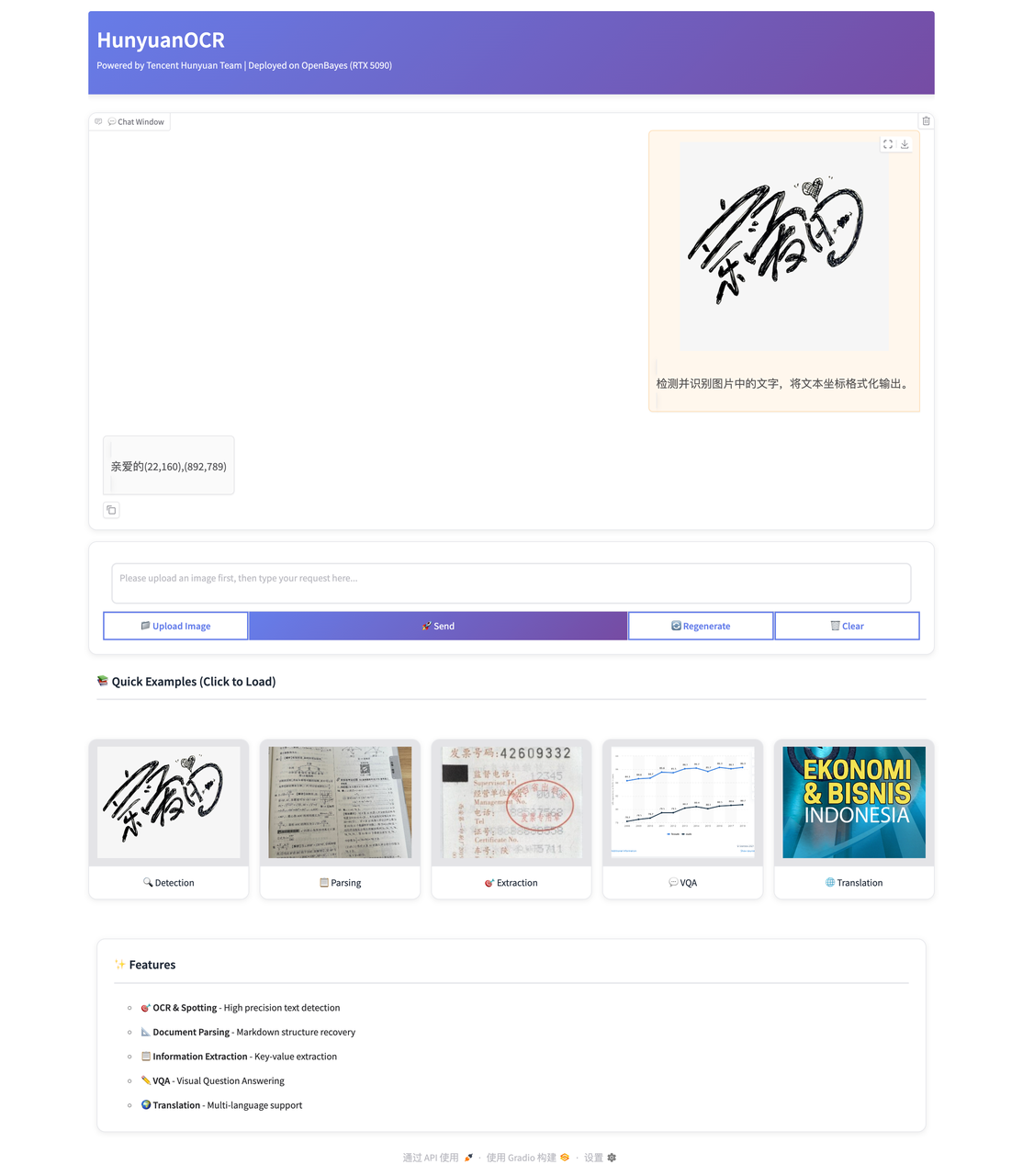
如果你用过 OCR,可能会发现它在单行文本上已经相当成熟,但一旦遇到多栏排版、表格或公式,效果就会明显下降。这并不是简单的识别精度问题,而是传统 OCR 更关注字符本身,却很少真正理解文档结构。
随着文档图像复杂度不断提高,OCR 正在从「认字」走向「读文档」。腾讯混元团队推出的 HunyuanOCR,是一款 1B 参数的端到端 OCR 多模态模型,尝试在一个模型中同时完成文本定位、识别与结构理解,摆脱对传统流水线式拼接的依赖。
