最近在各个平台看了看"豆包手机"和特斯拉集成GORK实现车机Agent的相关视频演示,个人从技术角度归纳两个关注的技术点:
- 将豆包大模型深度植入手机操作系统底层,获得 Android 系统级高危权限INJECT_EVENTS(注入事件)
- 实现 "视觉识别 + 模拟触控" 的 GUI Agent(图形用户界面Agent)技术,无需 App 配合即可跨应用操作。(结构化UI用XML解析,非结构化UI用像素级VLM定位,精准识别复杂界面(如地图施工图标),提升操作成功率。)
以上相关技术汇聚就是目前比较火的"GUI Agent",顺藤摸瓜的翻到了一篇关于移动端GUI Agent训练框架-MobileRL (也是用于Agent Auto GLM训练的框架)。下面来看看MobileRL都解决了什么问题。
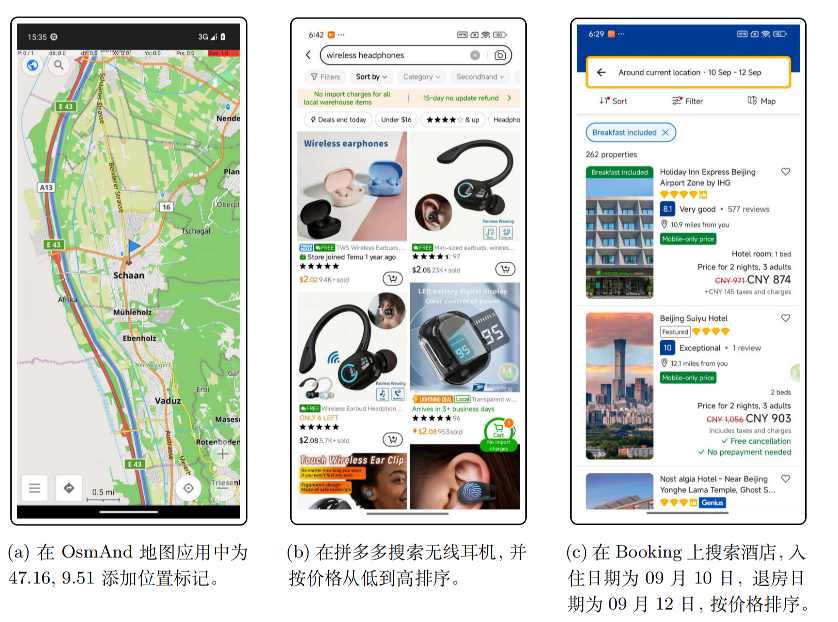
视觉语言模型(VLM)(如 Qwen2.5-VL、GLM-4.1V)让 "零样本交互网页 / 移动界面" 的 GUI Agent成为研究热点。这类Agent可通过感知屏幕截图 + 解析 UI 结构,自主执行点击、滑动、输入等操作,无需人工干预,理论上能适配各类移动应用(如日历、购物、地图 APP)。然而,移动 GUI 场景的特殊性(交互步骤长、环境反馈稀疏、设备仿真成本高)与通用 VLM 的 "静态感知" 能力存在矛盾 ------ 通用 VLM 仅能基于单帧画面生成动作,缺乏 "多步规划" 和 "环境反馈学习" 能力,难以应对复杂移动任务(如 "打开 Booking→筛选 9.10-9.12 的酒店→按价格排序")。因此,需通过强化学习(RL)让Agent从 "环境交互反馈" 中优化策略,但移动场景的 RL 面临独特挑战。MobileRL提出了过去GUI-RL 方法的几个挑战:
-
挑战 1:稀疏正信号下的复杂指令跟随:移动 GUI 任务的 "指令复杂度" 与 "反馈稀疏性" 矛盾。例如 "添加明天 3 点的重复日历事件" 需拆解为 "打开日历→点击新建→设置时间→开启重复→保存" 多步,但模型仅在 "全部步骤正确" 时才获奖励;移动模拟器的高延迟(单步交互需秒级)导致 "正确执行的轨迹(rollout)极少",早期探索阶段模型多生成错误动作,数据利用效率极低,训练周期被大幅拉长。
-
挑战 2:重尾且不稳定的任务难度分布:移动任务难度呈 "重尾分布"------ 少数任务占总计算量的大部分:
- 易任务:部分任务(如 "搜索无线耳机")仅需 3-5 步,多次采样即可成功;
- 死胡同任务:部分任务因 UI 设计限制(如隐藏菜单)或指令歧义,模型 "无论采样多少次都无法成功";
