基于YARN的Flink实时流应用内存使用率高,通常源于资源配置不当、数据处理不均或应用本身的问题。你可以按照以下路径系统性地排查和解决。
🗺️ 系统排查路径
你可以遵循下图的步骤,从集群资源到应用逻辑层层深入,定位问题根源。
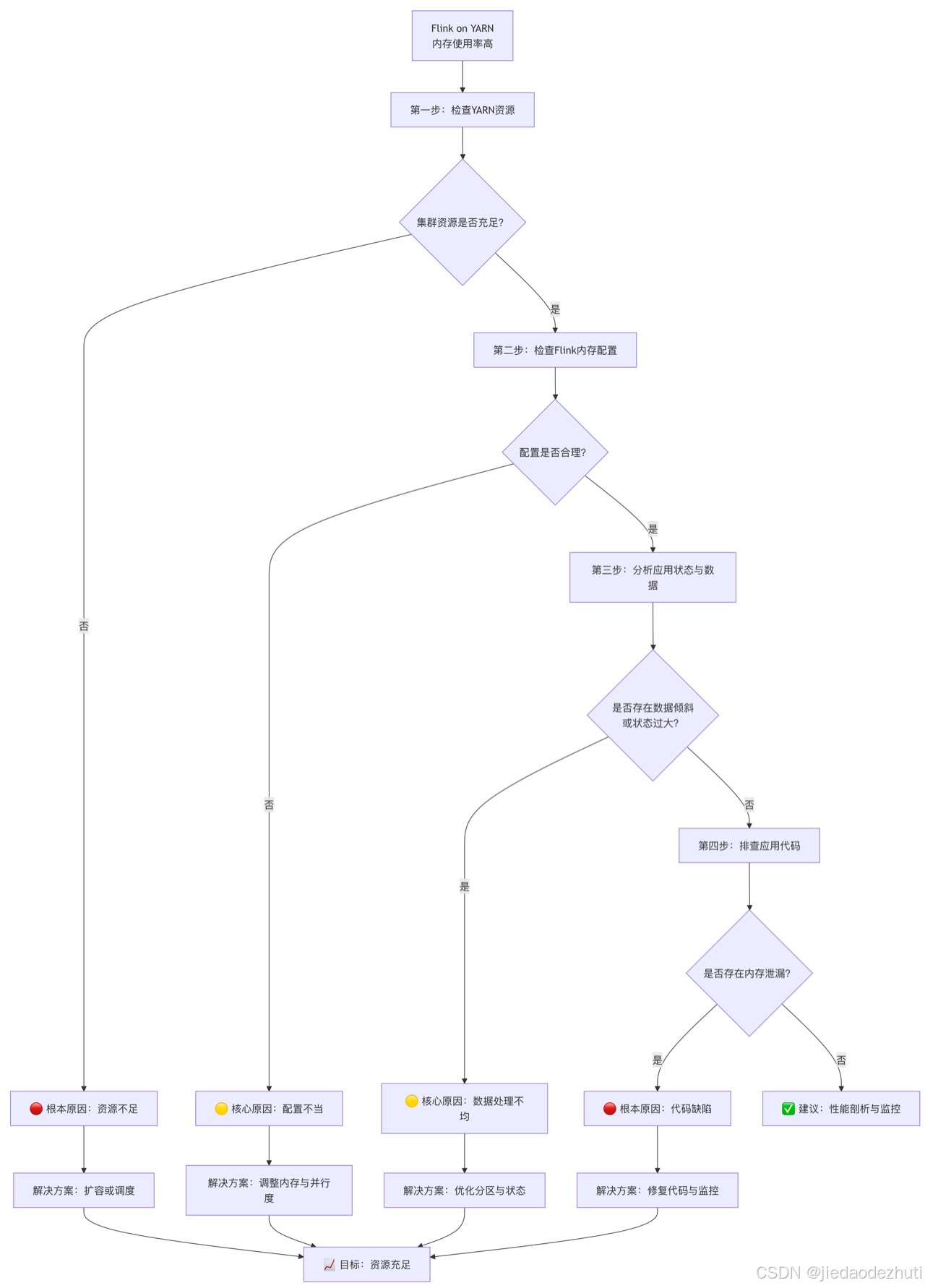
🔧 针对性解决方案
根据上述排查路径,你可以从以下几个方面着手优化。
1. 调整资源配置
不合理的资源配置是导致内存问题的首要原因。以下是基于YARN提交任务时和flink-conf.yaml中的关键参数调整建议:
核心配置参数
· TaskManager进程总内存 (-tm / taskmanager.memory.process.size)
· 作用与影响:单个TaskManager可使用的总内存上限。
· 建议与操作:依据任务复杂度调整。若任务状态大或并发高,需增加。可参考值:30GB - 50GB。
· TaskManager堆内存 (taskmanager.memory.task.heap.size)
· 作用与影响:用于运行用户代码的核心内存,不足会直接导致OOM。
· 建议与操作:在进程总内存中确保足够比例。可通过 -D 参数指定,如 -Dtaskmanager.memory.task.heap.size=4096m。
· 托管内存 (taskmanager.memory.managed.size)
· 作用与影响:由Flink管理,用于排序、缓存、RocksDB状态后端。
· 建议与操作:使用RocksDBStateBackend时必须配置足够大(如总内存的30%-50%)。堆上状态后端可设为0。
· JobManager内存 (-jm / jobmanager.memory.process.size)
· 作用与影响:负责任务调度与协调,任务过多或状态大时需要增加。
· 建议与操作:通常小于TaskManager内存。可参考值:4GB - 8GB。
· TaskManager数量 (-n) 与 Slot数 (-s)
· 作用与影响:决定总并发能力。Slot数过多会稀释单个Task可用内存。
· 建议与操作:总并行度 ≈ TaskManager数量 × 每个TaskManager的Slot数。避免Slot数设置过高导致单个Task内存不足。
并行度设置
