想象这样一个场景:你想买一套二手房,看了很多房源后,你发现一个"规律":房子面积越大,总价一般就越高;离地铁站越近,价格也越贵。你的大脑根据这些看过的"历史数据",自动对新看到的房子进行"估价"------这个寻找"规律"并进行"预测"的过程,本质上就是"回归算法"在做的事情。
回归算法,可以说是人工智能世界里最古老、最基础,却又无处不在的"智慧之源"。今天,就让我们用一杯茶的时间,把它聊透。
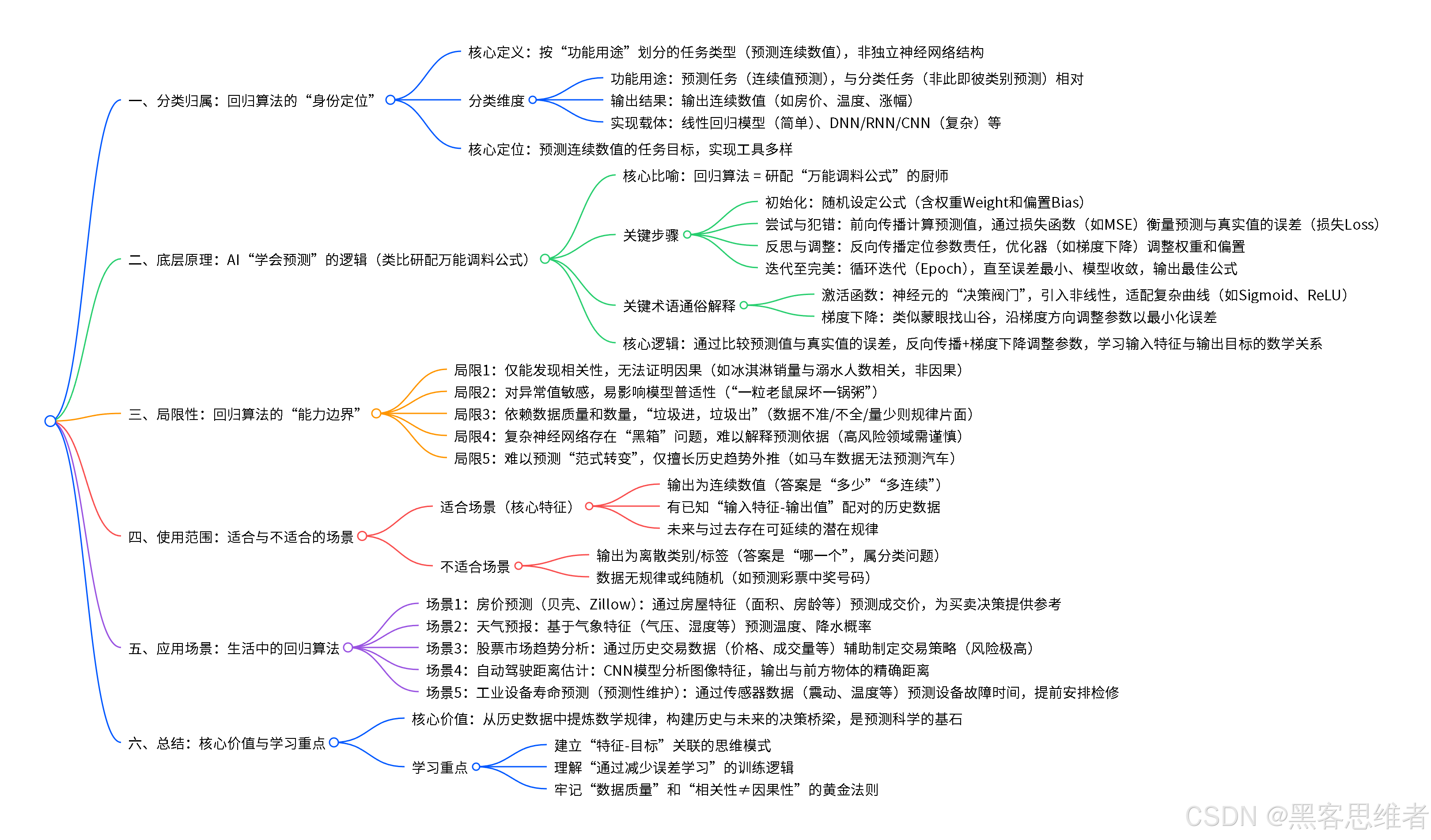
1. 分类归属:回归究竟是什么"身份"?
首先,我们得澄清一个常见误区:"回归算法"本身并不是一个独立的神经网络结构,而是一种按"功能用途"划分的任务类型和核心逻辑。
把它放到人工智能的"全家福"里,它的身份是这样的:
- 按功能用途划分 :它属于预测任务(尤其是连续值预测)的核心逻辑。与之相对的是分类任务(预测"非此即彼"的类别,比如这张图是猫还是狗)。
- 按输出结果划分 :其输出是一个连续的数值。比如预测房价(输出215.3万)、预测温度(输出28.5℃)、预测股票走势(输出明日涨幅+1.2%)。
- 实现的载体 :这种逻辑可以由非常多的神经网络结构来实现。最简单的可以用线性回归模型 (可视为只有一个神经元的超简单网络),复杂的可以用深度神经网络(DNN) 、循环神经网络(RNN)、**卷积神经网络(CNN)**等来实现回归预测功能。
简单说,回归是一种 "预测连续数值"的任务目标,而实现它的"工具"多种多样。我们今天重点理解这个"目标"本身及其核心思想。
2. 底层原理:AI如何"学"会预测?
让我们用一个做菜的类比,彻底搞懂回归算法是怎么工作的。
核心比喻:回归算法 ≈ 一位正在研配"万能调料公式"的厨师
假设你想复刻楼下餐馆那道百吃不腻的红烧肉。你不知道具体配方,但你有两样东西:
- 历史数据 :你吃过10次,每次厨师都记录了用了多少克糖(X1)、多少毫升酱油(X2) ,以及你做出来的美味评分(Y,满分10分)。
- 一个目标 :找到糖(X1)和酱油(X2) 与**美味评分(Y)**之间的"最佳公式",以便未来随便给个糖和酱油的量,你就能预测出评分。
回归算法要做的,就是帮你找到这个"最佳公式"。
第一步:初始化------"先随便蒙一个公式"
厨师(算法)一开始啥也不懂,它会随便猜一个公式。比如:
预测评分 = 0.5 * 糖的克数 + 0.3 * 酱油的毫升数 + 1.0
这个公式里的 0.5 和 0.3 叫做权重(Weight) ,1.0 叫做偏置(Bias)。你可以把它们理解为配方中各种调料的重要性系数和基础底味。
第二步:尝试与犯错------计算"预测"离"现实"有多远
厨师用这个瞎猜的公式,对那10次历史记录进行"预测"。比如第一次实际用了20克糖,10毫升酱油,实际美味评分是8分。但用公式算出来:
预测评分 = 0.520 + 0.3 10 + 1.0 = 10 + 3 + 1 = 14分
天哪,预测(14分)和现实(8分)差得太远了!这个差距,在AI里叫做损失(Loss)或误差 。衡量所有数据总误差的函数,叫损失函数 (比如常用均方误差MSE)。这一步就是前向传播 ------按现有公式计算预测值。
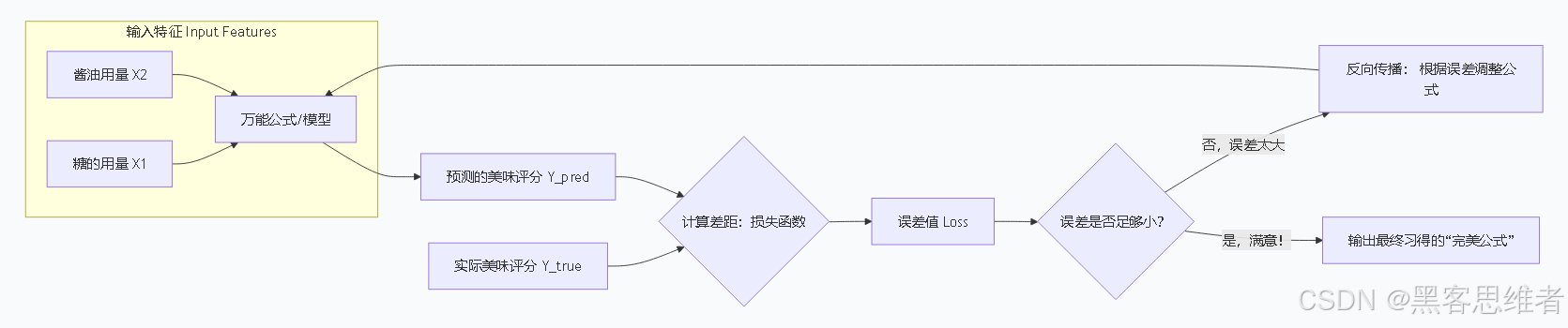
第三步:反思与调整------反向传播与优化
厨师现在知道猜错了,而且知道错得有多离谱(损失值)。关键来了:他需要知道到底是糖放多了(权重0.5太大),还是酱油放多了(权重0.3太大),还是底味太重了(偏置1.0太大)?
