FINN 是一个由 Xilinx(现 AMD Research)集成通信与 AI 实验室开源的机器学习框架,它提供了一个端到端的方案,用于探索和实现 量化神经网络(QNN)在 FPGA 上的高效推理加速器。它不是通用的神经网络加速通用库,而是通过 协同设计(co-design) 和 数据流体系结构生成,为每个网络构建定制的数据流式硬件架构。

📌 FINN 的定位
FINN 的核心目标是:
👉 从 训练好的量化神经网络(Quantized Neural Networks, QNN) 入手
👉 经过一系列编译与变换
👉 自动生成 高效的 FPGA 数据流加速器
👉 并能以极低延迟、高吞吐率运行推理任务
与传统库不同,FINN 不只是一个简单的硬件调用层,而是 编译器级框架:即输入网络模型,输出完整可合成的硬件设计。
🔍 核心特点
💡 1. 端到端数据流架构生成
FINN 主要面向量化神经网络,通过构建 数据流架构(dataflow architecture),使每层网络的计算和数据移动都以定制流方式并行执行,因此能够达到 低延迟和高性能 推理效果。
⚙️ 2. HLS + RTL 模块模板库
FINN 内置大量基于 Vitis HLS 和 RTL 的流式组件模板,每个组件代表神经网络中的一层,如卷积、线性层等,这些模块可以按需组合生成硬件设计。
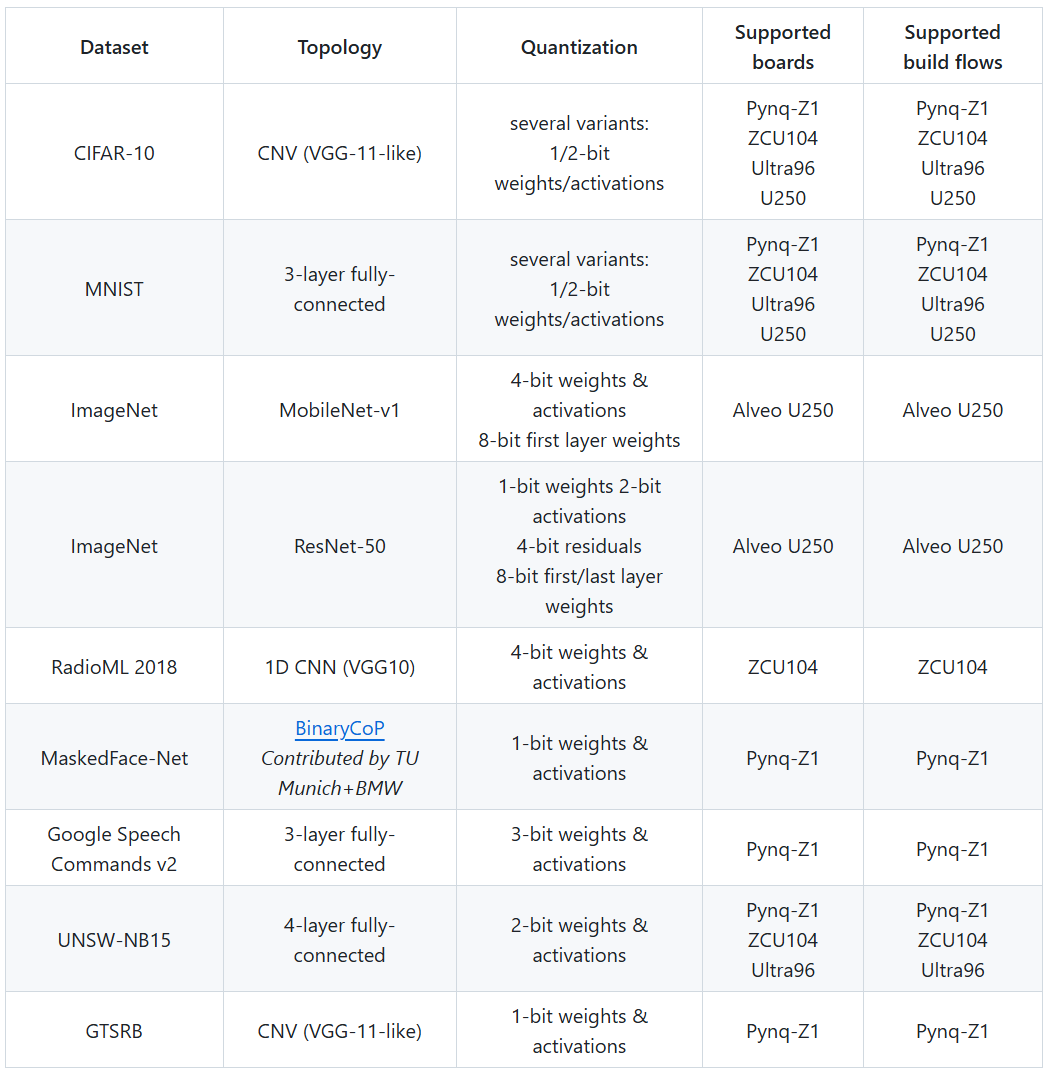
🎓 3. 示例丰富 + 可快速设计空间探索
官方提供了大量示例,涵盖从量化模型训练、ONNX 导入,到 FPGA 工程生成、综合实现的完整流程,支持参数调优、吞吐量 / 资源权衡探索。
🧠 4. 高吞吐 & 低延迟
生成的硬件通常通过数据流水线实现可达亚微秒级延迟,并具备 FPGA 的高并行性能,适合实时、边缘推理场景。
🧠 技术细节与工作流
FINN 的编译过程一般包括:
- 训练与量化