并行度并非越高越好。过高的并行度会导致任务切片过细,每个TaskManager需要维护更多线程和缓冲区,增加管理开销和内存碎片。请根据数据吞吐量和可用资源合理设置。
2. 优化状态后端 (State Backend)
如果你使用 RocksDBStateBackend,内存配置尤为关键,因为它严重依赖堆外(托管)内存。
· 确保托管内存充足:RocksDB的性能和状态存储依赖托管内存。你需要显式配置 taskmanager.memory.managed.size 为一个较大的值(例如总内存的40%)。
· 调整RocksDB内存:检查 state.backend.rocksdb.memory.managed 是否为 true(默认值)。这允许Flink管理RocksDB的内存使用,防止其失控增长导致容器被YARN杀死。
3. 处理数据倾斜
数据倾斜会导致少数Task负载过重、内存激增,而其他Task闲置。解决方法包括:
· 重新设计Key:使用更组合、更均匀的Key来分散数据。
· 使用预聚合:在本地进行一定程度的预聚合,减少发送到下游的数据量。
· 使用重分区算子:在可能发生倾斜的算子前,使用 rebalance() 或 rescale() 算子强制数据均匀分布。
4. 排查应用内存泄漏
如果上述调整后内存仍持续增长,可能存在代码层面的内存泄漏。
· 开启内存监控:在Flink UI中观察各Task的"Memory Usage"是否随时间持续增长而不释放。
· 启用Heap Dump:在JVM参数中添加 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dump,在OOM时自动生成堆转储文件,用MAT等工具分析可疑对象。
· 检查用户代码:重点审查无限增长的集合、未关闭的外部连接、生命周期过长的静态变量引用等。
💎总结与行动建议
综合来看,解决Flink内存使用率高的问题,建议你按以下优先级操作:
-
首先检查并调整配置:确认 TaskManager 总内存、堆内存、托管内存的设置是否与你的任务状态大小和计算复杂度匹配。
-
其次分析数据分布:通过Flink UI检查各Subtask的吞吐量和背压情况,判断是否存在数据倾斜,并应用相应的数据重分布策略。
-
最后深入代码排查:如果配置和数据都正常,则需使用监控工具和Heap Dump诊断用户代码是否存在内存泄漏。