学习目标 :理解机器学习的本质,掌握监督/无监督学习的区别,理解训练集/测试集的重要性
预计时间 :20分钟
前置知识:Python基础,Numpy基础
📋 本篇内容
机器学习本质 → 学习方式分类 → 核心术语(训练/测试/过拟合)🤖 1. 什么是机器学习?
1.1 传统编程 vs 机器学习
生活类比:
- 传统编程 就像是照菜谱做菜。你告诉电脑每一步怎么切、怎么炒(规则),给它食材(数据),它给你做出一道菜(结果)。
- 机器学习 就像是教徒弟做菜。你给徒弟尝100道好吃的菜(数据+结果),让他自己去琢磨其中的规律(模型),最后他学会了做菜(规则)。
核心区别:
- 传统编程 :输入
规则+数据= 输出答案 - 机器学习 :输入
数据+答案= 输出规则(这个规则就是模型)
1.2 为什么要用机器学习?
当规则太复杂,人类无法显式写出代码时。
- 例子 :写一个程序识别照片里是否有猫。
- 传统方法:试图定义猫的耳朵形状、胡须长度...(太难了,猫的姿态千变万化)
- ML方法:给机器看10000张猫的照片,让它自己找规律。
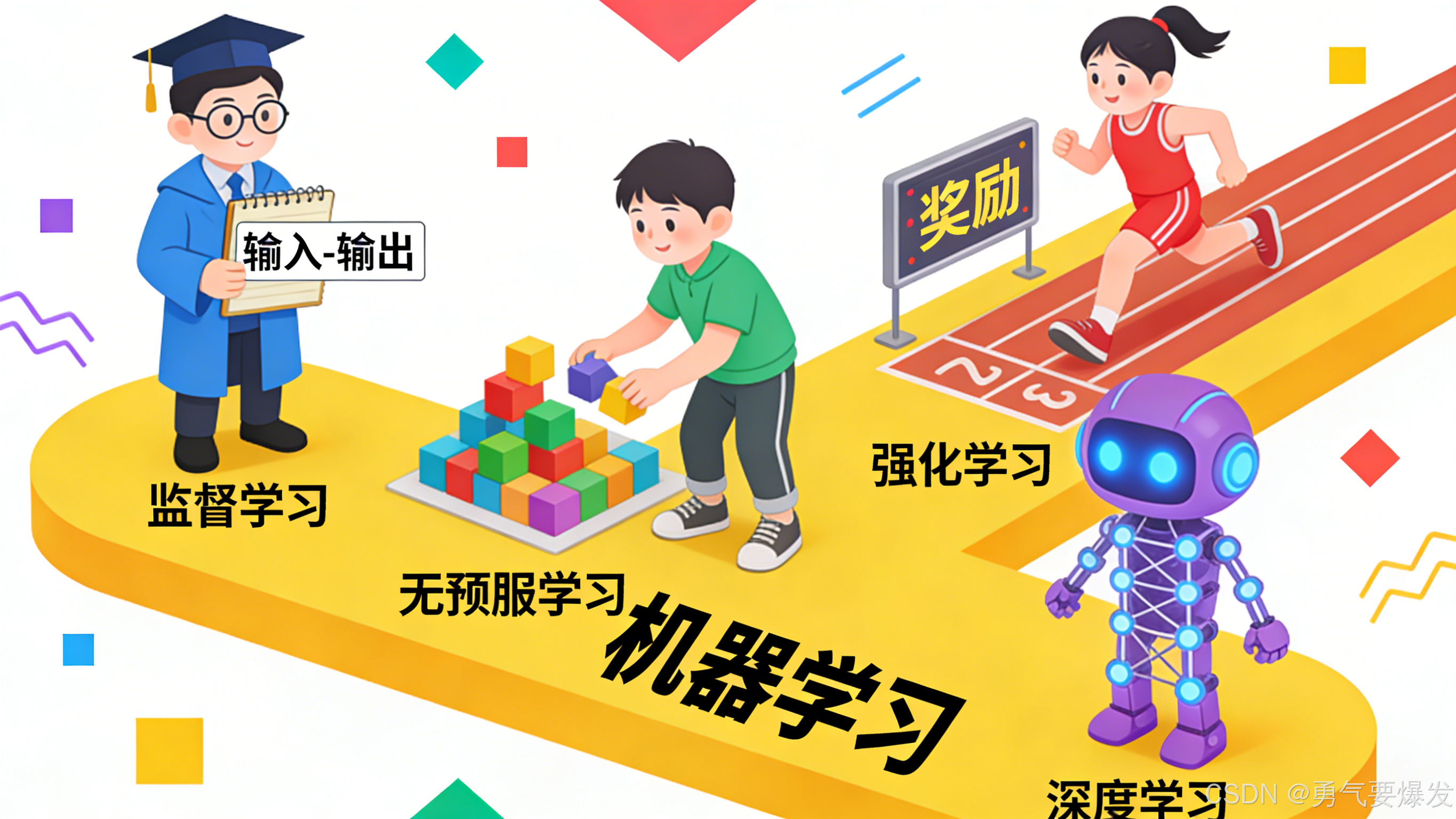
📚 2. 机器学习的三大流派
机器学习主要分为三种学习方式,我们可以用学生的学习方式来类比。
2.1 监督学习 (Supervised Learning) - "有老师辅导"
类比:老师在课堂上讲题,每道题都给出了标准答案。学生通过练习这些带答案的题目来学习,考试时做新题。
- 特点 :数据带标签 (Label)。即我们既有输入数据 XXX,也有正确答案 yyy。
- 两大任务 :
- 回归 (Regression) :预测一个连续的数值 。
- 例子 :根据房屋面积、地段预测房价(输出是具体的金额)。
- 分类 (Classification) :预测一个离散的类别 。
- 例子 :判断邮件是垃圾邮件 还是正常邮件(输出是类别标签)。
- 回归 (Regression) :预测一个连续的数值 。
2.2 无监督学习 (Unsupervised Learning) - "自习/探索"
类比:老师给了一堆古文,但没给翻译和注释,让学生自己去发现其中的规律(比如哪些字经常一起出现,文章的风格分类)。
- 特点 :数据不带标签 。只有输入 XXX,没有答案 yyy。机器需要自己从数据中找结构。
- 常见任务 :
- 聚类 (Clustering) :把相似的东西分到一组。
- 例子:电商平台根据用户的购买记录,自动把用户分成"价格敏感型"、"品质追求型"等群体。
- 降维 (Dimensionality Reduction):把复杂的数据变简单,保留主要特征。
- 聚类 (Clustering) :把相似的东西分到一组。
2.3 强化学习 (Reinforcement Learning) - "训练宠物"
类比:训练狗狗。做对了给骨头(奖励),做错了打屁股(惩罚)。狗狗通过不断尝试,学会了怎么做能得到最多的骨头。
- 特点 :通过与环境交互,根据奖励/惩罚来优化策略。
