三、Memory(记忆)
Memory组件是LangChain中用于管理和维护对话或交互历史的核心模块,它使 LLM 能够记住之前的交互信息,实现上下文感知的对话
Memory组件主要负责:
-
存储历史对话消息
-
管理上下文信息
-
为后续交互提供记忆能力
-
支持多种记忆
常用的 Memory 类型有以下两种:
ConversationBufferMemory(对话缓冲记忆)
这是最简单直接的记忆方式,也是最传统的,它将所有过去的对话消息原封不动地保存在一个缓冲区(Buffer)里,优点是信息完整,不会丢失任何细节;缺点是对话越长,消耗的 Token 就越多,可能导致成本上升或超出模型的上下文窗口限制,而且最重要的是,这个类只提供了保存和读取对话历史的方法,但不会自动与每次 chain(链)的调用挂钩,所以要手动存储记忆,代码如下:
python
from langchain.memory import ConversationBufferWindowMemory
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core._api import LangChainDeprecationWarning
from my_chat.my_chat_model import ChatModel
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import LLMChain
import warnings
# 过滤掉LangChain的弃用警告
warnings.filterwarnings("ignore", category=LangChainDeprecationWarning)
class CompatibleConversationBufferWindowMemory(ConversationBufferWindowMemory):
@property
def messages(self):
"""
兼容性补丁:将load_memory_variables的结果转换为messages格式
"""
memory_data = self.load_memory_variables({})
return memory_data.get(self.memory_key, [])
def add_messages(self, messages):
"""实现必须的add_messages方法"""
for message in messages:
if isinstance(message, HumanMessage):
self.save_context({"input": message.content}, {"output": ""})
def test1():
# k=3表示存入最近的3次对话
memory = CompatibleConversationBufferWindowMemory(
k=3,
return_messages=True,
memory_key="history" # 明确指定内存键名
)
# 创建一个对象
chat = ChatModel()
llm = chat.get_online_model()
# 创建提示模版 - 这里变量名要和memory_key一致
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有趣的小助手"),
MessagesPlaceholder(variable_name="history"), # 这里使用"history"
("human", "{input}") # 用户的输入
])
# 创建一个chain对象,LLMChain会自动管理memory
chain = LLMChain(
prompt=prompt,
llm=llm,
memory=memory, # LLMChain会自动处理记忆的保存和加载
verbose=False # 设为False避免冗长输出
)
# 直接使用chain,不需要RunnableWithMessageHistory
print("=== 开始对话 ===")
# 提问1
res1 = chain.invoke({"input": "我叫Olivia, 今年21岁"})
print(f"Q1: 我叫Olivia, 今年21岁")
print(f"A1: {res1['text']}\n")
# 提问2
res2 = chain.invoke({"input": "我叫什么名字"})
print(f"Q2: 我叫什么名字")
print(f"A2: {res2['text']}\n")
# 提问3
res3 = chain.invoke({"input": "我今年多大"})
print(f"Q3: 我今年多大")
print(f"A3: {res3['text']}\n")
# 查看历史对话信息
history = memory.load_memory_variables({})
print("=== 完整历史记录 ===")
for i, msg in enumerate(history["history"]):
if isinstance(msg, HumanMessage):
print(f"用户说{i // 2 + 1}: {msg.content}")
elif isinstance(msg, AIMessage):
print(f"AI说{i // 2 + 1}: {msg.content}")
return chain
if __name__ == '__main__':
chain = test1()
# 继续对话
print("\n=== 继续对话 ===")
res4 = chain.invoke({"input": "我们刚才聊了什么?"})
print(f"Q: 我们刚才聊了什么?")
print(f"A: {res4['text']}")运行结果:

RunnableWithMessageHistory(记忆调度器)
RunnableWithMessageHistory 不是存记忆,而是在对话的正确时间,把记忆放进去,再拿出来,解决的是时序问题+隔离问题+自动化问题,功能有:
-
会话管理:将普通的 Chain 包装成支持多会话记忆的组件。
-
隔离会话 :通过
session_id区分不同对话的独立记忆。 -
自动记忆管理:自动调用 Memory 的读取/存储方法。
和 Memory 类的区别如下:
| 对比项 | RunnableWithMessageHistory | ConversationBufferMemory |
|---|---|---|
| 定位 | 中间件 / 调度器 | 具体实现 |
| 多会话 | ✅ 原生支持 | ❌ 很弱 |
| Agent 兼容 | ✅ 官方推荐 | ⚠️ 不稳定 |
| Prompt 控制 | ✅ 完全自己写 | ❌ 框架帮你写 |
| 工程化 | ⭐⭐⭐⭐⭐ | ⭐⭐ |
具体代码示例:
python
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core._api import LangChainDeprecationWarning
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from my_chat.my_chat_model import ChatModel
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
import warnings
warnings.filterwarnings("ignore", category=LangChainDeprecationWarning)
class ModerChatBot:
def __init__(self):
# 创建聊天模型
chat = ChatModel()
self.llm = chat.get_online_model()
# 创建提示模板
self.prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有趣的小助手"),
MessagesPlaceholder(variable_name="history"), #相当于占位符,会被自动替换成历史信息
("human", "{input}")
])
# 创建简单的链(没有memory),此时就是输入 → Prompt → LLM → 输出
self.chain = self.prompt | self.llm
# 会话存储,一个session_id对应一个对话存储
self.session_store = {}
#记忆的仓库管理员
def get_session_history(self, session_id: str) -> BaseChatMessageHistory:
"""获取或创建会话历史"""
if session_id not in self.session_store:
self.session_store[session_id] = ChatMessageHistory()
return self.session_store[session_id]
#给链装上记忆(核心)
def create_conversational_chain(self):
"""创建带历史管理的对话链"""
return RunnableWithMessageHistory(
self.chain, # 简单链
self.get_session_history, # 获取历史的函数
input_messages_key="input",
history_messages_key="history"
)
#一次对话的完整流程
def chat(self, session_id: str, message: str):
"""发送消息到指定会话"""
chain = self.create_conversational_chain()
response = chain.invoke(
{"input": message},
config={"configurable": {"session_id": session_id}}
)
return response.content
def get_chat_history(self, session_id: str):
"""获取指定会话的聊天历史"""
if session_id in self.session_store:
return self.session_store[session_id].messages #调试用接口
return []
def test3():
"""测试多对话系统"""
bot = ModerChatBot()
# 配置会话ID
config_a = {"configurable": {"session_id": "olivia_session"}}
config_b = {"configurable": {"session_id": "david_session"}}
print("=== Olivia的会话 ===")
response1 = bot.chat("olivia_session", "我叫Olivia,今年21岁")
print(f"Olivia: 我叫Olivia,今年21岁")
print(f"AI: {response1}")
response2 = bot.chat("olivia_session", "我叫什么名字?")
print(f"Olivia: 我叫什么名字?")
print(f"AI: {response2}")
print("\n=== David的新会话 ===")
response3 = bot.chat("david_session", "我叫什么名字?")
print(f"David: 我叫什么名字?")
print(f"AI: {response3}") # 应该不知道 说明会话隔离成功
response4 = bot.chat("david_session", "我叫David,25岁")
print(f"David: 我叫David,25岁")
print(f"AI: {response4}")
response5 = bot.chat("david_session", "我多大了?")
print(f"David: 我多大了?")
print(f"AI: {response5}")
print("\n=== 查看历史 ===")
print("Olivia的历史:", [f"{type(m).__name__}: {m.content[:30]}..." for m in bot.get_chat_history("olivia_session")])
print("David的历史:", [f"{type(m).__name__}: {m.content[:30]}..." for m in bot.get_chat_history("david_session")])
if __name__ == '__main__':
test3()运行结果:

可以看到是把两类对话分开的
四、Index(检索)
Langchain 中,Index 检索是从"聊天"迈向"知识系统/RAG/Agent"的分水岭,它是将非结构化文档转化为可检索知识的组件体系,它的目标是解决一个问题:如何让大模型"查资料",而不是"瞎编",Index 组件就通过向量化+相似度检索,让 LLM 在生成答案前,先从外部知识中检索相关内容,这也正是RAG的基础。
Index 整体可拆成四步:原始文档 -> 文档加载 -> 字符分割 -> 向量存储 -> 向量数据库检索,当然这里面的文档来源、分割策略、向量库、检索方式都可以换,Index 是一个可组合系统,不是黑盒,下面就简单看一下这四步:
文档加载
作用是将外部数据源统一转换为 Langchain 的对象,这样的作用是统一数据格式,保留元信息(来源、页码、路径等),为后续切分和溯源提供基础,代码如下:
python
from langchain_community.document_loaders import Docx2txtLoader, CSVLoader, TextLoader, PyPDFLoader, WebBaseLoader
#加载txt文件
def test1():
loader = TextLoader("../data/example.txt", encoding="utf-8")
docs = loader.load()
print(docs)
for doc in docs:
print(doc.page_content)
#加载pdf文件
def test2():
loader = PyPDFLoader("../data/example.pdf")
docs = loader.load()
print(docs)
for doc in docs:
print(doc.page_content)
#加载网页文件
def test3():
loader = WebBaseLoader("https://www.gaokao.com/e/20250604/684012cf1c697.shtml")
docs = loader.load_and_split()
print(docs)
for doc in docs:
print(doc.page_content)
#csv文件
def test4():
loader = CSVLoader("../data/example.csv", encoding="utf-8")
docs = loader.load_and_split() #分词方法有问题
print(docs)
for doc in docs:
print(doc.page_content)
#word文件
def test5():
loader = Docx2txtLoader("../data/example.docx")
docs = loader.load_and_split()
print(docs)
for doc in docs:
print(doc.page_content)
if __name__ == '__main__':
# test1()
# test2()
test3()
# test4()
# test5()首先 Loader 不理解,只负责"读数据",然后不同格式的文档用不同的 Loader 加载,但是最后返回的都是同一种数据结构,也就是 ListDocument,无论加载的是 TXT / PDF / 网页 / CSV / Word
最终都会变成 Document,所以每次读取完后统一写:
for doc in docs:
print(doc.page_content)完全不需要关心原始格式,这也是后续组件都能无缝衔接的前提。
至于每个 Loader 这里就不细讲了,应该都能明白比如 TextLoader 是加载纯文本文件的(记得指定encoding="utf-8"),PyPDFLoader 加载PDF文件等等,重点说一下 WebBaseLoader 和 CSVLoader。
首先 WebBaseLoader 用于加载网页内容,内部会请求网页 -> 提取正文,然后直接拆分,所以用的是 loader.load_and_split() 而不是 loader.load(),因为 Web 数据天然是"长文本 + 杂质多",Loader 通常会和简单切分逻辑绑定使用;至于 CSVLoader,在 docs = loader.load_and_split() 代码后面标注"分词有问题"是因为CSV 本质是结构化数据,每一行并不一定是"自然语言句子",直接按字符切分容易破坏语义,检索效果通常不好,所以在真实的项目中CSV 往往需要自定义 Loader,或转成自然语言描述再送入 Index,苯人这里只是演示。
最后讲一下 load() 和 load_and_split(),前者只加载不切分,后者加载后默认切分,但后者只是便捷方法,实际工程中,切分通常交给独立的 Text Splitter 控制,也就是下一个 "字符分割"。
总之,文档加载阶段的核心价值,不在于"处理文本",而在于将异构数据统一抽象为标准 Document 对象,这使得后续的文本切分、向量化和检索可以完全解耦于数据来源。
字符分割
首先字符分割决定了"模型看到的知识颗粒度",切不好的话后面全白搭,而 Langchain 里最常用的两种切分器是 CharacterTextSplitter 和 RecursiveCharacterTextSplitter,下面用代码来示例:
CharacterTextSplitter
python
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
#字符分割
def test1():
loader = TextLoader("../data/example.txt", encoding="utf-8")
docs = loader.load()
print(docs)
# 文本分割
text = CharacterTextSplitter(
separator="\n", #分割字符 先按换行符切,常用于诗歌或段落清晰的文本
chunk_size=8, #每段分割的最大长度 如果想要把一首七言诗分成两段 要在[17-25]之间 这里的8是分成了四段
chunk_overlap=0, #重叠长度(相邻块不共享内容) 0表示无需重叠
)
#分割文档
docs_split = text.split_documents(docs)
# print(docs_split)
for doc in docs_split:
print("----------------------------------")
print(doc.page_content)运行的结果是:
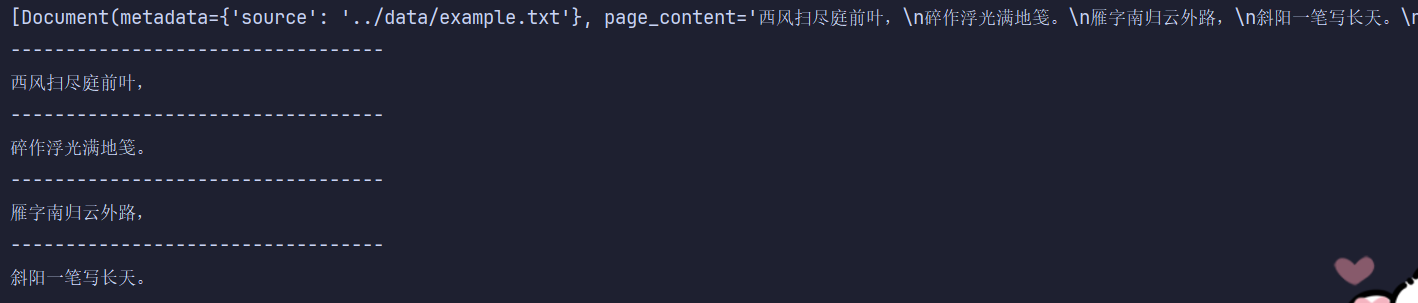
如果把 chunk_size 改为 18,结果就为:

所以,CharacterTextSplitter 的优点是行为完全可预测,性能好,实现简单,但缺点是不理解语义,容易把一句话切断,更适合结构明确、格式稳定的文本
RecursiveCharacterTextSplitter(常用)
python
#递归分割
def test2():
loader = TextLoader("../data/example.txt", encoding="utf-8")
docs = loader.load()
print(docs)
# 文本分割
text = RecursiveCharacterTextSplitter(
# separator="\n", #这里不用设置分割字符因为会自动检测字符
chunk_size=8, #每段分割的最大长度
chunk_overlap=0, #重叠长度 0表示无需重叠
)
#分割文档
docs_split = text.split_documents(docs)
# print(docs_split)
for doc in docs_split:
print("----------------------------------")
print(doc.page_content)这种方法被称为"递归分割","递归"的意思就是尽量用"更自然的方式"切,如果不行,再退而求其次,流程大概是:首先尝试按段落切 -> 按行切(如果还太长) -> 按词切(如果还不行) -> 按字符切(最后兜底),总结就是语义优先,长度兜底,同时这种方法也是RAG的"默认推荐",是 LangChain 中更偏"工程实用"的切分策略,在大多数非结构化文本场景下表现更稳定。
然后解释一下两种方法中都有的步骤:一、docs_split = text.split_documents(docs),这里它不仅是切文本,还复制 metadata(元数据,比如路径、页码、url这些)、保留文档来源信息、每个 chunk 仍然是 Document,这保证了后续可以做来源追溯,这点在RAG里很重要;二、chunk_size / overlap 的设计,chunk_size太小会导致语义破碎,太大会检索不精准,而 chunk_overlap 会防止上下文断裂,但是会增加向量数量和成本,在项目中常见的经验设置是
chunk_size: 200~500
overlap: 20~50
总之,文本切分并不是一个简单的字符串操作,而是在**上下文完整性、检索精度和系统性能之间的权衡,**合理的切分策略,是高质量 RAG 系统的关键前提。
向量存储
向量存储阶段负责将文本知识映射为向量空间中的点,并提供高效的相似度检索能力,是 RAG 系统中"知识可查询化"的关键步骤,到这里为止,知识已经不再是文本,而是"数学意义上的向量",下面用代码示例,以存入txt文件为例:
python
def test_txt():
# 存储txt文件
loader = TextLoader("../data/example.txt", encoding="utf-8")
docs = loader.load()
print(docs)
# 文本分割
text = RecursiveCharacterTextSplitter(
# separator="\n", #这里不用设置分割字符因为会自动检测字符
chunk_size=8, # 每段分割的长度
chunk_overlap=0, # 重叠长度 0表示无需重叠
)
# 分割文档
docs_split = text.split_documents(docs)
#把文档保存到向量数据库中
chat = ChatModel()
#获取向量模型
embedding = chat.get_embedding_model()
chroma = Chroma.from_documents(
docs_split, #文档列表
embedding, #向量模型
persist_directory="../chroma_db", #向量数据库的路径
collection_name="shi", #向量数据库集合名称
collection_metadata={"hnsw:space": "cosine"}
)
print("存入成功!")首先前面的文档加载+切分就不用多说了,直接从 chat = ChatModel() 开始看,
python
#把文档保存到向量数据库中
chat = ChatModel()
#获取向量模型
embedding = chat.get_embedding_model()这里发生的事是每一个切割后的 Document.page_content 都会被送进 embedding 模型,而Embedding 模型负责将自然语言映射到向量空间,使得"语义相近"的文本在向量空间中距离更近,(这里我把 embedding 模型单独封装在 ChatModel 里了,这段代码就不展示了),然后接下来就是向量入库的核心:
python
chroma = Chroma.from_documents(
docs_split,
embedding,
persist_directory="../chroma_db",
collection_name="shi",
collection_metadata={"hnsw:space": "cosine"}
)先解释下 Chroma,Chroma 是一个独立的向量数据库(Vector Database),专门用于存储向量并进行相似度搜索,它就是负责存向量、建索引、做近邻搜索,下面解释参数:
首先 docs_split 和 embedding 就不多说了;persist_directory 就是向量数据的保存地址,这意味着向量数据库是持久化的,程序退出后数据仍然存在下一次可以直接加载,持久化向量库是生产环境 RAG 系统的必要条件;collection_name 非常重要,一个 collection 可以理解为一个知识域,将不同知识库隔离方便做多知识源检索;collection_metadata={"hnsw:space": "cosine"} 表示 使用 HNSW 索引,cosine 表示使用 余弦相似度,在语义检索场景中,余弦相似度通常比欧式距离更稳定。这段代码的运行结果如下:

然后我们再写个查询数据库的函数来验证一下:
python
#查询数据库
def test2():
#链接向量数据库
client = chromadb.PersistentClient(path="../chroma_db")
#查询集合的数据
collections = client.get_collection(name="shi")
# collections = client.get_collection(name="gaokao")
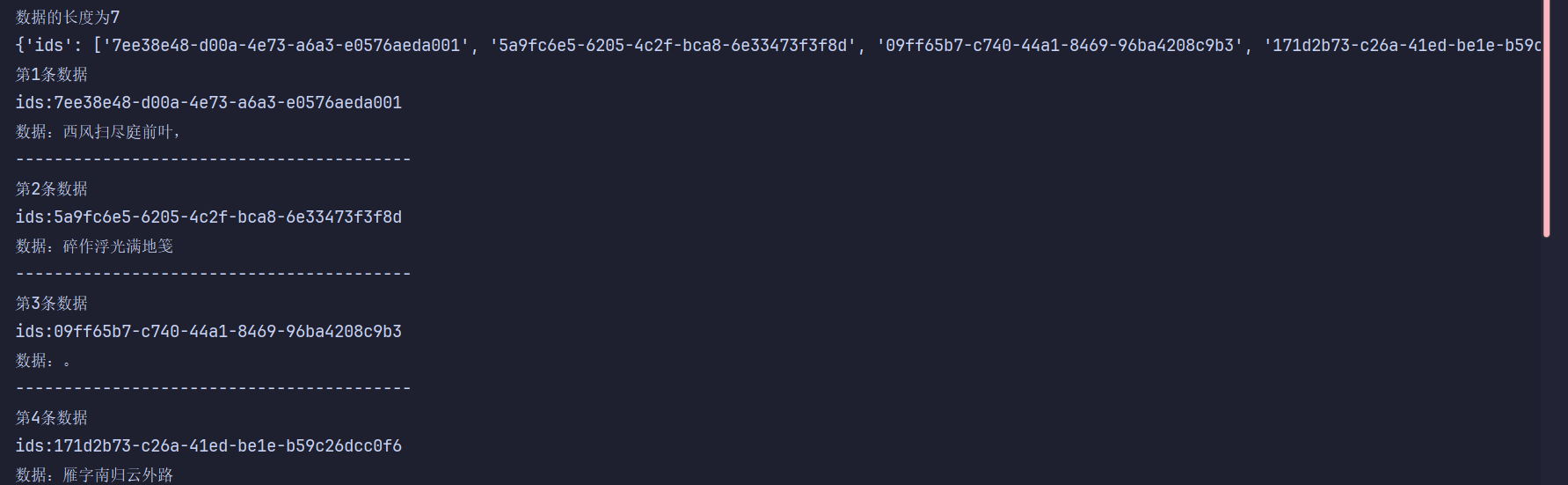
print(f"数据的长度为{collections.count()}")
#获取数据,查询所有数据
data = collections.get()
print(data)
#打印具体数据
for i in range(len(data["ids"])):
print(f"第{i+1}条数据")
print(f"ids:{data["ids"][i]}")
print(f"数据:{data["documents"][i]}")
print("-----------------------------------------")运行结果:
当然还有对数据库的一些操作,比如删除指定数据和删除整个集合:
python
#删除指定数据
def test3():
# 链接向量数据库
client = chromadb.PersistentClient(path="../chroma_db")
# 查询集合的数据
collections = client.get_collection(name="shi")
#删除指定的ids数据
collections.delete(ids="73fcebaa-d980-46c0-94be-554e2dbad774")
print("删除成功!")
#删除所有数据
def test4():
# 链接向量数据库
client = chromadb.PersistentClient(path="../chroma_db")
#删除集合
client.delete_collection(name="gaokao")
print("删除成功!")这里的名字叫gaokao的 collection 是我测试的存储网页HTML弄的集合,运行结果就是显示删除成功。
向量存储阶段不仅是将文本"转成向量",更是构建一个支持语义检索、可维护、可扩展的知识索引系统,合理的切分策略、稳定的 Embedding 模型以及合适的向量库配置,共同决定了 RAG 系统的最终效果。
向量数据库检索
首先要清楚向量数据库检索的本质,是将"用户问题"映射到向量空间中,并找到语义上最接近的文本片段,而不是关键词匹配,到这里为止 LLM 还没开始生成,系统只是在做一件事:帮模型找资料,下面还是代码示例,先来一半:
python
from my_chat.my_chat_model import ChatModel
from langchain_chroma import Chroma
#检索
def test1():
#创建向量模型
chat = ChatModel()
emb_model = chat.get_embedding_model()
#加载已有的集合数据
store = Chroma(
persist_directory="../chroma_db",
embedding_function=emb_model,
collection_name="animal",
collection_metadata={
"hnsw:space": "cosine"
}
)这里依然用的是 Chroma,这里承担的是存储文档向量、构建 HNSW 索引、提供相似度搜索能力,它本身不懂问题,只懂"给我一个向量,我帮你找最像的几个向量",接下来就是核心:
python
# 创建一个检索器
# search_type = "similarity" 表示根据文档的余弦相似度进行查询,k表示返回的文档数量
re = store.as_retriever(search_type="similarity", search_kwargs={"k": 1})
#检索
docs = re.invoke("描述一下猫咪")
print(docs)
print(f"数据类型{type(docs)}")
for x in docs:
print(f"文档来源:{x.metadata['source']}")
print(f"文档内容:{x.page_content}")首先这里的 as_retriever() 是"向量数据库的查询接口抽象",负责把用户问题转化为检索行为,所以 re 它不是数据库也不是模型,而是一个"查询策略对象",后面的 search_type="similarity"表示使用向量相似度搜索,也就是余弦相似度(cosine),在语义检索中,相似度搜索比关键词匹配更能捕捉语义相关性;k=1 就是返回最相似的1个文档 chunk,k小上下文更精,k大信息更全
后面的 docs = re.invoke("描述一下猫咪") ,这里发生了四步隐式流程:
文本问题转入 embedding -> 根据embedding进行Chroma 搜索 -> 通过相似度排序 -> 返ListDocument,最后返回的这个ListDocument会被自动塞进 Prompt 里的上下文材料,但现在模型还没有被调用,我只是在做检索。
最后打印的两行就能体现 metadata 在检索阶段的真正价值了,检索不是智能给模型看,也要能给人看,而 metadata 支持答案溯源、支持可解释性、支持可信 RAG,所以上麦那那段代码的运行结果为:

还有一种方法可以看到模型计算的相似度分数:
python
#查看文档分数 分数越小相似度越高
def test2():
# 创建向量模型
chat = ChatModel()
emb_model = chat.get_embedding_model()
# 加载已有的集合数据
store = Chroma(
persist_directory="../chroma_db",
embedding_function=emb_model,
collection_name="animal",
collection_metadata={
"hnsw:space": "cosine" #hnsw :近似最近邻算法
}
)
#查看提问的问题和文档的相似度得分
docs = store.similarity_search_with_score("解释一下金鱼", k=4)
print(docs)
for x in docs:
print(f"文档来源:{x[0].metadata['source']}")
print(f"文档内容:{x[0].page_content}")
print(f"文档的相似度分数:{x[1]}")
print("------------------------------------------")运行结果:
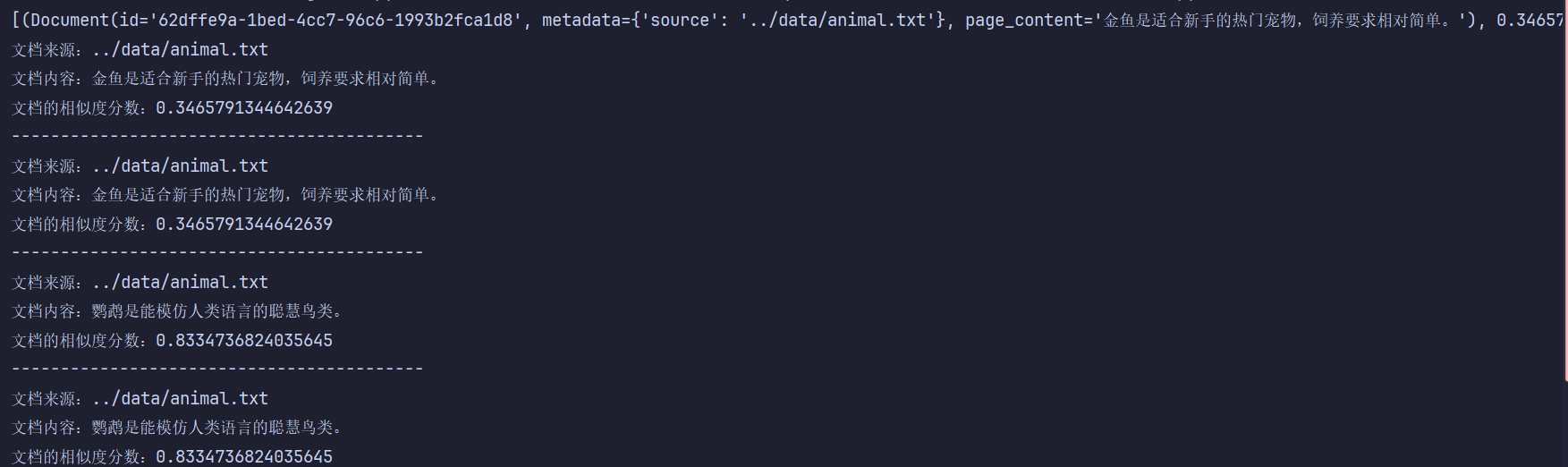
为什么分数越小越相似是因为 Chroma 使用的是距离度量,cosine distance 越小就越相似,而项目中看分数的原因是可以设置相似度阈值(低于就不要)、可以过滤"看起来像但其实不相关"的 chunk等,相似度分数用于衡量问题与文档在向量空间中的距离,是检索结果排序的重要依据。
总之,向量数据库检索阶段并不直接参与答案生成,而是通过语义相似度搜索,为大模型提供最相关的上下文信息。Retriever 作为检索策略的抽象,使得向量存储与查询逻辑解耦,从而构建出灵活、可扩展的 RAG 系统。
好吧由于某些原因现在这里断一下,下篇一定结束langchain。。以上有问题可以指出 (๑•̀ㅂ•́)و✧