目录
Transformer的总体架构:Encoder-Decoder结构、
[ViT(Vision Transformer)](#ViT(Vision Transformer))
Seq2Seq模型及其瓶颈
定义:Seq2Seq(Sequence to Sequence,序列到序列)模型,由编码器(Encoder)和解码器(Decoder)两部分组成,一般选用RNN/LSTM/GRU等网络实现。Seq2Seq的输入是一个不定长的序列,输出也是一个不定长的序列。
通俗理解 :它就像一个"翻译官",负责把一种序列(比如一句英文)转换成另一种序列(比如一句中文)。这个模型是处理输入输出长度都可能变化的任务的通用框架。
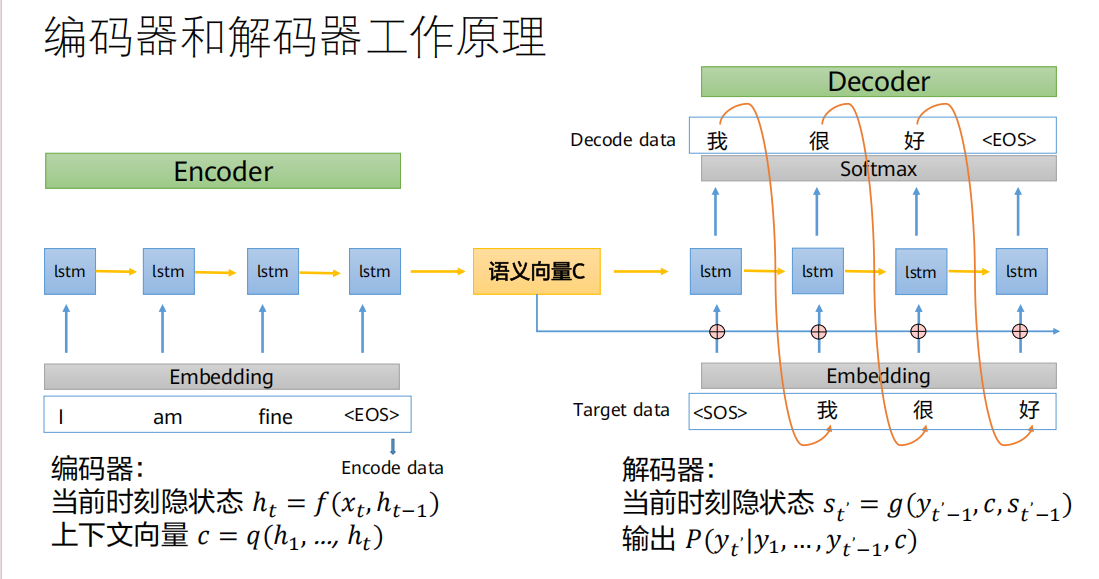
编码器的作用 :将长度可变的输入序列转换成一个固定长度的上下文向量(Context Vector),并将输入序列的所有信息"压缩"编码进这个向量中。
解码器的作用:进行相反的过程,将那个固定的上下文向量进行"解码",逐步生成长度可变的输出序列。
核心要点 :编码器把所有信息都"挤压"进一个固定大小的向量
c中,解码器就靠这个向量c来生成整个输出序列。输入(Encode data) :
I am fine <EOS>(<EOS>是句子结束符)输出(Target data) :
<SOS> 我 很 好 <EOS>(<SOS>是解码开始符)过程分解:
编码阶段:
编码器(通常是一个RNN/LSTM)逐个读入输入单词
I,am,fine,<EOS>。每读入一个词,它都会更新自己的隐状态(Hidden State)
。
当读到句尾
<EOS>时,最后的隐状态解码阶段:
解码器(另一个RNN/LSTM)拿到这个语义向量
C作为其初始状态。解码器在每一步接收前一步生成的单词(第一步接收
<SOS>)和当前的隐状态s_t',然后预测下一个最可能的单词。不断重复,直到输出
<EOS>,生成完整的翻译序列我 很 好 <EOS>。
Seq2Seq模型的瓶颈
Seq2Seq模型在处理长序列时表现不佳,原因有两点:
RNN/LSTM固有的"长期依赖"问题 :虽然LSTM比普通RNN有所改善,但当序列非常长时,信息在一步步传递中仍会不可避免地衰减或丢失。早期的信息很难有效传递到后期。
上下文向量
c的"信息过载"瓶颈(这是更关键的问题):
无论输入句子有多长(1个词还是100个词),编码器都必须把它们压缩到同一个固定维度的上下文向量
c中。想象一下,让你用一段固定长度的话总结一篇短文和一部长篇小说,总结短文可能很精准,但总结长篇小说必然会丢失海量细节。
对于解码器来说,在生成每一个输出词时,它都只能依赖这同一个、包含了所有信息的、拥挤的
c向量 。这导致模型难以聚焦于当前最相关的输入部分。
【总结】
Seq2Seq = 编码器(压缩输入为固定向量
c)+ 解码器(从c解码出输出)。瓶颈 :1) 长程依赖;2) 固定长度
c导致信息过载,解码时缺乏"焦点"。出路 :引入注意力机制,让解码器每一步都能动态地、有选择地查看输入序列的不同部分。
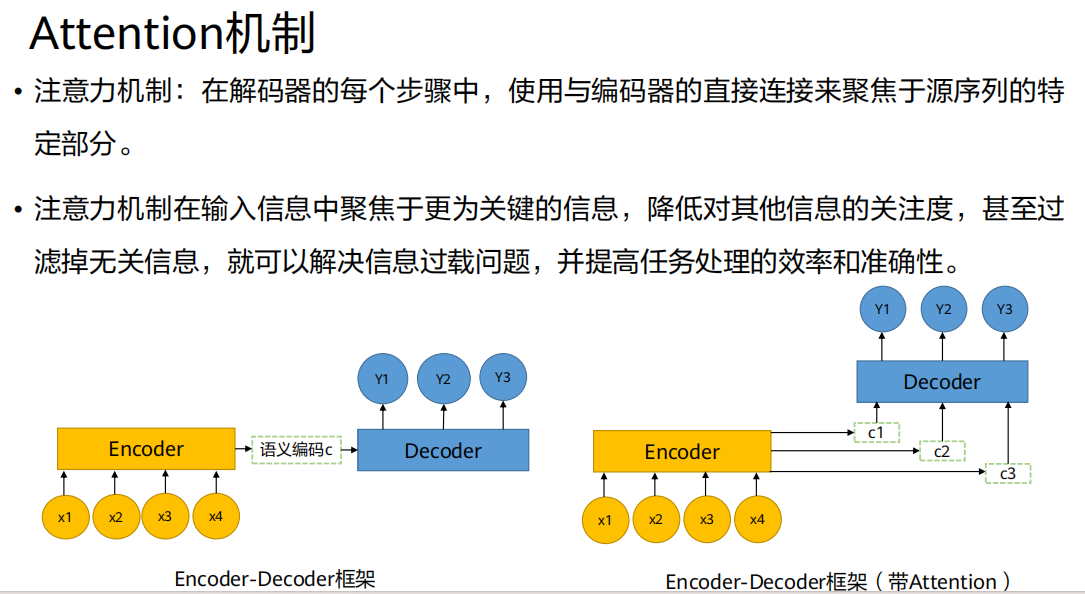
注意力机制(Attention)的引入
通俗比喻:
- 想象你在翻译一句话。传统Seq2Seq就像让你先听完整句话(编码),然后蒙上眼睛(只靠记忆
c)开始翻译。而引入Attention 就像允许你在翻译每一个词 的时候,都可以回头快速扫一眼原文的相应部分。翻译"苹果"时看"apple",翻译"吃"时看"eat"。假设我们现在要生成解码器的第
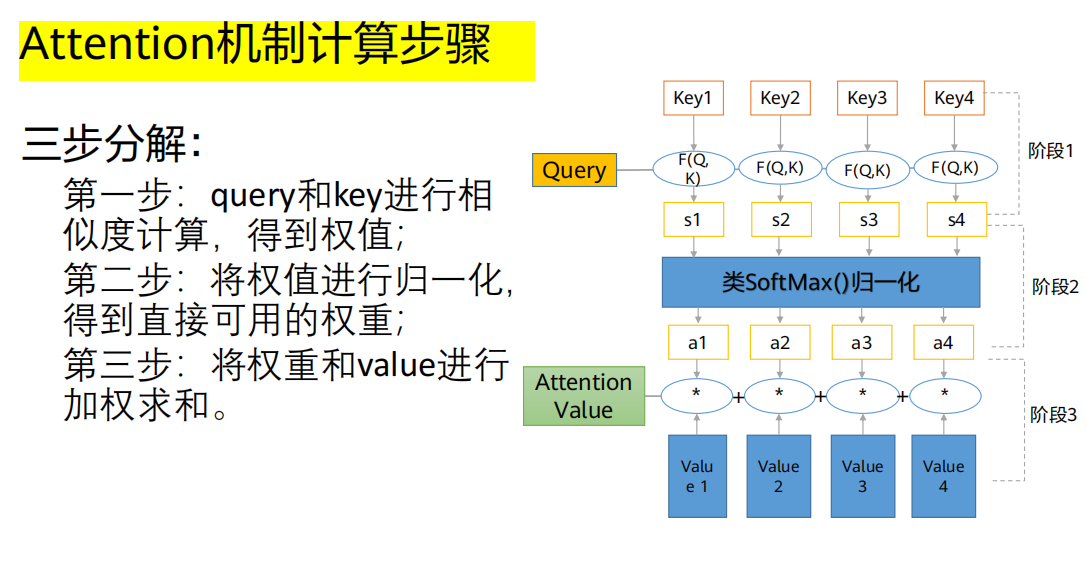
t个输出,需要计算其对应的上下文向量第一步:计算相似度得分(Score)
角色定义:
Query (Q,查询) :解码器当前的状态(可以理解为"我现在想知道什么")。
Key (K,键) :编码器所有输入单词的隐状态(可以理解为"我有什么信息可供匹配")。
Value (V,值) :通常与Key相同,即编码器的隐状态
操作 :用当前的
Query ()去和每一个输入单词的Key ()进行相似度计算F(),得到一个分数
- 常用方法 :点积(Dot-Product),即
第二步:归一化权重(Softmax)
