一、实验内容
基于cart-pole环境,实验AC算法的效果,并于策略梯度比较。
通俗理解:
actor是不知道啥好啥不好,只会不停的采样数据
基于采样到的数据,critic模型逐渐学会价值判断,学会价值判断有啥用呢?能够指导actor学习,让actor知道自己采样的数据是好还是差。
① 瞎子 背着 瘸子 走路
② 互利共赢
二、实验目标
2.1 确定实验流程(伪代码)
这是一个在线学习算法,收集episode粒度的数据,然后训练Critic模型、Critic模型可以进一步训练Actor模型。

初始化策略网络、价值网络
for 序列e=1->E:
用当前策略采样轨迹e={s,a,r,s,a......}
delta = [r + gamma*V(St+1)] - V(St)
# 优化价值模型
for d in e:
loss = torch.MSE(V(s), r + gamma*V(St+1))
# 优化策略模型
for d in e:
loss = -[delta]*log(π(a|s))2.2 建模Actor
2.3 建模Critic
2.4 建模Loss函数(即微分对象)
2.5 比较AC算法与策略梯度效果
目标 - 微分 - Loss 关系
三、实验过程
3.1 流程
完整代码见附件
3.2 建模Actor
Actor输入state,输出action分布,为critic提供TD训练数据
python
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)3.3 建模Critic
critic输入state,输出价值预估,为actor提供训练数据
python
class ValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
# 价值预估没有加激活函数
return self.fc2(x)3.4 建模Loss
建模AC强化算法,基于 时序差分优势 优化Actor模型,基于均方误差优化Critic模型。
python
def update(self, transition_dict):
# 获取sarsa五元组
# 时序差分目标
td_target = rewards + self.gamma * self.critic(next_states) * (1 -
dones)
td_delta = td_target - self.critic(states) # 时序差分误差
log_probs = torch.log(self.actor(states).gather(1, actions))
actor_loss = torch.mean(-log_probs * td_delta.detach())
# 均方误差损失函数
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward() # 计算策略网络的梯度
critic_loss.backward() # 计算价值网络的梯度
self.actor_optimizer.step() # 更新策略网络的参数
self.critic_optimizer.step() # 更新价值网络的参数四、实验结果
结论先行
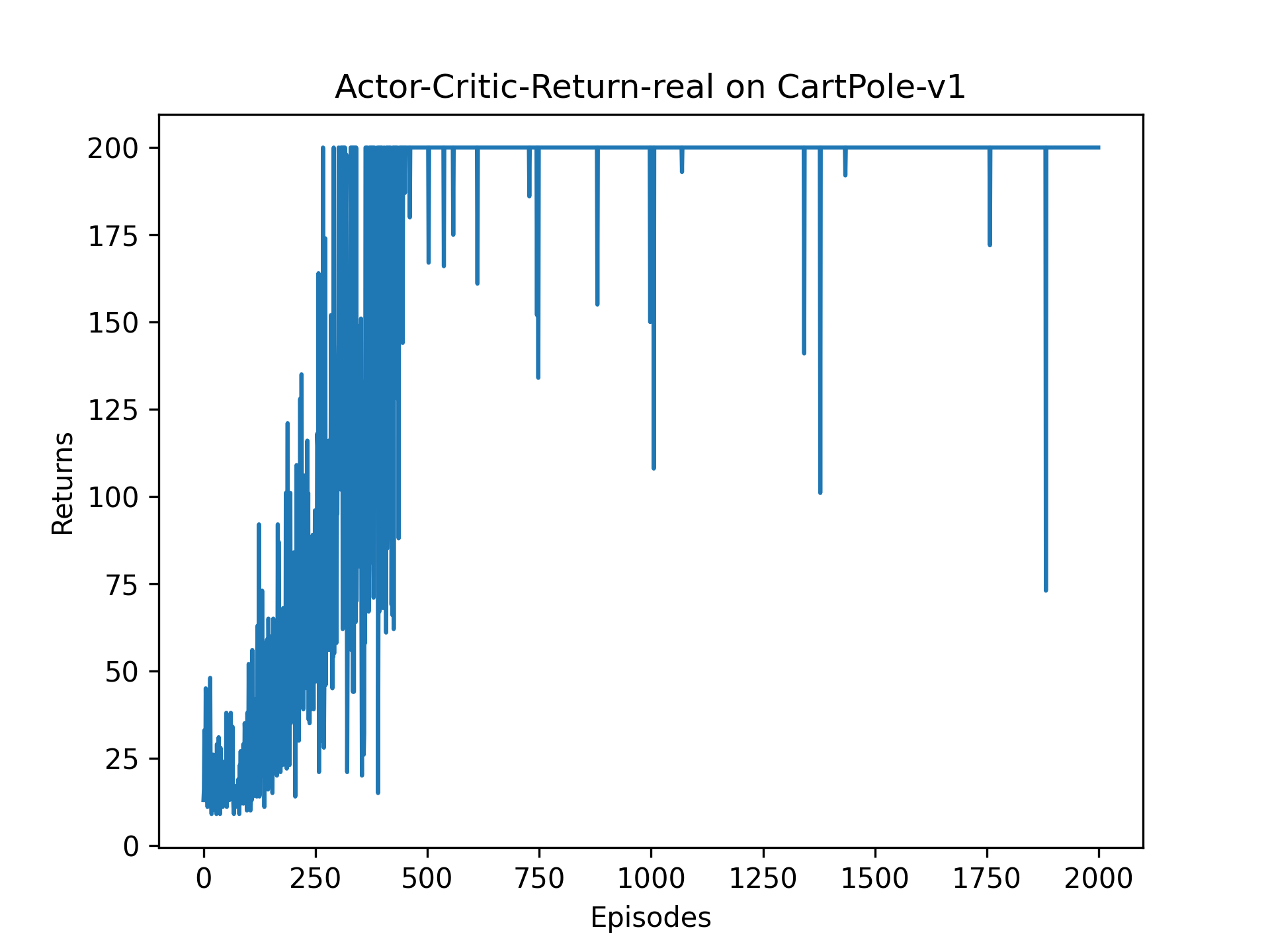
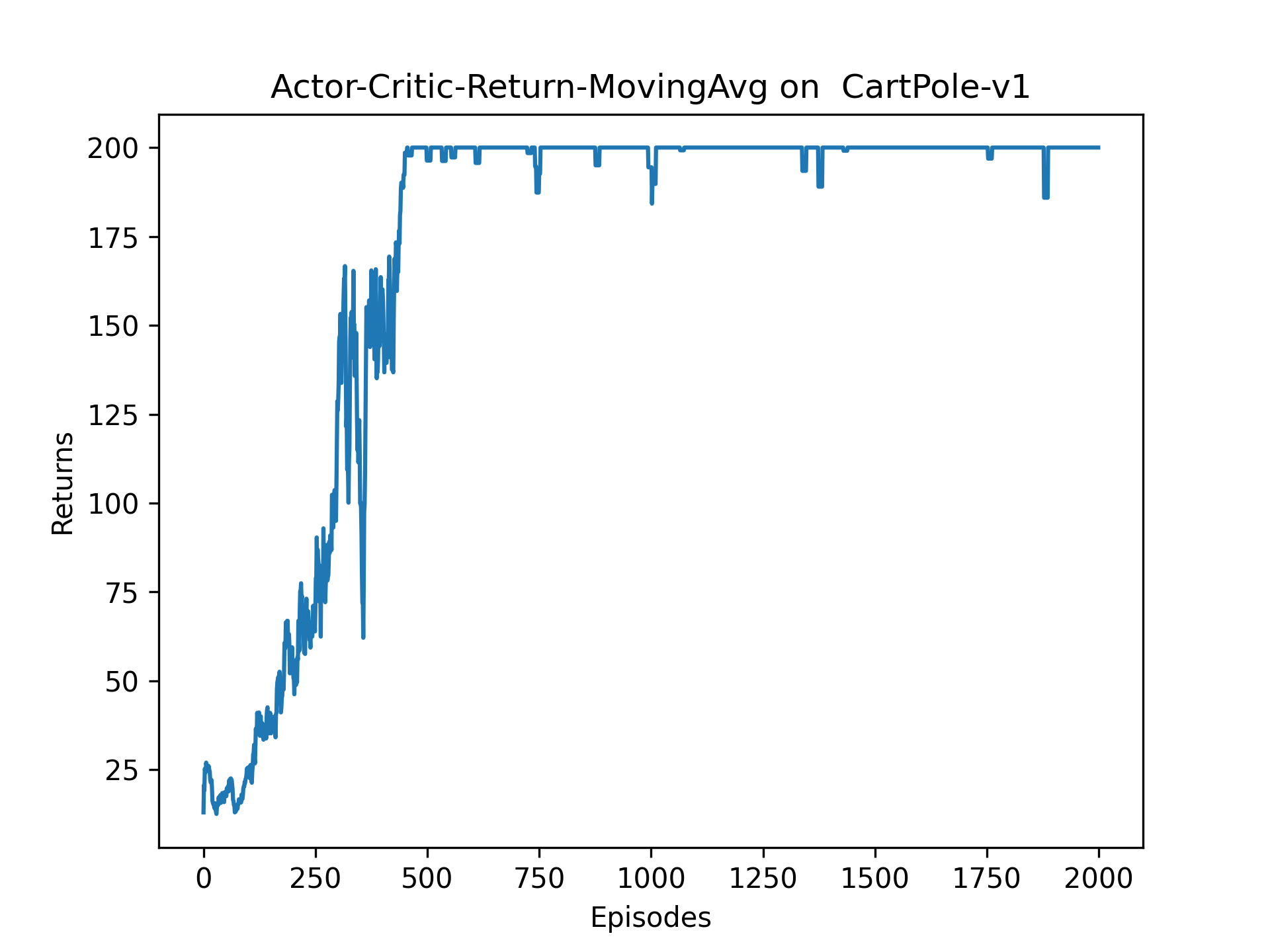
① 收敛效果明显由于策略梯度算法
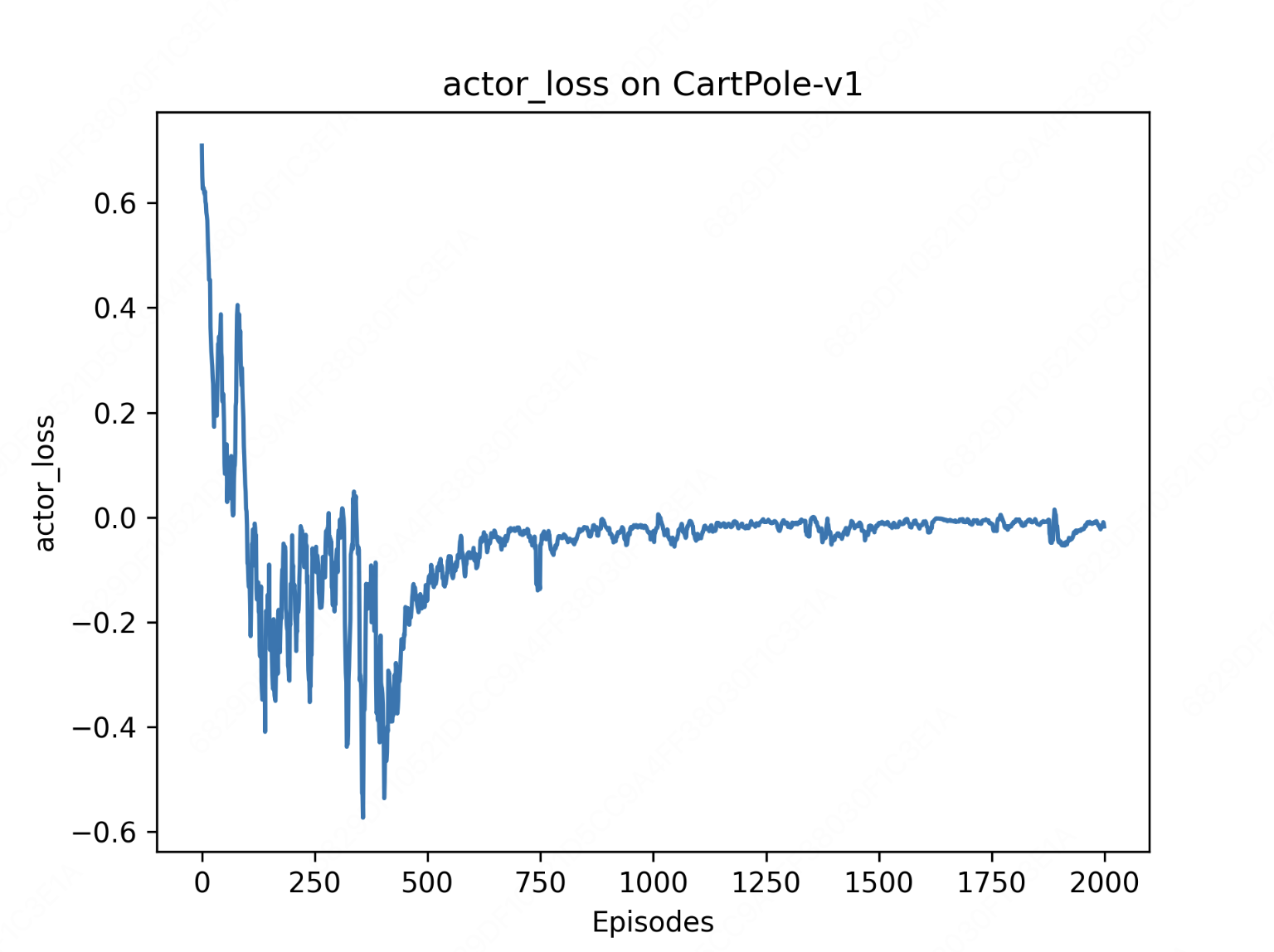
② actor-loss先降低,而后回升,原因未知(可能需要引入目标网络-PPO、熵正则化-SAC)。
4.1 实际收益
4.2 平滑收益
4.3 actor-loss
4.4 critic-loss