
1. 摘要
最新研究表明,深度神经网络对输入图像的微小扰动极为敏感,因此出现了 adversarial examples(对抗样本)。尽管这一特性通常被认为是学习模型的弱点,但我们探讨了它是否可能带来益处。我们发现神经网络可以学习利用无形的扰动来编码大量有用信息。事实上,人们可以利用这一能力来隐藏数据。
我们共同训练编码器和解码器网络,给定输入消息和载体图像(Cover Image),编码器生成一个视觉上无法区分的编码图像,解码器可以从中恢复原始消息。
我们证明这些编码在现有数据隐藏算法中具有竞争力,并且可以对噪声具有鲁棒性:我们的模型能够在编码图像中重建隐藏信息,尽管存在高斯模糊、像素丢失、裁剪和JPEG压缩。
尽管JPEG是不可微的,我们证明了可以通过可微近似训练一个稳健的模型。最后,我们证明对抗训练能提升编码图像的视觉质量。
Keywords: Adversarial Networks, Steganography, Robust blind water marking, Deep Learning, Convolutional Networks

2. 方法
我们的目标是开发一个可学习的端到端图像隐写术和水印模型,使其能够对任意类型的图像畸变具备鲁棒性。
网络结构由四个主要组成部分组成:编码器 E θ E_\theta Eθ、无参数噪声层 N N N、解码器 D ϕ D_\phi Dϕ和对抗判别器 A γ A_\gamma Aγ。 θ θ θ、 ϕ \phi ϕ和 γ γ γ都是可训练参数。编码器 E θ E_θ Eθ接收形状 C × H × W C×H×W C×H×W的载体图像 I c o I_{co} Ico和长度 L L L的二进制秘密消}息 M i n ∈ { 0 , 1 } L M_{in}∈ \{0,1\}^L Min∈{0,1}L,并生成与 I c o I_{co} Ico形状相同的编码图像(即 stego image) I e n I_{en} Ien。噪声层 N N N接收 I c o I_{co} Ico和 I e n I_{en} Ien作为输入,并对编码图像进行distort,生成噪声图像 I n o I_{no} Ino。解码器 D D D从 I n o I_{no} Ino那里恢复了消息 M o u t M_{out} Mout。同时,给定图像 I ~ ∈ { I c o , I e n } \tilde{I} \in \left\{ I_{co}, I_{en} \right\} I~∈{Ico,Ien},即载体图像或编码图像,判别器预测 A ( I ~ ) ∈ 0 , 1 A(\tilde{I})\in0,1 A(I~)∈0,1,即 I ~ \tilde{I} I~是编码图像(encoded image)的概率。
编码图像应在视觉上与封面图片相似。我们将图像失真损耗, I c o I_{co} Ico与 I e n I_{en} Ien之间的 L 2 L_2 L2距离,来表征"相似性"(similarity):
L I ( I c o , I e n ) = ∥ I c o − I e n ∥ 2 2 C H W \mathcal{L}I(I{co}, I_{en}) =\frac{\left\| I_{co} - I_{en} \right\|_2^2}{CHW} LI(Ico,Ien)=CHW∥Ico−Ien∥22
adversarial loss (对抗损失),指判别器检测编码图像 I e n I_{en} Ien的能力:
L G ( I e n ) = log ( 1 − A ( I e n ) ) \mathcal{L}G(I{en})=\log(1-A(I_{en})) LG(Ien)=log(1−A(Ien))
判别器会因预测而产生分类损失(classification loss):
L A ( I c o , I e n ) = log ( 1 − A ( I c o ) ) + log ( A ( I e n ) ) \mathcal L_A(I_{co},I_{en})=\log(1-A(I_{co}))+\log(A(I_{en})) LA(Ico,Ien)=log(1−A(Ico))+log(A(Ien))
解码后的消息应与编码消息相同。我们利用原始消息与解码消息之间的 l 2 l_2 l2 距离施加消息失真损耗(message distortion loss):
L M ( M i n , M o u t ) = ∥ M i n − M o u t ∥ 2 2 L \mathcal{L}M(M{in},M_{out})=\frac{\left\| M_{in} - M_{out} \right\|_2^2}{L} LM(Min,Mout)=L∥Min−Mout∥22
我们对 θ θ θ, ϕ \phi ϕ 进行随机梯度下降,以最小化输入消息和图像分布上的以下损失:
E I c o , M i n L M ( M i n , M o u t ) + λ I L I ( I c o , I e n ) + λ G L G ( I e n ) \mathbb{E}{I{co}, M_{in}} \left \\mathcal{L}_M(M_{in}, M_{out}) + \\lambda_I \\mathcal{L}_I(I_{co}, I_{en}) + \\lambda_G \\mathcal{L}_G(I_{en}) \\right EIco,MinLM(Min,Mout)+λILI(Ico,Ien)+λGLG(Ien)
其中, λ I \lambda_I λI和 λ G \lambda_G λG控制损失的相对权重。同时,我们训练判别器 A γ A_γ Aγ以在相同分布下最小化以下损耗:
E I c o , M i n L A ( I c o , I e n ) \mathbb{E}{I{co}, M_{in}} \left \\mathcal{L}_A(I_{co}, I_{en}) \\right EIco,MinLA(Ico,Ien)
2.1 Network Architecture
网络结构如下:
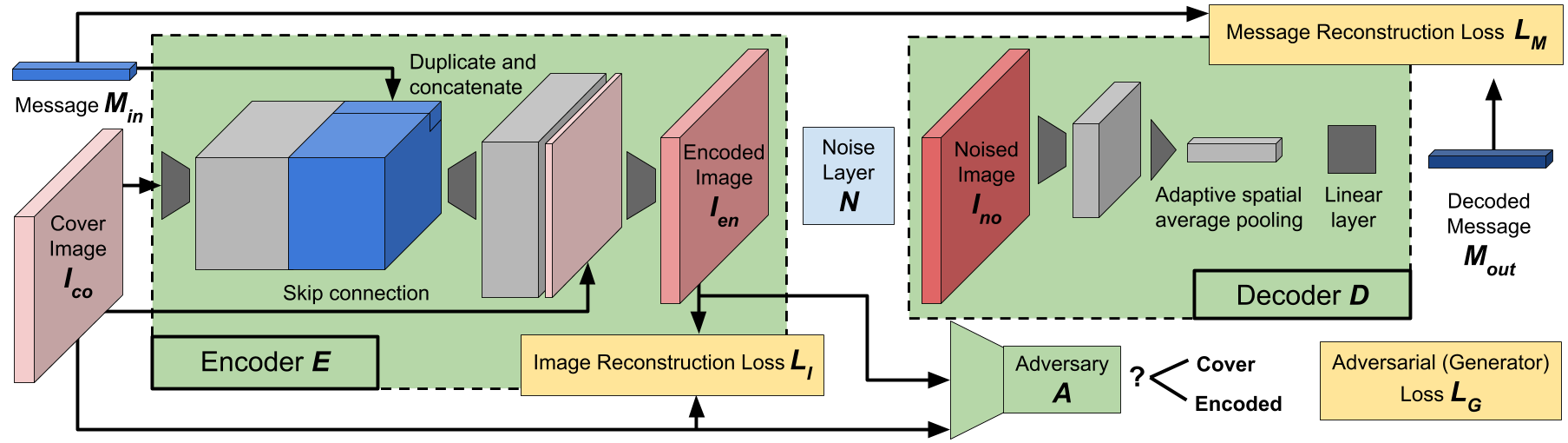

编码器(encoder )首先对输入图像 I c o I_{co} Ico执行卷积操作,以生成若干中间特征表示。接下来,我们旨在以一种便于编码器学习将消息部分嵌入到输出任意空间位置的方式,融入长度为 L L L的消息输入。为此,我们对该消息进行空间维度复制,并将这个 "消息体"(message volume)与encoder的中间特征表示进行拼接(concatenation) 。这一设计确保了下一层中的每个卷积核在对各个空间位置执行卷积运算时,都能访问到完整的消息信息。经过多层卷积运算后,编码器输出编码图像 I e n I_{en} Ien。
噪声层(noise layer )接收载体图像 I c o I_{co} Ico与编码图像 I e n I_{en} Ien作为输入,施加噪声处理后生成含噪图像 I n o I_{no} Ino。我们不强制要求 I n o I_{no} Ino与 I e n I_{en} Ien保持维度一致,以此支持裁剪这类会改变数据维度的噪声建模。
