锋哥原创的Transformer 大语言模型(LLM)基石视频教程:
https://www.bilibili.com/video/BV1X92pBqEhV
课程介绍

本课程主要讲解Transformer简介,Transformer架构介绍,Transformer架构详解,包括输入层,位置编码,多头注意力机制,前馈神经网络,编码器层,解码器层,输出层,以及Transformer Pytorch2内置实现,Transformer基于PyTorch2手写实现等知识。
Transformer 大语言模型(LLM)基石 - Transformer架构详解 - 解码器(Decoder)详解以及算法实现
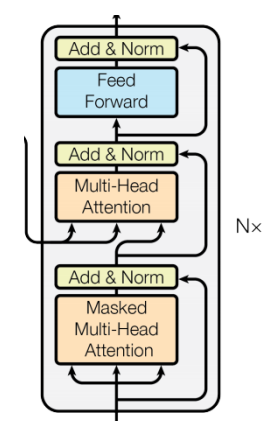
Transformer 解码器是 Transformer 模型的重要组成部分,主要用于生成序列,提取特征。
核心特点:
-
自注意力机制(Self-Attention):允许解码器关注输入序列的不同部分,但在解码器中,为了防止信息泄露,通常使用掩码自注意力(masked self-attention),确保当前位置只能关注之前的位置。
-
编码器-解码器注意力机制(Encoder-Decoder Attention):允许解码器关注编码器的输出。
-
前馈神经网络(Feed-Forward Network):每个注意力层后都有一个前馈网络。
解码器层通常由以下子层组成: a. 掩码自注意力层(Masked Multi-Head Self-Attention) b. 编码器-解码器注意力层(Multi-Head Cross-Attention) c. 前馈神经网络层(Feed-Forward Network)
每个子层后面都有残差连接(Residual Connection)和层归一化(Layer Normalization)。
代码实现:
# 解码器层
class DecoderLayer(nn.Module):
def __init__(self, d_model, self_attention, cross_attention, d_ff, dropout=0.1):
super().__init__()
self.d_model = d_model # 词嵌入维度大小
self.self_attention = self_attention # 多头自注意力机制
self.cross_attention = cross_attention # 多头交叉注意力机制
self.feed_forward = d_ff # 前馈神经网络
self.residual_connection1 = ResidualConnection(d_model, dropout) # 残差连接
self.residual_connection2 = ResidualConnection(d_model, dropout) # 残差连接
self.residual_connection3 = ResidualConnection(d_model, dropout) # 残差连接
def forward(self, x, encoder_output, mask):
"""
前向传播
:param x: 解码器输入
:param encoder_output: 编码器输出结果 [3,5,512]
:param mask: 掩码
:return:
"""
# 多头自注意力机制
x1 = self.residual_connection1(x, lambda x: self.self_attention(x, x, x, mask))
# 多头交叉注意力机制
x2 = self.residual_connection2(x1, lambda x: self.cross_attention(x, encoder_output, encoder_output))
# 前馈神经网络
x3 = self.residual_connection3(x2, lambda x: self.feed_forward(x))
return x3
# 解码器(由多个解码器层堆叠)
class Decoder(nn.Module):
def __init__(self, num_layers, layer):
super().__init__()
self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(num_layers)])
self.norm = LayerNorm(layer.d_model)
def forward(self, x, encoder_output, mask):
"""
前向传播
:param x: 解码器输入
:param encoder_output: 编码器的输出结果 [3,5,512]
:param mask: 掩码
:return:
"""
for layer in self.layers:
x = layer(x, encoder_output, mask)
return self.norm(x)
# 测试解码器
def test_decoder():
vocab_size = 2000 # 词表大小
embedding_dim = 512 # 词嵌入维度大小
embeddings = Embeddings(vocab_size, embedding_dim)
embed_result = embeddings(torch.tensor([[23, 5, 77, 3, 55], [166, 12, 13, 122, 15], [166, 21, 13, 14, 15]]))
positional_encoding = PositionalEncoding(embedding_dim)
positional_result = positional_encoding(embed_result)
mha = MultiHeadAttention(d_model=512, num_heads=8) # 多头自注意力机制
ffn = FeedForward(d_model=512, d_ff=2048) # 前馈神经网络
# 实例化解码器对象
decoder_layer = DecoderLayer(d_model=512, self_attention=mha, cross_attention=mha, d_ff=ffn)
# 编码器输入
encoder_output = test_encoder()
mask = create_sequence_mask(5)
# 实例化解码器对象
decoder = Decoder(num_layers=6, layer=decoder_layer)
decoder_result = decoder(positional_result, encoder_output, mask)
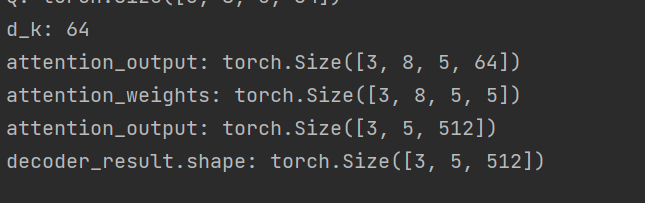
print('decoder_result.shape:', decoder_result.shape)
if __name__ == '__main__':
# test_encoder()
test_decoder()运行输出: