Jina Reader 是由 Jina AI 开发的一款开源工具,可将互联网网页的 HTML 内容转换为适合大型语言模型(LLMs)处理的纯文本格式。用户只需在网站地址前添加特定的前缀,即可快速提取网页的主要内容,并以结构化的文本格式输出,去除不必要的 HTML 标签和脚本。
本文面向小白开放,选取系统linux,足够任何人跟着走部署好jina reader,操作系统以ubuntu为例(一通百通),一篇文章带你安装canda、python、nodejs、git,随后部署jinareader,寓教于学,顺便拥有自己的网页提取工具~~~
一.安装conda
这里我们选用Miniconda,作为一个轻量级conad版本,安装非常简易
1.ctrl+alt+t 打开终端,输入
bash
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
2.安装
bash
bash Miniconda3-latest-Linux-x86_64.sh之后看到yes输入yes,没有让输入的就按回车键enter,全默认即可,不要看其他的安装conda的教程,以为有这个错误原因那个错误的弄!
(如果发生错误,自查三点:
1.安装的系统不管你是centos还是ubuntu,你确定是否真的安装好了系统而不是只是装了光盘?
2.如果是公司内部程序你准备私有化部署这个工具,你确定公司内网是否允许这种非软件安装申请?或者是否有防火墙?如果是个人部署,是否网络通畅?
3.依赖因为以前的某些操作丢失了吗?)
3.环境变量
只要你之前一路yes与enter下来,这个时候就安装好了,输入
bash
source ~/.bashrc你的终端就识别到已经按照好的canda了
然后输入
bash
conda --version
此时conda安装完毕,我们开启第二步
二、安装python
为了避免与系统自带的Python版本或其他项目发生冲突,建议创建一个独立的虚拟环境。
