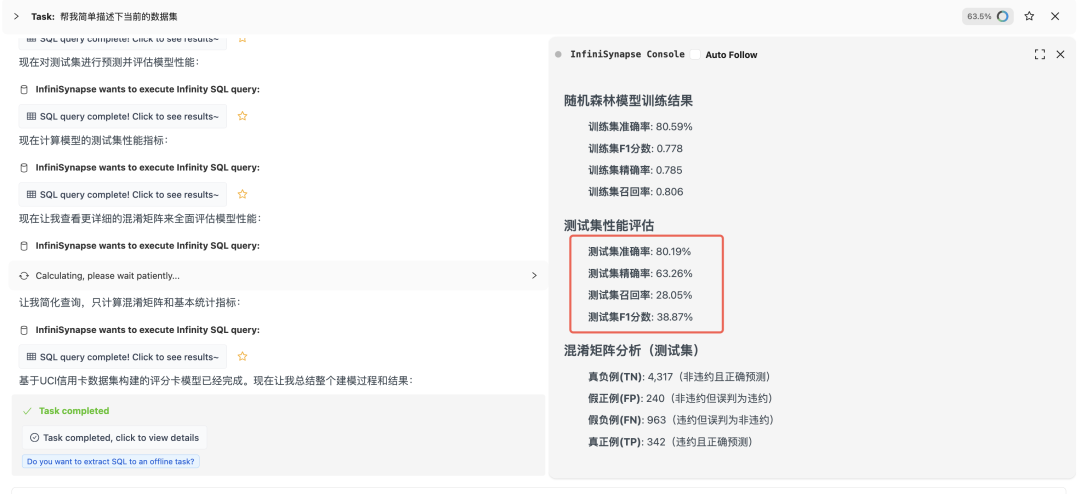
如果你觉得效果不好 ,可以让 InfiniSynapse 调整参数再次训练模型即可,让他必须达到多好的准确率才能停止。
模型部署
现在,我们将模型做个部署:
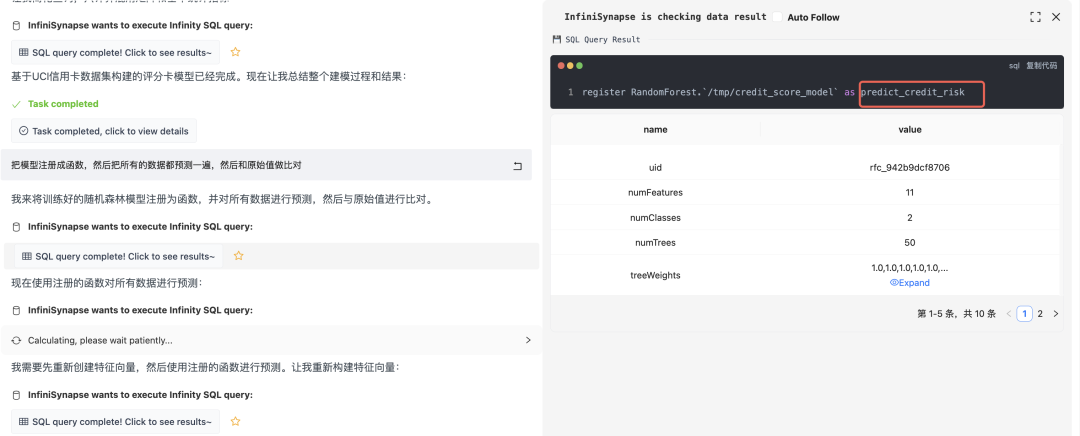
在 InfiniSynapse 里,一个模型可以被注册成一个SQL函数,所以接着你就可以用该SQL函数做预测了:
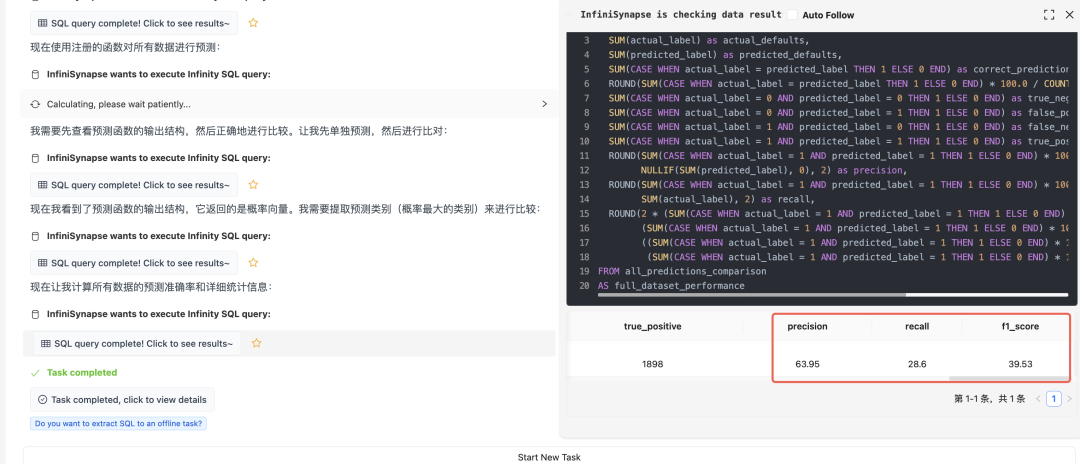
然后统计准确率,或者对数据做预测保存起来。
外部使用特征工程和模型
你可能会有疑问,特征工程以及训练好的模型能否被外部使用?当然 InfiniSynapse 对外提供 Rest 接口,你可以通过如下方式访问:
apache
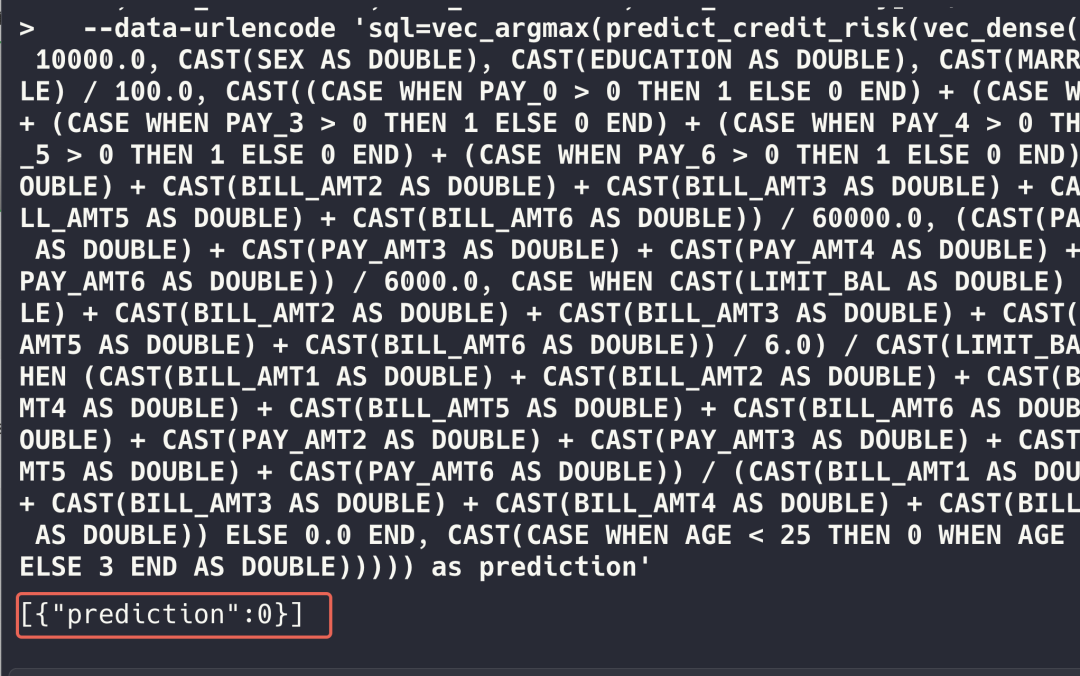
curl -X POST "http://localhost:9003/model/predict" \ -H "Content-Type: application/x-www-form-urlencoded" \ --data-urlencode "dataType=row" \ --data-urlencode "owner=<你的用户id>" \ --data-urlencode "sessionPerUser=true" \ --data-urlencode 'data=[{"LIMIT_BAL":80000,"SEX":2,"EDUCATION":2,"MARRIAGE":1,"AGE":35,"PAY_0":0,"PAY_2":0,"PAY_3":0,"PAY_4":0,"PAY_5":0,"PAY_6":0,"BILL_AMT1":25000,"BILL_AMT2":22000,"BILL_AMT3":18000,"BILL_AMT4":15000,"BILL_AMT5":12000,"BILL_AMT6":10000,"PAY_AMT1":5000,"PAY_AMT2":4000,"PAY_AMT3":3000,"PAY_AMT4":2000,"PAY_AMT5":1500,"PAY_AMT6":1000}]' \ --data-urlencode 'sql=vec_argmax(predict_credit_risk(vec_dense(array(CAST(LIMIT_BAL AS DOUBLE) / 10000.0, CAST(SEX AS DOUBLE), CAST(EDUCATION AS DOUBLE), CAST(MARRIAGE AS DOUBLE), CAST(AGE AS DOUBLE) / 100.0, CAST((CASE WHEN PAY_0 > 0 THEN 1 ELSE 0 END) + (CASE WHEN PAY_2 > 0 THEN 1 ELSE 0 END) + (CASE WHEN PAY_3 > 0 THEN 1 ELSE 0 END) + (CASE WHEN PAY_4 > 0 THEN 1 ELSE 0 END) + (CASE WHEN PAY_5 > 0 THEN 1 ELSE 0 END) + (CASE WHEN PAY_6 > 0 THEN 1 ELSE 0 END) AS DOUBLE), (CAST(BILL_AMT1 AS DOUBLE) + CAST(BILL_AMT2 AS DOUBLE) + CAST(BILL_AMT3 AS DOUBLE) + CAST(BILL_AMT4 AS DOUBLE) + CAST(BILL_AMT5 AS DOUBLE) + CAST(BILL_AMT6 AS DOUBLE)) / 60000.0, (CAST(PAY_AMT1 AS DOUBLE) + CAST(PAY_AMT2 AS DOUBLE) + CAST(PAY_AMT3 AS DOUBLE) + CAST(PAY_AMT4 AS DOUBLE) + CAST(PAY_AMT5 AS DOUBLE) + CAST(PAY_AMT6 AS DOUBLE)) / 6000.0, CASE WHEN CAST(LIMIT_BAL AS DOUBLE) > 0 THEN ((CAST(BILL_AMT1 AS DOUBLE) + CAST(BILL_AMT2 AS DOUBLE) + CAST(BILL_AMT3 AS DOUBLE) + CAST(BILL_AMT4 AS