在能力层面,HunyuanOCR 不仅具备高精度的文字识别与定位,还可以直接进行文档解析,自动恢复标题、段落和层级结构,并以 Markdown 等形式输出结果,使扫描文档能够直接进入编辑和二次处理流程。
同时,模型支持从文档中抽取关键信息,用于合同、表单等场景,并能基于文档内容进行视觉问答。此外,多语言建模能力也让跨语言文档的识别与翻译变得更加统一和自然。
1B 参数的规模,使这些能力具备现实部署价值。单卡即可运行,让端到端 OCR 不再只是研究概念,而是可以真正落地使用。本教程将基于 OpenBayes 平台,直观展示 HunyuanOCR 在真实文档场景中的表现。
当 OCR 开始覆盖解析、抽取与理解,文档图像也就不再只是图片,而是可以被直接利用的信息载体。HunyuanOCR,正是这一转变的代表。
教程链接:https://go.openbayes.com/5pnDt
使用云平台: OpenBayes
http://openbayes.com/console/signup?r=sony_0m6v
首先点击「公共教程」,找到「HunyuanOCR:腾讯混元端到端 OCR」,单击打开。
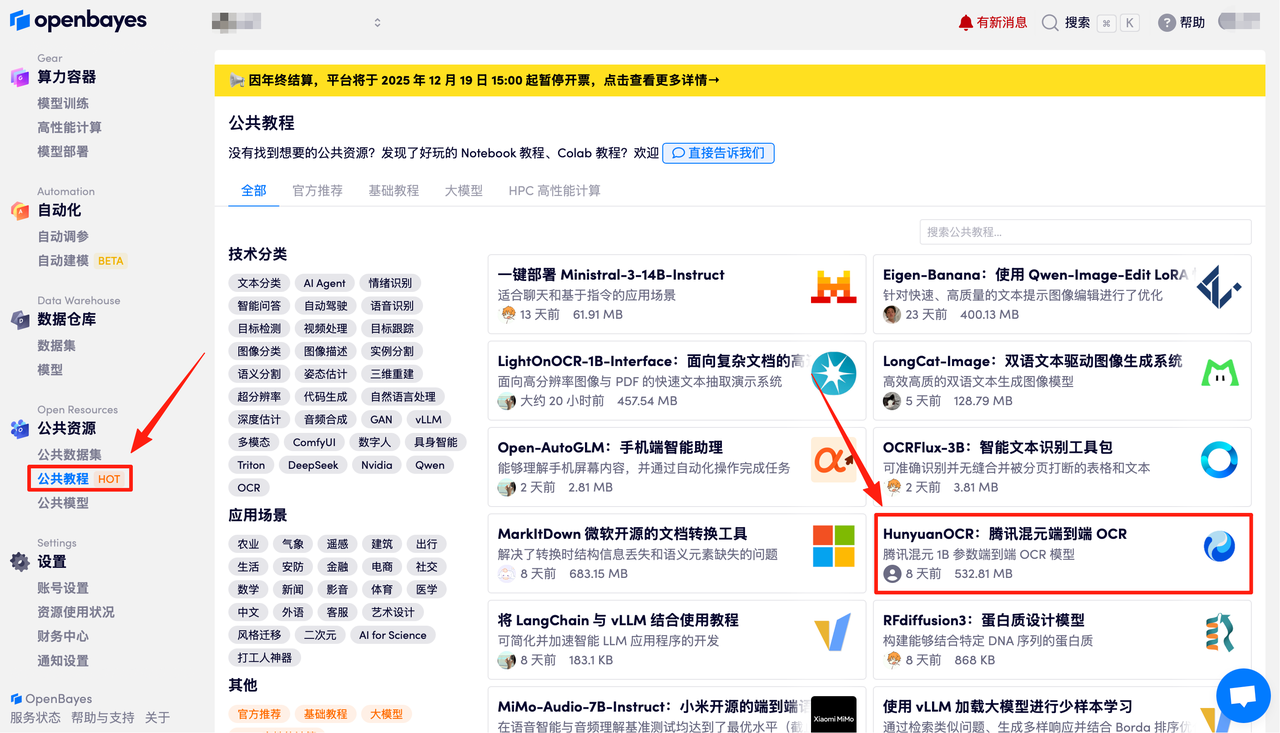
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
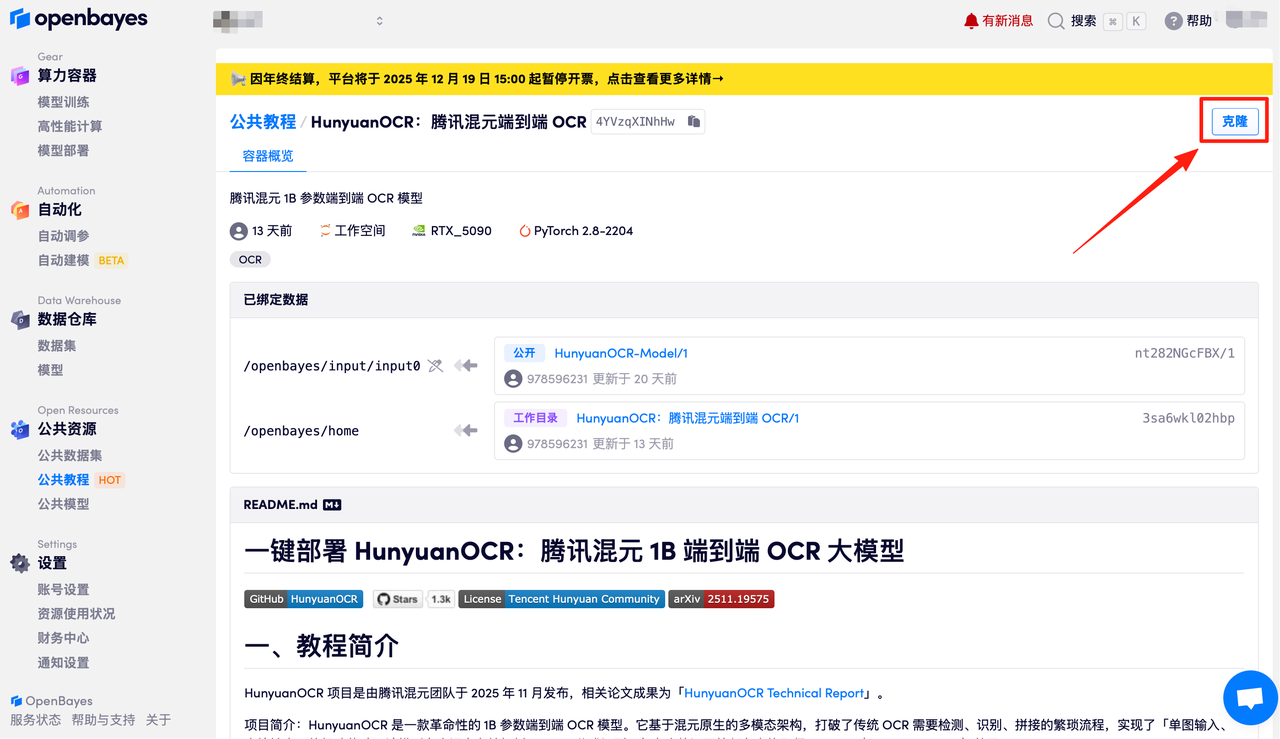
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
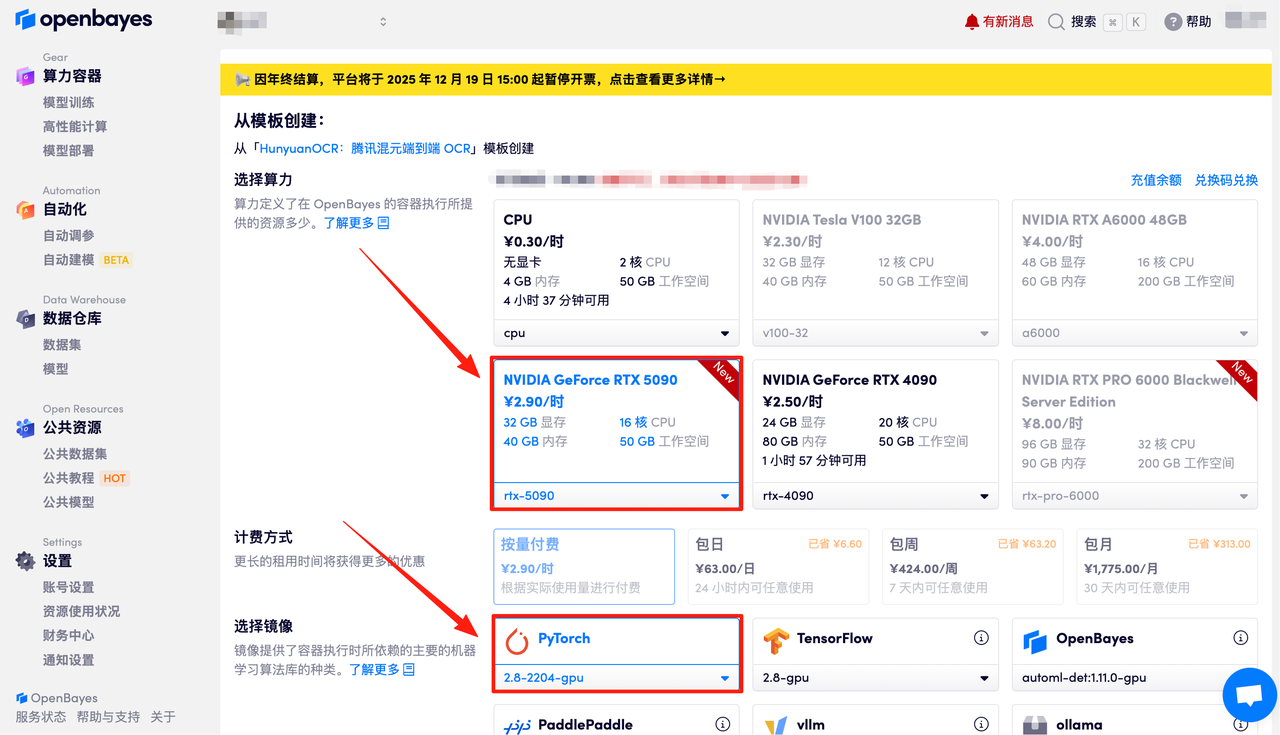
数据和代码都已经同步完成了。容器状态显示为「运行中」后,点击「API 地址」,即可进入模型界面。
若显示「Bad Gateway」,这表示模型正在加载中,请等待约 2-3 分钟后刷新页面即可。
使用步骤如下:
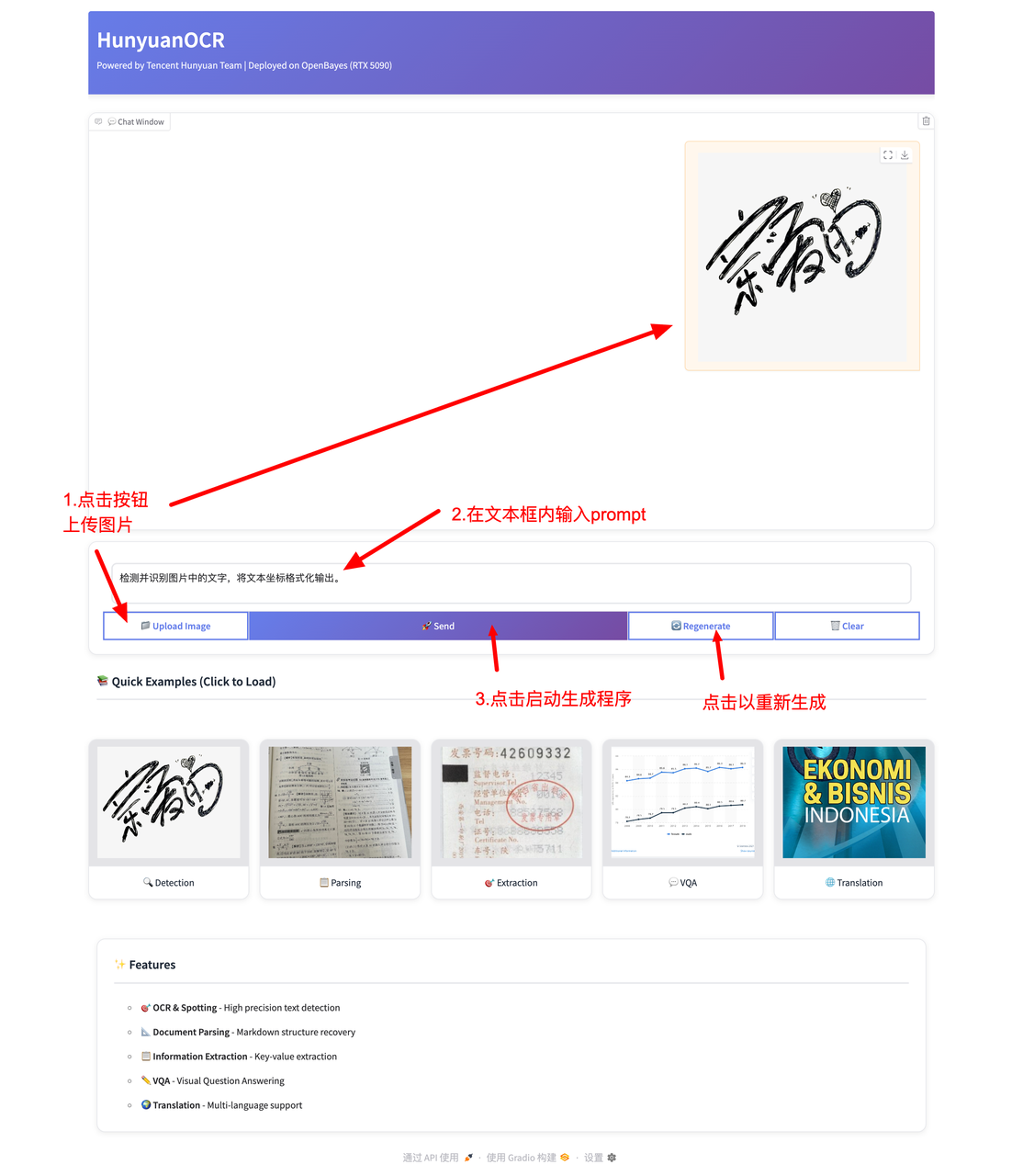
效果展示: