文章目录
-
- 从磁盘到文件系统:深入理解Ext2文件系统
- 一、理解磁盘硬件
-
- [1.1 磁盘在计算机中的位置](#1.1 磁盘在计算机中的位置)
- [1.2 磁盘物理结构](#1.2 磁盘物理结构)
- [1.3 磁盘的存储结构](#1.3 磁盘的存储结构)
-
- [1.3.1 磁道(Track)](#1.3.1 磁道(Track))
- [1.3.2 扇区(Sector)](#1.3.2 扇区(Sector))
- [1.3.3 柱面(Cylinder)](#1.3.3 柱面(Cylinder))
- [1.3.4 磁盘容量计算](#1.3.4 磁盘容量计算)
- 二、CHS与LBA寻址
-
- [2.1 CHS寻址方式](#2.1 CHS寻址方式)
- [2.2 磁盘的逻辑结构](#2.2 磁盘的逻辑结构)
-
- [2.2.1 磁带的启示](#2.2.1 磁带的启示)
- [2.2.2 把磁盘"拉直"](#2.2.2 把磁盘"拉直")
- [2.3 LBA寻址](#2.3 LBA寻址)
- [2.4 CHS与LBA转换](#2.4 CHS与LBA转换)
-
- [2.4.1 CHS转LBA](#2.4.1 CHS转LBA)
- [2.4.2 LBA转CHS](#2.4.2 LBA转CHS)
- [2.4.3 谁负责转换?](#2.4.3 谁负责转换?)
- 三、从硬件到文件系统
-
- [3.1 引入"块"概念](#3.1 引入"块"概念)
- [3.2 引入"分区"概念](#3.2 引入"分区"概念)
-
- [3.2.1 为什么要分区?](#3.2.1 为什么要分区?)
- [3.2.2 分区的本质](#3.2.2 分区的本质)
- [3.2.3 Linux下的分区](#3.2.3 Linux下的分区)
- [3.3 引入"inode"概念](#3.3 引入"inode"概念)
-
- [3.3.1 文件 = 内容 + 属性](#3.3.1 文件 = 内容 + 属性)
- [3.3.2 stat命令查看更多信息](#3.3.2 stat命令查看更多信息)
- [3.3.3 inode的定义](#3.3.3 inode的定义)
- [3.3.4 ext2_inode结构体](#3.3.4 ext2_inode结构体)
- 四、Ext2文件系统详解
-
- [4.1 宏观认识](#4.1 宏观认识)
-
- [4.1.1 整体布局](#4.1.1 整体布局)
- [4.2 Block Group 内部构成](#4.2 Block Group 内部构成)
- [4.3 Super Block(超级块)](#4.3 Super Block(超级块))
-
- [4.3.1 作用](#4.3.1 作用)
- [4.3.2 ext2_super_block 结构体(简化)](#4.3.2 ext2_super_block 结构体(简化))
- [4.3.3 为什么多个块组中会出现超级块?](#4.3.3 为什么多个块组中会出现超级块?)
- [4.4 GDT(Group Descriptor Table,块组描述符表)](#4.4 GDT(Group Descriptor Table,块组描述符表))
-
- [4.4.1 ext2_group_desc结构体](#4.4.1 ext2_group_desc结构体)
- [4.4.2 作用](#4.4.2 作用)
- [4.5 Block Bitmap(块位图)](#4.5 Block Bitmap(块位图))
- [4.6 Inode Bitmap(inode位图)](#4.6 Inode Bitmap(inode位图))
- [4.7 Inode Table(inode表)](#4.7 Inode Table(inode表))
- [4.8 Data Blocks(数据块区)](#4.8 Data Blocks(数据块区))
- [4.9 inode与datablock映射](#4.9 inode与datablock映射)
-
- [4.9.1 直接块指针(0-11)](#4.9.1 直接块指针(0-11))
- [4.9.2 一级间接块指针(12)](#4.9.2 一级间接块指针(12))
- [4.9.3 二级间接块指针(13)](#4.9.3 二级间接块指针(13))
- [4.9.4 三级间接块指针(14)](#4.9.4 三级间接块指针(14))
- [4.9.5 最大文件大小](#4.9.5 最大文件大小)
- 五、创建文件的过程
-
- [5.1 touch一个新文件](#5.1 touch一个新文件)
- [5.2 四个核心步骤](#5.2 四个核心步骤)
- [5.3 完整流程图](#5.3 完整流程图)
- 六、总结
从磁盘到文件系统:深入理解Ext2文件系统
💬 欢迎讨论:这是Linux系统编程系列的第九篇文章。在前八篇中,我们学习了进程管理、文件描述符、重定向和缓冲区机制。我们知道文件存储在磁盘上,但磁盘是如何组织管理文件的?文件的属性和内容究竟存储在哪里?Linux如何通过文件名找到文件?本篇将深入磁盘物理结构,理解Ext2文件系统的设计原理。
👍 点赞、收藏与分享:这篇文章包含了磁盘硬件原理、寻址方式和完整的文件系统实现,内容硬核,如果对你有帮助,请点赞、收藏并分享!
🚀 循序渐进:建议先学习前八篇文章,特别是第七、八篇的文件I/O知识,这样理解本篇会更轻松。
一、理解磁盘硬件
1.1 磁盘在计算机中的位置
在学习文件系统之前,我们必须先理解磁盘这个硬件设备。
磁盘的特点:
-
唯一的机械设备
- 计算机中唯一还在使用机械结构的部件
- CPU、内存、主板都是电子器件
- 磁盘有旋转的盘片、移动的磁头
-
外设
- 不属于主机核心部件
- 既是输入设备也是输出设备
- 通过总线与CPU、内存通信
-
慢
- CPU访问寄存器:< 1ns
- CPU访问内存:~100ns
- CPU访问磁盘:~10ms(慢100,000倍!)
-
容量大、价格便宜
- 内存:32GB ~ 128GB,价格昂贵
- 磁盘:1TB ~ 10TB,价格便宜
- 这就是为什么我们需要磁盘
题外话:机房与磁盘
让我们了解一下真实的计算环境:
bash
机房(Data Center)
↓
机柜(Rack)
↓
服务器(Server)
↓
磁盘(Disk)一个典型的互联网公司的机房:
- 成百上千台服务器
- 每台服务器多块磁盘
- RAID阵列提供冗余
- 数据中心级别的存储系统
关于磁铁:
有趣的事实:磁盘利用磁性存储数据,所以强磁场会损坏磁盘数据!早期的数据销毁方法之一就是用强力磁铁消磁。
1.2 磁盘物理结构
让我们深入磁盘内部,看看它的物理结构:
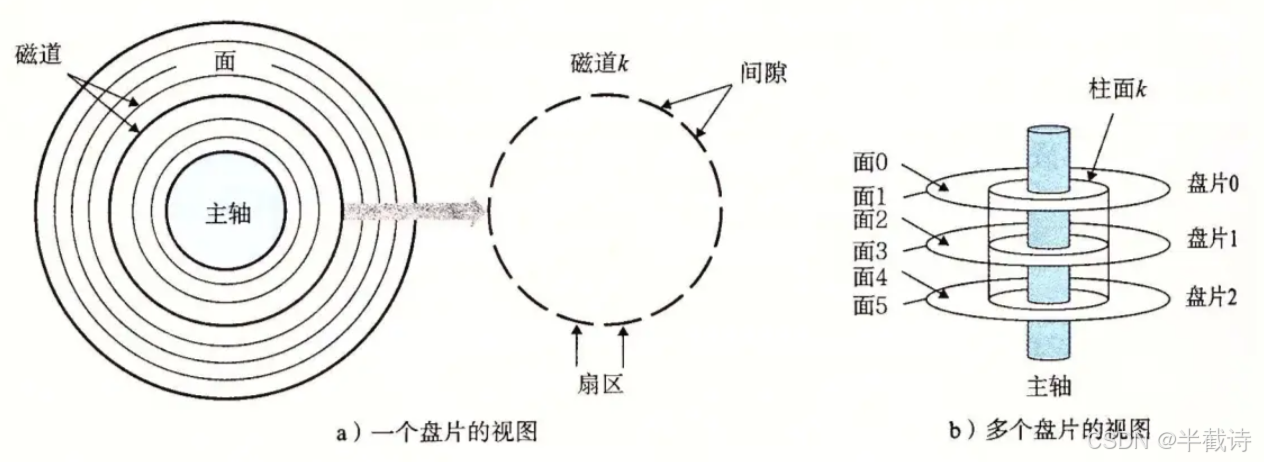
核心部件:
-
盘片(Platter)
- 圆形金属片
- 表面涂有磁性材料
- 高速旋转(5400/7200/10000 RPM)
-
磁头(Head)
- 读写数据的关键部件
- 每个盘面对应一个磁头
- 所有磁头固定在传动臂上
-
主轴(Spindle)
- 驱动盘片旋转
- 保持恒定转速
-
传动臂(Actuator Arm)
- 控制磁头移动
- 关键:所有磁头共进退!
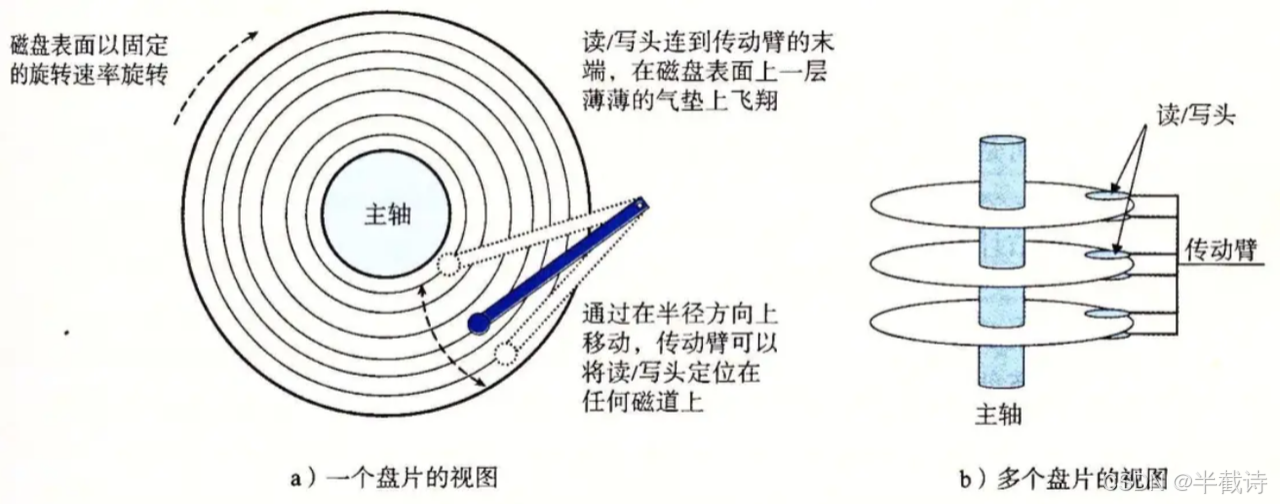
1.3 磁盘的存储结构
磁盘表面是如何组织数据的?
1.3.1 磁道(Track)
磁道特点:
- 同心圆结构
- 从外向内编号:0, 1, 2, ...