解码器(decoder )则首先通过若干层卷积操作,在中间特征表示中生成 L L L个特征通道。然后对中间特征执行全局空间平均池化操作,生成一个与消息尺寸相同的向量 L L L------ 平均池化的设计确保模型能够处理不同空间维度的输入。接着,解码器通过一线性层输出预测消息。
对抗器(adversary)采用与解码器相似的结构,但最终输出的是二分类结果。
正如我们将看到的,通过变化消息长度 L L L、图像尺寸 C C C、 H H H、 W W W、噪声层 N N N 以及权重因子 λ I λ_I λI 和 λ G λ_G λG,上述网络结构可以很好地适应隐写术和水印。
2.2 Noise Layers
我们的模型需具备在各类图像失真下稳健隐藏信息的能力;为此,设计了六种不同类型的噪声层,分别实现不同形式的图像失真操作。所有失真类型的示例均展示于 Figure 3 中。

Identity layer 是最简单的类型:它保持编码图像 I e n I_{en} Ien不发生任何改变;
Dropout layer 与 Cropout layer 会抵消 encoder 产生的部分变换,通过融合载体图像 I c o I_{co} Ico与编码图像 I e n I_{en} Ien的像素来生成含噪图像 I n o I_{no} Ino。这两类噪声层均保留 I e n I_{en} Ien中占比为 p p p 的像素,其余像素取自 I c o I_{co} Ico;区别在于,Dropout是对每个像素独立做选择,而Cropout则保留 I e n I_{en} Ien中一个随机方形裁剪区域。
Gaussion layer 通过宽度为 σ \sigma σ 的高斯核对编码图像 I e n I_{en} Ien 进行模糊处理;
Crop layer 对编码图像做随机方形裁剪(尺寸为 H ′ × W ′ H' \times W' H′×W′),其中裁剪后与原图像的尺寸比 H ′ × W ′ H × W \frac{H' \times W'}{H \times W} H×WH′×W′ 满足 p ∈ ( 0 , 1 ) p \in (0,1) p∈(0,1)。
JPEG layer 对 I e n I_{en} Ien施加JPEG压缩,压缩质量因子 Q ∈ ( 0 , 100 ) Q \in (0,100) Q∈(0,100)。
需注意:所有 non-identity noise layers 均通过一个标量超参数控制失真强度------Dropout、Cropout 与 Crop 的超参数是保留 I e n I_{en} Ien 像素的占比 p p p;Gaussion 的超参数是核宽度 σ \sigma σ;JPEG层的超参数是质量因子 Q Q Q。
我们针对噪声层 N N N 开展了多类失真形式的扩展性实验。其中,Dropout、裁剪(Crop)与 Cropout 这三类操作主要作用于空间域,而高斯模糊与 JPEG 压缩则作用于频域。允许噪声层访问载体图像 I c o I_{co} Ico 也会使任务难度进一步提升。对于LSB算法而言,将每个被篡改像素替换为固定值的噪声层,其作用等价于一个二进制删除信道(binary erasure channel);而将编码图像像素替换为原始载体图像像素的噪声层,则对应一个二进制对称信道(binary symmetric channel)。后者的稳健性更难保证,原因在于解码器无法获知篡改发生的具体位置。同理,裁剪层不仅要求解码器具备输入尺寸无关性(即兼容任意尺寸输入),还不会向解码器提供裁剪区域 H ′ × W ′ H'\times W' H′×W′ 的来源信息,这进一步限制了解码器可利用的先验知识。
