1. 核心概念界定
- 语言人工智能(Language AI)是AI的子领域,专注于开发理解、处理和生成人类语言的技术,与自然语言处理(NLP)概念相近,还涵盖检索系统等非LLM核心技术。
- 大语言模型(LLMs)并非仅指"规模庞大"的生成型模型,而是涵盖所有具备强语言处理能力的模型,包括表征型(如BERT)和生成型(如GPT系列),"大"的定义随技术发展动态变化,核心是复杂语言理解与生成能力。
- 关键区分:表征模型(Encoder-only)不生成文本,专注语言表示,适用于分类、聚类等任务;生成模型(Decoder-only)核心功能是文本生成,采用自回归方式逐token生成,适用于对话、文本续写等任务。
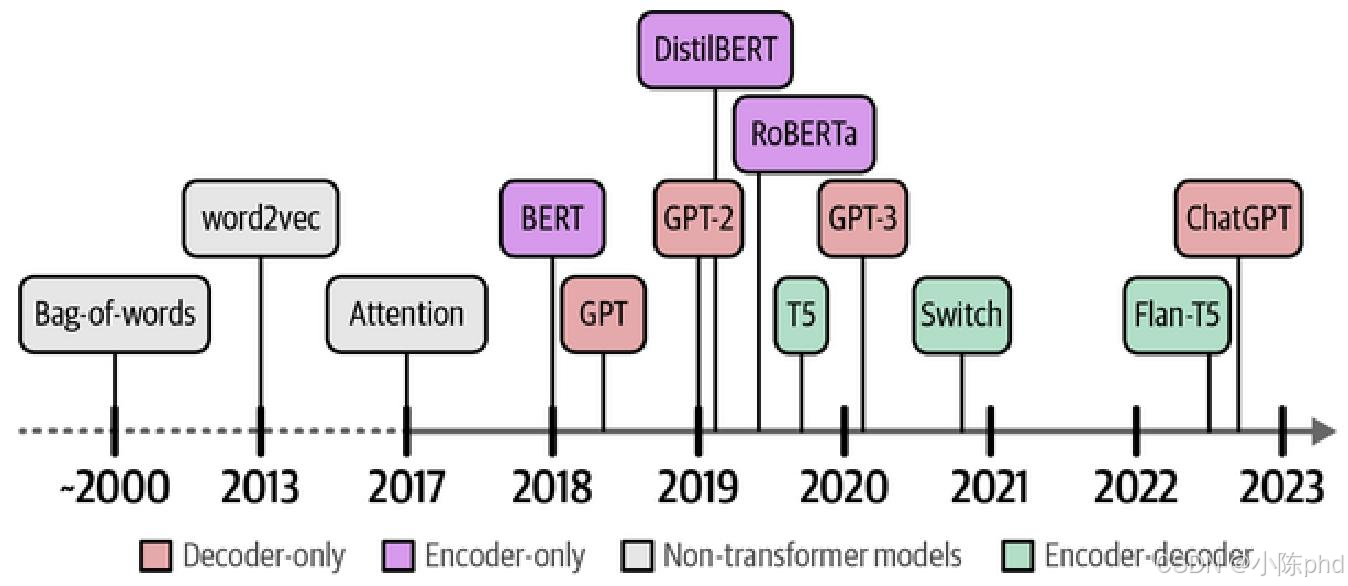
2. 语言AI的发展历程
- 早期阶段:以词袋模型(Bag-of-words)为代表,将文本拆分为独立单词并计数,忽略语义和语序,适用于简单文本表示。
- 关键突破:2013年word2vec通过神经网络学习词嵌入,捕捉单词语义关系;循环神经网络(RNNs)引入序列建模能力但存在长文本处理瓶颈;2014年注意力机制解决上下文依赖问题;2017年Transformer架构彻底脱离RNNs,基于纯注意力机制,支持并行训练,成为LLMs核心架构。
- 现代LLMs爆发:2018年BERT和GPT-1奠定两大技术路线;2022年ChatGPT(基于GPT-3.5)引爆普及;2023年"生成式AI元年",开源模型(如Llama 2、Mistral)与专有模型(如GPT-4、Claude 2)并行发展,新架构(如Mamba、RWKV)持续涌现。
3. LLM的训练范式
- 传统机器学习:单步训练,直接针对特定任务(如分类)训练模型,数据多为结构化。
- LLM双阶段训练:预训练(Pretraining)在海量无标注文本(如维基百科、网页数据)上训练,学习语法、上下文和语言模式,生成基础模型(Foundation Model),核心任务是"预测下一个单词";微调(Fine-tuning)基于预训练模型,用特定任务数据进一步训练,适配具体场景(如情感分析、指令遵循),大幅降低资源消耗。
4. 核心应用场景
LLMs的灵活性使其适用于多种任务,核心场景包括:
- 文本分类(如客户评论情感判断);
- 无监督聚类与主题建模(如提取工单共性主题);
- 检索与文档查询(如基于语义的文档检索);
- 对话机器人(结合检索增强、指令微调);
- 多模态任务(如图像到文本的食谱生成);
- 创意应用(如角色扮演、儿童书籍写作)。
5. 关键注意事项
- 伦理与责任:需警惕数据偏见、生成虚假信息、知识产权争议等问题,遵守相关法规(如欧盟AI法案)。
- 资源适配:训练和运行LLMs需强大GPU支持(如Meta训练Llama 2使用A100显卡),普通用户可通过Google Colab(免费T4 GPU,16GB VRAM)运行轻量化模型。
- 模型选择:专有模型(如GPT-4)性能强、无需本地硬件,但存在API成本、数据隐私风险;开源模型(如Phi-3-mini)可本地部署、自定义微调,适合资源有限或敏感数据场景。
6. 入门实践:生成第一句文本
通过Hugging Face Transformers库加载开源模型(以Microsoft Phi-3-mini为例),核心步骤包括:
- 加载模型和分词器(Tokenizer),分词器负责将文本转换为模型可处理的token ID;
- 构建对话提示(Prompt),遵循模型指定的格式(如
<<<|user|><<<|assistant|>标记); - 调用生成函数,通过参数(如
max_new_tokens控制生成长度、do_sample控制随机性)调整输出。
shell
# %%capture
!pip install transformers==4.41.2 accelerate==0.31.0
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=False,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
python
from transformers import pipeline
# Create a pipeline
generator = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
return_full_text=False,
max_new_tokens=500,
do_sample=False
)
python
# The prompt (user input / query)
messages = [
{"role": "user", "content": "Create a funny joke about chickens."}
]
# Generate output
output = generator(messages)
print(output[0]["generated_text"])