- 最内圈用于停靠磁头,不存储数据
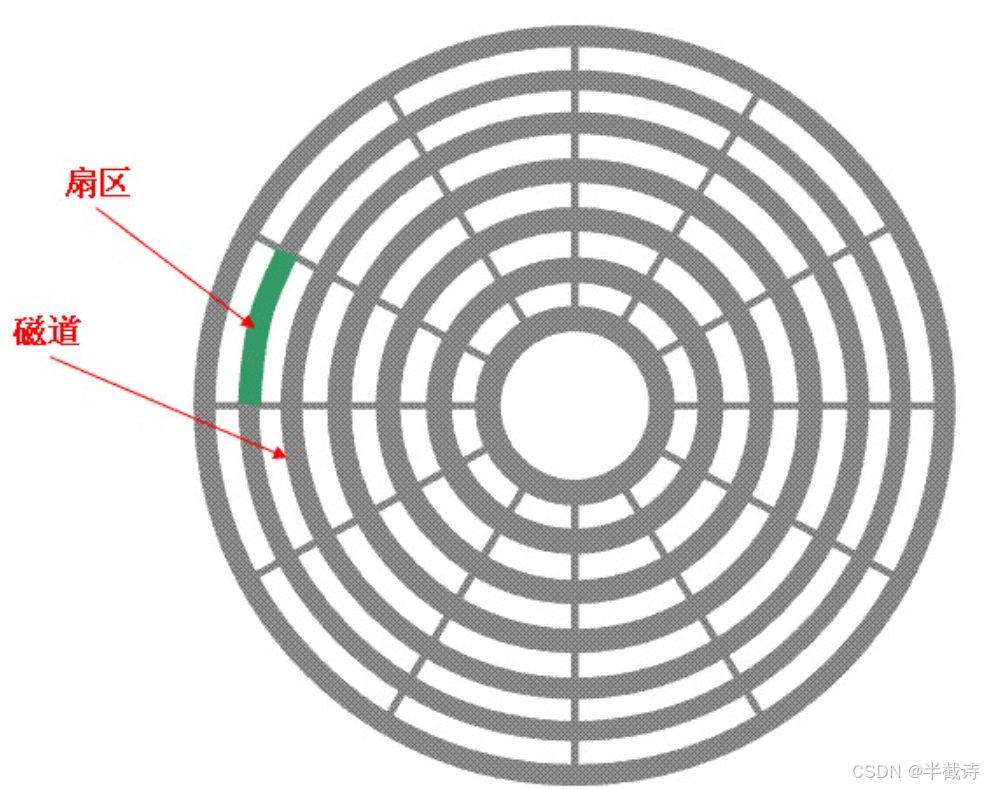
1.3.2 扇区(Sector)
每个磁道被切分成多个扇形区域:
扇区特点:
- 磁盘存储数据的基本单位
- 传统大小:512字节
- 现代磁盘:4096字节(4KB扇区)
- 每个磁道的扇区数相同
1.3.3 柱面(Cylinder)
重要概念:所有盘面上相同位置的磁道构成柱面!
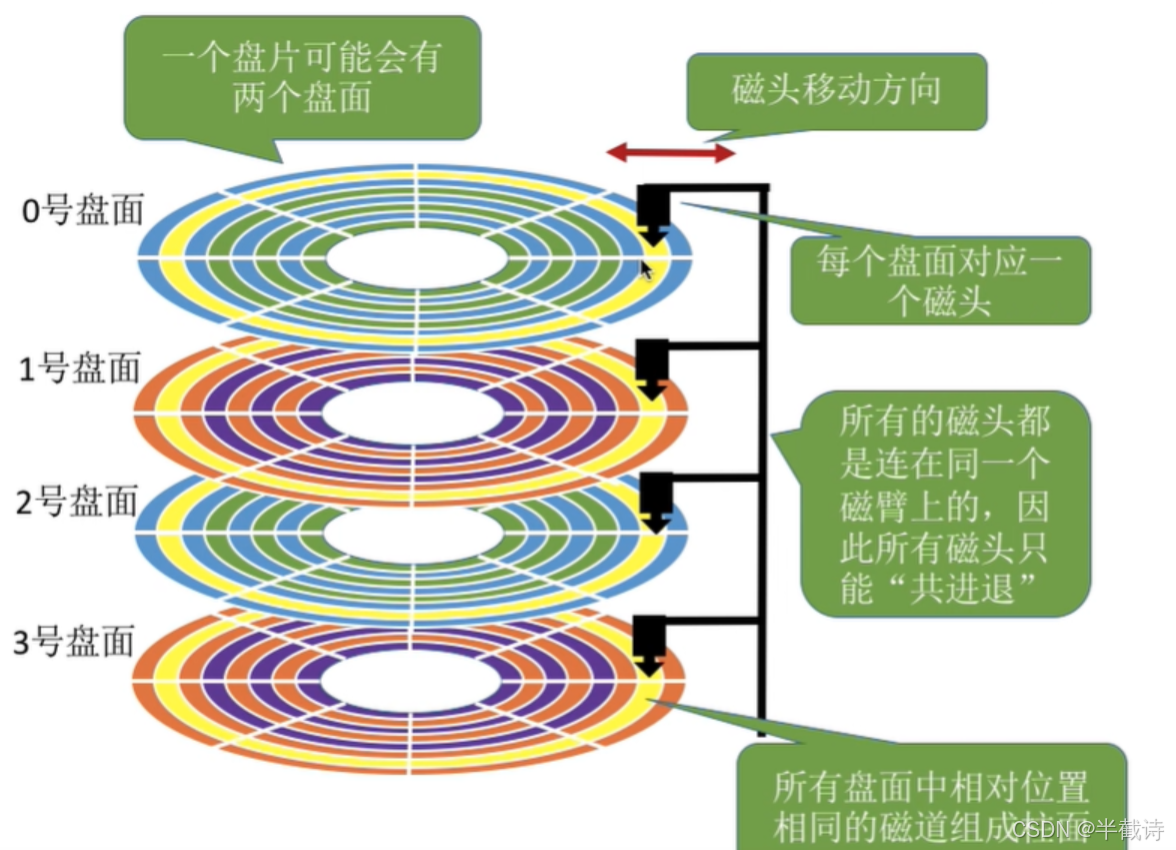
为什么需要柱面概念?
因为所有磁头共进退!当磁头移动到某个位置时,所有盘面上相同位置的磁道都可以访问,这就是柱面。
1.3.4 磁盘容量计算
假设一个磁盘参数:
- 盘片数:2
- 磁头数:4(每个盘片2个面)
- 柱面数(磁道数):1000
- 每磁道扇区数:63
- 每扇区字节数:512
磁盘容量 = 磁头数 × 柱面数 × 每道扇区数 × 每扇区字节数
bash
容量 = 4 × 1000 × 63 × 512
= 129,024,000 字节
≈ 123 MB二、CHS与LBA寻址
2.1 CHS寻址方式
知道了磁盘的物理结构,如何定位一个扇区呢?
CHS:Cylinder-Head-Sector
bash
定位一个扇区的三个步骤:
1. 确定柱面号(Cylinder) ─→ 磁头移动到指定位置
2. 确定磁头号(Head) ─→ 选择哪个盘面
3. 确定扇区号(Sector) ─→ 等待盘片旋转到指定扇区示例:读取 CHS(5, 2, 10)
bash
1. 传动臂移动,使所有磁头到达柱面5
2. 激活磁头2(盘片1的下表面)
3. 等待盘片旋转,直到扇区10经过磁头
4. 读取数据CHS寻址的限制:
早期BIOS使用CHS寻址,受到位数限制:
- 柱面:10 bit → 最多1024个柱面
- 磁头:8 bit → 最多256个磁头
- 扇区:6 bit → 最多63个扇区
最大容量 = 1024 × 256 × 63 × 512 = 8064 MB ≈ 8 GB
这就是为什么早期硬盘不能超过8GB!
2.2 磁盘的逻辑结构
CHS寻址虽然符合物理结构,但使用不便。能否把磁盘看成一个线性数组?
2.2.1 磁带的启示
bash
磁带:线性存储介质
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐
│ 0│ 1│ 2│ 3│ 4│ 5│ 6│ 7│ 8│ 9│
└──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘磁带可以"拉直",形成一维数组。
2.2.2 把磁盘"拉直"
虽然磁盘是旋转的,但我们可以逻辑上把它看成线性结构:
bash
物理结构(CHS):
盘片0上表面 → 柱面0 → 扇区0,1,2,...,62
柱面1 → 扇区0,1,2,...,62
...
盘片0下表面 → 柱面0 → 扇区0,1,2,...,62
...
逻辑结构(线性):
┌────┬────┬────┬────┬────┬────┬────┐
│ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ ...│
└────┴────┴────┴────┴────┴────┴────┘
扇区编号(LBA地址)2.3 LBA寻址
LBA:Logical Block Address(逻辑块地址)
核心思想:给每个扇区一个唯一的线性地址(就像数组下标)
优势:
- 简单:用一个整数就能定位扇区
- 不受CHS位数限制
- 支持更大容量硬盘
- 现代操作系统都使用LBA

2.4 CHS与LBA转换
虽然操作系统使用LBA,但磁盘硬件仍然需要CHS来物理定位。转换由磁盘固件完成。
2.4.1 CHS转LBA
公式:
bash
LBA = C × (磁头数 × 每道扇区数) + H × 每道扇区数 + (S - 1)说明:
- C:柱面号(从0开始)
- H:磁头号(从0开始)
- S:扇区号(从1开始)
示例:
假设磁盘参数:
- 磁头数:4
- 每道扇区数:63
计算 CHS(5, 2, 10) 对应的LBA:
bash
LBA = 5 × (4 × 63) + 2 × 63 + (10 - 1)
= 5 × 252 + 126 + 9
= 1260 + 126 + 9
= 13952.4.2 LBA转CHS
公式:
bash
每柱面扇区数 = 磁头数 × 每道扇区数
C = LBA ÷ 每柱面扇区数
H = (LBA % 每柱面扇区数) ÷ 每道扇区数
S = (LBA % 每道扇区数) + 1示例:
将 LBA = 1395 转换为CHS:
bash
每柱面扇区数 = 4 × 63 = 252
C = 1395 ÷ 252 = 5(余135)
H = 135 ÷ 63 = 2(余9)
S = 9 + 1 = 10
结果:CHS(5, 2, 10) ✓2.4.3 谁负责转换?
bash
操作系统
↓
使用LBA
↓
发送给磁盘控制器
↓
磁盘固件(Firmware)
↓
转换为CHS
↓
伺服系统(Servo System)
↓
物理定位扇区结论:从现在开始,我们可以认为磁盘就是一个"扇区数组",下标就是LBA地址!
三、从硬件到文件系统
3.1 引入"块"概念
虽然扇区是磁盘的物理单位,但操作系统并不直接以扇区为单位操作。
为什么?
- 扇区太小:512字节,读写效率低
- 系统调用开销大:每次读512字节,开销不划算
解决方案:引入"块"(Block)
bash
块 = 连续的多个扇区
常见配置:
┌────┬────┬────┬────┬────┬────┬────┬────┐
│扇区0│扇区1│扇区2│扇区3│扇区4│扇区5│扇区6│扇区7│
└────┴────┴────┴────┴────┴────┴────┴────┘
_************块0************/ ___****块1****
4KB(8个扇区)块的特点:
- 大小固定:通常是4KB(8个扇区)
- 格式化时确定:一旦格式化,不可更改
- 文件存取的最小单位:读写文件至少读写一个块
- 提高效率:减少系统调用次数
块号的计算:
bash
已知LBA:
块号 = LBA ÷ 8
已知块号:
起始LBA = 块号 × 83.2 引入"分区"概念
一块磁盘可以划分成多个独立的区域,每个区域称为分区(Partition)。
3.2.1 为什么要分区?
- 逻辑隔离:系统盘、数据盘分离
- 多操作系统共存:Windows、Linux各占一个分区
- 管理方便:不同分区不同用途
- 安全性:一个分区损坏不影响其他
分治思想
3.2.2 分区的本质
分区的本质:一段连续的 LBA 范围
在现代磁盘上,分区通常用 起始 LBA + 长度(扇区数) 来描述。历史上曾按CHS/柱面对齐,但现代系统更多采用按 1MiB 等边界对齐,以提高性能并兼容 4KB 物理扇区。
bash
早期分区磁盘平铺视图示例:
┌──────────────────────────────────────────────┐
│ Boot │ 分区1 │ 分区2 │ 分区3 │
│ Sector │ (C盘) │ (D盘) │ (E盘) │
│ 1KB │ │ │ │
└──────────────────────────────────────────────┘
柱面0 柱面1-100 柱面101-200 柱面201-3003.2.3 Linux下的分区
bash
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 50G 0 part /
├─sda2 8:2 0 30G 0 part /home
└─sda3 8:3 0 20G 0 part [SWAP]sda:第一块SATA硬盘sda1:第一个分区sda2:第二个分区sda3:第三个分区
3.3 引入"inode"概念
现在我们知道:
- 磁盘 = 扇区数组(LBA寻址)
- 操作系统 = 块数组
- 一个磁盘可以有多个分区
但还有一个核心问题:文件的属性存储在哪里?
3.3.1 文件 = 内容 + 属性
我们之前学过:
bash
ls -l test.c
-rw-r--r-- 1 root root 654 Sep 13 14:56 test.c这一行包含了文件的属性:
- 权限:
-rw-r--r-- - 硬链接数:
1 - 所有者:
root - 所属组:
root - 大小:
654字节 - 修改时间:
Sep 13 14:56 - 文件名:
test.c
3.3.2 stat命令查看更多信息
bash
stat test.c
File: test.c
Size: 654 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 263715 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-09-13 14:56:57.059012947 +0800
Modify: 2017-09-13 14:56:40.067012944 +0800
Change: 2017-09-13 14:56:40.069012948 +0800关键信息:
Inode: 263715:inode号Blocks: 8:占用8个块IO Block: 4096:块大小4KB- 三个时间:Access(访问)、Modify(修改)、Change(属性变化)
3.3.3 inode的定义
inode(index node,索引节点):存储文件元信息(属性)的数据结构
核心特点:
- 一个文件一个inode
- inode有唯一的编号
- 属性与内容分离存储
- inode大小固定:通常128字节或256字节
3.3.4 ext2_inode结构体
c
struct ext2_inode {
__le16 i_mode; // 文件类型和权限
__le16 i_uid; // 所有者UID
__le32 i_size; // 文件大小
__le32 i_atime; // 最后访问时间
__le32 i_ctime; // 状态改变时间(metadata change time)
__le32 i_mtime; // 最后修改时间
__le32 i_dtime; // 删除时间
__le16 i_gid; // 所属组GID
__le16 i_links_count; // 硬链接计数
__le32 i_blocks; // 占用的块数
__le32 i_flags; // 文件标志
// ... 其他字段
__le32 i_block[EXT2_N_BLOCKS]; // 数据块指针数组(重要!)
// ... 其他字段
};最重要的字段:i_block[15]
这个数组存储了文件内容所在的块号,后面会详细讲解。
注意:文件名不在inode中!
四、Ext2文件系统详解
现在所有准备工作都完成了,让我们正式认识 Ext2 文件系统!
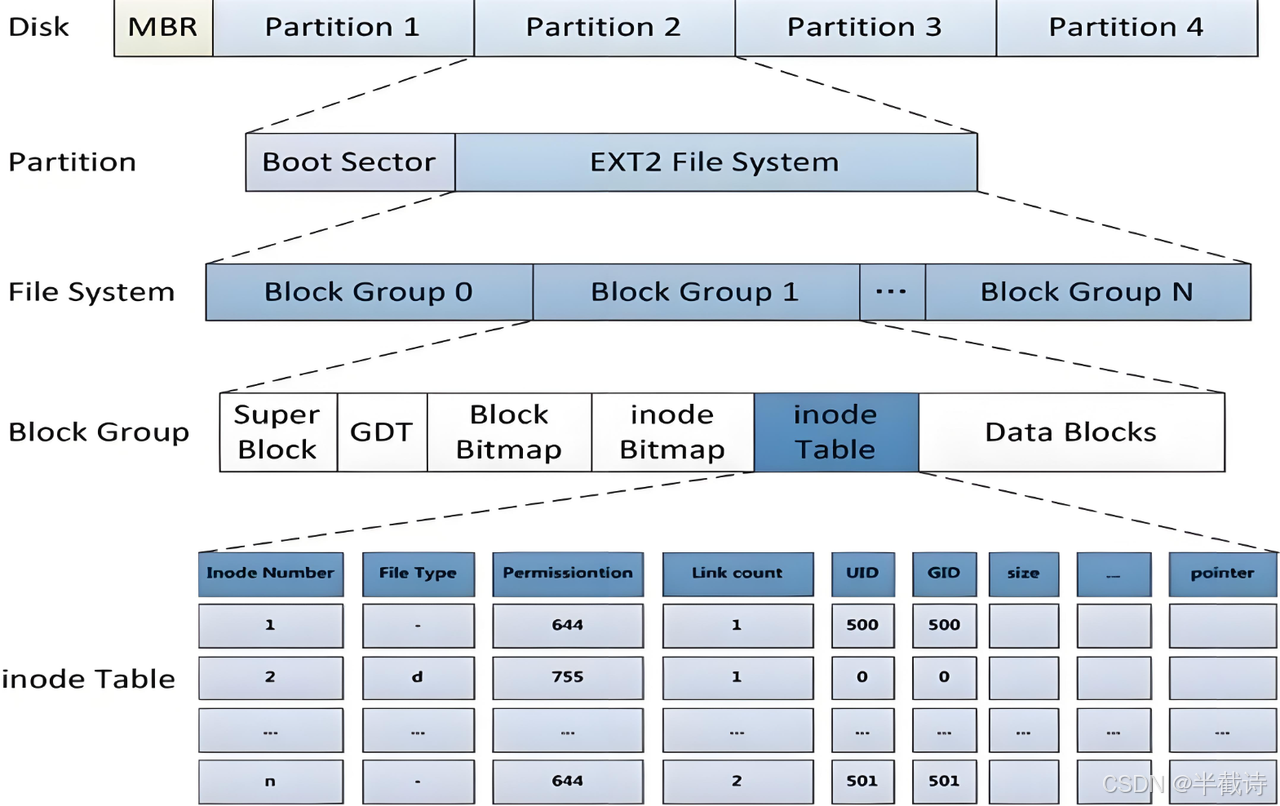
4.1 宏观认识
文件系统的目的:组织和管理磁盘中的文件
Ext2(Second Extended Filesystem)是 Linux 早期的主流文件系统。虽然如今已经发展出了 Ext3、Ext4 等更新的文件系统,但它们在整体设计思想和核心数据结构上,都继承自 Ext2。因此,理解 Ext2 是理解整个 Linux 文件系统体系的基础。
注意:文件系统通常以分区作为载体,它既包含磁盘上的数据结构布局,也包含操作系统中用于解析和管理这些结构的代码实现。不同分区可以使用不同的文件系统
4.1.1 整体布局
在一个已经格式化为 Ext2 的分区中,磁盘空间的整体布局如下:
text
┌────────────┬──────────────────────────────────────────┐