使用支持量化的训练工具(例如 Brevitas + PyTorch)对模型进行训练与量化。
- ONNX 导出
将量化神经网络导出为 ONNX 格式,这一格式作为 FINN 的输入。
- FINN 编译器处理
FINN 负责读取 ONNX 模型,并执行变换、优化,然后生成对应的硬件模块描述。
- 硬件集成与部署
编译器生成的模块可以通过 Vivado 或 Vitis 合成为可跑在 FPGA 上的 bitstream,并配合驱动完成部署。
整个流程可以停在任意阶段:比如只生成硬件 IP 供在更大系统中复用,也可以走到 完整 bitstream + 驱动部署。
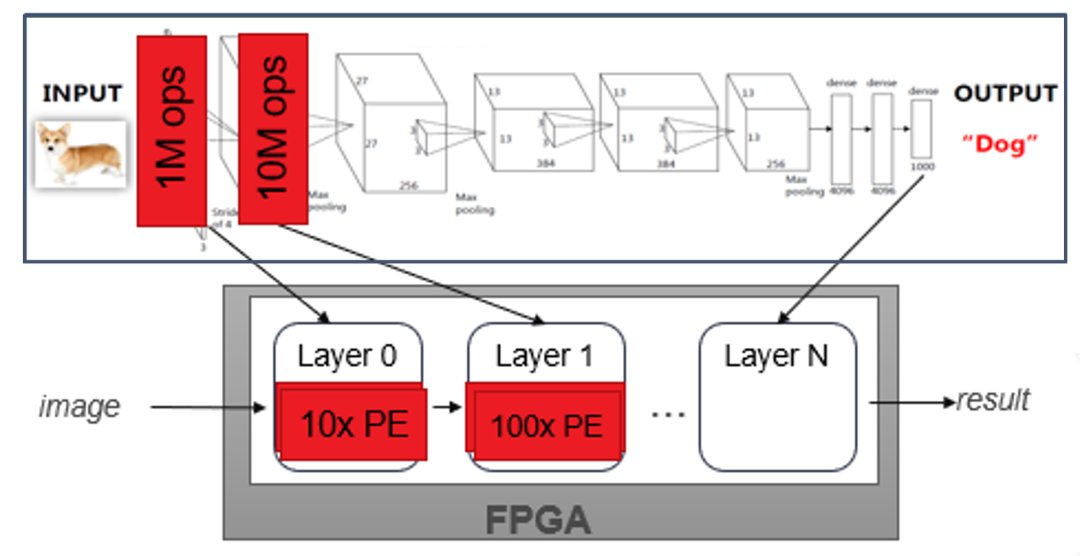
神经网络加速器示例
🧠 为什么 FINN 与众不同?
✅ 定制化而非通用加速
FINN 不提供一个通用神经网络核,而是针对每个 QNN 构建"定制化的硬件流水线"。此策略能极限压榨 FPGA 资源以换取最高性能。
✅ 研究与工程结合平台
作为开源项目,它不仅适合工业应用,还为跨软硬件堆栈的研究提供了完整的平台。研究者可以直接介入量化策略、架构生成与优化流程。
📌 适用场景
FINN 特别适合用于:
⭐ 边缘 AI 推理加速
⭐ 低延迟、高吞吐神经网络应用
⭐ 量化神经网络研究
⭐ FPGA 教学/原型开发
尤其是当你需要在 FPGA 上运行量化深度学习模型,并希望获得比通用 GPU 更低的延迟、更低的能耗时,FINN 提供了一条成熟技术路径。
📍结语
FINN 是一个真正意义上的 FPGA 神经网络加速编译器框架,它将量化神经网络与 FPGA 加速实践紧密结合。通过 ONNX、Brevitas、Vivado/Vitis 等生态协同工作,FINN 助力开发者把高效的推理加速器从软硬件无缝推进到可运行的 FPGA 设计中。由于其完整的开源体系,无论是科研探索还是工程落地,它都是 AI & FPGA 交叉领域中不可忽视的项目
开源地址
主页:
Vitis HLS库: