分词器相关包:该github文档有详细说明,建议先看看。
https://github.com/magese/ik-analyzer-solr?tab=readme-ov-file
写了测试代码,对源代码感兴趣的可以看看
bash
package org.wltea.analyzer.test;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.util.AttributeFactory;
import org.wltea.analyzer.lucene.IKTokenizerFactory;
import java.io.IOException;
import java.io.StringReader;
import java.util.HashMap;
import java.util.Map;
public class Test {
public static void main(String[] args) {
// 创建参数映射
Map<String, String> argsMap = new HashMap<>();
argsMap.put("useSmart", "false"); // 设置为细粒度分词模式
try {
// 创建 IKTokenizerFactory 实例
IKTokenizerFactory factory = new IKTokenizerFactory(argsMap);
// 创建 tokenizer
AttributeFactory attributeFactory = AttributeFactory.DEFAULT_ATTRIBUTE_FACTORY;
Tokenizer tokenizer = factory.create(attributeFactory);
// 测试文本
String text = "测试文本";
// 设置要分析的文本
tokenizer.setReader(new StringReader(text));
tokenizer.reset();
// 执行分词并输出结果
System.out.println("分词结果:");
while (tokenizer.incrementToken()) {
CharTermAttribute term = tokenizer.getAttribute(CharTermAttribute.class);
System.out.println(term.toString());
}
tokenizer.end();
tokenizer.close();
System.out.println("\n使用智能分词模式:");
// 测试智能分词模式
argsMap.put("useSmart", "true");
IKTokenizerFactory smartFactory = new IKTokenizerFactory(argsMap);
Tokenizer smartTokenizer = smartFactory.create(attributeFactory);
smartTokenizer.setReader(new StringReader(text));
smartTokenizer.reset();
// 执行分词并输出结果
while (smartTokenizer.incrementToken()) {
CharTermAttribute term = smartTokenizer.getAttribute(CharTermAttribute.class);
System.out.println(term.toString());
}
smartTokenizer.end();
smartTokenizer.close();
} catch (IOException e) {
System.err.println("测试过程中发生IO异常: " + e.getMessage());
e.printStackTrace();
}
}
}1.本地solr版本 solr-8.11.3 。准备工作:下载 ik-analyzer-8.5.0.jar ,lucene-core-8.5.0.jar ,lucene-analyzers-common-8.5.0.jar 。(我单独使用ik-analyzer-8.5.0.jar,会有包缺失问题,大家可以试试仅仅使用 ik-analyzer-8.5.0.jar可以不。)
将文件放入下面路径
bash
1. \solr-8.11.3\server\solr-webapp\webapp\WEB-INF\lib
2.solr-8.11.3\server\lib\ext2.配置Solr的(solr-8.11.3\server\solr\new_core\conf)managed-schema,添加ik分词器。相关字段加上相关类型分词属性,示例如下;
bash
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- 相关字段加上相关类型 -->
<field name="title" type="text_ik" indexed="true" stored="true"/>3.添加ik.conf到 (solr-8.11.3\server\solr\new_core\conf) ik.conf内容
bash
files=dynamicdic.txt
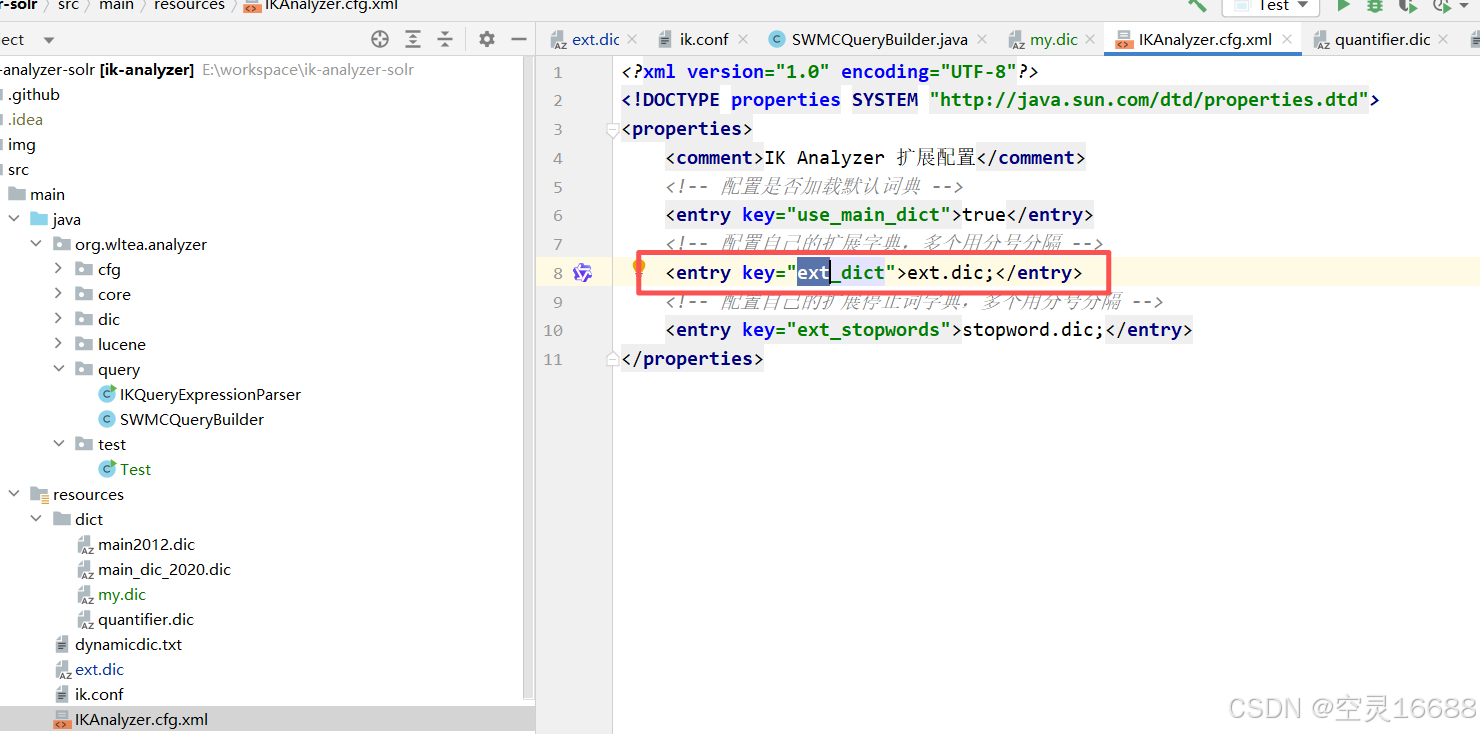
lastupdate=04.添加自己的扩展词汇词典,相关路径(solr-8.11.3\server\solr-webapp\webapp\WEB-INF)
新增classes文件,将ext.dic添加到该路径下。
根据源代码 提示添加自己想要的文件和提示词到文件中。
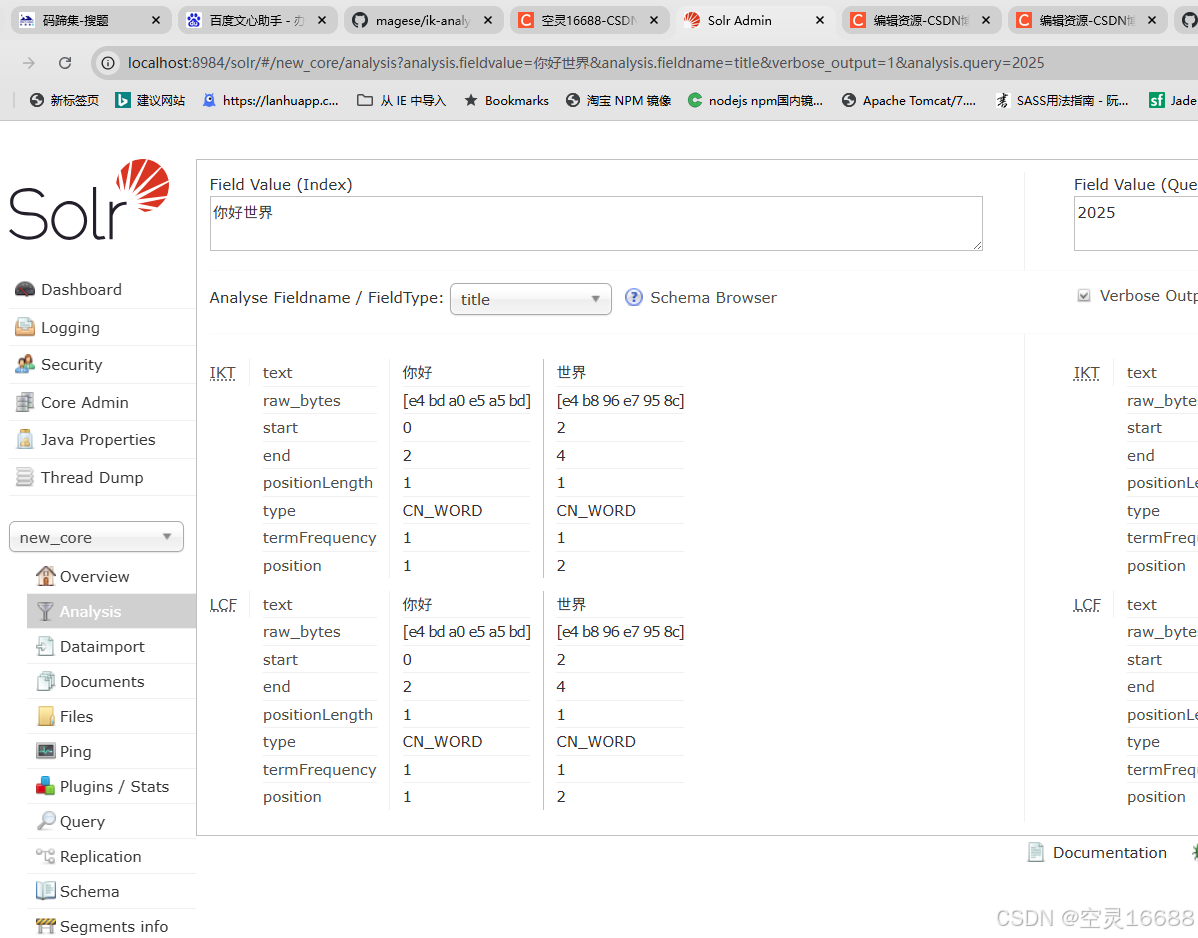
5.启动服务,测试自己家的分词
bash
./solr start -p 8984