1.创建新环境
执行命令来创建一个名为 jina-env(也可以自定义其他名称)的新环境,这里我指定了python版本为3.10,大家一步到位装3.13,这里我为了引入"选择环境"更新python版本的情节,我先装了3.10便于教学,大家忽略就好
bash
conda create --name jina-env python=3.13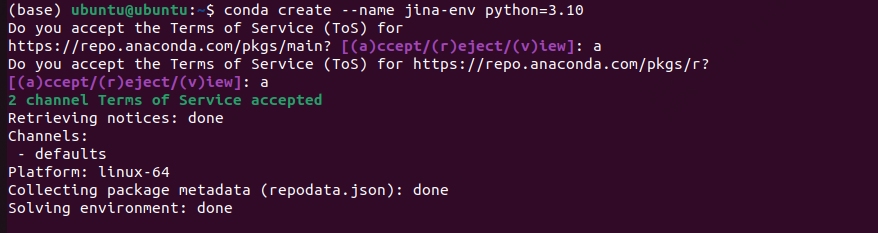
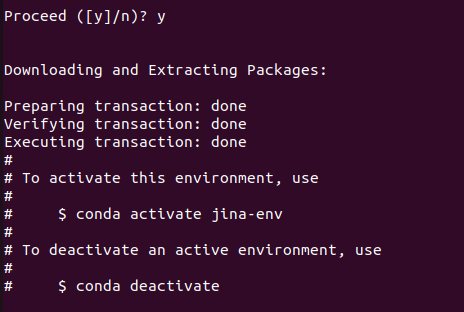
也就是遇到"a"输入"a",遇到"y"输入"y"
2.激活环境
环境创建成功后,使用以下命令激活它
bash
conda activate jina-env3.验证安装
bash
# 验证安装
python3 --version
pip3 --version
三、安装nodejs
1.首先安装工具curl
bash
sudo apt install curl -y
这里如果安装有问题就先更新apt,没有就不需要
bash
sudo apt update如果还是有问题那就试试以下代码选一个(没问题不需要使用)
bash
# 对于Debian 9.0以上系统,可能需要先安装sudo
sudo apt install sudo -y
# 或者尝试修复包管理器
sudo dpkg --configure -a
sudo apt update
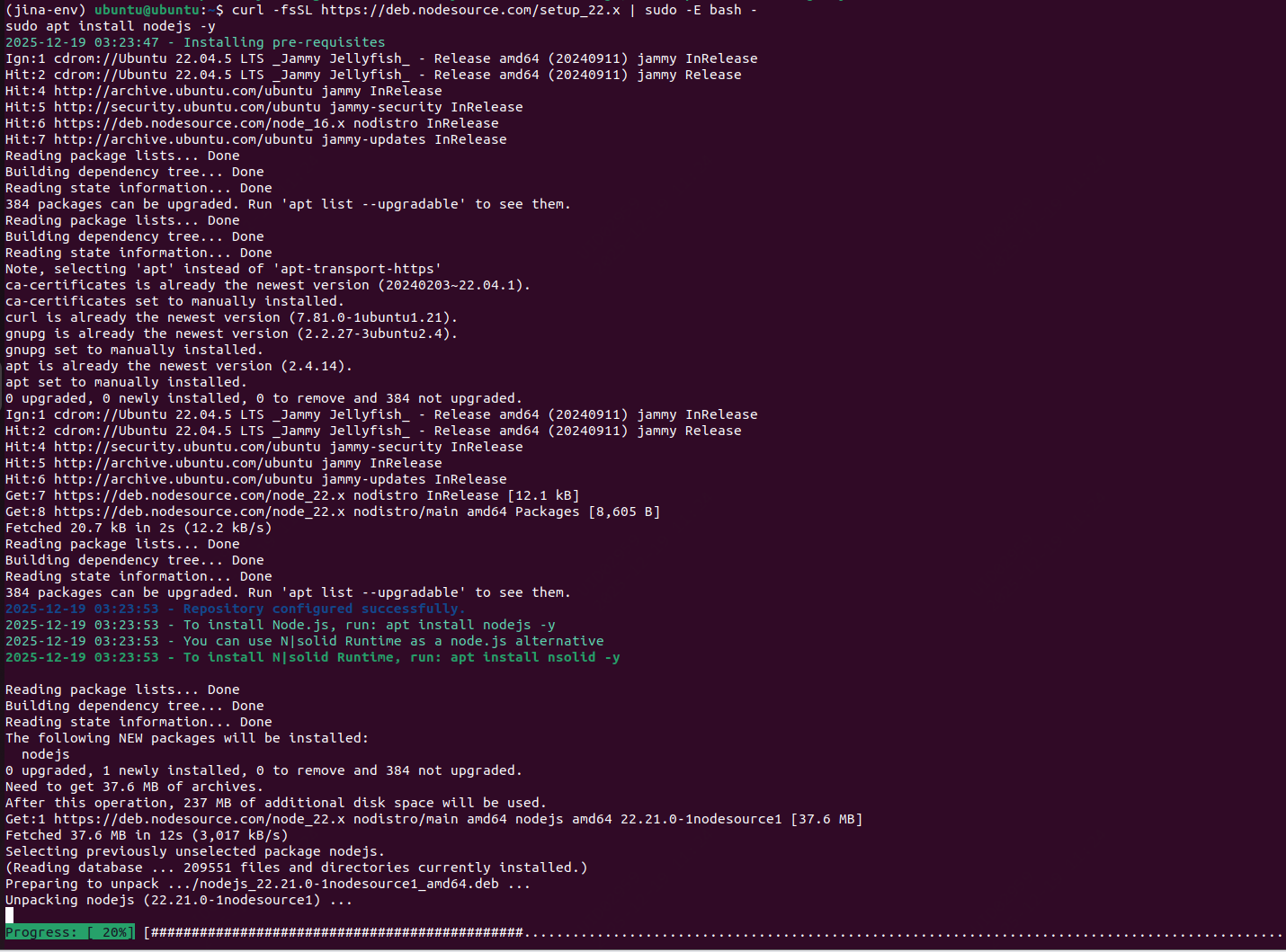
sudo apt install curl -y2.安装nodejs
输入
bash
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
sudo apt install nodejs -y后面不需要输入什么确认的内容,会直接安装好
3.验证版本
输入
bash
node -v
