前言
最近我处理了一个离散事件仿真(Discrete Event Simulation,DES)的项目,面临一个经典难题:代码逻辑完全正确,但运行速度慢到令人绝望。
如果按照传统的单机思路,完成一次可靠的蒙特卡洛(Monte Carlo)实验需要到 2026 年才能跑出结果。本文将分享我如何打利用 Kubernetes (K8s) 和 Argo Workflows 构建一套"仿真实验室",实现算力跃升。
核心痛点:为什么"加 CPU"解决不了问题?
在离散事件仿真中,系统的完整性依赖于一个统一的虚拟时钟 和中央未来事件列表(Future Event List, FEL)。
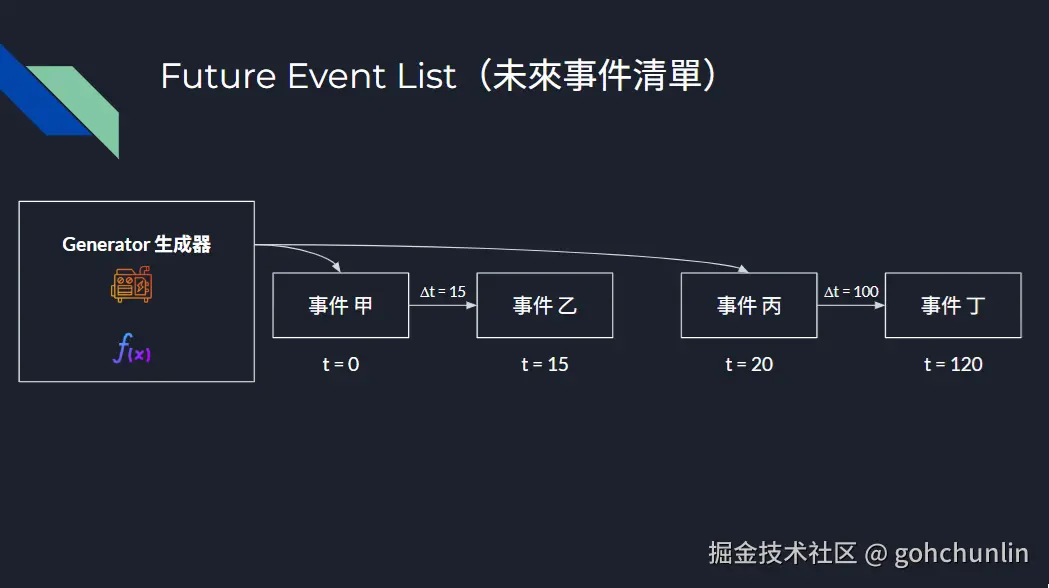
DES 的核心逻辑是严格按时间顺序处理事件。这意味着:
- 你无法将单个仿真任务拆分到多个 Pod 上跑。
- 各节点间的网络延迟会彻底摧毁事件的因果链。
- 结论: 单次仿真任务在架构上是天然单线程的。
虽然我们无法并行化"单个仿真",但我们可以并行化"整个实验"。这是一个典型的 "尴尬并行"(Embarrassingly Parallel) 场景。
架构设计:从"服务器"转向"实验室"
为了解决 5,000 次参数扫频(Parameter Sweeps)的需求,我将 Kubernetes 从一个"托管网站的平台"转化为一台"按需使用的超级计算机"。

执行引擎:Headless .NET 10
底层基于 .NET Console 程序,关键点在于利用 System.CommandLine 建立容器与编排器之间的严格契约。
我们将仿真变量设置为 CLI 参数。
dart
using System.CommandLine;
// 定义根命令
var rootCommand = new RootCommand { Description = "离散事件仿真 CLI 工具" };
// 核心参数:平均到达时间
var meanArrivalSecondsOption = new Option<double>(
name: "--arrival-secs",
description: "Mean arrival time in seconds.",
getDefaultValue: () => 5.0
);
var simpleServerCommand = new Command("simple-server", "运行仿真演示");
simpleServerCommand.AddOption(meanArrivalSecondsOption);
simpleServerCommand.SetHandler((double meanArrivalSeconds) =>
{
// 这里的逻辑是单线程的,但它是可配置的
SimpleServerAndGenerator.RunDemo(loggerFactory, meanArrivalSeconds);
}, meanArrivalSecondsOption);任务编排:Argo Workflows
很多人第一反应是使用原生 K8s Job。但在大规模场景下,原生 Job 太过简陋,难以可视化,且异常处理成本极高。
我选择了 Argo Workflows 。它的杀手锏是 withItems(或 withParam),可以轻松实现扇出(Fan-out):
yaml
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: sna-parallel-experiment-
spec:
entrypoint: sna-demo
templates:
- name: sna-demo
steps:
- - name: run-simulation
template: simulation-job
arguments:
parameters: [{name: arrival-secs, value: "{{item}}"}]
# 核心:定义参数池,Argo 会自动调度成百上千的 Pod 并发执行
withItems: ["5", "10", "15", "20", "25"]
- name: simulation-job
inputs:
parameters: [{name: arrival-secs}]
container:
image: my-registry/sna-demo:latest
args: ["demo", "simple-server", "--arrival-secs", "{{inputs.parameters.arrival-secs}}"]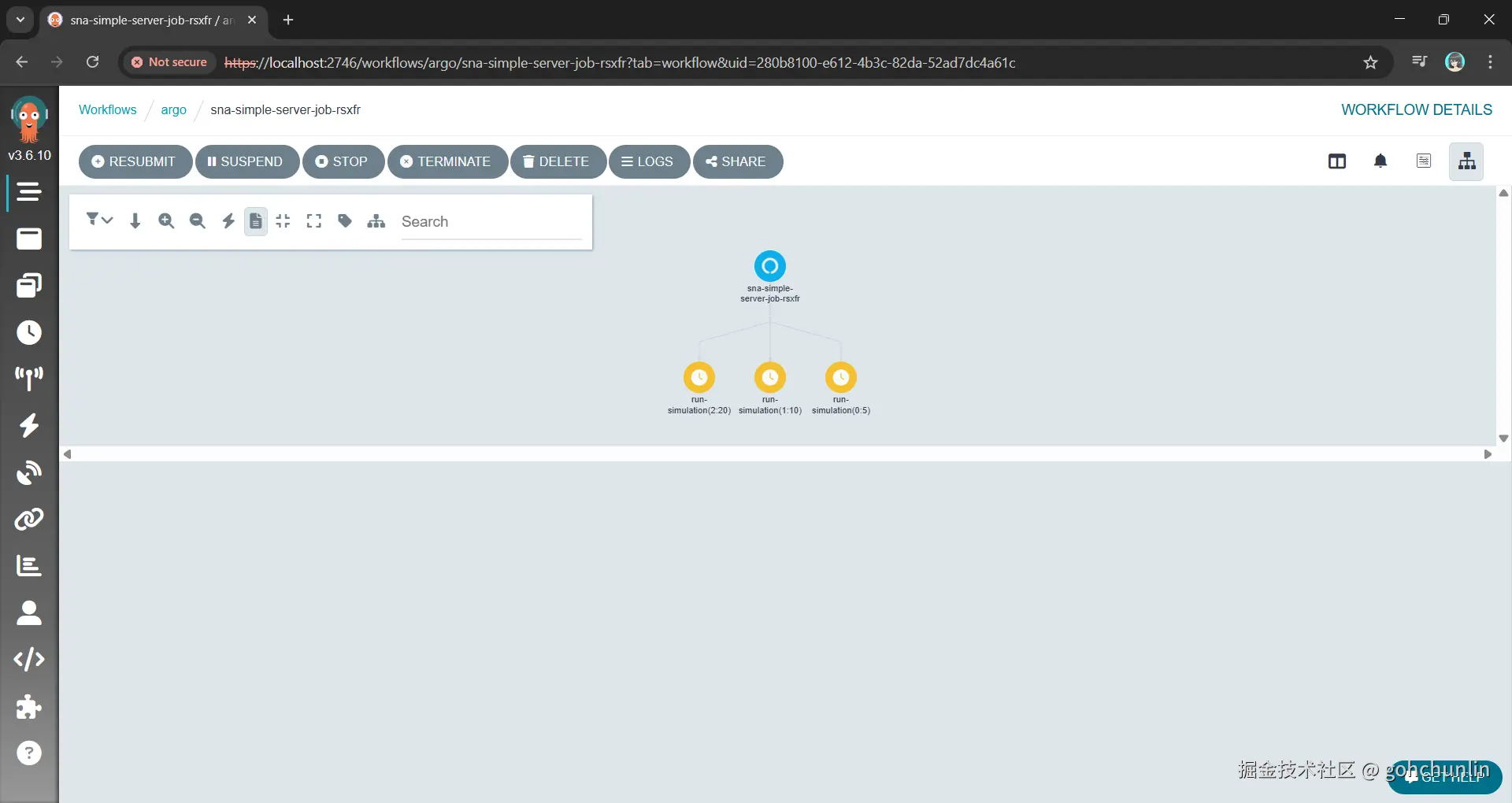
Argo 帮我们处理了节流(Throttling)、并发控制和失败重试,我们只需声明实验目标。
结构化日志
当一千个 Pod 同时运行时,kubectl logs 毫无意义。我们所要面对的是每分钟数大量的文本流。
因此,我们必须弃用纯文本日志,改用 结构化日志 (Structured Logging)。通过 Serilog 将参数和结果绑定为 JSON:
json
{
"Timestamp": "2025-05-20T10:00:00",
"Level": "Information",
"Message": "Simulation Completed",
"Properties": {
"WorkerCount": 5,
"ServiceTime": 12.5,
"Throughput": 0.98
}
}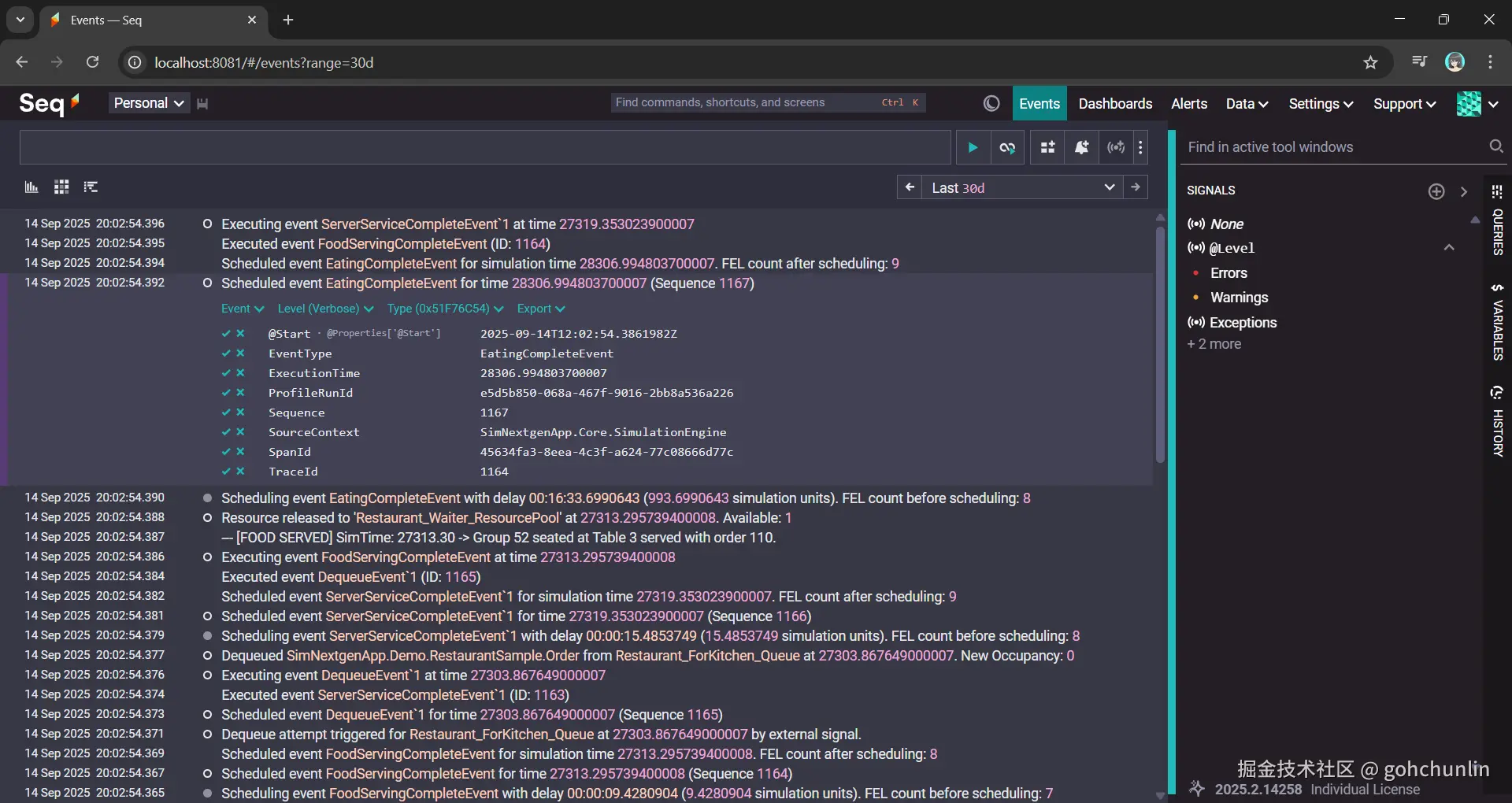
配合 Seq 或 ELK,我们就可以直接通过 SQL 语句在几万份实验结果中精准定位异常点。
实战复盘

在最近的台北 Hello World Developer Conference 2025 上,我也分享了这一模型。通过这套架构:
- 开发效率: C# 核心逻辑无需任何分布式改造。
- 算力利用: 以前单机跑一周的实验,现在在 K8s 集群上 10 分钟内跑完。
- 可维护性: 所有的实验参数都是声明式的,可追溯、可重现。
总结
Kubernetes 的强大不仅在于托管微服务,更在于它处理大规模并发计算的能力。通过将"执行引擎"与"编排大脑"解耦,我们能让老旧的单线程程序在云原生时代焕发新生。
项目开源地址: github.com/gcl-team/SN... (欢迎交流指正)
作者简介:坐标新加坡,20年架构/SRE经验。专注可观测性 (O11y) 与系统稳定性。Grafana & Friends SG 社区主理人。 业余项目:正在开发 SNA。试图用算法模拟高并发场景下的排队论与系统瓶颈(用 AI 辅助构建)。