反向传播 就是干这个的:它把总误差反向传递回去,精确计算出公式中每个参数(权重和偏置)对误差"贡献"了多少责任。这个过程就像沿着来路返回,检查到底是哪一步走错了。
接着,优化器(如梯度下降) 登场。它根据计算出的"责任大小",告诉厨师每个参数应该往哪个方向、以多大幅度调整。比如:"糖的权重0.5,你降一点!降0.2吧!"这个过程就像沿着山坡往下走,寻找最低的误差点。
第四步:迭代至完美
厨师根据指示调整了公式,比如把糖的权重从0.5调到0.3。然后,他回到第二步,用新公式重新预测、计算误差 。接着第三步,再次反思调整......如此循环往复,成千上万次。
每一次循环称为一个迭代(Epoch) 。最终,公式的预测评分会越来越接近真实评分,总误差会降到最低。这时,我们就说模型收敛了,找到了那个"最佳万能公式"。
核心逻辑的文字描述版 :回归算法通过不断比较预测值与真实值的差距(损失) ,并利用反向传播和梯度下降技术,自动、反复地调整模型内部的计算参数,最终学习到输入特征(如糖、酱油用量)与输出目标(美味评分)之间最匹配的数学关系。
必要的术语通俗解释:
- 激活函数 :在更复杂的神经网络里,它就像是神经元的一个"决策阀门"。它决定是否将接收到的信号(加权求和后的值)传递下去,以及传递多少。常见的有Sigmoid(把值压缩到0-1之间)、ReLU(负数归零,正数原样通过),为模型引入非线性,让网络能拟合更复杂的曲线。
- 梯度下降:想象你蒙着眼站在一座山上,要找到最低的山谷(误差最小点)。你每走一步,都先用脚感受一下四周哪个方向最陡峭向下(计算梯度),然后就朝那个方向迈一小步(更新参数)。重复这个过程,最终就能走到谷底。
3. 局限性:回归算法并非"万能预言家"
理解了它的强大,也必须认清它的边界。回归算法有几个关键的"做不到":
- "相关"不等于"因果":这是最重要的局限!回归能找到强关联,但无法证明因果。比如,它可能发现"冰淇淋销量"和"溺水人数"高度相关,并预测出公式。但你不能说"多卖冰淇淋导致更多人溺水"。真实原因是二者都与"夏天高温"有关。模型只懂数据,不懂世界逻辑。
- 对"异常值"非常敏感:还记得我们的红烧肉数据吗?如果10次记录里,有一次你错把盐当成糖放了,导致评分奇低。这个"异常数据点"会像一个巨大的磁铁,把寻找的"最佳公式"曲线强行拽歪,严重影响最终模型的普适性。**"一粒老鼠屎,坏了一锅粥"**在这里非常形象。
- 严重依赖数据质量和数量 :"垃圾进,垃圾出(Garbage in, garbage out)"。如果历史数据本身不准、不全面(比如从来没试过少糖的做法),或者数据量太少,那么学到的"规律"必然是片面甚至错误的。AI无法从不存在的数据中学习到知识。
- "黑箱"问题(对于复杂神经网络):当使用深度神经网络做回归时,模型可能预测得很准,但连开发者自己也很难说清,到底这个预测结果是基于哪些特征的何种复杂组合得出的。这在高风险领域(如医疗、金融)需要格外谨慎。
- 难以预测"范式转变":回归擅长基于历史趋势外推。但如果未来发生根本性改变,它就失灵了。比如,用马车时代的交通数据训练模型,它永远预测不出汽车的出现。
4. 使用范围:什么样的问题该请它出马?
