今天我们来解决为什么调用库时要使用 .h(头文件)以及目标文件(.o/.obj) 在里面起什么作用。
头文件与目标文件定义
(本段算是具体总结)
我们要先理解头文件与目标文件的作用,头文件(.h)用于函数的声明,而目标文件(.o/.obj)则是对头文件里声明函数的具体函数定义。
在调用目标文件时为什么要用头文件?因为编译器看不到目标文件的定义,目标文件的本质是打包成二进制的文件,是具体方法的实现。而头文件则是记录了方法,告诉编译器这些方法的存在。
即头文件是告诉编译器"这个函数存在并且怎么用",目标文件是告诉链接器"这个函数的具体代码"。
在调用库时两者需结合才能调用具体函数方法。
在日常编写代码时,自己手搓的函数方法为什么能直接使用,而使用库时就需要头文件里查看声明函数,而不是直接调用定义好的函数呢?
答案是自己写的函数,本质是「编译器已经看到了函数的声明 / 定义」,并非不需要声明;而库函数必须用头文件声明,是因为「编译器看不到库函数的定义,只能靠头文件告知接口规则」。
从下图我们可以到从整个文件到可执行程序的过程:
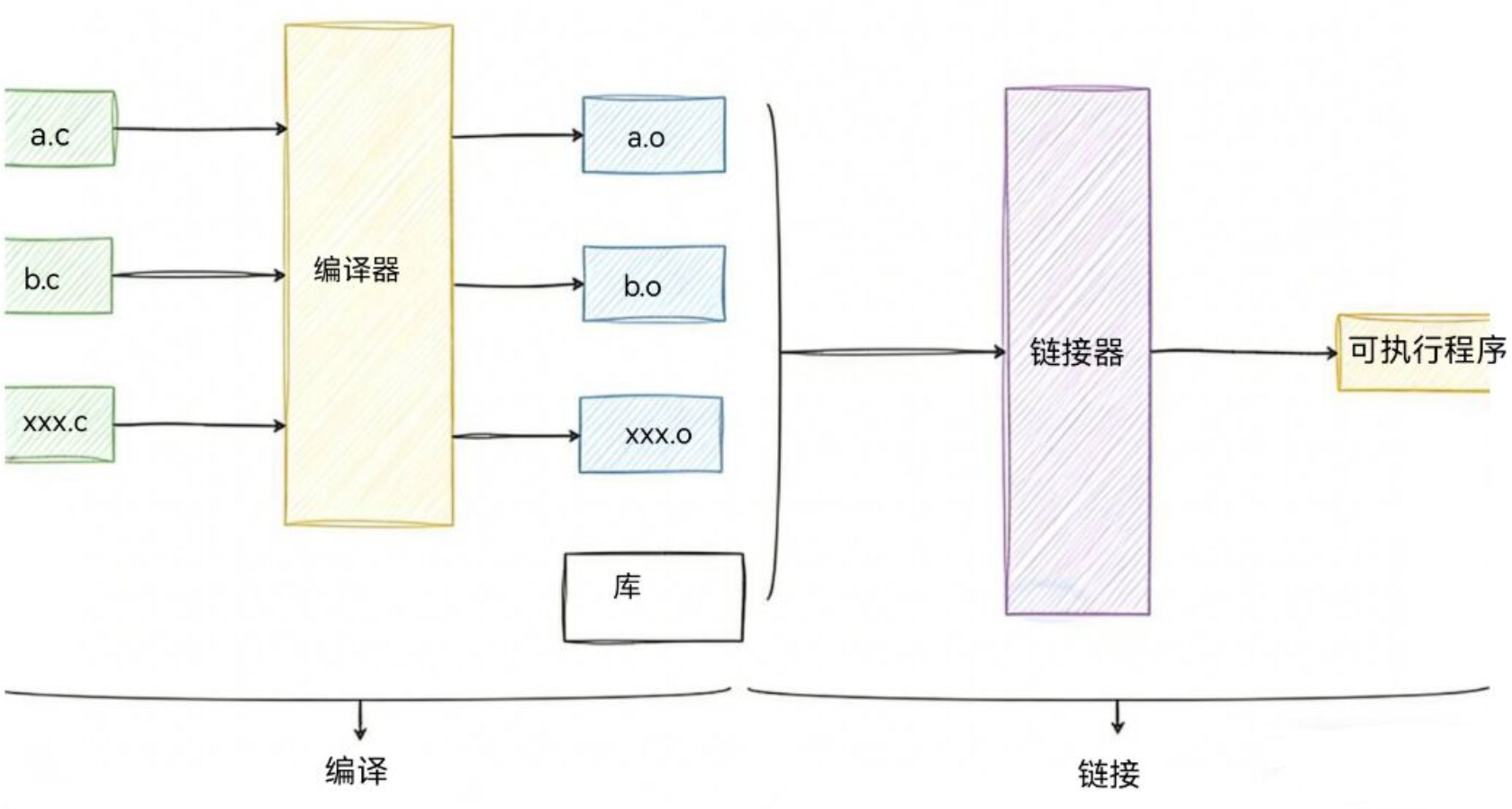
而下文则展示了每个阶段下,头文件与目标文件不可分割的原因!
下面我们来详细说明 ( ̄▼ ̄)
编译链接的核心分工
C/C++ 程序的构建分为「编译(Compile)」和「链接(Link)」两大核心步骤:
| 阶段 | 输入 | 核心工作 | 输出 |
|---|---|---|---|
| 编译阶段 | .c/.cpp + .h | 预处理(展开头文件 / 宏)→ 语法检查 → 生成汇编代码 → 汇编为目标文件(.o/.obj) | 目标文件 |
| 链接阶段 | 目标文件 + 库文件 | 解析符号引用(函数 / 变量)→ 将目标文件与库的二进制代码合并 → 解决依赖 | 可执行文件 / 库 |
简单说:头文件管「告诉编译器有什么」,库文件管「告诉链接器在哪里」。
编译阶段的核心作用
当调用库时为什么编译要有对应的.h 文件?
库的本质是封装好的二进制代码(比如你调用的printf在 libc 库中),但编译器在处理你的代码时,并不知道库中函数 / 变量的「接口信息」(比如函数的参数类型、返回值、变量类型、宏定义等),而.h 文件正是用来提供这些「接口声明」的。
就拿旧c标准的printf举例:
你写了printf("hello");,如果没有包含<stdio.h>(头文件):
编译阶段:编译器看到使用printf函数,但不知道它的返回值是int、参数是const char*,会默认按「返回 int、参数任意」处理,若参数类型不匹配(比如传了非字符串),编译器无法检查错误;
即使编译侥幸通过,链接阶段可能因符号签名不匹配(比如 C++ 的名字修饰)导致链接失败;
更严重的时,如果函数调用约定(比如参数传递方式)不匹配,程序运行时会崩溃(比如栈溢出)
所以我们得到头文件的核心价值:
- 接口声明:告诉编译器「库中有这个函数 / 变量,它的类型 / 参数 / 返回值是这样的」,让编译器能正确生成调用代码(比如栈布局、寄存器传参);
- 类型检查:编译器根据头文件的声明,检查你调用库函数的方式是否正确(参数个数、类型是否匹配),提前暴露错误;
- 宏 / 常量 / 结构体定义:库中用到的宏(如NULL)、常量(如EOF)、结构体(如FILE)都定义在头文件中,没有它们,代码连编译都通不过;
- 链接符号匹配:C++ 中头文件的extern "C"等声明,能保证编译生成的符号名与库中的符号名一致(避免名字修饰导致链接找不到符号)。
链接阶段
在进行链接时,只认二进制库,但依赖头文件的声明!
链接器的工作是「找符号」:你的目标文件中会记录「我调用了printf,但没定义它」,链接器需要从 libc 库的二进制文件中找到printf的实现代码,合并到可执行文件中。
但如果没有头文件:
- 编译阶段生成的目标文件中,printf的调用符号可能是错误的(比如 C++ 未加extern "C"导致符号名被修饰成_Z6printfPKc,而 libc 中的符号是printf);
- 即使符号名对了,函数调用的参数布局错误,链接后的程序运行时也会出错(链接器只检查符号是否存在,不检查参数是否匹配)。
由此便结束了今天的学习\\\\٩( 'ω' )و ////