文章目录
- [YOLO(You only look once 是一阶段,实时目标检测算法)](#YOLO(You only look once 是一阶段,实时目标检测算法))
- [一 .YOLOV1](#一 .YOLOV1)
-
- [1. YOLO V1缺点](#1. YOLO V1缺点)
- [2. YOLO V1优点](#2. YOLO V1优点)
- [1. Passthroug](#1. Passthroug)
- [2. BN](#2. BN)
- [3. 聚类提取先验框](#3. 聚类提取先验框)
- [4. 针对YOLO v1 的缺点YOLO V2检测头的改进:](#4. 针对YOLO v1 的缺点YOLO V2检测头的改进:)
- [5. YOLO V2 的改进](#5. YOLO V2 的改进)
- [6. YOLO V2 分类模型训练](#6. YOLO V2 分类模型训练)
- [三.YOLO V3](#三.YOLO V3)
- [四 .YOLO V4](#四 .YOLO V4)
-
- [1. Bag of freebies(BOF)](#1. Bag of freebies(BOF))
- [2. Bag of specials(BOS)](#2. Bag of specials(BOS))
- [五 .YOLO V5](#五 .YOLO V5)
- [六.YOLO X](#六.YOLO X)
YOLO(You only look once 是一阶段,实时目标检测算法)
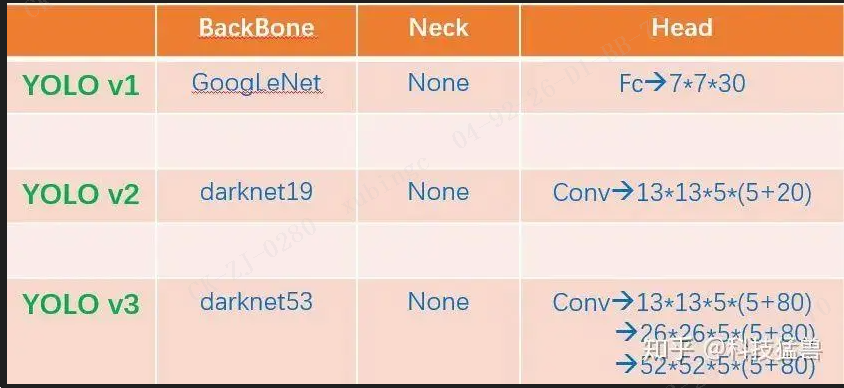
从2015年的YOLOv1,2016年YOLOv2,2018年的YOLOv3,再到2020年的YOLOv4()和YOLOv5(6月9日),2021年的YOLOX,YOLO系列在不断的进化发展。

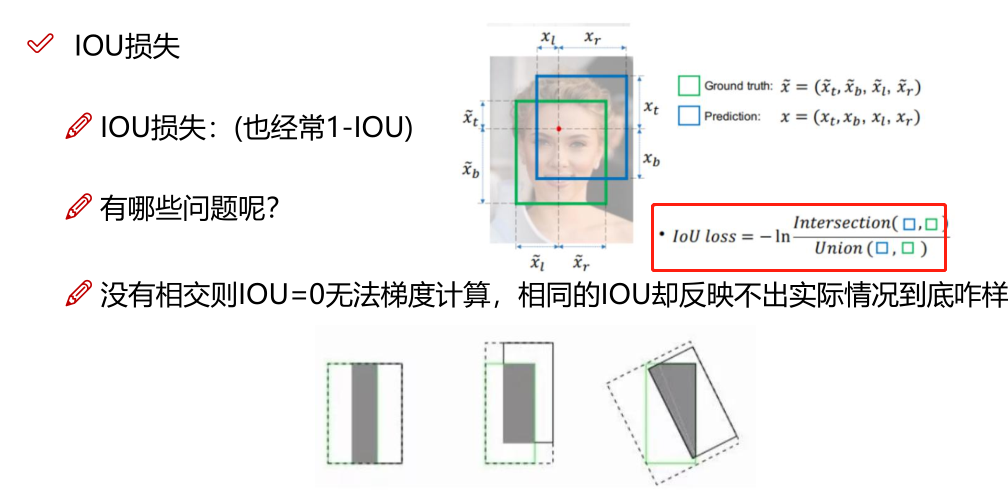
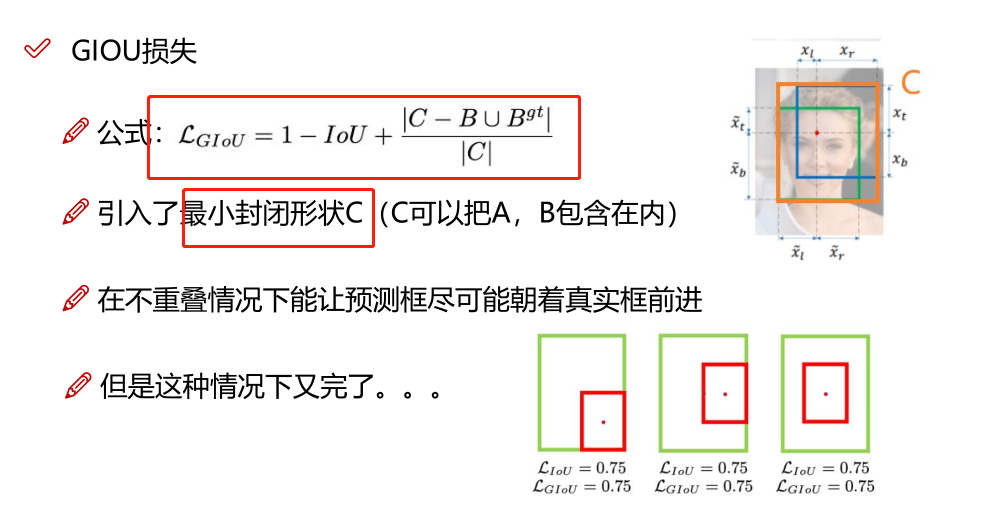
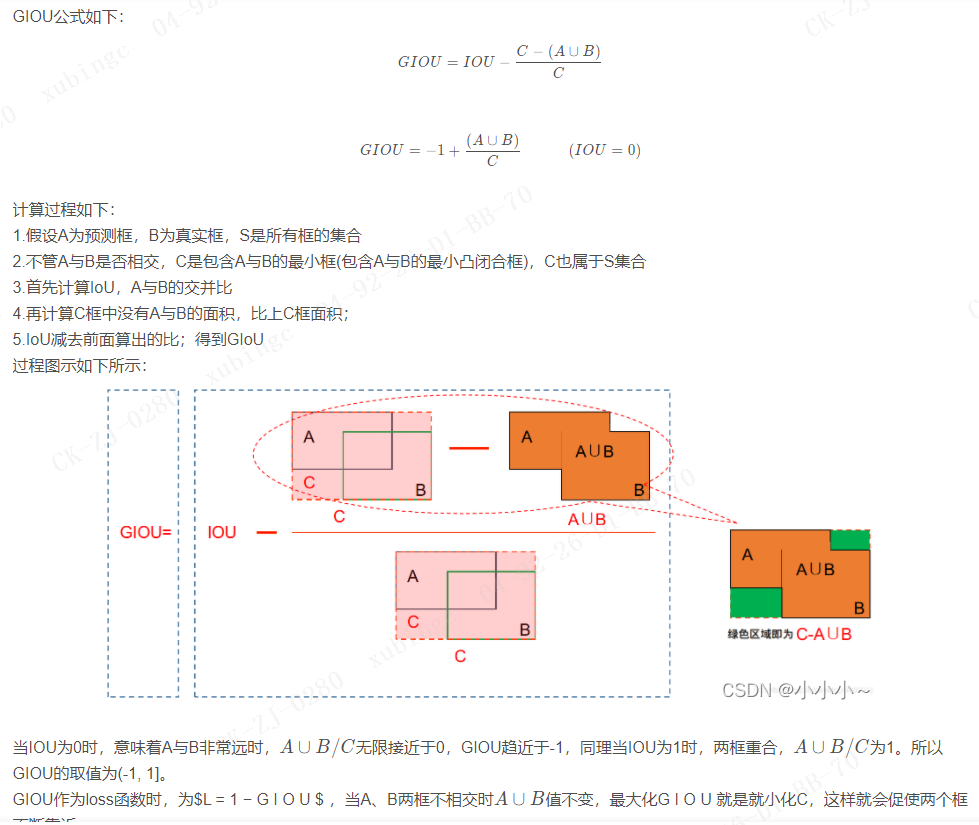
•从R-CNN到Faster R-CNN网络的发展中,都是基于proposal+分类的方式来进行目标检测的,检测精度比较高,但是检测速度不行,YOLO提供了一种更加直接的思路: 直接在输出层回bounding box 的位置和bounding box 所属类别的置信度,相比于R-CNN体系的目标检测,YOLO将目标检测从分类问题转换为回归问题。其主要特点是:
• 速度快,能够达到实时的要求,在Titan X的GPU上达到45fps;
• 使用全图Context信息,背景错误(把背景当做物体)比较少;
• 泛化能力强;
YOLO v1:
直接回归出位置。
77 的grid,2个先验框,20个类别
VGG16
多目标找不到
YOLO v2:
全流程多尺度方法。
13 13 的grid, 5个锚点,80个类别
DarkNet19
回归出的位置是相对于Grid的偏移量的归一化之后的值
小目标检测不准确
YOLO v3:
多尺度检测头
32倍,16倍,8倍下采样,每种3个尺寸的锚点,分别负责大中小目标的检测
resblock darknet53
YOLO v4:csp darknet53,spp,panet,tricks
一 .YOLOV1

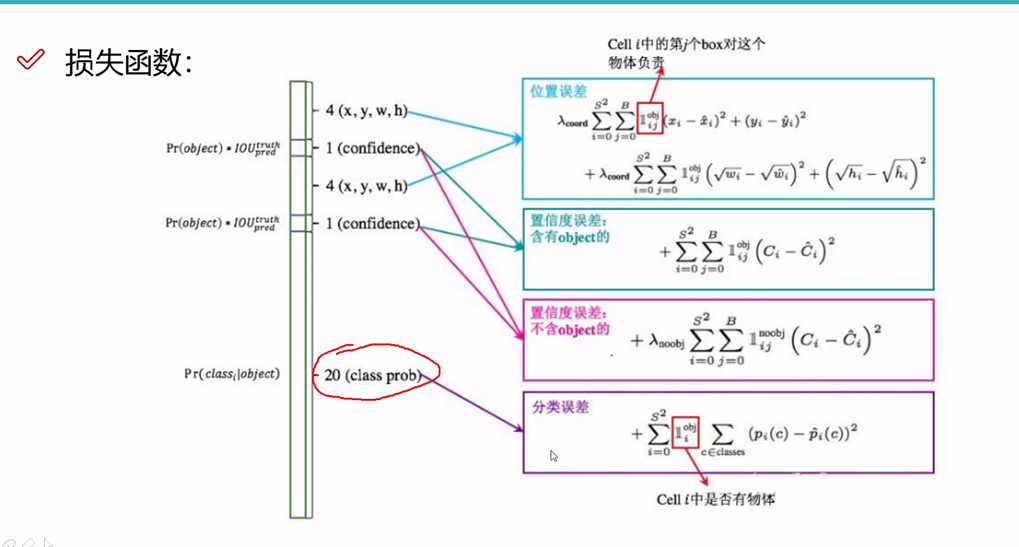
1. YOLO V1缺点
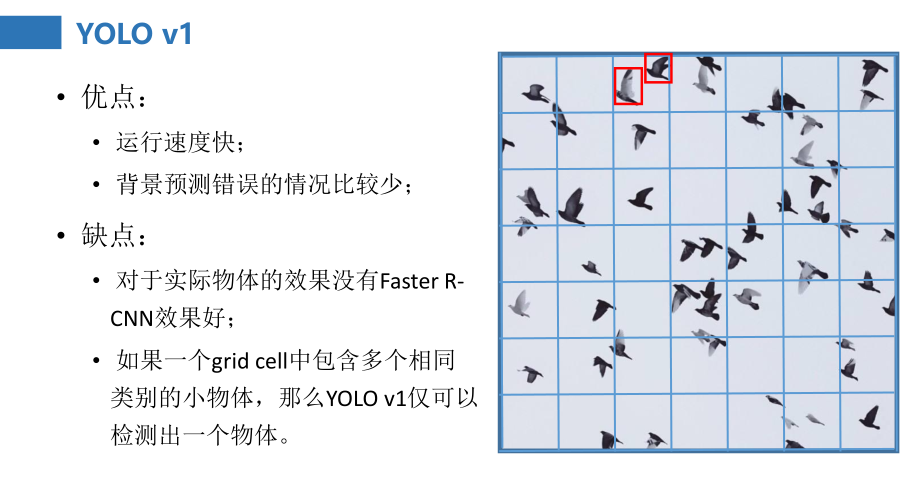
2. YOLO V1优点

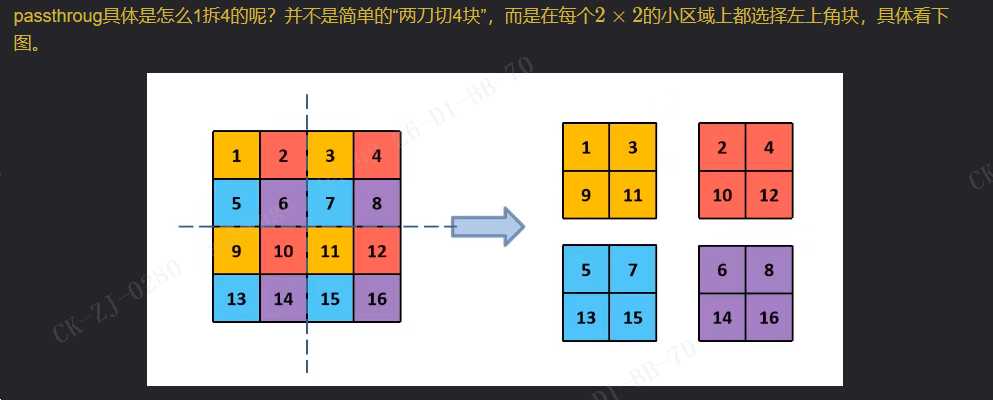
1. Passthroug
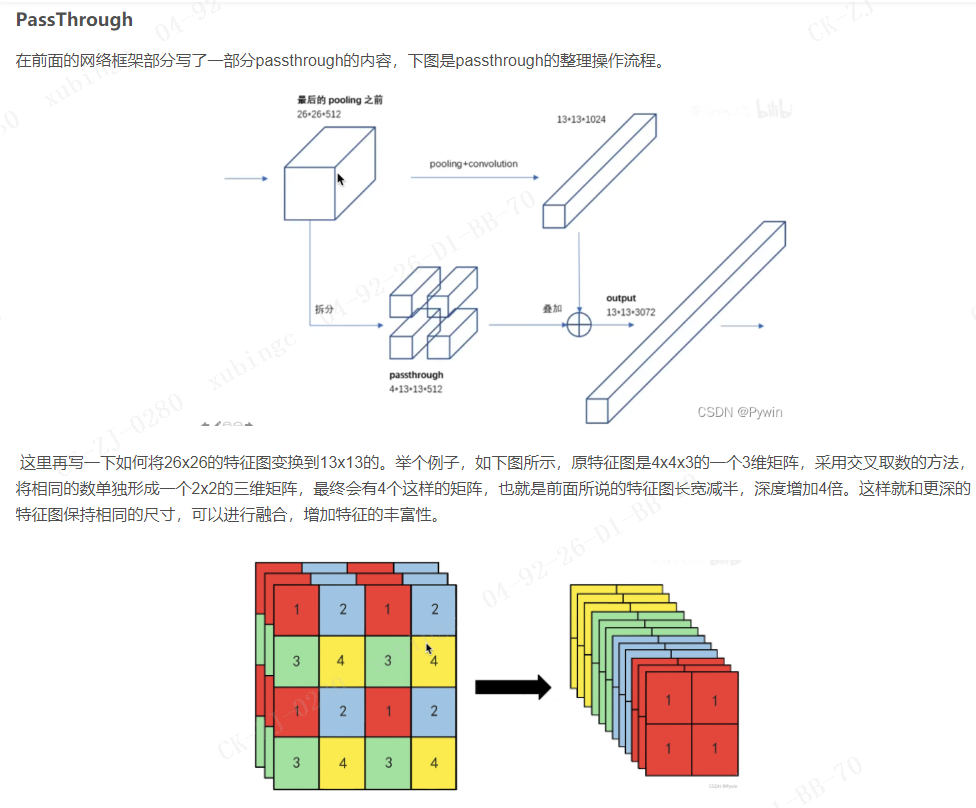
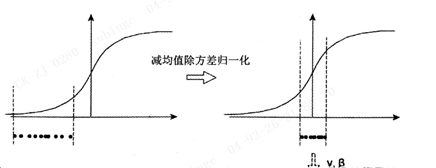
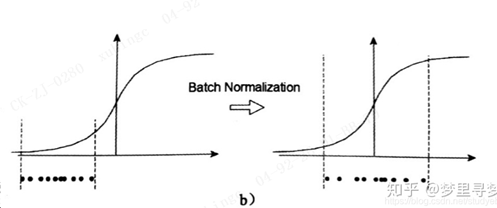
2. BN
图中曲线是sigmoid函数,如果数据在梯度很小的区域,那么学习率就会很慢,甚至陷入长时间的停滞。减均值除方差后,数据就被移动到中心区域如右图所示,对于大多数激活函数而言,这个区域的梯度都是最大的或者是有梯度的(比如ReLU),这可以看作是一种对抗梯度消失的有效手段。