- 例子:AlphaGo下围棋、自动驾驶。
🔑 3. 核心术语与实战概念
3.1 训练集、验证集与测试集
生活类比:
- 训练集 (Training Set) = 课本例题。平时上课用来学习知识的。
- 验证集 (Validation Set) = 模拟考试。学完一章后用来调整学习方法,看看自己掌握得怎么样的。
- 测试集 (Test Set) = 高考。最后一次真正的考核,考完才知道最终水平,且不能再改了。
黄金法则 :千万不能让模型在训练的时候看到测试集的数据!(否则就是作弊,平时满分,高考挂科)。
3.2 代码实战:如何切分数据集
在 Scikit-learn 中,我们通常使用 train_test_split。
python
import numpy as np
from sklearn.model_selection import train_test_split
# 1. 模拟生成 100 条数据
# X 是特征 (比如:学习时长, 刷题量)
# y 是标签 (比如:考试分数)
X = np.random.rand(100, 2)
y = np.random.rand(100)
# 2. 切分数据集
# test_size=0.2 表示 20% 的数据用来考试(测试集),80% 用来学习(训练集)
# random_state=42 是为了保证每次切分的结果一样 (42是程序员的宇宙终极答案)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"原始数据量: {len(X)}")
print(f"训练集数据量: {len(X_train)} (用于学习)")
print(f"测试集数据量: {len(X_test)} (用于评估)")3.3 过拟合 vs 欠拟合
这是机器学习中最头疼的两个问题。
生活类比:
- 欠拟合 (Underfitting) = 学渣。书没看懂,例题做不对,考试也挂科。模型太简单,抓不住数据的规律。
- 过拟合 (Overfitting) = 书呆子/死记硬背。把课本上的例题连标点符号都背下来了(在训练集上表现完美),但是稍微变一下题目就不会了(在测试集上表现很差)。泛化能力弱。
- 刚刚好 (Good Fit) = 学霸。理解了原理,举一反三。
图解:
欠拟合 刚刚好 过拟合
(直线拟合曲线) (曲线拟合曲线) (乱七八糟的折线)
📉 📈 📊
太简单 完美 太复杂3.4 偏差-方差权衡 (Bias-Variance Tradeoff)
- 偏差 (Bias):模型预测值与真实值的差异。(偏差高 = 欠拟合,瞄都不准)
- 方差 (Variance):模型在不同训练集上表现的波动。(方差高 = 过拟合,发挥极其不稳定)
我们追求的是:低偏差 + 低方差。但这很难,通常需要权衡。
🎯 总结
核心概念
- ✅ 监督学习:有标签,预测数值(回归)或类别(分类)。
- ✅ 无监督学习:无标签,发现数据结构(聚类)。
- ✅ 数据集划分:训练集(学习)、测试集(考试),严禁作弊。
- ✅ 过拟合:死记硬背,泛化能力差。