npm -v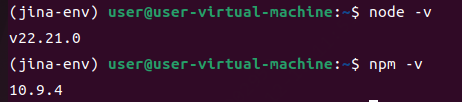
按照步骤来,不会出错,在确保网络正常、无防火墙干预的情况下,如果中间有任何问题,请附带系统+版本+问题私信我
四、安装git
1.安装git
bash
sudo apt install git注意填写自己的系统密码(linux是默认隐藏输入的密码,因此只是看上去没有输入)
2.验证
输入
bash
git --version
五、部署
1.拉取代码
直接输入
bash
git clone https://github.com/jina-ai/reader.git或者
bash
git clone https://gitclone.com/github.com/jina-ai/reader.git
2.移动到reader文件夹
输入
bash
cd reader3.检查先前的配置
这里要注意有没有关过终端或者中间换过环境
输入
bash
python --version看看是不是我们之前创建过的环境
如果得到不对的版本

那么回顾我们之前的操作,重新输入
bash
conda activate jina-env就可以回到我们之前的环境了(我装的版本是3.10.19,不必在意)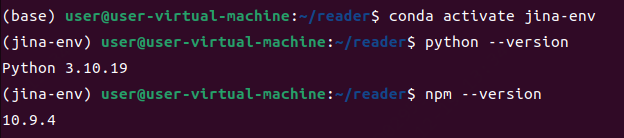
4.构筑
正常我们进入到reader文件夹后,输入
bash
npm install就会开始构建
接着输入
bash
npm run build
bash
npm run start此时服务启动,我们可以进入网址(在config.json自查),例如我的port是3000(自配)
以下是我的实际使用:
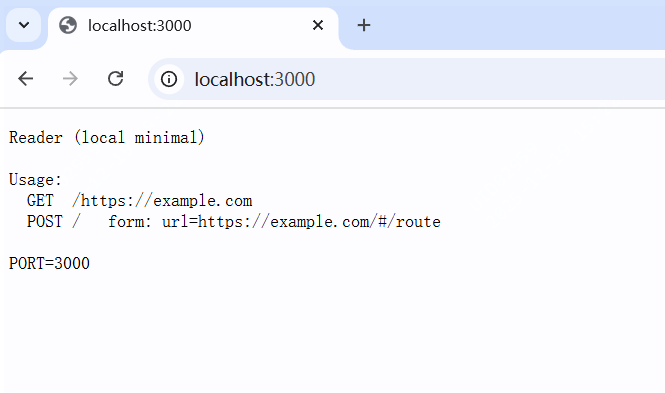
随意输入一个需要抽取的网站
1.例如https://www.gov.cn/zhengce/202512/content_7051904.htm,官方页面
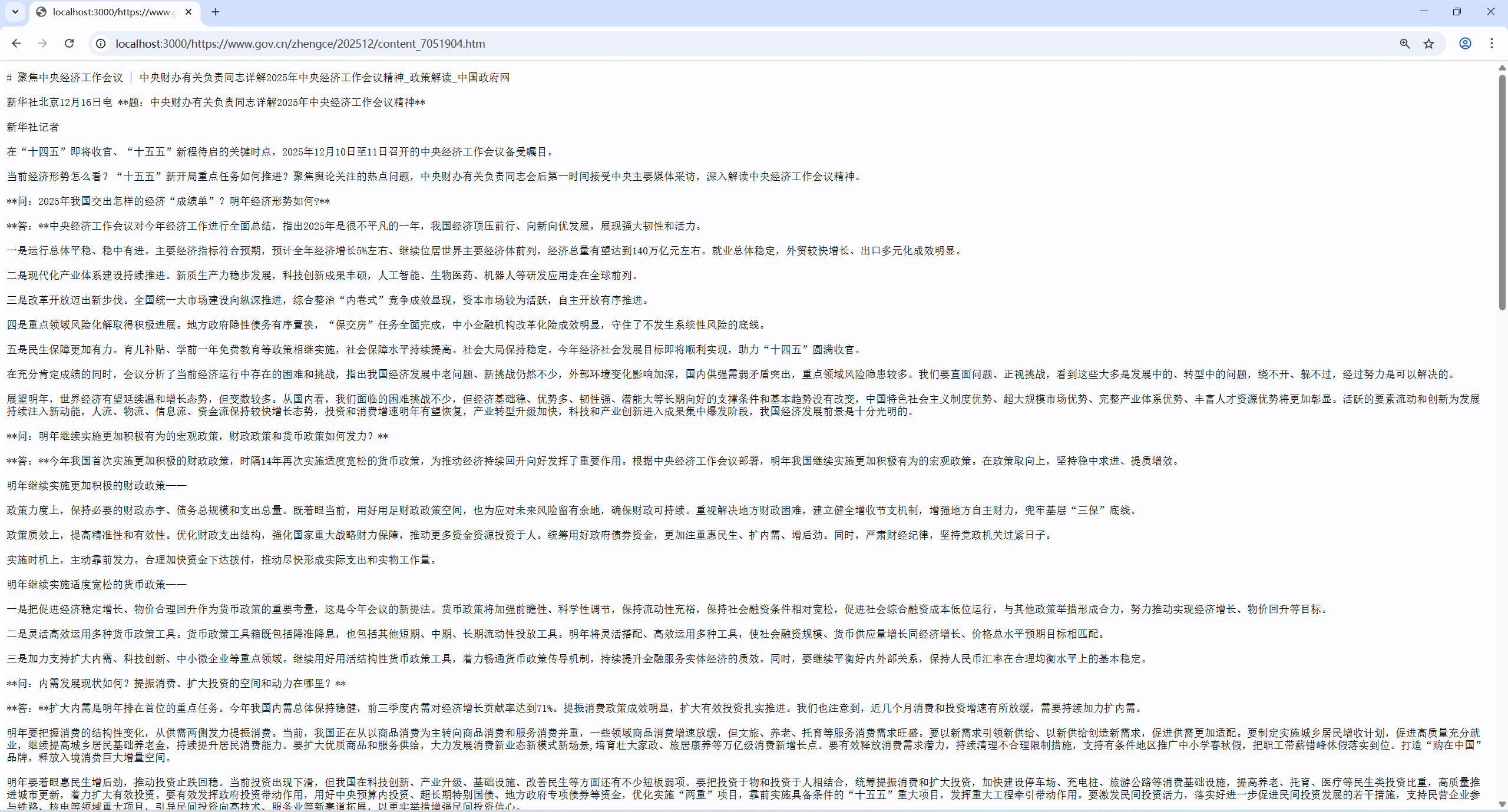
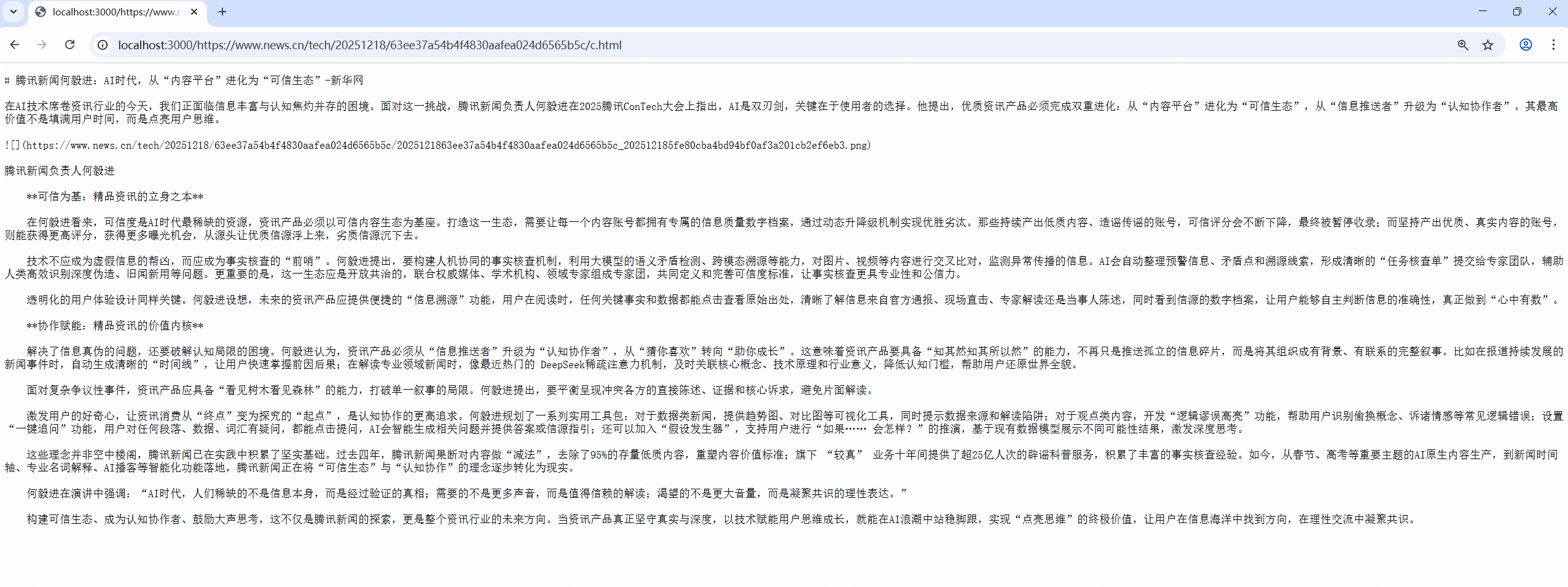
2.https://www.news.cn/tech/20251218/63ee37a54b4f4830aafea024d6565b5c/c.html,新华网
以下内容是部署失败的同学需要看的!
可能会遇到项目需要安装python3-dev(node-gyp需要Python开发头文件)
如果遇到,输入(没遇到就省略)
bash
# 安装编译工具链
sudo apt update
sudo apt install -y build-essential make g++
# 安装 Python 开发头文件(node-gyp 需要)
sudo apt install -y python3-dev注:(此处装的是python3.13版本的同学,学习一下就好,如果不是可以操作)
然后Python 版本取决于你使用的 node-gyp 版本, node-gyp 自 v10.0.0 起已正式放弃对 Python 2.x 的支持 ,全面转向 Python 3.12+ 。因此,对于新项目,强烈建议安装 Python 3.12 或更高版本。
我们首先确保在正确的环境
bash
conda activate jina-env输入
bash
conda install python=3.13 -n jina-env就可以更新python版本了,Conda 会解析依赖,列出所有将要安装、升级、降级或删除的包,并提示你确认 (Proceed ([y]/n)?),一路选y就可以了
也可以自行创建新的环境,返回上方创建新环境处自行创建即可。
这就提供了一种环境隔离的方法,可以隔离不同的依赖
如果大家学会了liunx安装canda、python、nodejs、git的方法,欢迎大家的点赞、收藏