DOUBLE) + CAST(BILL_AMT5 AS DOUBLE) + CAST(BILL_AMT6 AS DOUBLE)) / 6.0) / CAST(LIMIT_BAL AS DOUBLE) ELSE 0.0 END, CASE WHEN (CAST(BILL_AMT1 AS DOUBLE) + CAST(BILL_AMT2 AS DOUBLE) + CAST(BILL_AMT3 AS DOUBLE) + CAST(BILL_AMT4 AS DOUBLE) + CAST(BILL_AMT5 AS DOUBLE) + CAST(BILL_AMT6 AS DOUBLE)) > 0 THEN (CAST(PAY_AMT1 AS DOUBLE) + CAST(PAY_AMT2 AS DOUBLE) + CAST(PAY_AMT3 AS DOUBLE) + CAST(PAY_AMT4 AS DOUBLE) + CAST(PAY_AMT5 AS DOUBLE) + CAST(PAY_AMT6 AS DOUBLE)) / (CAST(BILL_AMT1 AS DOUBLE) + CAST(BILL_AMT2 AS DOUBLE) + CAST(BILL_AMT3 AS DOUBLE) + CAST(BILL_AMT4 AS DOUBLE) + CAST(BILL_AMT5 AS DOUBLE) + CAST(BILL_AMT6 AS DOUBLE)) ELSE 0.0 END, CAST(CASE WHEN AGE < 25 THEN 0 WHEN AGE < 35 THEN 1 WHEN AGE < 50 THEN 2 ELSE 3 END AS DOUBLE))))) as prediction'其中 owner 设置为你的用户ID:
然后data 是要预测的数据。 sql 是对要预测数据先做特征工程然后加模型预测。
下面是预测结果:
总结
尽管当前ML功能还处于Beta 阶段, 但我们可以看到,数据特征工程,模型训练,模型部署(内部或者外部使用),都可以让InfiniSynapse 自主完成,我相信,我们离摘下数据分析的皇冠已经很近,我们将数据分析和传统机器学习算法的成本大幅度降低,让世界所有个人和企业,都可以真正意义上被数据驱动。