1、了解大模型
- 大模型爆发背景:以ChatGPT为代表的大模型是2023年以来全球科技界焦点,创造用户增长纪录,引发"百模大战",推动AI进入2.0时代;其爆发关键在于应用层能提供实际价值、贴近普通人且使用门槛极低(仅需通过Prompt交互)。
- 大模型核心特征:属于生成式AI,区别于传统决策式AI,更擅长推理与创造,可生成文本、图片等AIGC内容;底层依赖复杂深度学习与神经网络,但应用层呈现简洁交互形式。
- 大模型应用进化 :
- 个人领域(To C):覆盖对话机器人、精准搜索、翻译、文档创作/辅助阅读、虚拟角色扮演、多模态创作、代码辅助生成等,以独立工具或AI Copilot形式存在;
- 企业领域(To B):逐步探索智能客服、在线咨询、智能营销、交互式数据分析等场景,部分处于原型验证阶段;
- 形态升级:从简单对话机器人,进化为具备自我规划、记忆、使用外部工具、自省纠错能力的AI智能体(AI Agent)。
- 大模型固有缺陷:并非无所不能,存在知识时效性差(训练数据滞后,无法回答超训练时间点问题)、"黑盒子"难以解释(内部推理过程不可观察,调试困难)、输出不确定性(受temperature等参数影响,结果随机性强)、"幻觉"(编造错误信息,尤其垂直领域/企业私有知识场景)四大核心问题,这些缺陷也推动了RAG等优化方案的诞生。
2、RAG简介
RAG是"检索增强生成"的缩写,是一种结合外部数据检索 和大模型生成的技术:
- 基础逻辑(简单版):先从外部数据(文档、数据库等)里检索与问题相关的信息,再把这些信息传给大模型,让它基于这些信息生成回答,以此解决大模型"知识过时""容易胡说(幻觉)"的问题。
- 复杂度差异 :
- 原型阶段很简单:用低代码平台/开发框架(比如LlamaIndex),几分钟就能搭出演示应用;
- 生产阶段很复杂:企业级场景要面对数据多样、检索不准、响应慢等问题,需要做大量优化。
3、LlamaIndex框架是什么?
LlamaIndex是一个专注于RAG(检索增强生成)场景的大模型应用开发框架,核心是帮开发者更高效地将外部数据(文档、数据库等)与大模型结合,快速搭建RAG应用。
它的特点是:
- 轻量易上手:学习门槛低于LangChain,对RAG场景的适配性更强;
- 组件封装完善:内置文档加载、分割、向量存储、索引构建、查询引擎等RAG全流程组件;
- 扩展性强:支持对接各类大模型、向量库、嵌入模型,可满足企业级个性化需求。
还有哪些同类框架?
主流的大模型应用开发框架(尤其适配RAG)还有:
- LangChain
- 特点:组件生态最丰富,不仅支持RAG,还覆盖智能体、多工具链等场景;但功能复杂,学习成本较高。
- AutoGen
- 特点:主打"多智能体协作",适合构建多角色交互的复杂应用,也可结合RAG实现数据增强。
- FastGPT
- 特点:低代码/无代码工具,内置RAG流程模板,适合快速搭建简单知识类应用,但灵活性较弱。
4、为什么需要RAG?