了解了能做什么和不能做什么,我们就能清晰地划出它的"势力范围":
✅ 适合用回归算法解决的问题(核心特征):
- 问题的答案是"多少"或"多连续" :输出是一个连续的数值。
- 有历史数据可供学习:存在已知的"输入特征"和对应的"输出值"配对数据。
- 未来与过去存在可延续的潜在规律:我们相信,影响结果的底层规律没有发生突变。
❌ 不适合用回归算法解决的问题:
- 问题的答案是"哪一个" :这是分类问题。比如判断邮件是否是垃圾邮件、识别图片中的动物种类。
- 输出是离散的类别或标签。
- 数据完全不存在规律或纯随机:比如预测彩票下一期的精确中奖号码。
5. 应用场景:回归算法在我们身边
它早已无声无息地渗透进我们的生活:
-
房价预测(如:贝壳、Zillow等平台)
- 作用:平台通过海量成交数据(特征:面积、房龄、楼层、地理位置、周边学校等,输出:成交价),训练出一个复杂的回归模型。当你输入心仪房子的特征时,模型能瞬间给出一个基于历史规律的估值参考,为买卖双方提供核心决策依据。
-
天气预报(如:温度、降水概率预测)
- 作用:气象部门收集全球历史气象数据(特征:气压、湿度、风速、卫星云图像素值等,输出:温度)。利用时空序列回归模型,分析这些特征如何协同作用导致温度变化,从而预测未来几小时甚至几天的精确温度。降水概率则是回归与分类的结合。
-
股票市场趋势分析(如:股价、指数预测)
- 作用 :量化交易公司使用回归模型,分析历史交易数据(特征:过往价格、成交量、公司财报指标、宏观经济数据等,输出:未来某一时点的股价)。虽然股市极其复杂且充满噪音,但回归模型是挖掘短期趋势和相关性、辅助制定交易策略的重要工具之一。(请注意,此领域风险极高,模型仅为辅助。)
-
自动驾驶中的距离估计
- 作用 :自动驾驶汽车的摄像头或激光雷达捕捉到前方物体。回归模型(通常是CNN)分析物体在图像中的特征(如像素位置、大小、模糊程度),并直接输出一个数值------该物体与汽车之间的精确距离(米)。这个连续的数值对于控制刹车、油门至关重要。
-
工业生产中的设备寿命预测(预测性维护)
- 作用:在工厂的风机、发电机等设备上安装传感器,持续收集数据(特征:震动频率、温度、电流电压波动等)。回归模型学习这些数据与设备最终故障时间的关系。当模型根据实时数据预测出"该设备可能在未来7天内发生故障"时,工程师就可以提前安排检修,避免意外停机造成巨大损失。
总结:回归算法的核心价值
回归算法的核心价值,在于它提供了一套 "从纷繁复杂的过去中,提炼出简洁数学规律,用以理性推测未来" 的自动化框架。它是预测科学的基石,是连接历史数据与未来决策的智慧桥梁。
对于初学者而言,学习回归的重点不是记忆复杂公式,而是建立一种思维模式 :理解**"特征"与"目标"** 之间的关联思想,明白**"通过减少误差来学习"** 的训练逻辑,并清醒地认识到数据质量 和相关性不等于因果性这两个贯穿整个AI学习生涯的黄金法则。
恭喜你!现在你已经掌握了让AI"预测未来"的第一把钥匙。下次当你看到房价评估、收到天气提醒时,你会知道,背后正有一个勤勤恳恳的"数字厨师",在无数历史数据中,为你默默计算着那个"最佳公式"。