来自Illuin Technology、巴黎中央理工-高等电力学院、苏黎世联邦理工学院等机构的团队,在2025年ICLR会议上提出了颠覆性解决方案------ColPali模型与ViDoRe基准测试,直接通过文档图像生成嵌入向量,完美融合文本与视觉信息,彻底简化检索流程并实现性能飞跃。

在RAG应用、学术文献检索等实际场景中,我们常遇到包含图表、复杂布局、多语言内容的"视觉丰富文档"。传统检索系统要先经过PDF解析、OCR提取、布局检测等繁琐步骤,不仅耗时还容易丢失视觉信息,导致检索效果大打折扣。
来自Illuin Technology、巴黎中央理工-高等电力学院、苏黎世联邦理工学院等机构的团队,在2025年ICLR会议上提出了颠覆性解决方案------ColPali模型与ViDoRe基准测试,直接通过文档图像生成嵌入向量,完美融合文本与视觉信息,彻底简化检索流程并实现性能飞跃。
项目地址:https://hf.co/vidore
论文地址:https://arxiv.org/pdf/2407.0144901、痛点直击:传统文档检索的两大致命缺陷
现代文档检索系统之所以难以应对视觉丰富文档,核心问题集中在两点:
- 预处理链路冗长脆弱:标准PDF检索需要经过"PDF解析→OCR文字提取→布局检测→文本分块→视觉元素描述"等多步骤流程,仅OCR和布局检测就占用大量时间,且每一步都可能引入误差,比如复杂表格的OCR识别错误、分块破坏语义连贯性等。
- 视觉信息利用不足:文档中的图表、配色、字体、空间布局等视觉元素,往往承载着关键信息(如折线图的趋势、表格的结构关系),但传统系统要么直接忽略这些元素,要么通过文本描述间接转化,导致信息丢失或扭曲。
这些问题使得传统系统在RAG、学术文献检索等实际场景中,既无法保证检索精度,又难以满足低延迟、高吞吐量的工业需求。
02、核心贡献:两大突破重新定义文档检索
ViDoRe基准测试:首个视觉丰富文档检索的"全能评估平台"
此前的基准测试要么只关注纯文本检索,要么局限于自然图像匹配,无法全面评估视觉丰富文档的检索能力。ViDoRe的出现填补了这一空白,其核心特点的是"全场景覆盖":
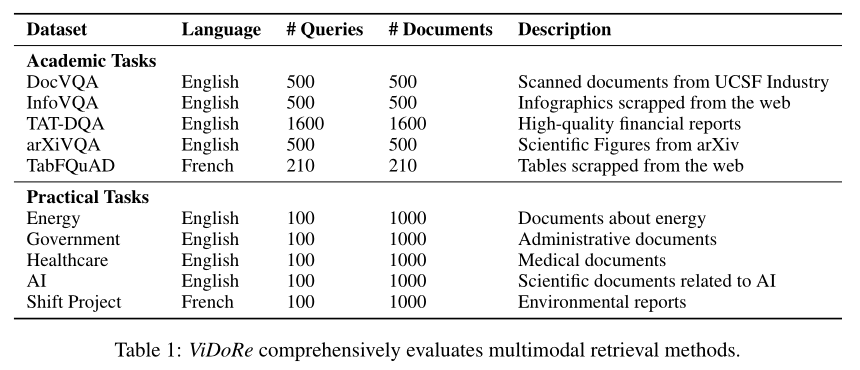
- 多维度任务设计:涵盖学术任务与实际任务两大类别,覆盖文本、图表、表格、信息图表等多种模态,涉及医学、商业、科学、行政等多个领域,支持英语、法语两种语言。
- 高质量数据集构建:
学术任务:复用DocVQA、InfoVQA等经典数据集,共包含500-1600个查询-页面对,聚焦特定视觉模态的检索能力;
实际任务:通过网络爬虫收集1000个文档页面/主题,利用Claude-3 Sonnet生成查询并经人工筛选,确保每个主题有100个高质量查询,贴近工业实际场景。 - 全面评估指标:不仅包含nDCG@5、Recall@K、MRR等标准检索指标,还新增查询延迟(在线性能)、索引吞吐量(离线效率)两项工业关键指标,实现"性能+效率"双重评估。
ViDoRe已开放公开排行榜(https://huggingface.co/spaces/vidore/vidore-leaderboard),为文档检索研究提供统一的评估标准。
ColPali模型:视觉语言模型驱动的端到端检索方案
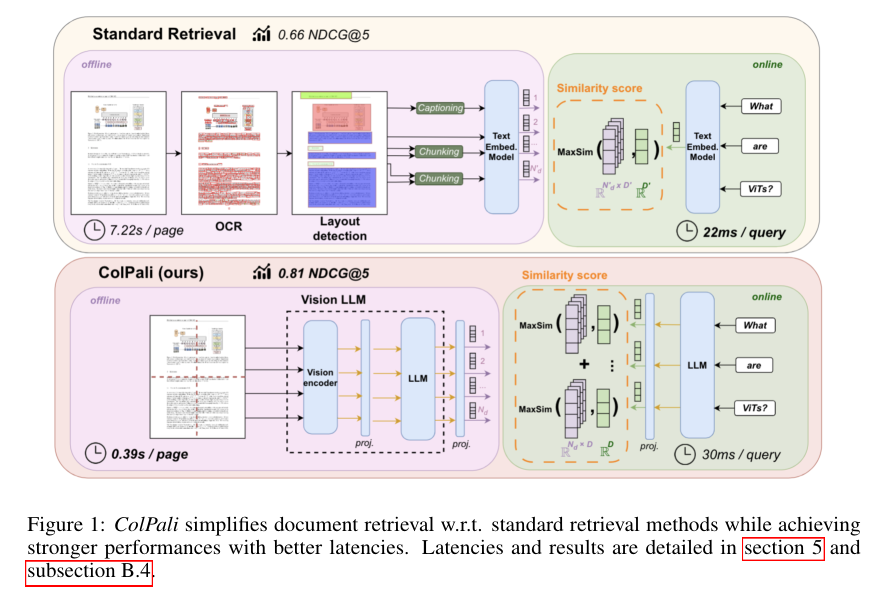
ColPali的核心创新是 "直接从文档图像生成多向量嵌入",无需任何预处理步骤,其架构设计围绕三大核心组件展开:
(1)基础模型选型:PaliGemma-3B的高效适配
选择PaliGemma-3B作为基础模型,原因在于它具备三大优势:
- 轻量化设计:30亿参数规模,兼顾性能与效率;
- 跨模态对齐:通过SigLIP视觉编码器与Gemma-2B语言模型的融合,实现图像与文本的深度对齐;
- 灵活的前缀注意力:支持图像patch与文本指令的全注意力交互,适合检索任务的细粒度匹配需求。
(2)核心机制:多向量嵌入+延迟交互
这是ColPali超越传统模型的关键:
-
多向量嵌入:为文档图像的每个patch生成独立嵌入向量,再通过投影层映射到128维空间,保留细粒度视觉与文本信息;
-
延迟交互(Late Interaction):查询时计算每个查询token与所有文档patch嵌入的最大相似度,再求和得到最终相关性分数,公式如下:
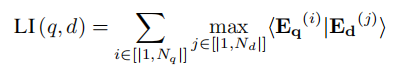
这种方式既保留了bi-encoder的高效性,又具备cross-encoder的细粒度匹配能力。
(3)训练策略:对比学习+数据增强
-
训练数据:118,695个查询-页面对,包含63%学术数据集和37%合成数据(网络爬取PDF+VLM生成伪查询),全英文训练以验证零-shot跨语言能力;
-
损失函数:采用批内对比损失,优化正样本(相关文档)与负样本(最相似无关文档)的相似度差异,公式如下:
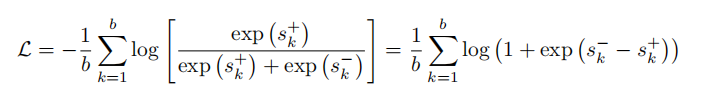
-
优化技巧:使用LoRA低秩适配、8bit量化优化、查询增强(添加5个
<unused0>tokens)等,平衡训练效率与模型性能。
03、实验结果:全面碾压传统方案,性能与效率双丰收
本次实验选取三类主流检索系统作为对比基准:
- 基于文本的检索系统(Text-Based Retrieval Systems):使用Unstructured工具从PDF文档中提取文本块,并使用BM25或BGE-M3嵌入模型进行检索。这些系统仅依赖于文本信息,忽略了文档中的视觉元素。
- 增强型检索系统(Enhanced Retrieval Systems) :
Unstructured + OCR :在提取文本的基础上,对文档中的图表、表格和图像进行OCR处理,并将这些视觉元素独立索引。
Unstructured + Captioning :使用视觉语言模型为视觉元素生成详细的描述文本,并将这些描述纳入检索流程。
这些方法虽然能够利用部分视觉信息,但显著增加了预处理的复杂性和延迟。 - 对比学习视觉语言模型(Contrastive Vision-Language Models):评估了如Jina CLIP、Nomic Embed Vision、SigLIP等模型。这些模型虽然在图像和文本对齐方面表现出色,但在文档检索任务中表现欠佳。
性能:全场景霸榜,视觉复杂任务提升显著
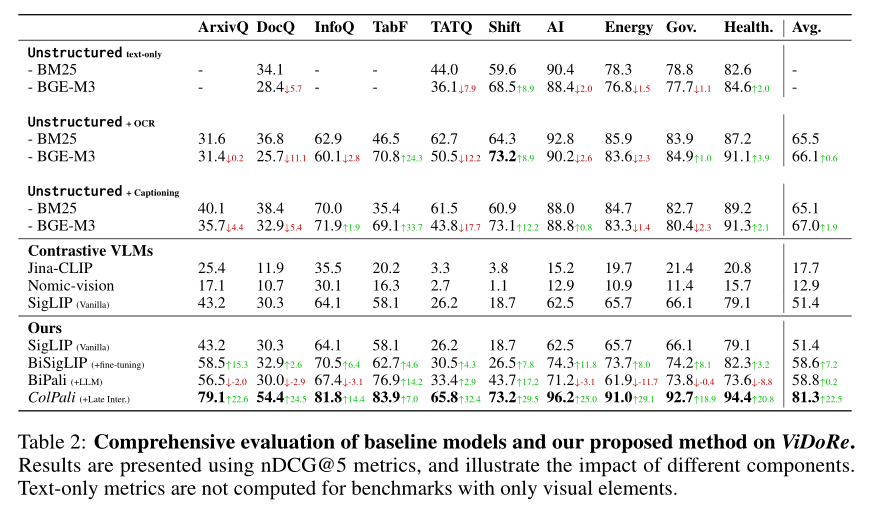
以nDCG@5为核心评估指标,ColPali在所有任务中均展现出压倒性优势,尤其在依赖视觉信息的复杂场景中,性能提升幅度达到20%-30%。
- BiSigLIP(微调视觉模型):在SigLIP基础上对文本组件进行文档检索专项微调后,性能全面提升。ArxivQA(科学图表检索)任务中,nDCG@5从43.2提升至58.5,TabFQuAD(法语表格检索)从58.1提升至62.7,证明针对文档场景的微调能让视觉语言模型更好地适配文本与视觉的联合理解。
- BiPali(将图像patch输入到LLM):通过将图像patch嵌入输入Gemma-2B语言模型,借助LLM的上下文理解能力增强视觉表示。在法语TabFQuAD任务中,nDCG@5达到76.9,远超BiSigLIP的62.7,即使训练数据中无法语样本,仍实现零-shot跨语言性能突破,验证了LLM对多语言语义理解的迁移价值。
- ColPali(多向量嵌入与延迟交互):融合多向量表示与延迟交互机制后,性能实现质的飞跃。在InfographicVQA(信息图表)任务中,nDCG@5达到81.8,较BiSigLIP高出22.6个百分点;ArxivQA(科学图表)任务中79.1的得分,较增强型检索系统的最优值(Unstructured+Captioning+BGE-M3为40.1)翻倍;即使在文本密集的Government(行政文档)、Healthcare(医疗文档)任务中,也以92.7、94.4的高分领先,证明其对文本与视觉信息的全面捕捉能力。
从整体表现来看,ColPali的平均nDCG@5达到81.3,较增强型检索系统的最优均值(67.0)提升21.3%,较最优对比视觉语言模型(SigLIP微调版58.6)提升38.7%,解决了传统系统"视觉信息利用不足"的核心痛点。
在线查询:低延迟适配工业需求
在线查询延迟直接影响用户体验,实验在NVIDIA L4 GPU上测试1000条查询的平均延迟:
- 传统检索系统(BGE-M3):因仅需计算文本向量相似度,延迟最低,约22ms/查询;
- ColPali:查询编码需处理文本与图像的多向量交互,延迟约30ms/查询,仅比BGE-M3高8ms;
- 对比优化空间:通过集成PLAID等高效延迟交互引擎,可支持百万级文档库检索,且延迟 degradation 可控,完全满足工业场景下"低延迟响应"的核心需求。
离线索引:跳过预处理,索引速度提升18倍
离线索引的核心瓶颈在于文档预处理流程,ColPali通过直接处理文档图像,彻底简化了索引链路,效率优势显著。
- 传统检索方法的局限性:增强型检索系统需经过"布局检测(0.81s)→OCR(2.67s)→Captioning(3.71s)→页面编码(0.03s)"等步骤,单页面索引总耗时达7.22s,其中视觉元素处理占比超99%,成为效率瓶颈。
- ColPali的优势:直接接收文档图像输入,无需任何预处理,单页面索引仅需0.39s,速度较增强型检索系统提升18倍;同时支持批量处理(批大小4),借助Flash Attention等优化技术,可充分利用GPU算力,进一步提升索引吞吐量,满足大规模文档库的快速构建需求。

Token池化:冗余压缩与性能平衡的最优解
针对图像patch中的冗余信息(如白色背景、空白区域),Token池化技术可在不显著损失性能的前提下降低存储与计算成本:
- 核心原理:基于CRUDE原则(支持文档动态增删),对语义相似或无意义的patch嵌入进行合并,减少向量数量。
- 实验结果:当池化因子为3时,向量总数减少66.7%,所有任务的平均相对性能保持在97.8%;其中Energy(能源文档)、InfoVQA(信息图表)任务性能损失不足1%,证明冗余patch的有效压缩不会影响核心信息捕捉。
- 特殊场景说明:Shift数据集(文本密集型文档)因冗余patch少,池化后性能损失略高(约5%),建议此类信息密集型场景采用较小池化因子(≤2),平衡存储与性能。
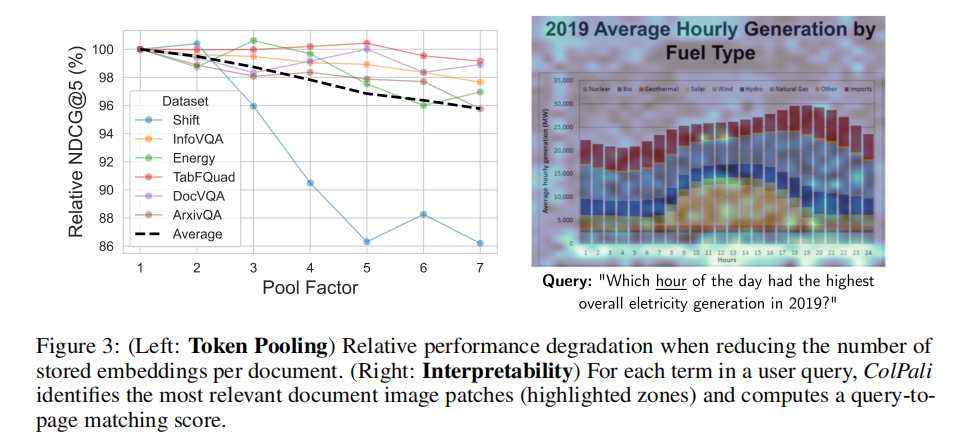
可解释性:可视化决策过程,提升信任度
ColPali的延迟交互机制天然支持细粒度可视化,通过延迟交互热图可直观展示模型的匹配逻辑,如图3:
- 精准文本匹配:查询token
<hour>与图像中"hourly""hours"等文字patch形成高相似度匹配,体现强大的隐式OCR能力; - 视觉特征理解:除文本外,模型还关注图表中表示小时的x轴、时间相关的坐标轴刻度等非文本视觉元素,证明其对视觉语义的深度理解;
- 实用价值:可视化结果可帮助用户验证检索相关性的合理性,尤其在学术、医疗等高精度需求场景中,能显著提升模型的可信任度。
04、总结
基于视觉检索的方案(如 ColPali)为解决传统基于文本的检索范式问题提供了全新思路。通过直接对文档图像进行编码,跳过复杂预处理步骤,不仅将索引速度提升一个数量级,更能完整保留文本、图表、布局等多模态信息的原生关联,从根源上缓解了传统范式的信息损耗问题。这种 "视觉空间检索" 的创新范式,尤其适配学术论文、金融报告、医疗文档等视觉元素密集的场景,实现了检索能力的质的飞跃。
但与此同时,视觉检索也面临着核心权衡:一方面,图文对齐的鸿沟依然存在,如何让模型精准理解图像中文本的语义与视觉元素的关联,仍是需要持续优化的关键;另一方面,与技术成熟的纯文本检索相比,视觉检索在早期面临检索精度波动的问题,尤其在文本密集、视觉冗余的场景中,需通过多向量表示、延迟交互、专项微调等技术手段弥补差距。
未来,检索策略的选择不是 "非此即彼" 的二元对立,而是需根据具体场景进行个性化适配或融合设计。若处理以纯文本为主、结构简单的文档(如新闻稿、普通邮件),技术成熟、精度稳定的传统文本检索仍是高效选择;若面对学术论文、金融报表、医疗影像报告等视觉元素密集的复杂文档,ColPali 这类视觉检索方案能更好地发挥信息完整性与效率优势;对于混合场景,则可采用 "视觉检索 + 文本检索" 的融合策略,通过互补机制兼顾各类文档的检索需求。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。