一、认识HTTP
HTTP(超文本传输协议)是互联网通信的基石。它定义了客户端(浏览器)和服务器之间如何交换数据(HTML、图片、视频等)。
核心特点:
- 应用层协议:基于 传输层/网络层协议 传输 。
- 无连接:虽然HTTP/1.1默认开启长连接(Keep-Alive),但在早期设计中,每次请求都需要重新建立连接 。
- 无状态:服务器默认不保存客户端的任何上下文信息,这也是为什么我们需要Cookie和Session的原因。
URL:统一资源定位符
平时我们说的"网址",在技术上称为URL。一个标准的URL包含以下部分: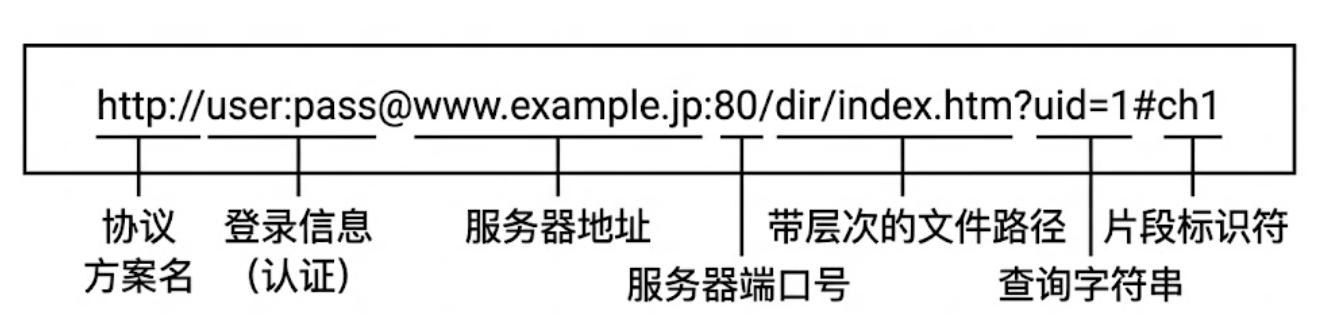
- 协议方案名 :如
http或https。 - 登录信息 :
user:pass。 - 服务器地址:域名或IP地址 。
- 端口号:HTTP默认80,HTTPS默认443 。
- 文件路径:带层次的资源路径 。
- 查询字符串 :
key=value形式,用&分隔 。 - 片段标识符 :
#后面部分,用于页面内部跳转 。