2.3 "Differentiating" the JPEG compression
尽管网络采用梯度下降法训练,但测试阶段的噪声无需具备可微分性(differentiable)。我们通过在可微分近似操作上训练,成功实现了对不可微分 JPEG 压缩的稳健性。
JPEG 压缩的流程为:将图像划分为 8 × 8 8 \times 8 8×8 的区域,在每个区域内执行离散余弦变换(DCT,本质是将 R 64 \mathbb{R}^{64} R64 空间的基进行变换),随后将得到的频域系数量化至不同粗糙程度。这一过程仅保留感知相关的信息。但量化步骤是不可微分的,这导致 JPEG 压缩无法直接用于基于梯度的优化过程。
然而,从信息论角度看,对数值进行量化等价于限制该 "channel" 可传输的信息量。为限制特定频域信道的信息传递量,我们设计了模拟 JPEG 压缩的噪声层。这些噪声层通过步长为 8 的 8×8 卷积层实现 DCT 变换 ------ 其中每个卷积核对应 DCT 变换的一个基向量。此时,网络的激活值即代表编码图像的 DCT 域系数。随后,我们对 DCT 系数执行 Masking / Dropout 操作以限制信息流:高频系数更易被 masked / dropped(详见Figure 4)。最终,通过转置卷积实现逆 DCT 变换,生成含噪图像 I n o I_{no} Ino。

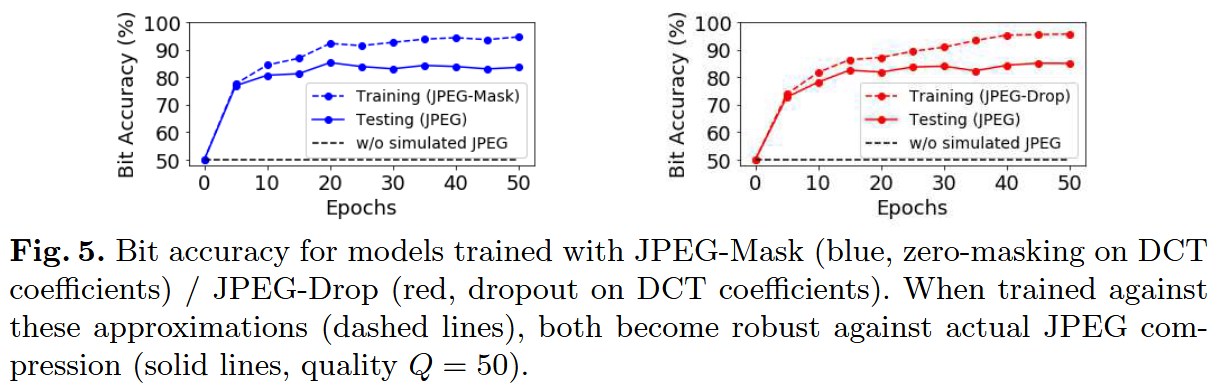
我们将对应的层命名为 JPEG-Mask 与 JPEG-Drop。JPEG-Mask 层采用固定掩码策略:在 Y Y Y 通道保留 25 个低频 DCT 系数,在 U U U、 V V V 通道各保留 9 个(这与 JPEG 的设计一致 ------JPEG 也会在 Y Y Y 通道保留更多信息),其余系数置零。
JPEG-Drop 层则对系数执行渐进式 Dropout:在实际 JPEG 压缩中,某一系数的量化程度越粗糙,在我们的模拟中该系数被置零的概率就越高。两种方法均能成功训练出对真实 JPEG 压缩具备稳健性的模型(详见Figure 5)。
2.4 Implementation details
所有模型均基于 COCO 数据集的 10,000 张图像进行训练,图像会被调整至实验指定的尺寸。评估过程使用训练阶段未见过的 1000 张图像测试集。消息的每个比特均通过均匀随机采样生成。梯度下降优化器采用 Adam,学习率设为 10 − 3 10^{-3} 10−3,其余超参数为默认值。所有模型的训练批次大小为 12,训练轮数(epoch)为 200;若需适配多种噪声层,则训练轮数增加至 400。
3. 实验
从三个维度评估模型:
- 容量(capacity):每单位图像比特可隐藏的消息比特数;
- 保密性(secrecy):检测编码图像的难度;
- 鲁棒性(robustness):方法在图像失真场景下的成功执行程度;
评估指标:采用多类指标衡量模型在上述维度的性能:
- 容量:主要通过每像素比特数(BPP)*衡量,即编码图像每像素可隐藏的消息比特数,可表示为 L / ( H W C ) L/(HWC) L/(HWC) ( L L L为消息长度, H W C HWC HWC为图像的高×宽×通道数);
