从零开始的C语言:文件操作与数据管理(下)(fseek,ftell,rewind,文件的编译和链接)
前言
本篇内容将继续为大家讲解文件操作
ftell
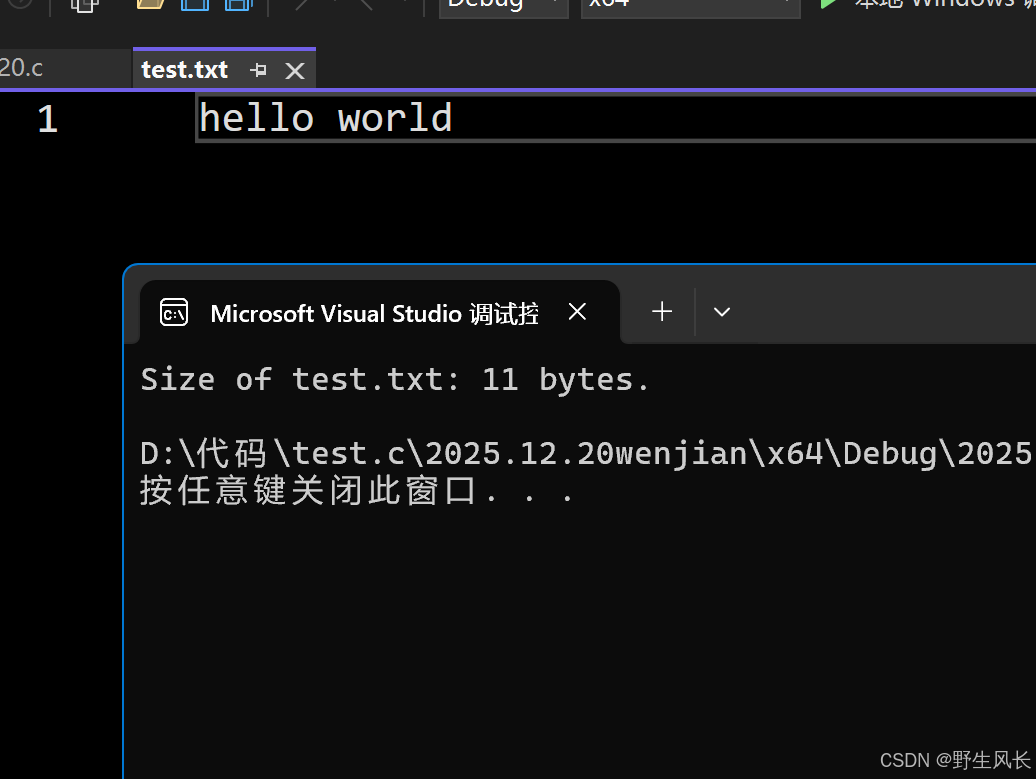
c
int main()
{
FILE* pFile;
long size;
pFile = fopen("test.txt", "rb");
if (pFile == NULL)
perror("Error opening file");
else
{
fseek(pFile, 0, SEEK_END);//从末尾指针开始读取0个字符------文件末尾
size = ftell(pFile);
fclose(pFile);
printf("Size of test.txt: %ld bytes.\n", size);//返回所有字节
}
return 0;
}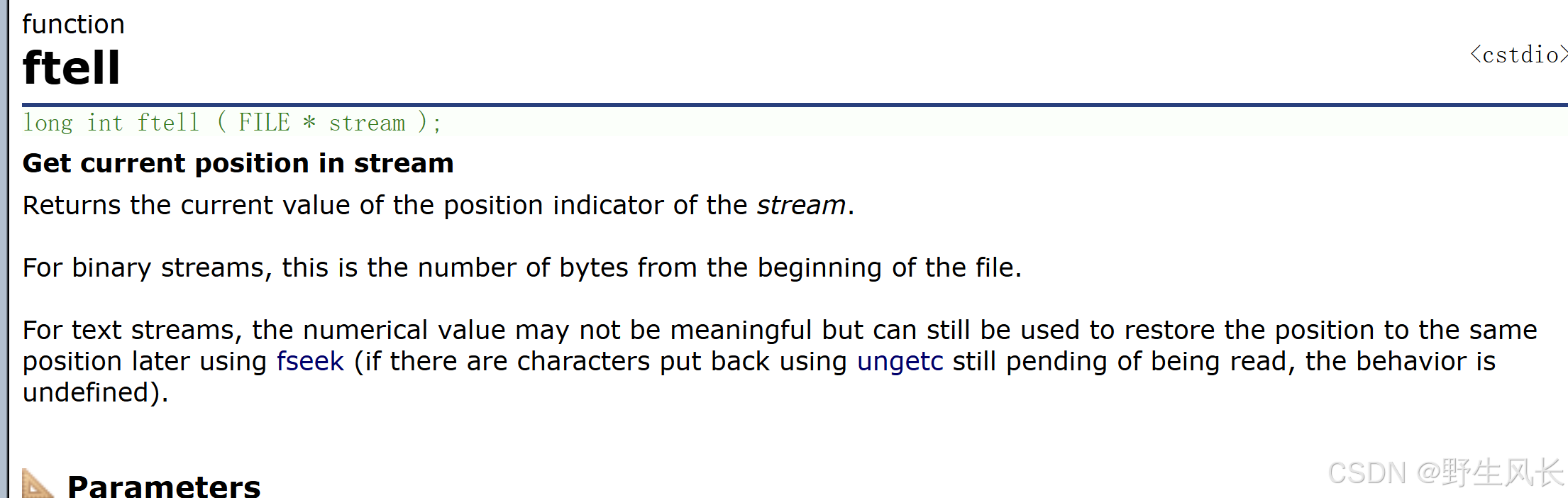
ftell是指返回的偏移量
常常与fseek一起搭配使用
代码结果如下
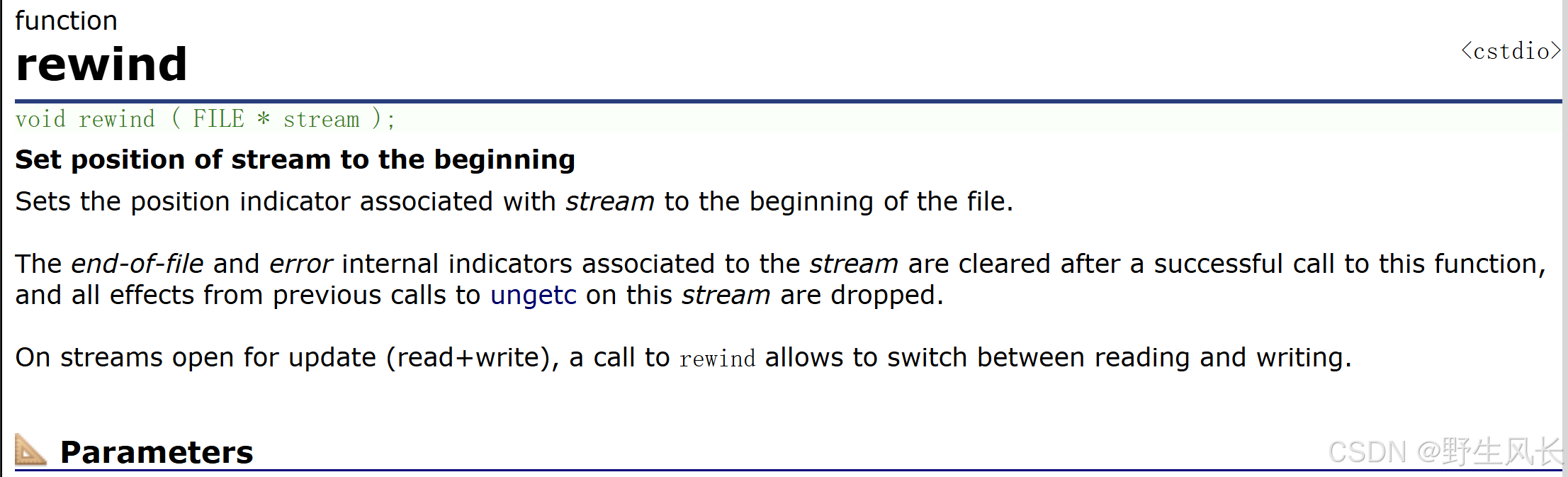
rewind
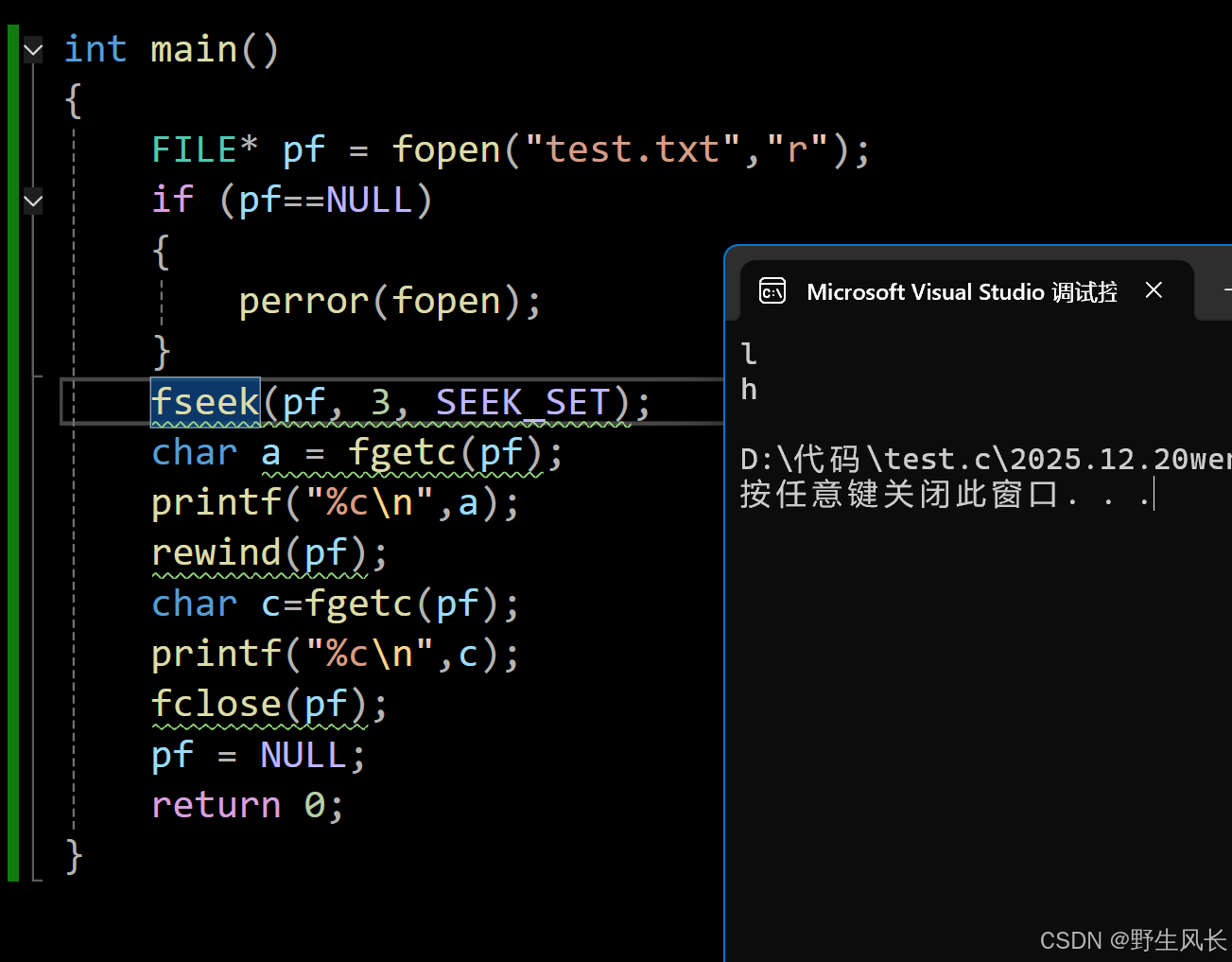
c
int main()
{
FILE* pf = fopen("test.txt","r");
if (pf==NULL)
{
perror(fopen);
}
fseek(pf, 3, SEEK_SET);
char a = fgetc(pf);
printf("%c\n",a);
rewind(pf);
char c=fgetc(pf);
printf("%c\n",c);
fclose(pf);
pf = NULL;
return 0;
}文本内容:hello world
第一个偏移三个字符读取l,第二个文件指针回到初始位置读取h
⽂件读取结束的判定
feof
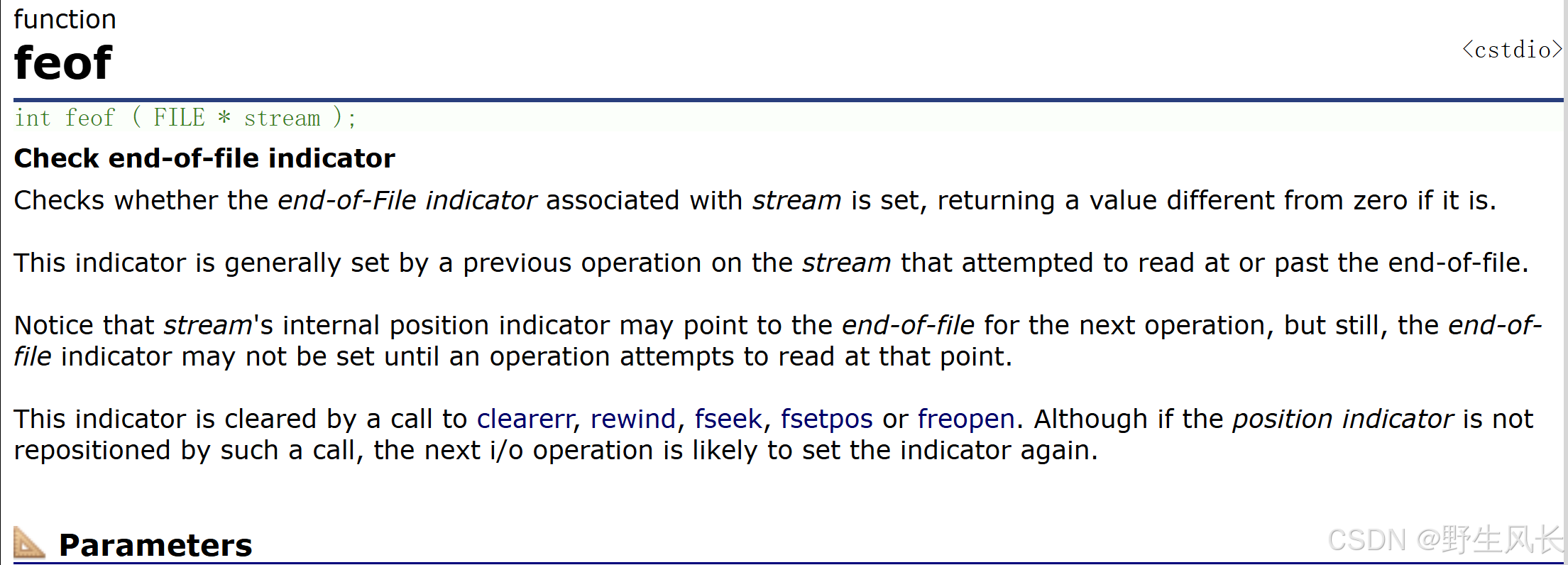
c
int feof ( FILE * stream );feof用来判定文件结束的原因,在这个函数有一个误区。
牢记:在⽂件读取过程中,不能⽤ feof 函数的返回值直接来判断⽂件的是否结束。
feof 的作⽤是:当⽂件读取结束的时候,判断读取结束的原因是否是:遇到⽂件尾结束。
ferror的作用是:当文件读取遇到错误时的判断
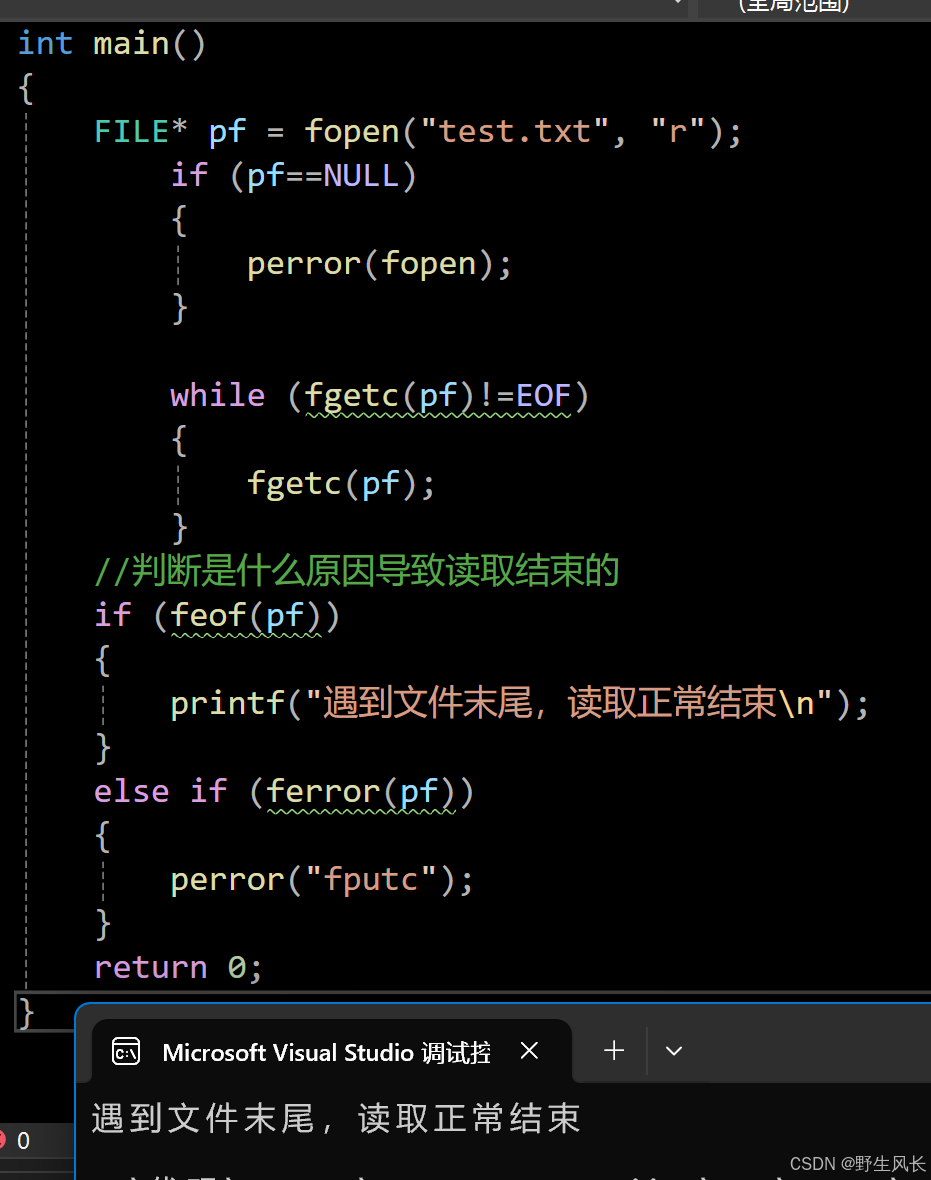
c
int main()
{
FILE* pf = fopen("test.txt", "r");
if (pf==NULL)
{
perror(fopen);
}
while (fgetc(pf)!=EOF)
{
fgetc(pf);
}
//判断是什么原因导致读取结束的
if (feof(pf))
{
printf("遇到文件末尾,读取正常结束\n");
}
else if (ferror(pf))
{
perror("fputc");
}
return 0;
}⽂本⽂件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets )
例如:
• fgetc 判断是否为 EOF .
• fgets 判断返回值是否为 NULL
⼆进制⽂件的读取结束判断,判断返回值是否⼩于实际要读的个数。
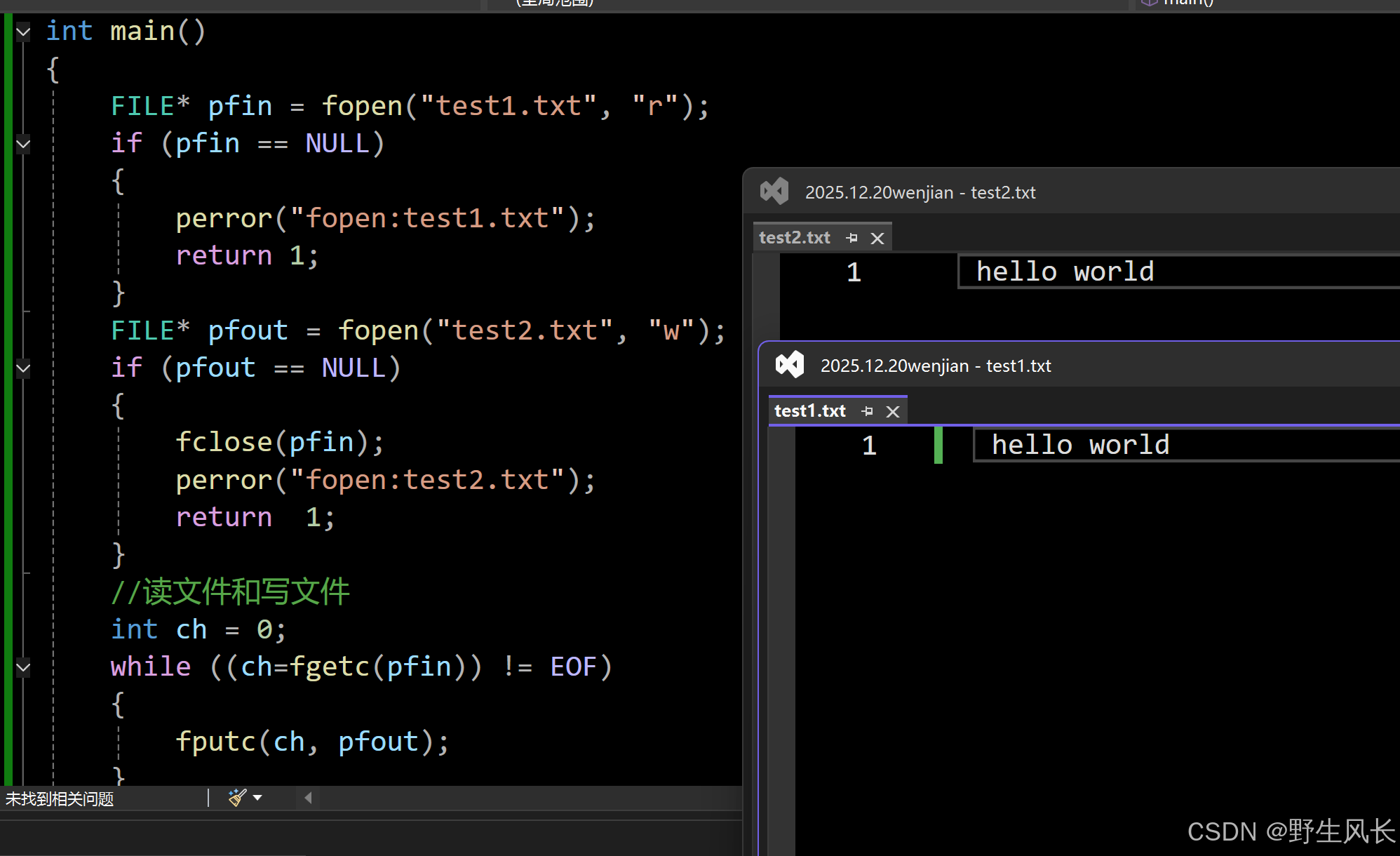
文件的copy
c
//拷贝文件:test1.txt ---> test2.txt
int main()
{
FILE* pfin = fopen("test1.txt", "r");
if (pfin == NULL)
{
perror("fopen:test1.txt");
return 1;
}
FILE* pfout = fopen("test2.txt", "w");
if (pfout == NULL)
{
fclose(pfin);
perror("fopen:test2.txt");
return 1;
}
//读文件和写文件
int ch = 0;
while ((ch=fgetc(pfin)) != EOF)
{
fputc(ch, pfout);
}
fclose(pfin);
pfin = NULL;
fclose(pfout);
pfout = NULL;
return 0;
}
文件的编译和链接
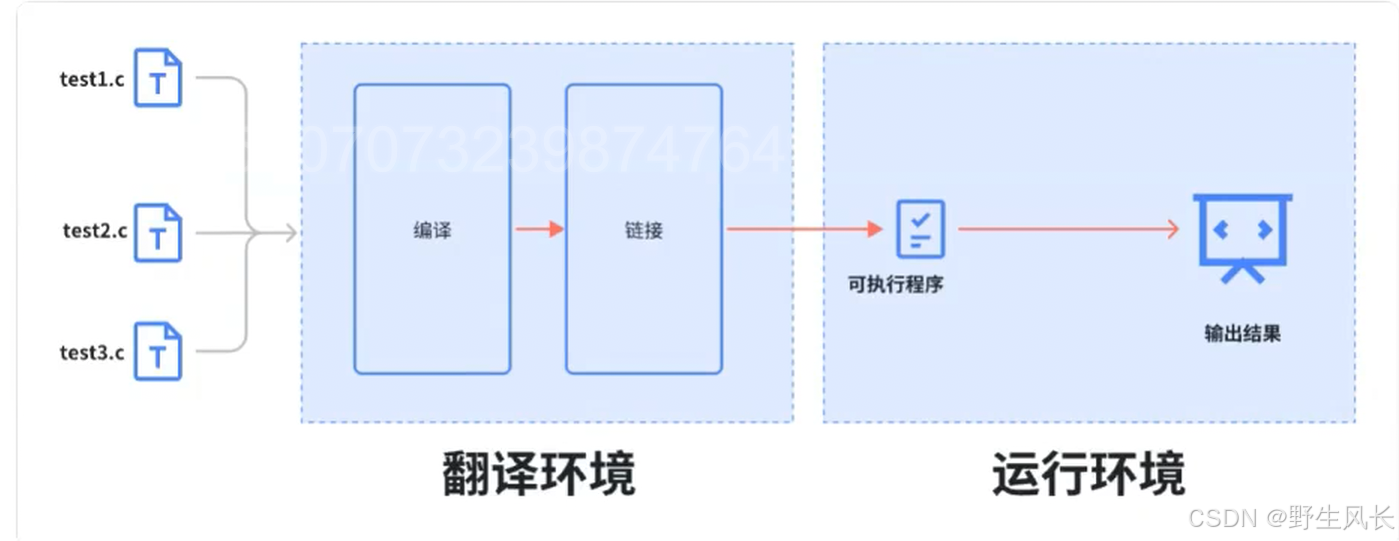
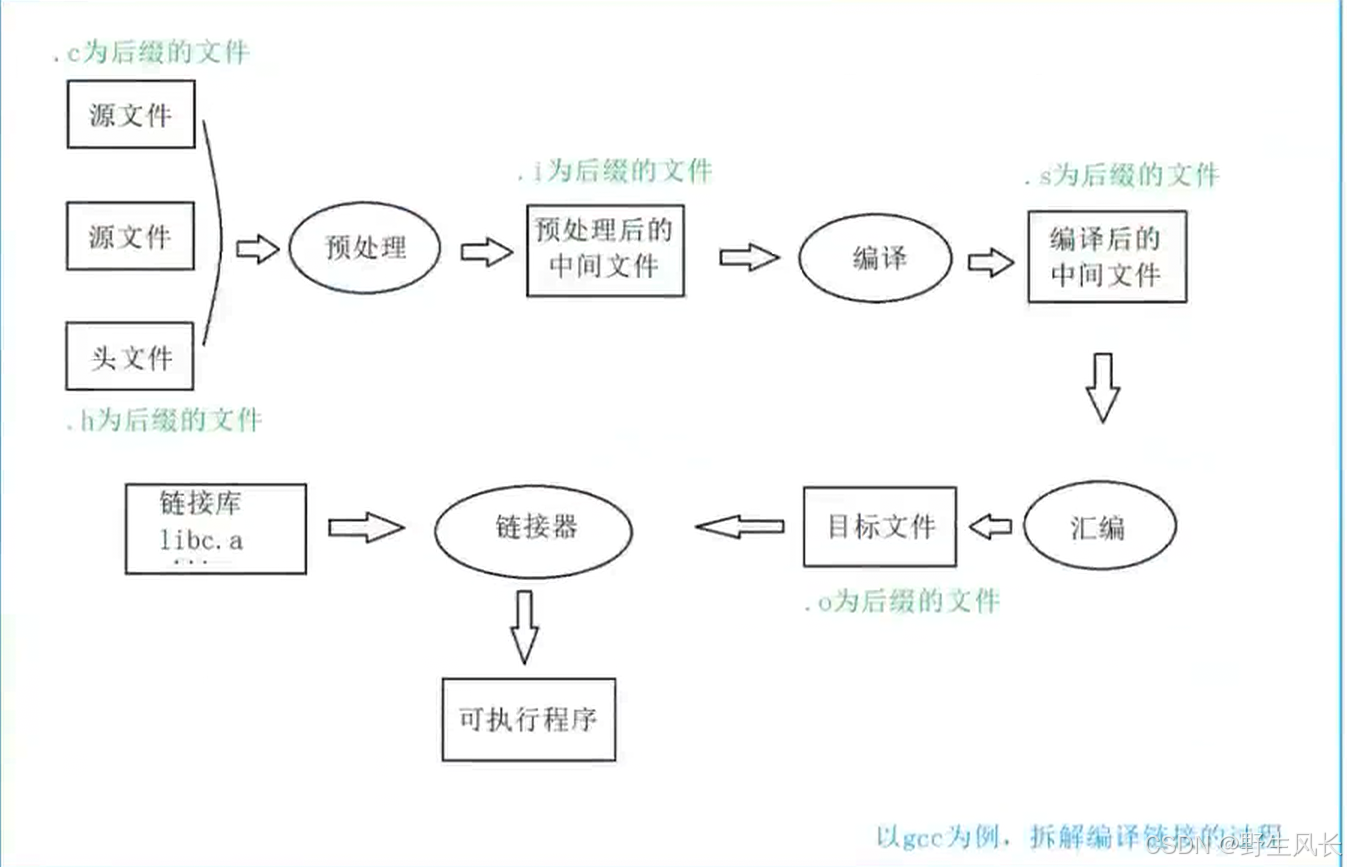
1. 翻译环境和运⾏环境
在ANSIC的任何⼀种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执⾏的机器指令(⼆进制指令)。 第2种是执⾏环境,它⽤于实际执⾏代码。
2. 翻译环境
那翻译环境是怎么将源代码转换为可执⾏的机器指令的呢?这⾥我们就得展开开讲解⼀下翻译环境所做的事情。
其实翻译环境是由编译和链接两个⼤的过程组成的,⽽编译⼜可以分解成:预处理(有些书也叫预编译)、编译、汇编三个过程。
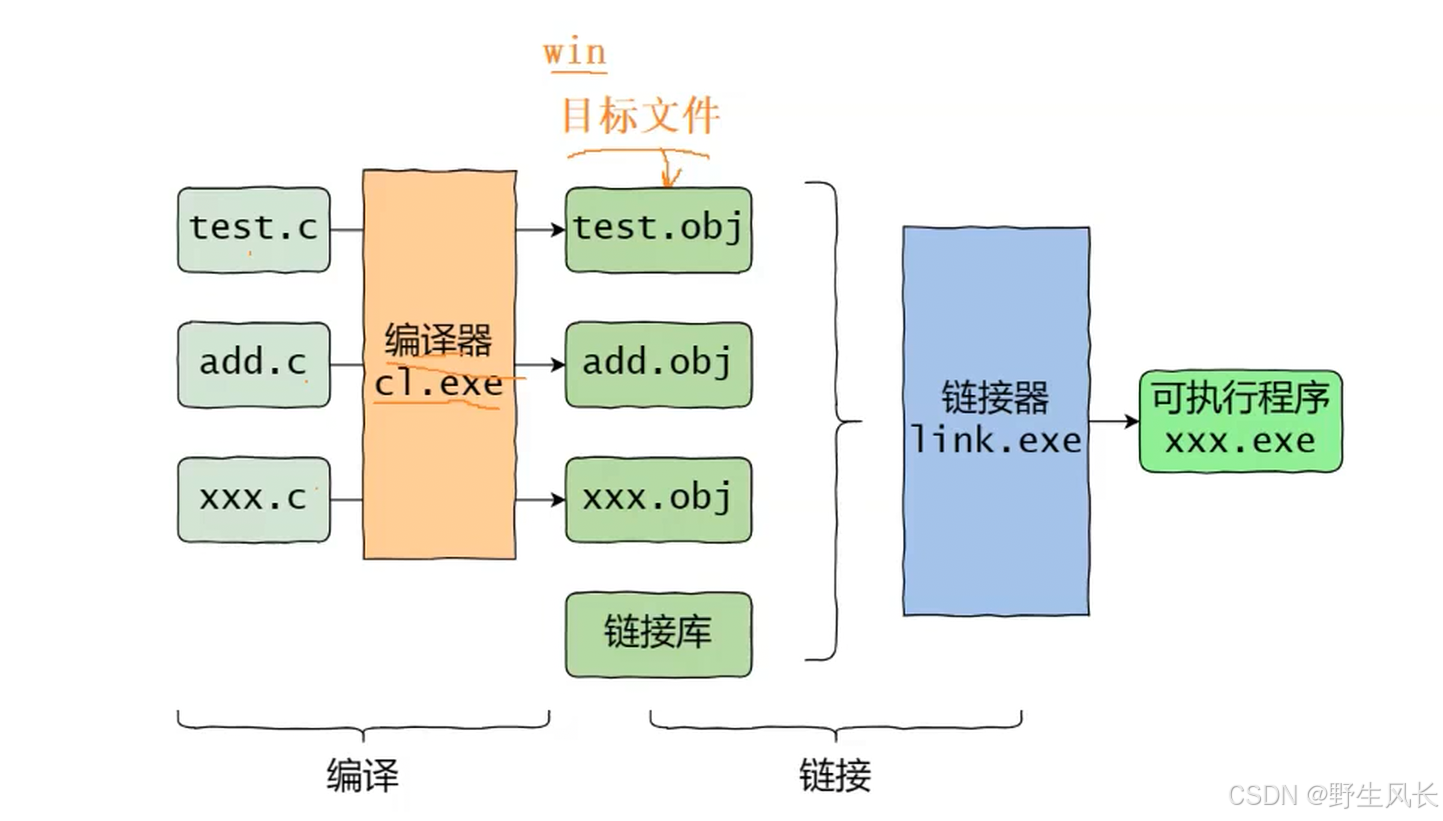
⼀个C语⾔的项⽬中可能有多个链接.c ⽂件⼀起构建,那多个.c⽂件如何⽣成可执⾏程序呢?
• 多个.c⽂件单独经过编译器,编译处理⽣成对应的⽬标⽂件。
• 注:在Windows环境下的⽬标⽂件的后缀是
.obj,Linux环境下⽬标⽂件的后缀是.o
• 多个⽬标⽂件和链接库⼀起经过链接器处理⽣成最终的可执⾏程序。
• 链接库是指运⾏时库(它是⽀持程序运⾏的基本函数集合)或者第三⽅库。
2.1 预处理(预编译)
在预处理阶段,源⽂件和头⽂件会被处理成为.i为后缀的⽂件。在gcc环境下想观察⼀下,对test.c ⽂件预处理后的.i ⽂件,命令如下:
注:可以在vscode上观察
gcc -E test.c -o test.i
预处理阶段主要处理那些源⽂件中#开始的预编译指令。⽐如:
• 将所有的#define 删除,并展开所有的宏定义#include,#define
•处理所有的条件编译指令,如
:#if、#ifdef、#elif、#else、#endif
• 处理#include预编译指令,将包含的头⽂件的内容插⼊到该预编译指令的位置。这个过程是递归进⾏的,也就是说被包含的头⽂件也可能包含其他⽂件。
• 删除所有的注释
• 添加⾏号和⽂件名标识,⽅便后续编译器⽣成调试信息等。
• 保留所有的#pragma 的编译器指令,编译器后续会使⽤。
经过预处理后的.i⽂件中不再包含宏定义,因为宏已经被展开。并且包含的头⽂件都被插⼊到⽂件中。所以当我们⽆法知道宏定义或者头⽂件是否包含正确的时候,可以查看预处理后的 .i ⽂件来确认。
2.2 编译
编译过程就是将预处理后的⽂件进⾏⼀系列的:词法分析、语法分析、语义分析及优化,⽣成相应的汇编代码⽂件。
编译过程的命令如下:
gcc -S test.i -o test.s
对下⾯代码进⾏编译的时候,会怎么做呢?假设有下⾯的代码
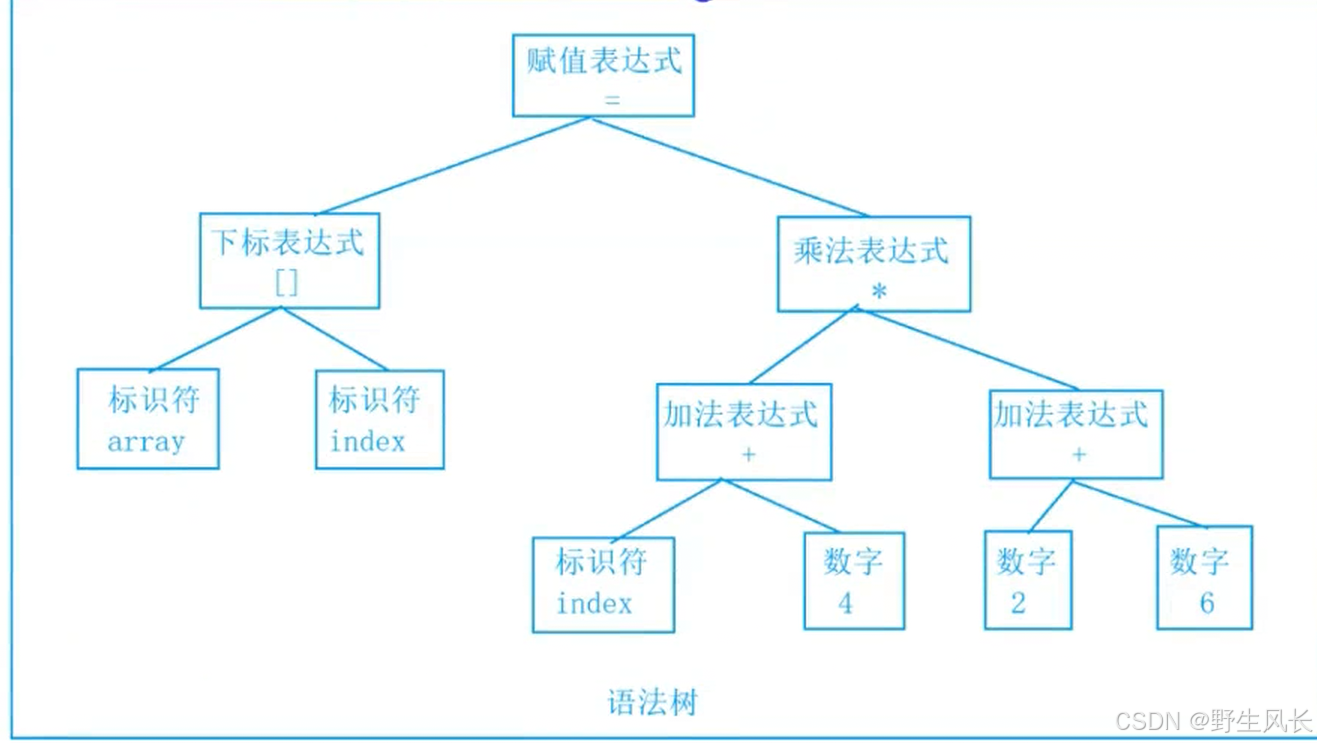
arrayindex = (index+4)*(2+6);
2.2.1 词法分析
将源代码程序被输⼊扫描器,扫描器的任务就是简单的进⾏词法分析,把代码中的字符分割成⼀系列的记号(关键字、标识符、字⾯量、特殊字符等)。上⾯程序进⾏词法分析后得到了16个记号:

2.2.2 语法分析
接下来语法分析器,将对扫描产⽣的记号进⾏语法分析,从⽽产⽣语法树。这些语法树是以表达式为节点的树。
2.3 汇编
汇编器是将汇编代码转变成机器可执⾏的指令(2进制的指令),每⼀个汇编语句⼏乎都对应⼀条机器指令。就是根据汇编指令和机器指令的对照表⼀⼀的进⾏翻译,也不做指令优化。
汇编的命令如下:
gcc -c test.s -o test.o
2.4 链接
链接是⼀个复杂的过程,链接的时候需要把⼀堆⽂件链接在⼀起才⽣成可执⾏程序。
链接过程主要包括:地址和空间分配,符号决议和重定位等这些步骤。链接解决的是⼀个项⽬中多⽂件、多模块之间互相调⽤的题。
3. 运⾏环境
- 程序必须载⼊内存中。在有操作系统的环境中:⼀般这个由操作系统完成。在独⽴的环境中,程序的载⼊必须由⼿⼯安排,也可能是通过可执⾏代码置⼊只读内存来完成。
- 程序的执⾏便开始。接着便调⽤main函数。
- 开始执⾏程序代码。这个时候程序将使⽤⼀个运⾏时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使⽤静态(static)内存,存储于静态内存中的变量在程序的整个执⾏过程⼀直保留他们的值。
- 终⽌程序。正常终⽌main函数;也有可能是意外终⽌。
完