文章目录
- [一、传统基于参考的推理评估(Reference-based CoT Evaluation)](#一、传统基于参考的推理评估(Reference-based CoT Evaluation))
-
- [1.1 基本评估范式](#1.1 基本评估范式)
- [1.2 基于 NLG 指标的推理评估](#1.2 基于 NLG 指标的推理评估)
- [1.3 基于语义与逻辑对齐的参考评估](#1.3 基于语义与逻辑对齐的参考评估)
- [1.4 基于参考评估的优势](#1.4 基于参考评估的优势)
- [二、无需参考的推理评估(Reference-free CoT Evaluation)](#二、无需参考的推理评估(Reference-free CoT Evaluation))
-
- [2.1 ROSCOE(2022)](#2.1 ROSCOE(2022))
-
- [(1) 语义对齐(ROSCOE-SA)](#(1) 语义对齐(ROSCOE-SA))
- [(2) 逻辑推理(ROSCOE-LI)](#(2) 逻辑推理(ROSCOE-LI))
- [(3) 语义相似性(ROSCOE-SS)](#(3) 语义相似性(ROSCOE-SS))
- [(4) 语言连贯性(ROSCOE-LC)](#(4) 语言连贯性(ROSCOE-LC))
- [(5) ROSCOE 的有效性](#(5) ROSCOE 的有效性)
- [2.2 ReCEval(2023)](#2.2 ReCEval(2023))
-
- [(1) 步骤内正确性(Intra-Step Correctness)](#(1) 步骤内正确性(Intra-Step Correctness))
- [(2) 步骤间正确性(Inter-Step Correctness)](#(2) 步骤间正确性(Inter-Step Correctness))
- [(3) 信息量(Informativeness)](#(3) 信息量(Informativeness))
- [(4) ReCEval 的有效性](#(4) ReCEval 的有效性)
- [2.3 SocREval(2023)](#2.3 SocREval(2023))
-
- [(1) 基于苏格拉底方法的三种Prompt优化策略](#(1) 基于苏格拉底方法的三种Prompt优化策略)
- [(2) SocREval 的有效性](#(2) SocREval 的有效性)
- [2.4 AutoRace(2024)](#2.4 AutoRace(2024))
-
- [(1) AutoRace 评估步骤](#(1) AutoRace 评估步骤)
- [(2) AutoRace 的有效性](#(2) AutoRace 的有效性)
- [2.5 MiCEval(2024)](#2.5 MiCEval(2024))
-
- [(1) 步骤正确性评估](#(1) 步骤正确性评估)
- [(2) MCoT 正确性的评估](#(2) MCoT 正确性的评估)
- [(3) MiCEval 的有效性](#(3) MiCEval 的有效性)
- [2.6 MME-CoT(2025)](#2.6 MME-CoT(2025))
-
- [(1) CoT 正确性评估](#(1) CoT 正确性评估)
- [(2) CoT 鲁棒性评估](#(2) CoT 鲁棒性评估)
- [(3) CoT 效率评估](#(3) CoT 效率评估)
- [(4) 评估结果及发现](#(4) 评估结果及发现)
- [2.7 THINK-Bench(2025)](#2.7 THINK-Bench(2025))
-
- [(1) 推理效率评估](#(1) 推理效率评估)
- [(2) CoT 质量评估](#(2) CoT 质量评估)
- [(3) 评估结果与分析](#(3) 评估结果与分析)
- [2.8 无参考评估方法的对比与趋势分析*](#2.8 无参考评估方法的对比与趋势分析*)
- 三、元评估框架介绍
-
- [3.1 Somers' D 的原理](#3.1 Somers’ D 的原理)
- [3.2 元评估的应用](#3.2 元评估的应用)
- [3.3 元评估的局限性与展望](#3.3 元评估的局限性与展望)
- 四、小结
随着大语言模型在多步推理任务中的能力不断提升,Chain-of-Thought(CoT)推理 已成为分析与改进模型行为的重要工具。然而,相比推理方法本身,如何可靠地评估模型生成的推理过程这一问题长期缺乏统一答案。
早期工作多依赖人工参考推理链进行对齐评估,但在推理路径高度多样、任务日益开放的场景下,这类方法在可扩展性与一致性方面逐渐显现局限。近年来,研究社区围绕这一问题提出了大量 reference-free 的推理评估方法,从逻辑一致性、信息贡献到推理效率等多个维度重新刻画推理质量。
本文系统梳理了 CoT 推理评估方法的发展脉络,重点总结近年来代表性的无参考评估指标与基准,并进一步讨论不同自动评估方法与人类判断之间的一致性问题。
一、传统基于参考的推理评估(Reference-based CoT Evaluation)
基于参考的推理评估(reference-based reasoning evaluation)是指:将模型生成的推理链(Chain-of-Thought, CoT)与人工构建的标准参考推理链进行对比,通过计算两者在语义、结构或逻辑层面上的一致性来评估模型推理质量。
在该范式中,参考 CoT 被视为"正确推理路径"的近似表达 ,通常由领域专家人工标注,或从高质量数据集中提取。评估的核心假设是:高质量的模型推理应当在形式或语义上接近人类给出的参考推理链。
1.1 基本评估范式
给定一个推理任务输入 X \mathcal{X} X,人工构建的参考推理链 R ∗ \mathcal{R}^{*} R∗,以及模型生成的推理链 R ^ \hat{\mathcal{R}} R^,基于参考的评估方法通常通过以下方式之一进行:
- 逐句 / 逐步对齐 :比较 R ^ \hat{\mathcal{R}} R^ 与 R ∗ \mathcal{R}^{*} R∗ 中对应推理步骤的相似性;
- 整体相似性评估:将整条推理链视为一个文本序列,计算整体语义或表面相似度;
- 结构或顺序一致性评估:评估推理步骤的顺序、依赖关系是否与参考一致。
这种范式在早期推理评估研究中占据主导地位,并被广泛应用于数学推理、自然语言推理(NLI)和问答等任务。
1.2 基于 NLG 指标的推理评估
最早的一类方法直接借鉴自然语言生成(NLG)评估指标,将推理链视为一种特殊的生成文本,并计算其与参考推理链之间的文本相似性。
常用指标包括:
- BLEU / ROUGE:衡量 n-gram 层面的重叠程度;
- METEOR:引入词形变化和同义词匹配;
- BERTScore:基于上下文语义表示计算 token 级相似性;
- BLEURT / COMET:利用监督学习模型预测文本质量得分。
这些指标在早期 CoT 评估中被广泛采用,因其实现简单、计算高效,且可以直接复用成熟的评估工具。
然而,这类方法存在明显局限:
- 推理链往往具有高度的表达多样性,不同但同样正确的推理路径在表面形式上可能差异巨大;
- n-gram 或语义相似性并不能准确反映逻辑正确性或因果依赖关系;
- 模型可能通过"文本模仿"获得较高分数,但实际推理并不严谨。
1.3 基于语义与逻辑对齐的参考评估
为克服纯文本相似性指标的不足,后续研究开始引入语义推理与逻辑一致性建模,将评估重点从"文本像不像"转向"推理是否成立"。
这类方法通常采用:
- 自然语言推理(NLI)模型:判断模型推理步骤是否被参考步骤所蕴含,或是否与之矛盾;
- 步骤级别对齐(step-level alignment):对生成步骤与参考步骤进行匹配,并评估每一步的正确性;
- 错误定位(error localization):不仅给出整体评分,还尝试指出推理链中具体出错的位置。
在一些工作中,推理链被表示为一系列中间结论或命题,评估模型则被用于判断这些命题是否可以从参考推理中推出。这种方法在一定程度上提高了评估的可解释性和逻辑敏感度,但仍高度依赖人工构建的参考推理链。
1.4 基于参考评估的优势
尽管存在局限,基于参考的推理评估在特定场景下仍然具有不可替代的优势:
- 评估标准明确:参考推理链提供了清晰的"正确性锚点";
- 适合封闭任务:在数学、定理证明等推理路径相对固定的任务中效果较好;
- 有利于细粒度误差分析:可直接对比参考步骤,定位模型的具体推理错误;
- 便于模型训练与调优:参考 CoT 可作为监督信号用于微调或奖励建模。
因此,在小规模、高价值、专家可控的任务设置中,基于参考的评估仍然是主流选择。
二、无需参考的推理评估(Reference-free CoT Evaluation)
随着模型生成能力的不断提升,对于一些复杂任务或新领域任务,获取高质量的参考 CoT 变得越来越困难和昂贵。传统的基于参考的评估方法在面对大量无参考 CoT 数据时无法有效应用,因此发展出无需参考的 CoT 质量评估方法。
2.1 ROSCOE(2022)
ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning
本文提出ROSCOE,一套可解释的、无监督的自动评分,改进并扩展了之前的文本生成评价指标。与现有的指标相比,ROSCOE可以通过利用分步推理的特性来衡量语义一致性、逻辑性、信息量、流畅性和事实性。
ROSCOE 包含四个细粒度指标:
(1)语义对齐(semantic alignment)定义了生成推理在多大程度上是连贯的,并与源上下文相关;
(2)逻辑推理(logical inference)评估生成的推理步骤是否在内部一致,并检查逻辑谬误;
(3)语义相似性(semantic similarity)量化生成推理与上下文或中间步骤之间的相似度,以捕捉幻觉或重复;
(4)语言连贯性(language coherence)评估整个链是否自然流畅。
每个指标的取值范围都在 0,1 之间,其中 1 表示完美得分,0 表示失败。
(1) 语义对齐(ROSCOE-SA)
核心概念:通过计算推理步骤与源上下文的对齐分数(alignment score)来衡量推理的语义一致性。
关键指标:
- Faithfulness-Step:衡量每个推理步骤与上下文的对齐程度。
- Faithfulness-Token:在Token级别上衡量对齐程度。
- Info-Step:衡量上下文信息在推理步骤中的使用情况。
- Repetition-Token:检测重复或相似的步骤。
- Hallucination:识别与上下文无关的推理步骤。
- Redundancy:检测推理中不必要的信息。
- Semantic Coverage-Step:衡量推理步骤对上下文的覆盖程度。
- Reasoning Alignment:衡量推理链与参考推理的对齐程度。
- Commonsense:检测推理中是否缺少常识性知识。
- Missing Step:识别推理中缺失的步骤。
(2) 逻辑推理(ROSCOE-LI)
核心概念:使用自然语言推理(NLI)模型来评估推理步骤之间的逻辑一致性。
关键指标:
- Self-Consistency:检测推理步骤之间的逻辑矛盾。
- Source-Consistency:检测推理步骤与源上下文之间的逻辑矛盾。
(3) 语义相似性(ROSCOE-SS)
核心概念:通过比较推理链的整体语义相似性来评估重复、幻觉等问题。
关键指标:
- Info-Chain:衡量推理链与上下文的整体语义一致性。
- Repetition-Step:检测推理步骤之间的重复。
- Semantic Coverage-Chain:衡量推理链与参考推理的整体语义相似性。
(4) 语言连贯性(ROSCOE-LC)
核心概念:使用语言模型(如GPT-2)的困惑度(Perplexity)和语法接受度(Grammar)来评估推理链的语言连贯性。
关键指标:
- Perplexity-Chain:衡量整个推理链的语言连贯性。
- Perplexity-Step:衡量每个推理步骤的语言连贯性。
- Grammar:评估推理步骤的语法正确性。
(5) ROSCOE 的有效性
ROSCOE 各指标与人类判断之间的 Somers' D 相关性得分:
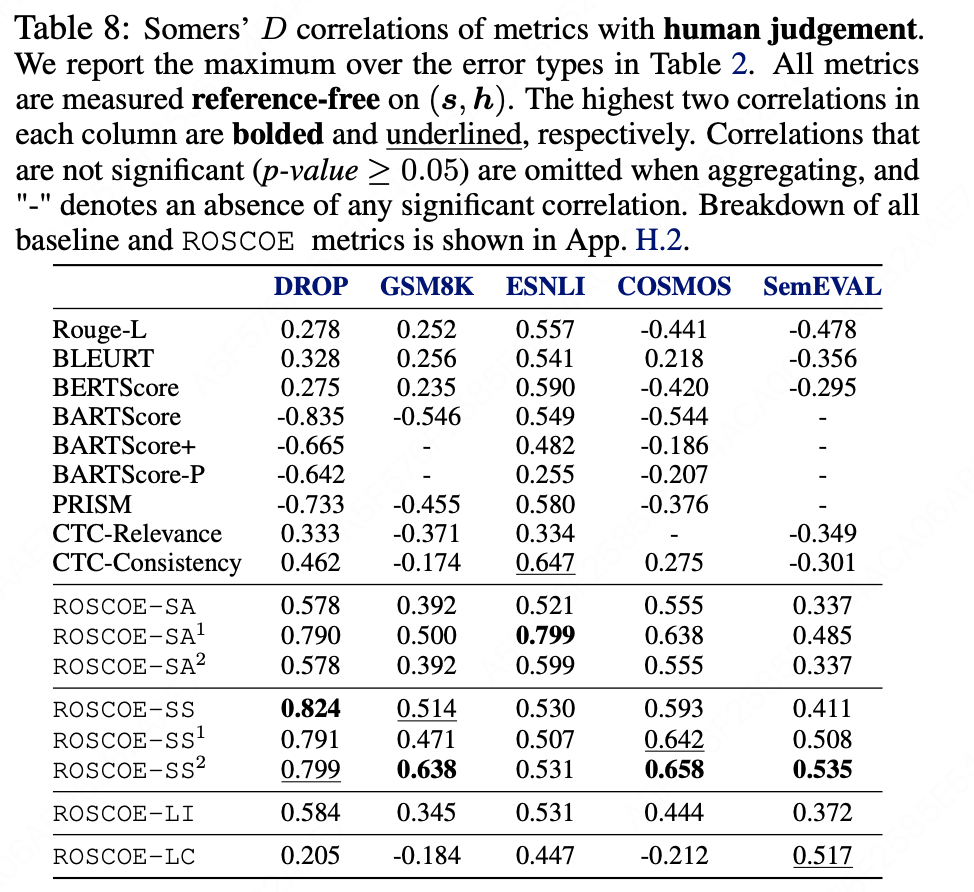
- 在所有任务中,ROSCOE 指标在无参考评估时表现优于所有其他基线;
- 总体而言,ROSCOE 产生了显著更好的相关性,这表明逐步推理生成可以更有效地通过 ROSCOE 进行评估。
2.2 ReCEval(2023)
ReCEval: Evaluating Reasoning Chains via Correctness and Informativeness
【定义】
- 推理链 :给定一个自然语言推理任务,令 X \mathcal{X} X 表示描述问题的输入上下文。我们定义一个推理链 R = { s ( 1 ) , ⋯ , s ( n ) } \mathcal{R} = \{s^{(1)}, \cdots, s^{(n)}\} R={s(1),⋯,s(n)} 为一个多步骤的推理过程,由 n n n 步组成,用于得出预测答案 a ^ \hat{a} a^。
- 推理内容单元(RCU) :我们假设每一步 s ( i ) s^{(i)} s(i) 包含一个或多个声明,我们称之为推理内容单元(RCUs)。
本文提出了RECEVAL,一个通过两个关键属性评估推理链的框架。
1. 正确性,即每一步基于步骤内、前一步和输入上下文中的信息进行有效推理;
- 步骤内正确性,它评估基于步骤内前提单元 R C U ( i ) p RCU(i)_p RCU(i)p 的信息。
- 步骤间正确性,它评估给定先前文(输入 X X X 和先前步骤 s ( < i ) s^{(<i)} s(<i) ) 的情况下, R C U ( i ) c RCU(i)_c RCU(i)c 是否正确。
- 直观上,步骤内正确性评估步骤内声明的一致性,而步骤间正确性衡量全局一致性。
2. 信息量,即每一步提供有助于推导出生成答案的新信息。
- 衡量每一步在产生最终答案过程中的有用性和重要性。并非所有(合理的)步骤中的推断对当前问题同样相关,因此信息量捕捉特定步骤对接近答案的贡献程度。
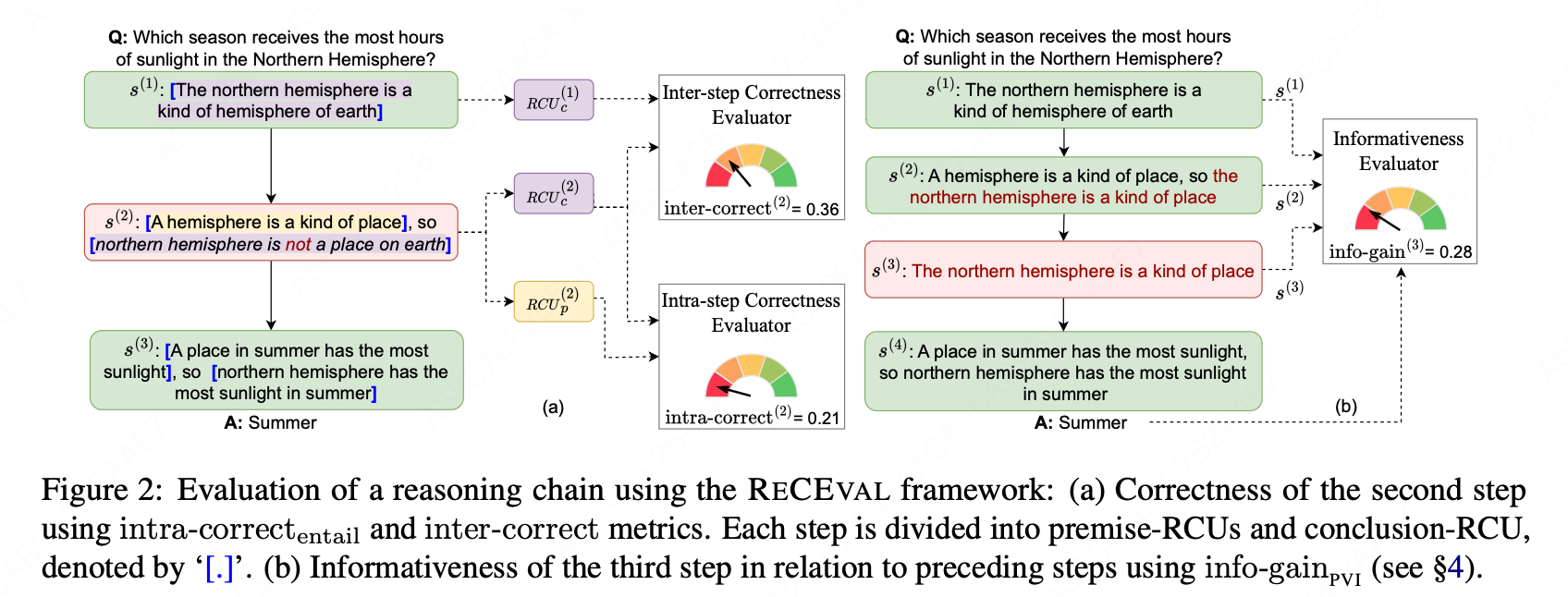
(1) 步骤内正确性(Intra-Step Correctness)
我们提出两种方法来衡量推理步骤的步骤内正确性,基于两种互补的正确性视角。
-
基于蕴含的步骤内正确性
我们的第一种方法旨在通过计算结论-RCU( R C U c ( i ) RCU_c^{(i)} RCUc(i))给定前提-RCUs( R C U p ( i ) RCU_p^{(i)} RCUp(i))在步骤 s ( i ) s^{(i)} s(i) 内的蕴含概率来捕捉正确性,如下所示:
intra-correct ( i ) entail = P entail ( R C U ( i ) p ; R C U ( i ) c ) \text{intra-correct}(i){\text{entail}} = P{\text{entail}}(RCU(i)_p; RCU(i)_c) intra-correct(i)entail=Pentail(RCU(i)p;RCU(i)c)我们严格定义蕴含,其中结论-RCU 对前提-RCUs 中立则获得低概率。这种设计选择考虑了可能包含幻觉或不支持的非事实声明的错误推理步骤。
-
基于PVI的步骤内正确性
之前的方法要求前提-RCUs 和结论-RCU 之间严格蕴含。然而,在自然语言中,推理步骤可以是非正式的,并且在省略一些前提-RCUs 的情况下仍然被认为是正确的。为了允许这种灵活性,我们引入了一个放松的标准,评估从前提中得出结论的容易程度。使用 pvi,我们评估基于前提-RCUs 中已经存在的有用信息生成结论-RCU 的容易程度。形式上:
intra-correct ( i ) PVI = P V I ( R C U ( i ) p → R C U ( i ) c ) \text{intra-correct}(i)_{\text{PVI}} = PVI(RCU(i)_p \to RCU(i)_c) intra-correct(i)PVI=PVI(RCU(i)p→RCU(i)c)
(2) 步骤间正确性(Inter-Step Correctness)
- 在具有多个步骤的推理链中,确保任何新的结论-RCU 与所有已知信息保持一致,无论是在输入 X \mathcal{X} X 中还是在所有先前结论-RCUs ( R C U c ( < i ) ) (RCU_c^{(<i)}) (RCUc(<i)) 中,都是至关重要的。为了衡量这种"全局"步骤间正确性,我们验证当前 RCU c ( i ) c^{(i)} c(i) 与先前信息之间没有矛盾,包括 X \mathcal{X} X 和 RCU c ( < i ) c^{(<i)} c(<i)。我们利用 NLI 模型获得矛盾概率( P c o n t r . P{contr.} Pcontr.),计算:
inter-correct ( i ) = 1 − max r ( P contr ( r ; R C U ( i ) c ) ) \text{inter-correct}(i) = 1 - \max_r(P{\text{contr}}(r; RCU(i)c)) inter-correct(i)=1−rmax(Pcontr(r;RCU(i)c))
其中, r ∈ X ∪ { R C U c ( j ) } j = 1 i − 1 r \in \mathcal{X} \cup \{RCU_c^{(j)}\}{j=1}^{i-1} r∈X∪{RCUc(j)}j=1i−1。我们仅评估结论-RCUs,排除由于与输入上下文 X \mathcal{X} X 重叠而来自先前步骤的前提-RCUs。
(3) 信息量(Informativeness)
基于PVI的信息增益。为了捕捉推理步骤的贡献,我们测量在推理链中添加它后的信息增益。一个大的正增益表明该步骤使预测答案变得更容易。因此,评估基于信息量的推理有助于识别诸如重复或冗余等问题。计算步骤 s ( i ) s(i) s(i) 向预测答案 a ^ \hat{a} a^ 提供的信息,条件是先前的步骤 s ( < i ) s^{(<i)} s(<i) ),表示为:
- 基于PVI的信息增益
为了捕捉推理步骤的贡献,我们测量在推理链中添加它后的信息增益。一个大的正增益表明该步骤使预测答案变得更容易。因此,评估基于信息量的推理有助于识别诸如重复或冗余等问题。计算步骤 s ( i ) s^{(i)} s(i) 向预测答案 a ^ \hat{a} a^ 提供的信息,条件是之前的步骤 s ( < i ) s^{(<i)} s(<i),表示为:
i n f o - g a i n P V I ( i ) = P V I ( s ( i ) → a ^ ∣ s ( < i ) ) info\text{-}gain_{PVI}^{(i)} = PVI(s^{(i)} \rightarrow \hat{a}|s^{(<i)}) info-gainPVI(i)=PVI(s(i)→a^∣s(<i))
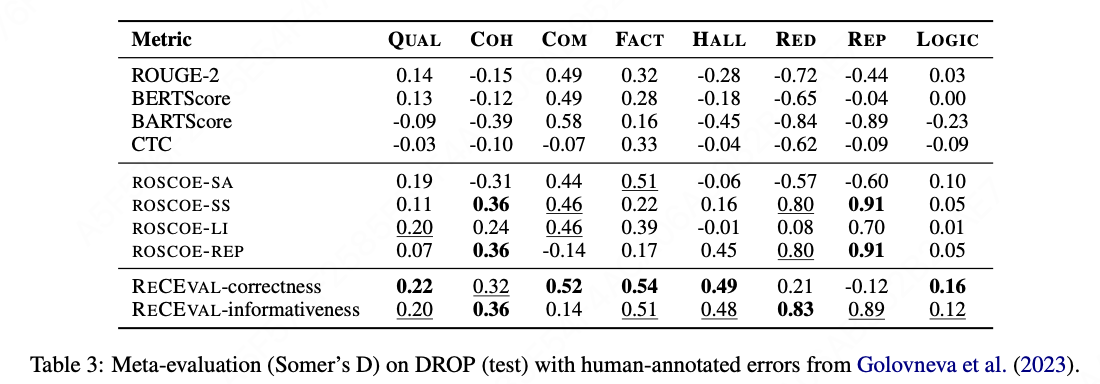
(4) ReCEval 的有效性
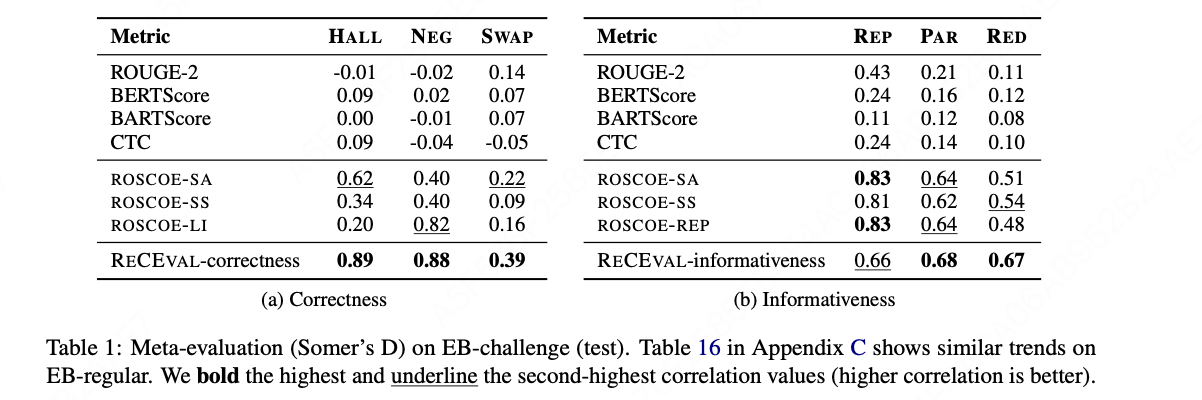
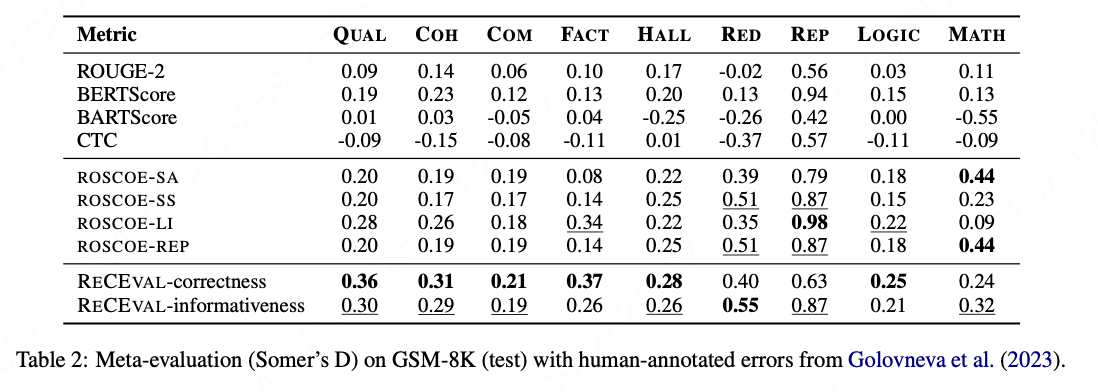
在EB-challenge、GSM-8K和DROP数据集上的元评估(Somers' D)结果:
2.3 SocREval(2023)
SocREval: Large Language Models with the Socratic Method for Reference-Free Reasoning Evaluation
在本工作中,我们提出利用 LLMs 的能力来评估模型生成的推理链,显著消除了对模型微调和依赖人类编写的推理链的需求。借鉴苏格拉底方法的应用,我们进一步利用苏格拉底方法来设计优化的提示,以便更好地利用 LLMs 进行无参考推理评估,具体而言,我们采用苏格拉底方法中的三种基本策略------定义、助产术和辩证法及其组合,旨在优化 LLMs 在无参考推理评估中的提示机制。
在无参考推理评估中,有两种主要的解释范式,为此设计不同的提示模板以评估这些范式中的推理链:
- Explain-then-Predict (E-P):Instruction + Example question + Example generated response + Example representation + Question + Generated response + Evaluation prompt.
- Predict-then-Explain (P-E):Instruction + Example Situation (Premise) + Example Claim (Hypothesis) + Example question + Example generated response + Example representation + Situation (Premise) + Claim (Hypothesis) + Question + Generated response + Evaluation prompt.
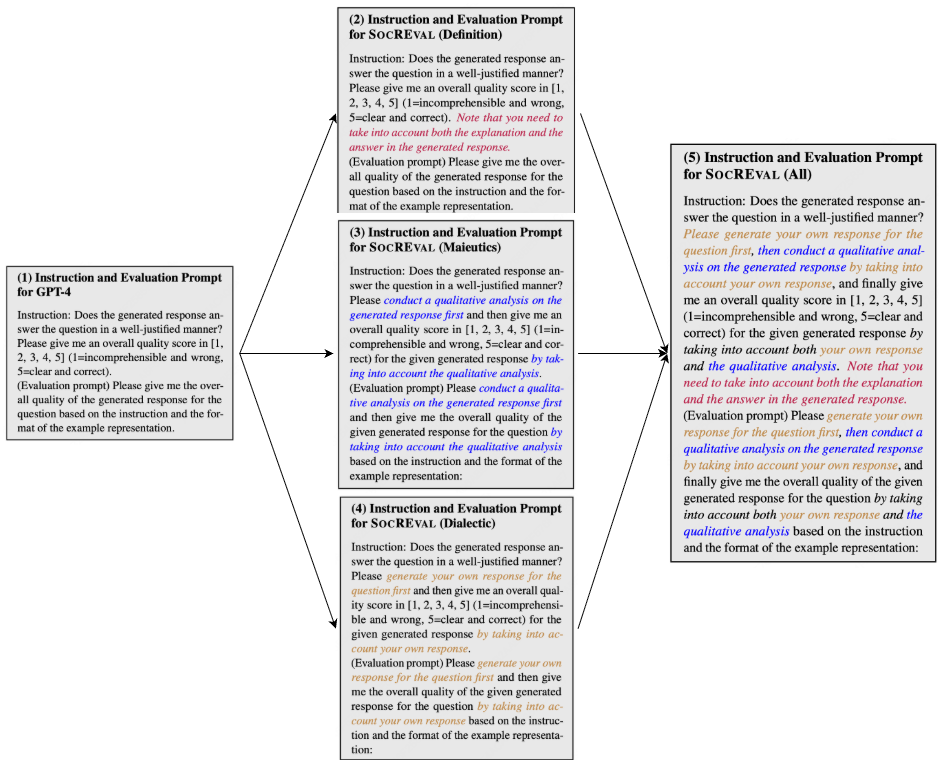
(1) 基于苏格拉底方法的三种Prompt优化策略
- 定义法(Definition)
- 核心思想:通过明确关键术语和概念的定义,帮助模型更好地理解评估标准。
- 应用方式:在提示中加入对关键术语的定义,确保模型在评估推理链时能够准确理解每个步骤的含义。
- 助产术(Maieutics)
- 核心思想:通过逐步引导模型进行自我分析,帮助其揭示内在的知识和逻辑错误。
- 应用方式:在提示中加入对生成推理链的定性分析步骤,要求模型在给出最终评分之前先进行自我反思。
- 辩证法(Dialectic)
- 核心思想:通过引入不同的观点和对话,帮助模型从多个角度审视推理链,促进更全面的理解。
- 应用方式:在提示中加入模型自身生成的回答,要求模型在评估时同时考虑自己的回答和生成的推理链。
最后,将上述三种策略结合起来,为无参考推理评估设计优化的提示,得到最终的SOCREVAL评估指标。
(2) SocREval 的有效性
推理评估指标与人类判断之间的 Somers' D 相关性对比(vs ROSCOE、ReCEval)
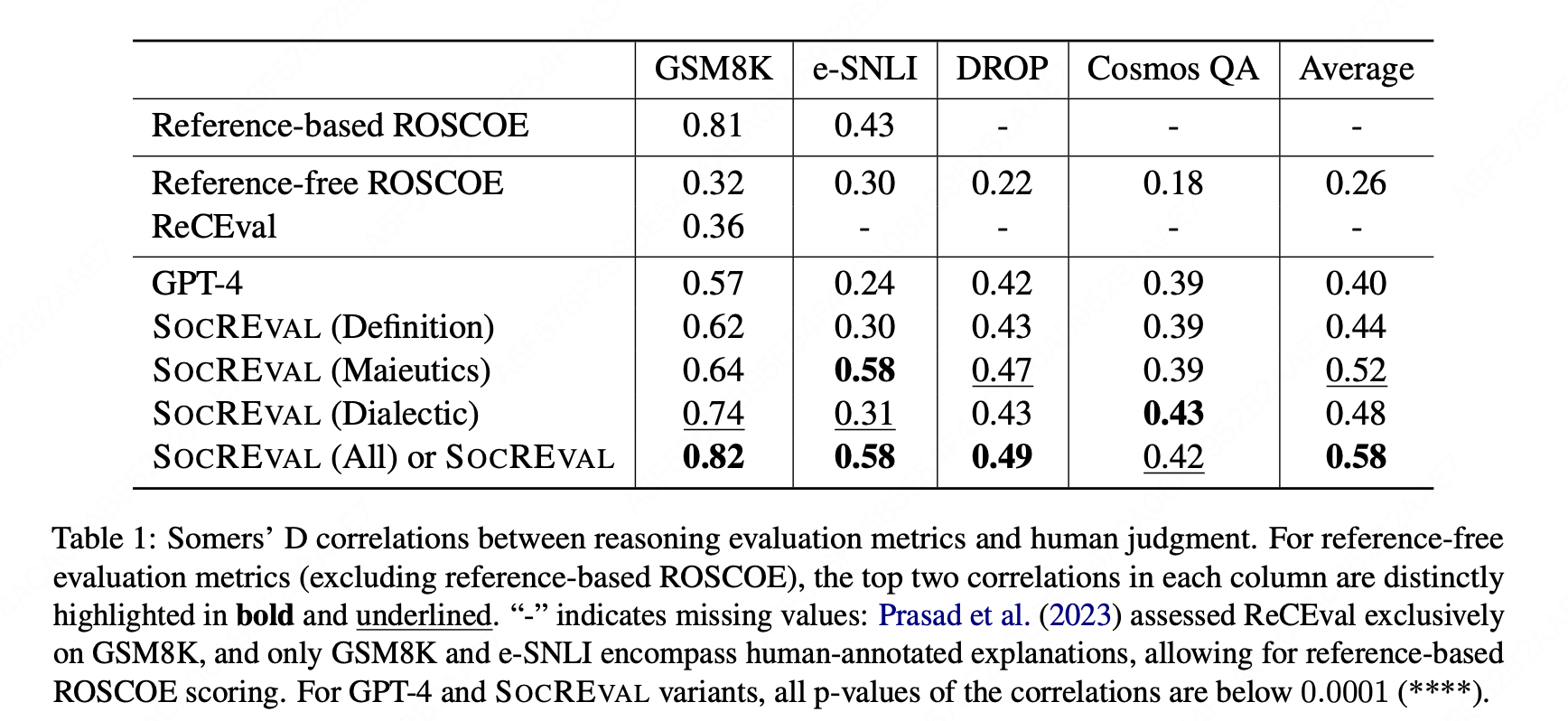
结论:
- GPT-4 在现有的无参考推理评估指标中表现优于其他指标,即无参考的 ROSCOE 和 ReCEval。
- ROSCOE 和 ReCEval 都需要在具有人工标注推理链的数据集上进行模型微调,但 GPT-4 在没有这种微调的情况下也能有效地运行,这突显了其在无参考推理评估中的有效性。
- 通过整合来自苏格拉底方法的三种策略提出的评估指标 SoCREVAL 进一步超越了 GPT-4。在这些策略中,辩证法平均上最有效。
局限 :需要GPT-4首先生成一个参考推理链,这限制了其在GPT-4无法解决的复杂推理任务中的表现。此外,固定的提示模板无法根据不同的任务进行调整,这也限制了评估准确性。
2.4 AutoRace(2024)
本文引入AutoRace,用于全自动推理链评估。现有的评估指标依赖于昂贵的人类标注或不适应不同任务的预定义LLM提示。相比之下,AutoRace自动为每个任务创建详细的评估标准,并使用GPT-4根据标准进行准确评估。
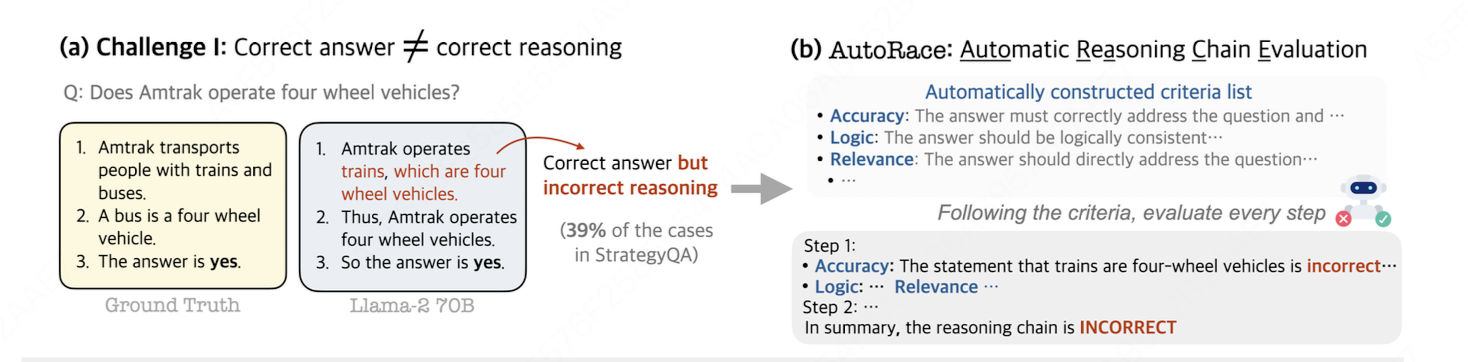
(1) AutoRace 评估步骤
考虑推理问题 x x x 、LLM 生成的推理链 z z z 和预测答案 y y y,同时有参考答案 y r y_r yr 和参考推理链 z r z_r zr。目标是构建一个自动评估指标 s ( z ) s(z) s(z),使其更接近人类对推理链的评估。
主要步骤:
- 收集错误推理链
- 给定训练集 D t r a i n D_{train} Dtrain,使用学生 LLM 生成推理链 z z z 和答案 y y y。
- 筛选出生成答案与参考答案不一致的样本,形成错误推理链集合 D e r r o r D_{error} Derror。
- 检测错误
- 将问题、参考推理链和学生推理链提供给 GPT-4,指示其指出学生推理链中的错误。
- 总结评估标准
- GPT-4 根据检测到的错误,总结出适用于该任务的评估标准列表。
- 应用标准评估新推理链
- 使用总结出的标准,GPT-4 评估任何新的推理链 z z z,确保每个步骤都符合标准。
(2) AutoRace 的有效性
AutoRace 与其他基于 LLM 的推理链评估指标 进行比较:
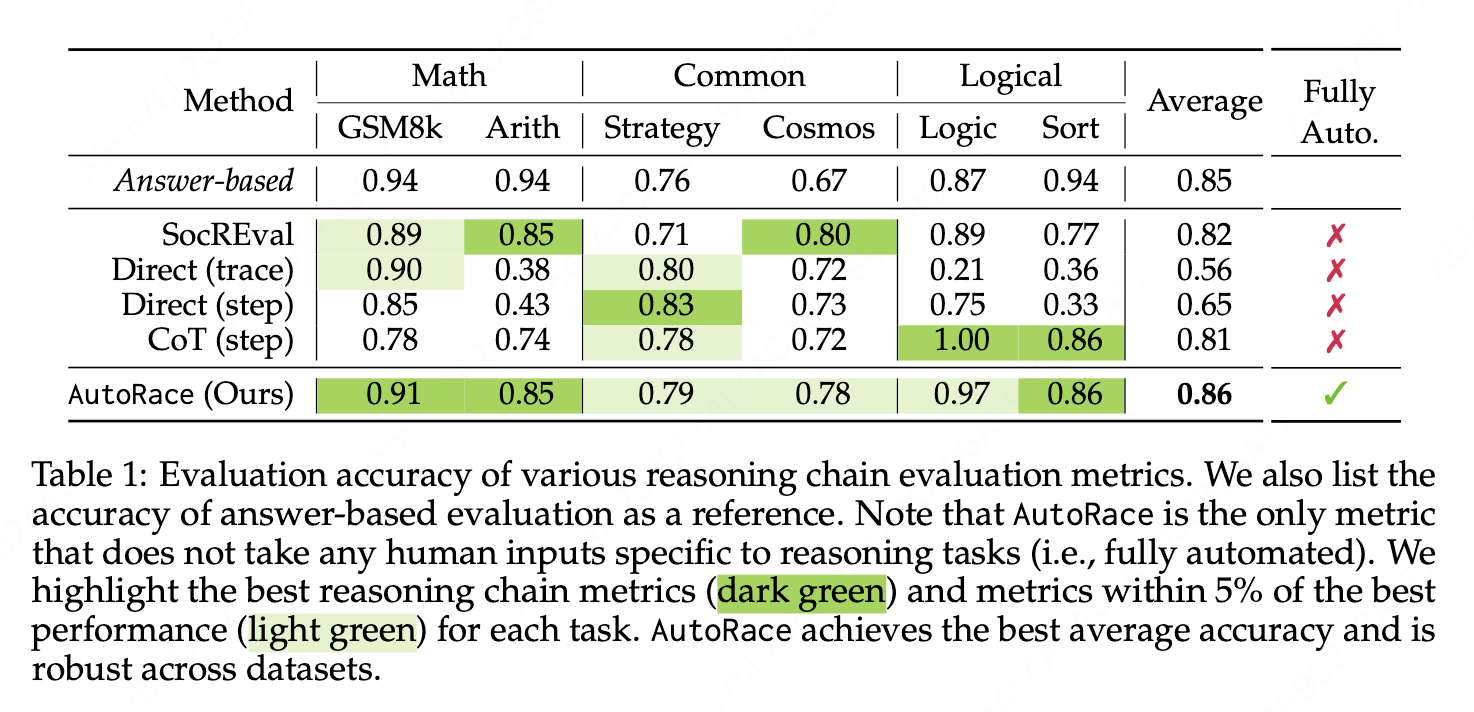
(a)SocREval 通过苏格拉底方法为 GPT-4 设计了一个详细的指令提示,包括要求它在评估之前生成一个参考推理链。这种方法需要人类为每个任务编写一个one-shot。
Tyen 等人(2023)提出了三种方法(所有这些方法都需要人类编写的 3-shot):
(b)直接(trace)要求 GPT-4 直接评估推理链;
(c)直接(step)要求 GPT-4 逐步检查推理链;
(d)CoT(step)要求 GPT-4 在评估每个推理步骤之前生成一个推理过程。
AutoRace优势:
- 自动化:无需人工标注,自动适应不同任务。
- 准确性:通过 GPT-4 的强大先验知识,确保评估的准确性。
- 鲁棒性:在多个任务上表现出色,能够检测到常规方法无法发现的错误推理链。
2.5 MiCEval(2024)
MiCEval: Unveiling Multimodal Chain of Thought's Quality via Image Description and Reasoning Steps
本文提出了MiCEval框架,用于通过将MCoT链分解为描述和推理步骤,并评估每一步的质量来评估MCoT。MiCEval将MCoT验证分解为五个核心任务,涵盖视觉和文本模态:描述正确性、图像相关性、逻辑正确性、逻辑相关性和信息量。此外,MiCEval引入了一个包含903个MLLM生成的MCoT答案和2,889个人类注释的MCoT步骤的数据集,作为我们对MCoT及其验证器进行综合逐步评估的基础。
【定义】
MCoT :一个 MCoT 由一张图像 I \mathcal{I} I、一个问题 Q \mathcal{Q} Q 和一个推理链 R C = r 1 , . . . , r n \mathcal{RC} = r_1, ..., r_n RC=r1,...,rn 组成:
M C o T = P r o m p t ( I , Q , R C ) MCoT = Prompt(\mathcal{I}, \mathcal{Q}, \mathcal{RC}) MCoT=Prompt(I,Q,RC) P r o m p t ( ) Prompt() Prompt() 表示将多模态输入转换为特定任务指令格式的过程。CoT 和 MCoT 之间的主要区别在于后者包含了视觉输入。
两种评估级别设定:
- MCoT级别 。给定输入 I , Q , R C \mathcal{I}, \mathcal{Q}, \mathcal{RC} I,Q,RC,其中 R C \mathcal{RC} RC 包含 { r 1 , r 2 , . . . , r n } \{r_1, r_2, ..., r_n\} {r1,r2,...,rn} 被整体评估。MLLM 生成一个介于 0, 1 之间的分数,反映整个序列 R C \mathcal{RC} RC 的正确性。
- 步骤级别 。对于给定的输入 I , Q \mathcal{I}, \mathcal{Q} I,Q,当前步骤 r i r_i ri,以及先前步骤 R C i − 1 = { r 1 , r 2 , . . . , r i − 1 } \mathcal{RC}{i-1} = \{r_1, r_2, ..., r{i-1}\} RCi−1={r1,r2,...,ri−1},仅评估当前步骤 r i r_i ri,MLLM 输出一个介于 0, 1 之间的分数,反映 r i r_i ri 的正确性。
描述步骤:仅从视觉信息中派生的步骤(即描述视觉内容)。
推理步骤:涉及超出视觉内容推断的信息,结合问题和先前步骤的步骤。
(1) 步骤正确性评估
- 对于描述步骤,重点是描述的正确性和相关性。
- 对于推理步骤,重点是逻辑正确性、相关性和信息量。
描述步骤正确性
我们的目标是指导 MLLM 生成一个描述步骤 r i r_i ri 的正确性分数,使用基于提示的输入 ( I , Q , R C i ) (\mathcal{I}, \mathcal{Q}, \mathcal{RC}_i) (I,Q,RCi),得出以下指标:
S d _ c o r r e c t , S d _ r e l e v a n t = M p r o m p t ( I , Q , R C i ) S_{d\correct}, S{d\relevant} = M{prompt}(\mathcal{I}, \mathcal{Q}, \mathcal{RC}_i) Sd_correct,Sd_relevant=Mprompt(I,Q,RCi)
C o r r e c t n e s s D ( i ) = S d _ c o r r e c t ⊙ S d _ r e l e v a n t Correctness_D^{(i)} = S_{d\correct} \odot S{d\_relevant} CorrectnessD(i)=Sd_correct⊙Sd_relevant
其中 M p r o m p t M_{prompt} Mprompt 表示基于提示的 MLLM, S d _ c o r r e c t S_{d\correct} Sd_correct 指的是描述正确性分数, S d _ r e l e v a n t S{d\_relevant} Sd_relevant 表示描述相关性分数。 ⊙ \odot ⊙ 表示几何平均运算。
推理步骤正确性
类似地,使用基于提示的输入 ( I , Q , R C i ) (\mathcal{I}, \mathcal{Q}, \mathcal{RC}_i) (I,Q,RCi),我们指导 MLLM 生成推理步骤 r i r_i ri 的正确性分数。相应的指标定义为:
S l _ c o r r e c t , S l _ r e l e v a n t , S i n f o = M p r o m p t ( I , Q , R C i ) S_{l\correct}, S{l\relevant}, S{info} = M_{prompt}(\mathcal{I}, \mathcal{Q}, \mathcal{RC}i) Sl_correct,Sl_relevant,Sinfo=Mprompt(I,Q,RCi) C o r r e c t n e s s R ( i ) = S l _ c o r r e c t ⊙ S l _ r e l e v a n t ⊙ S i n f o Correctness_R^{(i)} = S{l\correct} \odot S{l\relevant} \odot S{info} CorrectnessR(i)=Sl_correct⊙Sl_relevant⊙Sinfo
其中 M p r o m p t M_{prompt} Mprompt 表示基于提示的 MLLM, S l _ c o r r e c t S_{l\correct} Sl_correct 表示逻辑正确性分数, S l _ r e l e v a n t S{l\relevant} Sl_relevant 指的是逻辑相关性分数, S i n f o S{info} Sinfo 信息量分数。
(2) MCoT 正确性的评估
通过基于提示的 MLLM 为每个步骤生成分数来计算 MCoT 答案的总体分数。
首先,我们需要根据 MLLM 获取每种步骤的类型: T y p e ( i ) = M p r o m p t ( I , Q , R C i ) Type^{(i)} = M_{prompt}(\mathcal{I}, \mathcal{Q}, \mathcal{RC}_i) Type(i)=Mprompt(I,Q,RCi)
然后,根据每个步骤的类型,来计算整个 MCoT 答案的总分。
C o r r e c t n e s s ( i ) = { C o r r e c t n e s s D ( i ) , 描述步骤 C o r r e c t n e s s R ( i ) , 推理步骤 Correctness^{(i)} = \begin{cases} Correctness_D^{(i)},& \text{描述步骤} \\ Correctness_R^{(i)},& \text{推理步骤} \end{cases} Correctness(i)={CorrectnessD(i),CorrectnessR(i),描述步骤推理步骤 C o r r e c t n e s s t y p e = ∏ i = 1 n C o r r e c t n e s s ( i ) n Correctness_{type} = \sqrtn{\prod_{i=1}^{n} Correctness^{(i)}} Correctnesstype=ni=1∏nCorrectness(i)
其中 C o r r e c t n e s s D ( i ) Correctness_D^{(i)} CorrectnessD(i) 表示描述步骤 r i r_i ri 的正确性分数, C o r r e c t n e s s R ( i ) Correctness_R^{(i)} CorrectnessR(i) 表示推理步骤 r i r_i ri 的正确性分数。总体 MCoT 分数计算为所有步骤正确性分数的几何平均值。
另一种不基于步骤类型的正确性计算方法,为每个步骤计算描述步骤正确性和推理步骤正确性,然后得出整个 MCoT 的总分:
C o r r e c t n e s s ( i ) = C o r r e c t n e s s D ( i ) ⊙ C o r r e c t n e s s R ( i ) Correctness^{(i)} = Correctness_D^{(i)} \odot Correctness_R^{(i)} Correctness(i)=CorrectnessD(i)⊙CorrectnessR(i) C o r r e c t n e s s a l l = ∏ i = 1 n C o r r e c t n e s s ( i ) n Correctness_{all} = \sqrtn{\prod_{i=1}^{n} Correctness^{(i)}} Correctnessall=ni=1∏nCorrectness(i)
(3) MiCEval 的有效性
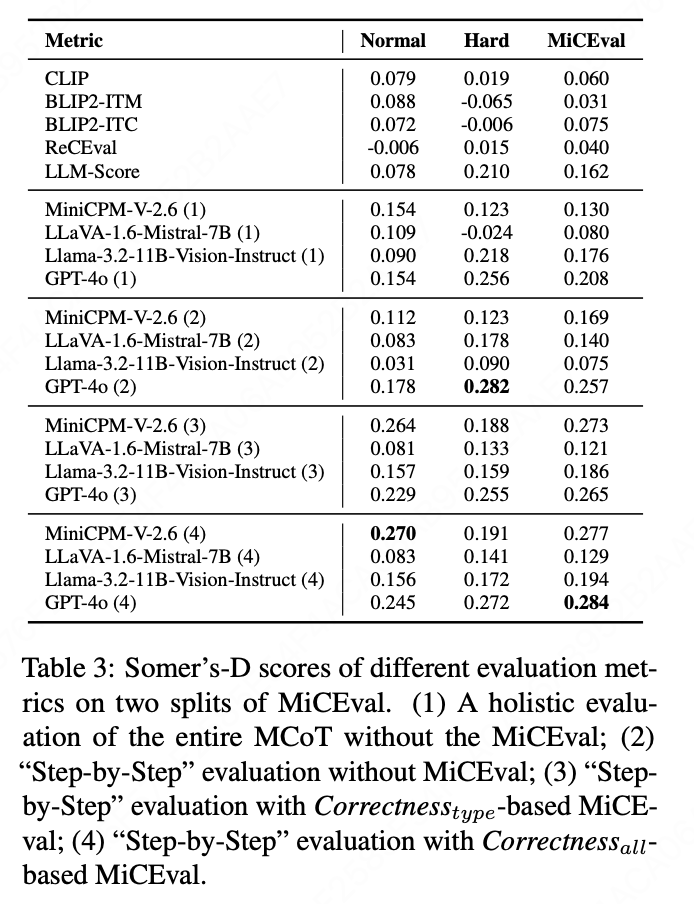
- 现有指标不太适合评估 MCoT 答案。与现有方法相比,基于 MLLM 的方法显示出与人类判断在 MCoT 答案中的更强相关性。
- MiCEval 使 MLLM 评估器更接近人类偏好。相比于没有 MiCEval 的评估,基于描述和推理正确性的 MiCEval 显示出更好的性能,并与人类判断更紧密地一致。
- MiCEval 有助于筛选出高质量的 MCoT。
2.6 MME-CoT(2025)
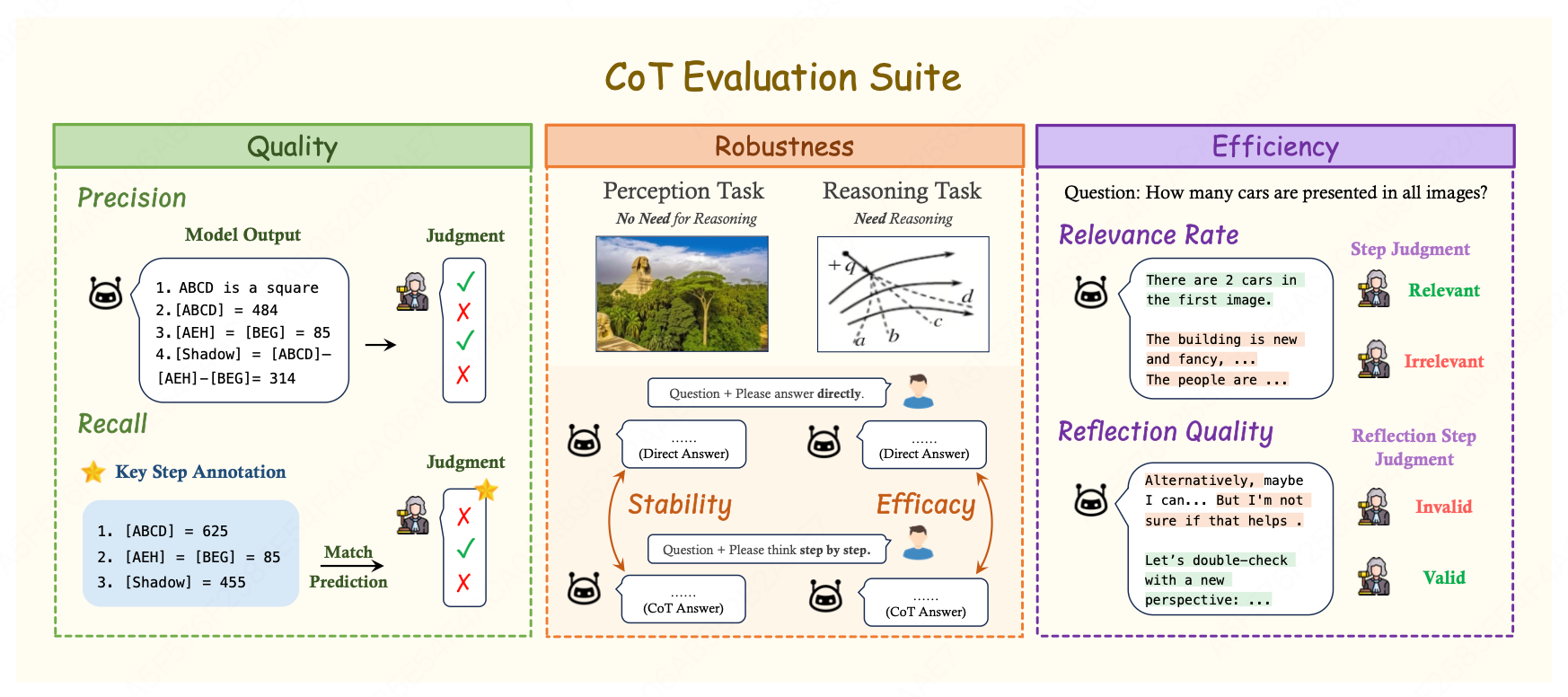
本文引入 MME-CoT,这是一个专门评估 LMMs 在 CoT 推理性能的基准,涵盖六个领域:数学、科学、OCR、逻辑、时空和一般场景。作为该领域的首次全面研究,提出了一套全面的评估方法,以细粒度地评估推理质量、鲁棒性和效率。
(1) CoT 正确性评估
现有的评估方法存在两个主要问题:
- 评分过程仅关注每个步骤的逻辑有效性,忽略了其帮助性评估
- 许多复杂的视觉推理问题甚至评分模型也无法解决,这种情况下的评估是不合理的。
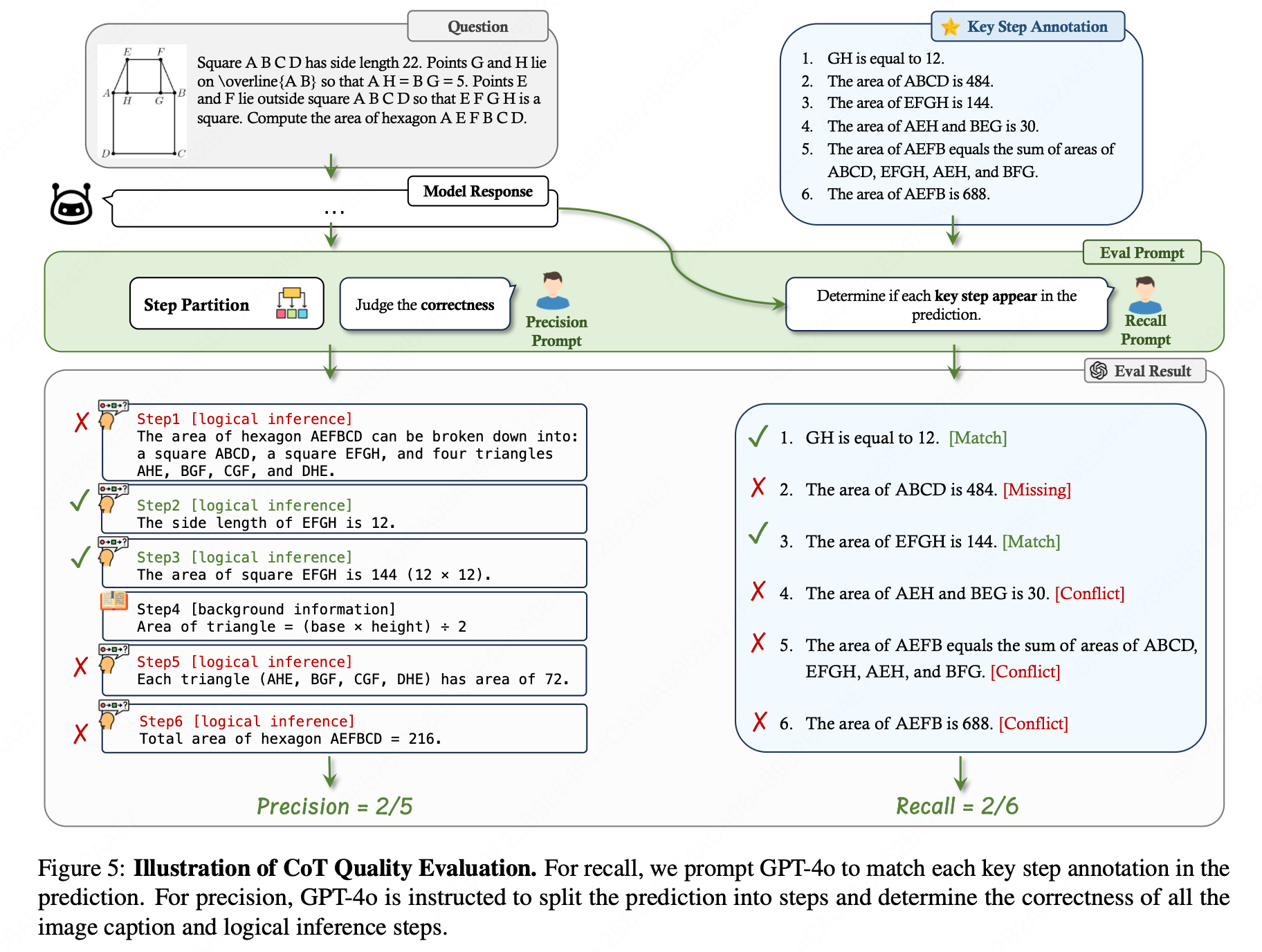
因此,MME-CoT引入了两个可解释的指标来评估CoT的正确性:召回率(Recall)和精确率(Precision)。这两个指标分别关注推理链正确性的两个方面:信息性和准确性。
关键步骤 表示为 S = C ∪ I \mathcal{S} = \mathcal{C} \cup \mathcal{I} S=C∪I,其中 C = { c 1 , . . . , c M } \mathcal{C} = \{c_1, ..., c_M\} C={c1,...,cM} 包含 M M M 个关键推理逻辑和 I = { i 1 , . . . , i N } I = \{i_1, ..., i_N\} I={i1,...,iN} 包含 N N N 个关键图像描述。
召回率(Recall) :通过测量模型响应中出现的真实解决方案步骤的比例来量化推理的信息量。从另一个角度来看,该指标也严格检查过程达到正确答案的严谨性,消除了随机猜测的可能性。
研究者使用GPT-4o来确定每个关键步骤是否出现在模型的CoT响应中,然后计算匹配的关键步骤与所有标注关键步骤的比例。
k 0 = arg max k ∣ S k k ∣ ∣ S k ∣ , k_0 = \arg \max_k \frac{|\mathcal{S}_k^k|}{|\mathcal{S}^k|}, k0=argkmax∣Sk∣∣Skk∣,
Recall C = ∣ C matched k 0 ∣ ∣ C k 0 ∣ , Recall I = ∣ I matched k 0 ∣ ∣ I k 0 ∣ , Recall = ∣ S matched k 0 ∣ ∣ S k 0 ∣ . \text{Recall}{\mathcal{C}} = \frac{|\mathcal{C}{\text{matched}}^{k_0}|}{|\mathcal{C}^{k_0}|}, \quad \text{Recall}{\mathcal{I}} = \frac{|\mathcal{I}{\text{matched}}^{k_0}|}{|\mathcal{I}^{k_0}|}, \quad \text{Recall} = \frac{|\mathcal{S}_{\text{matched}}^{k_0}|}{|\mathcal{S}^{k_0}|}. RecallC=∣Ck0∣∣Cmatchedk0∣,RecallI=∣Ik0∣∣Imatchedk0∣,Recall=∣Sk0∣∣Smatchedk0∣.
其中 S k \mathcal{S}^k Sk 表示问题的第 k k k 种方法。对于具有多种方法的问题,我们计算最匹配方法的召回率。
精确率(Precision) :通过评估生成的步骤中有多少是准确的来衡量其忠实性。
研究者首先将预测内容划分为一系列步骤 P \mathcal{P} P,每个步骤被分类为逻辑推理、图像描述或背景信息。然后,专注于评估逻辑推理步骤( C P \mathcal{C}^{\mathcal{P}} CP)和图像描述步骤( I P \mathcal{I}^{\mathcal{P}} IP)的正确性。
我们使用两个标准进行评估:1. 如果步骤存在于 S \mathcal{S} S 中,则步骤是正确的。2. 如果步骤在逻辑上正确或基于注释合理地描述图像,则步骤也是正确的。因此,我们计算精确度如下:
Precision C = ∣ C correct P ∣ ∣ C P ∣ , Precision I = ∣ I correct P ∣ ∣ I P ∣ , Precision = ∣ C correct P ∪ I correct P ∣ ∣ C P ∪ I P ∣ . \text{Precision}{\mathcal{C}} = \frac{|\mathcal{C}{\text{correct}}^{\mathcal{P}}|}{|\mathcal{C}^{\mathcal{P}}|}, \quad \text{Precision}{\mathcal{I}} = \frac{|\mathcal{I}{\text{correct}}^{\mathcal{P}}|}{|\mathcal{I}^{\mathcal{P}}|},\quad \text{Precision} = \frac{|\mathcal{C}{\text{correct}}^{\mathcal{P}} \cup \mathcal{I}{\text{correct}}^{\mathcal{P}}|}{|\mathcal{C}^{\mathcal{P}} \cup \mathcal{I}^{\mathcal{P}}|}. PrecisionC=∣CP∣∣CcorrectP∣,PrecisionI=∣IP∣∣IcorrectP∣,Precision=∣CP∪IP∣∣CcorrectP∪IcorrectP∣.
最终,研究者通过F1得分来综合评估CoT质量。
(2) CoT 鲁棒性评估
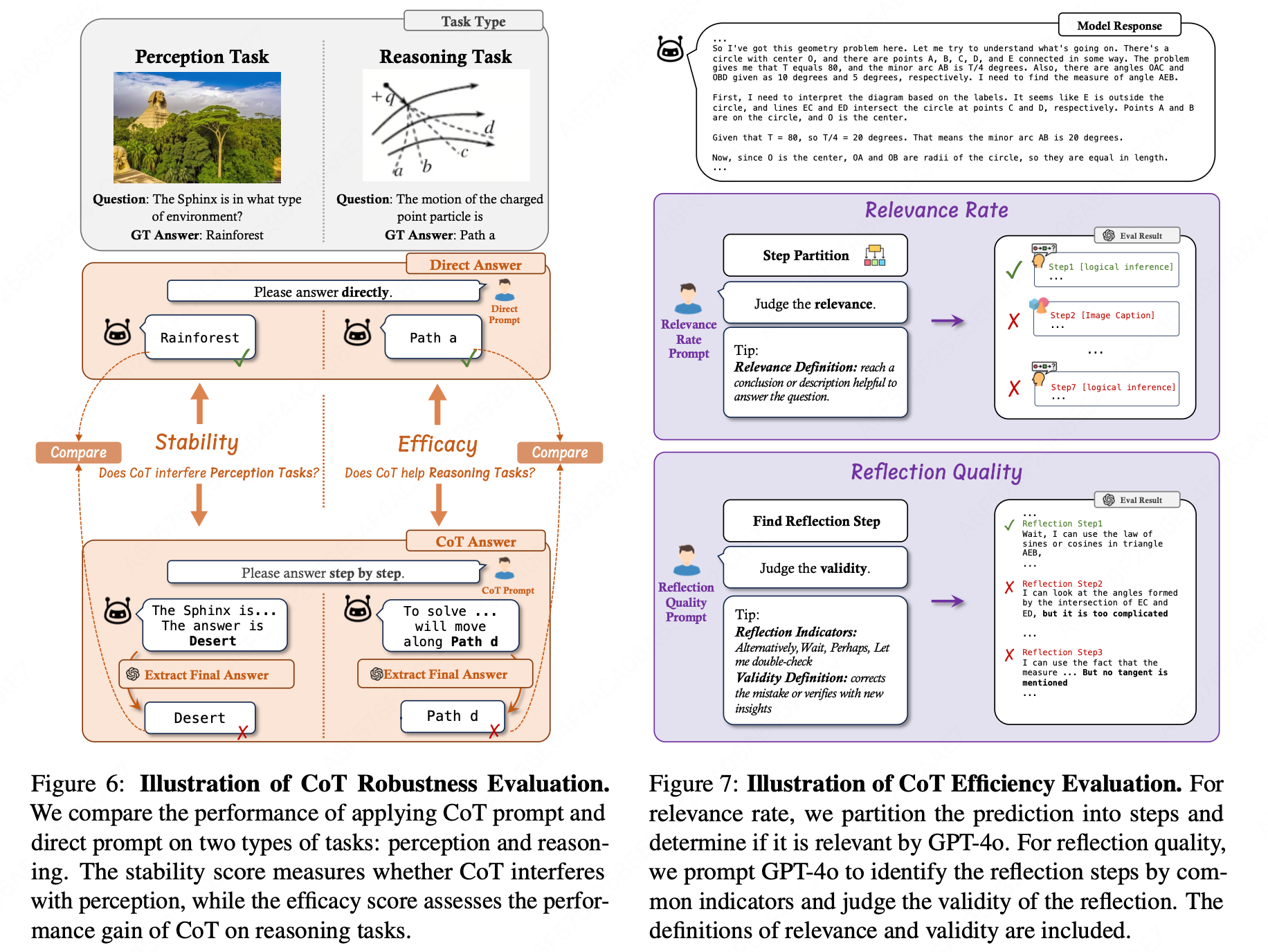
CoT在推理任务中的有效性已得到验证,但其对视觉感知任务或需要极少推理的任务的影响仍然未知。为此,MME-CoT提出了两个评估指标:稳定性(Stability)和效能(Efficacy)。
稳定性(Stability) :稳定性衡量CoT在感知任务中的表现是否受到干扰。
通过比较使用直接提示(direct prompt)和 CoT提示(CoT prompt)在感知任务上的表现差异来评估稳定性。理想情况下,应用CoT提示不应降低感知任务的性能。
Stability = Acc COT P − Acc DIR P \text{Stability} = \text{Acc}{\text{COT}}^{\mathbf{P}} - \text{Acc}{\text{DIR}}^{\mathbf{P}} Stability=AccCOTP−AccDIRP
效能(Efficacy) :效能衡量CoT在复杂推理任务中的表现提升。
通过比较使用直接提示和CoT提示在推理任务上的表现差异来评估效能。理想情况下,CoT应显著提升推理任务的性能。
Efficacy = Acc COT R − Acc DIR R \text{Efficacy} = \text{Acc}{\text{COT}}^{\mathbf{R}} - \text{Acc}{\text{DIR}}^{\mathbf{R}} Efficacy=AccCOTR−AccDIRR
(3) CoT 效率评估
MME-CoT 对视觉推理中的CoT效率进行详尽分析,提出了两个指标:相关率(Relevance Rate)和反思质量(Reflection Quality)。
相关率(Relevance Rate) :相关率评估生成内容中与回答问题相关的比例。用于衡量模型在生成内容时是否专注于问题的关键元素。
和先前一样,将预测内容划分为一系列步骤,然后使用GPT-4o确定所有相关步骤 P relevant \mathcal{P}_{\text{relevant}} Prelevant(只有当步骤的大部分内容有助于解决问题时,才认为该步骤是相关的)。
计算原始相关率,用 r x r_x rx 表示:
r C = ∣ C relevant P ∣ ∣ C P ∣ , r I = ∣ I relevant P ∣ ∣ I P ∣ , r = ∣ P relevant ∣ ∣ P ∣ r_{\mathcal{C}} = \frac{|\mathcal{C}{\text{relevant}}^{\mathcal{P}}|}{|\mathcal{C}^{\mathcal{P}}|}, \quad r{\mathcal{I}} = \frac{|\mathcal{I}{\text{relevant}}^{\mathcal{P}}|}{|\mathcal{I}^{\mathcal{P}}|},\quad r = \frac{|\mathcal{P}{\text{relevant}}|}{|\mathcal{P}|} rC=∣CP∣∣CrelevantP∣,rI=∣IP∣∣IrelevantP∣,r=∣P∣∣Prelevant∣
然后应用一个缩放因子来放大模型之间的差异,最终的相关率 Relevance Rate x \text{Relevance Rate}_x Relevance Ratex 定义为:
Relevance Rate x = r x − α 1 − α , x ∈ C , I , ∅ \text{Relevance Rate}_x = \frac{r_x - \alpha}{1 - \alpha}, \quad x \in \mathcal{C}, \mathcal{I}, \emptyset Relevance Ratex=1−αrx−α,x∈C,I,∅
反思质量(Reflection Quality) :反思质量分析每个反思步骤是否推动问题向正确方向发展。衡量了模型在反思过程中的有效性。
定义有效的反思为要么正确指出之前的错误,要么用新的见解验证之前的结论。 对于所有有效的反思步骤 R v a l i d \mathcal{R}{valid} Rvalid,反思质量计算如下:
Reflection Quality = ∣ R v a l i d ∣ ∣ R ∣ \text{Reflection Quality} = \frac{|\mathcal{R}{valid}|}{|\mathcal{R}|} Reflection Quality=∣R∣∣Rvalid∣
(4) 评估结果及发现
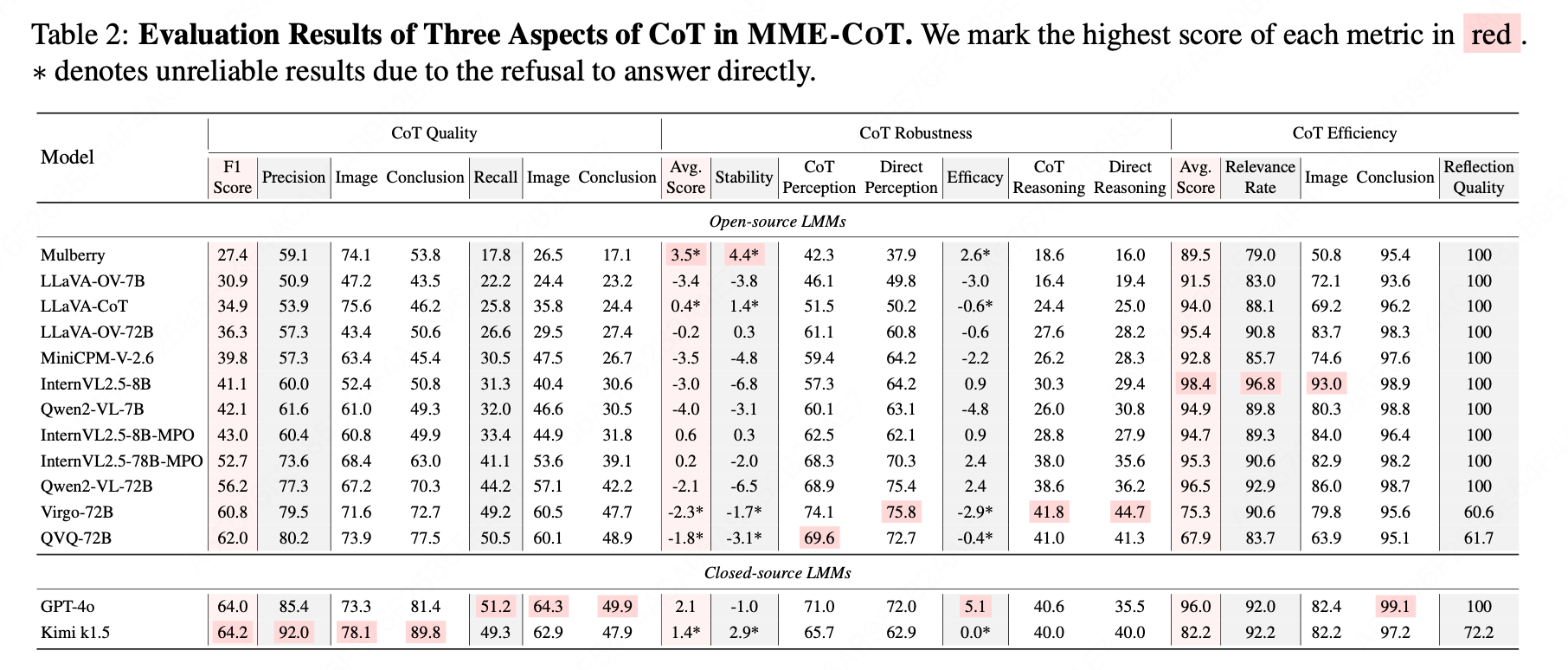
- 具备反思机制的模型显著提升了CoT质量
- 长CoT并不总是覆盖关键步骤
- CoT在大多数模型中损害了感知任务的性能
- 更多参数使模型更好地掌握推理能力
- 长CoT模型可能更容易分心,相关率得分往往低于其他模型
- 反思往往无法提供帮助
2.7 THINK-Bench(2025)
THINK-Bench: Evaluating Thinking Efficiency and Chain-of-Thought Quality of Large Reasoning Models
过度思考问题严重限制了大型推理模型(LRMs)的计算效率。该问题通常发生在模型生成过多且冗余的标记时,这些标记对准确结果的贡献很小,尤其是在简单任务中,导致计算资源的显著浪费。
本文为系统研究这一问题引入 Think-Bench,这是一个旨在评估 LRMs 推理效率的基准。
(1) 推理效率评估
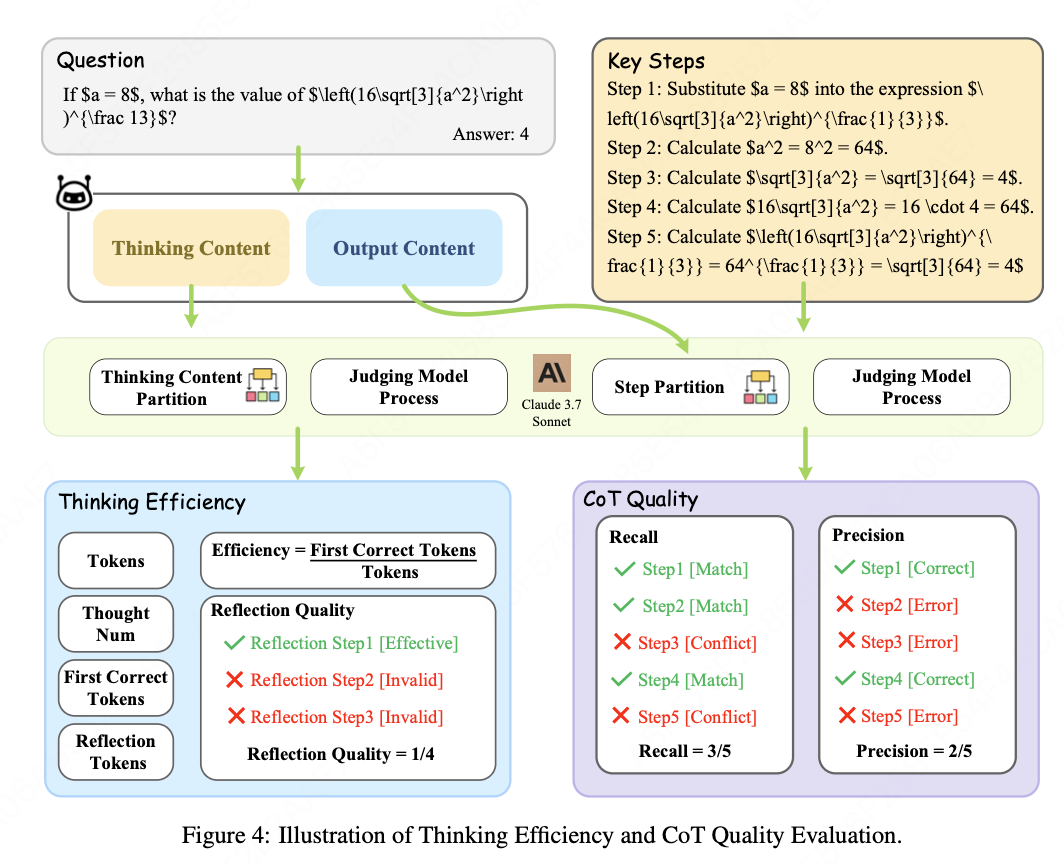

我们提出了六个互补的指标,系统地评估推理效率,包括标记使用、推理动态和反思质量。
- Tokens 测量最终预测前处理的总标记数,代表推理链长度,并为计算成本估算提供基础。
- First Correct Tokens 测量从推理开始到首次出现正确答案的标记数。这个指标评估模型在推理过程中达到有效解决方案的速度,其中较少的标记表示更快的正确收敛。
- Efficiency 是一个标准化指标,指的是首次正确标记数与推理标记总数的比率 。正式定义为:
Efficiency = 1 N ∑ i = 1 N T i ^ T i \text{Efficiency} = \frac{1}{N}\sum^N_{i=1}\frac{\hat{T_i}}{T_i} Efficiency=N1i=1∑NTiTi^ 其中 T i ^ \hat{T_i} Ti^ 表示模型在响应中首次出现正确答案之前生成的标记数, T i T_i Ti 代表第 i i i 个实例的总推理标记数。如果模型未能产生正确答案,我们设置 T i ^ = 0 \hat{T_i}=0 Ti^=0 。这个指标值越高,表示更有效的推理行为。 - Reflection Quality 衡量模型自我反思推理的有效性 ,特别是在产生正确答案之后。并非所有的反思步骤都有意义:有些只是重复先前的结论,而其他可能引入错误的修正。(同MME-CoT)
Reflection Quality = ∣ R v a l i d ∣ ∣ R ∣ \text{Reflection Quality} = \frac{|\mathcal{R}_{valid}|}{|\mathcal{R}|} Reflection Quality=∣R∣∣Rvalid∣ - Reflection Tokens 量化从首次正确答案到推理过程结束生成的标记数。这一部分通常包括验证步骤、反思分析和结论重述。尽管这些内容可能提供有价值的见解,但过长往往表示推理效率低下或不必要的重复。
- Thought Num 衡量模型更改推理路径的频率。这个指标通过计算诸如"alternatively"、"on second thought"和"wait a moment"等话语标记来估计。较高的计数可能表明推理不稳定或倾向于探索性行为。
(2) CoT 质量评估
类似于 MME-CoT,从召回率和精确度两个可解释的维度评估推理质量。每个CoT响应通过详细的提示被分解为多个推理步骤 R = { r 1 , r 2 , ⋯ , r M } R = \{r_1, r_2, \cdots, r_M\} R={r1,r2,⋯,rM},与预先注释的参考集进行比较,其中包含关键推理组件 S = { s 1 , s 2 , ⋯ , s N } S = \{s_1, s_2, \cdots, s_N\} S={s1,s2,⋯,sN}。
每个 r j r_j rj 被判断与任何 s i s_i si 的语义对齐,使用Claude 3.7 Sonnet作为评判,由一致的提示指令引导。定义:
- R m a t c h ⊆ R R_{match} \subseteq R Rmatch⊆R :正确匹配至少一个参考步骤的推理步骤子集。
- S c o v e r e d ⊆ S S_{covered} \subseteq S Scovered⊆S:成功匹配至少一个步骤的参考步骤子集。
使用 R m a t c h R_{match} Rmatch 和 S c o v e r e d S_{covered} Scovered ,我们如下计算召回率和精确度指标:
Recall = ∣ S c o v e r e d ∣ ∣ S ∣ , Precision = ∣ R m a t c h ∣ ∣ R ∣ \text{Recall} = \frac{|S_{covered}|}{|S|},\quad \text{Precision} = \frac{|R_{match}|}{|R|} Recall=∣S∣∣Scovered∣,Precision=∣R∣∣Rmatch∣
- 召回率衡量LRMs输出中准确捕获基本推理步骤的程度,反映了生成推理链的信息量和全面性。
- 精确度评估推理步骤的正确性和相关性,惩罚任何不准确或逻辑不一致的情况。
(3) 评估结果与分析
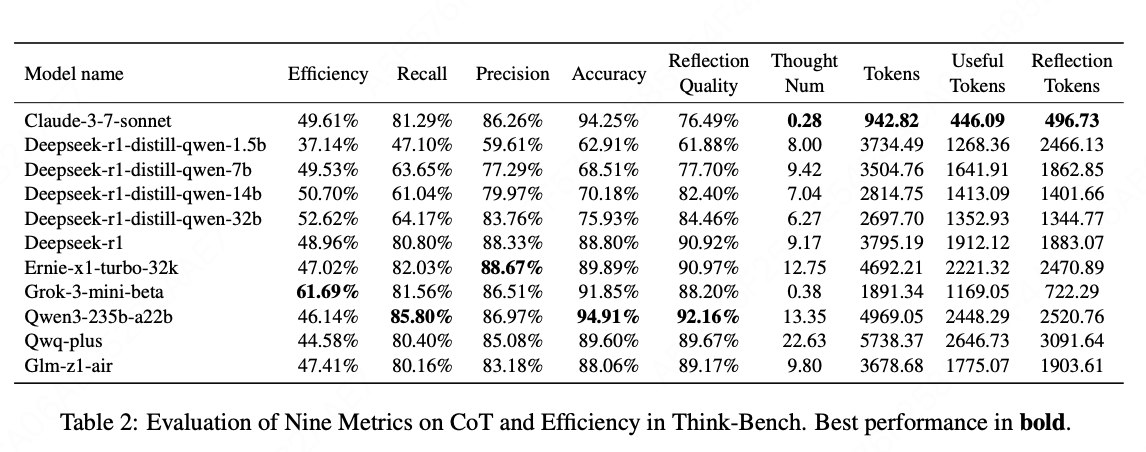
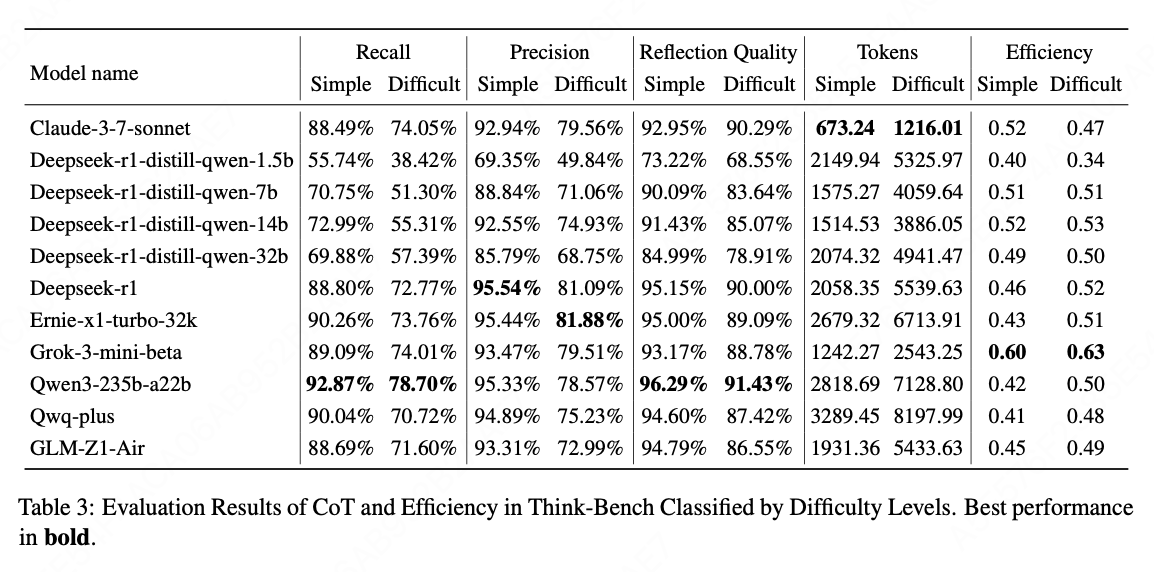
基于问题难度级别的评估和分析
- 表3的结果表明,大多数LRMs在简单问题上的平均效率明显低于困难问题。这表明,当面对简单问题时,这些模型倾向于过度思考并生成不必要的推理链。
- 相比之下,对于高难度问题,模型更有效地集中注意力,消除冗余推理步骤并提高效率。
- 困难问题的标记消耗始终高于简单问题,这是由于解决复杂问题所需的额外推理步骤。
- 随着任务难度的增加,反思质量、召回率和精确度都略有下降,这表明虽然困难问题需要更多的计算资源,但它们对模型的推理提出了更大的挑战。
2.8 无参考评估方法的对比与趋势分析*
| 方法名称 | 核心思想与特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| ROSCOE | 细粒度评估,涵盖语义对齐、逻辑推理、语义相似性和语言连贯性。 | 多维度评估,与人类判断相关性高。 | 需要人工标注数据进行微调。 | 通用推理任务,需要高质量标注数据支持。 |
| ReCEval | 通过正确性和信息量评估推理链。 | 强调推理的正确性和信息量,与人类判断相关性好。 | 需要人工标注数据进行微调。 | 通用推理任务,尤其适合需要高准确性的场景。 |
| SoCREval | 使用LLM进行评估,借鉴苏格拉底方法,通过优化提示实现无参考评估。 | 不需要人工标注数据,适应性强。 | 固定提示模板适应性有限。 | 通用推理任务,尤其是对标注数据依赖度低的场景。 |
| AutoRace | 自动创建评估标准并应用。 | 完全自动化,无需人工标注。 | 对复杂任务的适应性需要进一步验证。 | 多种推理任务,尤其是需要快速部署的场景。 |
| MiCEval | 多模态推理链评估,分解为描述和推理步骤。 | 细粒度评估,适应多模态任务。 | 数据集和模型依赖度高。 | 多模态推理任务,如图像描述和推理。 |
| MME-CoT | 综合评估推理质量、鲁棒性和效率。 | 全面评估,涵盖多个维度。 | 实现复杂,对模型要求高。 | 多领域推理任务,尤其是需要综合评估的场景。 |
| THINK-Bench | 更注重推理效率评估。 | 针对效率优化,指标全面。 | 主要适用于简单任务的效率评估。 | 推理模型在简单任务中的效率优化场景。 |
无参考质量评估阶段 早期标注微调阶段 LLM质量评估阶段 多模态推理链评估阶段 SoCREval
开始使用LLM评估 2024年 AutoRace
自动化评估标准创建 MiCEval
开启MCoT的评估 2025年 MME-CoT
开始关注推理效率 THINK-Bench
更加关注推理效率 2022年 ROSCOE
无参考评估的兴起 2023年 ReCEval
进一步细化评估指标
由上述分析总结出CoT质量评估方法发展趋势:
- 自动化与效率:从依赖人工标注数据的 ROSCOE 和 ReCEval 到完全自动化的 AutoRace,评估方法的自动化程度不断提高,显著提升了评估效率。
- 大模型广泛应用:大模型在推理评估中的应用越来越广泛,未来可能会进一步探索其潜力,开发更智能的评估策略。
- 多模态多领域综合评估:MiCEval 和 MME-CoT 的出现表明,评估方法开始向多模态和多领域综合评估方向发展,能够更全面地评估模型的推理能力。
- 适应性与灵活性:SoCREval 和 AutoRace 等方法通过优化提示或自动创建评估标准,提高了评估方法的适应性和灵活性,减少了对特定数据集的依赖。
- 效率与质量的平衡:MME-CoT和THINK-Bench 的提出反映了对推理效率的关注,未来评估方法可能会更加注重在效率和质量之间找到平衡。
三、元评估框架介绍
在评估推理链生成模型(如 ROSCOE、RECEVAL、SCOREVAL)时,一个核心挑战在于:如何比较不同自动评估指标与人类判断之间的一致性。为此,研究中通常引入元评估(meta-evaluation)框架,从更高层次评估"评估指标本身"的有效性。
在众多元评估统计量中,Somers' D 因其能够有效衡量两个有序变量之间的关联关系,并且在处理存在大量并列(ties)的偏置随机变量时具有优势,被广泛用于衡量自动评估指标与人工评分之间的一致性。
3.1 Somers' D 的原理
Somers' D 是一种衡量两个有序变量之间序关系关联程度的统计量,由 Somers(1962)提出。该统计量常用于评估在给定一个参考变量排序的条件下,另一个变量与其保持一致的程度。
Somers' D 的取值范围在 − 1 , 1 -1, 1 −1,1 之间,其中:
- 1 1 1 表示完全正相关;
- − 1 -1 −1 表示完全负相关;
- 0 0 0 表示不存在相关性。
Somers' D 的计算公式
在ROSCOE、RECEVAL、SCOREVAL的论文中,Somers' D 通过 Kendall's τ 系数进行计算,其形式定义为:
D ( Y ∣ X ) = τ ( X , Y ) τ ( X , X ) D(Y \mid X) = \frac{\tau(X, Y)}{\tau(X, X)} D(Y∣X)=τ(X,X)τ(X,Y)
其中:
- X X X 表示参考变量,通常为人类评分或错误存在指示变量(如 X ∈ 0 , 1 X \in 0,1 X∈0,1);
- Y Y Y 表示待评估的自动评估指标得分;
- τ ( X , Y ) \tau(X, Y) τ(X,Y) 为变量 X X X 与 Y Y Y 之间的 Kendall's τ 相关系数;
- τ ( X , X ) \tau(X, X) τ(X,X) 表示变量 X X X 与自身之间的 Kendall's τ 相关性,在 X X X 存在大量并列值时,该项小于 1,从而对相关性进行校正。
由于 Somers' D 是一个非对称(asymmetric)统计量 ,在计算时需将人类评分变量 X X X 作为第一个变量,自动评估指标得分 Y Y Y 作为第二个变量。
3.2 元评估的应用
在推理链评估中,我们将自动评估指标的得分作为变量 Y Y Y,将人类专家的评分或错误标注作为变量 X X X。通过计算 D ( Y ∣ X ) D(Y \mid X) D(Y∣X),可以评估自动评估指标在多大程度上反映了人类判断所诱导的排序关系。具体流程如下:
- 收集数据:收集自动评估指标得分以及对应的人类专家评分或错误标注。
- 计算 Kendall's τ 系数 :计算变量 X X X 与 Y Y Y 之间的 Kendall's τ 值 τ ( X , Y ) \tau(X, Y) τ(X,Y),以及 τ ( X , X ) \tau(X, X) τ(X,X)。
- 计算 Somers' D :依据公式 D ( Y ∣ X ) = τ ( X , Y ) / τ ( X , X ) D(Y \mid X) = \tau(X, Y) / \tau(X, X) D(Y∣X)=τ(X,Y)/τ(X,X) 计算 Somers' D。
- 分析结果:根据 Somers' D 的数值大小,分析不同自动评估指标与人类判断之间的一致性。
当一个评估方法包含多个变体(如 ROSCOE 或 RECEVAL),分别计算各变体对应的 Somers' D,并报告其中相关性最高的结果。
3.3 元评估的局限性与展望
尽管 Somers' D 是一个有用的元评估工具,但它也有局限性。例如,当样本量较小时,Somers' D 的结果可能不够稳定。此外,Somers' D 主要关注整体关联性,可能无法完全捕捉评估指标在某些特定维度上的表现。
未来的研究可以探索更精细的元评估方法,结合多种统计工具和机器学习技术,以更全面地评估推理评估指标的性能。同时,随着人工智能技术的不断发展,我们也可以利用元评估框架来指导评估指标的自动优化和改进,使其更加符合人类的认知和判断标准。
总之,元评估框架为我们提供了一个从更高层次审视和改进推理评估指标的视角。通过合理运用 Somers' D 等工具,我们可以更好地理解不同评估指标的优势与不足,从而推动推理评估领域的发展,使其更加科学、准确和高效。
四、小结
随着推理模型能力的持续提升,"是否给出正确答案"已不再足以刻画模型的推理质量。推理链的合理性、信息贡献、逻辑一致性以及生成效率,正逐步成为评估体系中的关键维度。围绕这些目标,研究社区已经从早期依赖人工参考推理链的评估范式,逐步转向更加灵活、可扩展的 reference-free 推理评估方法。
本文回顾了这一演化过程,并对近年来具有代表性的评估框架与基准进行了系统整理。可以看到,不同方法在评估粒度、监督形式和适用任务上各有侧重,其评估结果之间也并非总是一致。因此,引入诸如 Somers' D 等元评估指标,从排序一致性的角度分析自动指标与人类判断之间的关系,成为理解和比较不同评估方法的重要工具。
总体而言,推理评估仍是一个快速演进、尚未收敛的研究方向。未来的评估体系很可能需要在 正确性、效率、鲁棒性与可解释性之间取得更好的平衡,并在多模态与开放世界推理场景中经受更严格的检验。