- 保密性:主要通过检测率 (detection rate)衡量 ------ 训练一个现代隐写分析器,用于区分载体图像与隐写图像,其测试集准确率即为检测率。同时,以峰值信噪比(PSNR)作为保密性的代理指标:载体图像与隐写图像的失真程度越高,隐写图像越易被检测。
- 鲁棒性:通过比特准确率(bit accuracy)衡量 ------ 在测试阶段对编码器与解码器之间的图像施加不同失真后,统计输入消息 M M M 与预测消息 M ′ M' M′ 的相同比特数占比。
这些指标中的多数存在矛盾关系:容量更高的模型通常会牺牲保密性---因为在图像中隐藏更多信息必然导致更大的图像失真;对噪声高度稳健的模型则往往会牺牲容量或保密性---因为消息需要以冗余方式编码在图像中。
从某种意义上,隐写术与水印技术处于该问题谱的两端,二者分别优先考虑不同维度:隐写术强调保密性,而水印技术侧重稳健性。由于 HiDDeN 涵盖一整套数据隐藏算法,我们可通过调整消息长度 L L L、使用不同噪声层等方式,灵活训练出侧重不同维度的模型。
3.1 Steganography: Capacity and Secrecy
我们训练模型在 16×16 的灰度图像中编码长度为 ( L L L=52) 的二进制消息,此时模型的容量为 52/(16×16)≈0.203 BPP。对于更大尺寸的图像,我们通过延长消息长度来保持编码容量 --- 模型会在图像的每个 16×16 块上编码 L L L 比特的消息块。
由于隐写术通常假设传输过程无噪声,我们将噪声层 N N N 设为 恒等映射层(identity layer)。我们首先在Figure 6 中与传统方法 4,10,11 进行对比,随后在 Figure 7 中与基于神经网络的方法 21 进行对比。
Image quality
我们与三种隐写方法对比:HUGO 4、WOW 10、S-UNIWARD 11。每种方法均配置为 0.2 BPP 的容量,以匹配我们的模型。所有方法均在 BOSS 数据集 31 的 512×512 载体图像上测试(该数据集是隐写算法的通用测试基准)。由于我们的模型是在 COCO 数据集上训练的,这体现了其对新数据的泛化能力。Fiigure 6 展示了我们的方法与 HUGO 生成的cover and stego image 示例(其他经典基线的结果与 HUGO 无明显差异)。HUGO 与我们的方法生成的编码图像,在视觉上均与载体图像无差异。
Capacity
我们的模型在 BPP 指标上与基线方法接近(0.203 vs 0.200)。神经网络隐写的一个劣势是解码器可能出错:如Figure 6 所示,我们的方法能准确重建消息,但并非完全无误差,错误率低于 10 − 5 10^{-5} 10−5。若需更高准确率,可引入纠错码。
Secrecy
我们通过训练隐写分析器 ATS 来区分所有方法的 Cover 与 Stego 图像,以此衡量保密性(结果见 Figure 6)。遵循原作者的最佳性能建议 30,我们为每种算法向 ATS 提供小型数据集:250 张载体图像与 250 张隐写图像。
ATS 从该无标签测试集中生成同名的人工训练集:通过对数据重复应用隐写算法,再用此人工训练集训练监督分类器;最终评估该分类器在测试集中识别隐写图像的能力。

我们针对模型评估了两种威胁场景:
- 场景 1(模型权重已知):训练一组编解码器,评估 ATS(隐写分析器)------ 假设其可直接访问训练好的模型。此设置下,ATS 的检测准确率达 98%,说明当模型精确权重被获知时,我们的模型易受统计分析攻击。
- 场景 2(仅知架构 / 超参数,未知模型权重):假设攻击者已知使用了 HiDDeN(且知晓精确架构、超参数与数据集),但无法获取训练好的模型本身(无参数初始化的随机种子则无法精确复现)。为测试该场景,我们用不同种子训练 5 个结构相同的 HiDDeN 模型,提供给 ATS 构建人工训练集;最终训练第 6 个新随机初始化的模型用于评估。当 ATS 测试该第 6 个模型(Ours -- different model)时,检测准确率仅为 50%,与随机猜测无差异。
作为对比,ATS 对 HUGO 的检测准确率为 70%,对 WOW 与 S-UNIWARD 的检测准确率为 68%。该结果表明:每个训练后模型产生的图像失真模式是唯一的,这使得我们的方法在攻击者无法直接访问训练模型时,可规避 ATS 的检测。这体现了学习型隐写模型的优势:与静态的经典算法不同,它们可采用多样化的编码策略。
Against other neural network based methods
文献 21 采用全连接网络生成编码图像,而我们的方法使用卷积网络,大幅提升了编码图像的质量。Figure 7 展示了我们与文献 21 的结果对比:在比特率达到其 2 倍的情况下,我们的方法实现了更低的误差,且生成的图像与载体图像的差异更小。

3.2 Watermarking: Robustness
数字水印优先考虑稳健性,而非容量与保密性:它仅在图像中隐藏少量消息,但这些信息需在编码图像经显著失真后仍能保留。通过调整训练时施加的图像失真类型,我们证明模型可学习对多种失真的稳健性。
我们在尺寸为 C × H × W = 3 × 128 × 128 C \times H \times W = 3 \times 128 \times 128 C×H×W=3×128×128 的YUV彩色图像上训练模型,消息长度 L = 30 L=30 L=30,权重因子 λ I = 0.7 \lambda_I=0.7 λI=0.7、 λ G = 0.001 \lambda_G=0.001 λG=0.001;同时训练了基于恒等映射噪声层(identity noise layer)的模型作为基准。 我们用6种不同噪声层 N N N 训练了专用模型(每种模型针对特定失真优化):Dropout( p = 0.3 p=0.3 p=0.3)、Cropout ( p = 0.3 p=0.3 p=0.3)、Crop( p = 0.035 p=0.035 p=0.035)、Gaussian ( σ = 2.0 \sigma=2.0 σ=2.0)、JPEG-mask、JPEG-drop。此外,我们还训练了组合模型(combined model):训练时每个mini-batch使用不同噪声层(详情见补充材料)。
Baseline
据我们所知,近期数字水印方法无开源实现,因此选择闭源商业工具Digimarc 32作为基线。由于Digimarc闭源,与HiDDeN对比存在局限(尤其是传输准确率),详细分析与对比方法见附录。
Qualitative Results
Figure 8展示了各模型生成的128×128图像示例,以及Digimarc生成的图像,并报告了载体图像 I c o I_{co} Ico 与编码图像 I e n I_{en} Ien 的PSNR。结果显示:我们的模型生成的编码图像与载体图像视觉无差异;组合模型可同时对所有失真保持稳健性,且不牺牲图像质量。