│ Boot Block │ File System Area (Ext2) │
│ (reserved)│ │
│ │ Block Group 0 | Block Group 1 | ... │
└────────────┴──────────────────────────────────────────┘注意:这里讨论的是分区内部结构,而不是整个磁盘。
Boot Block(引导保留区)
-
位置:分区起始位置的第一个块(通常对应分区起始扇区)
-
大小:与文件系统块大小相关(Ext2 中通常为 1KB)
-
用途:
- 为启动程序(Bootloader)或历史兼容性预留
- 可能包含分区级启动代码,也可能完全未使用
-
重要说明:
- Boot Block 不属于文件系统的正式数据结构
- 是否写入启动代码,取决于系统启动方式(BIOS / UEFI)和实际需求
- 这是文件系统的约定性保留区域,并非硬件强制不可修改
从 SuperBlock 开始,文件系统才正式接管该分区的空间。
Block Group(块组)
在 Ext2 中,整个文件系统区域被划分为多个 Block Group(块组):
- 一个分区包含 多个块组
- 每个块组的 大小相同
- 每个块组的 内部结构基本一致
为什么要引入块组?
text
整个分区太大 → 管理复杂、访问效率低
↓
划分为多个块组 → 分而治之
↓
每个块组独立管理自己的 inode 和数据块这种设计可以:
- 提高空间分配和查找效率
- 减少磁盘寻道距离
- 提高文件系统的可靠性
4.2 Block Group 内部构成
每个块组在逻辑上包含如下结构:
text
┌───────────────────────────────────────────┐
│ Block Group │
│ │
│ [SuperBlock backup] (可选,备份) │
│ [GDT backup] (可选,备份) │
│ Block Bitmap │
│ Inode Bitmap │
│ Inode Table │
│ Data Blocks │
└───────────────────────────────────────────┘注意:
SuperBlock 和 GDT 在部分块组中以备份形式存在,并非每个块组都包含。
下面我们逐一理解这些组成部分。
4.3 Super Block(超级块)
SuperBlock 是整个 Ext2 文件系统的核心元数据结构。
它描述的是整个文件系统的全局状态,而不是某一个具体文件或块组。
4.3.1 作用
超级块中记录了文件系统的关键信息,包括但不限于:
- inode 和 block 的总数量
- 空闲 inode 和 block 的数量
- block 和 inode 的大小
- 每个块组包含的 block / inode 数量
- 最近一次挂载时间、写入时间
- 文件系统状态和魔数
- 文件系统检查相关信息
只要 SuperBlock 损坏,文件系统就无法被正确识别。
4.3.2 ext2_super_block 结构体(简化)
c
struct ext2_super_block {
__le32 s_inodes_count; // inode 总数
__le32 s_blocks_count; // block 总数
__le32 s_r_blocks_count; // 保留 block 数
__le32 s_free_blocks_count; // 空闲 block 数
__le32 s_free_inodes_count; // 空闲 inode 数
__le32 s_first_data_block; // 第一个数据块号
__le32 s_log_block_size; // block 大小(log2)
__le32 s_log_frag_size; // 片段大小
__le32 s_blocks_per_group; // 每个块组的 block 数
__le32 s_frags_per_group; // 每组片段数
__le32 s_inodes_per_group; // 每组 inode 数
// ...
__le32 s_mtime; // 最近挂载时间
__le32 s_wtime; // 最近写入时间
__le16 s_mnt_count; // 挂载计数
__le16 s_max_mnt_count; // 最大挂载计数
__le16 s_magic; // 魔数(0xEF53)
__le16 s_state; // 文件系统状态
__le16 s_errors; // 错误处理方式
__le32 s_lastcheck; // 上次检查时间
__le32 s_checkinterval; // 检查间隔
__le32 s_creator_os; // 创建者 OS
__le32 s_rev_level; // 修订级别
__le16 s_def_resuid; // 保留块默认 uid
__le16 s_def_resgid; // 保留块默认 gid
__le32 s_first_ino; // 第一个非保留 inode
__le16 s_inode_size; // inode 大小
__le16 s_block_group_nr; // 本超级块所在块组号
// ...
};4.3.3 为什么多个块组中会出现超级块?
答案:冗余备份(可靠性设计)。
text
Block Group 0 : SuperBlock(主)
Block Group N : SuperBlock(备份)原因如下:
- 超级块损坏 → 文件系统整体不可用
- 磁盘可能出现坏道
- 在多个块组中保存备份,可以提高容错能力
- Block Group 0 一定包含主超级块
- 其他块组中是否保存备份,取决于文件系统的具体策略(如 sparse super)
4.4 GDT(Group Descriptor Table,块组描述符表)
GDT存储每个块组的描述信息
4.4.1 ext2_group_desc结构体
在 ext2 中,块组描述符表(GDT)是一个由多个 ext2_group_desc 结构体组成的数组,其中第 i 个描述符记录了分区内第
i 个块组的元数据布局信息,如块位图、inode 位图和 inode 表在磁盘上的块号。
c
struct ext2_group_desc {
__le32 bg_block_bitmap; // 块位图所在块号
__le32 bg_inode_bitmap; // inode位图所在块号
__le32 bg_inode_table; // inode表起始块号
__le16 bg_free_blocks_count; // 空闲块数
__le16 bg_free_inodes_count; // 空闲inode数
__le16 bg_used_dirs_count; // 目录数
__le16 bg_pad; // 填充
__le32 bg_reserved[3]; // 保留
};4.4.2 作用
bash
假设有3个块组:
GDT[0] → 描述Block Group 0
├─ 块位图在哪里
├─ inode位图在哪里
├─ inode表在哪里
└─ 空闲块/inode数量
GDT[1] → 描述Block Group 1
└─ ...
GDT[2] → 描述Block Group 2
└─ ...4.5 Block Bitmap(块位图)
位图记录哪些数据块已被使用
bash
Block Bitmap(假设只有16个数据块):
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐
│ 1│ 1│ 0│ 1│ 0│ 0│ 0│ 1│ 1│ 0│ 0│ 0│ 0│ 0│ 0│ 0│
└──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
↑ ↑ ↑ ↑ ↑
已 已 已 已 已
用 用 用 用 用
1 = 已使用
0 = 空闲作用:
- 快速查找空闲块
- 分配新块时使用
- 释放块时清除对应位
大小:
- 一个块组有N个数据块
- 需要N个bit来记录
- 如果块大小4KB = 4096字节 = 32768 bit
- 一个块位图块可以管理32768个数据块
- 即:4KB位图可以管理 32768 × 4KB = 128MB
4.6 Inode Bitmap(inode位图)
位图记录哪些inode已被使用
bash
Inode Bitmap(假设只有16个inode):
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐
│ 1│ 1│ 1│ 1│ 1│ 1│ 1│ 1│ 0│ 0│ 1│ 0│ 0│ 0│ 0│ 0│
└──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
↑保留 ↑ ↑ ↑
(前8个通常是系统保留)
1 = 已使用
0 = 空闲注意:
- 前几个inode通常被系统保留
- inode 2 通常是根目录
/
4.7 Inode Table(inode表)
存储所有inode结构体的区域
bash
Inode Table:
┌─────────────┐
│ inode 1 │ ← 128字节
├─────────────┤
│ inode 2 │ ← 128字节(根目录)
├─────────────┤
│ inode 3 │ ← 128字节
├─────────────┤
│ inode 4 │
├─────────────┤
│ ... │
├─────────────┤
│ inode N │
└─────────────┘计算:
- 假设块组有8192个inode
- 每个inode 128字节
- inode表大小 = 8192 × 128 = 1MB = 256个块
4.8 Data Blocks(数据块区)
存储文件实际内容的区域
bash
Data Blocks:
┌───────┬───────┬───────┬───────┬───────┐
│Block 0│Block 1│Block 2│Block 3│ ... │
└───────┴───────┴───────┴───────┴───────┘
4KB 4KB 4KB 4KB不同文件类型的存储:
- 普通文件:文件内容
- 目录:目录项(文件名 + inode号映射)
- 符号链接:目标路径
4.9 inode与datablock映射
核心问题:inode如何找到文件内容所在的数据块?
答案:i_block15数组
c
struct ext2_inode {
// ... 其他字段
__le32 i_block[EXT2_N_BLOCKS]; // EXT2_N_BLOCKS = 15
};4.9.1 直接块指针(0-11)
bash
i_block[0] → 直接指向数据块0
i_block[1] → 直接指向数据块1
...
i_block[11] → 直接指向数据块11
可以直接访问 12 个数据块 = 12 × 4KB = 48KB4.9.2 一级间接块指针(12)
bash
i_block[12] → 指向一个间接块
↓
┌───────────┐
│ 块号0 │ → 数据块
│ 块号1 │ → 数据块
│ ... │
│ 块号1023 │ → 数据块
└───────────┘
一个4KB块可以存储1024个块号(4字节×1024=4KB)
可以访问 1024 个数据块 = 1024 × 4KB = 4MB4.9.3 二级间接块指针(13)
bash
i_block[13] → 一级间接块
↓
┌─────────┐
│ 块号0 │ → 二级间接块 → 1024个数据块
│ 块号1 │ → 二级间接块 → 1024个数据块
│ ... │
│ 块号1023│ → 二级间接块 → 1024个数据块
└─────────┘
可以访问 1024 × 1024 = 1048576 个数据块 = 4GB4.9.4 三级间接块指针(14)
bash
i_block[14] → 一级间接块 → 二级间接块 → 三级间接块 → 数据块
可以访问 1024 × 1024 × 1024 = 1073741824 个数据块 = 4TB4.9.5 最大文件大小
bash
直接块: 12 × 4KB = 48KB
一级间接: 1024 × 4KB = 4MB
二级间接: 1024 × 1024 × 4KB = 4GB
三级间接: 1024 × 1024 × 1024 × 4KB = 4TB
总计:约 4TB注:以上为在 block=4KB、块号占 4 字节时的理论寻址规模估算,实际最大文件大小还可能受具体实现与字段限制影响。
五、创建文件的过程
现在让我们通过一个完整的例子,理解文件系统是如何工作的。
5.1 touch一个新文件
bash
touch abc
ls -i abc
263466 abc5.2 四个核心步骤
步骤1:分配inode
bash
1. 查找Inode Bitmap,找到空闲的inode
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐
│ 1│ 1│ 1│ 1│ 0│ 1│ 1│ 1│ 0│ 0│ 0│ 0│
└──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘
↑找到空闲的inode 5
2. 在Inode Bitmap中标记为已使用
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐
│ 1│ 1│ 1│ 1│ 1│ 1│ 1│ 1│ 0│ 0│ 0│ 0│
└──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘
↑
3. 在Inode Table中初始化inode结构体
inode[5].i_mode = 0644;
inode[5].i_uid = 0;
inode[5].i_size = 0;
inode[5].i_ctime = 当前时间;
inode[5].i_mtime = 当前时间;
// ...步骤2:分配数据块(如果有内容)
假设文件需要写入一些内容:
bash
1. 查找Block Bitmap,找到空闲块
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐
│ 1│ 1│ 0│ 1│ 0│ 0│ 1│ 1│ 0│ 0│
└──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘
↑ ↑ ↑ ↑
找到空闲块:2, 4, 5, 8
2. 假设分配块2、4、5
3. 在Block Bitmap中标记
┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐
│ 1│ 1│ 1│ 1│ 1│ 1│ 1│ 1│ 0│ 0│
└──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘
4. 将数据写入这些块步骤3:记录块分配情况
bash
在inode中记录数据块位置:
inode[5].i_block[0] = 2; // 第一个块
inode[5].i_block[1] = 4; // 第二个块
inode[5].i_block[2] = 5; // 第三个块
inode[5].i_blocks = 3; // 总共3个块
inode[5].i_size = 实际字节数;步骤4:添加目录项
bash
在当前目录的数据块中添加记录:
目录的数据块内容:
┌────────┬───────────┐
│ inode │ 文件名 │
├────────┼───────────┤
│ 2 │ . │ (当前目录)
│ 1048577│ .. │ (父目录)
│ 263464 │ test.c │
│ 263465 │ main.c │
│ 263466 │ abc │ ← 新添加
└────────┴───────────┘
目录项结构(简化):
struct ext2_dir_entry {
__le32 inode; // inode号
__le16 rec_len; // 记录长度
__u8 name_len; // 文件名长度
__u8 file_type; // 文件类型
char name[]; // 文件名
};5.3 完整流程图
bash
创建文件 abc 的完整流程:
┌─────────────────┐
│ 用户执行touch │
└────────┬────────┘
↓
┌────────┴────────┐
│ 系统调用creat │
└────────┬────────┘
↓
┌────────┴────────────────┐
│ VFS层 │
│ 1. 解析路径 │
│ 2. 检查权限 │
│ 3. 调用ext2_create │
└────────┬────────────────┘
↓
┌────────┴────────────────┐
│ Ext2文件系统 │
│ │
│ ① 分配inode │
│ 查Inode Bitmap │
│ 找到空闲inode 263466│
│ 标记为已用 │
│ 初始化inode结构 │
│ │
│ ② 分配数据块(可选) │
│ 查Block Bitmap │
│ 找到空闲块 │
│ 标记为已用 │
│ │
│ ③ 更新inode │
│ 记录块号到i_block[] │
│ 更新i_size等字段 │
│ │
│ ④ 更新目录 │
│ 在父目录数据块中 │
│ 添加(263466, "abc") │
│ │
│ ⑤ 更新元信息 │
│ Super Block │
│ GDT │
└────────┬────────────────┘
↓
┌────────┴────────┐
│ 返回成功 │
└─────────────────┘六、总结
通过本篇文章,我们深入理解了从磁盘硬件到Ext2文件系统的完整知识体系:
核心知识点:
-
磁盘物理结构
- 盘片、磁头、磁道、扇区、柱面
- 扇区:512字节,存储基本单位
-
寻址方式
- CHS:物理寻址,容量受限
- LBA:逻辑寻址,磁盘=扇区数组
- 固件负责CHS↔LBA转换
-
从硬件到文件系统
- 块:8个扇区,4KB,提高效率
- 分区:柱面为单位,逻辑隔离
- inode:存储文件属性,固定大小
-
Ext2文件系统
- Boot Block + Block Groups
- 每个块组:SB + GDT + 位图 + inode表 + 数据区
- Super Block:文件系统全局信息
- GDT:块组描述信息
- 位图:管理空闲块和inode
- inode表:存储所有inode
- 数据区:存储文件内容
-
inode与数据块映射
- i_block15数组
- 直接块 + 间接块 + 二级间接 + 三级间接
- 最大文件约4TB
-
创建文件过程
- 分配inode
- 分配数据块
- 更新inode
- 添加目录项
重要原理图:
bash
完整的文件访问流程:
文件名 "abc"
↓
查找目录(需要目录的inode)
↓
找到目录项:(263466, "abc")
↓
获得inode号:263466
↓
定位inode:块组号 = 263466 / 每组inode数
inode表偏移 = 263466 % 每组inode数
↓
读取inode结构体
↓
从i_block[]获取数据块号
↓
读取数据块
↓
得到文件内容下一篇预告:
在下一篇文章中,我们将学习:
- 目录的本质:目录也是文件
- 路径解析:从根目录开始的递归过程
- 路径缓存:dentry结构体
- 挂载分区:如何访问多个分区
- 软硬链接:两种不同的文件引用方式
💡 思考题:
- 为什么需要位图?能否用其他数据结构管理空闲块?
- 如果一个块组的inode用完了,文件会创建失败吗?
- 为什么inode要固定大小?如果可变会有什么问题?
- 删除一个大文件时,系统主要做什么操作?
以上就是Ext2文件系统的核心原理!下一篇我们将学习目录、路径和软硬链接!