Transformer实战(32)------Transformer模型压缩
0. 前言
我们已经学习了如何设计自然语言处理 (Natural Language Processing, NLP) 架构,以利用 Transformer 成功解决实际任务。在本节中,我们将学习如何通过蒸馏、剪枝和量化将训练好的模型转化为高效模型,还将了解模型模型压缩的实际应用。随着大规模神经网络模型的扩展,在有限计算能力下运行大模型变得越来越困难,如何构建高效的模型变得尤为重要。轻量化的通用语言模型(例如 DistilBERT )可以像未蒸馏的模型一样进行微调,并能够获得与未压缩模型相媲美的性能。我们还将简要介绍 bitsandbytes,以实现更高效、更简便的量化。
1. 高效 Transformer 简介
基于 Transformer 的模型在许多 NLP 问题中取得了优异表现,但其代价是平方级的内存和计算复杂度。我们可以将复杂性问题总结如下:
- 由于自注意力机制的复杂度随序列长度呈平方级增长,
Transformer模型在处理长序列时效率较低 - 内存受限的情况下(例如
16GB GPU),模型可以处理512个词元的句子进行训练和推理,但通常无法处理更长的输入序列 NLP模型的规模不断增长,从BERT-Base的1.1亿参数到GPT-3的1750亿参数,再到PaLM的5400亿参数,这种趋势引发了关于计算和内存复杂性的担忧- 还需要关注成本、生产、可重复性和可持续性,因此,我们需要更快速和更轻量的
Transformer,特别是在边缘设备上
为了降低计算复杂性和内存占用,研究人员已经提出了多种方法。除了修改模型架构,还有一些方法在不改变原始架构的情况下,对训练好的模型或训练阶段进行改进。这些方法分为两类:模型压缩和高效自注意力机制。
模型压缩可以通过三种不同的方法实现,每种方法都有不同的压缩方式:
- 知识蒸馏
- 剪枝
- 量化
在知识蒸馏中,通过让一个小型 Transformer 模型(学生模型)学习大型 Transformer 模型(教师模型)的知识。训练学生模型,使其能够模仿教师模型的行为,或者在相同的输入下产生相同的输出。蒸馏后的模型可能在性能上略逊于教师模型,在压缩率、速度和性能之间存在权衡。
剪枝是一种模型压缩技术,旨在通过移除对结果贡献较小的部分来减少模型的大小。最典型的例子是决策树剪枝,它有助于减少模型复杂度并提高模型的泛化能力。
量化将模型权重的类型从较高精度转换为较低精度。例如,大模型通常使用 64 位浮点数 (float64) 表示每个权重,每个权重需要 64 bits 内存,而在量化中可以使用 8 位整数 (int8),每个权重仅需要 8 bits 内存,虽然这会降低数值表示的精度,但显著减少了内存需求。
2. 模型压缩
尽管基于 Transformer 的模型在自然语言处理 (Natural Language Processing, NLP) 中取得了优异的表现,但它们通常存在一个共性问题,模型非常庞大,推理速度不够快。例如,在需要将模型嵌入到移动应用或网页界面等场景中时,直接使用原始模型几乎是不可能的。
为了提高模型的推理速度并减小其规模,研究人员提出了多种技术,主要包括:
- 知识蒸馏 (
Distillation) - 剪枝 (
Pruning) - 量化 (
Quantization)
接下来,我们将分别对这些技术进行详细的分析和介绍。
3. 使用 DistilBERT 进行知识蒸馏
知识蒸馏是指将大型模型(教师模型)的知识迁移到小型模型(学生模型)的过程。教师模型通常规模更大、性能更强,而学生模型则更小、更轻量。这种技术广泛应用于计算机视觉及自然语言处理 (Natural Language Processing, NLP) 领域。下图展示了一个典型的蒸馏实现过程:
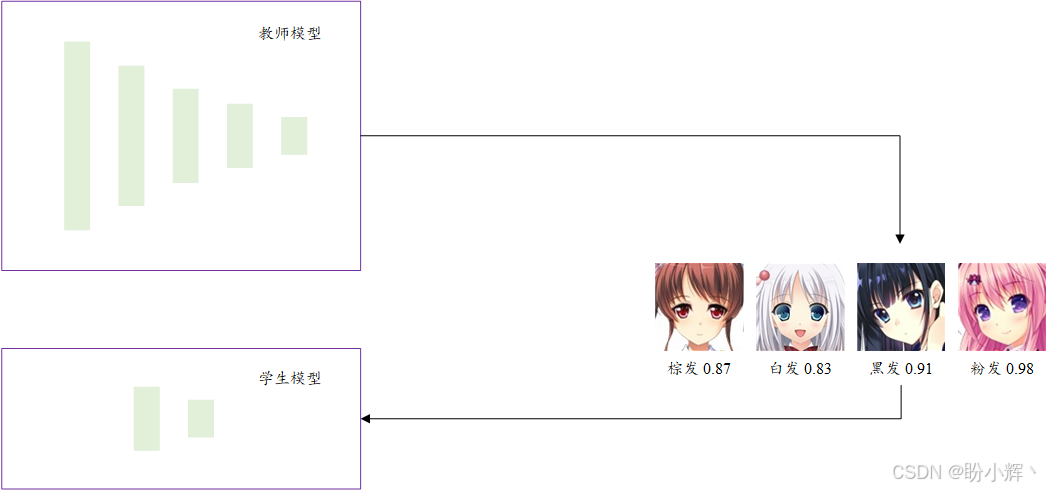
DistilBERT 是高效 Transformer 领域中最重要的模型之一,DistilBERT 模型试图模仿 BERT-Base 的行为,其参数量比 BERT 减少了 50%,但性能达到了教师模型的 95% 以上。与原始 BERT 进行比较:
DistilBERT压缩了1.7倍,速度提升了1.6倍,性能保持97%Mini-BERT压缩了6倍,速度提升了3倍,性能保持98%TinyBERT压缩了7.5倍,速度提升了9.4倍,性能保持97%