结合文章内容,需要RAG的核心原因是解决大模型本身的缺陷 ,具体如下:
大模型虽然具备强大的自然语言生成能力,但存在几个关键问题:
- 知识时效性差:大模型的训练数据是固定的,无法获取训练后更新的信息;
- 易产生"幻觉":会编造不存在的内容,尤其是专业领域知识;
- "黑盒子"属性:输出结果的依据不透明,难以解释;
- 上下文窗口有限:无法处理超长文本的完整信息。
而RAG通过"检索外部数据+增强大模型生成"的模式,能直接补充实时/专业知识、减少"幻觉"、让回答更可追溯,同时突破大模型自身的知识与上下文限制。
RAG 的基本思想可以简单表述如下 :将传统的生成式大模型与实时信息 检索技术相结合,为大模型补充来自外部的相关数据与上下文,以帮助大模型 生成更丰富、更准确、更可靠的内容。这允许大模型在生成内容时可以依赖实 时与个性化的数据和知识,而不只是依赖训练知识。
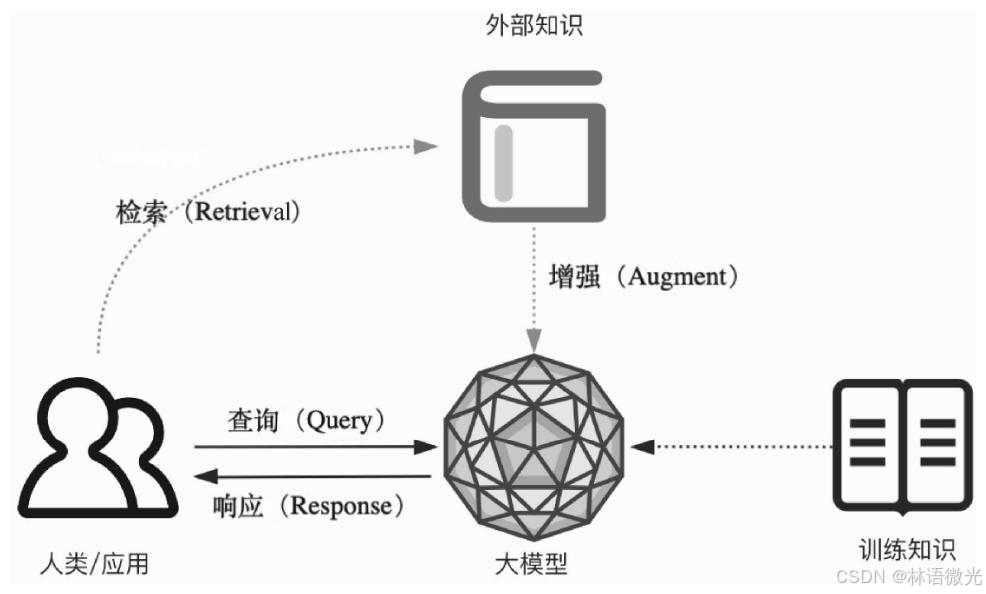
4.1、RAG的经典流程
在了解了RAG 的一些基本概念与简单的应用场景后,我们从技术层来看 一个最基础、最常见的RAG 应用的逻辑架构与流程。注意:下面这张图中仅展示了一个最小粒度的RAG 应用的基础原理,而在当今的实际RAG 应用中,对于不同的应用场景、客观条件、工程要求,会有更多的模块、架构 与流程的优化设计,在后面的内容中将会进一步阐述。
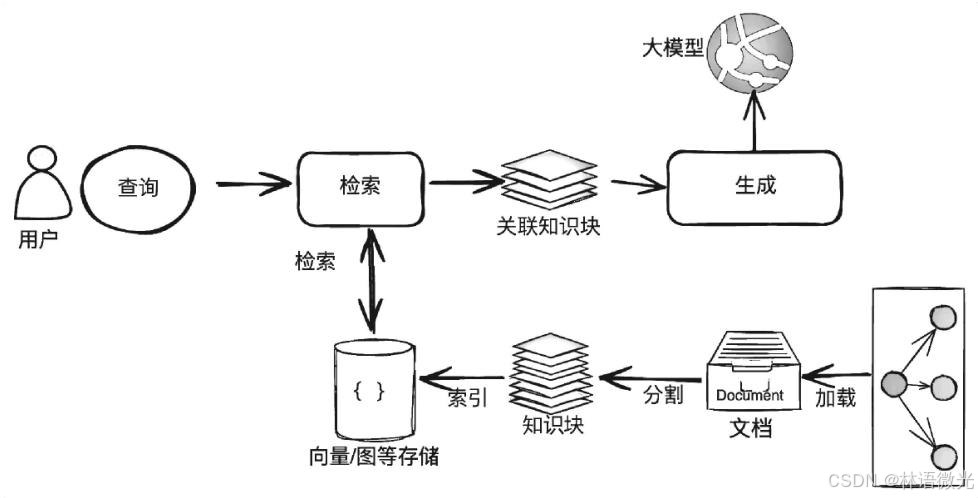
通常可以把开发一个简单的RAG 应用从整体上分为**数据索引 (Indexing)与 数据查询(Query)**两个大的阶段,在每个阶段都包含不同的处理阶段。
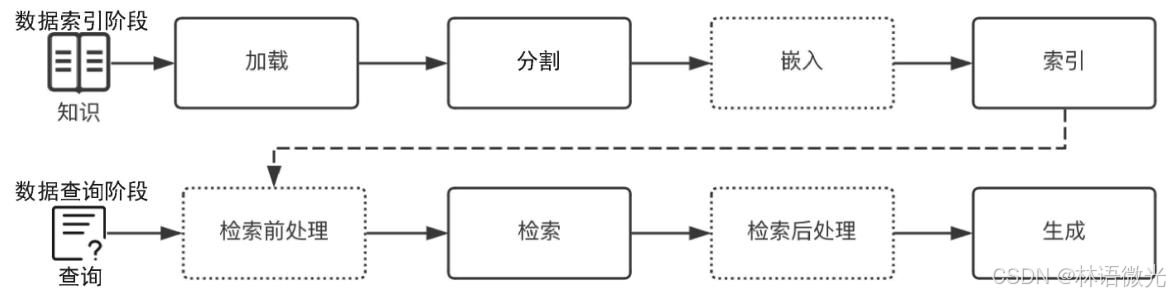
4.2、数据索引阶段
数据索引阶段是RAG应用的"知识储备环节",核心是将原始数据转化为可高效检索的格式,为后续查询打基础,核心流程为"加载→分割→嵌入→索引"四步:
- 数据加载 :读取本地文档、网络数据、数据库等多源数据,统一转为
Document对象,同时生成基础/自定义元数据; - 数据分割 :按语义或规则将文档拆为合适粒度的知识块,通过
chunk_size(知识块token数)和chunk_overlap(重叠token数)平衡语义完整与检索精准; - 数据嵌入:用嵌入模型(云端如OpenAI模型、本地如BGE模型)将知识块转为向量,且索引与查询阶段需用同一模型;
- 数据索引 :将"向量+知识块+元数据"存入索引库,常见索引类型有向量存储索引(核心)、文档摘要索引、知识图谱索引等。
该阶段需应对知识块粒度、数据去重更新、多模态处理等挑战,处理质量直接影响后续检索精准度。
4.3、数据查询阶段
数据查询阶段是RAG应用的"知识调用与生成环节",核心是基于用户查询从索引库中精准获取相关知识,并借助大模型生成答案,核心流程包含两大核心阶段(检索、生成)及优化阶段(检索前处理、检索后处理):
- 检索(Retrieval):依托数据索引阶段构建的索引(如向量索引),从存储库(向量库等)中检索与用户查询语义相关的知识块,按相关性排序后输出(通常取top_K个),为生成阶段提供参考上下文;
- 生成(Generation):以大模型为核心(本地部署或云端调用),结合用户原始查询与检索出的相关知识块,通过设计的Prompt生成最终答案并输出;
- 优化阶段:部分优化的RAG流程会增加检索前处理(如查询转换、扩充,提升检索精准度)与检索后处理(如知识块重排序、过滤无效信息,优化生成质量)。
5、RAG面临的挑战
RAG应用在实际落地(尤其是企业级场景)中主要面临5大核心挑战,具体如下:
-
检索召回精确度不足
RAG的核心是通过检索补充外部知识,若检索出的知识块携带大量无用、噪声数据或矛盾信息(如自然语言歧义导致语义匹配偏差),会直接影响大模型生成质量,无法为后续生成提供有效支撑。
-
大模型抗干扰能力弱
检索出的上下文可能包含干扰、多余或矛盾信息,而大模型需准确识别、区分这些无效内容,并严格按Prompt指令基于有效知识生成答案,若模型自身理解与筛选能力不足,会导致输出偏离预期。
-
大模型上下文窗口限制
大模型存在输入token数量上限(即上下文窗口限制),若需从大规模知识库中检索大量相关知识块,可能超出窗口容量导致失败,如何在有限窗口内携带"最有价值知识块"是关键难题。
-
RAG与微调的选择困境
模型微调是另一种优化大模型领域适配性的方案,与RAG相比,微调将知识融入模型训练过程,简化应用架构,但需额外数据与算力成本;RAG灵活度高但依赖检索精度,开发者需根据业务场景(如知识更新频率、成本预算)权衡选择,存在决策难度。
-
响应性能与延迟矛盾
相较于大模型直接生成,RAG增加了"检索-前处理-后处理"等步骤,且复杂RAG范式(如多轮迭代优化)会进一步增加处理环节,导致端到端响应延迟升高,在企业级低延迟需求场景(如实时客服)中,如何平衡"生成质量"与"响应速度"成为挑战。
6、RAG应用架构演进小结