urlencode和urldecode
像 /, ?, : 等字符在URL中有特殊含义。如果参数本身包含这些字符,就必须转义。
规则 :将字符转为16进制,每2位前加 %。例如 C++ 会被转义为 C%2B%2B(+被转义为%2B)。
二、HTTP协议格式
HTTP是基于文本的协议,格式非常规整,主要分为请求和响应。
HTTP请求
请求报文由四部分组成:

- 请求行 :
方法 URL 版本(例如:GET /index.html HTTP/1.1) 。 - 请求头 :
Key: Value格式,每行一个,以\r\n结尾 。 - 空行 :
\r\n,非常重要,用于区分报头和正文 。 - 请求正文 :POST方法常用,GET通常为空。如果有正文,请求头中必须有
Content-Length
示例: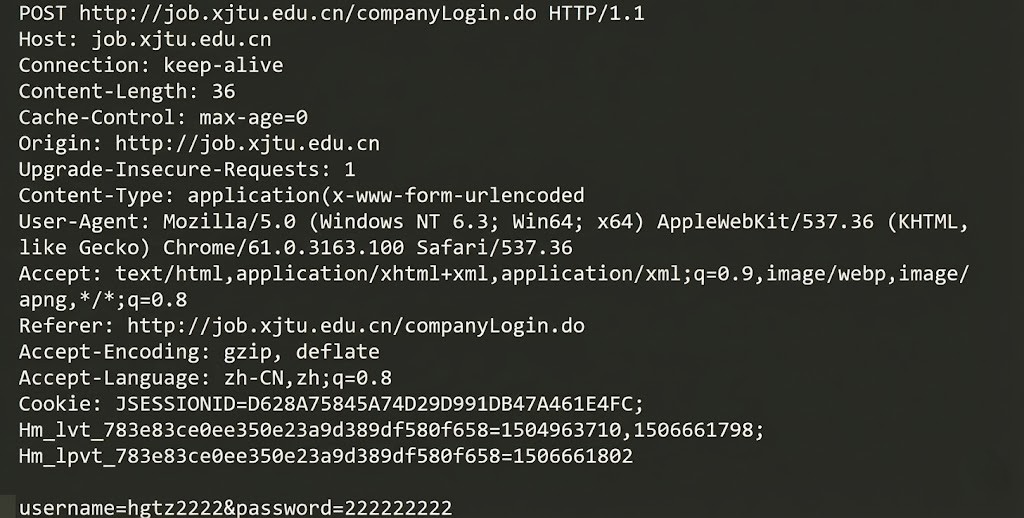
HTTP响应
响应报文也由四部分组成:
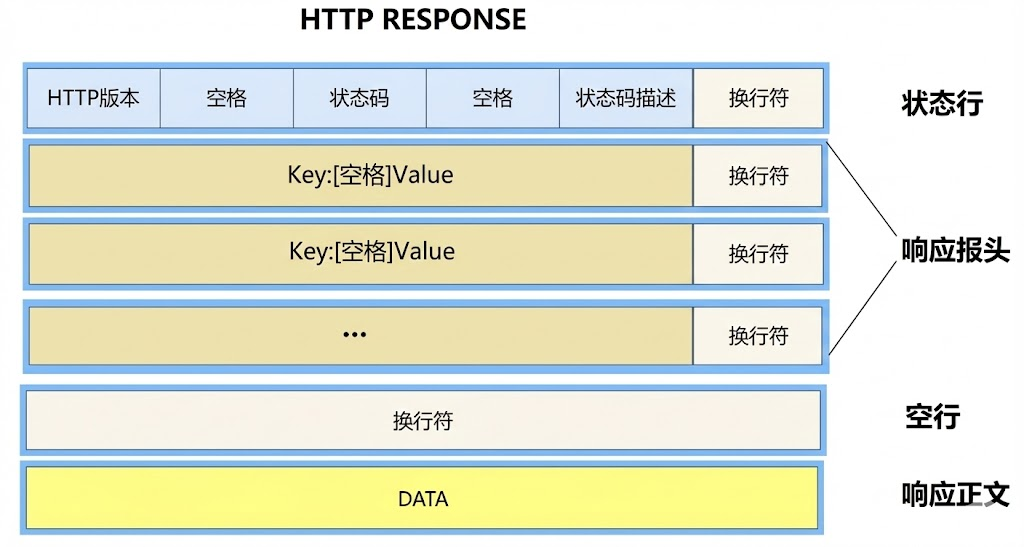
- 状态行 :
版本 状态码 状态描述(例如:HTTP/1.1 200 OK) 。 - 响应头:同请求头 。
- 空行 :
\r\n。 - 响应正文:服务器返回的数据(HTML、JSON等) 。
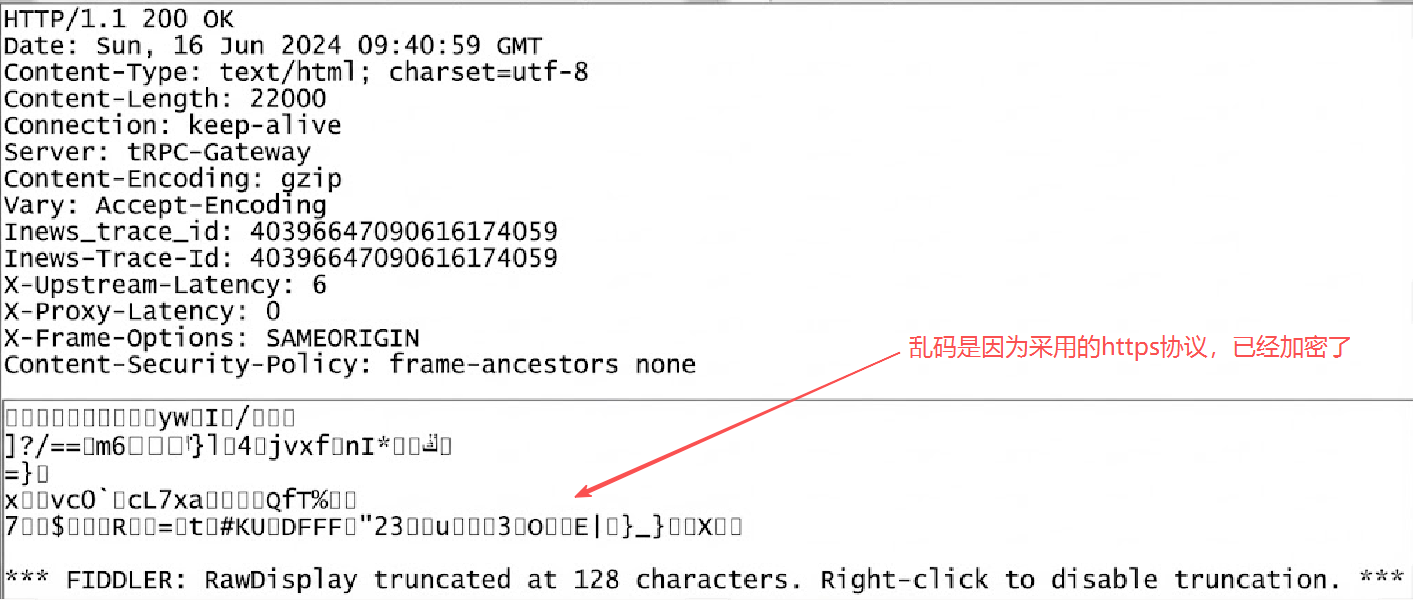
示例:
三、HTTP常用方法
虽然HTTP定义了很多方法,但我们最常用的主要是 GET 和 POST。
| 方法 | 说明 | 区别与应用场景 |
|---|---|---|
| GET | 获取资源 | 参数在URL中,不安全,有长度限制。常用于请求页面。 |
| POST | 传输实体主体 | 参数在正文中,相对安全,支持大数据量。常用于提交表单、登录。 |
| PUT | 传输文件 | 向服务器上传文件。 |
| DELETE | 删除文件 | 删除资源。 |
| HEAD | 获得报头 | 类似GET,但只返回报头,不返回正文。用于测试连接或检查资源修改时间 。 |
| OPTIONS | 询问支持方法 | 检查服务器支持哪些方法。 |
GET 请求可以用来上传文件/资源吗?
技术实现上讲是可以的,但在传输文件(二进制流)时极其受限。
首先就是
- Body 的缺失
在 HTTP 规范中,GET 请求通常不包含请求正文,这意味着,如果你想用 GET 传数据,只能把数据塞到 URL 的查询字符串里(即 ?key=value 后面)。
于是有了第2个问题
- URL 长度限制
上传文件通常意味着大数据量。虽然 HTTP 协议没限制 URL 长度,但浏览器和服务器有限制
-
IE 浏览器可能限制 2KB。
-
Chrome 可能限制 8KB 左右。
-
Nginx 默认配置也有限制。
试想一下,把一张 5MB 的图片塞进 URL 里,直接就报错了
- 二进制数据的编码
文件(图片、视频、压缩包)都是二进制数据,而URL 中只能包含 ASCII 字符。
把文件内容放在 URL 里,必须进行 URL 编码
这意味着原本 1MB 的文件,经过编码后体积会变得更大,而且编解码过程非常消耗 CPU 资源。
最关键的点是GET 请求的参数会明文显示在浏览器的地址栏中,也会被保存在浏览器历史记录、代理服务器日志和服务器访问日志中。如果你上传的是私密文件或敏感信息,会出安全问题。
PUT 和 POST 的区别
这是两者在技术实现上最本质的区别是幂等性。
那么什么是**幂等性:**一个操作执行一次和执行多次,对服务器状态产生的影响是一样的。
PUT 是幂等的:
如果你发送 PUT /articles/1 更新文章内容,无论你发送一次还是十次,服务器上的文章内容最终都是你发的那个版本。第 2 到 10 次的请求不会产生额外的副作用。
POST 不是幂等的:
如果你发送 POST /articles 创建文章,发送一次,服务器创建一篇文章。如果你不小心发了两次,服务器就会创建两篇内容相同但 ID 不同的文章。
四、HTTP状态码
状态码由三位数字组成,分为五大类:
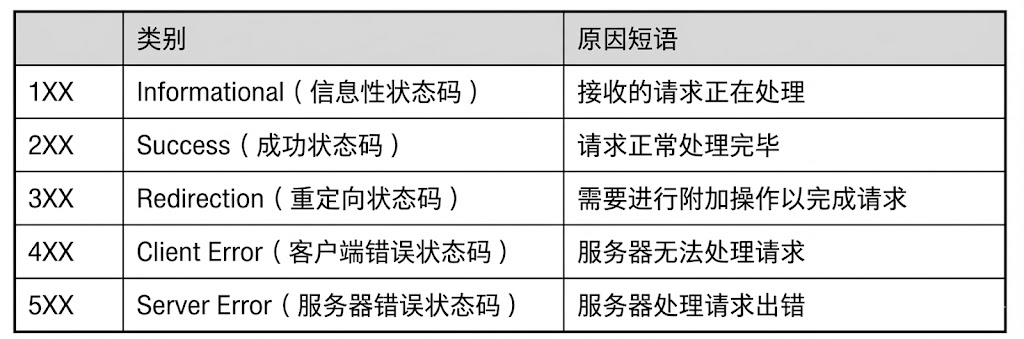
我们讲讲最常见的状态码,比如 200(OK),404(Not Found),403(Forbidden),302(Redirect,重定向),504(Bad Gateway)。
200 OK ------ 一切正常
含义:这是最希望看到的状态码,表示客户端的请求被服务器成功接收、理解并处理 。
场景:访问百度首页,服务器返回网页 HTML 内容。
Linux 验证:

404 Not Found ------ 查无此人
含义:服务器上没有找到你请求的资源 。
常见原因:
-
URL 输错了。
-
资源被删除了。
-
Linux 服务器的文件路径配置错误。
排查 :检查 URL拼写,或者去服务器上 ls 看看文件还在不在。
403 Forbidden ------ 禁止入内
含义:服务器收到了请求,但是拒绝提供服务 。
关键点:这和 401 不同。401 是不认识你,403 是我认识你,但你没权限。
常见原因:
-
文件权限问题(例如 Linux 下文件权限是 600,Web 服务器用户读不到)。
-
IP 白名单限制。
-
尝试访问目录列表。
302 Redirect ------ 临时重定向
核心机制: Location 头 无论是 301 还是 302,服务器都会在响应头里加一个 Location 字段,告诉浏览器:"你去这个新地址找它" 。
301、302 的区别 :
**301 :**搜索引擎会更新索引,浏览器会缓存这个跳转,下次直接去新地址,不问旧地址了。
HTTP/1.1 301 Moved Permanently\r\n
Location: https://www.new-url.com\r\n**302 :**搜索引擎不会更新索引,浏览器也不会缓存,下次还是先访问旧地址,看服务器怎么说。
HTTP/1.1 302 Found\r\n
Location: https://www.new-url.com\r\n场景:用户登录成功后,从"登录页" 302 跳转到"个人主页" 。
504 Gateway Timeout / 502 Bad Gateway
502 Bad Gateway:作为网关或代理服务器,从上游服务器收到了无效的响应 。
504 Gateway Timeout:通常表示网关超时。即 Nginx 转发请求给后端应用,但后端处理太慢,超过了 Nginx 等待的时间。
五、HTTP常见Header
Header是HTTP灵活性的体现,以下是必须要掌握的:
| 字段名 (Header) | 核心含义 | 详细说明与应用场景 |
|---|---|---|
| Content-Type | 数据类型 | 告诉接收端正文里是什么数据。例如 text/html (网页)、application/json (JSON数据)、multipart/form-data (文件上传) 。 |
| Content-Length | Body 长度 | 单位是字节。非常重要,因为 HTTP 是流式传输,接收端必须依靠这个长度才知道 Body 读到哪里结束 。 |
| Host | 主机域名 | 客户端告知服务器它请求的是哪个域名。这是虚拟主机技术的基础(允许一个 IP 地址部署多个网站,服务器靠 Host 区分)。 |
| User-Agent | 用户代理 | 声明客户端的身份,包含操作系统、浏览器版本等信息。服务器可据此返回适配手机或电脑的页面 。 |
| Referer | 来源页面 | 记录当前请求是从哪个页面跳转过来的。常用于防盗链。 |
| Location | 重定向地址 | 搭配 3xx 状态码使用。进行重定向。 |
| Cookie | 会话信息 | 用于在客户端存储少量状态信息。通常用于携带 Session ID,实现用户登录状态保持。 |
| Connection | 连接控制 | 控制 TCP 连接的状态: • keep-alive:长连接(HTTP/1.1 默认),复用 TCP 连接,减少握手开销。 • close:短连接(HTTP/1.0 默认),请求结束后立即关闭 TCP 连接。 |
六、实战:手写一个最简单的HTTP服务器
原理很简单:创建一个TCP Server,接收到连接后,不管客户端发什么请求,我们都按照HTTP响应格式返回 "hello world"。
cpp
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void Usage() {
printf("usage: ./server [ip] [port]\n");
}
int main(int argc, char* argv[]) {
if (argc != 3) {
Usage();
return 1;
}
// 1. 创建套接字
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0) {
perror("socket");
return 1;
}
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = inet_addr(argv[1]);
addr.sin_port = htons(atoi(argv[2]));
// 2. 绑定端口
int ret = bind(fd, (struct sockaddr*)&addr, sizeof(addr));
if (ret < 0) {
perror("bind");
return 1;
}
// 3. 监听
ret = listen(fd, 10);
if (ret < 0) {
perror("listen");
return 1;
}
for (;;) {
struct sockaddr_in client_addr;
socklen_t len = sizeof(client_addr);
// 4. 接受连接
int client_fd = accept(fd, (struct sockaddr*)&client_addr, &len);
if (client_fd < 0) {
perror("accept");
continue;
}
// 5. 读取请求
char input_buf[10240] = {0};
ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1);
if (read_size < 0) {
return 1;
}
printf("[Request] %s\n", input_buf); // 打印浏览器发来的请求内容
// 6. 构造HTTP响应
char buf[1024] = {0};
const char* hello = "<h1>hello world</h1>";
// 注意格式:状态行 + Header + 空行 + Body
sprintf(buf, "HTTP/1.0 200 OK\nContent-Length:%lu\n\n%s", strlen(hello), hello);
// 7. 发送响应
write(client_fd, buf, strlen(buf));
// 8. 关闭连接 (HTTP/1.0 默认短连接)
close(client_fd);
}
return 0;
}运行测试:
-
编译:
g++ server.c -o server -
运行:
./server 0 9090 -
浏览器访问:
http://[你的IP]:9090 -
你会看到页面显示大大的 "hello world"。
如果不加
HTTP/1.0 200 OK\n...这些协议头,直接发送 "hello world" 会怎样?
浏览器可能无法识别,或者认为是无效响应,这就说明协议就是双方都要遵守的约定。