集成学习的含义:
集成学习是将多个基学习器进行组合, 来实现比单一学习器显著优越的学习性能。
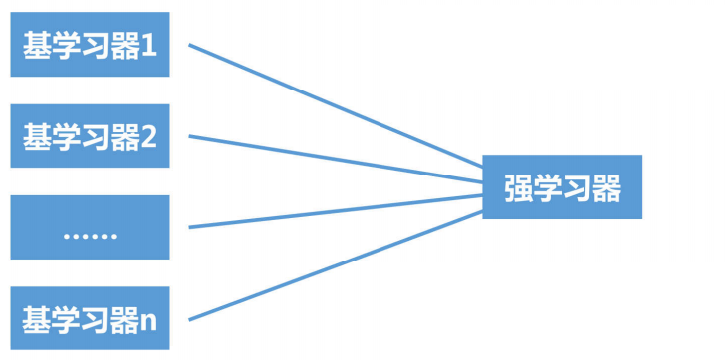
多个相对简单的基学习器(如基学习器1、基学习器2......基学习器n)依次训练,前序基学习器的经验指导后续基学习器聚焦易错处,最终将这些基学习器的能力整合,形成精度与泛化能力更强的强学习器,实现"多个弱学习器合力成强学习器"的效果,像AdaBoost、XGBoost等流行算法都基于此思路设计。
集成学习的代表:
bagging方法:典型的是随机森林
boosting方法:典型的是Xgboost
stacking方法:堆叠模型
XGBoost和随机森林两种集成学习算法
相同点分析
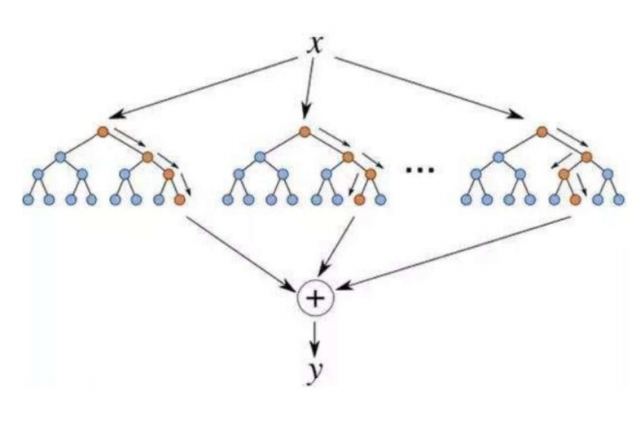
树的组成与结果决定方式:二者均由多棵树构成,并且最终结果都由这些树共同决定。这意味着它们都不是依赖单一决策树进行预测或分类,而是综合多棵树的输出来得到更可靠的结果。
CART树的应用:在使用CART(分类与回归树)树的情况下,它们既可以被用作分类树处理分类任务,也可以作为回归树处理回归任务。这体现了这两种算法在树类型应用上的灵活性。
不同点分析
树的生成方式:随机森林中组成它的树能够并行生成。这使得在训练过程中可以利用多核处理器等硬件资源加速训练过程。而XGBoost是串行生成树的,后一棵树的生成依赖于前面树的结果,相对来说训练速度可能会受到一定影响,但这种串行机制也有助于更好地拟合数据和处理复杂的非线性关系。
结果计算方式:随机森林的结果是通过多数表决得出的。比如在分类任务中,将所有树的分类结果进行统计,得票最多的类别就是最终的预测类别;在回归任务中,通常是对所有树的预测值求平均等方式。XGBoost则是多棵树预测结果的累加之和,这种方式使得它能够不断修正之前树的预测误差,逐步提升模型性能。
对异常值的敏感性:随机森林对异常值不敏感,因为它是基于多个树的集成,在面对少量异常值时,整体的预测结果不会受到太大影响。而XGBoost对异常值比较敏感,异常值可能会在树的构建过程中产生较大影响,进而影响整个模型的性能 。
集成学习的应用:
1.分类问题集成。
2.回归问题集成。
3.特征选取集成。
Bagging 之随机森林
随机森林 (Random Forest):
- 什么是随机森林?
随机森林是一种集成学习(Ensemble Learning)算法。它通过构建并结合多个弱学习器(通常是决策树)来形成一个强学习器,以做出预测或进行分类。与单一的决策树相比,随机森林通过综合多个树的判断结果,通常能够提供更高的准确率、更好的泛化能力和更强的鲁棒性。
- 随机森林的特点?
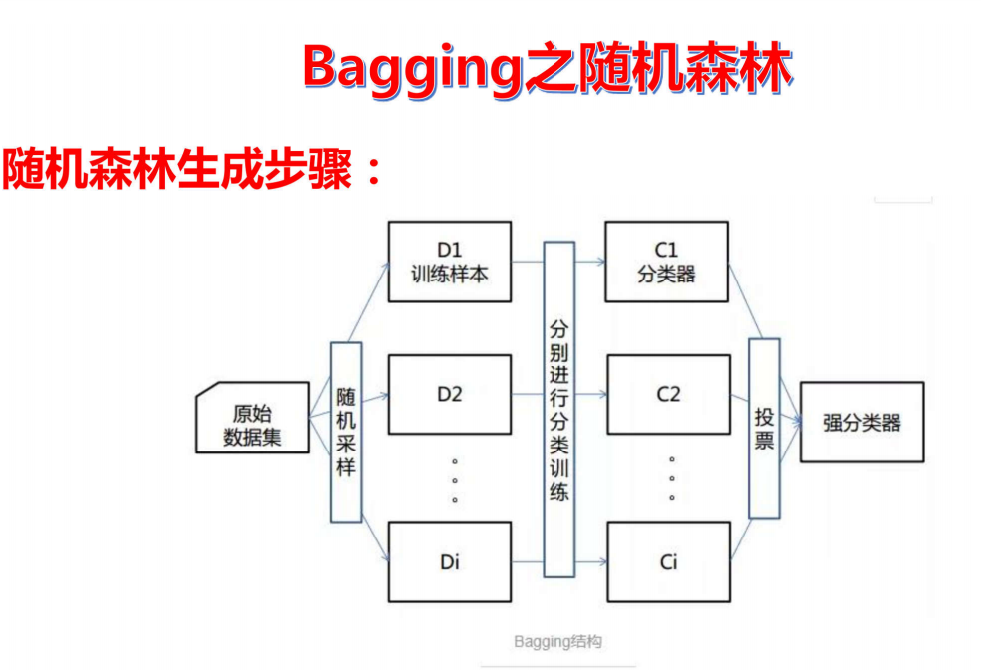
(1) 数据采样随机: 随机森林在构建每一棵决策树时,都会从原始训练集中采用有放回抽样的方式(即Bootstrap抽样)随机选取一个子数据集。这意味着不同的树可能基于略有不同的数据进行训练。
(2) 特征选取随机: 在构建每一棵决策树的每个内部节点(分裂点)时,不会考虑所有的特征,而是从所有特征中随机选取一个特征子集,然后在这个子集中选择最优的特征进行分裂。这增加了树与树之间的多样性。
(3) 森林: "森林"指的是该算法由大量(通常是数百到数千棵)独立的决策树组成。这些树并行构建。
(4) 基分类器为决策树: 随机森林中的每一个"弱学习器"或者说"基分类器"都是一个决策树。最终模型的输出是所有这些决策树输出的某种统计汇总(例如,对于分类问题通常是投票,对于回归问题通常是平均)。
- 为什么使用随机森林?
使用随机森林主要有以下几个原因:
高准确性: 通过集成多棵决策树,随机森林通常能提供比单棵决策树更高的预测准确率。
良好的泛化能力: 由于采用了Bootstrap抽样和特征随机选取,随机森林能有效降低模型的方差(Variance),减少过拟合的风险,从而在新数据上表现更好。
鲁棒性强: 对噪声数据和异常值具有较强的抵抗力。
处理高维数据: 能够有效地处理特征数量很多的数据集。
可以评估特征重要性: 随机森林算法可以很方便地计算出各个输入特征对模型预测结果的重要性排序。
不易过拟合: 尽管每棵树都可能过拟合,但通过平均或投票,整体的预测误差通常会降低。
可扩展性好: 算法相对容易并行化,可以处理大规模数据。
适用于多种任务: 可用于分类、回归、特征选择等多种机器学习任务。
随机森林生成步骤
随机森林优点:
1.具有极高的准确率。
2.随机性的引入,使得随机森林的抗噪声能力很强。
3.随机性的引入,使得随机森林不容易过拟合。
4.能够处理很高维度的数据,不用做特征选择。
5.容易实现并行化计算。
随机森林缺点:
当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大。
随机森林模型还有许多不好解释的地方,有点算个黑盒模型。