后果:传统 RL 的 "均匀采样" 会将大量计算资源浪费在 "死胡同任务" 上,同时未充分利用 "难但可解决" 的高价值轨迹(这类轨迹包含 "错误恢复""复杂指令拆解" 的关键信号)。
-
挑战 3:大规模移动环境的采样瓶颈:部署 / 管理 "数百个并发安卓实例" 的技术门槛高:每个安卓虚拟设备(AVD)需独立内存 / 存储,多机器协调难度大;不同机器的模拟器配置(如系统版本、APP 安装状态)差异,会导致同一动作的环境反馈不一致,影响 RL 训练稳定性;早期模拟器不支持 "真正并发执行",采样吞吐量极低(如仅能同时运行数十个实例),无法支撑 "大规模 RL 训练"(需数千次轨迹采样优化策略)。
建模目标
移动GUIAgent需根据自然语言指令(如"打开日历,添加明天下午3点的事件"),在移动设备上自主完成闭环交互:感知屏幕状态→定位UI元素→执行连续动作(无需人类干预),仅在任务成功时获得奖励,失败或达到最大步数时终止。
论文将移动GUIAgent建模为有限时域马尔可夫决策过程(MDP) M=(S, A, P, r, H, \\mu_0) ,各组件的具体定义贴合移动场景特性:
| MDP组件 | 具体含义(移动GUI场景适配) |
|---|---|
| 状态空间 S | 每个状态 s_t \\in S 包含两部分: ① 设备当前截图(视觉信息); ② 从XML元数据解析的结构化UI层级(功能信息,如按钮位置、可交互属性)。 |
| 动作空间 A | 9类原子GUI操作(覆盖移动交互核心需求): Tap(点击)、Swipe(滑动)、Type(输入文本)、Long Press(长按)、Launch(启动应用)、Home(返回主页)、Back(返回上一页)、Wait(等待3秒)、Finish(终止任务,可选消息)。 |
| 转移概率 P | 安卓系统与应用的随机转移机制(如点击按钮后的页面跳转不确定性)。 |
| 奖励函数 r | 稀疏二元奖励:任务成功时 r=1 ,失败或超时 r=0 ,仅在任务终止时反馈。 |
| 时域 H | 最大交互步数(实验中设为50步),避免无限循环。 |
| 初始分布 \\mu_0 | 指令-状态对的联合分布(即任务初始时的设备状态+自然语言指令)。 |
优化目标 :
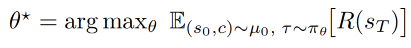
其中 \\tau=((s_0,a_0),...,(s_T,a_T)) 是交互轨迹, R(\\tau) 是轨迹总奖励。
MobileRL
框架核心思路:先通过两阶段监督微调(SFT)预热,再进行自适应强化学习(RL),解决直接RL冷启动效率低、探索成本高的问题。
组件1:无推理监督微调(Reasoning-Free SFT)
直接从基础视觉语言模型(VLM)启动RL,会因移动环境采样成本高(每个样本需安卓模拟器运行)、初始策略动作准确率低,导致探索效率极差。因此,第一步用"无推理专家数据"快速搭建动作执行基础。
- 数据来源:遵循Xu等人(2024)的协议收集人类标注专家演示数据,补充AndroidControl数据集(Li等人,2024)的训练集,总计97.9k训练步。
- 训练特点:数据仅包含"指令→动作序列"的映射(无中间推理步骤),目标是让模型掌握基础GUI操作(如"点击按钮""输入文本")的执行逻辑,避免RL初期因动作错误浪费计算资源。
- 训练配置:使用Llama-Factory框架,训练2个epoch,学习率从 1e-5 余弦衰减至 1e-6 ,图像保留原始分辨率以保证UI元素识别精度。
组件2:推理监督微调(Reasoning SFT)
无推理SFT的策略是"黑箱"(仅知动作序列,不知为何执行),难以处理长指令、组合型任务(如"搜索酒店→筛选日期→按价格排序")。需通过添加"中间推理步骤",提升模型的指令拆解和逻辑规划能力。
通过"基础指令模型引导+迭代精炼",给专家轨迹添加透明的推理过程,构建推理增强训练集:
- 引导采样:对每个任务 x 和专家动作 a\^\* ,用现成指令模型生成多个"推理-动作对" (c_k,a_k) ,仅保留 a_k=a\^\* 的有效对,存入推理数据集 D_R 。
- 监督微调:用 D_R 训练初始推理策略 \\pi_0\^R ,让模型学会"先推理再动作"。
- 迭代精炼:在第 t 轮,用 \\pi_t\^R 生成候选推理-动作对,筛选与 a\^\* 匹配的最优推理 c\^\* 加入 D_{new} ,微调得到 \\pi_{t+1}\^R 。
- 训练配置:同样训练2个epoch,数据集规模23.6k训练步,与无推理SFT数据互补。
组件3:Agent强化学习(Agentic RL)
前面两阶段SFT已搭建"动作执行+指令理解"基础,但仍缺乏环境交互反馈(如错误动作的修正、任务效率优化)。需通过RL利用环境反馈,进一步提升策略的鲁棒性和效率。
选择GRPO作为基础算法,用"组内相对基线"替代传统价值网络基线:对同一任务采样 G 条轨迹,计算组内奖励的均值 \\mu_R 和标准差 \\sigma_R ,轨迹优势 \\hat{A}_{i,t} = \\frac{R(\\tau_i)-\\mu_R}{\\sigma_R} ,避免价值网络估计不准的问题。损失函数设计(含KL正则防止策略漂移):
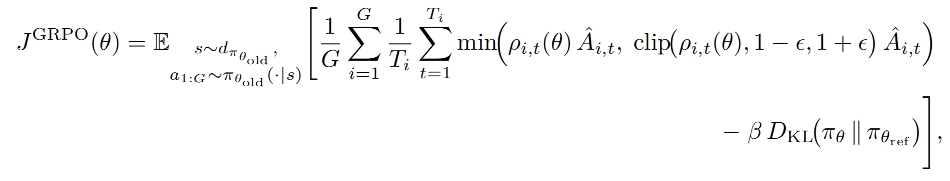
难度自适应GRPO(ADAGRPO)算法
为解决移动场景的三大挑战,在GRPO基础上设计了ADAGRPO(Difficulty-ADAptive GRPO),包含三个关键策略,分别对应"奖励分配""采样效率""难度适配"问题:
策略1:最短路径奖励调整(SPA)
原始稀疏奖励将 r=1 均匀分配给成功轨迹的每一步,导致模型偏向"长轨迹"(长轨迹贡献更多梯度更新),但移动用户更偏好高效、短步骤的交互。
根据轨迹长度调整奖励,短成功轨迹获得更高回报:
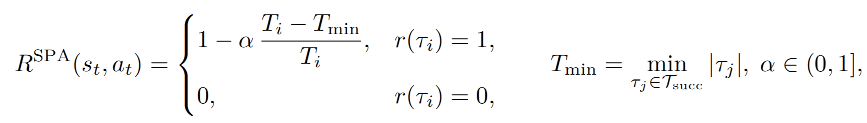
- T_i = \|\\tau_i\| :当前成功轨迹的长度;
- T_{min} = \\min_{\\tau_j \\in \\mathcal{T}_{succ}} \|\\tau_j\| :同一任务所有成功轨迹中的最短长度;
- \\alpha \\in (0,1\] :惩罚强度(实验中设为1.0);
- r(\\tau_i) :原始二元奖励(0或1)。
2. 策略2:难度自适应正向回放(AdaPR)
移动环境中,"成功且有挑战性"的轨迹极少(稀疏奖励),但这类轨迹包含关键学习信号(如复杂指令的拆解、错误恢复);而普通RL的均匀采样会浪费资源在低价值轨迹上。
借鉴经验回放,构建"高质量轨迹缓冲区",平衡回放与探索:
- 缓冲区构建:每轮RL迭代后,计算所有轨迹的优势值,将Top-κ(实验中κ=0.25)的高价值成功轨迹存入回放缓冲区 B ;
- 混合采样 :策略更新时,从"缓冲区+新采样轨迹"中混合抽取迷你批次:
q(\\tau) = \\gamma p_B(\\tau) + (1-\\gamma) p_{on}(\\tau)
- p_B(\\tau) :缓冲区轨迹的经验分布;
- p_{on}(\\tau) :当前策略的在线采样分布;
- \\gamma=1.0 (实验配置):最大化高价值轨迹的利用效率。
策略3:失败课程过滤(FCF)
任务难度呈"重尾分布":部分任务模型始终无法解决(如超复杂多步骤任务),反复采样这类任务会浪费计算资源,且无正向学习信号。
基于"课程学习"思想,动态过滤持续失败的任务:
- 失败判定:若某任务连续2个epoch的所有轨迹均失败(奖励为0),进入3个epoch的"冷却期";
- 权重衰减 :冷却期内,该任务的采样概率按 w_{task} = \\exp(-f) 降低(f为连续失败epoch数);
3.冷却期结束后仍未成功,永久从采样池中移除。
XML预处理
安卓无障碍服务生成的原始XML包含UI页面的完整布局和元素信息,但存在三大问题:
- 含大量"结构型节点":仅用于页面布局(如框架容器),无实际交互语义;
- 屏外节点干扰:可滚动页面会包含未显示在屏幕上的节点,影响动作模拟(如点击、滑动)的准确性;
- 属性描述冗余:XML属性冗长(如完整类名、重复布尔值),增加模型处理的token开销。
处理步骤
1. 移除屏外节点
根据任务需求动态控制是否保留屏外节点,避免无效节点干扰:
- 控制参数:
remain_nodes(布尔值)remain_nodes=True:保留屏外节点(如需总结整页内容、无需滚动交互的场景);remain_nodes=False:移除屏外节点(默认用于动作模拟场景,避免模型点击/滑动不可见元素)。
- 判断逻辑:递归检查节点的
bounds属性(边界坐标),仅保留完全位于屏幕尺寸[0,0]~[Window_Height, Window_Width]内且被父节点包含的"屏内节点"。
2. 删除冗余节点
仅保留"有功能/语义的节点",剔除无交互价值的结构型节点:
- 功能节点判断标准(满足任一即可保留):
- 布尔属性为
True:包含checkable(可勾选)、clickable(可点击)、scrollable(可滚动)等交互相关属性; - 文本属性非空:
text(显示文本)或content-desc(内容描述)字段有有效信息。
- 布尔属性为
- 处理逻辑:遍历所有节点,删除不满足上述条件的冗余节点(如纯布局框架、空白占位元素)。
3. 属性简化
精简XML属性描述,减少token消耗并突出关键信息:
- 具体优化规则:
- 布尔属性:仅保留
True值(如clickable="true"保留,clickable="false"直接省略); - 无用属性删除:移除
index(索引)、resource-id(资源ID)、package(应用包名),这些信息对语义理解无帮助; - 类名精简:仅保留类名的最后一部分(如
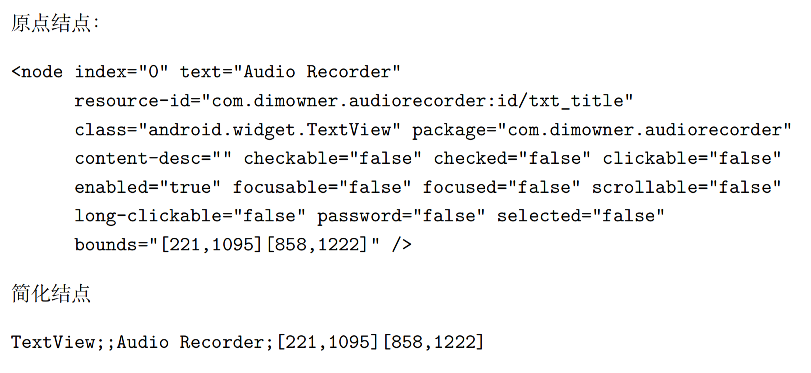
android.widget.FrameLayout简化为FrameLayout); - 文本属性合并:将
text和content-desc合并为统一文本字段,单独展示; - 完整保留边界属性:
bounds(元素坐标,如[221,1095][858,1222])是动作执行的核心依据,完全保留。
- 布尔属性:仅保留
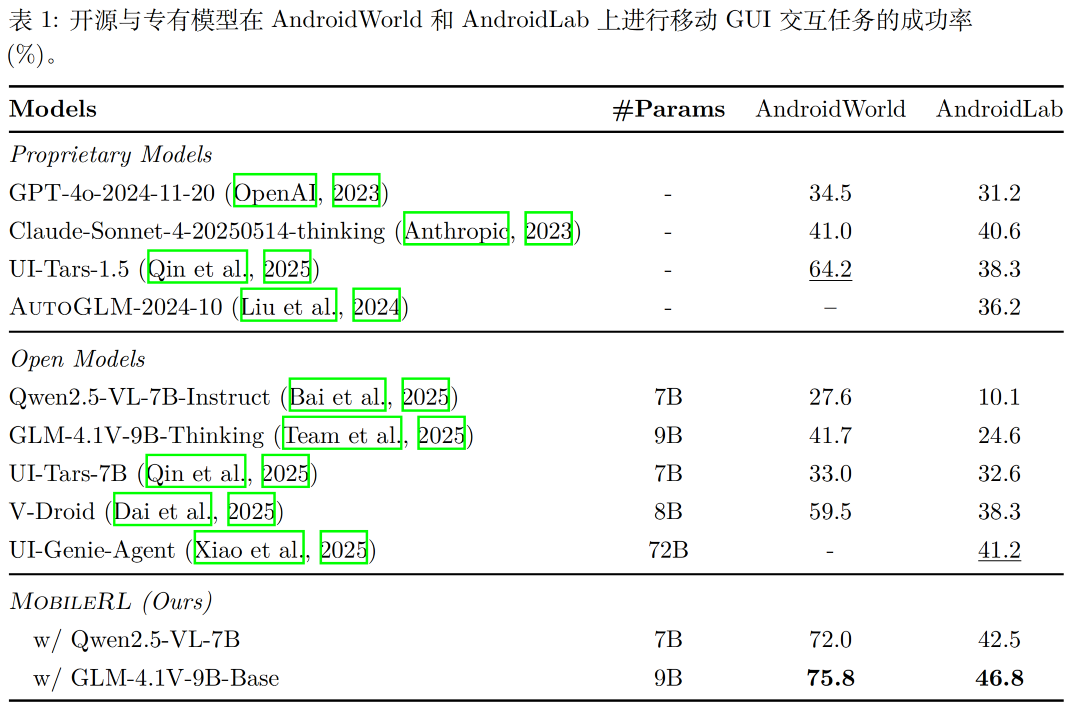
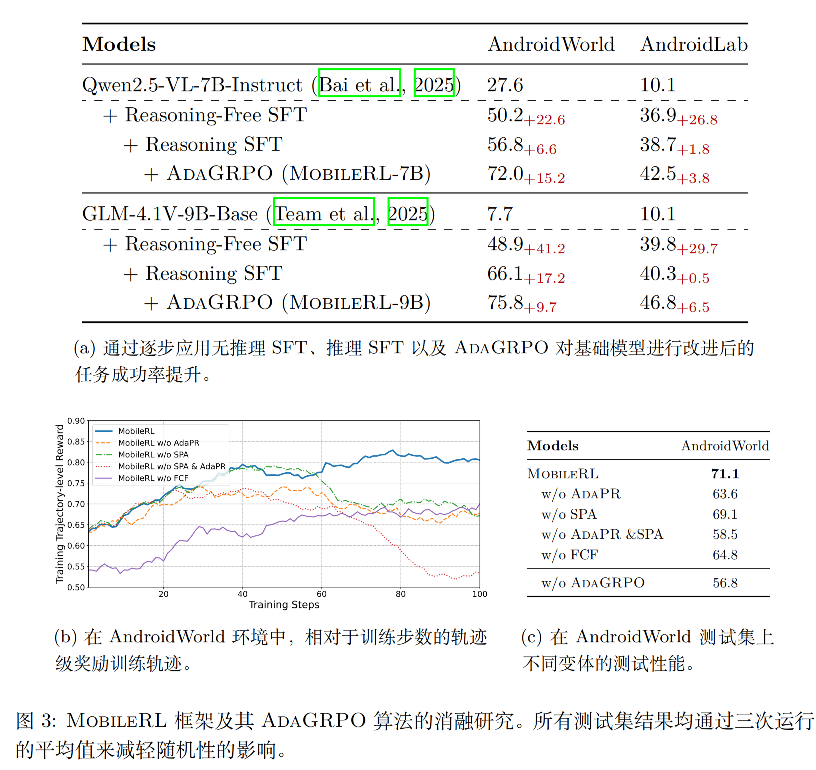
实验性能
参考文献
- MobileRL: Online Agentic Reinforcement Learning for Mobile GUI Agents,https://arxiv.org/pdf/2509.18119
- https://github.com/THUDM/MobileRL