操作 :将所有分数
()送入一个 Softmax函数进行归一化。目的 :将所有分数转化为一个概率分布 ,即得到权重
()。和为1 ,且均为正数。i个输入词的"注意力权重"。第三步:加权求和得到上下文向量(Weighted Sum)
操作 :用第二步得到的权重
结果 :
后续 :解码器将这个动态的
Attention带来的革命性改进
解决了信息过载 :解码器不再需要从单一、固定的
c中费力提取所有信息,而是每次按需(缓解了长程依赖 :无论输入词距离多远,只要在计算
提供了可解释性 :通过观察权重
【总结】
Attention要解决的核心问题 :传统Seq2Seq中固定上下文向量
c的信息瓶颈。核心思想 :为解码器每一步生成一个动态的、聚焦的上下文向量
计算三步曲 :1. Query-Key打分 -> 2. Softmax归一化 -> 3. 对Value加权求和。
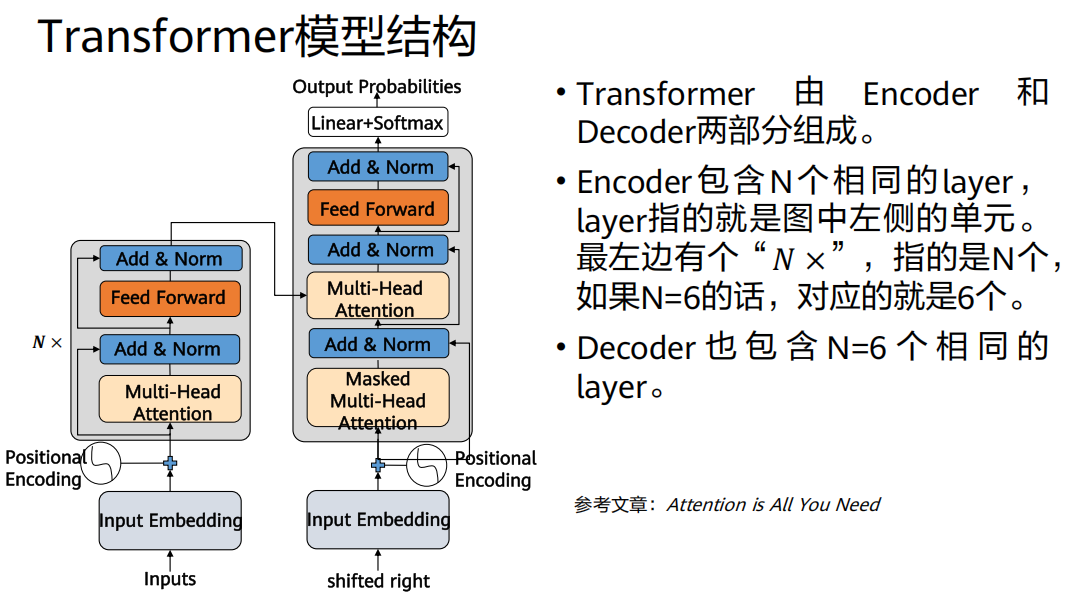
Transformer整体概览
Transformer的总体架构:Encoder-Decoder结构、
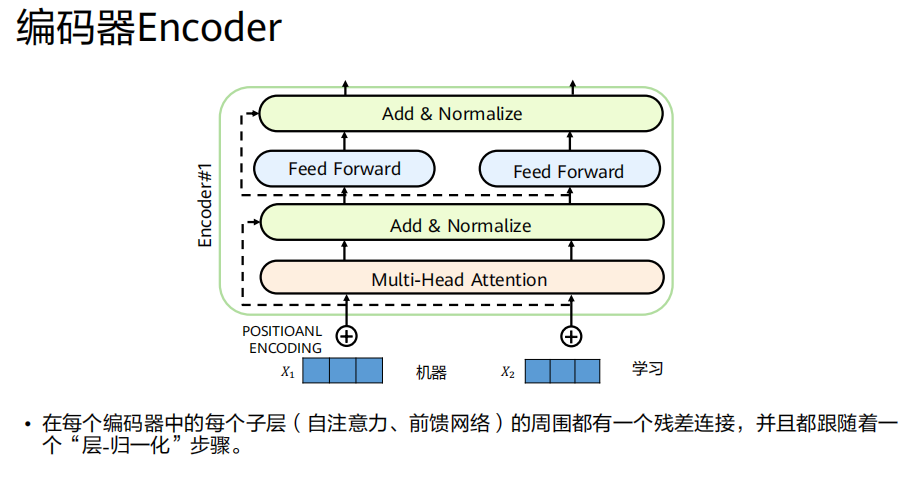
1. 编码器(Encoder - 左侧堆叠的部分)
构成 :由 N个(原论文N=6)完全相同的层(Layer) 堆叠而成。
单层结构(每个灰色框):包含两个核心子层:
多头自注意力层(Multi-Head Self-Attention)
前馈神经网络层
辅助设计 :每个子层周围都有一个残差连接(Add) ,并紧随一个层归一化(Layer Normalization) 。即遵循
LayerNorm(x + Sublayer(x))的模式。输入/输出维度 :所有子层及嵌入层的输出维度保持统一,论文中为
d_model = 512。2. 解码器(Decoder - 右侧堆叠的部分)
构成 :同样由 N个(原论文N=6)完全相同的层 堆叠而成。
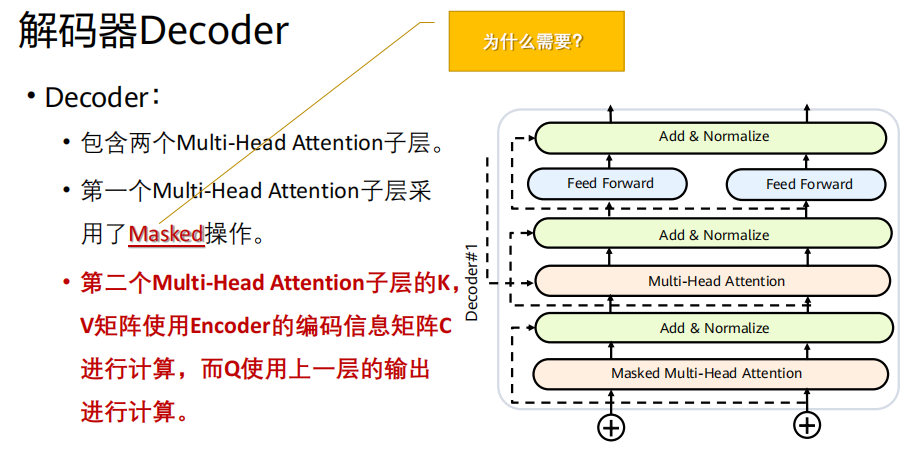
单层结构 (每个灰色框):包含三个核心子层:
带掩码的多头自注意力层(Masked Multi-Head Self-Attention):确保当前位置只能关注到已生成的序列,防止信息泄漏。
多头注意力层(Multi-Head Attention) :这里的Key和Value来自编码器的最终输出,Query来自上一层输出。这是连接编码器和解码器的关键。
前馈神经网络层。
辅助设计 :同样,每个子层都有残差连接和层归一化。、
3. 输出端
- 解码器的输出经过一个线性层(Linear) 和一个Softmax层,得到目标词汇表上的概率分布,用于预测下一个词。

【阶段总结】
Transformer = 基于纯Attention的Encoder-Decoder架构。
Encoder :N x **多头自注意力层** + **前馈网络层** (Add & Norm环绕)。
Decoder :N x **掩码多头自注意力层** + **多头注意力层(连接Encoder)** + **前馈网络层** (Add & Norm环绕)。
工作流 :输入→(嵌入+位置编码)→Encoder堆叠 →生成编码信息→Decoder自回归生成(每一步都利用编码信息)。
Transformer工作流程
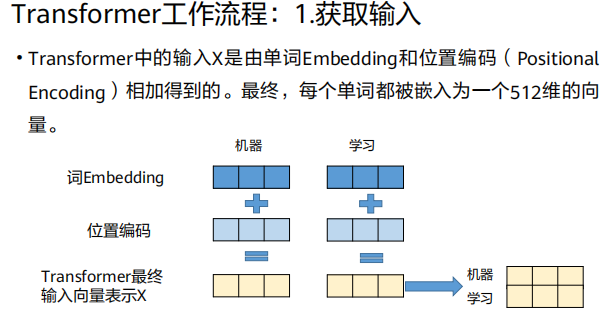
1、获取输入
Transformer的输入
X是以下两者之和:
X = 词嵌入(Word Embedding) + 位置编码(Positional Encoding)词嵌入
词嵌入是将一个单词(或子词)映射到一个高维、稠密、连续的向量空间的技术。
在Transformer中随机初始化并训练 :在《Attention Is All You Need》论文中,词嵌入矩阵是随机初始化,并作为模型参数的一部分,在训练过程中共同学习得到的。
关键点 :在Transformer里,词嵌入层通常就是一个简单的查找表 或线性投影层 ,将每个词的索引转换为一个
d_model维的向量。

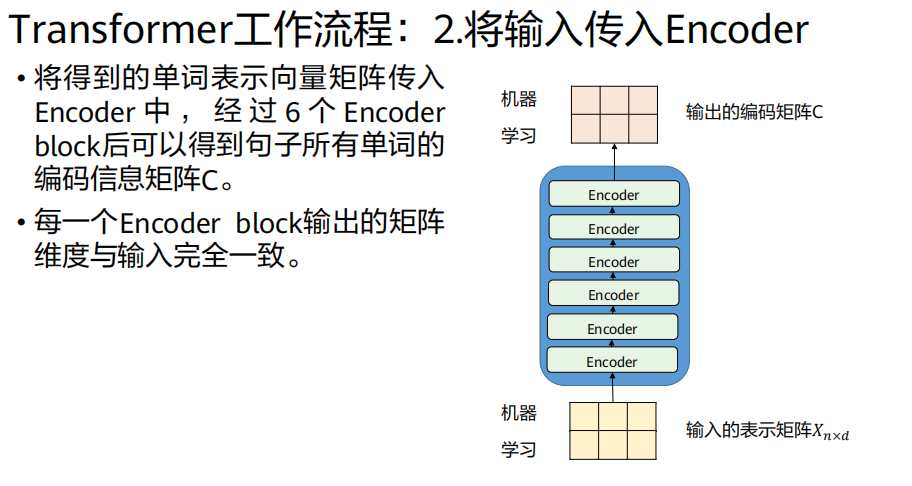
2、将输入传入Encoder
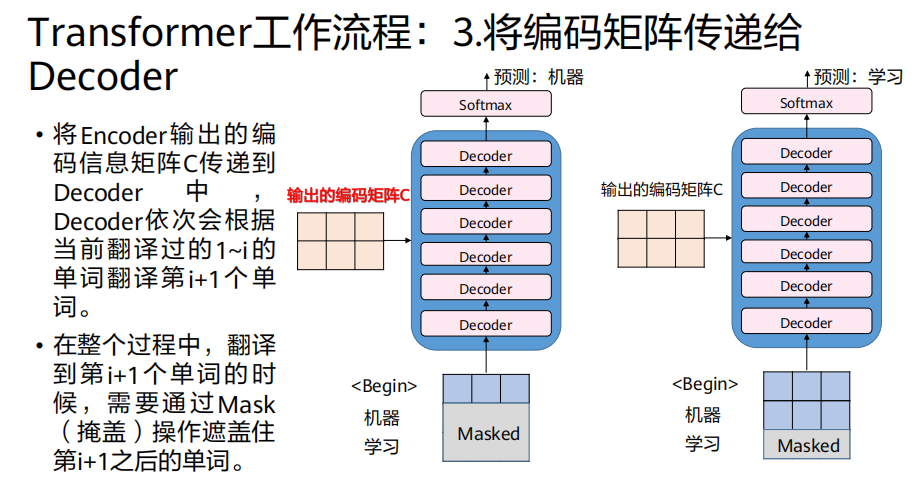
3、将编码矩阵传递给Decoder
自注意力机制
为什么需要自注意力?
自注意力的计算步骤
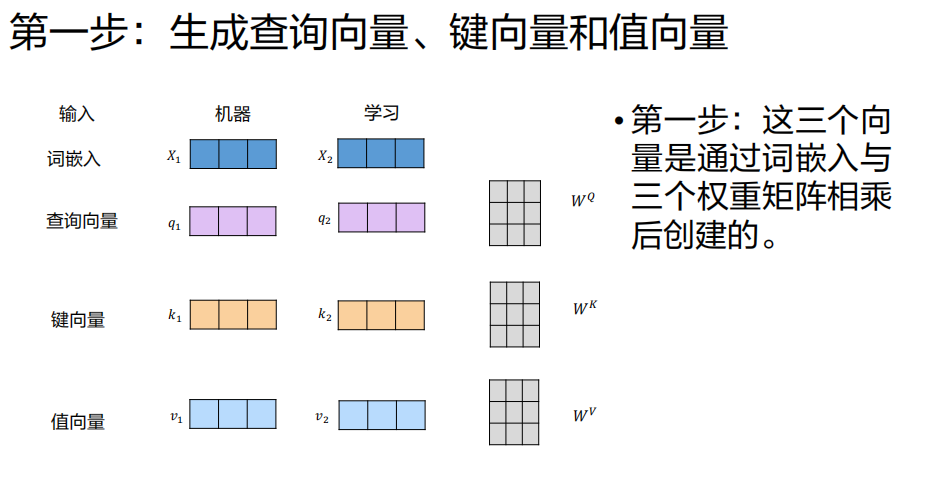
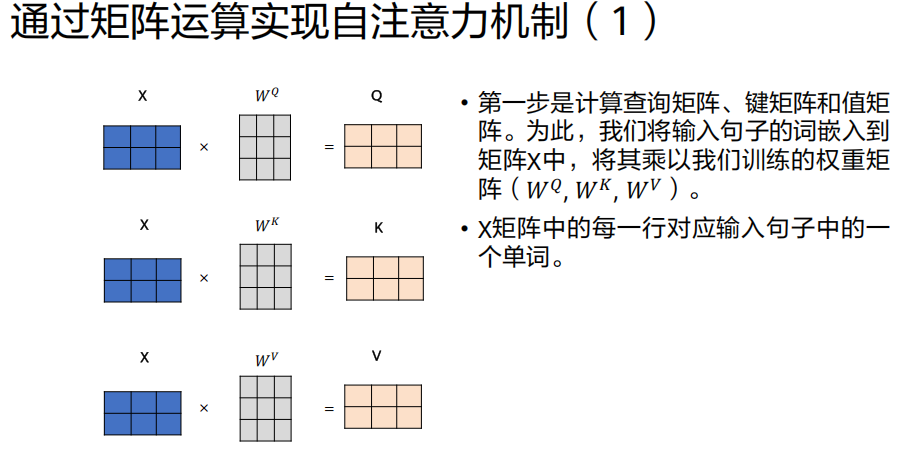
我们以编码器第一层处理输入
X(已含位置编码)为例,假设输入序列是"机器学习"。
- 三个不同的、可训练的权重矩阵
W^Q,W^K,W^V
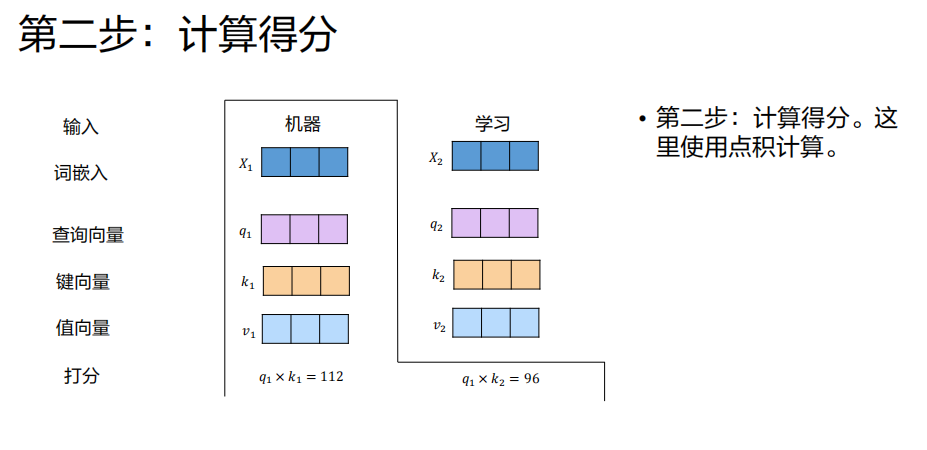
计算注意力分数
目的 :衡量"机器"(当前词)与序列中每个词(包括自己)的相关性。
操作 :用"机器"对应的查询向量
q1,分别与序列中每个词的 键向量 做点积。
分数1 = q1 · k1("机器"与"机器"自身的相关性)
分数2 = q1 · k2("机器"与"学习"的相关性)结果:得到一组分数,分数越高表示相关性越强。
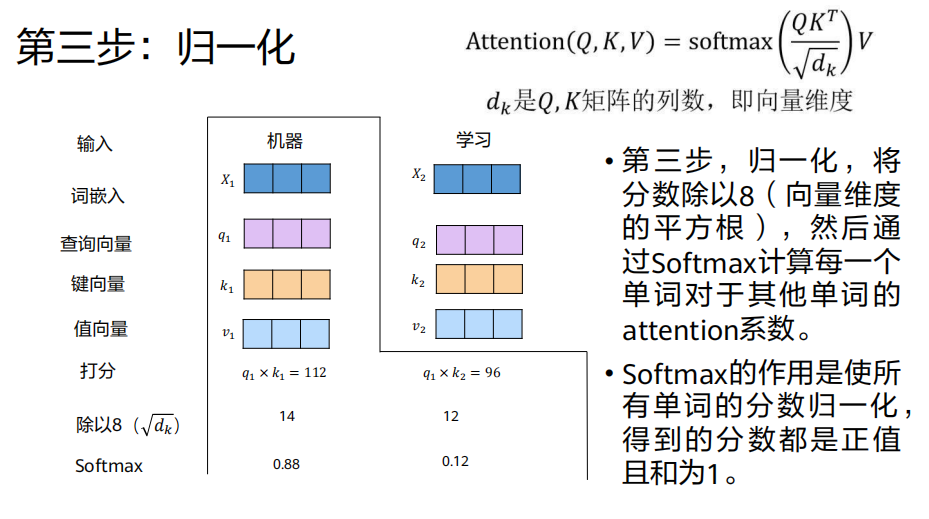
缩放与 Softmax 归一化
缩放 :将上一步的分数除以
√(d_k)(d_k是键向量K的维度,例如64)。目的:防止点积结果过大,导致Softmax梯度消失。
缩放后分数1 = 112 / √64 = 112 / 8 = 14
缩放后分数2 = 96 / 8 = 12Softmax归一化 :对缩放后的分数应用Softmax函数,将其转化为概率分布(权重,和为1,均为正数)。
权重1 = softmax(14) ≈ 0.88
权重2 = softmax(12) ≈ 0.12意义:现在我们知道,在编码"机器"这个词时,应该以88%的注意力关注"机器"本身,以12%的注意力关注"学习"。
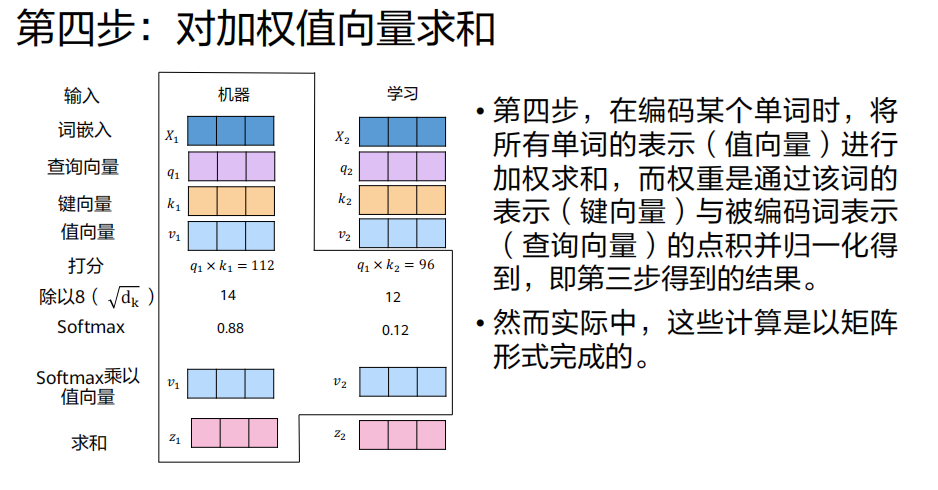
加权求和值向量
操作 :用第二步得到的权重,对对应的值向量(Value)
v1,v2进行加权求和。
z1 = 0.88 * v1 + 0.12 * v2结果 :
