前言
大语言模型(如ChatGPT)的"智能"并非一蹴而就,而是通过分阶段的精细化训练逐步实现的。本文基于课程内容,拆解ChatGPT的四阶段构建流程,解析每个环节的核心逻辑与技术细节。 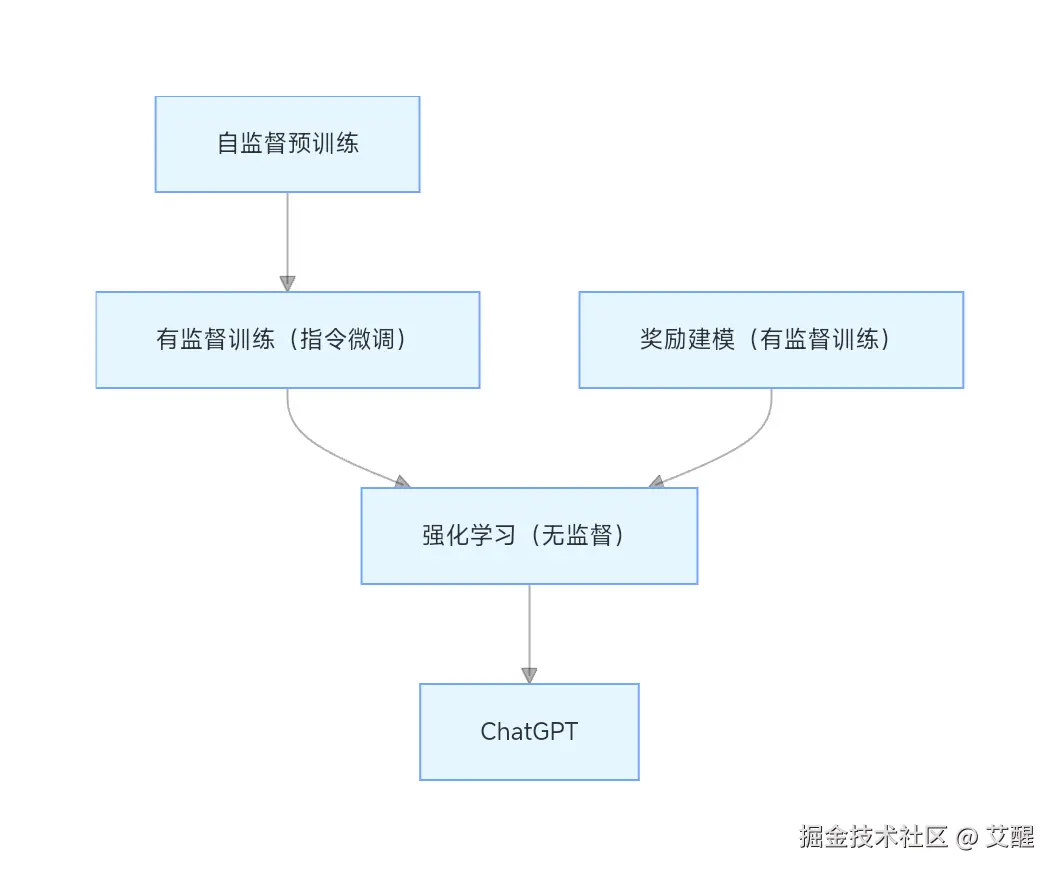
一、阶段一:自监督预训练------给模型"打知识底子"
这是大模型的基础能力奠基阶段,核心是让模型学习语言规律与世界知识。
- 核心思路:利用文本的前k个词(token),预测第k+1个词,实现"自监督学习"(无需人工标注标签)。
- 训练数据:覆盖互联网网页、维基百科、书籍、GitHub代码、论文等多源语料,总量达数千亿至数万亿单词,确保内容的多样性与知识覆盖度。
- 训练目标 :最大化预测概率,数学表达为: Max∑ilogP(ui∣ui−k,...,ui−1;θ) (其中 ui是语料中的词, θ是模型参数)
- 输出与资源 :得到"基础模型",需1000+GPU/月的训练资源。
二、阶段二:有监督微调(指令微调)------让模型"听懂人类指令"
预训练模型能"续写文本",但还不懂"指令";这一阶段的目标是让模型理解人类需求。
- 核心逻辑 :在预训练模型的基础上,用 "用户指令+理想输出"的标注数据 继续训练。
- 训练数据:数万级标注用户指令+对应高质量输出,聚焦开放问题、阅读理解、代码生成等场景。
- 能力提升:模型具备初步的指令理解能力,能完成开放领域问答、翻译、代码编写,还能泛化到未知任务。
- 输出与资源 :得到"SFT模型(有监督微调模型)",需1-100GPU/天的训练资源。
三、阶段三:奖励建模------给模型"立评价标准"
这一阶段的核心是构建"文本质量评估体系",为后续优化提供"奖励信号"。
- 核心目标:训练一个"奖励模型(RM)",用于评估SFT模型输出内容的质量高低。
- 训练方式:人工标注百万级样本------将同一个指令输入SFT模型得到多个输出,由标注人员对这些输出按质量排序,以此训练RM模型。
- 作用:RM模型会成为后续强化学习的"裁判",为模型的输出打分。
- 输出与资源 :得到"RM模型(奖励模型)",需1-100GPU/天的训练资源。
四、阶段四:强化学习------让模型"越答越贴合需求"
这是ChatGPT的最终优化阶段,核心是用奖励信号让模型持续迭代。
- 核心流程 :
- 输入十万级用户指令,让SFT模型生成输出;
- 用RM模型对输出打分(即"奖励");
- 根据奖励结果调整SFT模型的参数,让模型更倾向于生成高分内容。
- 最终输出:经过此阶段训练后,得到最终的ChatGPT模型。
- 资源需求 :需1-100GPU/天的训练资源。
总结:ChatGPT构建的"四步逻辑"
ChatGPT的训练是一个"从基础到优化"的递进过程:
- 预训练:学语言、攒知识 → 基础模型;
- 有监督微调:学指令、懂需求 → SFT模型;
- 奖励建模:定标准、做裁判 → RM模型;
- 强化学习:靠反馈、迭代优 → ChatGPT。
各阶段的数据规模、算法类型、计算资源需精准匹配,才能最终实现模型的"智能表现"。