目录
摘要
本周深入研究了Ego-Exo4D数据集中的手势识别和熟练度评估任务,特别关注了眼视数据处理。手势识别任务需要从第一人称视角预测手部的三维坐标,而熟练度评估则包含两种变体:评估操作者的整体技能水平和评估具体操作的执行质量。通过学习眼视数据的处理流程,掌握了如何将三维眼视方向投影到二维图像平面,并了解了Project Aria工具链的基本使用方法。
Abstract
This week's study delved into hand gesture recognition and proficiency assessment tasks within the Ego-Exo4D dataset, with particular focus on eye gaze data processing. The hand gesture recognition task involves predicting 3D hand joint coordinates from first-person perspective, while proficiency assessment includes two variants: evaluating the operator's overall skill level and assessing the quality of specific operations. By learning the processing flow of eye gaze data, I mastered how to project 3D eye gaze directions onto 2D image planes and understood the basic usage of the Project Aria toolchain.
一、介绍
手势识别任务涉及从自我中心的画面预测摄像机佩戴者首部的三维坐标
自我视角中的框架被提取且不失真,用于训练和评估。对于需要二维手工包围框的基线,我们利用提供的裁剪内在矩阵,将相机坐标中的三维手关节投影到二维图像平面上。 请注意,任务输入不包括深度图、任何来自ego或exo相机的额外视图、相机姿态信息以及IMU或主动距离传感器测量。 我们明确排除此类信息,以促进该方法适用于使用单眼图像进行一般手部姿势估计问题。
二、熟练度估计
这项任务不仅仅能识别一个人在做什么,还旨在推断用户的技能水平。我们考虑两种变体:示范者熟练度估计和示范熟练度估算
1、示范者熟练度估算
目标是估算参与者在任务中的绝对技能水平。

2、示范熟练度估计
目标是对给定任务执行进行细致分析,识别参与者的良好行为并提出改进建议。

请注意,模型输入不包含活动的文字描述/旁白、音频、凝视传感器读数及任何受试者信息,这将大大简化任务,但牺牲了普遍适用性,因为这些信号通常无法用于野外视频。我们认为,这里提出的表述将鼓励基于视频的方法的发展,这些方法(1)不依赖于明确的主题信息,如性别、年龄、族裔等;(2)学习基于视觉线索而非高层次的文本活动描述或声音、眼神等替代方式来评估熟练度。
三、Ego-Exo4D数据集中的凝视
目的:引入凝视数据,并逐步指导如何将眼视重新投射为以自我中心和外在中心的视角。
本教程中,我们介绍了Ego-Exo4D数据集中的凝视数据,并一步步指导如何在Egocentric/Exocentric视角中将3D眼睛凝视投影到二维。
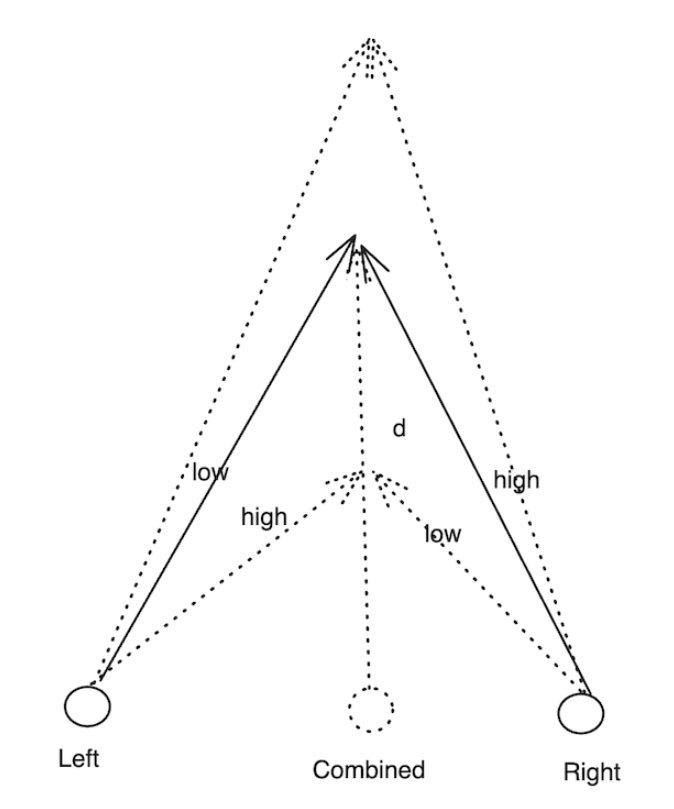
眼视是Ego-Exo4D数据集提供的三维空间信号之一,该数据集由Project Aria的机器感知服务(MPS)预先计算完成。使用者的视线方向被估计为一束向外的光线,锚定在佩戴者眼睛之间。数据集中提供了左右眼的凝视方向(偏航值)以及它们相交的深度(平移值)。汇聚点和距离是根据预测的视线方向推导而来的。合并方向的偏航用于填充EyeGaze对象的偏航场,以实现向后兼容。音高与左右视线和综合视线方向相同。
1、提前条件与导入
在开始之前,我们需要安装必要的库。我们将安装Project Aria Tools的Python包,然后我们导入一些库
python
import numpy as np
from tqdm import tqdm
import os
import json
import re
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
from moviepy import VideoFileClip
import cv2
import math
# project Aria tools
from projectaria_tools.core.calibration import CameraCalibration, DeviceCalibration, KANNALA_BRANDT_K3
from projectaria_tools.core.sophus import SE3
from projectaria_tools.core import mps, data_provider
from projectaria_tools.core.mps.utils import get_gaze_vector_reprojection
from projectaria_tools.core.stream_id import StreamId
from projectaria_tools.core.sensor_data import TimeDomain, TimeQueryOptions
from projectaria_tools.utils.rerun_helpers import AriaGlassesOutline, ToTransform3D2、加载一个采样片段及其VRS和MPS数据
我们将加载一个关于烹饪的拍摄fair_cooking_05_2示例。你需要更改 Ego-Exo4D 数据集的下载目录。如前所述,有些镜头可能基于校准数据进行个性化眼神凝视。我们使用布尔变量来决定是使用一般眼神凝视还是个性化眼神凝视。
python
ego_exo_root = '/datasets01/egoexo4d/v2/' # 替换我们的 Ego-Exo4D CLI 下载目录
take_name = 'fair_cooking_05_2'
ego_exo_project_path = os.path.join(ego_exo_root, 'takes', take_name)
assert os.path.exists(ego_exo_project_path), "Please do update your path to a valid EgoExo sequence folder."
use_general_gaze = True
if not use_general_gaze:
assert os.path.exists(os.path.join(ego_exo_project_path, "eye_gaze", "personalized_eye_gaze.csv")), "personalized eye gaze not exists for this take"
# 查找 aria 编号,例如,aria03.vrs 的 aria_number 为 3
pattern = re.compile(r'aria0(\d+)\.vrs')
for root, _, files in os.walk(ego_exo_project_path):
for file in files:
match = pattern.match(file)
if match:
aria_number = int(match.group(1))我们检索VRS数据,包括Aria眼镜采集的设备校准,并绘制传感器的位置和方向。
VRS:VRS 是用于存储 Project Aria 眼镜多模态数据的文件格式。VRS数据存储在Stream中,并以唯一的StreamId标识。 允许您列出并检索所有VRS数据及校准数据
DeviceCalibration:一个接口,可用于检索图像流数据(即相机数据)的内在数据------以及为所有传感器定义的外在数据
Project Aria眼镜采用3D坐标框架约定。你可以在这里(CPF)找到这些约定的概述,三维坐标系和系统约定也涵盖在内。我们使用 projectaria_tools API 来获取每个传感器的 DeviceCalibration 和 POSE。
首先,我们加载了样本录音的VRS文件。
python
vrs_file_path = os.path.join(ego_exo_project_path, f'aria0{aria_number}.vrs')
print(f"VRS file path: {vrs_file_path}")
assert os.path.exists(vrs_file_path), "We are not finding the required vrs file"
vrs_data_provider = data_provider.create_vrs_data_provider(vrs_file_path)
assert vrs_data_provider, "Couldn't create data vrs_data_provider from vrs file"接下来,我们加载ARIA眼镜的设备校准,以及设备框架中中央瞳孔框的姿态。
python
device_calibration = vrs_data_provider.get_device_calibration()
T_device_CPF = device_calibration.get_transform_device_cpf()我们可以从给定的StreamId获得RGB和SLAM左右流标签。
python
rgb_stream_id = StreamId("214-1")
slam_left_stream_id = StreamId("1201-1")
slam_right_stream_id = StreamId("1201-2")
rgb_stream_label = vrs_data_provider.get_label_from_stream_id(rgb_stream_id)
slam_left_stream_label = vrs_data_provider.get_label_from_stream_id(slam_left_stream_id)
slam_right_stream_label = vrs_data_provider.get_label_from_stream_id(slam_right_stream_id)我们还能从流中获取时间域和图像配置。
python
= TimeQueryOptions.CLOSEST #获取时间域中与查询时间最接近的数据
# 获取给定传感器流 ID 的开始和结束时间
start_time = vrs_data_provider.get_first_time_ns(rgb_stream_id, time_domain)
end_time = vrs_data_provider.get_last_time_ns(rgb_stream_id, time_domain)
# FYI,你可以使用以下方法获取镜像配置
image_config = vrs_data_provider.get_image_configuration(rgb_stream_id)
width = image_config.image_width
height = image_config.image_height
print(f"StreamId {rgb_stream_id}, StreamLabel {rgb_stream_label}, ImageSize: {width, height}")
python
StreamId 214-1, StreamLabel camera-rgb, ImageSize: (1408, 1408)现在让我们从RGB和SLAM左右摄像头中获取流。
python
# 加载 takes.json 注释
takes_info = json.load(open(os.path.join(ego_exo_root, "takes.json")))
# 查看所有拍摄片段以找到采样的片段,即 cmu_bike01_5
for take in takes_info:
if take["take_name"] == take_name: break
# 获取捕获名称,并加载 timesync.csv
capture_name = re.sub(r"_\d+$", "", take_name)
timesync = pd.read_csv(os.path.join(ego_exo_root, f"captures/{capture_name}/timesync.csv"))
start_idx = take["timesync_start_idx"]+1
end_idx = take["timesync_end_idx"]
take_timestamps = []
for idx in range(start_idx, end_idx):
take_timestamps.append(int(timesync.iloc[idx][f"aria0{aria_number}_214-1_capture_timestamp_ns"]))我们可以从 VRS 数据中检索 RGB 图像和 SLAM 图像,并用时间戳可视化来自 RGB、SLAM 左右摄像头的帧。
python
# 我们每100帧抽样1帧以加快可视化
sample_freq=100
sample_frame_num=400
for sample in take_timestamps[:sample_frame_num:sample_freq]:
#获取RGB图像
image_tuple_rgb = vrs_data_provider.get_image_data_by_time_ns(rgb_stream_id, int(sample), time_domain, option)
timestamp = image_tuple_rgb[1].capture_timestamp_ns
# 正在检索SLAM图像
image_tuple_slam_left = vrs_data_provider.get_image_data_by_time_ns(slam_left_stream_id, int(sample), time_domain, option)
image_tuple_slam_right = vrs_data_provider.get_image_data_by_time_ns(slam_right_stream_id, int(sample), time_domain, option)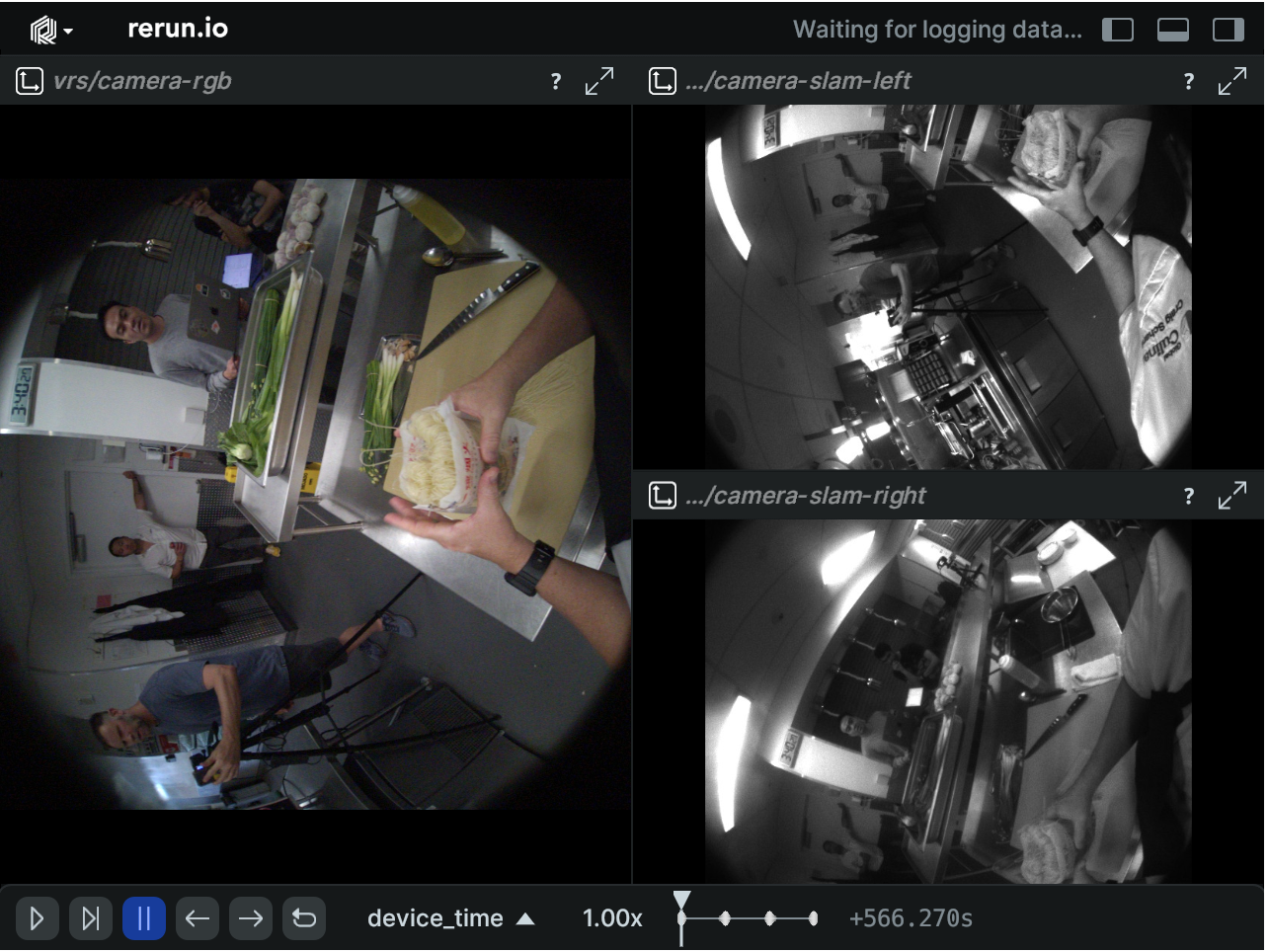
总结
今天的学习让我对第一人称视觉理解任务有了更深入的认识。手势识别不仅要考虑二维图像特征,还要恢复三维空间信息,这比传统的计算机视觉任务更具挑战性。熟练度评估的两个维度很有启发性------既要从宏观上评估一个人的技能水平,又要从微观上分析具体操作的质量。眼视数据的处理部分特别有价值,通过学习Project Aria工具的使用,我理解了如何将传感器数据与视觉信息对齐,这是多模态学习的基础。代码示例展示了完整的处理流程,从数据加载到校准再到投影变换,这些实践知识对我后续处理类似数据很有帮助。