解释典型的Transformer架构用于时序预测效果差的原因 ,它们的观点:
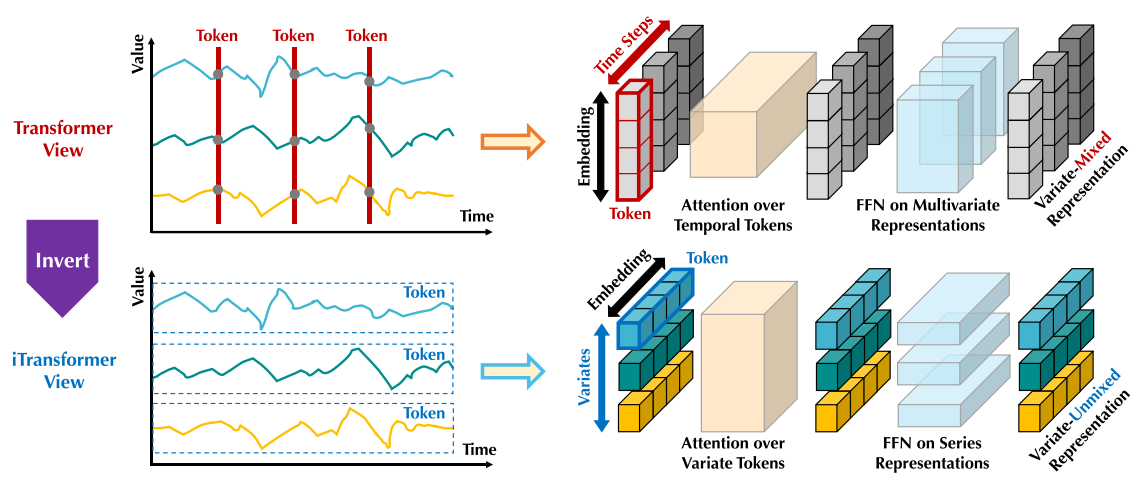
由单个时间步长形成的Token ,由于过于局部的感受野 和同时时间点表示的时间不对齐事件而难以显示有益信息。
时间序列预测模型的标准设定:
输入 (历史窗) XXX:包含TTT个时间步,NNN个变量。矩阵维度为RT∗NR^{T*N}RT∗N;
输出(预测窗)YYY: 预测未来SSS个时间步,同样包含NNN个变量, 矩阵维度为RS∗NR^{S*N}RS∗N
数据处理的两种视角:
(1)Xt,:X_{t,:}Xt,:: ttt 时刻所有变量的快照。表示的是Excel表格中的一行,代表"此时此刻所有传感器的读数"。大多数Transformer(如Informer)是将这个Xt:X_{t:}Xt:, 作为一个TokenTokenToken输入模型。
(2)X:,nX_{:,n}X:,n: 第nnn个变量的完整时间序列,Excel中的一列,代表 "某个传感器在过去一段时间内的所有读数"。
为什么否定Xt,:X_{t,:}Xt,:?
直接处理Xt,:X_{t,:}Xt,:(即把同一时刻的不同变量揉在一起)在物理意义上的两个缺点:
(1)系统性时滞(Systematical Time Lags):在现实世界中,因果关系往往不是瞬时的,如果强制模型只看Xt:X_{t:}Xt:(同时关注ttt时刻的A和B),可能变量在该时刻并不具备直接因果关系的数据点,真正的关联式错位的。
(2)物理量纲与分布的差异:同一时刻的Xt,:X_{t,:}Xt,:包含了性质完全不同的数据。这些数据的语义空间(Semantic Space)完全不同。虽然可以归一化,但是在深度学习,将这些物理意义极不相同的数值映射到同一个特征空间进行交互,难以学习到鲁棒的特征。
为什么拥抱X:nX_{:n}X:n?
单个变量的整条序列具有物理一致性,该变量在ttt时刻和t+1t+1t+1时刻的物理性质不变,它们的统计分布是平稳的。将X:nX_{:n}X:n视为一个Token进行Embedding,模型更容易学习到特征。
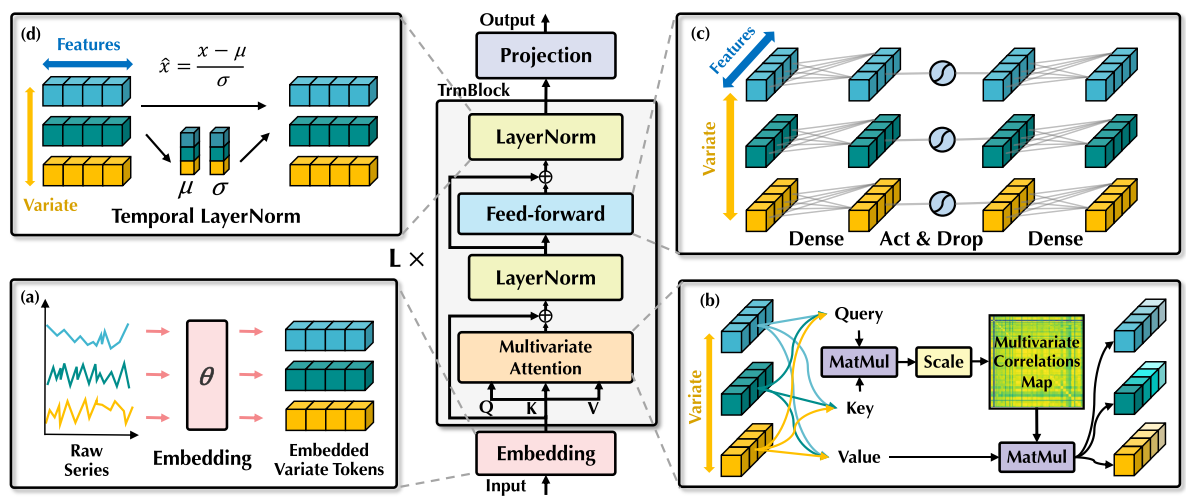
层归一化:
在此前Transformer中,层归一化将同一时刻的的多个变量进行归一化 ,使**每个变量杂糅无法区分**,提高了注意力建模词关联的难度。一旦收集到的数据没有按时间对齐,该操作还将引入延迟过程之间的噪声干扰。
在倒置版本中,层归一化作用于Variate Token内部 ,让所有变量的特征都**处于相对统一的分布下,减弱测量单位的差异**。这种方式还可以有效处理时间序列的非平稳问题问题。
前馈网络:
基于多层感知机的万能表示定理,前馈网络作用在整条序列上 ,能够提取序列的内在属性,例如幅值,周期性,频率谱(傅立叶变换可视作在序列上的全连接映射),从而提高在其他的序列上的泛化性。
在原始的Transformer中,模型的预测效果不一定随着输入的历史观测的变长而提升,在使用倒置框架之后,模型随着历史观测长度的增加,呈现明显的预测误差降低趋势。