(1) 模型蒸馏训练的步骤非常简单,使用 PyTorch 实现蒸馏训练过程:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Optimizer
KD_loss = nn.KLDivLoss(reduction='batchmean')
def kd_step(teacher: nn.Module,
student: nn.Module,
temperature: float,
inputs: torch.tensor,
optimizer: Optimizer):
teacher.eval()
student.train()
with torch.no_grad():
logits_t = teacher(inputs=inputs)
logits_s = student(inputs=inputs)
loss = KD_loss(input=F.log_softmax(
logits_s/temperature,
dim=-1),
arget=F.softmax(logits_t/temperature, dim=-1))
loss.backward()
optimizer.step()
optimizer.zero_grad()这种监督训练方法为我们提供了一个与基础模型行为非常相似的小型模型。训练过程中的损失函数使用 Kullback-Leibler (KL) 散度,确保学生模型能够模仿教师模型,而不会改变最后一层 softmax 输出的决策。KL 散度用于衡量两个分布之间的差异;差异越大,损失值越高。使用该损失函数的目的是让学生模型尽可能完全地模仿教师模型的行为。BERT 和 DistilBERT 在 GLUE 基准测试中的差异仅为 2.8%。
4. 剪枝 Transformer
剪枝是根据预设的标准将某些层中的权重设置为零的过程。该方法会消除那些值较小且对结果影响不大的权重。同样,我们也可以剪枝 Transformer 网络中的一些冗余部分。剪枝后的网络通常比原始网络具有更好的泛化能力。剪枝操作之所以能够成功,是因为剪枝过程保留了真正具有解释性的因素,并丢弃了冗余的子网络,那些权重较小或者移除它们对模型性能影响不大的单元会被移除。
剪枝方法主要分为两种:
- 非结构化剪枝:无论权重位于神经网络的哪个部分,只要其显著性较低(或权重值较小),就会被移除
- 结构化剪枝:剪枝整个注意力头或层
剪枝过程必须与 GPU 兼容,大多数深度学习库(如PyTorch和TensorFlow)都支持剪枝功能。接下来,我们将介绍如何使用 PyTorch 对模型进行剪枝。剪枝有多种不同的方法(基于权重大小或基于互信息),其中最易于理解和实现的方法是 L1 剪枝法。该方法会计算每一层的权重,并将 L1 范数最小的权重置为零,还可以指定剪枝后需要将多少比例的权重设为零。为了更好的理解剪枝,并展示其对模型的影响,我们将使用文本表示模型 Roberta,对模型进行剪枝,并观察剪枝后的表现。
(1) 加载 Roberta 模型:
python
from sentence_transformers import SentenceTransformer
distilroberta = SentenceTransformer('stsb-distilroberta-base-v2')(2) 加载评估所需的度量标准和数据集:
python
from datasets import load_dataset
import evaluate
stsb_metric = evaluate.load('glue', 'stsb')
stsb = load_dataset('glue', 'stsb')
mrpc_metric = evaluate.load('glue', 'mrpc')
mrpc = load_dataset('glue','mrpc')(3) 为了评估模型,使用函数 roberta_sts_benchmark():
python
import math
import tensorflow as tf
def roberta_sts_benchmark(batch):
sts_encode1 = tf.nn.l2_normalize(distilroberta.encode(batch['sentence1']),axis=1)