z1就是"机器"这个词经过自注意力层后得到的新表示 。它不再是孤立的 ,而是融入了"学习"这个词的信息的表示。
(自)注意力机制
自注意力(Self-Attention) :让序列中的每个词都能与所有词直接交互,计算加权和 来更新自己的表示。核心公式 :
Z = softmax( (Q*K^T)/√d_k ) * V。计算四步:1. QK点积得分 -> 2. 缩放并Softmax归一化 -> 3. 对V加权求和 -> 4. 矩阵输出。

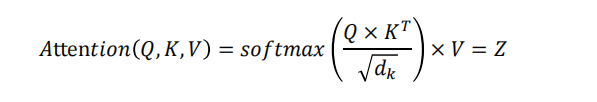
多头注意力机制
为什么需要多头?
单一的自注意力机制在一次计算中只能学习到一种类型的词间关系。但词与词之间的关系是多维和多种多样的。
例子 :"今天阳光不错,适合出去跑步"中,"今天"与"阳光"有天气 上的关系,与"跑步"有时间上的关系。
目标 :我们希望模型能同时学习到不同类型的关系。
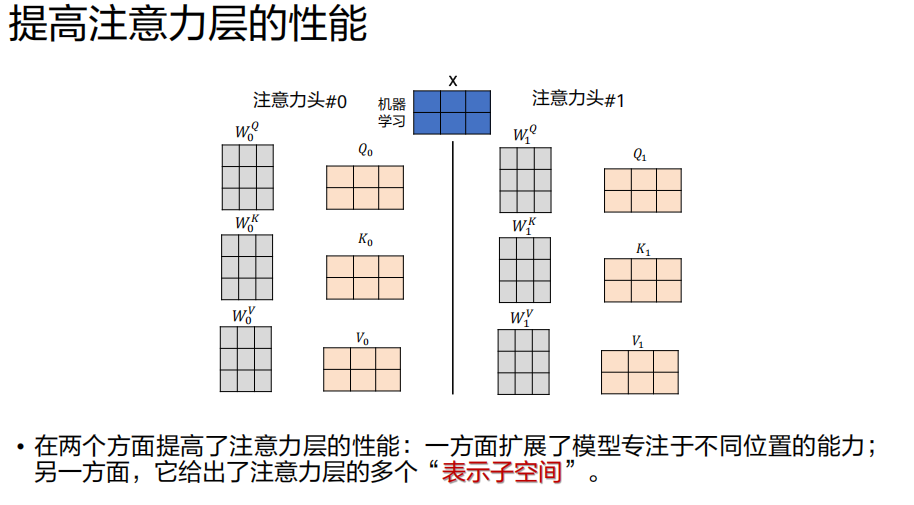
- 核心思想 :将输入的
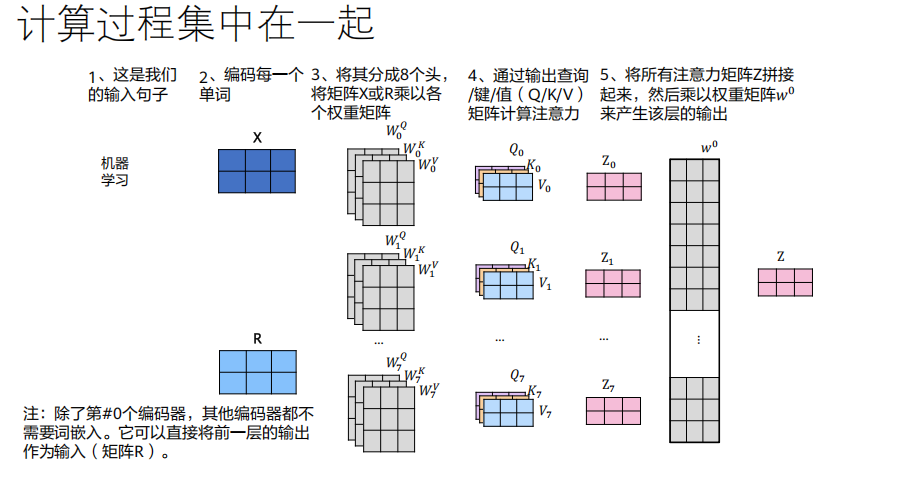
Q, K, V矩阵投影到多个不同的子空间(通过不同的W_i^Q, W_i^K, W_i^V矩阵) ,然后在每个子空间里并行地执行一次完整的自注意力计算。过程:
线性投影 :输入
X被8组不同的权重矩阵投影,得到8组不同的(Q_i, K_i, V_i)。并行计算 :对每一组
(Q_i, K_i, V_i),独立计算Attention(Q_i, K_i, V_i),得到8个输出矩阵Z_i(每个头的结果)。拼接(Concat) :将8个
Z_i矩阵在特征维度上拼接起来。线性投影 :将拼接后的大矩阵,通过一个可训练的权重矩阵
W^O做一次线性投影,将维度映射回d_model,得到最终的输出Z。
编码器的完整结构与残差连接
一个编码器层 = (多头自注意力 + Add & Norm) + (前馈网络 + Add & Norm)。
前馈网络(FFN) :一个简单的两层全连接网络(如512→2048→512),带激活函数,独立应用于每个位置,负责非线性特征加工。
残差连接(Add) :
输出=输入+子层(输入),解决梯度消失,保护信息。层归一化(Norm) :在特征维度上归一化,稳定训练,加速收敛。
编码器整体 :将上述单层堆叠 N次,对输入进行深度编码。
解码器
- 实现:在计算注意力分数(
QK^T)后,Softmax之前,将未来位置(位置 > 当前位置)的分数设置为一个极大的负数(如-1e9)。这样,经过Softmax后,这些位置的权重几乎为0。- 效果 :确保在生成第
i个词时,注意力只能集中在第1到第i-1个已生成的词上。解码器的整体目标与工作模式
目标 :以自回归(Autoregressive) 的方式,逐个生成目标序列的单词。
工作模式:
接收编码器的最终输出 (上下文矩阵
C)。在每一步,接收已生成的部分目标序列 (初始为
<SOS>)。预测下一个最可能的词。
将预测出的词追加到输入序列中,重复步骤2-4,直到生成
<EOS>。


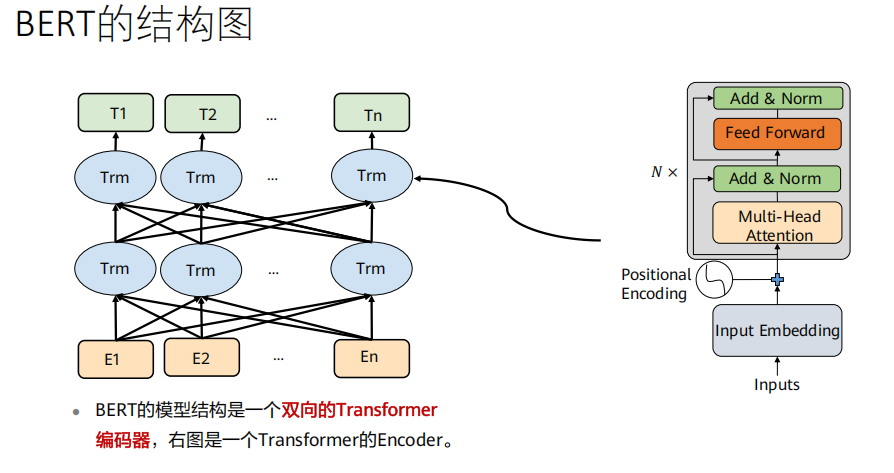
BERT(双向Transformer编码器)
BERT的本质就是一个(堆叠的)Transformer编码器(Encoder)。
对比 :原始的Transformer是一个完整的编码器-解码器(Encoder-Decoder) 架构,用于序列到序列的任务(如翻译)。
BERT :只使用了Transformer的编码器部分 ,并将其堆叠(Base:12层, Large:24层)。它不进行序列生成,而是为整个输入序列 计算一个富含上下文信息的表示。
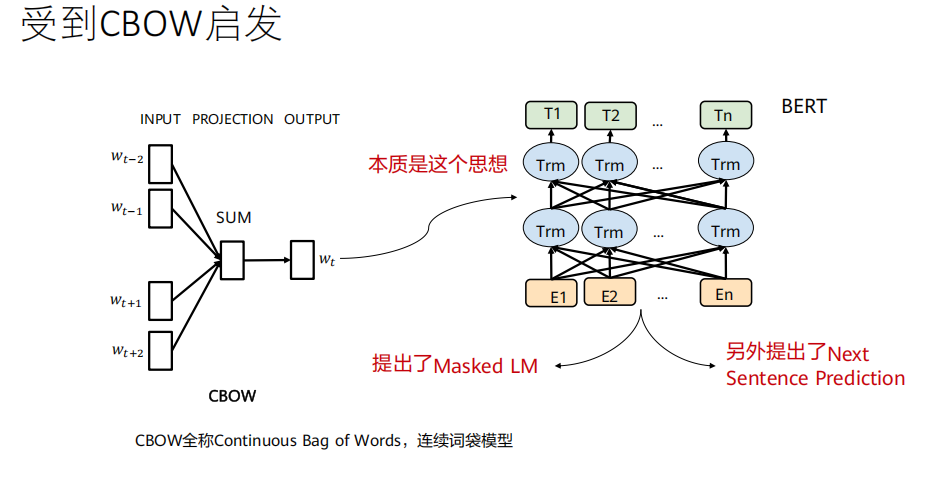
任务一:遮蔽语言模型(Masked Language Model, MLM)
训练目标 :让模型根据未被遮盖的上下文词语(双向的),来预测被遮盖位置上的原始词。
意义 :这迫使模型必须真正理解每个词在上下文中的含义,而不仅仅是记住它。
任务二:下一句预测(Next Sentence Prediction, NSP)
训练目标:一个二分类任务。
意义 :让模型学习句子级别的语义关系,这对问答(QA)、自然语言推理(NLI)等需要理解句子间关系的任务至关重要。




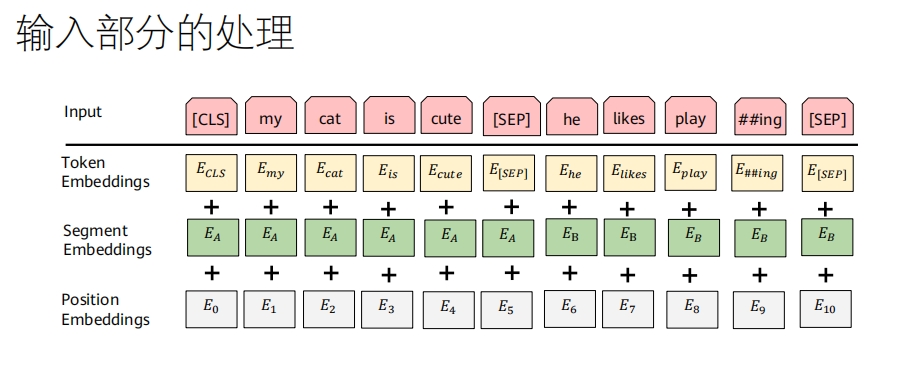
BERT的输入表示
BERT的输入是三个嵌入的总和:
词嵌入(Token Embeddings):将每个词(或子词)转换为向量。
段落嵌入(Segment Embeddings) :标记一个词属于句子A(
E_A)还是句子B(E_B)。用于区分两个句子。位置嵌入(Position Embeddings) :和原始Transformer的位置编码作用相同,但这里是可学习的参数,而不是固定的正弦函数。
输入格式 :
[CLS] 第一句 [SEP] 第二句 [SEP]
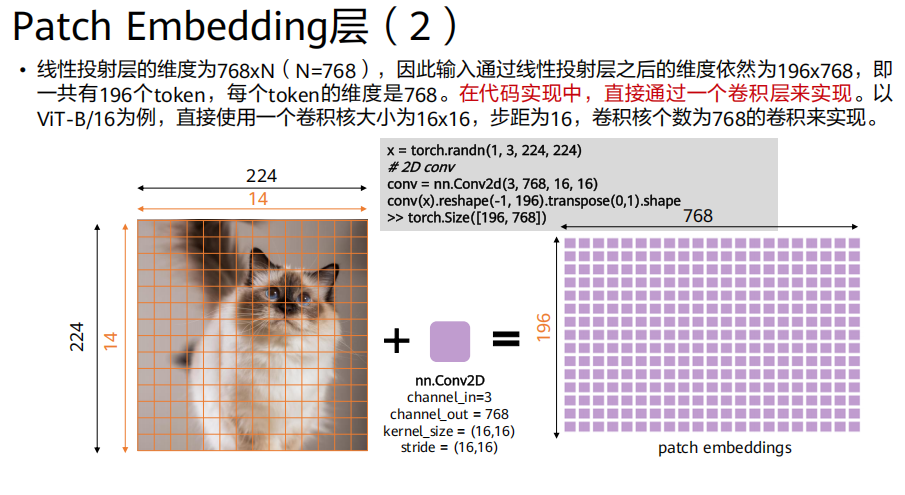
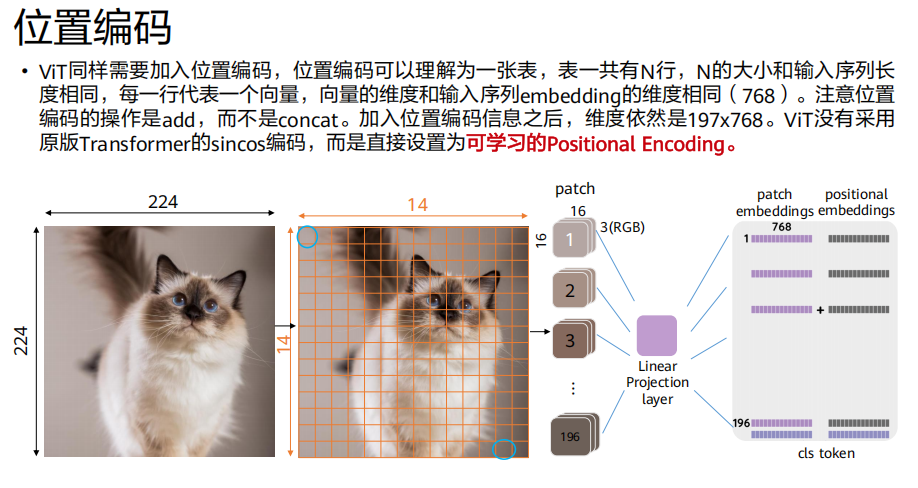
ViT(Vision Transformer)
- 输入图像 (
224x224x3)
Patch Embedding层:
生成
(224/16)^2 = 196个图像块。每个块投影为
768维向量 → 得到196x768的矩阵。拼接
[class] token(1x768) → 得到197x768的矩阵。加上位置嵌入 (
197x768) → 最终输入197x768。




由 L个 相同的编码器层堆叠而成(ViT-Base: L=12)。
每个编码器层 = 多头自注意力 (MSA) + 多层感知机 (MLP) ,每个子层前有层归一化 (LayerNorm) ,并配有残差连接 (Add)。
注意 :这里的自注意力是全局的 ,意味着每个图像块都能与其他所有图像块直接交互,从而捕获全局依赖关系。

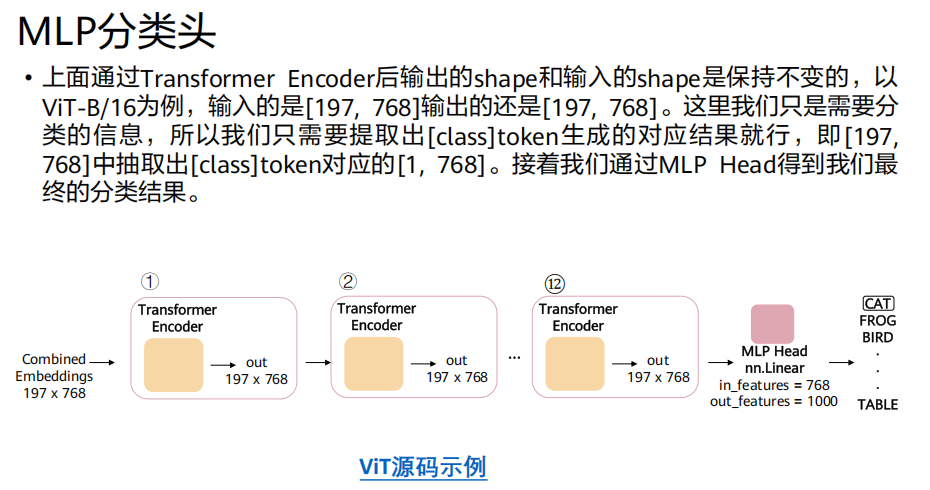
Transformer编码器的输出是
197x768的矩阵。我们只取
[class] token对应的输出向量 (第一行,1x768)。将这个向量送入一个小型MLP(通常是两层全连接层),得到最终的分类结果(如ImageNet的1000个类别)。