Adversary
Fgiure 8 还对比了"带对抗器训练"与"无对抗器训练"的模型生成图像(均基于组合噪声层训练并单独调优):仅用 l 2 l_2 l2 损失训练的模型生成图像存在可见伪影;而基于对抗判别器训练的模型,生成图像无可见伪影。
Robustness
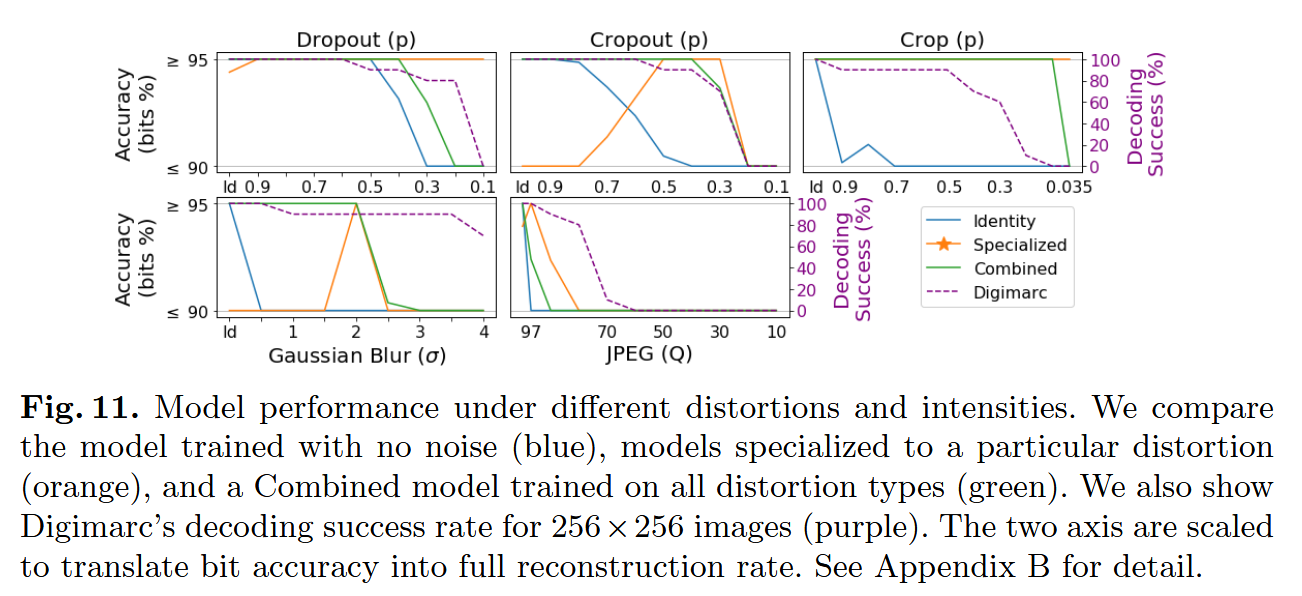
图像失真强度可通过标量控制:Dropout, Cropout, Crop对应保留比例 p p p,Gaussian对应核宽度 σ \sigma σ,JPEG对应质量因子 Q Q Q。 Fgire 9展示了模型在不同噪声层下的比特准确率:评估了identity noise layer 训练的模型(无噪声,蓝色),同类型噪声层训练的专用模型(橙色),组合噪声层训练的模型(绿色),测试集为1000张训练未见过的图像;Figure 10展示了比特准确率随测试失真强度的变化。
无噪声训练的模型在失真场景下表现极差:在Crop与JPEG失真下,比特准确率仅50%(随机水平)------因为训练时编解码器间是无损传输,模型无需学习对失真的稳健性。

Figure 9 中专用模型(橙色柱)的高比特准确率证明:训练时引入失真,模型可学习对多种失真的稳健性------即使失真不可微分(如JPEG):无噪声训练的模型在真实JPEG压缩下准确率仅50%,而用模拟JPEG噪声训练的模型准确率提升至85%。 组合模型(训练时覆盖所有失真)在多数场景下与专用模型性能相当:例如,其对Cropout的准确率达94%,接近专用模型的97%,体现了组合模型的泛化能力。
Compare with Digimarc
Digimarc仅报告固定尺寸水印的解码成功/失败,不提供比特错误率,因此对比需做适配:
- 先估算Digimarc的容量;
- 用纠错码匹配HiDDeN与Digimarc的比特率,将比特准确率转换为解码成功率(少量错误可被纠正,详情见附录B)。
我们定义:HiDDeN的比特准确率 ≥ 95 % \geq95 \% ≥95% 对应Digimarc解码成功, ≤ 90 % \leq90\% ≤90%对应解码失败。
Figure 11展示了对比结果(Y轴按上述标准裁剪):
- 空间域失真 :高噪声强度下,我们的模型性能超过Digimarc。例如,Dropout ( p = 0.1 p=0.1 p=0.1)时,专用模型准确率( ≥ 95 % \geq95\% ≥95%),而Digimarc完全失效;Crop( p = 0.1 p=0.1 p=0.1)时,专用/组合模型准确率均( ≥ 95 % \geq95\% ≥95%),但Digimarc无法恢复测试的10个水印;
- 频率域失真:我们的模型性能弱于Digimarc------原因是我们的架构未嵌入频域变换的先验知识,而水印工具通常直接在频域操作;
4. 结论
我们提出了一个基于神经网络端到端训练的图像数据隐藏框架。相较于经典数据隐藏方法,该框架可通过调整训练阶段的参数或噪声层,灵活权衡容量、保密性与对不同噪声的稳健性。
与基于深度学习的隐写方法相比,我们的方法在定量与定性性能上均有提升。就稳健水印任务而言,HiDDeN 是目前已知首个基于神经网络的端到端方法。
端到端方法(如 HiDDeN)在稳健数据隐藏任务中具备根本优势:新的失真形式可直接融入训练流程,无需设计新的专用算法。
在未来工作中,我们期望提升消息容量、增强对更多样失真(如几何变换、对比度变化及其他有损压缩方案)的稳健性,并拓展至音频、视频等其他输入域的数据隐藏任务。
参考: