BitMap 简单介绍
高效的数据结构(bit数组),使用二进制位(0或1)来简洁地表示信息,适用于处理海量数据(大规模整数)的去重、查询和统计。
更优的Bitmap - RoaringBitmap
将32位整数分成高16位(计算桶的索引位置)和低16位(实际存放数据的桶),使用桶来存储。Container有三种类型:ArrayContainer、BitmapContainer和RunContainer
使用要求:
字段为 int 类型: 连续性越好,性能越高
示例:
单位关系: (1byte = 8bit) 1 int = 4byte
bitmap 实际空间: 99999999 / 8 / 1024 /1024 = 11.92 M
RoaringBitmap 实际空间: 22 + 2 2 = 8 byte 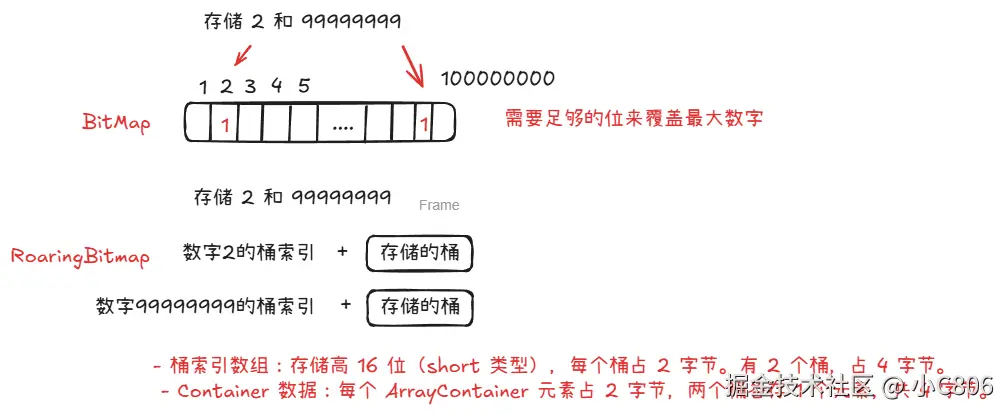
在Hive 和 Starrocks 联合使用
使用场景:
大量数据精确去重场景: 热门网站 pv pu , 用户画像圈人等场景
- bitmap 索引加速(starrocks 使用较多)
- hive 中使用(包括spark)
- hive中原生不支持 bitmap,一般需要自己构建UDF将数据转成bitmap格式,然后存储为 binary 类型。
UDF 构建
在新版本的starrocks中,有官方提高的 hive-udf.jar 包可以支持 hive bitmap的使用;
jar 包地址
fe/hive-udf/hive-udf-1.0.0.jar
使用场景
- 原始数据量大,需要导入 starrocks 构建bitmap类型字段,直接导入会导致 SR 集群负载高,希望在 hive 中构建完成再导入。
- 导出 starrocks 中的 bitmap 至 hive,提供其他场景使用
支持的 hive bitmap udf 函数:
具体参考: https://docs.starrocks.io/zh/docs/3.5/sql-reference/sql-functions/hive_bitmap_udf/#%E6%94%AF%E6%8C%81%E7%94%9F%E6%88%90%E7%9A%84-hive-bitmap-udf-%E5%87%BD%E6%95%B0
常用以下:
- bitmapAgg :将数据列转成 bitmap 类型,性能好
- bitmapcount:统计bitmap中的数据值
- bitmapunion: 求一组bitmap的并集一般联合 bitmapcount 使用, 效果类时 count distinct
使用前提(对象列必须为 整数类型):
非整数字符串数据需要构建全局字典表进行映射
构建方式:
- hive 中处理
sql
-- 字典表
create table prd_tmp.dict_test (id string,load_date string, id_int bigint) using orc;
-- 数据写入 or 更新
with
max_id_int as (
select ifnull(max(id_int),0) as max_id_int from prd_tmp.dict_test
)
,
new_data as (
select
sale_ordr_doc
,date_format(CURRENT_TIMESTAMP(),'yyyyMMdd') load_date
,(row_number() over(order by sale_ordr_doc )) + (select * from max_id_int) id_int
from prd_dwd.ordr_detl t1
left join prd_tmp.dict_test t2 on t1.sale_ordr_doc = t2.id
where t2.id is null and t1.stat_date = '20251213'
group by sale_ordr_doc limit 100
)
insert into prd_tmp.dict_test
select * from new_data效果如下: 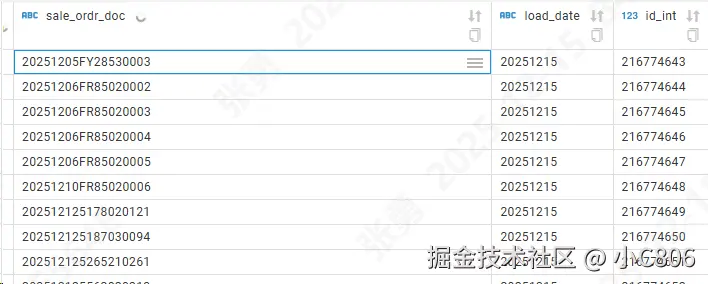
- Starrocks 中处理
Starrocks 3.0 + 版本支持,auto_increment 可简化全局字典构建流程
详情:https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/table_bucket_part_index/auto_increment/
使用注意事项:https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/table_bucket_part_index/auto_increment/#%E5%8D%95%E8%B0%83%E6%80%A7%E4%BF%9D%E8%AF%81
sql
-- 构建带自增的主键表,主键为需要替换的ID
CREATE TABLE test_tbl1
(
id BIGINT NOT NULL,
number BIGINT NOT NULL AUTO_INCREMENT
)
PRIMARY KEY (id)
DISTRIBUTED BY HASH(id)
PROPERTIES("replicated_storage" = "true");hive 中使用bitmap UDF查询
sql
-- 1. 将 hive-udf.jar 上传至hdfs目录, 这里假如上传至 /tmp 目录
-- 2. 链接hive或者spark
-- 3. 注册jar
add jar hdfs:///tmp/hive-udf.jar;
-- 4. 创建函数
create temporary function bitmap_count as 'com.starrocks.hive.udf.UDFBitmapCount';
create temporary function bitmap_agg as 'com.starrocks.hive.udf.UDAFBitmapAgg';
-- 5. bitmap 函数去重查询
select bitmap_count(bitmap_agg(id_int)) from
(select
t1.sale_ordr_doc,
t2.id_int
from
ordr_detl t1
left join prd_tmp.dict_test t2 on t1.sale_ordr_doc = t2.id
where t1.dt >= '20250710' and t1.dt<='20251210' ) a ;
-- 6. 不使用bitmap 函数去重查询 (也可以不关联 prd_tmp.dict_test ,直接count原表的 id,这里为了验证 id_int 的数据量是否准确,所以保持一致 )
select count(DISTINCT id_int) from
(select
t1.sale_ordr_doc,
t2.id_int
from
ordr_detl t1
left join prd_tmp.dict_test t2 on t1.sale_ordr_doc = t2.id
where t1.stat_date >= '20250710' and t1.stat_date<='20251210' ) a ;两者执行DAG和耗时如下: 左边为不使用 bitmap,右边为使用 bitmap, 耗时方面有所提升 (为什么: 因为 【bitmap_agg(id_int)】过程为将查询的 int_id 构建为bitmap , 也存在性能损耗)
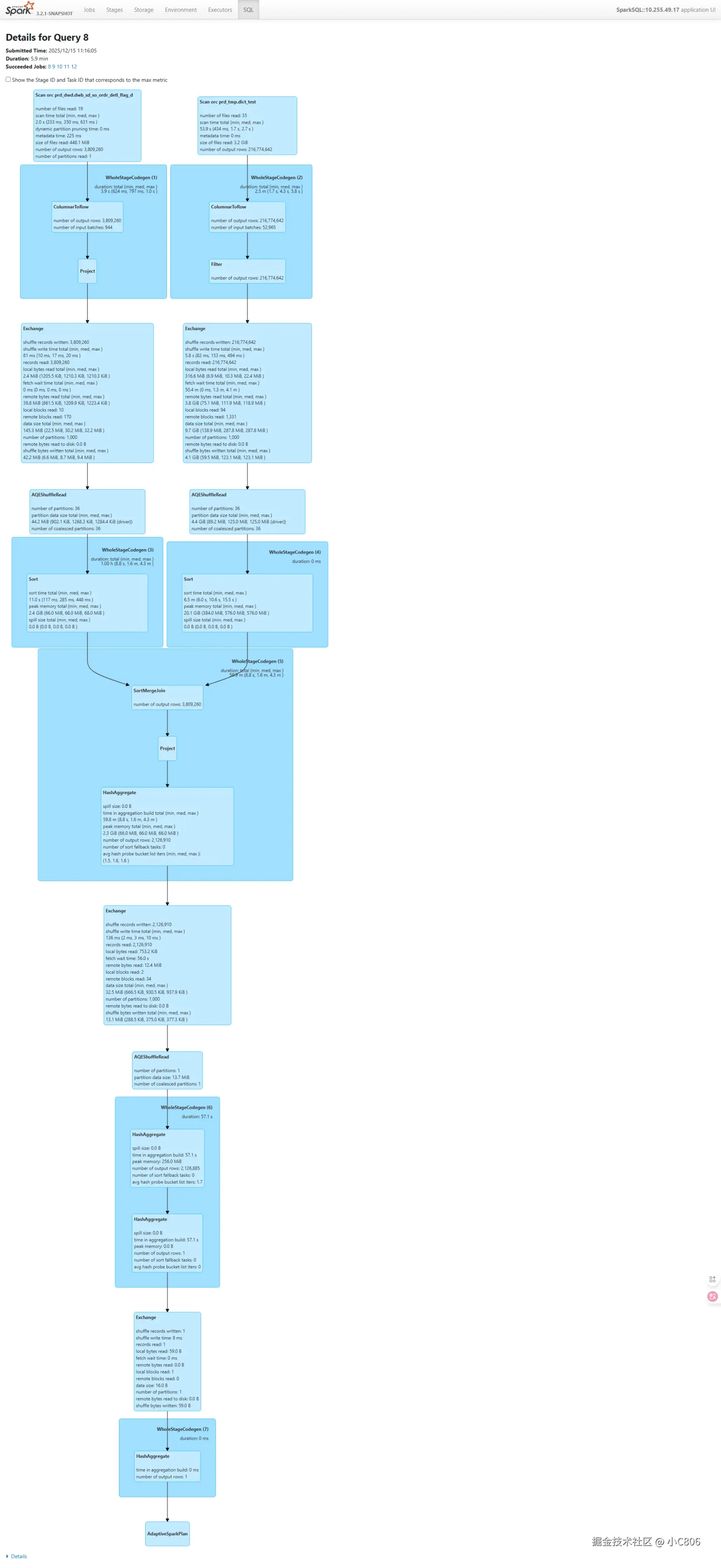
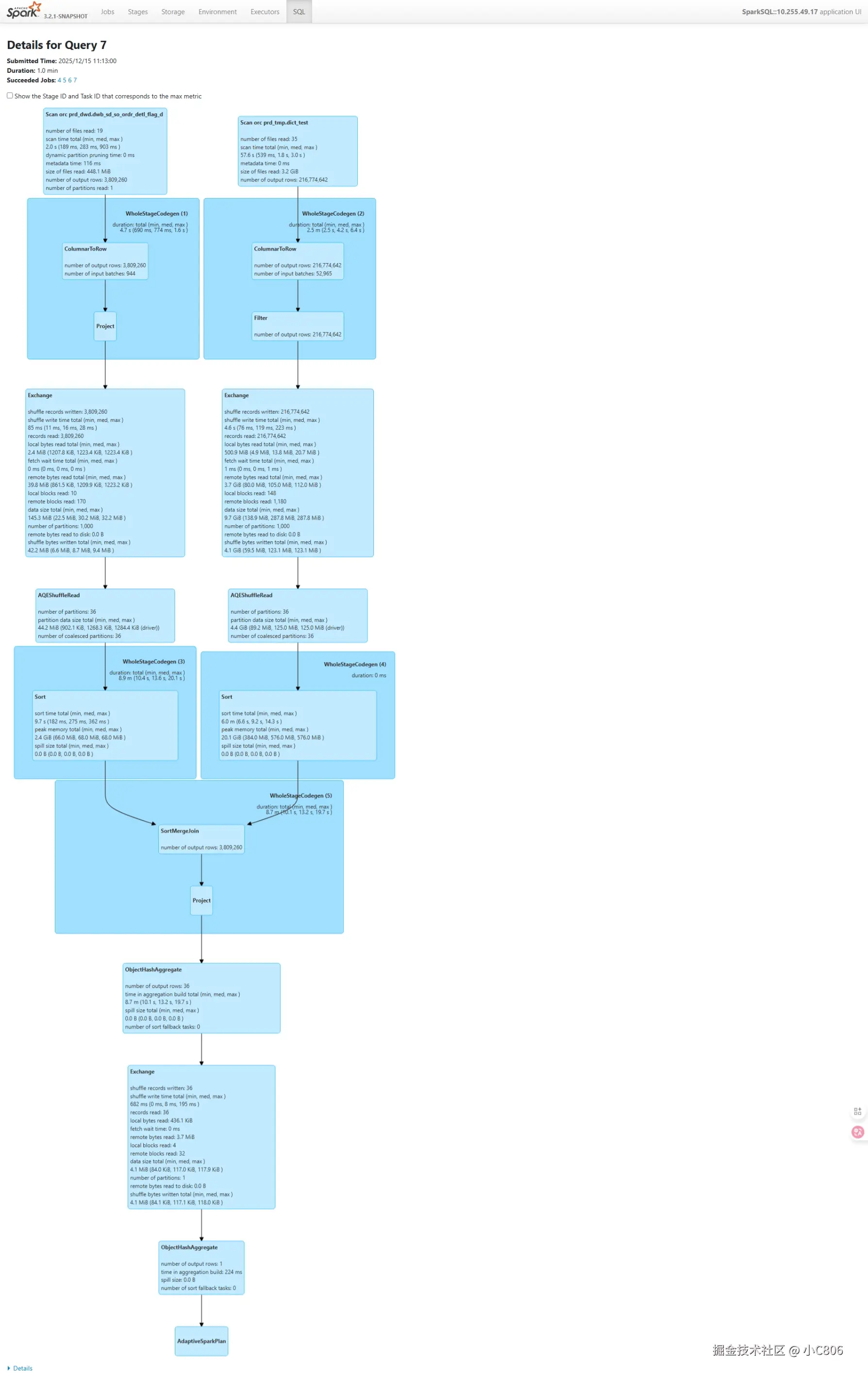
对比下来,速度有一定提升,主要差别体现在执行计划上, 使用bitmap是,少了一段 shuffle 过程, 在数据的交换上也比count distinct 上小一个量级,在资源上有一定的节省。
Starrocks 中使用
方式 :
- 在hive中根据使用场景构建完bitmap后导入starrocks
- 直接在starrocks中使用明细数据在物化视图中使用
两者根据场景选择,第一种适用于查询场景固定且数据量巨大,可以降低starrocks的集群负载,
第二种属于直接在starrocks中进行计算构建,集群负载比第一种场景要高。
hive中构建导入
某个商品的订单数:
sql
-- 构建 hive bitmap 表
create table prd_tmp.bitmap_goods_ordr_test(
goods_code varchar(16),
bitmap_col binary) using orc;
-- 数据写入
insert into prd_tmp.bitmap_goods_ordr_test
select
t1.goods_code
,bitmap_agg(t2.id_int) as bitmap_col
from
ordr_detl t1
left join prd_tmp.dict_test t2
on t1.sale_ordr_doc = t2.id
where t2.id is not null and t1.stat_date >= '20250710' and t1.stat_date<='20251210'
group by t1.goods_code
-- sr 建表
create table bitmap_goods_ordr_test(
goods_code varchar(16), bitmap_col bitmap bitmap_union)
aggregate key(goods_code)
distributed by hash(goods_code);
-- 数据写入 方式有很多种这里使用 broker load
LOAD LABEL rpt_db.bitmap_goods_ordr_test_1
(
data infile("hdfs://xxxx:8020/warehouse/tablespace/managed/hive/prd_tmp.db/bitmap_goods_ordr_test/*")
into table bitmap_goods_ordr_test
format as "orc"
)
WITH BROKER
(
"username" = "hdfs"
)
-- starrocks 数据查询
-- bitmap_to_string(bitmap_col) 将 bitmap 转成字符串
-- bitmap_count 计算bitmap中的id个数
select goods_code,bitmap_to_string(bitmap_col) as c2,bitmap_count(bitmap_col) as cnt
from bitmap_goods_ordr_test where goods_code in ('1000310','1000324','1000330');c2 为转换后的 int 类型的订单ID 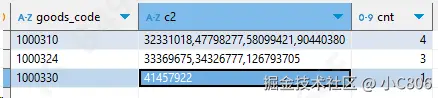
Starrocks 中使用构建使用
- 创建明细表
- 创建字典表
- 替换或者关联字典表使用
- 使用 dit_mapping 函数,
版本 3.x 之后且不支持存算分离部署方式结合物化视图
sql
```sql
-- 创建明细表
CREATE TABLE ordr_detl (
store_code string,
goods_code string,
sale_ordr_doc string ,
int_sale_ordr_doc bigint ,
dt date
)
ENGINE=OLAP
DUPLICATE KEY(store_code,goods_code,sale_ordr_doc,dt)
PARTITION BY RANGE(`dt`)()
DISTRIBUTED BY HASH(`store_code`) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-180",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.replication_num" = "3",
"dynamic_partition.buckets" = "3",
"in_memory" = "false"
);
-- 示例查询
select stsc_mon , phmc_code , count(DISTINCT sale_ordr_doc)
from ordr_detl where dt >= '2025-07-01'
group by phmc_code,stsc_mon;
select stsc_mon , phmc_code , bitmap_count(bitmap_union(to_bitmap(int_sale_ordr_doc)))
from ordr_detl where dt >= '2025-07-01'
group by phmc_code,stsc_mon;耗时对比: 上述为 bitmap , 下述为 count distinct 修正这里的耗时仅作为参考,bitmap_union(to_bitmap(int_sale_ordr_doc) ) 代表需要从整数构建成bitmap类型的过程,当基数较大时耗费的时间和CPU会很长,从而导致耗时比distinct更长,所以一般将该部分放在物化视图中进行构建,查询时之间使用

在查询资源消耗上 bitmap 有很大的节省. 图片太大无法上传
使用场景分析
- 需要实时分析的场景+数据量较大的count去重分析+查询灵活多变:一般建议使用明细模型+物化视图+bitmap进行处理 灵活处理。
- 固定场景+离线分析:可以使用hive进行离线计算后导入使用,及预计算。
物化视图
分为同步物化视图 和异步物化视图
- 同步物化视图
- 仅支持单表
- 同步刷新,无需人工操作
- 仅支持基于 default catalog 的单表构建
- 支持的聚合函数: min, max, hll_union, percentile_union, count, sum, bitmap_union
- 异步物化视图
- 支持多表关联
- 异步更新,手动刷新
- 支持多表构建:Default catalog、external catalog (v2.5)、已有异步物化视图(v2.5)、已有视图(v3.1)
sql
-- 定义查询场景
select dt,phmc_code,count(DISTINCT int_sale_ordr_doc) ordr_cnt
from ordr_detl
group by dt,phmc_code ;
-- 构建物化视图
CREATE MATERIALIZED VIEW store_ordr_cnt AS
select dt,phmc_code,bitmap_union(to_bitmap(int_sale_ordr_doc)) ordr_cnt
from ordr_detl
group by dt,phmc_code ;
-- 查看物化视图构建状态
SHOW ALTER MATERIALIZED VIEW
-- 取消正在构建的物化视图 12090 为 job ID 使用 【SHOW ALTER MATERIALIZED VIEW】 获取
CANCEL ALTER TABLE ROLLUP FROM ordr_detl (12090);
-- 删除构建完成的物化视图
DROP MATERIALIZED VIEW store_amt;构建状态: 
之前的查询计划:【使用原表作为查询底表】 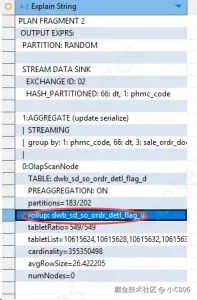
构建完成后再次执行查看执行计划:【使用物化视图作为底表查询】
备注 在执行sql SR 会根据已有的物化视图自动改写查询,如果匹配中有可用的物化视图则会
sql
select dt,phmc_code,count(DISTINCT int_sale_ordr_doc) ordr_cnt
from ordr_detl
group by dt,phmc_code ;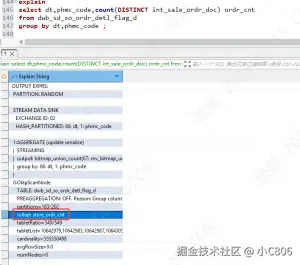
查看表结构会发现多出一个物化视图相关的信息:【DESC ordr_detl_flag ALL】 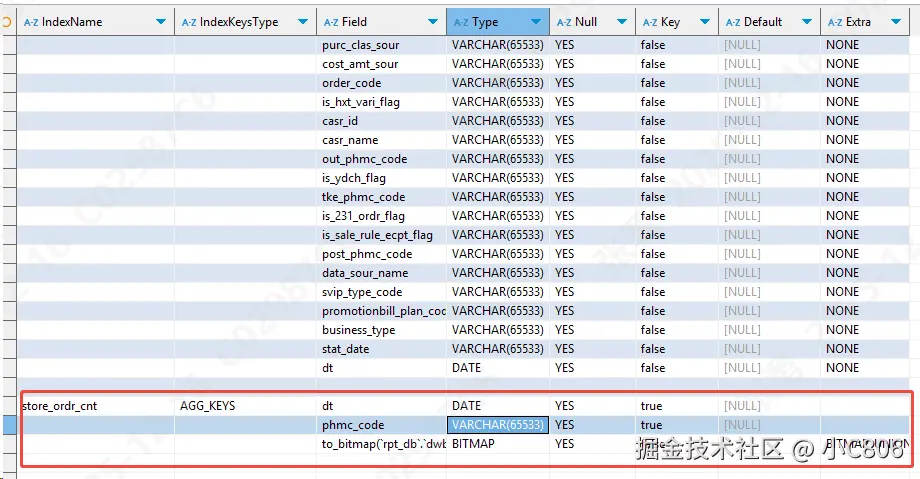
异步物化视图
- 多表关联
- 手动调用、定时任务、或者自动触发刷新
- 支持部分分区刷新
- 支持更多的聚合算子
使用场景:
数仓环境:
- 加速重复聚合查询:大量可重复使用的子查询,占用大量资源
- 周期性多表关联查询:多表关联形成宽表,可以避免手动关联调度任务,设置定期刷新规则
- 数仓分层
- 湖仓加速:查询数据湖可能因为网络延迟或者对象存储吞吐限制变慢,构建物化视图固化
sql
-- 查询示例
select dt,phmc_code,ordr_sour_code ,count(DISTINCT sale_ordr_doc) ordr_cnt from dwb_sd_so_ordr_detl_flag_d
group by dt,phmc_code,ordr_sour_code
DISTRIBUTED BY HASH(`order_id`)
CREATE MATERIALIZED VIEW order_mv
REFRESH ASYNC START('2022-09-01 10:00:00') EVERY (interval 1 day)
AS
select dt,phmc_code,ordr_sour_code ,bitmap_union(to_bitmap(int_sale_ordr_doc)) ordr_cnt from dwb_sd_so_ordr_detl_flag_d
group by dt,phmc_code,ordr_sour_code查看异步视图执行状态:
查看 tasks 表中的最新任务 select * from information_schema.tasks order by CREATE_TIME desc limit 1; 
查看 在 task_runs 表中的执行状态 select * from information_schema.task_runs where task_name='mv-10647552' order by CREATE_TIME; 
手动刷新异步视图 REFRESH MATERIALIZED VIEW order_mv;
实际使用:
基于 异步视图 order_mv 测试
sql
-- 查询语句在 ordr_mv 的子集中 SR 自动改写使用了 物化视图
select phmc_code,ordr_sour_code,count(DISTINCT int_sale_ordr_doc) ordr_cnt from ordr_detl
where dt >= '2025-10-01'
group by phmc_code,ordr_sour_codeexplain 如下: count distinct 也转成了 bitmap 操作
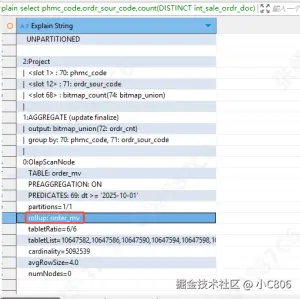
可以将物化视图看成一张物理表,索引、分区、分桶等优化操作都可执行,具体参考官网 : https://docs.starrocks.io/zh/docs/3.5/sql-reference/sql-statements/materialized_view/CREATE_MATERIALIZED_VIEW/
性能虽好合理使用:
优点:
- 提升响应速度,优化查询性能
- 优化任务分层逻辑
不足:
- 人工配置,维护成本高
- 异步视图,定时刷新,难以保证数据的强一致性
- 过多的物化视图导致集群压力过大,维护困难
- 物化视图空间换时间,存储成本增加