sts_encode2 = tf.nn.l2_normalize(distilroberta.encode(batch['sentence2']),axis=1)
cosine_similarities = tf.reduce_sum(tf.multiply(sts_encode1, sts_encode2),axis=1)
clip_cosine_similarities = tf.clip_by_value(cosine_similarities,-1.0,1.0)
scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi
return scores(4) 设置标签:
python
references = stsb['validation'][:]['label'] (5) 然后,运行未做任何修改的基础模型:
python
distilroberta_results = roberta_sts_benchmark(stsb['validation']) (6) 完成以上操作后,开始剪枝模型:
python
from torch.nn.utils import prune
pruner = prune.L1Unstructured(amount=0.2)(7) 以上代码通过 L1 范数剪枝方法创建了一个剪枝对象,剪去每一层中 20% 的权重。将剪枝应用于模型:
python
state_dict = distilroberta.state_dict()
for key in state_dict.keys():
if "weight" in key:
state_dict[key] = pruner.prune(state_dict[key]) 迭代地剪枝所有在名称中包含 "weight" 的层,换句话说,对所有包含权重的层进行剪枝,而不会触及偏置层。当然,也可以尝试对偏置层进行剪枝。
(8) 完成剪枝后,重新加载模型的状态字典:
python
distilroberta.load_state_dict(state_dict) (9) 测试剪枝后的模型性能:
python
distilroberta_results_p = roberta_sts_benchmark(stsb['validation']) (10) 为了更好地展示,可视化结果:
python
import pandas as pd
pd.DataFrame({
"DistillRoberta":stsb_metric.compute(predictions=distilroberta_results, references=references),
"DistillRobertaPruned":stsb_metric.compute(predictions=distilroberta_results_p, references=references)
})剪枝后的结果如下所示:

通过剪枝,我们已经移除了模型中 20% 的权重,减少了模型规模和计算成本,但性能仅下降了 4%。剪枝可以与其他技术(如量化)结合使用,以进一步优化模型。
这种剪枝方法应用于每一层中的部分权重,但也可以完全移除 Transformer 架构中的某些部分或层。例如,可以移除一些注意力头,并跟踪性能变化。同时,PyTorch 还支持其他类型的剪枝算法,如迭代剪枝和全局剪枝。
5. 量化
量化 (Quantization) 是信号处理和通信领域的一个术语,通常用于表示数据提供的精度。位 (bit) 数越多,数据的精度和分辨率越高。例如,一个变量用 4 bits 表示,如果希望其量化为 2 bits,则意味着需要降低数据的分辨率。使用 4 bits 时,可以表示 16 种不同的状态,而使用 2 bits 时,则只能表示 4 种状态。换句话说,通过将数据的分辨率从 4 bits 降低到 2 bits,可以节省 50% 的空间和计算复杂度。
大多数深度学习库(如PyTorch和TensorFlow)都支持混合精度运算。例如,TrainingArguments 类中使用的 fp16 参数。fp16 可以提高计算效率,因为 GPU 在执行低精度数学运算时效率更高,但结果仍然会以 fp32 精度累积。混合精度可以减少训练所需的内存,从而允许增加批大小或模型规模。
量化可以应用于模型权重,以减少其分辨率并节省计算时间、内存和存储空间。在本节中,我们将对剪枝后的模型进行量化。
(1) 首先,将模型量化为 8 bits 整数表示:
python
import torch
distilroberta = torch.quantization.quantize_dynamic(
model=distilroberta,
qconfig_spec = {torch.nn.Linear: torch.quantization.default_dynamic_qconfig}, dtype=torch.qint8)(2) 计算量化后模型的评估结果:
python
distilroberta_results_pq = roberta_sts_benchmark(stsb['validation']) (3) 查看结果:
python
pd.DataFrame({
"DistillRoberta":stsb_metric.compute(predictions=distilroberta_results, references=references),
"DistillRobertaPruned":stsb_metric.compute(predictions=distilroberta_results_p, references=references),
"DistillRobertaPrunedQINT8":stsb_metric.compute(predictions=distilroberta_results_pq, references=references)
})输出如下所示:

(4) 我们已经实现了一个蒸馏模型,并对其进行了剪枝和量化,以减小其规模和复杂度。接下来,我们通过保存模型来观察节省了多少空间:
python
distilroberta.save("model_pq")(5) 查看模型文件大小:
shell
$ ls model_pq/0_Transformer/ -l --block-size=M | grep pytorch_model.bin
# -rw-r--r-- 1 root 191M May 23 14:53 pytorch_model.bin可以看到,模型的大小为 191MB,而初始模型的大小为 313MB,这意味着我们成功地将模型大小减少到了原始大小的 61%,而性能仅损失了 6%--6.5%。需要注意的是,查看文件大小的命令在不同操作系统上可能有所模型,本节以 linux 为例。
在本节中,我们学习了剪枝和量化技术,这些方法在实际场景中非常实用。同时,也了解了蒸馏过程及其应用除此之外,还有许多其他剪枝和量化技术值得探索,例如动态剪枝,这种剪枝方法是一种一阶权重剪枝方法。它利用训练中的权重变化来判断哪些权重对结果影响较小,从而进行剪枝。
6. 使用 bitsandbytes 简化量化过程
尽管量化可以通过降低精度来减小模型规模,但使用 GPU 友好的函数以充分发挥其作用是非常重要的。
(1) bitsandbytes 库实现了 NVidia CUDA 的自定义函数,专门用于 8 bits 量化。transformers 库也集成了这一功能,使其更易于使用。只需将运行时环境切换到 GPU,然后安装 bitsandbytes 和 accelerate:
shell
$ pip install bitsandbytes
$ pip install accelerate(2) 加载模型并使用 8 bits 量化,可以看到,使用 transformers 进行量化非常简单,只需将 load_in_8bit 设置为 True 即可:
python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('decapoda-research/llama-7b-hf', load_in_8bit=True)量化是一种在内存和计算能力有限的机器上加载大模型的技术。但需要注意的是,这会降低模型的精度。
小结
在本节中,我们学习了如何在硬件资源受限的情况下减轻运行大模型的负担。我们介绍了如何通过蒸馏、剪枝和量化从训练好的模型中提取高效模型。预训练轻量级的通用语言模型(如 DistilBERT) 可以在各种任务上进行微调,并表现出与非蒸馏模型相当的性能。随着数据量的不断增加,我们希望模型能够更快地运行,在这方面,高效 Transformer 起着至关重要的作用。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策