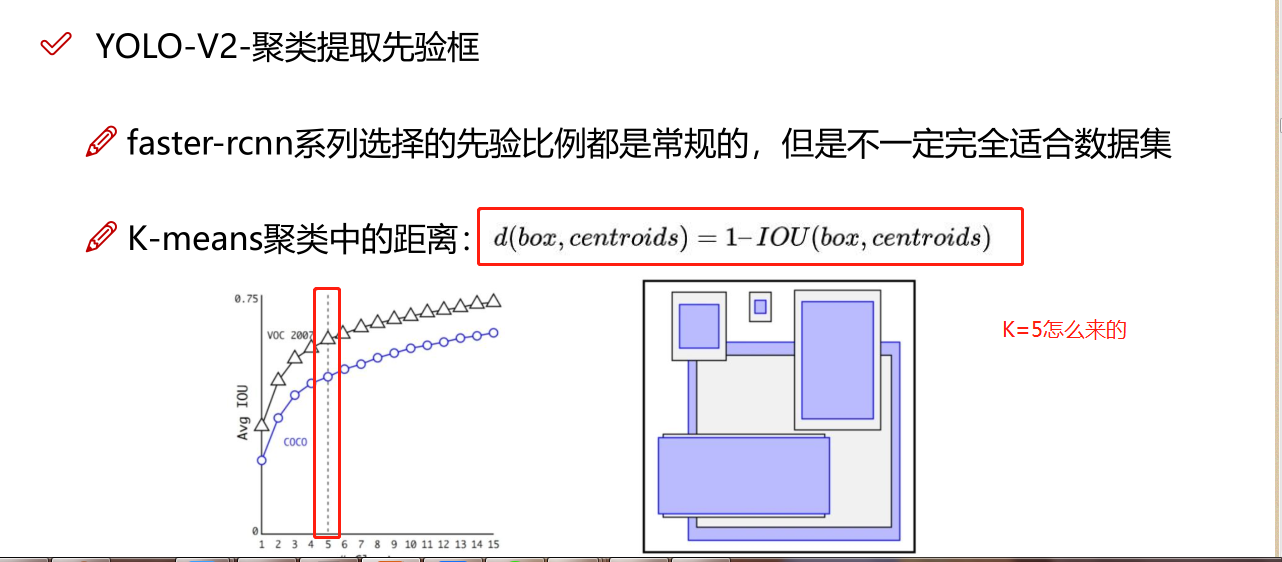
3. 聚类提取先验框
4. 针对YOLO v1 的缺点YOLO V2检测头的改进:

YOLO v1虽然快,但是预测的框不准确,很多目标找不到:
预测的框不准确:准确度不足。
很多目标找不到:recall不足。
问题1:预测的框不准确:当时别人是怎么做的?
同时代的检测器有R-CNN,人家预测的是偏移量。
V2中并没有直接使用偏移量,而是选择相对grid cell的偏移量

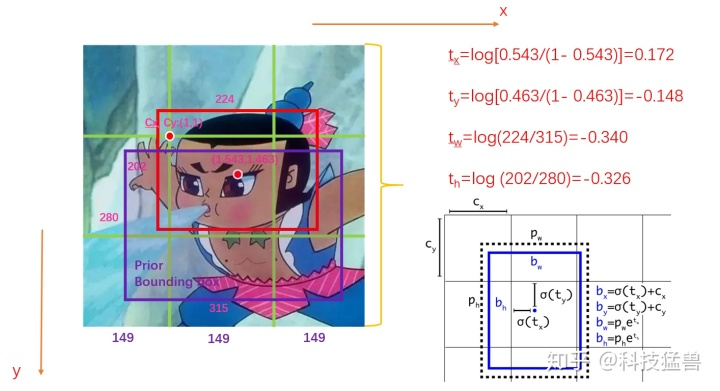
问题2:很多目标找不到:
(如果一个grid cell中包含多个相同类别的小物体,那么YOLO v1仅可以检测出一个物体。)
增加预测框77的Grid,2个框---》1313的Grid,5个框(COCO数据集聚类出来5个框效果最好)

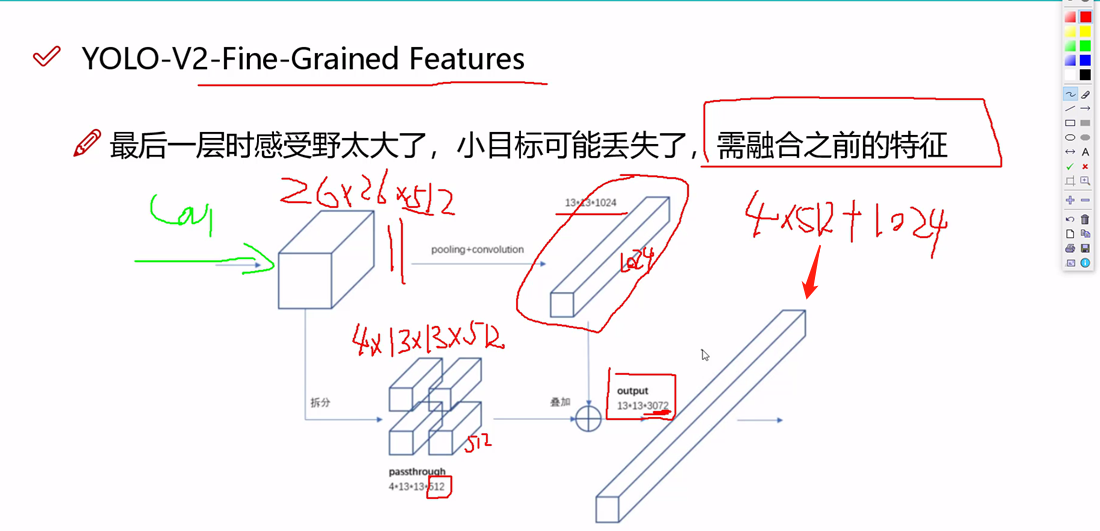

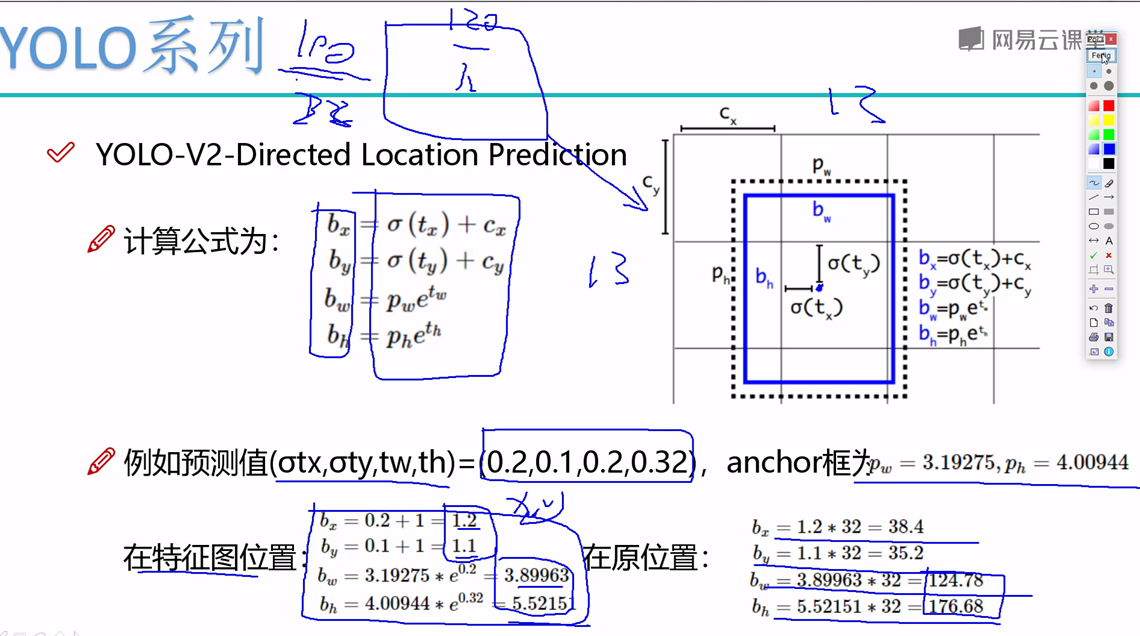
5. YOLO V2 的改进
• 为了改善YOLO模型的检测速度,YOLO v2在Faster方面也做了一些改进。
• 大多数神经网络依赖于VGG Net来提取特征,VGG-16特征提取功能是非常强大的,但是复杂度有点高,对于224*224的图像,前向计算高达306.9亿次浮点数运算。
• YOLO v2中使用基于GoogleNet的定制网络DarkNet,一次前向传播仅需要85.2亿次浮点数计算。精度相比来讲低2%(88%/90%)
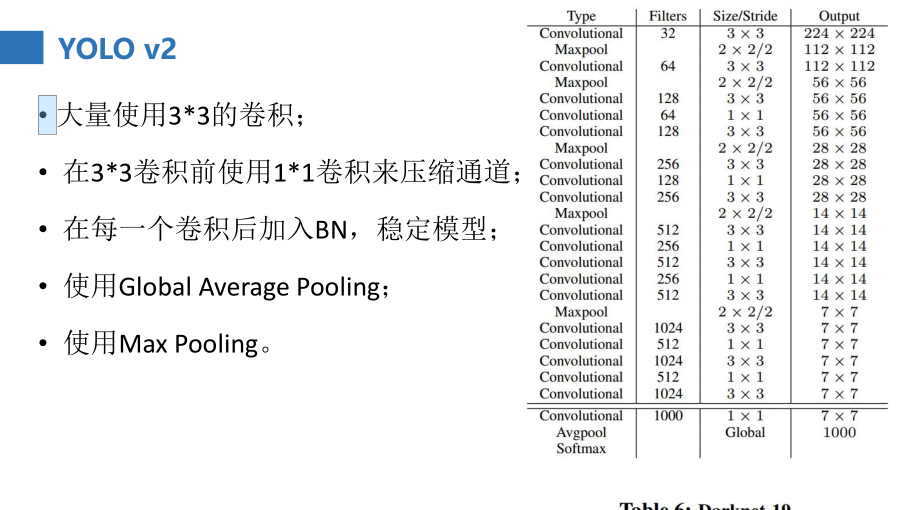
6. YOLO V2 分类模型训练


• 检测网络的训练
将分类网络的最后一个卷积层去掉,更改为三个33 1024的卷积层,并且每个卷积层后跟一个1*1的卷积层,输出维度为检测需要的数目;
比如在VOC数据集中,需要预测5个框,每个框4个坐标值+1个置信度+20个类别概率值,也就是输出为125维。同时将转移层(passthrough layer)从倒数第二层做一个连接的操作。


• 训练方式以及Loss的定义和YOLO v1类似
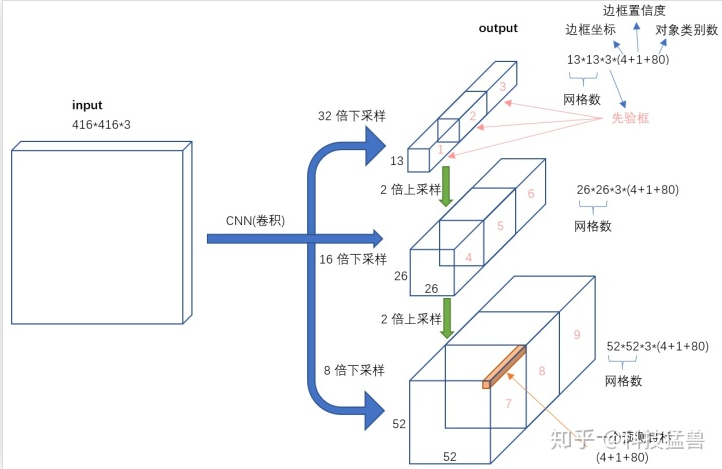
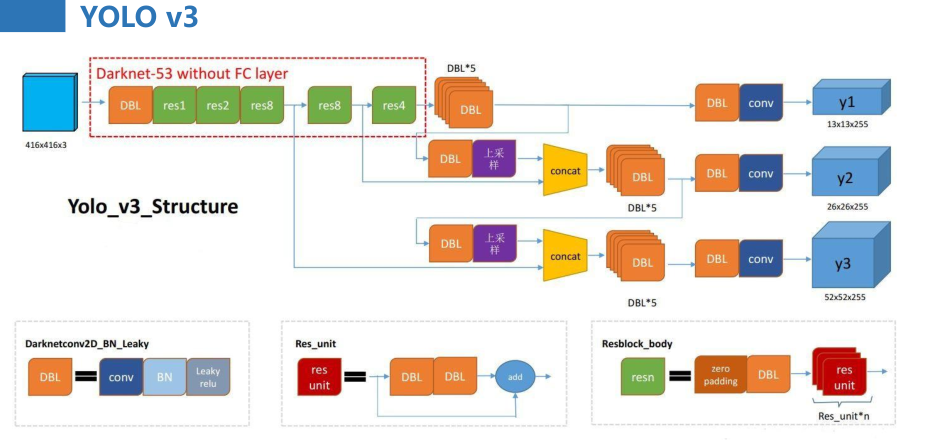
三.YOLO V3
终于到V3了,最大的改进就是网络结构,使其更适合小目标检测
特征做的更细致,融入多持续特征图信息来预测不同规格物体
先验框更丰富了,3种scale,每种3个规格,一共9种
softmax改进,预测多标签任务
img → cbrp16→ cbrp32→ cbrp64→ cbrp128→ ...→ fc256-fc10
这里的cbrp指的是conv,bn,relu,pooling的串联。
由于输入要是one-hot形式,所以最后我们设计了2个fc层(fully connencted layer)

四 .YOLO V4
YOLOv4在结构上没有额外的创新,但是收集了目标检测中各种tricks,并进行实验分析了各种tricks的有效性,相对于对近些年来目标检测领域中从数据,网络结构,和后处理等过程做了很好的总结。最终,在速度和准确性上达到了最好的balanceV4贡献:
亲民政策,单GPU就能训练的非常好,接下来很多小模块都是这个出发点
两大核心方法,从数据层面和网络设计层面来进行改善
消融实验,感觉能做的都让他给做了,这工作量不轻
全部实验都是单GPU完成,不用太担心设备了
1. Bag of freebies(BOF)
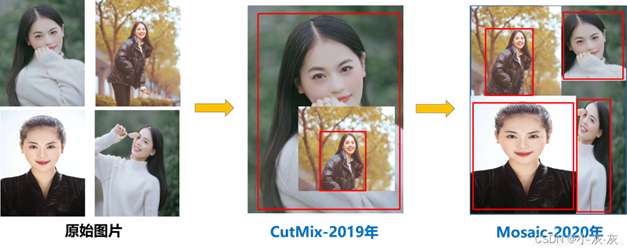
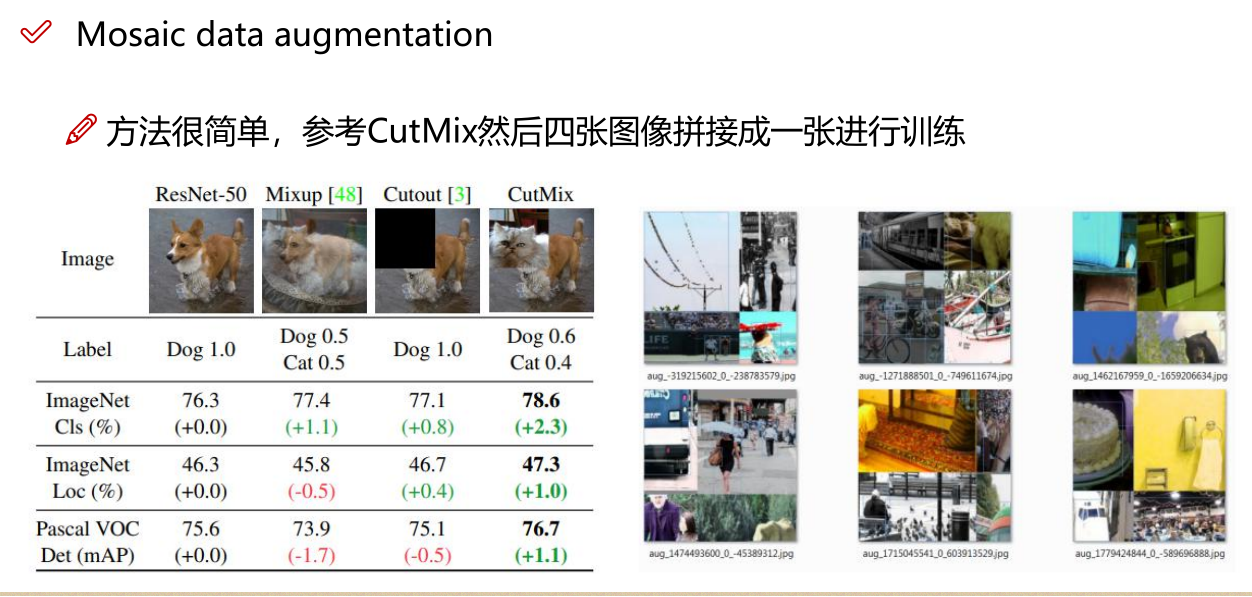
通常,常规的目标检测器是离线训练的。因此,研究人员总是喜欢利用这一优势,并开发出更好的训练方法,以使目标检测器获得更好的精度而又不增加推理成本。我们称这些仅改变训练策略或仅增加训练成本方法为"bag of freebies"。数据增强是目标检测方法经常采用的并符合bag of freebies定义
只增加训练成本,但是能显著提高精度,并不影响推理速度
数据增强:调整亮度、对比度、色调、随机缩放、剪切、翻转、旋转
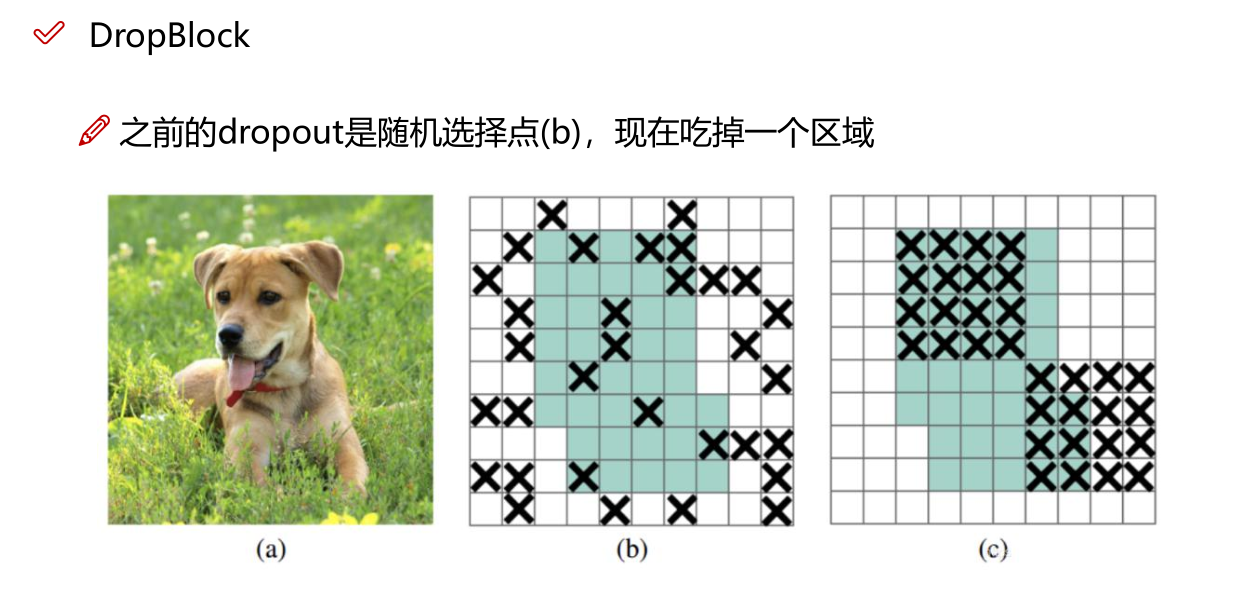
网络正则化的方法:Dropout、Dropblock等
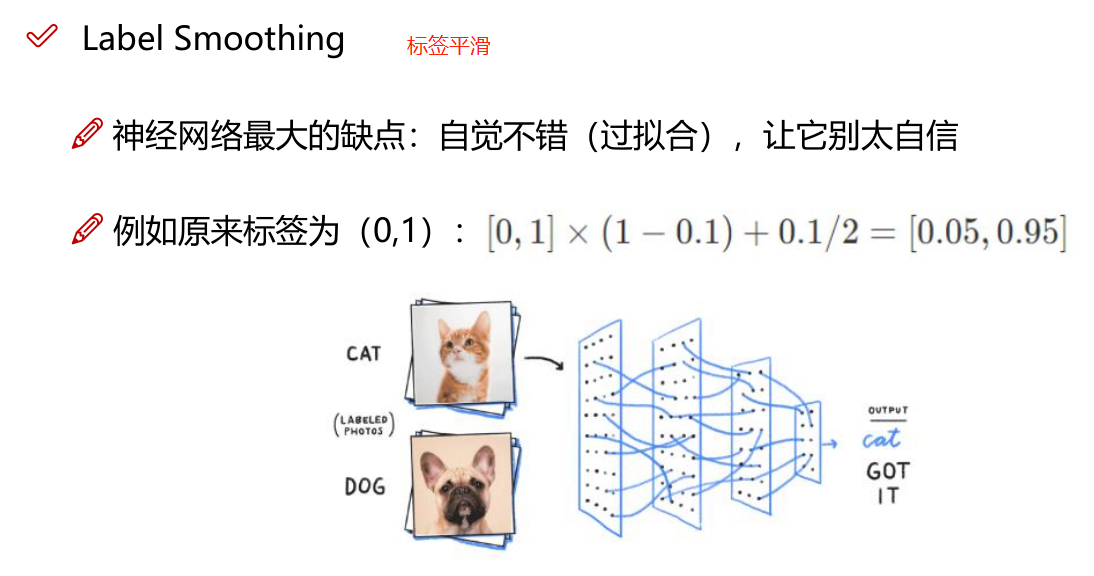
类别不平衡,损失函数设计
1.1 数据增强


1.2 网络正则化的方法
1.3 类别不平衡
1.4 损失函数设计





2. Bag of specials(BOS)
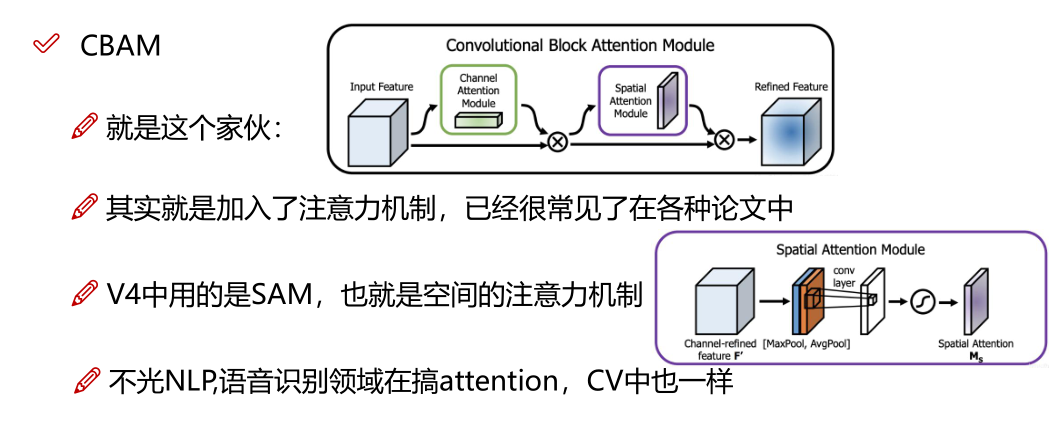
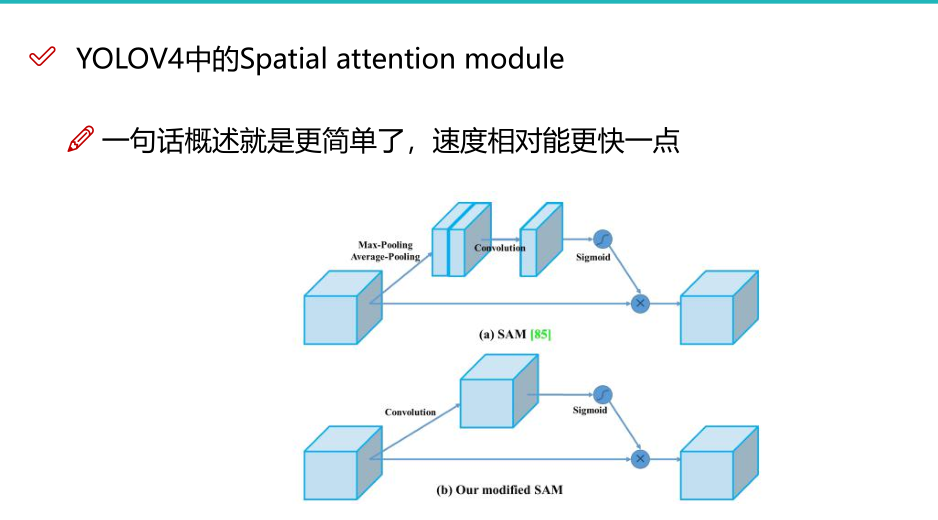
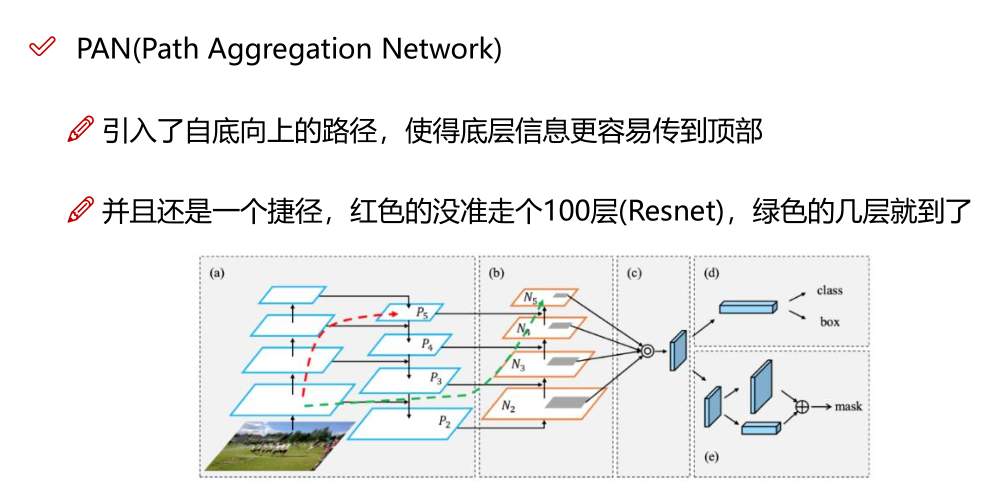
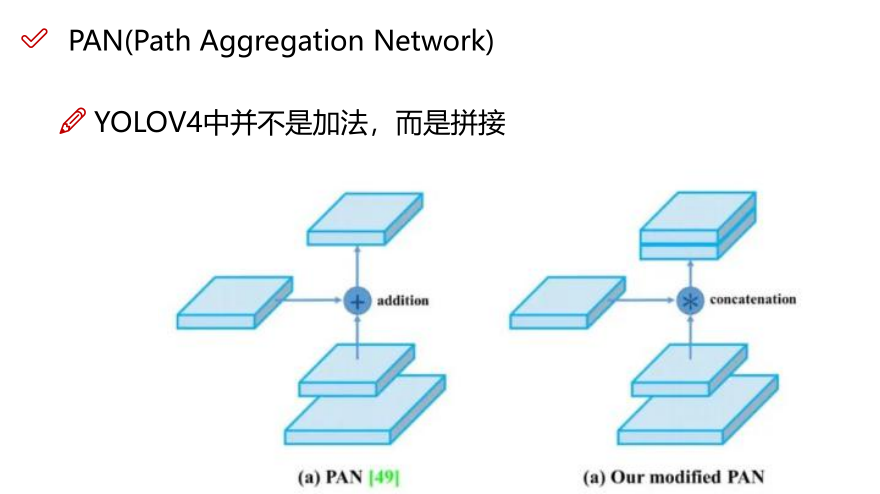
对于那些仅增加少量推理成本但可以显着提高目标检测准确性的插件模块和后处理方法,我们将其称为"bag of specials"。 一般而言,这些插件模块用于增强模型中的某些属性,例如扩大感受野,引入注意力机制或增强特征集成能力等,而后处理是用于筛选模型预测结果的方法。
增加稍许推断代价,但可以提高模型精度的方法
网络细节部分加入了很多改进,引入了各种能让特征提取更好的方法
注意力机制,网络细节设计,特征金字塔等,你能想到的全有
读折一篇相当于把今年来部分优秀的论文又过了一遍



五 .YOLO V5
1. 网络结构
关于YOLOv5的网络结构其实网上相关的讲解已经有很多了。网络结构主要由以下几部分组成:
Backbone: New CSP-Darknet53
Neck :SPPF New CSP-PAN
Head:YOLOv3 Head
下面是我根据yolov5l.yaml绘制的网络整体结构,YOLOv5针对不同大小(n, s, m, l, x)的网络整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度,分别应对yaml文件中的depth_multiple和width_multiple参数。还需要注意一点,官方除了n, s, m, l, x版本外还有n6, s6, m6, l6, x6,区别在于后者是针对更大分辨率的图片比如1280x1280,当然结构上也有些差异,后者会下采样64倍,采用4个预测特征层,而前者只会下采样到32倍且采用3个预测特征层。本博文只讨论前者。下面这幅图(yolov5l)有点大,大家可以下载下来仔细看一下
通过和上篇博文讲的YOLOv4对比,其实YOLOv5在Backbone部分没太大变化。但是YOLOv5在v6.0版本后相比之前版本有一个很小的改动,把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层。两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。详情可以参考这个issue #4825。下图是原来的Focus模块(和之前Swin Transformer中的Patch Merging类似),将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个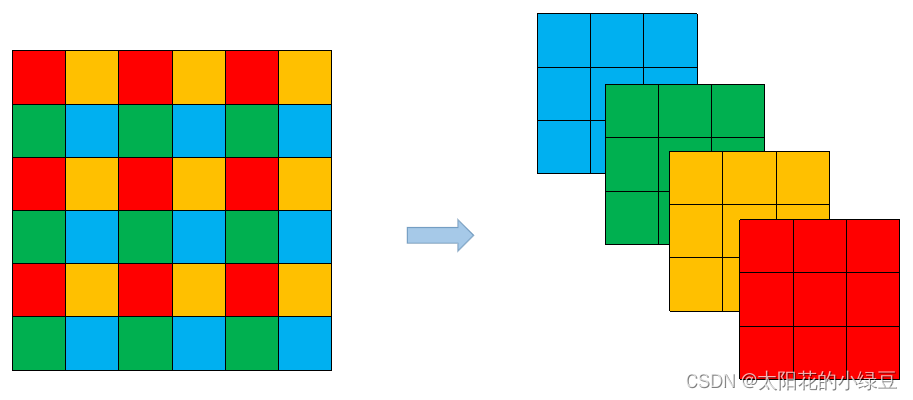
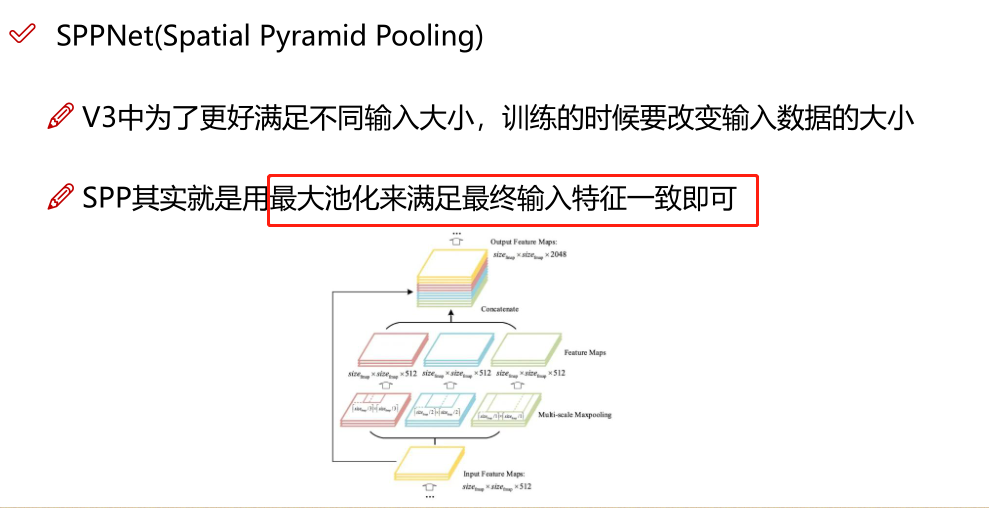
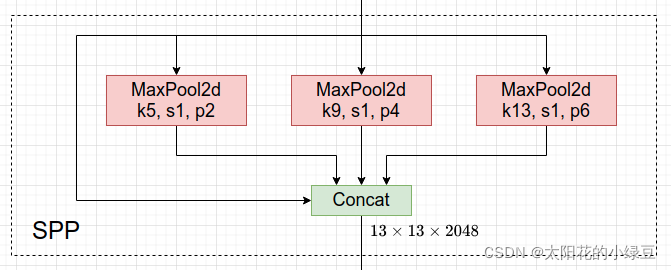
在Neck部分的变化还是相对较大的,首先是将SPP换成成了SPPF(Glenn Jocher自己设计的),这个改动我个人觉得还是很有意思的,两者的作用是一样的,但后者效率更高。SPP结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
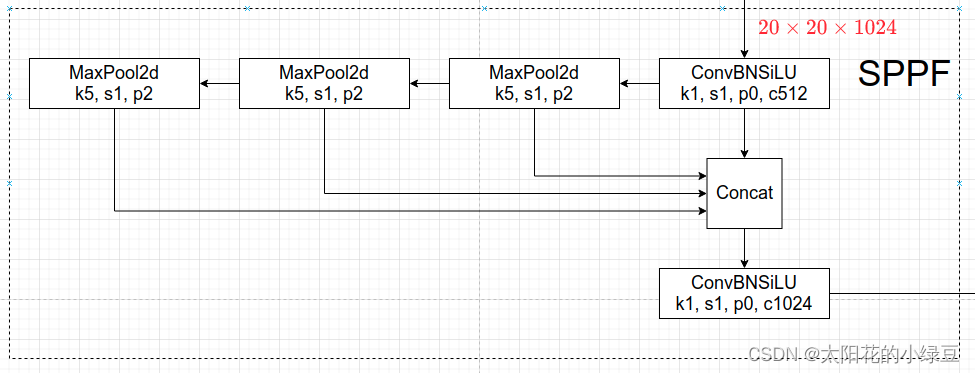
而SPPF结构是将输入串行通过多个5x5大小的MaxPool层,这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是一样的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的。
python
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()
True
spp time: 0.5373051166534424
sppf time: 0.20780706405639648通过对比可以发现,两者的计算结果是一模一样的,但SPPF比SPP计算速度快了不止两倍,快乐翻倍。
在Neck部分另外一个不同点就是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。详情见上面的网络结构图,每个C3模块里都含有CSP结构。在Head部分,YOLOv3, v4, v5都是一样的,这里就不讲了。
2. 数据增强
3.训练策略
在YOLOv5源码中使用到了很多训练的策略,这里简单总结几个我注意到的点,还有些没注意到的请大家自己看下源码:
Multi-scale training(0.5~1.5x),多尺度训练,假设设置输入图片的大小为640 × 640 640 \times 640640×640,训练时采用尺寸是在0.5 × 640 ∼ 1.5 × 640 0.5 \times 640 \sim 1.5 \times 6400.5×640∼1.5×640之间随机取值,注意取值时取得都是32的整数倍(因为网络会最大下采样32倍)。
AutoAnchor(For training custom data),训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成Anchors模板。
Warmup and Cosine LR scheduler,训练前先进行Warmup热身,然后在采用Cosine学习率下降策略。
EMA(Exponential Moving Average),可以理解为给训练的参数加了一个动量,让它更新过程更加平滑。
Mixed precision,混合精度训练,能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。
Evolve hyper-parameters,超参数优化,没有炼丹经验的人勿碰,保持默认就好。
4.其他
4.1 损失计算
YOLOv5的损失主要由三个部分组成:
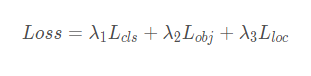
Classes loss,分类损失,采用的是BCE loss,注意只计算正样本的分类损失。
Objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的obj损失。
Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失。
其中,λ 1 , λ 2 , λ 3为平衡系数。
4.2 平衡不同尺度的损失
这里是指针对三个预测特征层(P3, P4, P5)上的obj损失采用不同的权重。在源码中,针对预测小目标的预测特征层(P3)采用的权重是4.0,针对预测中等目标的预测特征层(P4)采用的权重是1.0,针对预测大目标的预测特征层(P5)采用的权重是0.4,作者说这是针对COCO数据集设置的超参数。
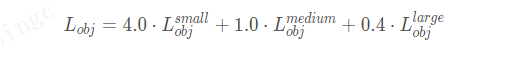
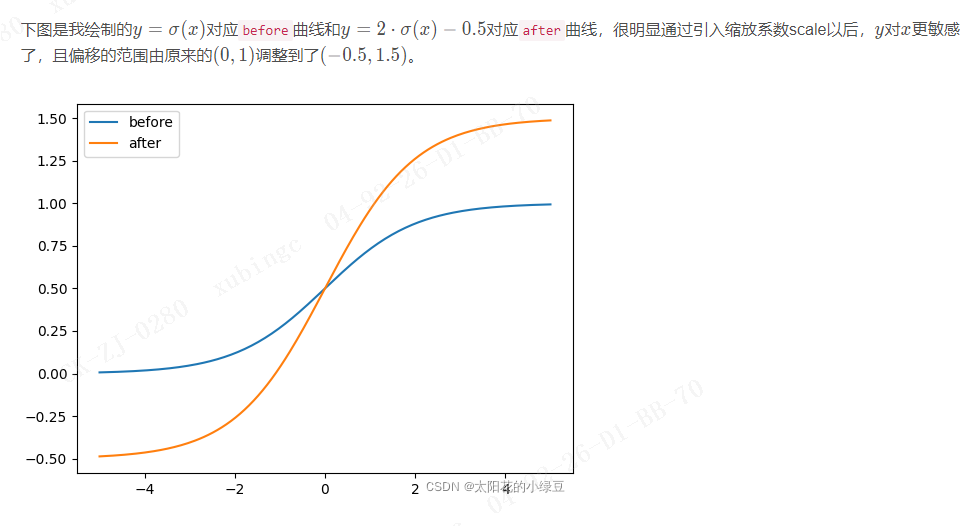
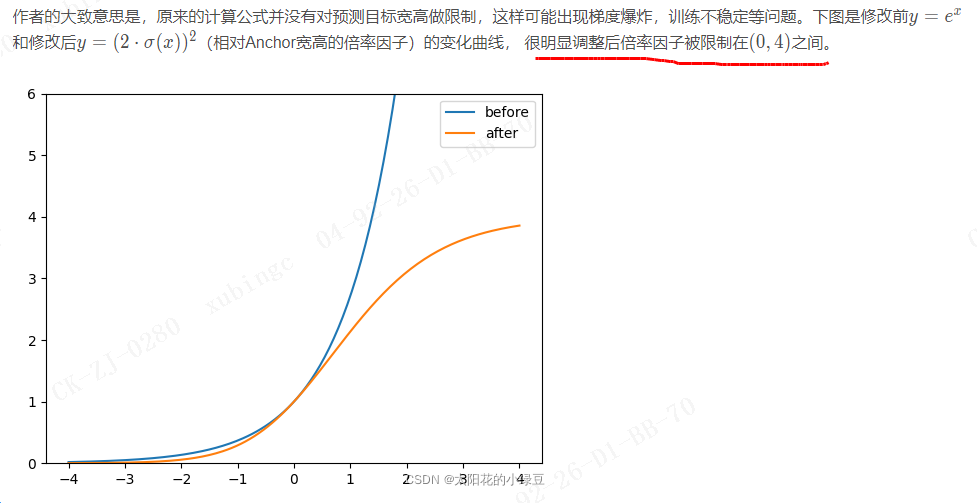
4.3 消除Grid敏感度
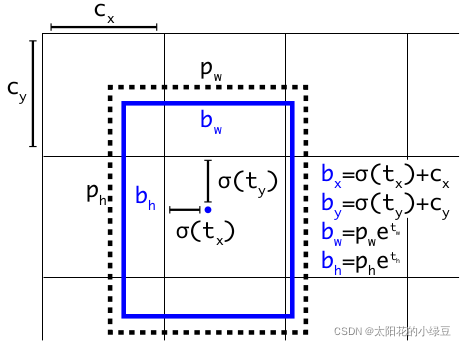
在上篇文章YOLOv4中有提到过,主要是调整预测目标中心点相对Grid网格的左上角偏移量。下图是YOLOv2,v3的计算公式。


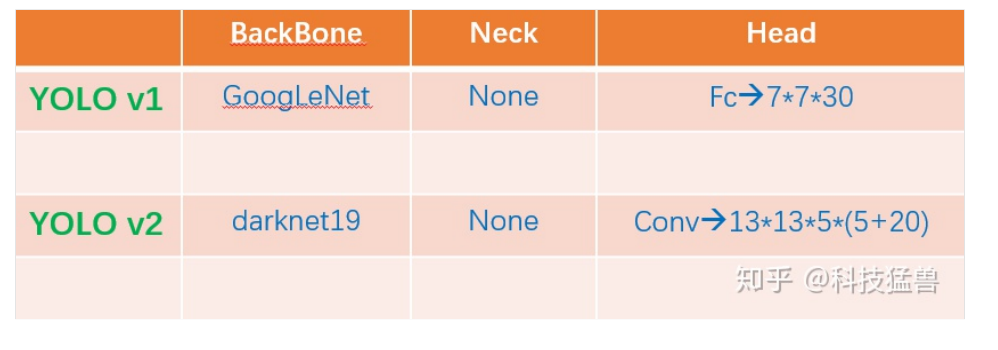
YOLO系列backbone方面的优化和对输入端的改进
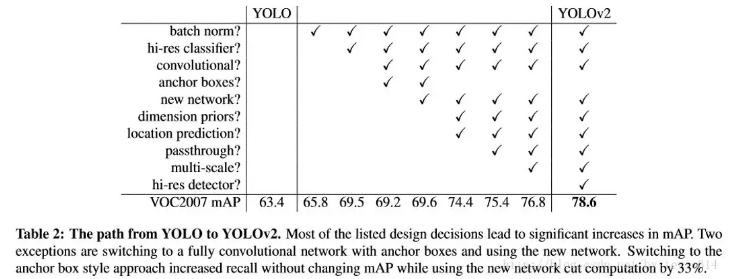
图2:YOLO系列比较
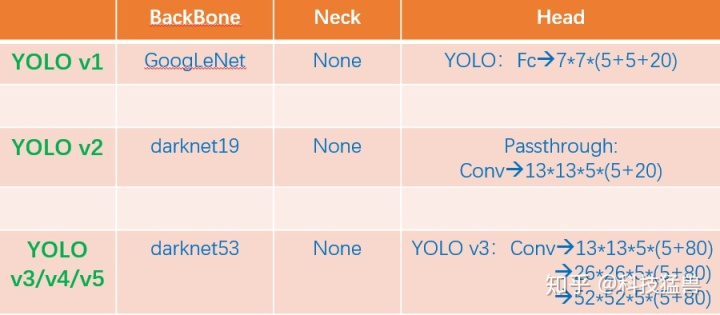
我们发现YOLO v1只是把最后的特征分成了 7×7 个grid,到了YOLO v2就变成了 13×13 个grid,再到YOLO v3 v4 v5就变成了多尺度的(strides=8,16,32),更加复杂了。那为什么一代比一代检测头更加复杂呢?答案是:因为它们的提特征网络更加强大了,能够支撑起检测头做更加复杂的操作。换句话说,如果没有backbone方面的优化,你即使用这么复杂的检测头,可能性能还会更弱。所以引出了今天的话题:backbone(主干网络)的改进六.YOLO X
1.网络结构图
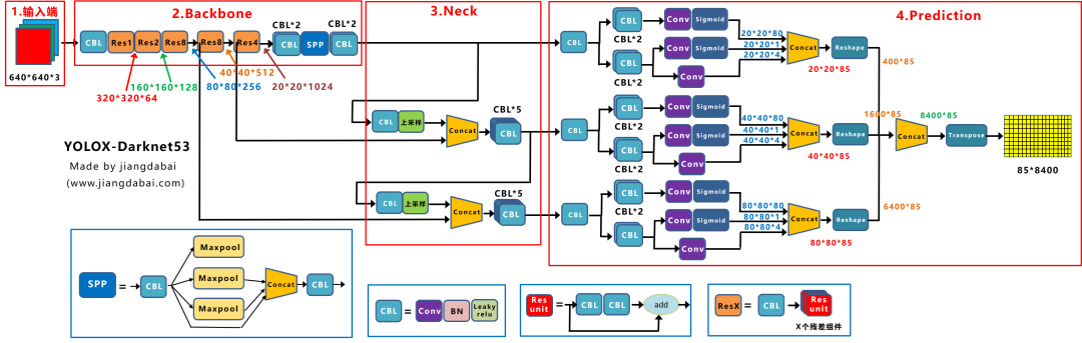
2.输入端
在yolox的输入端采用了 Mosaic、Mixup两种数据增强方式,采用了这两种数据增强,直接将Yolov3baseline,提升了2.4个百分点;可见数据增强对网络还是很有贡献。