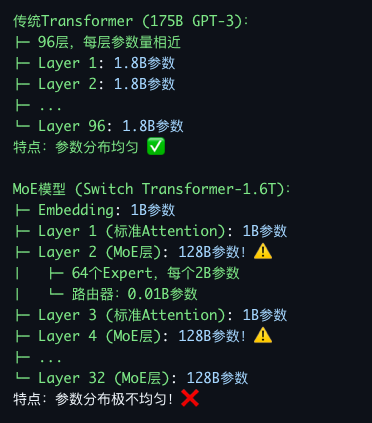
MoE 区别于传统的 Transformer 是其参数分布极为不均
传统Transformer (175B GPT-3): ├─ 96层,每层参数量相近 ├─ Layer 1: 1.8B参数 ├─ Layer 2: 1.8B参数 ├─ ... └─ Layer 96: 1.8B参数 特点:参数分布均匀 ✅ MoE模型 (Switch Transformer-1.6T): ├─ Embedding: 1B参数 ├─ Layer 1 (标准Attention): 1B参数 ├─ Layer 2 (MoE层): 128B参数!⚠️ │ ├─ 64个Expert,每个2B参数 │ └─ 路由器:0.01B参数 ├─ Layer 3 (标准Attention): 1B参数 ├─ Layer 4 (MoE层): 128B参数!⚠️ ├─ ... └─ Layer 32 (MoE层): 128B参数 特点:参数分布极不均匀!❌如果使用 ZeRO-3,当计算的时候all-gather 所有模型参数,如果 expert 数量很多,例如 64 个,那么总显存可能带 256G, 远超一个 GPU所能承载的
Expert Parallelism
核心思想
Expert并行 (EP):
不同GPU负责不同的Expert
只加载被本GPU负责的Expert参数
Token根据路由结果发送到对应GPU
配置:EP=64(64个GPU,每个负责1个Expert)
参数分配:
├─ GPU 0: Expert 0 (2GB)
├─ GPU 1: Expert 1 (2GB)
├─ GPU 2: Expert 2 (2GB)
├─ ...
└─ GPU 63: Expert 63 (2GB)每个GPU显存占用:
- Expert参数:2GB(只有1个Expert)✅
- 共享层参数:1GB(Attention等)
- 激活值:根据收到的token数量
Pytorch分布式训练/多卡训练(六) —— Expert Parallelism (MoE的特殊策略)
hxxjxw2025-12-18 17:58
相关推荐
神奇小汤圆5 分钟前
面试官:Agent意图识别怎么做?95%的人一句话就把自己送走了兜客互动21 分钟前
2026年AI关键词拓展挖掘软件,高效助力内容创作精准获流weixin_5386019722 分钟前
智能体测开Day30pytest测试框架MC皮蛋侠客24 分钟前
uv 系列(七):CI/CD、Docker 与私有索引——生产级交付AI的探索之旅25 分钟前
AI辅助原理图评审:电源去耦、BOOT引脚、VCAP——19项逐一核查,遗漏?不存在的武子康32 分钟前
Kimi K3 2.8T:开放权重不等于本地可跑 超稀疏 MoE、百万上下文与真实部署边界邪神与厨二病37 分钟前
牛客周赛 Round 153yaoxin5211231 小时前
470. Java 反射 - Member 接口与 AccessFlag老刘说AI1 小时前
AI服务核心: 高并发原理与性能监控调优GeekArch1 小时前
第24讲:Vibe模式代码风格控制——适配Keil/STM32工程规范