RAG范式与架构随技术发展和场景需求迭代,核心分为3个阶段,整体呈现"从简单顺序流程到灵活模块化组合"的演进逻辑,具体如下:
-
第一阶段:Naive RAG(朴素/经典RAG)
是最早的基础架构,遵循"索引→检索→生成"3个核心模块的顺序流程,仅保留最简单的执行节点,无额外优化环节,适用于原型演示或简单知识问答场景,但面对复杂业务需求时灵活性与性能不足。
-
第二阶段:Advanced RAG(高级RAG)
在Naive RAG基础上增强核心阶段,重点优化检索环节------新增"检索前处理"(如查询转换、扩充以提升检索精准度)与"检索后处理"(如知识块重排序、过滤无效信息以优化生成质量),进一步提升检索召回精度与生成可靠性,更适配中低复杂度的企业级场景。
-
第三阶段:Modular RAG(模块化RAG)
突破前两阶段的链式顺序流程,采用"模块类-模块-算法"的分层设计:将RAG流程拆解为预检索、检索、生成等核心模块类,每个模块类下包含多个功能模块(如预检索中的"查询转换"模块),每个模块又支持多种算法实现(如查询转换可通过普通重写、HyDE重写等算法完成)。
其核心优势是高灵活性与扩展性 :开发者可根据业务场景(如多模态文档处理、复杂推理需求)灵活组合模块与算法,构造个性化RAG工作流,能应对复杂多变的企业级需求。
此外,2020年Meta首次提出RAG概念,2022年ChatGPT推动RAG研究聚焦"解决大模型幻觉",2024年随先进大模型(如GPT-4、Gemini Pro)应用,更多优化理论(如RAG与微调结合、迭代自省流程)涌现,推动架构向模块化、精细化方向发展。
7、RAG与微调的选择
该部分核心围绕"如何为大模型增强生成能力选择方案"展开,先明确两者本质差异,再通过对比与场景划分提供选择依据,具体如下:
一、大模型微调基础认知
微调是对大模型(基座模型)在少量标注数据上二次训练,分"受监督微调+RLHF(基于人类反馈的强化学习)"阶段,核心是让模型"记住"特定领域知识或适配任务(如情感检测、行业术语理解)。其特点是:需额外数据准备(采集、清洗、标注)、算力与技术成本(需ML专家),但优化后模型可直接输出领域相关结果,推理时token消耗低。
二、RAG与微调核心差异(类比理解)
- RAG:类似"考试时给学生一本参考书",需实时检索外部知识辅助回答,无需改变模型本身,知识更新灵活(更新参考书即可);
- 微调:类似"考试前给学生针对性辅导",将知识融入模型,考试时无需额外参考,但知识更新需重新辅导(再次微调)。
三、RAG与微调优劣势对比
| 维度 | RAG | 微调 |
|---|---|---|
| 优点 | 1. 灵活:可随时调整Prompt适配需求;2. 技术简单:无需复杂训练流程;3. 知识适配快:新增知识只需更新检索库;4. 无额外训练成本 | 1. 模型自带领域能力:输出更贴合场景,无需实时检索;2. 下游使用简单:调用时无需携带大量上下文;3. 推理成本低:节省token消耗 |
| 缺点 | 1. 受大模型上下文窗口限制;2. 连续对话中上下文管理难;3. 高准确性场景失败概率高;4. 推理时需携带长Prompt,成本高;5. 模型迭代可能需重新调整Prompt | 1. 非开箱即用:需数据、算力、技术投入;2. 知识更新慢:新内容需重新微调,不适用于实时知识;3. 无法完全避免"幻觉",过度微调可能导致模型能力下降;4. 需专业人员(ML、数据专家)支持 |
四、选择建议
- 优先选RAG的场景:多数通用场景(如企业知识库问答、实时信息查询),尤其知识动态更新(如产品迭代快)、成本敏感、无专业技术团队的情况;
- 优先选微调的场景:①需注入大量稳定领域知识(如医疗、法律专业知识),且知识更新周期长;②关键任务需极高准确率(如医疗诊断、精准数据分析);③用RAG、Prompt工程后仍无法达业务目标(如指令理解偏差、输出稳定性差)。
此外,"两者融合是未来方向"------可通过微调让模型更擅长"使用RAG检索结果",或用RAG辅助生成微调数据,兼顾灵活性与准确性。
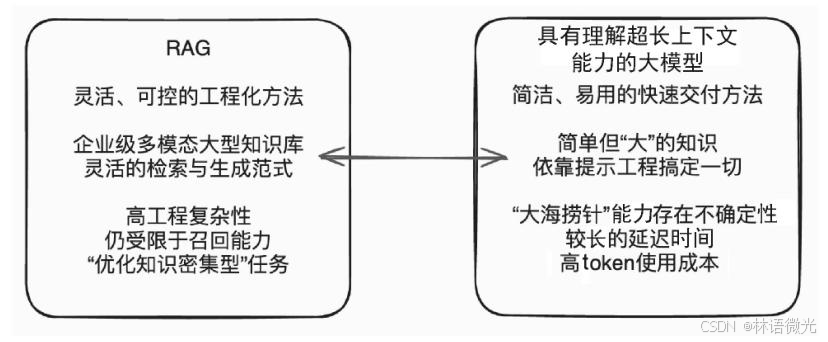
8、RAG与具有理解超长上下文能力的大模型小结
超长上下文大模型和RAG"两者需互补而非替代",具体内容如下:
一、背景:超长上下文大模型的兴起
随着大模型技术发展,上下文窗口从早期4K-8K token大幅扩容(如Claude 3、Gemini 1.5宣称支持1M token),部分模型还具备"大海捞针"能力(在超长上下文中精准定位事实知识),引发"RAG是否可被替代"的争议------有观点认为,若能直接将大量文档塞入模型窗口,外部检索(RAG核心)便无必要。
二、超长上下文大模型无法替代RAG的核心原因
尽管超长上下文模型看似能覆盖更多知识,但从实际应用(尤其企业级场景)的效用、成本、可靠性等维度看,仍存在不可忽视的问题,无法完全替代RAG:
-
上下文窗口仍有局限:1M token虽大,但企业级知识库可能包含数百万文档,无法一次性塞入模型;
-
成本与性能失衡:反复输入超长上下文会显著增加网络传输、推理时间与token成本,性价比低;
-
知识动态更新难题:企业知识实时变化(如产品迭代、政策更新),无法每次都重新输入全部文档;
-
"大海捞针"能力不稳健:测试(如LLMTest_NeedleInAHaystack工具)显示,模型检索精度受上下文长度(2K与128K精度差异大)、知识块位置(文档首尾与中间精度不同)、知识块数量(检索1个与10个精度不同)影响,可靠性不足;
-
复杂任务适配差:知识密集型任务不仅是事实问答,还需多轮推理、跨文档关联,仅依赖模型自身上下文理解难以满足需求;
-
工程化管理困难 :超长上下文导致模型输出溯源、调试、评估更复杂,且企业私有知识直接输入模型存在安全风险。
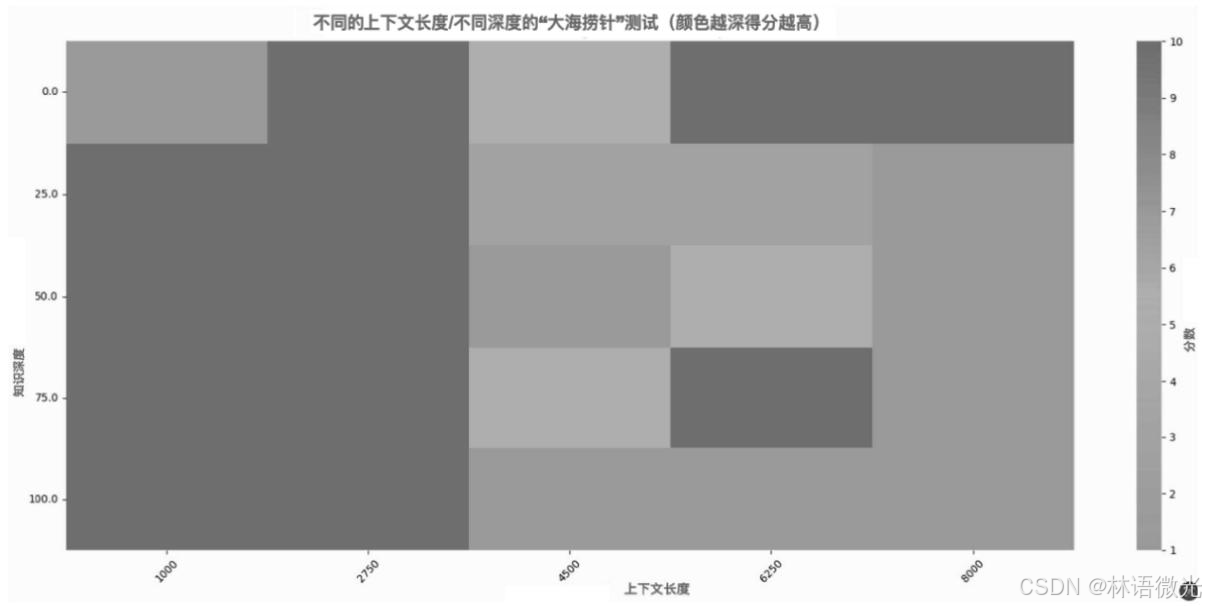
上图是借助 LLMTest_NeedleInAHaystack(开源测试工具) 对大模型"大海捞针"能力(在超长上下文中精准检索事实知识)的测试结果,核心说明当前具有理解超长上下文能力的大模型,其精准检索能力并非绝对可靠,受多因素影响存在明显局限性,具体可结合测试结论拆解:
-
检索精度与上下文长度强相关:图中不同颜色/深度代表不同得分(颜色越深得分越高),能直观看到------当输入上下文长度不同(如2K token vs 128K token)时,大模型精准检索目标知识的得分差异显著,并非上下文越长检索越精准,长上下文场景下精度可能下降。
-
知识块位置影响检索结果:测试显示,目标知识块在超长上下文所处的位置(如文档开头、中间、结尾)会直接影响模型检索效果,部分模型在处理"非首尾位置"的知识块时,得分明显降低,说明其对上下文中间区域的信息捕捉能力较弱。
-
知识块数量增加会降低精度:当需要从超长上下文中检索多个知识块(如1个 vs 10个)时,模型检索准确率会随知识块数量增多而下降,难以同时精准定位多个分散的事实信息。
综上,上图可视化数据佐证了"仅依赖超长上下文大模型无法完全替代RAG"的结论------大模型的超长上下文能力存在局限性,而RAG通过精准检索筛选核心知识的优势,可弥补这一不足,两者需互补协同。
三、两者的最优关系:互补协同
RAG与超长上下文大模型需取长补短,平衡"简洁性"与"灵活性":
- 超长上下文大模型为RAG提供优化基础:未来可将"较大文档"而非"小知识块"作为RAG检索单位,简化分割与索引流程;
- RAG为模型弥补灵活性与可控性短板 :通过精准检索筛选核心知识,避免模型处理冗余信息,同时支持知识动态更新、安全管控,适配企业级复杂需求。